HDFS Full Block Report超限导致性能下降的原因分析
文章目录
- 前言
- 发现问题
- 失败的为什么是FBR
- 块汇报频率的变化
- 为什么FBR会反复失败
- HDFS性能下降导致Yarn负载变高的形式化分析
- 理解线程
- 理解IO Wait
- 理解HDFS性能下降导致Yarn负载和使用率增高
- 引用
前言
我们的Yarn Cluster主要用来运行一批由Airflow定时调度的Spark Job,这些Spark Job。。这些Job根据其处理的时间粒度的不同(Batch Duration)和业务逻辑(Business Type)的不同而被打上不同的Prometheus标签,然后我们构建了对应的Grafana Dashboard来监控各个Job处理的数据量以及运行时间的变化。
从某个时刻开始,我们的Yarn集群开始出现拥塞,但是业务层面其实没有发生太大变化。在troubleshooting的过程中,我们逐渐找到了问题的元凶HDFS, 并在root cause层面讲问题解决。
本文详细介绍了我们从发现问题、找到怀疑对象、并最终解决问题以及事后对问题进行分析的全过程。
发现问题
大概从28/Apr下午开始,我们发现所有的批处理任务的运行时间逐渐变长,有些批处理任务的运行时间变成了之前的5到10倍,因此,我们开始分析原因。由于与此同时,我们观察到对应的批处理任务的数据输入量整体也有所增加(这是业务变化引起的,因此是预期之内的),如下图所示,大概增加了50%左右:

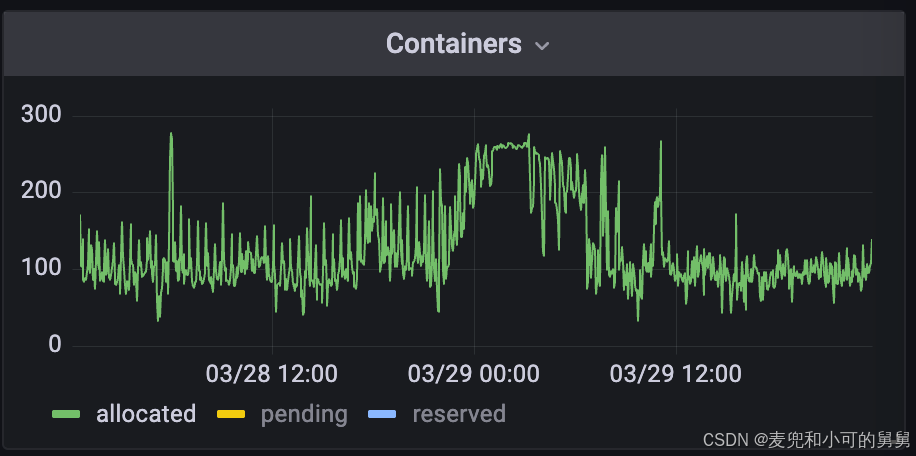
我们查看整个Yarn集群的状态,我们发现集群的负载在对应的时间范围内也逐渐升高,正在运行的Container数量逐渐增加直到Yarn集群持续满负荷运行:
同时,整个集群的可用Memory和CPU的可用资源和Pending Container如下所示:


从上图可以看到,在数据量增加以前,我们Yarn集群的内存和CPU资源使用率以CPU为主,平均使用率也是35%左右,所以,如果系统运行正常,即使所有Spark Job的输入数据量增加50%,Yarn集群的内存和CPU资源也是完全够用的。
由于找不到特别明显的原因,我们一度怀疑是由于Yarn集群的不合理设置导致在集群的资源没有用完的情况下Yarn的资源分配已经出现了瓶颈。
但是,两个现象让我们的这种怀疑变得不特别Solid:
- 数据量增加的比例和我们的Spark Job运行时间的比例不成正比
- Spark Job运行时间的Peak时间点和输入数据量的Peak时间点不吻合,即,当数据量开始逐渐下降的时候,Spark Job的运行时间依然在接下来的1个小时逐渐攀升。
- 当我们最初认为真的只是Yarn的资源不足的时候,作为一种让线上系统快速恢复的手段,我们首先尝试停止提交一些优先级和重要性不高的Job。但是,我们发现,问题完全无法解决。
经过更加深入的问题分析,我们最后发现,整个Yarn的资源使用率的降低是由于HDFS的性能降低引起的,因为无论是Yarn本身,还是Yarn上运行的Spark Job(从HDFS上读取数据然后写入到ClickHouse)都需要依赖HDFS,并且随后发现,HDFS的性能急剧下降是由于DataNode的块汇报失败造成的锁争用。最终,我们在root cause层面解决问题。
在DataNode端,我们打印了对应堆栈,发现堆栈信息如下所示。
首先,我们看到有很多线程如下所示:
"DataXceiver for client DFSClient_NONMAPREDUCE_-1403695307_28 at /0.21.1.113:36094 [Receiving block BP-862625392-0.21.7.109-1687238140050:blk_3132608831_2058910583]" #460048
344 daemon prio=5 os_prio=0 tid=0x00007fbe86b2a800 nid=0x569 waiting for monitor entry [0x00007fbeddba6000]java.lang.Thread.State: BLOCKED (on object monitor)at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.createRbw(FsDatasetImpl.java:1377)- waiting to lock <0x0000000438637dd0> (a org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl)at org.apache.hadoop.hdfs.server.datanode.BlockReceiver.<init>(BlockReceiver.java:199)at org.apache.hadoop.hdfs.server.datanode.DataXceiver.writeBlock(DataXceiver.java:675)at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opWriteBlock(Receiver.java:169)at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:106)at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:246)at java.lang.Thread.run(Thread.java:748)
可以看到,这是多个DataXceiver的writeBlock()方法尝试写一个块的时候,需要构造一个BlockReceiver对象,但是构造BlockReceiver对象的时候,需要调用一个Synchronized 的 实例方法FsDatasetImpl.createRbw(), 该方法需要获取FsDatasetImpl对象的监视器锁,因此持续在一个FsDatasetImpl对象对应的监视器锁0x0000000438637dd0上等待:
BlockReceiver(final ExtendedBlock block, final StorageType storageType,final boolean pinning) throws IOException {try{this.block = block;.....// Open local disk out//if (isDatanode) { //replication or movereplicaHandler = datanode.data.createTemporary(storageType, block);} else {switch (stage) {case PIPELINE_SETUP_CREATE:replicaHandler = datanode.data.createRbw(storageType, block, allowLazyPersist); // 这是一个Synchronized方法
@Override // FsDatasetSpipublic synchronized ReplicaHandler createRbw( // 这是一个实例的同步方法StorageType storageType, ExtendedBlock b, boolean allowLazyPersist)throws IOException {ReplicaInfo replicaInfo = volumeMap.get(b.getBlockPoolId(),b.getBlockId());if (replicaInfo != null) {
