linux0.11内核源码修仙传第十三章——进程调度之fork函数
🚀 前言
本文对应的章节是书中第25回。希望各位给个三连,拜托啦,这对我真的很重要!!!
目录
- 🚀 前言
- 🏆fork函数的作用
- 🏆fork函数的内容与简化
- 🏆 fork函数讲解
- 📃 系统中断
- 🏆进程基本信息的复制(sys_fork系统函数)
- 📃 存放进程信息(find_empty_process函数)
- 📃构建进程结构(copy_process函数)
- 🏆内存规划
- 📃 内存拷贝
- 📃 页表复制
- 📃写时复制
- 📃题外话,为什么要设置物理内存一致
- 🎯总结
- 📖参考资料
🏆fork函数的作用
为防止到这里有点乱,先来梳理一下目前进程调度的进度:
进程调度初始化:初始化了 TSS 与 LDT 并告知内存TSS0与LDT0的位置。之后设置时钟中断与系统调用,一个是确保计数器的中断能够传到CPU,另一个是为了用户态能够调用内核提供的方法。
内核态到用户态的切换:设置了特权级,保证了代码跳转只能是同级跳转,数据访问只能高特权级访问低特权级。通过中断返回进入用户态。
进程调度规则:保存上下文环境,即CPU的核心寄存器。设置不同进程的优先级,进程状态与调度时机。完善定时器中断函数,设置进程调度函数。
现在已经有了进程调度,剩下的工作就是创建进程,而本文的 fork 函数就是这个作用。
🏆fork函数的内容与简化
在linux内核中,fork函数的源码如下所示:
static inline _syscall0(int,fork)#define _syscall0(type,name) \
type name(void) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \: "=a" (__res) \: "0" (__NR_##name)); \
if (__res >= 0) \return (type) __res; \
errno = -__res; \
return -1; \
}
这是一个由宏定义产生的函数模板,只需要传入函数返回值类型,名字就可以生成一个函数,所以fork的返回类型是int型,于是可以将上面函数改写为如下形式:
#define __NR_fork 2int fork(void) {volatile long __res;_asm {_asm mov eax,__NR_fork_asm int 80h_asm mov __res,eax}if (__res >= 0)return (void) __res;errno = -__res;return -1;
}
🏆 fork函数讲解
📃 系统中断
这里面又是汇编,但是我们看到一个令人兴奋的东西:int 80h。聪明的你一定看出来这个是触发了0x80号软中断,还记得0x80号中断吗,可以查看这篇博客:linux0.11内核源码修仙传第十章——进程调度始化 📃 设置系统调用 章节,这是一个系统中断,于是去找系统中断:
_system_call:···call _sys_call_table(,%eax,4)···
这里是调用了sys_call_table里面下标为2的函数,为什么是下标为2呢?这是因为在fork函数第一行的汇编让eax寄存器的值为2。言归正传,看回这个sys_call_table:
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid };
这个sys_call_table就是一个系统调用函数表,里面全是可以供给用户态使用的系统调用函数。下标为2就是sys_fork函数。
btw,插句题外话,fork函数内调用了int 0x80这个中断并且给eax赋值,那么理论上可以直接调用这个中断。事实也是如此:
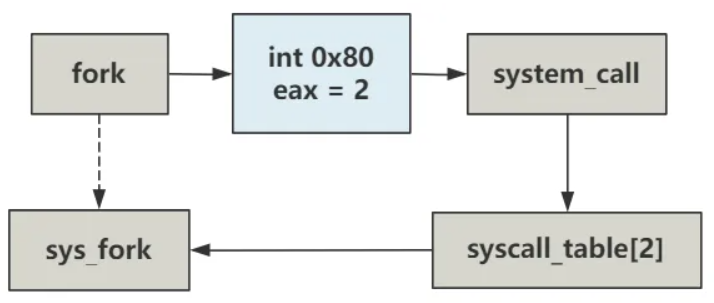
再扩展一下,所有的系统调用都可以调用int 0x80这个中断并且给eax赋值来实现。
🏆进程基本信息的复制(sys_fork系统函数)
📃 存放进程信息(find_empty_process函数)
上面已经追到了sys_fork函数,下面来看看这个函数具体的内容:
_sys_fork:call _find_empty_processtestl %eax,%eaxjs 1fpush %gspushl %esipushl %edipushl %ebppushl %eaxcall _copy_processaddl $20,%esp
梳理一下这个函数,首先调用了一个函数叫find_empty_process,然后压栈了一堆寄存器,最后再调用了copy_process 函数。中间的test和js两行是指检测到指令错误,就到错误处理标号1f处。这两个函数从字面意义上的含义如下:
find_empty_process:找到空闲的进程槽位
copy_proces:复制进程
我们一个一个来看,先来看find_empty_process 函数。找空闲的进程槽位说人话就是找个空白的位置放这个进程的一些信息,还记得进程怎么组织起来的吗?可以查看这篇博客:linux0.11内核源码修仙传第十章——进程调度始化 📃 初始化剩下的TSS与LDT。存储进程的数据结构是一个task[64]数组:

