Differentiable Micro-Mesh Construction 论文阅读
信息
2024 CVPR
论文地址
摘要
本文提出了一个可微分框架,用于将标准网格转换为Micro-mesh( μ \mu μ-mesh)这种非常高效的格式,与以前基于阶段的方法相比,提供了一个整体方案。
本文的框架为高质量的 μ \mu μ 网格生产提供了许多优势:
- 端到端几何优化和位移烘焙;
- 使渲染结果相对于 μ \mu μ-mesh可微分,以忠于重投影;
- 具有高可扩展性。

微网格构建
该论文介绍了微网格构建的基本方法。
- 首先在高多边形输入网格上应用边缘塌陷抽取和重新网格划分获得一个各向同性简化,称为基础网格,其中基础三角形在渲染时被视为基本基元。
- 其次,以 1 到 4 的方式将基础三角形平稳地细分为 μ \mu μ面(论文这里是参考论文1中的方法对基网格进行细分的),并递归重复这个操作,直到达到最大水平或满足某些停止标准。
- 最后,通过沿法线方向在 μ \mu μ顶点( μ \mu μ顶点就是在细分基础三角形时产生的新的顶点)处进行光线投射,将几何表面细节烘焙到基础表面中,然后对生成的标量位移进行量化和打包。
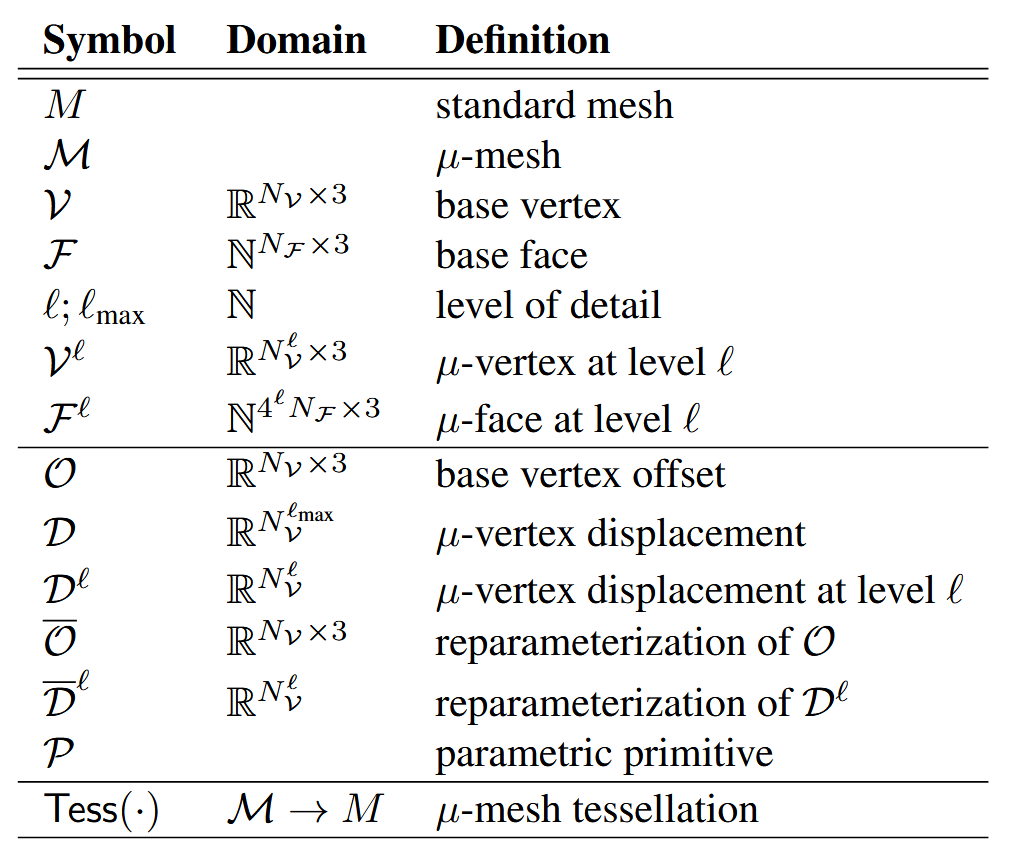
对于该论文中的变量的定义,文中有绘制一个表格做说明:
方法
微网格参数化
该论文将 μ \mu μ-mesh 定义成 M = ( V , F , O , D ) \mathcal{M}=(\mathcal{V},\mathcal{F},\mathcal{O},\mathcal{D}) M=(V,F,O,D)。
其中 V \mathcal{V} V是基顶点;
其中 F \mathcal{F} F是基三角面。
细分
论文这里参考论文1中的方法对基网格进行细分。
文章这里定义了一个细分等级" ℓ \ell ℓ",对于初始网格,细分等级定义为 ℓ \ell ℓ=0,随后每细分一次 ℓ \ell ℓ值加1。
可训练参数
- 基顶点的偏移向量
- 微顶点的标量位移(这里的位移是标量,因为每个微顶点的位移方向是对应的法向量,这里定义微顶点位移只需要一个标量就可以了)
参数基元
这里笔者认为参数基元就是上面定义的可训练参数的集合。
微网格上的拉普拉斯算子
这里提出直接在网格上进行变形和编辑,可能会导致 μ \mu μ-mesh的缠结,所以在参数优化过程需要附加一个拉普拉斯平滑正则器(论文2)。
那么两个可训练参数被参数化为
O ‾ = ( I + λ 1 L ) O , D ‾ ℓ = ( I + λ 2 L ℓ ) D ℓ \overline{\mathcal{O}}=(\mathbf{I}+\lambda_1\mathbf{L})\mathcal{O},\quad\overline{\mathcal{D}}^\ell=(\mathbf{I}+\lambda_2\mathbf{L}^\ell)\mathcal{D}^\ell O=(I+λ1L)O,Dℓ=(I+λ2Lℓ)Dℓ
