深度学习总结(12)
层:深度学习的基础模块
神经网络的基本数据结构是层。层是一个数据处理模块,它接收一个或多个张量作为输入,并输出一个或多个张量。有些层是无状态的,但大多数层具有状态,即层的权重。权重是利用随机梯度下降学到的一个或多个张量,其中包含神经网络的知识(knowledge)。
不同类型的层适用于不同的张量格式和不同类型的数据处理。例如,简单的向量数据存储在形状为(samples,features)的2阶张量中,通常用密集连接层[denselyconnected layer,也叫全连接层(fully connected layer)或密集层(dense layer),对应于 Keras 的 Dense 类〕来处理。序列数据存储在形状为(samples,timesteps,features)的3阶张量中,通常用循环层(recurrentlayer)来处理,比如LSTM层或一维卷积层(Conv1D)。图像数据存储在4阶张量中,通常用二维卷积层(Conv2D)来处理。
可以把层看作深度学习的乐高积木。在 Keras 中构建深度学习模型,就是将相互兼容的层拼接在一起,建立有用的数据变换流程。
Keras 的 Layer 基类
简单的 API应该具有单一的核心抽象概念。在 Keras 中,这个核心概念就是 ayer 类。Keras 中的一切,要么是 Layer,要么与 Layer 密切交互。
Layer 是封装了状态(权重)和计算(一次前向传播)的对象。权重通常在build() 中定义(不过也可以在构造函数 init ()中创建),计算则在 call()方法中定义。前面,我们实现了一个NaiveDense类,它包含两个权重w和b,并进行如下计算:output =activation(dot(input, w)+ b)。Keras 的层与之非常相似。
代码清单:
from tensorflow import keras
import tensorflow as tf
class SimpleDense(keras.layers.Layer): #Keras 的所有层都继承自 Layer 基类
def __init__ (self,units,activation=None):
super().__init__()
self.units =units
self.activation =activation
#在 build()方法中创建权重
def build(self,input_shape):
input_dim = input_shape[-1]
#add weight()是创建权重的快捷方法。
self.w=self.add_weight(shape=(input_dim, self.units),
initializer="random_normal")
self.b=self.add_weight(shape=(self.units,),
initializer="zeros")
def call(self,inputs): #在 ca11()方法中定义前向传播计算
y = tf.matmul(inputs,self.w) + self.b
if self.activation is not None:
y= self.activation(y)
return y
将层实例化,它就可以像函数一样使用,接收一个TensorFlow张量作为输入。
my_dense = SimpleDense(units=32, activation=tf.nn.relu)
#创建一些测试输入
input_tensor =tf.ones(shape=(2, 784))
#对输入调用层,就像调用函数一样
output_tensor =my_dense(input_tensor)
print(output_tensor.shape)
既然最终对层的使用就是简单调用(通过层的__ca11__()方法),那为什么还要实现 ca11 ()和 build()呢?原因在于能够及时创建状态。
自动推断形状:动态构建层
就像玩乐高积木一样,只能将兼容的层“拼接”在一起。层兼容性(layer compatibility)的概念具体指的是,每一层只接收特定形状的输入张量,并返回特定形状的输出张量。
from tensorflow.keras import layers
#有32个输出单元的密集层
layer = layers.Dense(32,activation="relu")
该层将返回一个张量,其第一维的大小已被转换为 32。它后面只能连接一个接收32维向量作为输入的层。在使用 Keras 时,往往不必担心尺寸兼容性问题,因为添加到模型中的层是动态构建的,以匹配输入层的形状。
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential(「
layers.Dense(32,activation"relu")
layers.Dense(32)
这些层没有收到任何关于输入形状的信息;相反,它们可以自动推断,遇到第一个输入的形状就是其输入形状。我们实现的简单Dense层NaiveDense中,必须将该层的输入大小明确传递给构造函数,以便能够创建其权重。这种方法并不理想,因为它会导致模型的每个新层都需要知道前一层的形状。
model = NaiveSequential([
NaiveDense(input_size=784, output_size=32,activation="relu"),
NaiveDense(input_size=32, output_size=64, activation"relu"),
NaiveDense(input_size=64, output_size=32, activation="relu")
NaiveDense(input_size=32,output_size=10,activation="softmax")
])
如果某一层生成输出形状的规则很复杂,那就更糟糕了。如果某一层返回输出的形状是 (batch,input_size*2 if input_size % 2==0 else input_size * 3),那该怎么办?
