多种方案对比实现 Kaggle 比赛介绍进行行业分类
Kaggle 平台汇集了大量来自不同行业的数据科学竞赛,但这些比赛的标题或简介往往表述多样、不易直接归类。无论是做项目归档、行业研究,还是搭建竞赛推荐系统,都需要一个可靠的方法来将比赛自动归入对应行业标签。
本教程提供使用 HuggingFace 的 zero-shot pipeline 和 Sentence Transformers 实现结果并进行对比。包含实现代码、适用条件、优缺点对比,并提供可直接应用的分类模型和标签建议。无论你是做数据分析、行业报告,还是搭建平台自动分类系统,这篇文章都能帮你快速落地一个实用方案。
文章目录
- 数据获取
- HuggingFace Zero-shot
- Sentence Transformers
- 方案对比
- 总结
数据获取
进入 Meta Kaggle 自行下载 Kaggle 元数据,本地应用的分类数据是 Competitions.csv 。
编写一个脚本将英文列名转换成中文并保存成excel,这里要对csv的字符进行处理否则无法保存。
import pandas as pddf=pd.read_csv("Competitions.csv",encoding="utf8")df = df.rename(columns={'Id': '比赛ID','Slug': '比赛别名','Title': '比赛标题','Subtitle': '副标题','HostSegmentTitle': '主办方分类','ForumId': '论坛ID','OrganizationId': '主办机构ID','EnabledDate': '比赛开放时间','DeadlineDate': '报名截止时间','ProhibitNewEntrantsDeadlineDate': '禁止新参赛者时间','TeamMergerDeadlineDate': '组队合并截止时间','TeamModelDeadlineDate': '组队模型提交截止','ModelSubmissionDeadlineDate': '最终模型提交截止','FinalLeaderboardHasBeenVerified': '最终排行榜已验证','HasKernels': '是否支持Notebook','OnlyAllowKernelSubmissions': '仅允许Notebook提交','HasLeaderboard': '是否有排行榜','LeaderboardPercentage': '排行榜开放比例','ScoreTruncationNumDecimals': '分数保留小数位数','EvaluationAlgorithmAbbreviation': '评估算法缩写','EvaluationAlgorithmName': '评估算法名称','EvaluationAlgorithmDescription': '评估算法描述','EvaluationAlgorithmIsMax': '是否最大化指标','MaxDailySubmissions': '每日最多提交次数','NumScoredSubmissions': '计分提交次数','MaxTeamSize': '最大组队人数','BanTeamMergers': '是否禁止队伍合并','EnableTeamModels': '是否支持团队模型','RewardType': '奖励类型','RewardQuantity': '奖金数额','NumPrizes': '奖项数量','UserRankMultiplier': '用户积分倍率','CanQualifyTiers': '是否有等级资格','TotalTeams': '参赛队伍总数','TotalCompetitors': '参赛者总数','TotalSubmissions': '提交总数','LicenseName': '使用许可类型','Overview': '比赛简介','Rules': '比赛规则','DatasetDescription': '数据集描述','TotalCompressedBytes': '压缩数据总大小','TotalUncompressedBytes': '解压后数据总大小','ValidationSetName': '验证集名称','ValidationSetValue': '验证集数值','EnableSubmissionModelHashes': '提交模型是否哈希校验','EnableSubmissionModelAttachments': '提交模型是否附带附件','HostName': '主办方名称','CompetitionTypeId': '比赛类型ID'
})import re# 定义非法字符正则表达式(Excel 不允许的 ASCII 控制字符)