同时,我们也看到有很多线程如下所示:
"DataXceiver for client DFSClient_NONMAPREDUCE_-940941604_93 at /1.12.1.240:40478 [Sending block BP-862625392-0.21.7.109-1687238140050:blk_3132534170_2058835614]" #460048343daemon prio=5 os_prio=0 tid=0x00007fbda42c1800 nid=0x567 waiting for monitor entry [0x00007fbeddca7000]java.lang.Thread.State: BLOCKED (on object monitor)at org.apache.hadoop.hdfs.server.datanode.BlockSender.<init>(BlockSender.java:240)- waiting to lock <0x0000000438637dd0> (a org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl)at org.apache.hadoop.hdfs.server.datanode.DataXceiver.readBlock(DataXceiver.java:537)at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opReadBlock(Receiver.java:148)at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:103)at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:246)at java.lang.Thread.run(Thread.java:748)BlockSender(ExtendedBlock block, long startOffset, long length,boolean corruptChecksumOk, boolean verifyChecksum,boolean sendChecksum, DataNode datanode, String clientTraceFmt,CachingStrategy cachingStrategy)throws IOException {try {this.block = block;....synchronized(datanode.data) { // 尝试获取FsDatasetImpl的对象监视器锁replica = getReplica(block, datanode);replicaVisibleLength = replica.getVisibleLength();if (replica instanceof FinalizedReplica) {// Load last checksum in case the replica is being written// concurrentlyfinal FinalizedReplica frep = (FinalizedReplica) replica;chunkChecksum = frep.getLastChecksumAndDataLen();}}
可以看到,读请求也在同一把锁上Block住了:DataXceiver在处理对一个Block的读取请求的时候,需要构造一个BlockSender对象,但是构造BlockSender对象的时候,有一段synchronized代码块,该同步代码块需要的锁也是DatasetImpl对象的监视器锁,因此持续在一个FsDatasetImpl对象对应的监视器锁0x0000000438637dd0上等待,如上述堆栈所示。
因此,我们需要看一下哪个线程已经获取了FSDatasetImpl对象的监视器锁呢?我们搜索 0x0000000438637dd0这个锁id,看到以下线程已经获取了对应的监视器锁:
"DataNode: [[[DISK]file:/corp/data/nvme1/dfs/dn/, [DISK]file:/corp/data/nvme2/dfs/dn/, [DISK]file:/corp/data/nvme3/dfs/dn/, [DISK]file:/corp/data/nvme4/dfs/dn/]]
heartbeating to rccp407-24a.iad6.prod.corp.com/0.21.7.109:8022" #176 daemon prio=5 os_prio=0 tid=0x00007fbf262eb000 nid=0x1ffa runnable [0x00007fbeee5a2000]java.lang.Thread.State: RUNNABLEat com.google.protobuf.CodedOutputStream.writeRawVarint64(CodedOutputStream.java:1039)at org.apache.hadoop.hdfs.protocol.BlockListAsLongs$Builder.add(BlockListAsLongs.java:242)at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.getBlockReports(FsDatasetImpl.java:1768)- locked <0x0000000438637dd0> (a org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.blockReport(BPServiceActor.java:287)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:561)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:695)at java.lang.Thread.run(Thread.java:748)很明显,是方法BPServiceActor.blockReport()进行块汇报,已经获得了FsDatasetImpl对象对应的监视器锁0x0000000438637dd0。后来自己看代码才知道,blockReport()是用来完成Full Block Report的方法。
但是,全量块汇报每6个小时执行一次,并且应该在很短的时间内完成才对,那么是不是有可能我们打印堆栈的时机比对,即,我们打印堆栈的时候刚好就遇到了这个全量块汇报呢?于是,过了15分钟我们再次打印堆栈,发现堆栈状态依然如上所示。这说明:全量块汇报状态不正常。
随后,我们开始查看HDFS的相关日志。
DataNode端BlockReport失败的有关日志如下所示:
2025-03-28 22:38:09,622 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Unsuccessfully sent block report 0x4bc7fea3d6c94cf6, containing 4 storage report(s), of which we sent 0. The reports had 20093201 total blocks and used 0 RPC(s). This took 1212 msec to generate and 43 msecs for RPC and NN processing. Got back no commands.
