进程的查看与属性
一、进程的存储与查看
1.1为什么要有PCB
OS要管理进程,就要遵循“先描述,后组织”的原则,组织的结果就是PCB
1.2Linux中task_struct的存储与查看
1.2.1task_struct的存储
task_struct是一个内存级的,是Linux内核中一种数据结构的单位,在内存(RAM)中创建
1.2.2task_struct的查看(结合示例)
首先准备一个无限循环的code.c
将其编译运行后用来进行进程的查看
code.c:
1 #include<stdio.h>2 #include<unistd.h>3 int main()4 { 5 int n=0;6 while(1)7 {8 9 printf("%d\n",n);10 n++;11 sleep(1);12 }13 return 0;14 }
此时再打开一个shell,可以选择
ps ajx 查看的所有当前进行的程序
ps ajx结果:
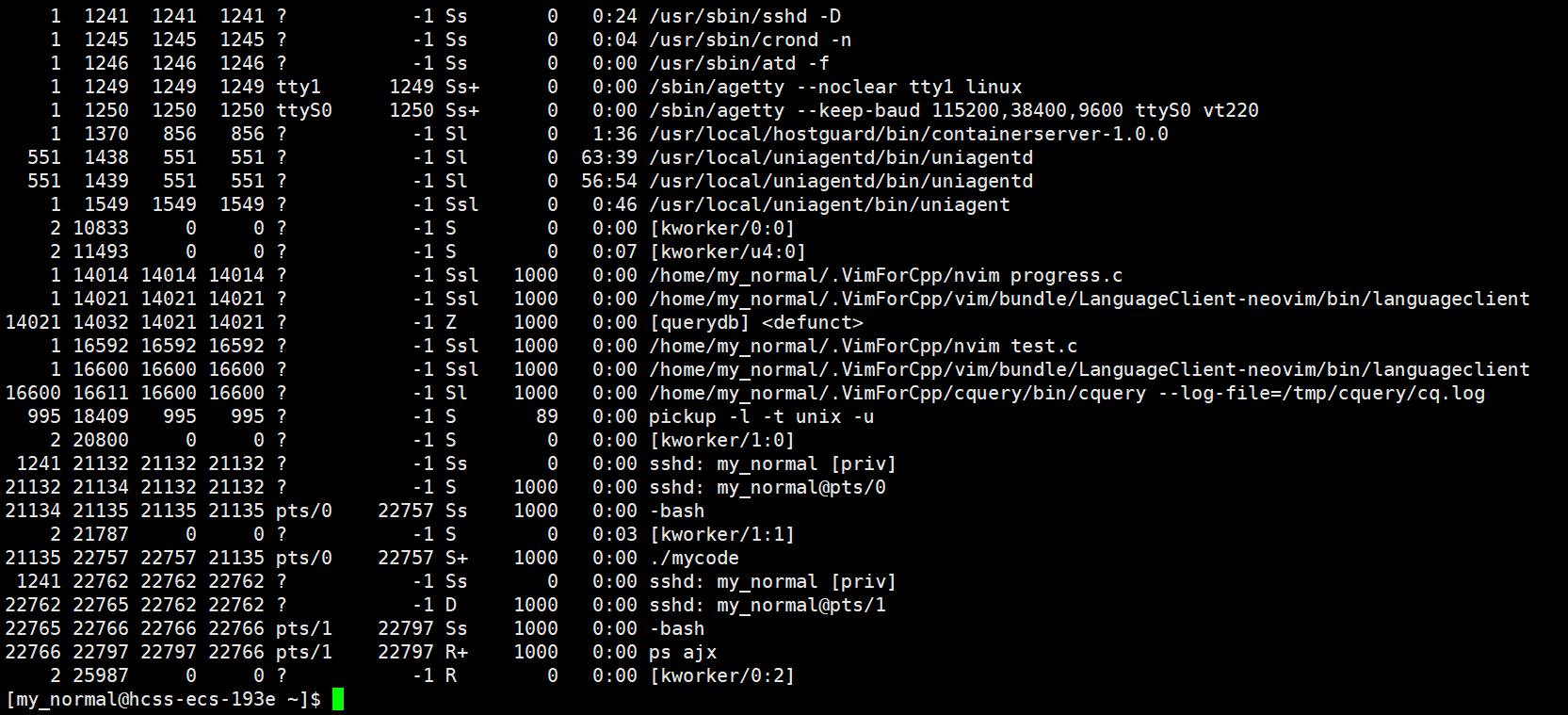
这并不容易观察,我们可以:
利用head -1来提取第一行标题信息,利用grep来搜索需要的内容(一行执行多条指令,可以用;或者&&来连接)

为什么会有这一行呢?