illegal_char_pattern = re.compile(r'[\x00-\x1F]+')# 针对所有 object 类型的列进行清洗
for col in df.select_dtypes(include=['object']):df[col] = df[col].astype(str).apply(lambda x: illegal_char_pattern.sub('', x))df.to_excel("data.xlsx",index=False)
HuggingFace Zero-shot
该方案采用 HuggingFace 提供的 Zero-Shot Classification 推理接口,能够在无需重新训练的前提下直接将文本映射到语义明确的标签类别,适合在样本量有限但对语义理解要求较高的分类任务中使用。通过基于自然语言推理(NLI)的预训练模型,如 xlm-roberta-large-xnli,该方法可在每条文本与全部候选标签之间进行比对,从而精准判断其所属类别。尤其在行业标签为自然语言短语的场景下,能有效提升分类的准确性与解释力,兼顾灵活性与实用性。
| 方案名称 | 使用模型 | 技术路径 | 最佳适配场景 | 分类能力 | 推荐文本数量 |
|---|---|---|---|---|---|
| HuggingFace Zero-Shot | xlm-roberta-large-xnli | pipeline(“zero-shot-classification”) | 行业标签为自然语言短语、小样本分类需求 | 精准高语义匹配 | 少于500条 |
import os
import pandas as pd
from transformers import pipeline# 使用国内镜像 + 禁用 TensorFlow(可选)
os.environ["TRANSFORMERS_NO_TF"] = "1"
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"# 加载比赛数据
df = pd.read_excel("data_orgin.xlsx")
text_column = "比赛简介" # 可换成副标题或数据集描述# 定义行业标签
candidate_labels = ["医疗健康", "金融科技", "教育科研", "交通物流", "人工智能"]# 初始化分类器
classifier = pipeline("zero-shot-classification", model="joeddav/xlm-roberta-large-xnli")# 分类函数
def classify_industry(text):if not isinstance(text, str) or not text.strip():return "未知"result = classifier(text, candidate_labels, multi_label=False)return result["labels"][0]# 应用分类
df["预测行业"] = df[text_column].apply(classify_industry)
df.to_excel("结果_zero_shot.xlsx", index=False)
该方法最大的优势在于其对复杂文本的语义理解能力,适配多语言、多任务的场景,无需训练即可上手,极大地降低了模型使用门槛。在小样本语义分类任务中,它能够有效保持标签语义与文本的高匹配度。然而,由于其基于逐条推理机制,当标签数量较多或样本量增加时,推理效率成为瓶颈,不支持高效的批量处理也限制了其在大规模文本处理中的应用。
| 优点 | 缺点 |
|---|---|
| 语义理解强,适合复杂文本 | 推理慢,标签越多耗时越久 |
| 不需要训练或向量预处理 | 逐条处理,无法批量加速 |
| 支持多语言和多任务 | 不适合大数据量场景 |
Sentence Transformers
通过将文本与候选标签共同嵌入语义空间,该方案利用 sentence-transformers 提供的向量表示能力,实现高效的余弦相似度匹配,从而对大规模文本数据进行快速归类。相比逐条推理的方式,这种方法更加高效,适合在不牺牲整体准确性的前提下处理数千条短文本。尤其在标签短小明确、语义指向清晰的应用场景中,该方法能够提供稳定且可控的分类效果,兼顾处理速度与分类质量,适用于批量行业归类、舆情聚类等自动化任务。
| 分类方案名称 | 技术核心 | 模型推荐 | 优势概述 | 适用数据规模 | 典型应用场景 |
|---|---|---|---|---|---|
| SentenceTransformer语义向量分类 | 嵌入向量 + 余弦相似度匹配 | paraphrase-multilingual-MiniLM-L12-v2 | 支持中英文,批量处理快,整体精度较高 | 1000条及以上 | Kaggle简介批量归类、行业聚合任务 |
