基础学习(4): Batch Norm / Layer Norm / Instance Norm / Group Norm
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 1 batch normalization(BN)
- 2 Layer normalization (LN)
- 3 instance normalization (IN)
- 4 group normalization (GN)
- 总结
前言
对 norm/batch/instance/group 这四种normalization进行整理.
首先假设我们的数据结构都是 [n, c, h, w] 数据结构如下图,下图中n=4, c = 7, h=她喜欢的数字, w=他喜欢的数字
还有个链接写的不错,但是语言晦涩,尤其across 用的太晦涩。link:https://isaac-the-man.dev/posts/normalization-strategies/
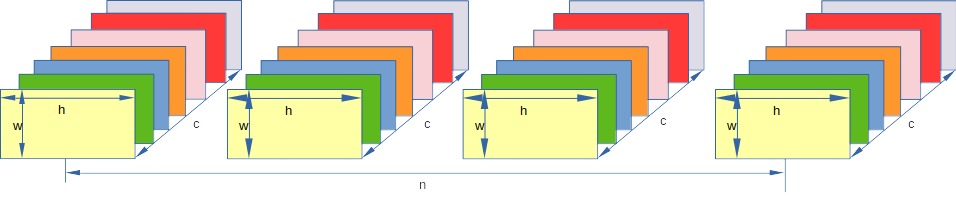
1 batch normalization(BN)
因为深度学习中,一个channel的数据往往是同一类数据,比如rgb中的 r,所以在同一个channel上做nomrlization是合理的. 下图中,我的例子是将橙色的channel全部取出, 做normalization,也就是论文中说的"across the channel dimension C"(横跨了所有c).
对应的数学过程:
(1) 求平均, x x x是图像中的一个点
μ c = 3 = 1 H ∗ W ∗ N ∑ n , h , w x [ n , h , w ] \mu_{c=3} = \frac{1}{H * W * N} \sum_{n,h,w} x[n,h,w] μc=3=H∗W∗N1∑n,h,wx[n,h,w] c 从 0开始
(2) 计算方差:
δ c = 3 = 1 H ∗ W ∗ N ∑ n , h , w ( x [ n , h , w ] − μ c ) 2 \delta_{c=3} = \frac{1}{H * W * N} \sum_{n,h,w} (x[n,h,w] - \mu_c)^2 δc=3=H∗W∗N1∑n,h,w(x[n,h,w]−μc)2
(3)归一化
x ^ n , c = 3 , h , w = x n , c = 3 , h , w − μ c δ c 2 + ϵ γ + β \hat x_{n,c=3,h,w} = \frac{x_{n,c=3,h,w}- \mu_c}{ \sqrt{\delta_c^2 + \epsilon} } \gamma + \beta x^n,c=3,h,w=δc2+ϵxn,c=3,h,w−μcγ+β, γ \gamma γ 是 scale β \beta β 是 bais
这样就使得数据分布范围是0~1 之间,这样就不梯度爆炸或者数据奇异,始终将数据拉到一个合理范围内
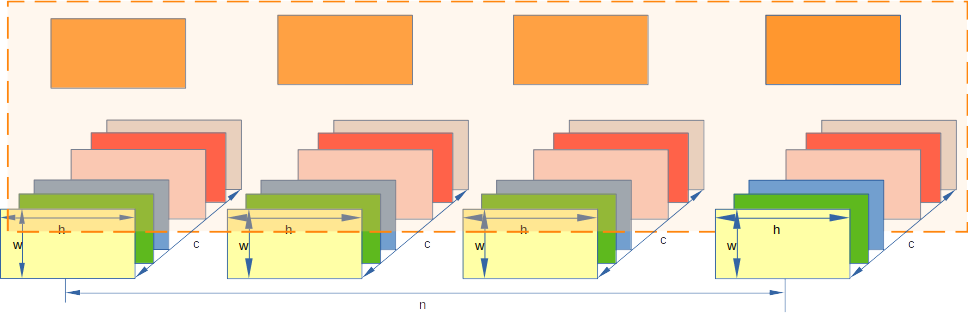
2 Layer normalization (LN)
layernorm 是 transformer 中出现的, 原因是处理语音等数据, 相同channel跨着batch 一起做norm 效果不大,反而是一个语音段前后是有逻辑连续性, 因此以一个sample 为单元(即从* h * w) 做normalization. 就是 论文中的 “across the batch dimension N”
数学过程:
(1) 求平均
μ n = 1 C ∗ H ∗ W ∑ c , h , w x [ c , h , w ] \mu_{n} = \frac{1}{C*H*W} \sum_{c,h,w} x[c,h,w] μn=C∗H∗W1∑c,h,wx[c,h,w] 例如图中是 n=0
(2) 计算方差:
δ n = 1 C ∗ W ∗ N ∑ c , h , w ( x [ c , h , w ] − μ n ) 2 \delta_n = \frac{1}{C * W * N} \sum_{c,h,w} (x[c,h,w] - \mu_{n})^2 δn=C∗W∗N1∑c,h,w(x[c,h,w]−μn)2
