Apache Paimon Append Queue表解析
a) 定义
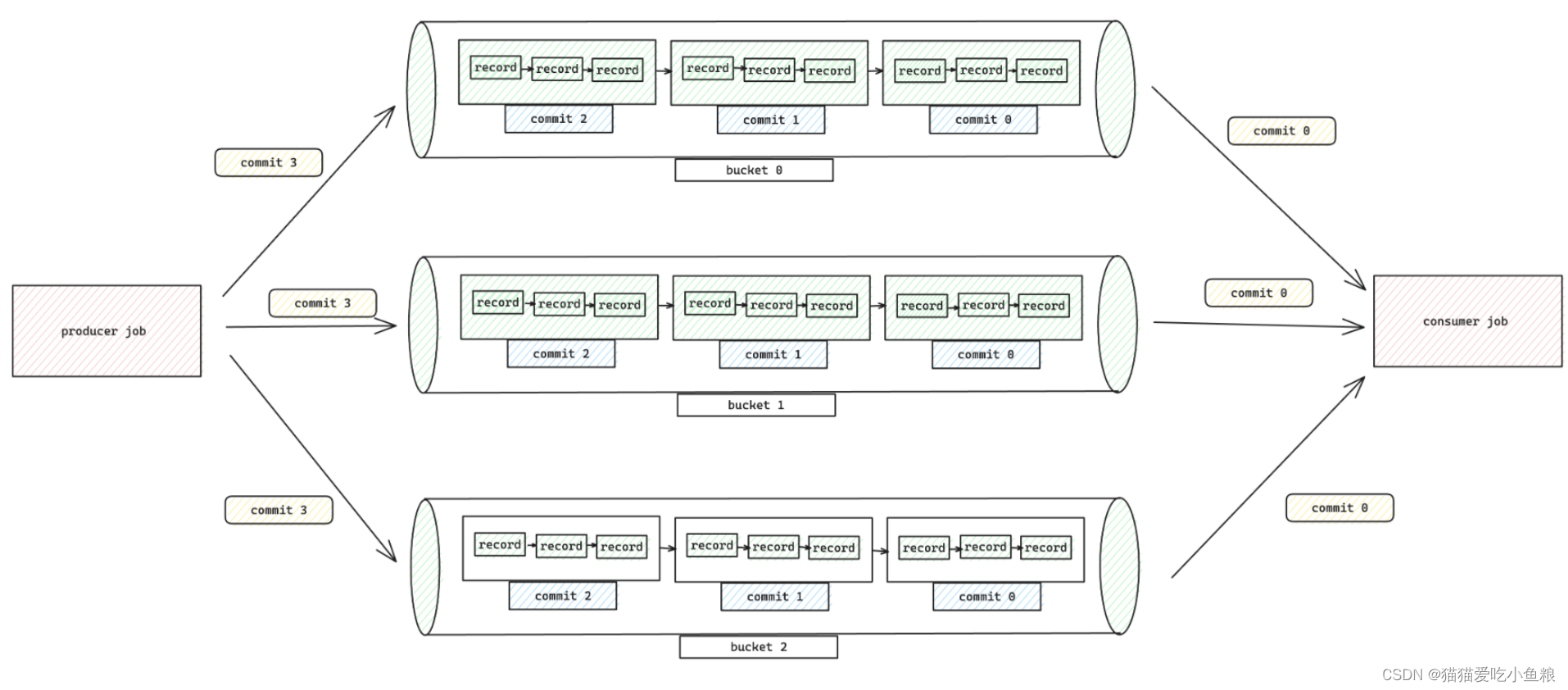
在此模式下,将append table视为由bucket分隔的queue。
同一bucket中的每条record都是严格排序的,流式读取将完全按照写入顺序将record传输到下游。
使用此模式,无需特殊配置,所有数据都将作为queue进入一个bucket,还可以定义bucket和bucket-key,以启用更大的并行度和分散数据。
b) Compaction
默认情况下,sink node将自动执行compaction以控制文件数量,以下参数调整compaction策略:
| Key | Default | Type | Description |
|---|---|---|---|
| write-only | false | Boolean | If set to true, compactions and snapshot expiration will be skipped. This option is used along with dedicated compact jobs. |
| compaction.min.file-num | 5 | Integer | For file set [f_0,…,f_N], the minimum file number which satisfies sum(size(f_i)) >= targetFileSize to trigger a compaction for append table. This value avoids almost-full-file to be compacted, which is not cost-effective. |
| compaction.max.file-num | 50 | Integer | For file set [f_0,…,f_N], the maximum file number to trigger a compaction for append table, even if sum(size(f_i)) < targetFileSize. This value avoids pending too much small files, which slows down the performance. |
| full-compaction.delta-commits | (none) | Integer | Full compaction will be constantly triggered after delta commits. |
c) Streaming Source
目前仅支持Flink引擎。
i)Streaming Read Order
对于streaming reads,records按以下顺序生成:
- 两条记录来自不同的分区
- 如果
scan.plan-sort-partition设置为true,分区值较小的记录将先生成。 - 否则,将首先生成具有较早分区创建时间的记录。
- 如果
- 两条记录来自同一分区的同一个桶,先written的记录将先生成。
- 两条记录来自同一分区的两个不同桶,不同的桶由不同的任务处理,它们之间不保证有序。
ii) Watermark 定义
定义reading Paimon tables的watermark。
CREATE TABLE T (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (...);
-- launch a bounded streaming job to read paimon_table
SELECT window_start, window_end, COUNT(`user`) FROM TABLE(
TUMBLE(TABLE T, DESCRIPTOR(order_time), INTERVAL '10' MINUTES)) GROUP BY window_start, window_end;
可以启用Flink Watermark alignment,确保没有sources/splits/shards/partitions额外增加watermarks:
| Key | Default | Type | Description |
|---|---|---|---|
| scan.watermark.alignment.group | (none) | String | A group of sources to align watermarks. |
| scan.watermark.alignment.max-drift | (none) | Duration | Maximal drift to align watermarks, before we pause consuming from the source/task/partition. |
iii) Bounded Stream
Streaming Source可以有界,指定"scan.bounded.watermark"定义有界流模式的结束条件,遇到更大的watermark snapshot时stream reading将结束。
snapshot中的Watermark由writer生成,例如,指定kafka source并定义watermark,当使用此kafka source写入Paimon表时,Paimon表的snapshots将生成相应的watermark,以便在streaming reads此Paimon表时使用bounded watermark功能。
CREATE TABLE kafka_table (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH ('connector' = 'kafka'...);
-- launch a streaming insert job
INSERT INTO paimon_table SELECT * FROM kakfa_table;
-- launch a bounded streaming job to read paimon_table
SELECT * FROM paimon_table /*+ OPTIONS('scan.bounded.watermark'='...') */;
d)创建Append table并指定bucket key示例
CREATE TABLE MyTable (
product_id BIGINT,
price DOUBLE,
sales BIGINT
) WITH (
'bucket' = '8',
'bucket-key' = 'product_id'
);