如果我们把 NaiveDense 层重新实现为能够自动推断形状的 Keras 层,那么它看起来就像前面的
SimpleDense层,具有 build()方法和 cal1()方法。在simpleDense中,我们不再像NaiveDense 示例那样在构造函数中创建权重;相反,我们在一个专门的状态创建方法 build()中创建权重。这个方法接收该层遇到的第一个输入形状作为参数。第一次调用该层时(通过其__ca11__()方法),build()方法会自动调用。事实上,这就是为什么我们将计算定义在一个单独的 ca11()方法中,而不是直接定义在__ca11__()方法中。基类层__ca11__()方法的代码大致如下。
def __ca11__ (self,inputs):
if not self.built:
self.build(inputs.shape)
self.built = True
return self.call(inputs)
有了自动形状推断,前面的示例就变得简洁了,如下所示。
model= keras.Sequential([
SimpleDense(32,activation="relu")
SimpleDense(64,activation="relu")
SimpleDense(32,activation="relu")
SimpleDense(10,activation-"softmax")
])
自动形状推断并不是Layer类的__ca1l__()方法的唯一功能。它还要处理更多的事情,特别是急切执行和图执行之间的路由),以及输入掩码。
从层到模型
深度学习模型是由层构成的图,在 Keras 中就是Model类。sequential类是层的简单堆叠,将单一输入映射为单一输出。一些常见的网络拓扑结构包括:
双分支(two-branch)网络
多头(multihead)网络
残差连接
网络拓扑结构可能会非常复杂。例如,下图是Transformer 各层的图拓扑结构,这是一个用于处理文本数据的常见架构。
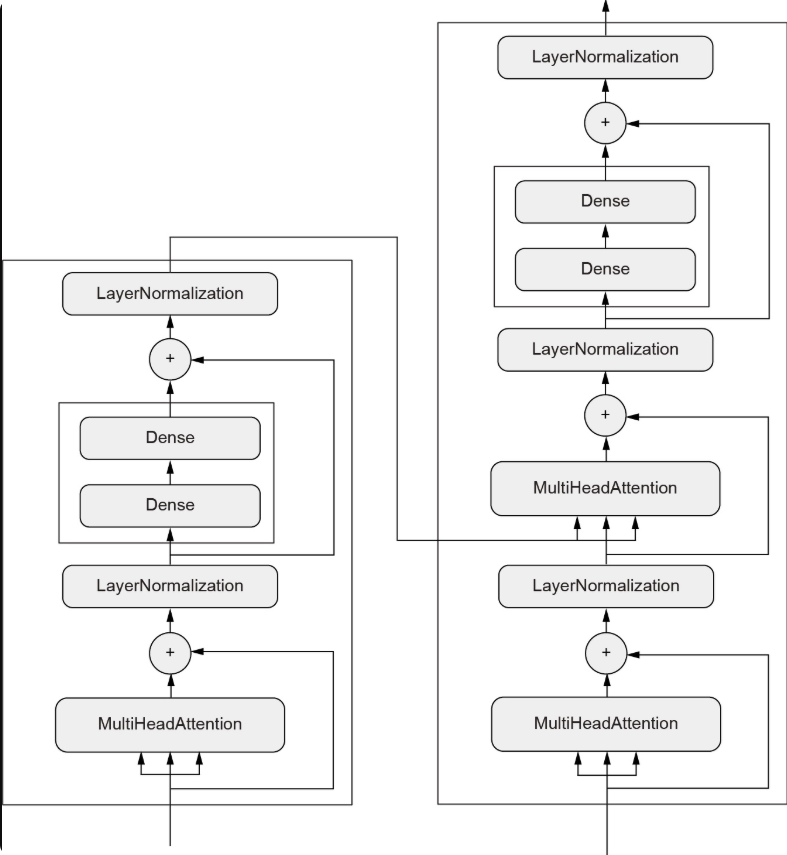
在 Keras 中构建模型通常有两种方法:直接作为 Model类的子类,或者使用函数式 API,后者可以用更少的代码做更多的事情。
模型的拓扑结构定义了一个假设空间。机器学习就是在预先定义的可能性空间内,利用反馈信号的指引,寻找特定输入数据的有用表示。通过选择网络拓扑结构,你可以将可能性空间(假设空间)限定为一系列特定的张量运算,将输入数据映射为输出数据。然后,你要为这些张量运算的权重张量寻找一组合适的值。
要从数据中学习,你必须对其进行假设。这些假设定义了可学习的内容。因此,假设空间的结构(模型架构)是非常重要的。它编码了你对问题所做的假设,即模型的先验知识。如果你正在处理一个二分类问题,使用的模型由一个没有激活的 Dense 层组成(纯仿射变换),那么你就是在假设这两个类别是线性可分的。
选择正确的网络架构,更像是一门艺术而不是科学。虽然有一些最佳实践和原则,但只有实践才能帮助成为合格的神经网络架构师。掌握构建神经网络的原则,并训练直觉,判断哪些架构对特定问题有效、哪些无效。深刻熟悉这些问题:每种类型的模型架构适合解决哪类问题?在实践中如何构建这些网络?如何选择正确的学习配置?如何调节模型,直到产生想要的结果。