![]()
这是因为grep查询mycode本身也是一个进程
我们可以选择用-v选项结合[忽视内容]来屏蔽grep的进程

1.3进程的创建方式:瞬时和常驻
实际上,windows中的双击或者运行可执行程序本质上就是在系统中启动了一个进程
①瞬时进程:执行完就退出,如ls,pwd等
②常驻进程:一直不退,只有用户关闭才会退出,例如刚刚写的mycode
1.4进程的结束方式
①使用kill指令的-9选项
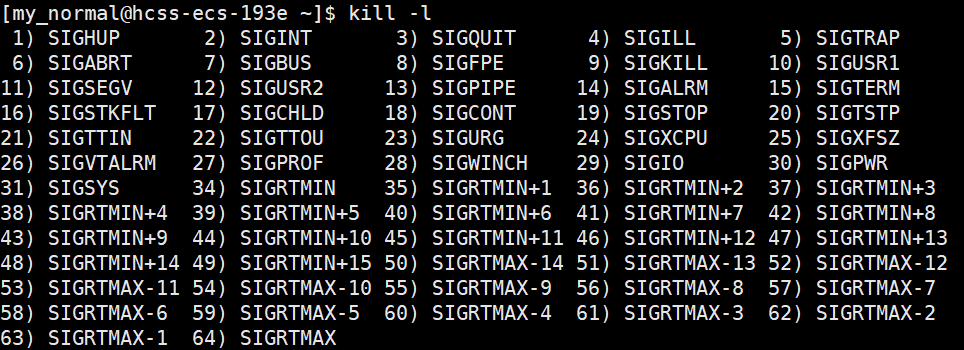
第九选项SIGKILL可以结束进程
使用方式:
kill -9 +[进程PID]
②ctrl+C杀进程
二、进程中的属性
2.1进程中的唯一标识符:PID
2.1.1PID是什么
PID是每个进程都会有的一个“唯一标识符”
我们在ps axj查看进城的时候,可以发现每个进程都有一个PID(实际上PID随机分配底层类似累加器,而且一个进程结束以后再次运行,它的PID也是不一样的)
mycode原PID:

mycode新PID:

