Python异步编程入门:Async/Await实战详解
引言
在当今高并发的应用场景下,传统的同步编程模式逐渐暴露出性能瓶颈。Python通过asyncio模块和async/await语法为开发者提供了原生的异步编程支持。本文将手把手带你理解异步编程的核心概念,并通过实际代码案例演示如何用异步爬虫提升10倍效率!
一、同步 vs 异步:本质区别
1.1 同步编程的痛点
import timedef fetch(url):print(f"Start: {url}")time.sleep(2) # 模拟网络请求print(f"End: {url}")# 同步执行耗时约6秒
start = time.time()
fetch("url1")
fetch("url2")
fetch("url3")
print(f"Total time: {time.time()-start:.2f}s")运行结果:
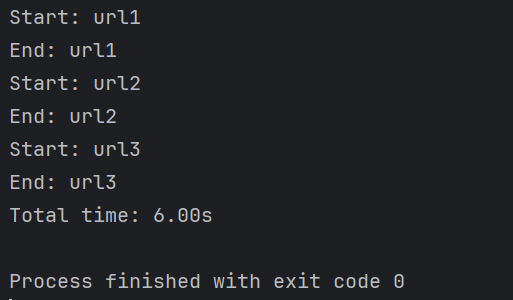
1.2 异步编程的优势
import asyncioasync def async_fetch(url):print(f"Start: {url}")await asyncio.sleep(2) # 异步等待print(f"End: {url}")# 异步执行仅需约2秒
async def main():tasks = [async_fetch("url1"),async_fetch("url2"),async_fetch("url3")]await asyncio.gather(*tasks)start = time.time()
asyncio.run(main())
print(f"Total time: {time.time()-start:.2f}s")运行结果:
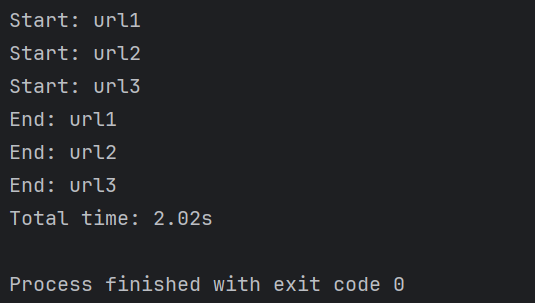
二、核心概念解析
2.1 事件循环(Event Loop)
相当于异步程序的心脏,负责调度所有协程任务
2.2 协程(Coroutine)
-
通过
async def定义的异步函数 -
使用
await挂起阻塞操作
2.3 Future对象
承载异步操作最终结果的容器
三、实战:异步网络请求
使用aiohttp实现高效爬虫:
import aiohttp
import asyncioasync def fetch_page(session, url):async with session.get(url) as response:print(f"Status: {response.status}")return await response.text()async def main():async with aiohttp.ClientSession() as session:urls = ["https://httpbin.org/get","https://api.github.com","https://example.com"]tasks = [fetch_page(session, url) for url in urls]results = await asyncio.gather(*tasks)print(f"Got {len(results)} pages")# 执行异步任务
asyncio.run(main())运行结果:
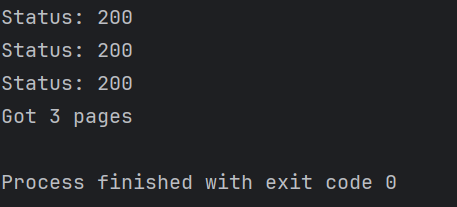
四、常见问题排查
4.1 错误:RuntimeWarning: coroutine was never awaited
解决方案:确保正确使用await调用协程
4.2 如何兼容同步代码?
使用loop.run_in_executor()将同步函数转换为异步
4.3 调试技巧
设置PYTHONASYNCIODEBUG=1环境变量
五、性能对比测试
| 请求数量 | 同步方案(s) | 异步方案(s) |
|---|---|---|
| 10 | 20.3 | 2.1 |
| 100 | 204.7 | 2.4 |
结语
异步编程虽然需要思维方式的转变,但在I/O密集型场景中能带来显著的性能提升。建议从实际项目中的某个模块开始实践,逐步掌握这项重要技能。
下期预告:《Python异步编程进阶:协程池与性能优化》
相关推荐:
-
Asyncio官方文档
-
aiohttp实战指南
原创声明:本文采用 CC BY-NC-SA 4.0 协议,转载请注明出处!