编译步骤:配置学习过程
一旦确定了模型的网络架构,还需要选定以下3个参数。
损失函数(目标函数)————在训练过程中需要将其最小化。它衡量的是当前任务是否成功。
优化器————决定如何基于损失函数对神经网络进行更新。它执行的是随机梯度下降(SGD)的某个变体。
指标————衡量成功的标准,在训练和验证过程中需要对其进行监控,如分类精度。与损失不同,训练不会直接对这些指标进行优化。因此,指标不需要是可微的。
一旦选定了损失函数、优化器和指标,就可以使用内置方法 compile()和 fit()开始训练模型。此
外,也可以编写自定义的训练循环。下面我们来看一下 compile()和 fit()。
compile()方法的作用是配置训练过程。它接收的参数是optimizer、loss和metrics(一个列表)。
model = keras.Sequential([keras.layers.Dense(1)]) #定义一个线性分类器
model.compile(optimizer"rmsprop" #指定优化器的名称:RMSprop(不区分大小写)
1oss="mean squared error" #指定损失函数的名称:均方误差
metrics=["accuracy"]) #指定指标列表:本例中只有精度
在上面对 compile()的调用中,我们把优化器、损失函数和指标作为字符串(如"rmsprop")来传
递。这些字符串实际上是访问 Python 对象的快捷方式。例如,"rmsprop"会变成 keras.optimizers.RMSprop()。重要的是,也可以把这些参数指定为对象实例,如下所示。
model.compile(optimizer=keras.optimizers.RMsprop()
loss=keras.losses.MeanSquaredError()
metrics=keras.metrics.BinaryAccuracy()
如果你想传递自定义的损失函数或指标,或者想进一步配置正在使用的对象,比如向优化器传入参数
learning rate,那么这种方法很有用。
model,compile(optimizer=keras.optimizers.RMSprop(learning rate-le-4)
1oss=my custom oss
metrics=lmy custom metric 1my custom metric 2])
一般来说,无须从头开始创建自己的损失函数、指标或优化器,因为 Keras 提供了下列多种内置选项,很可能满足你的需求。
优化器:
SGD(带动量或不带动量)
RMSprop
Adam
Adagrad
等等
损失函数:
CategoricalCrossentropy
SparseCategoricalCrossentropy
BinaryCrossentropy
MeansquaredError
KLDivergence
Cosinesimilarity
等等
指标:
CateqoricalAccuracy
SparseCategoricalAccuracy
BinaryAccuracy
AUC
Precision
Recal1
等等