优化
整体是用渲染一致性损失进行优化。

微网格的细分
这里提到了每次细分后微顶点的法线计算,每一次细分用上一次细分结果的重心插值计算新的微顶点的法线。
结合前面的拉普拉斯平滑结果,得到每次迭代的微顶点的位置坐标。
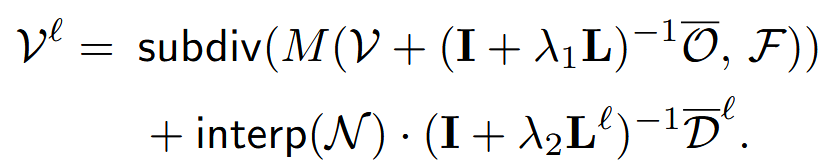
最终这个优化问题被建模为
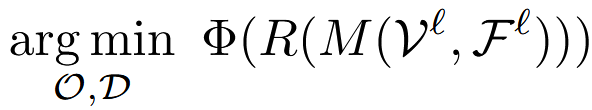
关于微网格的微分
这里是对于原始参数 O \mathcal{O} O的更新规则的推导,证明优化过程是可以稳定训练而且能够抗失真的。文章推导过程比较详细,不再赘述。
渐进式细分和优化
程序的运行流程如下:
- 预热阶段,基础网格优化与之类似,可以理解为初始化参数。
- 迭代细分和优化损失函数,在本文中就是优化渲染损失
- 最后一步冻结偏移量 O ‾ \overline{\mathcal{O}} O,然后调整所有级别的位移 D ‾ \overline{\mathcal{D}} D,理解为顶点位置不再优化,而是调整微顶点的位移。
重建之外的工作
本文提出的可微分系统除了可以重建之外,还能最大限度的减少壳体积,各向同性基础网格以及更好的自适应细节水平。
最小化壳体积
这里提到了一个BLAS(底层加速结构)的概念,说是新一代GPU 以更紧密、更高效的 BLAS(底层加速结构)对μ网格进行光线追踪,即每个基三角形的棱柱体。(关于BLAS的详细内容,笔者能力有限,没能深入理解这个内容,有兴趣可以自行查询)。
这一部分提出壳体积,也就是所有棱柱体积之和,是影响渲染时间成本的关键因素,
本节内容提出了一个损失用于优化壳体积。
各向同性
采用各向同性对网格进行划分,可以保证大致等边形状的基三角形,这样的基三角形允许有更高效的细分和烘焙[论文3]。
本节提出了一个尽可能等边的约束,可以保证在演化过程中保持基础网格的各向同性。
自适应细节级别
μ \mu μ-mesh支持每个基础三角形的细分级别,即自适应细节级别(LOD)。可以理解为为平面区域分配较低的细节级别,曲面区域分配较高的细节级别。
本文认为实现自适应LOD的两种途径如下:
- 在优化期间提前停止细分
- 均匀细分所有三角形,在后处理中修建过度细分的三角形。
本文提出了一个新的停止标准,一个视觉引导的停止标准,并采用方法1停止细分。
论文中给出了详细的视觉导向的细分指标计算过程以及伪代码。
参考文献
- Smooth subdivision surfaces based on triangles, master’s thesis.1987
- Laplacian mesh processing.
- Andrea Maggiordomo, Henry Moreton, and Marco Tarini. Micro-mesh construction.