2025-03-28 22:38:09,622 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: IOException in offerService
java.io.EOFException: End of File Exception between local host is: "rccp401-25a.iad6.prod.corp.com/0.21.1.113"; destination host is: "rccp408-24a.iad6.prod.corp.com":8022; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFExceptionat sun.reflect.GeneratedConstructorAccessor35.newInstance(Unknown Source)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764)at org.apache.hadoop.ipc.Client.call(Client.java:1508)at org.apache.hadoop.ipc.Client.call(Client.java:1441)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230)at com.sun.proxy.$Proxy20.blockReport(Unknown Source)at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.blockReport(DatanodeProtocolClientSideTranslatorPB.java:204)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.blockReport(BPServiceActor.java:323)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:561)at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:695)at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.EOFExceptionat java.io.DataInputStream.readInt(DataInputStream.java:392)at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1113)at org.apache.hadoop.ipc.Client$Connection.run(Client.java:1006)
从上面的堆栈可以看到,DataNode发送了FBR的RPC请求给NameNode,但是在试图获取响应的时候发现连接断开了。
然后,我们开始检查NameNode的异常日志,并找出了如下对应异常:
2025-03-28 21:36:31,432 WARN org.apache.hadoop.ipc.Server: Requested data length 71428864 is longer than maximum configured RPC length 67108864. RPC came from 0.21.3.113
2025-03-28 21:36:31,432 INFO org.apache.hadoop.ipc.Server: Socket Reader #1 for port 8022: readAndProcess from client 0.21.3.113 threw exception [java.io.IOException: Requested data length 71428864 is longer than maximum configured RPC length 67108864. RPC came from 0.21.3.113]
java.io.IOException: Requested data length 71428864 is longer than maximum configured RPC length 67108864. RPC came from 0.21.3.113at org.apache.hadoop.ipc.Server$Connection.checkDataLength(Server.java:1601)at org.apache.hadoop.ipc.Server$Connection.readAndProcess(Server.java:1663)at org.apache.hadoop.ipc.Server$Listener.doRead(Server.java:887)at org.apache.hadoop.ipc.Server$Listener$Reader.doRunLoop(Server.java:751)at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:722)
从这个异常可以看到,这个异常发生在IPC连接的处理层,即,这个异常根本还未到达上层的业务层,即业务层方法NameNodeRpcServer.blockReport()方法根本就没有调用。
失败的为什么是FBR
事后我们看到(下文会详细介绍),DataNode和NameNode之间的间歇性通信包括了三种类型:
-
心跳(Heartbeat):这是通过方法
BPServiceActor.heartbeat()来完成的,我们从下文的sendHeartbeat()方法的实现可以很容易地看到,心跳信息主要用来告知NameNode自己的Storage元信息以及各种状态信息(xceiver count, cache等)。心跳不携带任何与块和块的数量等信息:HeartbeatResponse sendHeartBeat(boolean requestBlockReportLease)throws IOException {scheduler.scheduleNextHeartbeat();StorageReport[] reports =dn.getFSDataset().getStorageReports(bpos.getBlockPoolId());VolumeFailureSummary volumeFailureSummary = dn.getFSDataset().getVolumeFailureSummary();int numFailedVolumes = volumeFailureSummary != null ?volumeFailureSummary.getFailedStorageLocations().length : 0;return bpNamenode.sendHeartbeat(bpRegistration,reports, // 这个DataNode的每一个 Storage上的Storage元信息dn.getFSDataset().getCacheCapacity(),dn.getFSDataset().getCacheUsed(),dn.getXmitsInProgress(),dn.getXceiverCount(), // xceiver信息,NameNode会依据该信息判断DataNode的繁忙程度,进而影响NameNode的块调度策略numFailedVolumes,volumeFailureSummary,requestBlockReportLease);}每一个Storage的原信息封装在StorageReport对象中,如下所示,这里不赘述。