2.1.2PID在代码中的获取方式
我们可以使用getpid函数来获取当前进程的PID
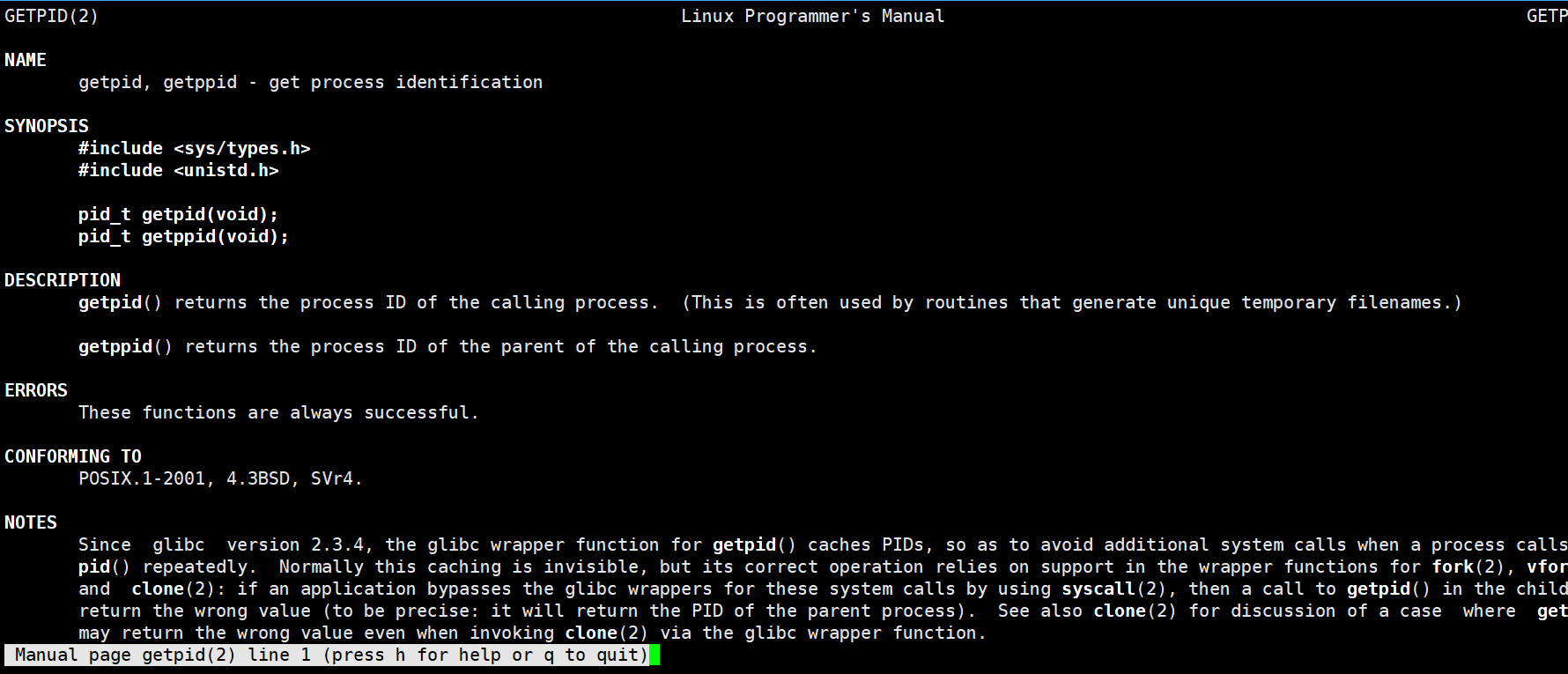
使用时需要包含两个头文件:
#include <sys/types.h>
#include <unistd.h>
它的返回值pid_t本质上就是一个int类型的typedef
1 #include<stdio.h>2 #include<unistd.h>3 #include <sys/types.h>4 int main()5 {6 int n=0;7 while(1)8 {9 10 printf("%d\n",n);11 printf("PID:%d\n",getpid()); 12 n++;13 sleep(1);14 }15 return 0;16 }
运行结果:
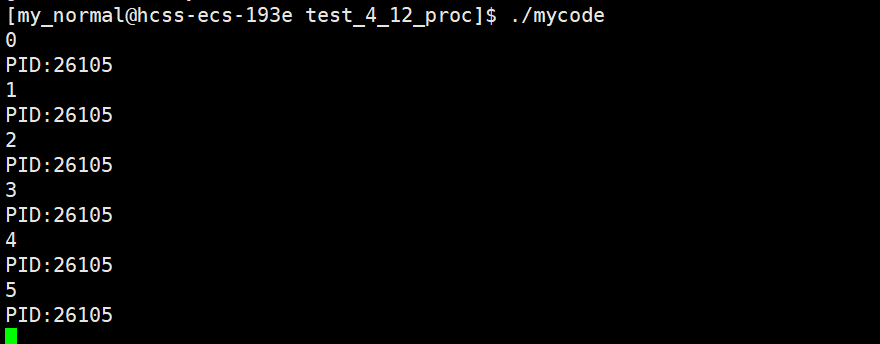
2.2进程中的两个常用属性:exe和cwd
2.2.1根目录下储存进程中属性的文件夹proc