(3)归一化
x ^ n , c , h , w = x n , c , h , w − μ c δ n 2 + ϵ γ + β \hat x_{n,c,h,w} = \frac{x_{n,c,h,w}- \mu_c}{ \sqrt{\delta_n^2 + \epsilon} } \gamma + \beta x^n,c,h,w=δn2+ϵxn,c,h,w−μcγ+β, γ \gamma γ 是 scale β \beta β 是 bais
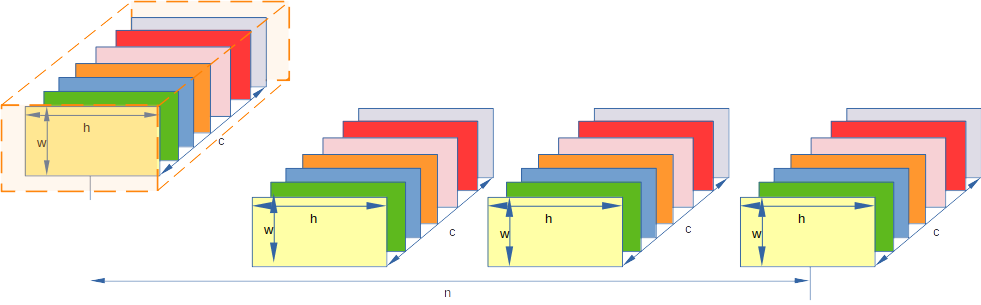
3 instance normalization (IN)
instance normalization 我认为就是对一个batch 中 某个channel的数据进行归一化,比较简单
太简单了,我就截图数学过程:
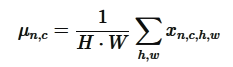
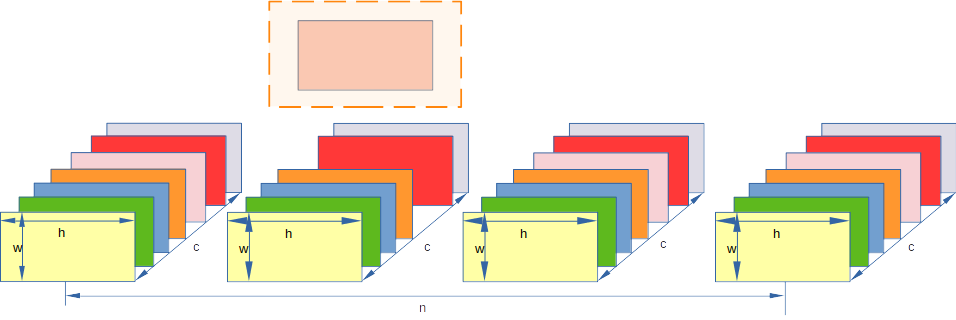
4 group normalization (GN)
group normalization 就是在layer norm 的基础上不会取完所有channel数据,而是一部分,所以跟layer norm 非常像. 注意这里的G 是将 C 分成了多少个组, 也就是每个组内channel数量是C/G
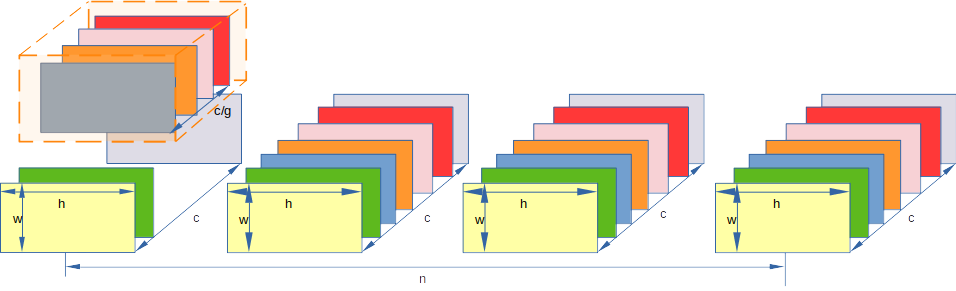
注意我图中话的不是很合理,因为 c/g 不是整数,这里只是示意
数学公式:
(1) 求平均
μ g = 1 C / G ∗ H ∗ W ∑ c ^ , h , w x [ c ^ , h , w ] \mu_{g} = \frac{1}{C/G*H*W} \sum_{{\hat c},h,w} x[{\hat c},h,w] μg=C/G∗H∗W1∑c^,h,wx[c^,h,w] 其中, c ^ \hat c c^ 属于c/g 的那个组
(2) 计算方差:
δ g = 1 C / G ∗ W ∗ N ∑ c ^ , h , w ( x [ c ^ , h , w ] − μ g ) 2 \delta_g = \frac{1}{C/G * W * N} \sum_{{\hat c},h,w} (x[{\hat c},h,w] - \mu_{g})^2 δg=C/G∗W∗N1∑c^,h,w(x[c^,h,w]−μg)2
(3)归一化
x ^ n , c ^ , h , w = x n , c ^ , h , w − μ g δ g 2 + ϵ γ + β \hat x_{n,{\hat c},h,w} = \frac{x_{n,{\hat c},h,w}- \mu_g}{ \sqrt{\delta_g^2 + \epsilon} } \gamma + \beta x^n,c^,h,w=δg2+ϵxn,c^,h,w−μgγ+β, γ \gamma γ 是 scale β \beta β 是 bais
可以这么说:
如果 G=1:GroupNorm = LayerNorm
如果 G=C:GroupNorm = InstanceNorm
如果 G=任意值:就是常规 GN
总结
这里将4种norm进行常见应用总结
| 方法 | 归一化的维度 | 每个 μ 和 σ 的计算范围 | 是否依赖 Batch Size | 应用场景 |
|---|---|---|---|---|
| BatchNorm | 每个通道 C,跨 batch 和空间 [N, H, W] | 每个通道一个统计量 | 是 | CNN / 图像识别训练加速 |
| LayerNorm | 每个样本,每个位置 [C, H, W] | 每个样本单独归一化 | 否 | NLP / Transformer |
| InstanceNorm | 每个样本、每个通道 [H, W] | 像 LayerNorm 但只在 spatial 上归一化 | 否 | 图像生成、风格迁移 |
| GroupNorm | 每个样本,每组通道 [C/G, H, W] | 将通道分组归一化 | 否 | 替代 BatchNorm,无 batch size 限制 |