public class StorageReport {private final DatanodeStorage storage;private final boolean failed;private final long capacity;private final long dfsUsed;private final long nonDfsUsed;private final long remaining;private final long blockPoolUsed;NameNode收到heartbeat以后,会更新自己所维护的DataNode的各种信息,这是通过DataNodeDescriptor的成员方法updateHeartbeatState()完成的:
/*** process datanode heartbeat or stats initialization.*/public void updateHeartbeatState(StorageReport[] reports, long cacheCapacity,long cacheUsed, int xceiverCount, int volFailures,VolumeFailureSummary volumeFailureSummary) {.....setCacheCapacity(cacheCapacity);setCacheUsed(cacheUsed);setXceiverCount(xceiverCount);setLastUpdate(Time.now()); this.volumeFailures = volFailures;this.volumeFailureSummary = volumeFailureSummary;for (StorageReport report : reports) {DatanodeStorageInfo storage = updateStorage(report.getStorage());if (checkFailedStorages) {failedStorageInfos.remove(storage);}storage.receivedHeartbeat(report);totalCapacity += report.getCapacity();totalRemaining += report.getRemaining();totalBlockPoolUsed += report.getBlockPoolUsed();totalDfsUsed += report.getDfsUsed();totalNonDfsUsed += report.getNonDfsUsed();}rollBlocksScheduled(getLastUpdate());// Update total metrics for the node.setCapacity(totalCapacity);setRemaining(totalRemaining);setBlockPoolUsed(totalBlockPoolUsed);setDfsUsed(totalDfsUsed);setNonDfsUsed(totalNonDfsUsed);.....}```同时,DataNode从NameNode领取的各种Command也不是NameNode直接发送给DataNode的,而是放在DataNode的heartbeat的response中的。所以,DataNode是需要处理heatbeat的响应的。 -
增量块汇报(Incremental Block Report):这是通过方法
IncrementalBlockReportManager.sendIBRs()方法完成的,主要用来汇报在过去的短暂时间内最新增加的和删除的Block的信息。增量的块信息是通过方法generateIBRs()收集的:private synchronized StorageReceivedDeletedBlocks[] generateIBRs() {final List<StorageReceivedDeletedBlocks> reports= new ArrayList<>(pendingIBRs.size());for (Map.Entry<DatanodeStorage, PerStorageIBR> entry: pendingIBRs.entrySet()) {final PerStorageIBR perStorage = entry.getValue();// Send newly-received and deleted blockids to namenodefinal ReceivedDeletedBlockInfo[] rdbi = perStorage.removeAll();if (rdbi != null) {reports.add(new StorageReceivedDeletedBlocks(entry.getKey(), rdbi));}}readyToSend = false;return reports.toArray(new StorageReceivedDeletedBlocks[reports.size()]);}与heartbeat不同,增量块汇报并无返回值,即这是单向的RPC调用。
-
全量块汇报(Full Block Report):这是通过
BPServiceActor.blockReport()来进行的,用来对DataNode端的全部块信息进行汇报,其中,在进行全量块汇报的时候,也会在内部先触发一次增量块汇报。这里不赘述,感兴趣的读者可以自行阅读代码。
我们从上面DataNode端的异常堆栈可以看到,异常的发生是在方法BPServiceActor.blockReport()中,即发生在Full Block Report的过程中。这个是合理的:
- RPC Size随着块的数量的增加而增加,只有可能是Full Block Report。因为Incremental Block Report只会涉及到过去很短时间内的变化的块信息,根本不会带来超过64MB的RPC Size。
- 而且,根据HDFS的设计,无论是Heartbeat还是增量块汇报,一旦发生问题,系统将会发生写错误。只有Full Block Report发生问题的时候不会带来直接的系统功能异常,而仅仅会造成我们当前遇到的写性能的降低。比如:
- 如果心跳长期丢失,主要会导致NameNode将这个DataNode判别为Dead DataNode并开始对应块的复制操作以保证副本数量。对heartbeat的检查,发生在一个专门的异步线程HeartbeatManager.Monitor类中,这个HeartbeatManager.Monitor类是一个Runnable