进程中的属性其实都存在根目录下的文件夹proc中,它是process的简称
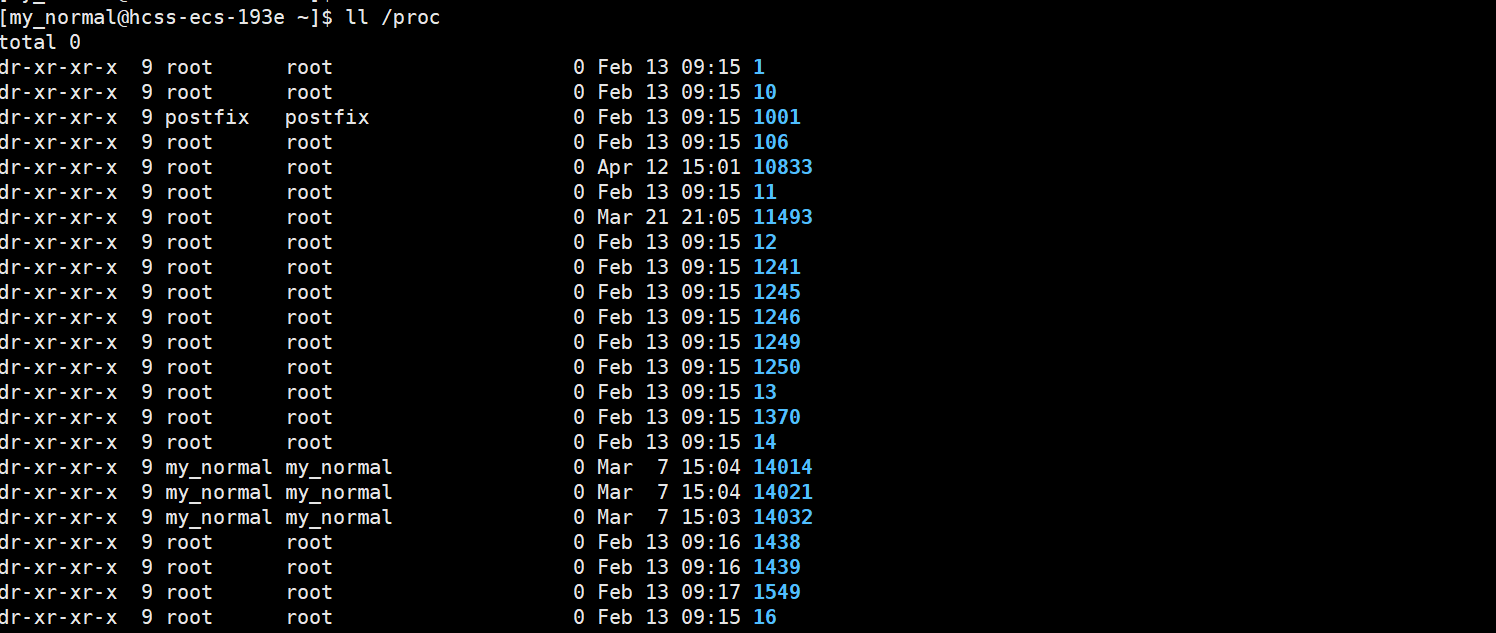
在这个文件中,我们可以通过PID查找进程

进程中的属性
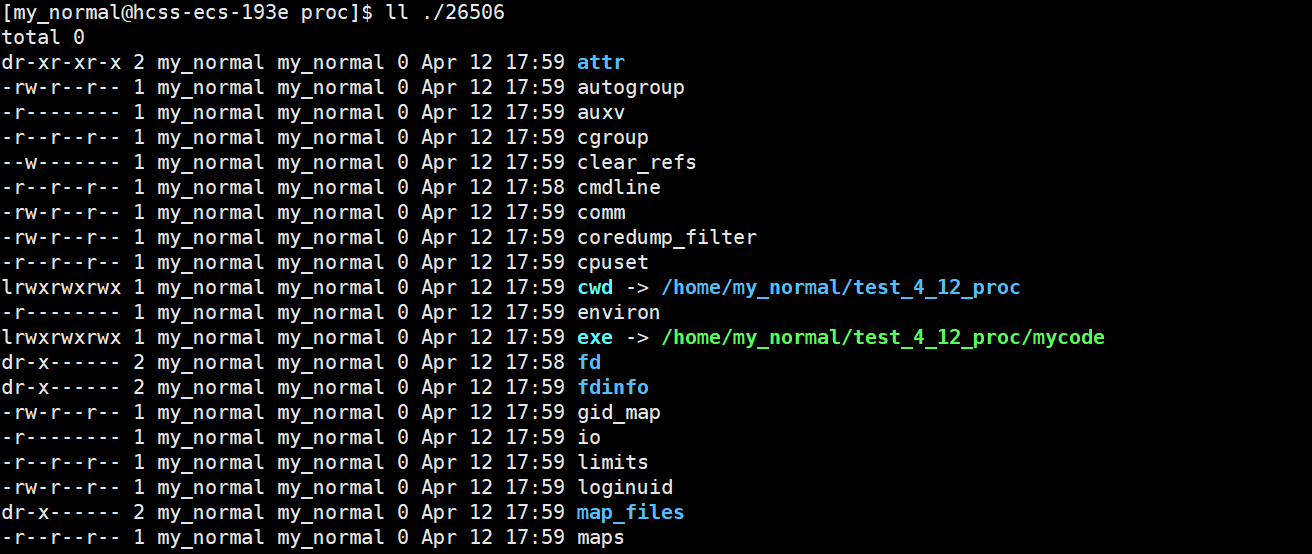
2.2.1补:ps底层就是/proc
ps 指令可以直接查看部分当前进程的属性,本质上也是调用/proc并整理其内容
它们的区别是:ps是封装的结果,/proc是系统调用接口
2.2.2exe属性
![]()
指向的是对应进程源头可执行程序的路径
此时如果去该路径下删除可执行程序,运行中的程序不会立即停止,为什么?
![]()
我们删除的是磁盘中的可执行程序,但是该可执行程序在此之前是通过被加载到了内存中来实现运行的,所以内存中的可执行程序依旧存在,不受影响
2.2.3cwd属性
全称是current work dir:当前工作目录
其展示的内容与pwd的结果基本一致
![]()

