【HDFS入门】HDFS核心组件DataNode详解:角色职责、存储机制与健康管理
目录
1 DataNode的角色定位
2 DataNode的核心职责
2.1 数据块管理
2.2 与NameNode的协作
3 DataNode的存储机制
3.1 数据存储目录结构
3.2 数据块文件组织
4 DataNode的工作流程
4.1 数据写入流程
4.2 数据读取流程
5 DataNode的健康管理
5.1 心跳机制(Heartbeat)
5.2 块汇报(BlockReport)
5.3 故障检测与恢复
5.4 磁盘健康管理
5.5 运维命令与监控
6 DataNode的配置优化
6.1 关键配置参数
6.2 多目录配置策略
7 常见问题处理
7.1 磁盘空间不足
7.2 块损坏恢复
8 DataNode与HDFS生态
9 总结
1 DataNode的角色定位
DataNode是HDFS的数据存储工作节点,负责实际的数据块存储与管理。它在HDFS架构中扮演着"体力劳动者"的角色,与NameNode的"管理者"角色形成鲜明对比。
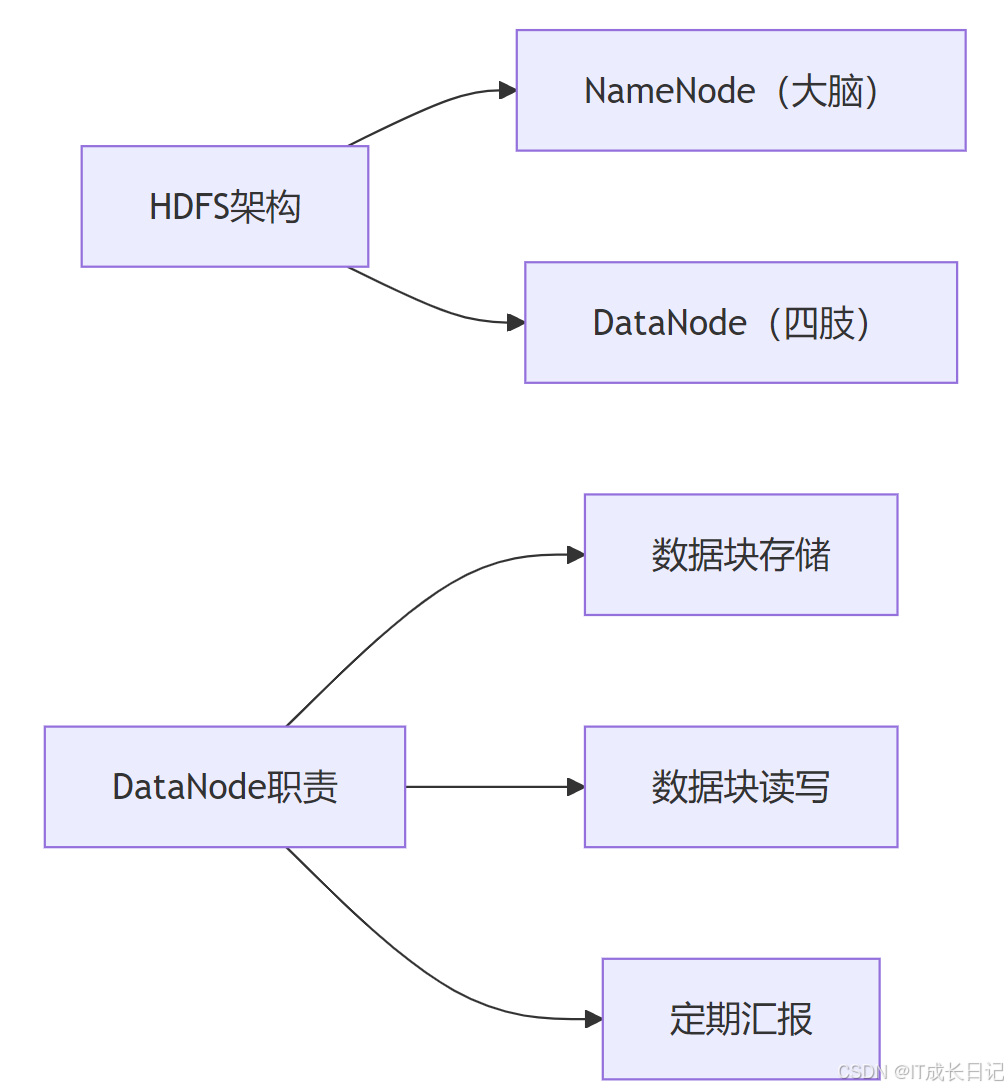
2 DataNode的核心职责
2.1 数据块管理
- 存储实际数据块(默认128MB/块)
- 维护块到文件的映射关系
- 执行数据块的创建、删除和复制
2.2 与NameNode的协作
- 定期心跳汇报(3秒一次)
- 全量块报告(默认6小时一次)
- 增量块报告(块变化时实时汇报)
3 DataNode的存储机制