- 由于heartbeat不够及时,NameNode无法获取实时的、准确的DataNode的Storage信息和状态(xceiver, cache)信息
- 同时,心跳本身携带了DataNode发送给NameNode的一些Command,这些Command定义在DatanodeCommand类的实现类中,比如,BlockRecoveryCommand, RegisterCommand等等;
- DataNode无法收到NameNode通过heartbeat的response发送给DataNode的各种Command;
- 如果IBR长期丢失,那么写一个Block的操作是无法完成的,因为写到DataNode的块是需要由DataNode向NameNode进行汇报才会最终被finalize的。这里不再赘述。
块汇报频率的变化
由于我们的dfs.datanode.block.report.intervalMsec设置为21600000,即每6个小时进行一次FBR(每天4次FBR)调度,所有,在事故没有发生的时候,我们观察到DataNode的FBR频率正常,每台DataNode每天会进行8次针对某台NameNode的FBR(想象为啥是8次不是4次?因为FBR会同时发送给Active和StandBy NameNode),同时,对应的IBR的频率大概为200K/10min,而对应的heartbeat的频率大概为400次/10min,如下图所示:

但是,在事故发生的过程中,FBR的频率发生了陡增,几乎到了平均20K/天的频率,而IBR和heartbeat的频率则对应下降。如下图所示:

我们还需要准确理解这个Dashboard的含义,即这里的块汇报次数,是否包含失败的块汇报次数? 即,这个急剧增加的FBR次数,是否都是成功的FBR呢?
我们查看blockReport()代码可以看到,无论FBR成功和失败,都是增加该Counter值:
List<DatanodeCommand> blockReport(long fullBrLeaseId) throws IOException {final ArrayList<DatanodeCommand> cmds = new ArrayList<DatanodeCommand>();......try {if (totalBlockCount < dnConf.blockReportSplitThreshold) {.......success = true;} finally {.......dn.getMetrics().addBlockReport(brSendCost);// 增加fbr统计值 }为什么FBR会反复失败
综上,我们从Metrics上看到FBR的频率陡增,应该是失败以后的重试。我们需要在代码层面看一下FBR的重试逻辑。
在DataNode端,进行FBR、IBR和heartbeat发生在方法BPServiceActor::offerService()中,每一个BPServiceActor对象会绑定到一个NameNode节点上,因此,在我们Active/Standby架构下,会有两个BPServiceActor对象。每一个BPServiceActor对象都是一个Runnable,即一个独立线程,用来和远程的NameNode进行通信:
/*** A thread per active or standby namenode to perform:* <ul>* <li> Pre-registration handshake with namenode</li>* <li> Registration with namenode</li>* <li> Send periodic heartbeats to the namenode</li>* <li> Handle commands received from the namenode</li>* </ul>*/
@InterfaceAudience.Private
class BPServiceActor implements Runnable {
通信的内容包括向NameNode的注册(DataNode启动的时候),重新注册(NameNode在发现DataNode失去联系的时候会向DataNode发送DatanodeProtocol.DNA_REGISTER命令以要求重新注册),发送心跳,IBR和FBR,以及处理来自NameNode的命令。
/*** No matter what kind of exception we get, keep retrying to offerService().* That's the loop that connects to the NameNode and provides basic DataNode* functionality.** Only stop when "shouldRun" or "shouldServiceRun" is turned off, which can* happen either at shutdown or due to refreshNamenodes.*/@Overridepublic void run() {LOG.info(this + " starting to offer service");try {while (true) {// init stufftry {// setup storageconnectToNNAndHandshake(); // 和NN通信break;} catch (IOException ioe) {......}}runningState = RunningState.RUNNING;while (shouldRun()) { // 只要系统没有停止服务,就不断循环try {offerService();} catch (Exception ex) {.... // 即使offerService()抛出异常,sleep一会儿也会继续运行sleepAndLogInterrupts(5000, "offering service");}}runningState = RunningState.EXITED;} catch (Throwable ex) {.....} }可以看到,BPServiceActor的run()方法就是在首次启动并连接到NameNode以后,开始保证offerService()发生异常以后继续运行。而offerService()方法内部会不断循环以向NameNode发送心跳,或者进行IBR,或者进行FBR:
/*** Main loop for each BP thread. Run until shutdown,* forever calling remote NameNode functions.*/private void offerService() throws Exception {.....while (shouldRun()) {try {final long startTime = scheduler.monotonicNow();//// Every so often, send heartbeat or block-report//final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);HeartbeatResponse resp = null;if (sendHeartbeat) {boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&scheduler.isBlockReportDue(startTime);if (!dn.areHeartbeatsDisabledForTests()) {resp = sendHeartBeat(requestBlockReportLease);assert resp != null;if (resp.getFullBlockReportLeaseId() != 0) {.....fullBlockReportLeaseId = resp.getFullBlockReportLeaseId();}.....}}if (ibrManager.sendImmediately() || sendHeartbeat) {ibrManager.sendIBRs(bpNamenode, bpRegistration,bpos.getBlockPoolId(), dn.getMetrics());}List<DatanodeCommand> cmds = null;boolean forceFullBr =scheduler.forceFullBlockReport.getAndSet(false);......if ((fullBlockReportLeaseId != 0) || forceFullBr) {cmds = blockReport(fullBlockReportLeaseId); // 在这里抛出异常fullBlockReportLeaseId = 0;}.....} catch(RemoteException re) {....LOG.warn("RemoteException in offerService", re);sleepAfterException();} catch (IOException e) {LOG.warn("IOException in offerService", e);sleepAfterException();}processQueueMessages();} // while (shouldRun())} // offerService
-
循环持续运行,只要 DataNode 应该继续服务(即还没有关闭)
while (shouldRun()) {try {final long startTime = scheduler.monotonicNow(); -
如果当前时间已到心跳时间,则向 NameNode 发送心跳信息:
final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);HeartbeatResponse resp = null;if (sendHeartbeat) {boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&scheduler.isBlockReportDue(startTime);if (!dn.areHeartbeatsDisabledForTests()) {resp = sendHeartBeat(requestBlockReportLease);...}}每个心跳会携带节点状态(名称、端口、容量等)。如果块报告也到期,心跳中还会请求块报告的租约(lease)。
返回的 HeartbeatResponse 包含后续指令。 -
处理 NameNode 返回的状态,包括:更新租约 ID,检查是否为 Active NameNode,执行来自 NameNode 的命令,更新高可用状态(HA state):
if (resp.getFullBlockReportLeaseId() != 0) {...fullBlockReportLeaseId = resp.getFullBlockReportLeaseId();}dn.getMetrics().addHeartbeat(...);bpos.updateActorStatesFromHeartbeat(this, resp.getNameNodeHaState());state = resp.getNameNodeHaState().getState();if (state == HAServiceState.ACTIVE) {handleRollingUpgradeStatus(resp);}if (!processCommand(resp.getCommands()))continue; -
按需要进行增量块汇报,即如果到达了增量块汇报的时间,或者尽管没到,但是刚刚进行了heartbeat的发送,那么就进行一次增量块汇报:
if (ibrManager.sendImmediately() || sendHeartbeat) {ibrManager.sendIBRs(bpNamenode, bpRegistration,bpos.getBlockPoolId(), dn.getMetrics()); } -
如果收到了NameNode端批准的全量块汇报租约,或者,收到了强制进行块汇报的请求,那么就进行全量块汇报:
boolean forceFullBr = scheduler.forceFullBlockReport.getAndSet(false);if ((fullBlockReportLeaseId != 0) || forceFullBr) {cmds = blockReport(fullBlockReportLeaseId);fullBlockReportLeaseId = 0; // 将fullBlockReportLeaseId取消置位,等待下一次的FBR时机}processCommand(cmds == null ? null : cmds.toArray(new DatanodeCommand[cmds.size()])); -
其它的处理不再赘述。
从上述代码我们看到,在正常情况下:
- 什么时候会尝试去请求一个blockReport的租约:
-
heartbeat只会在blockReport的时间到了(6h),并且目前还没有获取租约,才会尝试向NameNode去请求一个blockReport的租约:
// 只有当blockReport的时机到了(距离上一次blockReport过去6h,并且当前还没有获得租约)boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&scheduler.isBlockReportDue(startTime);boolean isBlockReportDue(long curTime) {return nextBlockReportTime - curTime <= 0;}由于是且的关系,因此,正常情况下,最短6小时才会尝试进行一次FBR租约的请求。
-
如果response中获取到了租约,则将租约存下来:
if (resp.getFullBlockReportLeaseId() != 0) {fullBlockReportLeaseId = resp.getFullBlockReportLeaseId();} -
一般情况下(不考虑用户强制FBR的情况),如果有了租约,则立刻进行FBR,FBR完成以后重新将租约清空避免反复FBR:
if ((fullBlockReportLeaseId != 0) || forceFullBr) {cmds = blockReport(fullBlockReportLeaseId);fullBlockReportLeaseId = 0;}
我们乍一看上述代码,看到的FBR重试逻辑,如果FBR失败了,后面会反复高频重试吗?