①作用:其作用的体现可以通过fopen来说明,例如在code.c中添加这样一行代码
FILE* fp=fopen("text.txt","w");本质上就是将cwd的内容拼接到第一个参数列表之前,以此形成完整的访问路径
②cwd的主动修改:
可以通过代码中的chdir函数来实现cwd的主动修改
(chdir函数:修改成功返回0,否则返回-1)
加入此时将code.c代码修改为
再次查看属性
![]()
2.2.4特殊的proc:内存在磁盘中的映射
实际上,/proc并不是磁盘级文件,他只是内存中对应对象(一个task_struct对象)的属性在磁盘中的“挂名”,属于内存级文件
2.3父进程标识:PPID
2.3.1什么是PPID
ppid中的第一个p指的是parent,即父进程的PID
2.3.2PPID在代码中的获取方式
可以在代码中使用getppid函数来获取
更改code.c代码
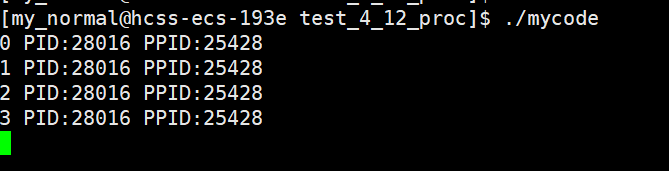