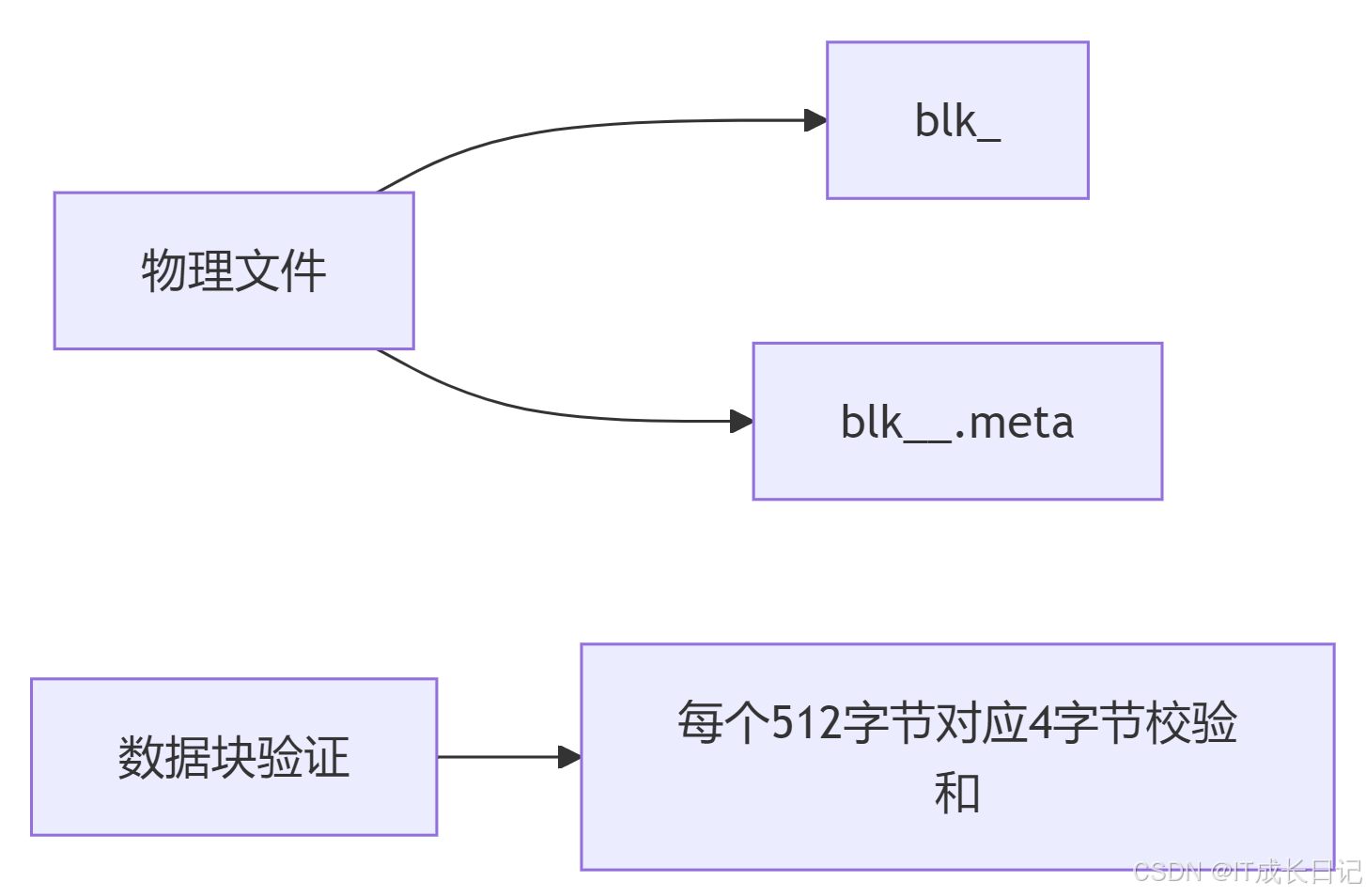
3.1 数据存储目录结构
${dfs.datanode.data.dir}/
├── current/
│ ├── BP-526805057-192.168.10.32-1711980876842/
│ │ ├── current/
│ │ │ ├── VERSION
│ │ │ ├── finalized/
│ │ │ │ ├── subdir0/
│ │ │ │ │ ├── blk_1073741825