我们看一下blockReport()方法中关于下次调度时机的设置:
/*** Report the list blocks to the Namenode* @return DatanodeCommands returned by the NN. May be null.* @throws IOException*/List<DatanodeCommand> blockReport(long fullBrLeaseId) throws IOException {.....try {... // 发送blockReport请求success = true;} finally {....scheduler.scheduleNextBlockReport(); // 设置下一次进行fbr的时间return cmds.size() == 0 ? null : cmds;}void scheduleNextBlockReport() {// If we have sent the first set of block reports, then wait a random// time before we start the periodic block reports.if (resetBlockReportTime) {nextBlockReportTime = monotonicNow() +DFSUtil.getRandom().nextInt((int)(blockReportIntervalMs));resetBlockReportTime = false;} else {nextBlockReportTime +=(((monotonicNow() - nextBlockReportTime + blockReportIntervalMs) /blockReportIntervalMs)) * blockReportIntervalMs;}}
可以看到,即使blockRepor太失败了,scheduler.scheduleNextBlockReport()也会正常被调用,并且,我们进一步查看scheduleNextBlockReport()方法细节,下一次fbr的时间也与这次的fbr成功与否无关。所以,再结合offerService()方法中的下面代码:
boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&scheduler.isBlockReportDue(startTime);
的条件判断,不应该发生FBR反复失败并反复调用的情况,预期的逻辑是,如果这次FBR失败了,下次重试也是在6个小时以后了。
我想了很久,才看到了其中的奥秘:
if ((fullBlockReportLeaseId != 0) || forceFullBr) {cmds = blockReport(fullBlockReportLeaseId);fullBlockReportLeaseId = 0; // 如果blockReport抛出异常,这行代码不会执行}
可以看到,如果blockReport(fullBlockReportLeaseId)抛出异常,那么fullBlockReportLeaseId不会被清空,而如果fullBlockReportLeaseId没有被清空,blockReport(fullBlockReportLeaseId)就会被反复执行,根本不再依赖调度时机,也不再依赖向NameNode发送新的租约请求了。
HDFS性能下降导致Yarn负载变高的形式化分析
由此我们可以看到,Yarn的资源使用率变高(负载变高),居然有可能是存储系统的性能下降导致的。
我们可以类比操作系统层面我们经常遇到的问题,即我们在操作系统性能诊断的时候经常遇到的,IO Wait的大量增加,居然会导致CPU Load Average增加的例子,与此同时CPU Usage却很低。
理解线程
我们先看一下常见的操作系统层面的线程状态:
| 状态 | 名称 | 含义 | 常见场景说明 |
|---|---|---|---|
| R | Running | 正在运行或在就绪队列中等待 CPU | CPU 正在执行线程,或线程在抢占 CPU |
| S | Sleeping | 可中断的休眠状态 | 等待信号、网络事件、定时器,正常休眠状态 |
| D | Uninterruptible Sleep | 不可中断的休眠状态(主要是 I/O 等待) | 等磁盘、NFS、网络存储、驱动响应;kill -9 无效 |
| Z | Zombie | 僵尸进程 | 子进程退出但父进程未回收,常见于编程错误 |
| T | Stopped | 被暂停 | 手动 kill -STOP,或 Ctrl+Z 暂停终端程序 |
| I | Idle (内核专用) | 内核线程空闲状态 | Linux kernel 的空闲线程,普通用户进程不会出现该状态 |
| X | Dead | 死亡状态(极罕见) | 已彻底结束的线程,瞬间即逝 |
对于操作系统层面的线程,我们需要关键区分的问题是:
- R状态的线程:不一定正在运行,也有可能处于就绪队列中等待运行;
- S状态的线程:当我们调用sleep方法的时候,当前线程进入休眠,这时候会主动让出CPU资源,直到被唤醒并重新执行
- D状态的线程: 当我们执行IO操作的时候,如果是等待磁盘读写完成,则进入到Uninterruptible Sleep状态,这时候是无法通过kill -9进行中断的。这时候线程也会让出CPU资源。