1 #include<stdio.h>2 #include<unistd.h>3 #include <sys/types.h>4 int main()5 {6 int n=0;7 chdir("/home/my_normal/test_2_20");8 while(1)9 {10 11 printf("%d ",n);12 printf("PID:%d ",getpid());13 printf("PPID:%d\n",getppid()); 14 n++;15 sleep(1);16 }17 return 0;18 }
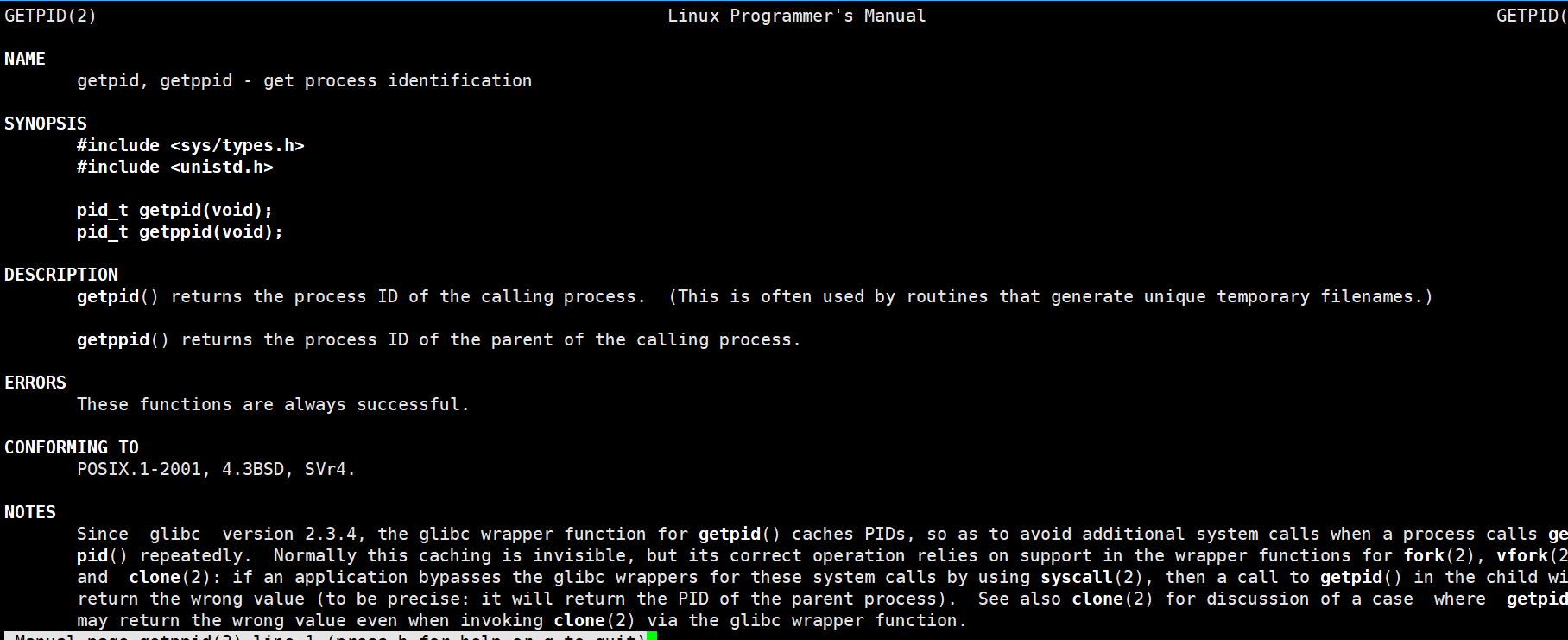
打印结果
2.4bash进程
在上一个例子中,我们看到mycode的PPID值为25428,那么这到底是什么呢?

从结果可以看出:这正是bash
我们在命令行中执行命令/程序,本质是bash进程创建的子进程,由子进程来执行我们的代码
bash其实就是命令行解释器shell(属于统称)在Linux下的特化
bash什么时候创建呢?
