【AI论文】PixelFlow:基于流的像素空间生成模型
摘要:我们提出PixelFlow,这是一系列直接在原始像素空间中运行的图像生成模型,与主流的潜在空间模型形成对比。这种方法通过消除对预训练变分自编码器(VAE)的需求,并使整个模型能够端到端训练,从而简化了图像生成过程。通过高效的级联流建模,PixelFlow在像素空间中实现了可负担的计算成本。在256×256的ImageNet类条件图像生成基准测试中,它取得了1.98的FID(Fréchet Inception Distance)分数。定性的文生图结果展示出,PixelFlow在图像质量、艺术性和语义控制方面均表现出色。我们希望这一新范式能够激发并开拓下一代视觉生成模型的新机遇。代码和模型可在https://github.com/ShoufaChen/PixelFlow获取。Huggingface链接:Paper page,论文链接:2504.07963
研究背景和目的
研究背景
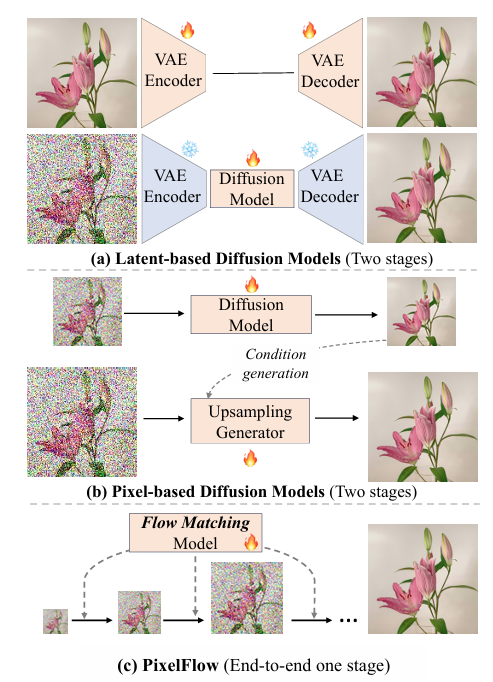
近年来,随着生成模型,特别是扩散模型(Diffusion Models, DMs)的迅速发展,图像生成领域取得了显著进步。传统的潜在空间扩散模型(Latent Space Diffusion Models, LDMs)通过将原始数据压缩到紧凑的潜在空间中,然后使用预训练的变分自编码器(Variational Autoencoders, VAEs)进行表示,大大降低了计算需求并提高了生成效率。然而,这种方法也存在一些局限性。首先,LDMs将VAE和扩散模型分为两个独立的部分进行训练,这阻碍了它们的联合优化,使得整体诊断变得复杂。其次,虽然LDMs在图像生成方面表现出色,但它们依赖于高质量的潜在表示,这在某些情况下可能难以实现。
另一方面,直接在像素空间进行图像生成的模型也受到了广泛关注。然而,由于像素空间中的信息量大且复杂,直接在像素空间进行扩散生成变得计算上不可行,特别是对于高分辨率图像。因此,一些研究采用了级联方法,先生成低分辨率图像,然后使用超分辨率模型将其提升到高分辨率。然而,这种方法仍然需要多个独立训练的网络,限制了端到端优化的可能性。
鉴于上述背景,探索一种既能在像素空间中高效生成高分辨率图像,又能实现端到端优化的新方法显得尤为重要。
研究目的
本文提出PixelFlow,旨在解决直接在像素空间中生成高分辨率图像时面临的计算挑战,并实现端到端的训练优化。PixelFlow通过级联流建模,从低分辨率到高分辨率逐步生成图像,避免了在整个过程中进行全分辨率计算,从而显著降低了计算成本。同时,PixelFlow不使用预训练的VAE,直接对原始像素数据进行操作,实现了端到端的可训练性。本文的主要研究目的包括:
- 提出一种直接在像素空间中运行的图像生成模型PixelFlow,实现高效且端到端的图像生成。
- 通过级联流建模,从低分辨率到高分辨率逐步生成图像,降低计算成本。
- 在类条件图像生成和文生图任务上验证PixelFlow的性能,并与其他先进模型进行比较。
- 探索PixelFlow在图像生成中的潜在应用,为下一代视觉生成模型提供新的思路。
研究方法
模型架构
PixelFlow采用基于Transformer的架构,通过级联流匹配(Flow Matching)算法实现从低分辨率到高分辨率的逐步图像生成。PixelFlow的模型架构主要包括以下几个部分:
- Patchify层:将输入图像转换为一系列令牌序列,以便在Transformer中进行处理。与传统的潜在空间模型不同,PixelFlow直接对原始像素数据进行操作。
- RoPE(Rotary Position Embedding):用于处理不同分辨率的令牌序列,使模型能够适应不同阶段的生成任务。