- CPU 是靠操作系统的调度器来管理的。当某个线程进入 I/O wait(D 状态),OS 就会把它从“可运行队列”中移除。调度器会立刻选择另一个 R 状态(就绪状态)的线程(如果有的话),分配给 CPU 执行。
对于Java线程,其线程状态(Thread.State)和操作系统层面的状态(比如 Linux 的 R, S, D, 等)不是一一对应。Java线程状态如下:
| Java 状态 | 含义 |
|---|---|
| NEW | 线程创建了但还没启动 |
| RUNNABLE | 正在运行或等待操作系统分配 CPU(对应 Linux 的 R) |
| BLOCKED | 等待获取某个锁(synchronized) |
| WAITING | 进入无限等待(wait()、join()、LockSupport.park()) |
| TIMED_WAITING | 等待有限时间(如 sleep()、wait(timeout)) |
| TERMINATED | 执行完毕,线程结束 |
最关键的,Java 中的 BLOCKED 是线程在尝试进入一个 synchronized 块或方法,但别的线程已经拿了锁,所以它阻塞在锁入口处,还没进去。 在这个阶段,Java 线程不是主动休眠,而是卡在等待互斥锁的获取。
通常会被操作系统标记为 S(Sleeping)状态 或者 R(Running)状态下阻塞住的),取决于实现和调度时机**。
| Java 状态 | 含义 |
|---|---|
| BLOCKED | 等待进入 synchronized 代码块,别的线程持有锁,线程的该状态中的操作系统线程状态依赖于操作系统实现,有可能是S,有可能是R |
| WAITING | 调用了 wait()、join()、LockSupport.park(),主动休眠,对应操作系统层面应该是S |
| TIMED_WAITING | 和 WAITING 类似,但带有超时时间(如 sleep()、wait(timeout)),对应操作系统层面也应该是S |
理解IO Wait
操作系统层面,一个线程一旦 I/O 完成,中断触发,操作系统会把原线程从D状态恢复为R状态,等待下一轮调度。
-
CPU Load Average 的准确定义
-
Load Average 表示单位时间内系统处于 可运行状态(Runnable, R状态) 或 不可中断睡眠状态(Uninterruptible Sleep,即 D 状态) 的进程数的平均值。
-
例如,1分钟负载 2.0 表示过去1分钟内平均有2个进程占用或等待CPU资源。
-
关键点:Load Average 不仅包括正在使用CPU的进程,还包括就绪队列中的进程(等待CPU调度),或者因为IO阻塞处于 D 状态的进程(如等待磁盘响应的进程)。
-
-
为什么高 IO Wait 会导致CPU Load Average 升高?
- 当磁盘性能下降时,进程发起IO请求后会被阻塞,进入 D 状态(Uninterruptible Sleep)。 D 状态的进程无法被中断,直到IO完成。 这些D状态的进程会被计入Load Average(因为它们是“等待系统资源的活动进程”)。
- 如果大量进程因IO阻塞,Load Average 会显著上升,但是其实它们并未真正消耗CPU。
-
为什么IO Wait高的时候,CPU 使用率(Usage)不一定高?
- 因为CPU 使用率统计的是CPU 实际执行代码的时间比例。当进程因IO阻塞时,它们处于D状态,不占用CPU(CPU可能空闲或执行其他少数任务)。甚至,如果所有进程都在等IO,CPU可能因无任务可做而使用率为0。
- 因此,高IO Wait时:
- Load Average 高:大量进程阻塞在D状态(被计入负载)
- CPU Usage 低:CPU本身没有太多任务需要处理
-
类比解释
想象一个银行柜台(CPU)和排队的人(进程):- 正常情况:人们快速办理业务(IO快),队列很短(Load低);
- 磁盘慢时:柜台处理速度不变,但每个人办理业务时被卡在签字环节(IO阻塞),队伍越来越长(Load高),但柜台可能空闲(CPU Usage低);
所以
- CPU Load Average 反映的是系统资源的整体压力(CPU+IO等),而不仅是CPU使用率。D 状态的进程是负载升高的“元凶”:它们被计入负载但影响CPU使用率。
- 高 Load + 低 CPU Usage 是典型的IO瓶颈特征(如磁盘慢、网络存储延迟等)。
理解这一点后,我们就知道为什么优化磁盘(如换SSD、调整文件系统)或减少IO密集型任务可以降低负载,即使CPU本身并不忙。
理解HDFS性能下降导致Yarn负载和使用率增高
这时候我们往往有一个问题,就是在操作系统层面如果IO Wait增加,那么伴随着CPU Load Average的增加和CPU Usage的降低,但是,在HDFS性能下降的时候,Yarn的Waiting Application的确增加了,但是为什么Yarn的Memory和CPU的Usage也增加了呢?
这个也很好理解,因为Yarn上Memory和CPU的使用率是假的使用率。因为Yarn对Application的Memory Usage和CPU Usage的统计是在申请时确定的,而并不真正关心Application实际上占用多少内存或者占用了多少CPU。比如,一个Spark Batch Job申请了100GB 内存和 40个vCore,这个Spark job运行期间即使在进行sleep(Integer.MAX_VALUE), Yarn这边也会认为这个Spark Batch Application占用了100GB 内存和40 vCore的CPU.
引用
HDFS的块汇报和块放置策略–从一次HDFS写文件故障开始