我们每次登录时都会创建一个-bash
例如此时我进行了三次登录

三、子进程的创建
3.1fork函数进行子进程的创建
3.1.1fork函数的功能介绍
fork函数是一个系统调用接口
可以用来创建一个子进程,返回值分三种:
①创建成功,在父进程中返回子进程的PID
②创建成功,在子进程中返回0
③创建失败:返回-1
3.1.2fork函数使用举例
1 #include<stdio.h>2 #include<unistd.h>3 4 int main()5 6 { 7 printf("下面展示创建子进程后的情况:\n");8 9 pid_t pd=fork();10 (void)pd;11 printf("I am a process ,PID:%d ,PPID:%d\n",getpid(),getppid());12 sleep(1);13 14 return 0;15 }
运行结果:

分析结果我们可以看出:
第一条结果的PID是第二条结果的PPID,也就是父进程
对应的,第二条结果无疑就是子进程了
所以,使用fork函数可以让我们以原来的进程为父进程,继续创建新的子进程
3.1.2补:当变量定义但未使用时发出警告的处理方案
在使用vim中,有一个设置会让没有使用的变量上被标记一个警告,如果要正常编译运行我们需要将这一警告解除,此时可以选择
(void)+[变量]
3.1.3返回值的设置根据
为什么fork的返回值会这么设置呢?
实际上在Linux中,进程的整体是一个树形结构的
父 :子 = 1 :n
所以需要区分的是”父亲的孩子“,而不是”孩子的父亲“
3.2父子进程间代码的共享与数据的私有
3.2.1结合例子观察现象
代码逻辑:
1 #include<stdio.h>2 #include<unistd.h>3 #include <sys/types.h>4 5 int tmp=0;6 int main()7 {8 printf("I am a process, pid: %d, ppid: %d\n", getpid(), getppid());9 pid_t id = fork();10 if(id > 0)11 {12 while(1)13 { 14 printf("我是父进程, pid: %d, ppid:%d, ret id: %d, gval: %d\n", getpid(), getppid(), id, tmp); 15 tmp+=2;16 sleep(1);17 }18 }19 else if(id == 0)20 {21 while(1)22 {23 printf("我是子进程, pid: %d, ppid:%d, ret id: %d, gval: %d\n", getpid(), getppid(), id, tmp);24 tmp++;25 sleep(1);26 }27 }28 return 0;29 }①当返回pid_t的值为子进程的PID时,说明当前进程为父进程,我们让tmp为偶数