那 find_empty_process 函数的作用就是在上面这个task数组中找一个空闲的位置存一个新的进程结构task_struct,这个结构可以看这篇博客:linux0.11内核源码修仙传第十三章——进程调度大战前夕。这个结构体内容如下所示,注意里面有个pid,这个是进程的唯一id标识。
struct task_struct {long state;long counter;long priority;···long pid;···struct tss_struct tss;
};
该函数的内容如下:
int find_empty_process(void)
{int i;repeat:if ((++last_pid)<0) last_pid=1;for(i=0 ; i<64; i++)if (task[i] && task[i]->pid == last_pid) goto repeat;for(i=1 ; i<NR_TASKS ; i++)if (!task[i])return i;return -EAGAIN;
}
内容很简单,第一步:首先做了一个保护,保证last_pid不会超过long的范围。第二步,接一个for循环,查看所定的pid是不是已经有进程使用了,有的话就重新找一个pid,直到找到一个没有被用过的pid,保证进程id的唯一性。第三步,又是一个for循环,直到找到task中一个空闲的位置(task初始为null,所以只要不是null就是被占用了)。
由于我们现在只有 0 号进程,且 task[] 除了 0 号索引位置,其他地方都是空的,所以这个方法运行完,last_pid 就是 1,也就是新进程被分配的 pid 就是 1,然后即将要加入的 task[] 数组的索引位置,也是 1。
📃构建进程结构(copy_process函数)
整个copy_process函数内容较多,但其实绝大部分是设置 task_struct 对象的东西,也就是进程的一些属性,现在我们分批次来阅读这个难搞的东西!
首先是跟内存申请空间。进程总要在内存里面的吧,那肯定就需要和内存申请空间,内容如下:
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs,long es,long ds,long eip,long cs,long eflags,long esp,long ss)
{struct task_struct *p;int i;struct file *f;p = (struct task_struct *) get_free_page();if (!p)return -EAGAIN;*p = *current;···return last_pid;
}
还记得内存里面是如何管理的吗,可以看这篇博客:linux0.11内核源码修仙传第五章——内存初始化(主存与缓存)。这里贴出内存管理情况:

copy_process函数里面就是通过get_free_page函数来实现,做法就是:遍历 mem_map[] 这个数组,找出值为零的项,就表示找到了空闲的一页内存。然后把该项置为 1,表示该页已经被使用。最后,算出这个页的内存起始地址,返回。将拿到的内存起始地址给 task_struct 的对象 p。之后将这个p记录在进程管理结构task中。最后把当前进程,即 0 号进程的task_struct的全部值复制给即将创建的进程p,也就是说二者完全一样。现在内存的布局如下所示:

现在进程0和进程1是完全等价的。下一步就是设置进程1中不一样的值
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs,long es,long ds,long eip,long cs,long eflags,long esp,long ss)
{···p->state = TASK_UNINTERRUPTIBLE;p->pid = last_pid;p->father = current->pid;p->counter = p->priority;p->signal = 0;p->alarm = 0;p->leader = 0; /* process leadership doesn't inherit */p->utime = p->stime = 0;p->cutime = p->cstime = 0;p->start_time = jiffies;p->tss.back_link = 0;p->tss.esp0 = PAGE_SIZE + (long) p;p->tss.ss0 = 0x10;p->tss.eip = eip;p->tss.eflags = eflags;p->tss.eax = 0;p->tss.ecx = ecx;p->tss.edx = edx;p->tss.ebx = ebx;p->tss.esp = esp;p->tss.ebp = ebp;p->tss.esi = esi;p->tss.edi = edi;p->tss.es = es & 0xffff;p->tss.cs = cs & 0xffff;p->tss.ss = ss & 0xffff;p->tss.ds = ds & 0xffff;p->tss.fs = fs & 0xffff;p->tss.gs = gs & 0xffff;p->tss.ldt = _LDT(nr);p->tss.trace_bitmap = 0x80000000;···return last_pid;
}
别看这么多,其实就两个部分,第一个部分是 state,pid,counter 等这种进程的元信息,另一部分是 tss 里面保存的各种寄存器的信息,即上下文。
里面之前提到主要用到的都有了,优先级继承了父进程并据此更新了counter,pid是进程的唯一标号,state是进程状态。对应的tss里面就是各种寄存器,细看可以发现两个特殊的寄存器:ss0和esp0。为什么特殊呢,因为后面还有ss和esp。ss0和esp0表示0特权级,即内核态时的ss:esp的指向。ss0是0x10,对照段选择子可以查到是内核态的数据段,esp则是指向了对应被分配的页。简单点来讲就是将代码在内核态时使用的堆栈栈顶指针指向进程 task_struct 所在的 4K 内存页的最顶端,而且之后的每个进程都是这样被设置的。

至此这一节的长度也差不多了,这个函数先暂时告一段落,可以出去喝个水,吃个零食缓一缓。
🏆内存规划
emsp; 接着上一节的copy_process函数:
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs,long es,long ds,long eip,long cs,long eflags,long esp,long ss)
{···if (copy_mem(nr,p)) {task[nr] = NULL;free_page((long) p);return -EAGAIN;}for (i=0; i<NR_OPEN;i++)if (f=p->filp[i])f->f_count++;if (current->pwd)current->pwd->i_count++;if (current->root)current->root->i_count++;if (current->executable)current->executable->i_count++;set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));p->state = TASK_RUNNING; /* do this last, just in case */return last_pid;
}
emsp; 函数剩下的主要是两部分,第一部分是进行内存拷贝,如果失败就释放对应的页,接下来就是文件系统的一些设置,等到后面文件系统再回过头看。所以下一个目标是copy_mem函数,这个函数决定进程之间的内存规划。
📃 内存拷贝
下面就是copy_mem函数的内容:
int copy_mem(int nr,struct task_struct * p)
{unsigned long old_data_base,new_data_base,data_limit;unsigned long old_code_base,new_code_base,code_limit;code_limit=get_limit(0x0f);data_limit=get_limit(0x17);old_code_base = get_base(current->ldt[1]);old_data_base = get_base(current->ldt[2]);if (old_data_base != old_code_base)panic("We don't support separate I&D");if (data_limit < code_limit)panic("Bad data_limit");new_data_base = new_code_base = nr * 0x4000000;p->start_code = new_code_base;set_base(p->ldt[1],new_code_base);set_base(p->ldt[2],new_data_base);if (copy_page_tables(old_data_base,new_data_base,data_limit)) {free_page_tables(new_data_base,data_limit);return -ENOMEM;}return 0;
}
有点多,但是不慌,这个函数其实就是赋值了LDT表项并进行了页表的拷贝。下面一点一点来看。在此之前,先来回顾一下已有的段页管理,可以查看博客:linux0.11内核源码修仙传第三章——head.s。不考虑段限长的话,32位CPU线性地址空间为4G。现在只有4个页目录表,将前16M的线性地址空间与16M的物理地址空间一一对应起来:

为啥是16M呢,这里前面的博客没有解释,这里可以算一下,下图是经过段页管理后线性地址与物理地址的换算关系:

每个页表共有1024项,对应着4K的空间,那么一个页表就有4M的空间,4个页表就是16M。很简单对不对。
我们给进程0准备的LDT的代码段和数据段,段基地址是0,段限长是640K。如下所示:

好了,又有新问题了对不对,为啥是640K呢,这是因为在初始化时规定的,看如下代码(看注释部分):
static union task_union init_task = {INIT_TASK,};/** INIT_TASK is used to set up the first task table, touch at* your own risk!. Base=0, limit=0x9ffff (=640kB)*/
#define INIT_TASK \
/* state etc */ { 0,15,15, \
/* signals */ 0,{{},},0, \
/* ec,brk... */ 0,0,0,0,0,0, \
/* pid etc.. */ 0,-1,0,0,0, \
/* uid etc */ 0,0,0,0,0,0, \
/* alarm */ 0,0,0,0,0,0, \
/* math */ 0, \
/* fs info */ -1,0022,NULL,NULL,NULL,0, \
/* filp */ {NULL,}, \{ \{0,0}, \
/* ldt */ {0x9f,0xc0fa00}, \{0x9f,0xc0f200}, \}, \
/*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\0,0,0,0,0,0,0,0, \0,0,0x17,0x17,0x17,0x17,0x17,0x17, \_LDT(0),0x80000000, \{} \}, \
}
扯远了,现在的进程1是复制的进程0,代码段和数据段还没有设置,所以第一步就是给LDT赋值,就是上面那一张图还未设置的代码段和数据段,段限长取自设置好的段限长,即640K:
int copy_mem(int nr,struct task_struct * p)
{···code_limit=get_limit(0x0f);data_limit=get_limit(0x17);···
}
而段基址有点意思,是取决于当前是几号进程,也就是 nr 的值:
int copy_mem(int nr,struct task_struct * p)
{···new_data_base = new_code_base = nr * 0x4000000;set_base(p->ldt[1],new_code_base);set_base(p->ldt[2],new_data_base);···
}
这里的0x4000000等于64M,也就是说,今后每个进程通过段基地址,在线性地址空间中占用64M的空间,最后设置LDT里面的代码段与数据段(不考虑段限长的情况)并且紧挨着,如下图所示:

至此为止,完成了段式管理,将进程映射到了相互隔离的线性空间内,接下来还需要开启分页管理,最终形成段页式的管理方式,这就是下一个页表的复制。
📃 页表复制
页表复制代码如下:
int copy_mem(int nr,struct task_struct * p)
{···if (copy_page_tables(old_data_base,new_data_base,data_limit)) {free_page_tables(new_data_base,data_limit);return -ENOMEM;}···
}
复制页表采用的函数是copy_page_tables,这是一段linus本人都在注释吐槽说不想再debug的代码,但是不要慌,一点点来看:
int copy_page_tables(unsigned long from,unsigned long to,long size)
{unsigned long * from_page_table;unsigned long * to_page_table;unsigned long this_page;unsigned long * from_dir, * to_dir;unsigned long nr;if ((from&0x3fffff) || (to&0x3fffff))panic("copy_page_tables called with wrong alignment");from_dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */to_dir = (unsigned long *) ((to>>20) & 0xffc);size = ((unsigned) (size+0x3fffff)) >> 22;for( ; size-->0 ; from_dir++,to_dir++) {if (1 & *to_dir)panic("copy_page_tables: already exist");if (!(1 & *from_dir))continue;from_page_table = (unsigned long *) (0xfffff000 & *from_dir);if (!(to_page_table = (unsigned long *) get_free_page()))return -1; /* Out of memory, see freeing */*to_dir = ((unsigned long) to_page_table) | 7;nr = (from==0)?0xA0:1024;for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {this_page = *from_page_table;if (!(1 & this_page))continue;this_page &= ~2;*to_page_table = this_page;if (this_page > LOW_MEM) {*from_page_table = this_page;this_page -= LOW_MEM;this_page >>= 12;mem_map[this_page]++;}}}invalidate();return 0;
}
好了,忽略代码问题,我们来直接思考需求。现在进程 0 的线性地址空间是 0 - 64M,进程 1 的线性地址空间是 64M - 128M。我们现在要造一个进程 1 的页表,使得进程 1 和进程 0 最终被映射到的物理空间都是 0 - 64M,这样进程 1 才能顺利运行起来,不然就乱套了。这个逻辑对应关系如下:

总之最终的效果就是进程 0 和进程 1 目前共同映射物理内存的前 640K 的空间:
假设现在正在运行进程 0,代码中给出一个虚拟地址 0x03,由于进程 0 的 LDT 中代码段基址是 0,所以线性地址也是 0x03,最终由进程 0 页表映射到物理地址 0x03 处。
假设现在正在运行进程 1,代码中给出一个虚拟地址 0x03,由于进程 1 的 LDT 中代码段基址是 64M,所以线性地址是 64M + 3,最终由进程 1 页表映射到物理地址也同样是 0x03 处。
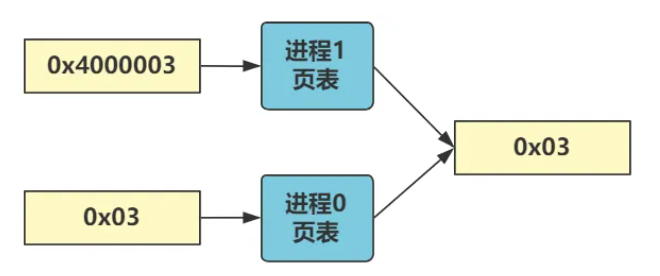
那么如何实现呢,举个例子:
进程 1 的线性地址 64M + 0x03 用二进制表示是:
0000010000_0000000000_000000000011
进程 0 的线性地址 0x03 用二进制表示是:0000000000_0000000000_000000000011
还记得分页转化规则吗,可以看这篇博客:linux0.11内核源码修仙传第三章——head.s。上面用_分好了,前10位代表页目录项,中间10位代表页表项,后12位表示页内偏移。对照这个查看上面的二进制结果:
进程 1 要找的是页目录项 16 中的第 0 号页表
进程 0 要找的是页目录项 0 中的第 0 号页表
那只要让这俩最终找到的两个页表里的数据一模一样即可。
📃写时复制
现在新老进程一开始共享一个物理内存空间,那么用户肯定不能随便进行修改,不然就乱套了,但是一点都不修改也是不可能的,那怎么办的呢?还记得页表结构吧,查看这篇博客:linux0.11内核源码修仙传第三章——head.s:

其中 RW 位表示读写状态,0 表示只读(或可执行),1表示可读写(或可执行)。当然,在内核态也就是 0 特权级时,这个标志位是没用的。
那我们看下面的代码:
int copy_page_tables(unsigned long from,unsigned long to,long size) {...for( ; size-->0 ; from_dir++,to_dir++) {...for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {...this_page &= ~2;...if (this_page > LOW_MEM) {*from_page_table = this_page;...}}}...
}
~2 表示取反,2 用二进制表示是 10,取反就是 01,其目的是把 this_page 也就是当前的页表的 RW 位置零,也就是是把该页变成只读。而 *from_page_table = this_page 表示又把源页表也变成只读。
也就是说,经过 fork 创建出的新进程,其页表项都是只读的,而且导致源进程的页表项也变成了只读。
如果只是读,那相安无事,如果进程要写怎么办?那么由于页面是只读的,将触发缺页中断,然后就会分配一块新的物理内存给产生写操作的那个进程,此时这一块内存就不再共享了。
这些是后话了。
📃题外话,为什么要设置物理内存一致
Linux 中进程1的页表映射与进程0的物理空间相同,是内存共享和进程高效创建的必然设计。通过分页机制的灵活控制,既保证了进程的独立性(如数据段隔离),又实现了资源的共享(如代码段),这是早期 Linux 内存管理的核心优化之一。

🎯总结
本文有点长,主要是创建进程时的一些动作,即fork函数,通过系统中断,调用系统函数sys_fork创建进程,在这个过程中复制了父进程,即进程0,之后在task数组中找到一个空的位置,并向内存申请空间,设置自己的独特属性和上下文,最后就是内存规划,包括内存拷贝,页表拷贝等等。
📖参考资料
[1] linux源码趣读
[2] 一个64位操作系统的设计与实现