import os
import pandas as pd
from sentence_transformers import SentenceTransformer, util
import torchdevice = "cuda" if torch.cuda.is_available() else "cpu"# 加载数据
df = pd.read_excel("data_orgin.xlsx")
text_column = "比赛简介" # 可调整为副标题等字段# 定义标签
candidate_labels = ["医学影像识别", "股票价格预测", "电网负荷预测", "用户转化分析", "赛事预测"]# 加载模型 + 向量编码
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2", device=device)
label_embeddings = model.encode(candidate_labels, convert_to_tensor=True)# 分类函数
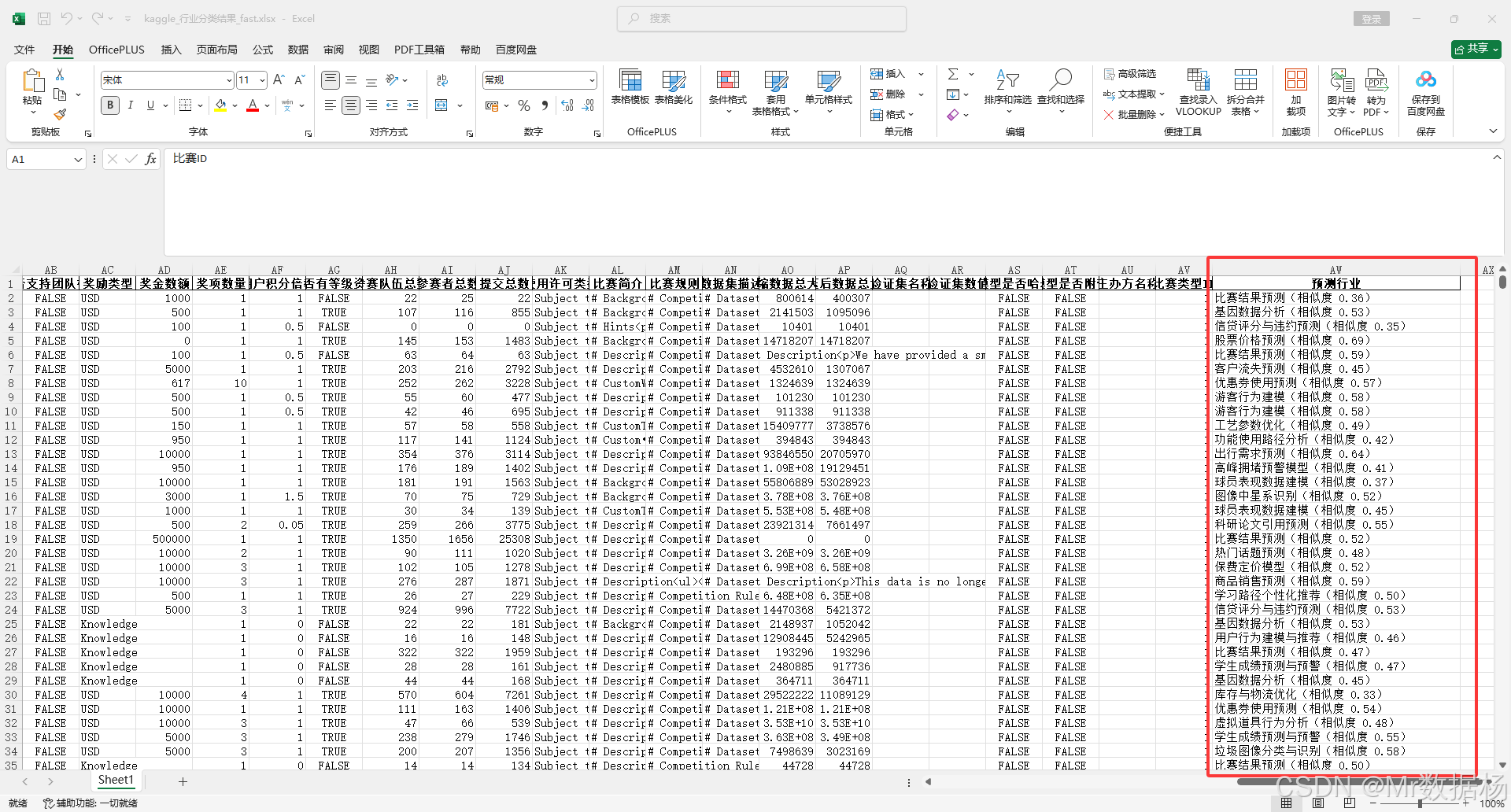
def classify(text):if not isinstance(text, str) or not text.strip():return "未知"text_emb = model.encode(text, convert_to_tensor=True)cosine_scores = util.cos_sim(text_emb, label_embeddings)[0]best_idx = int(torch.argmax(cosine_scores))score = float(cosine_scores[best_idx])return f"{candidate_labels[best_idx]}(相似度 {score:.2f})"# 应用分类(可加入 tqdm)
for i, row in df.iterrows():if i % 100 == 0:print(f"处理到第 {i + 1} 行...")df.at[i, "预测行业"] = classify(row[text_column])df.to_excel("结果_sentence_transformer.xlsx", index=False)
该方法在大规模文本分类场景中具备明显的效率优势,能够通过一次性嵌入与向量化操作完成成千上万条数据的标签分配,适合需要快速响应与自动化的实际需求。同时,其支持中英文混合语料和多标签任务,具有较好的通用性与灵活性。模型结构轻量,使其在普通计算资源(如本地 CPU 或 GPU)下也能稳定运行。但由于分类过程基于语义相似度计算,对于标签表达的明确性与紧凑性要求较高,过于抽象或不一致的标签可能导致匹配失误。此外,该方案仅返回相似度得分,无法像基于推理的模型那样提供具体的判断逻辑解释,需结合阈值或评分机制辅助决策。
| 优点 | 缺点 |
|---|---|
| 处理速度快,支持批量向量计算 | 对标签语义依赖较强 |
| 支持中英文、多任务分类 | 标签需短小精炼,不宜太抽象 |
| 可在本地 CPU/GPU 上快速运行 | 无法直接给出解释理由,需配合相似度阈值辅助判断 |
方案对比
两种分类方案在适用范围和技术特性上呈现出显著差异。Zero-shot Pipeline 更强调逐条语义推理判断,适合精度导向型任务,尤其在标签语义复杂或需详细逻辑解释时具有优势,但在大规模任务中推理速度较慢。而基于 Sentence Transformers 的方案则更侧重效率与整体精度,通过向量匹配快速完成大批量数据的归类,适合标签短小明确的场景。两者均具备多语言支持能力,但在使用门槛与可解释性上有所不同,前者更易于直接部署,而后者则需要开发者具备一定的向量表示理解能力,适合对性能与处理量有较高要求的工程化场景。
| 对比维度 | Zero-shot Pipeline | Sentence Transformers |
|---|---|---|
| 推理速度 | 慢(每条与每个标签比) | 快(向量一次性匹配) |
| 精度表现 | 适合小样本+语义复杂 | 标签清晰时效果好 |
| 多语言支持 | ✅ | ✅(选对模型) |
| 适合任务量 | 小规模(< 500 条文本) | 大规模(上千甚至上万条) |
| 可解释性 | 强,输出逻辑清晰 | 中等,可输出相似度 |
| 使用门槛 | 较低 | 略高,需要理解向量匹配 |
总结
在面对上百或上千条 Kaggle 比赛文本时,选对分类方案比微调模型更重要。可以根据实际需求、资源条件选择方案。如果希望前期快速验证效果,后期高效扩展规模,不妨两个方案结合使用。