②当返回pid_t的值为0时,说明当前进程为子进程,我们让tmp为奇数
运行结果
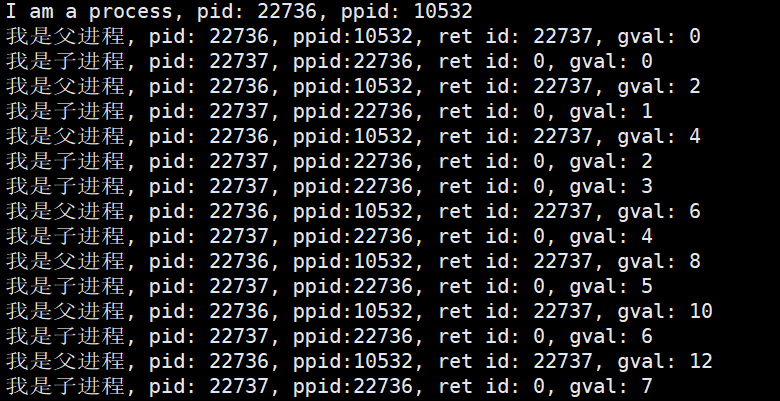
综上,fork()的运行结果会呈现出两个进程(二者间是父子关系)
他们之间:代码是会共享的,但是数据各自私有一份
3.2.2为什么会出现代码共享
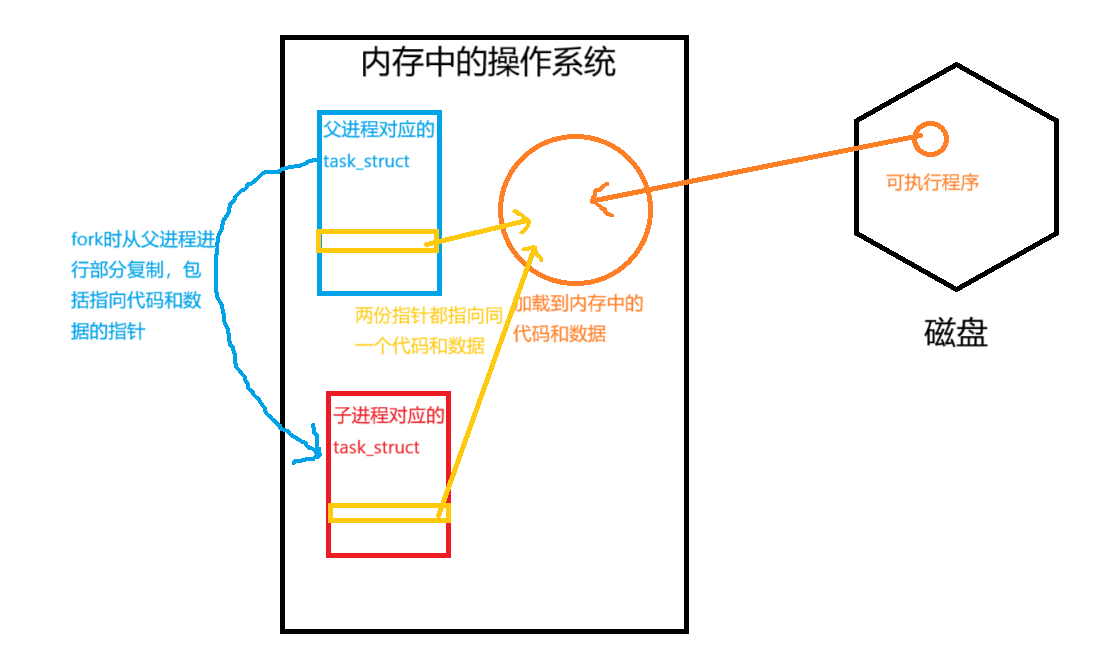
我们知道:进程=内核数据结构+代码和数据
磁盘当中的代码和数据仅有一份加载到内存中,我们创建子进程时虽然为它创建了task_struct,但并没有对代码和数据做二次加载,默认指向与父进程同一份
3.2.3为什么数据各自私有一份
进程之间具有很强的独立性,多个进程之间运行时互不影响,就算是父子进程也一样
这种独立性在代码和数据二者中都有体现:①代码是只读的,不受多进程影响②数据各自私有一份
3.2.4选择语句if-else同时得以执行的原因
我们例子中的if-else语句的内容都被执行了,这是因为在fork创建子进程后,这两个进程同时运行
在第一个进程中走if的逻辑;第二个进程中走else的逻辑
但我们看到的只是他们同时运行的结果:if与else都被执行
对于pid_t id = fork();返回的本质就是向指定变量写入返回值数据,因此父/子进程有着不同的id变量
3.3多进程的创建
3.3.1C++的编译方式
创建C++文件:后缀为.cc .cxx .cpp都可以
需要先安装g++
sudo yum install -y gcc-c++
调用
g++ -o $@ $^ -std=c++11
3.3.2多进程创建的原理
多进程创建其实就是循环调用fork函数,每次调用都会形成当前父进程下一个新的的子进程
3.4对于子进程创建的理解
创建子进程使用的函数fork是一个系统调用接口
在fork内部:创建子进程意味着多了一个task_struct:先从父进程拷贝,然后调整一部分属性;
之后将这个新的task_struct连入到进程列表中,完成这些,父子进程就都已经开始运行了
为什么fork函数会有两个返回值呢?
其实是因为fork函数在父子进程中分别进行了返回,fork中俄return语句也属于代码,也是被父子进程共享的,但他们对应的数据并不一样
3.4补:fork运行结束后,父子进程谁先开始执行
这是不确定的,需要由OS调度器自行决定