- 分辨率嵌入:为了区分不同分辨率的特征图,引入了分辨率嵌入,将其与时间步嵌入相结合,并传递给模型。
- Transformer解码器:采用标准的Diffusion Transformer(DiT)架构,通过自回归的方式进行训练,以预测下一个令牌。
级联流建模
PixelFlow通过级联流建模实现从低分辨率到高分辨率的逐步图像生成。在训练过程中,通过下采样和上采样操作构建不同分辨率的样本,并在这些样本之间进行插值,以构建训练示例。模型被训练来预测从中间样本到真实数据样本的速度,从而指导生成过程。在推理过程中,从最低分辨率的纯高斯噪声开始,逐步去噪并上采样图像,直到达到目标分辨率。
训练与推理
在训练过程中,PixelFlow从所有分辨率阶段均匀采样训练示例,并使用序列打包技术在一个小批量中联合训练不同分辨率的样本,以提高效率和可扩展性。在推理过程中,PixelFlow采用标准的流基采样方法,使用欧拉离散采样器或Dopri5求解器,根据所需的速度和准确性权衡进行选择。为了确保不同尺度之间的平滑过渡,还采用了重噪声策略来减轻跳跃点问题。
研究结果
模型性能
在ImageNet 256×256类条件图像生成基准测试上,PixelFlow取得了1.98的FID分数,与先进的潜在空间模型相比具有竞争力。此外,在文生图任务上,PixelFlow在GenEval、T2I-CompBench和DPG-Bench等基准测试上也表现出色,证明了其在生成高质量图像方面的能力。
定性分析
定性结果显示,PixelFlow能够生成具有高质量、艺术性和语义控制的图像。特别是在文生图任务中,PixelFlow能够准确地捕捉复杂文本描述中的关键视觉元素和它们之间的关系,生成与文本高度一致的图像。
消融研究
消融研究表明,级联流建模和端到端训练对于PixelFlow的性能至关重要。通过减少起始序列长度、增加推理步骤数和使用更高级的ODE求解器,可以进一步提高PixelFlow的生成质量。此外,分类器自由引导(CFG)策略的使用也对PixelFlow的性能产生了显著影响。
研究局限
尽管PixelFlow在图像生成方面取得了显著成果,但仍存在一些局限性:
- 计算成本:尽管PixelFlow通过级联流建模显著降低了计算成本,但在最后一个阶段仍然需要进行全分辨率计算,这占据了总推理时间的约80%。
- 训练收敛速度:随着序列长度的增加,PixelFlow的训练收敛速度会变慢。
- 模型扩展性:PixelFlow的模型扩展性尚未得到充分验证,特别是在处理更高分辨率的图像时。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
- 优化计算成本:探索更高效的算法和硬件加速技术,以进一步降低PixelFlow的计算成本,特别是在最后一个阶段的全分辨率计算中。
- 提高训练效率:研究如何加速PixelFlow的训练过程,特别是在处理长序列时。这可能包括改进模型架构、优化训练策略或使用更强大的计算资源。
- 扩展模型能力:验证PixelFlow在处理更高分辨率图像时的性能,并探索其在其他视觉生成任务中的应用,如视频生成和图像编辑等。
- 结合潜在空间表示:研究如何将潜在空间表示与PixelFlow相结合,以进一步提高其生成质量和可扩展性。这可能包括在PixelFlow中引入预训练的VAE或使用混合潜在空间和像素空间的方法。
综上所述,PixelFlow作为一种直接在像素空间中运行的图像生成模型,通过级联流建模和端到端训练实现了高效且高质量的图像生成。未来的研究将进一步优化PixelFlow的性能和扩展性,推动其在视觉生成领域的应用和发展。