│ │ │ │ │ ├── blk_1073741825_1001.meta3.2 数据块文件组织
4 DataNode的工作流程
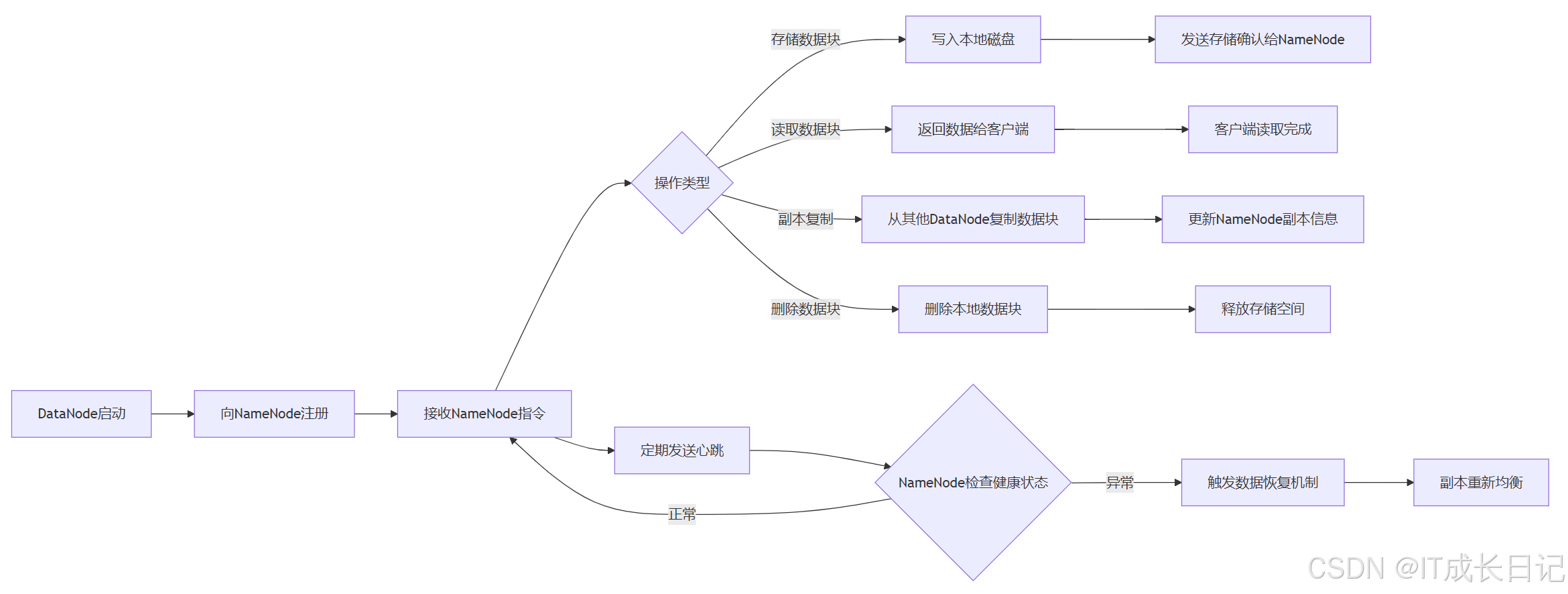
4.1 数据写入流程
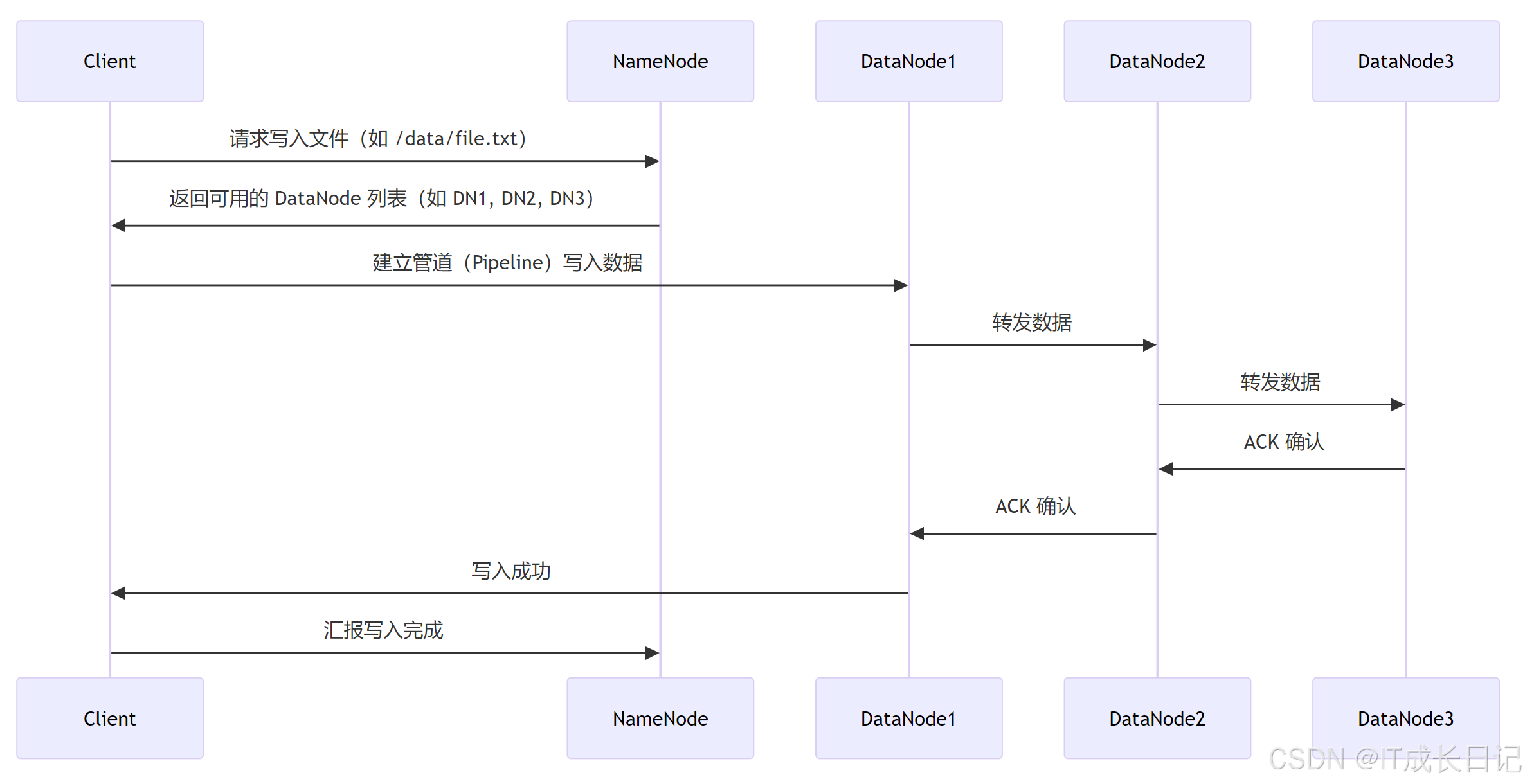
4.2 数据读取流程
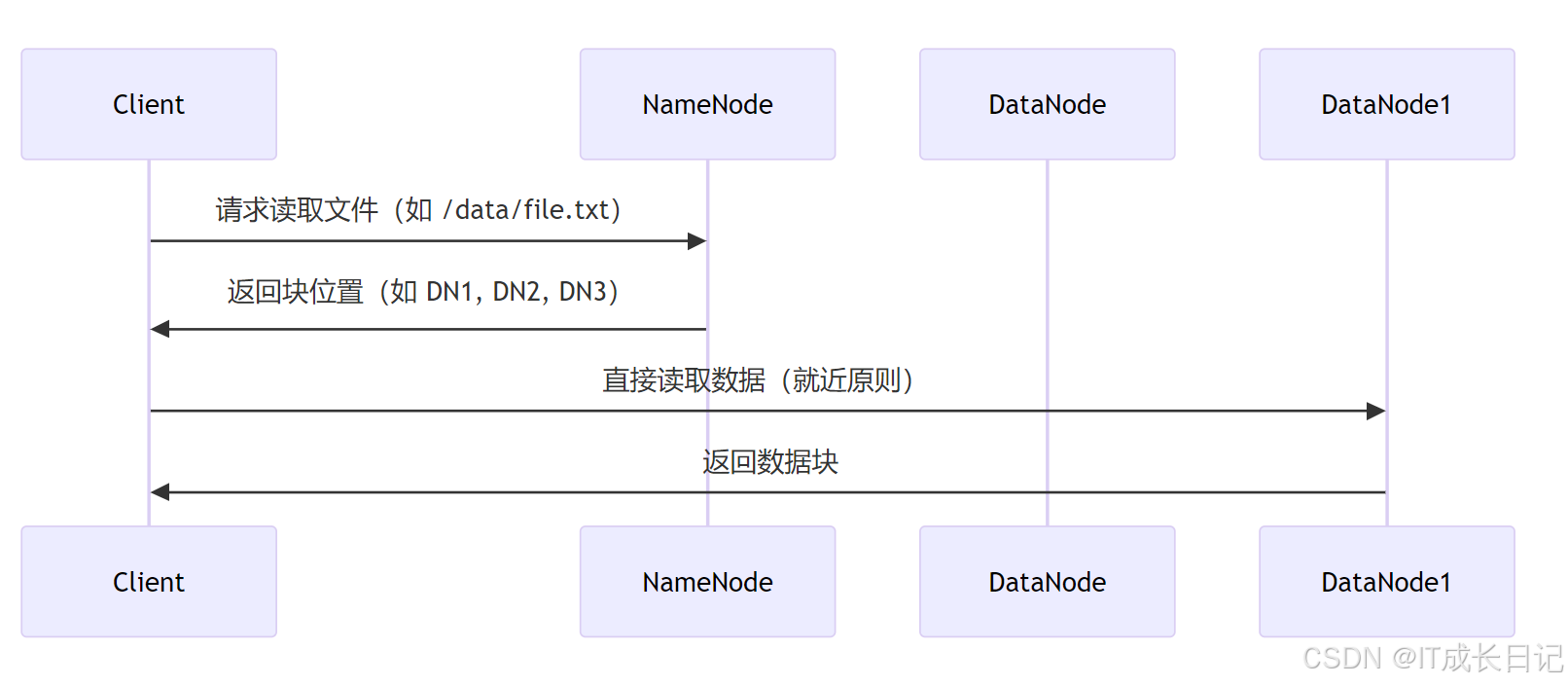
5 DataNode的健康管理
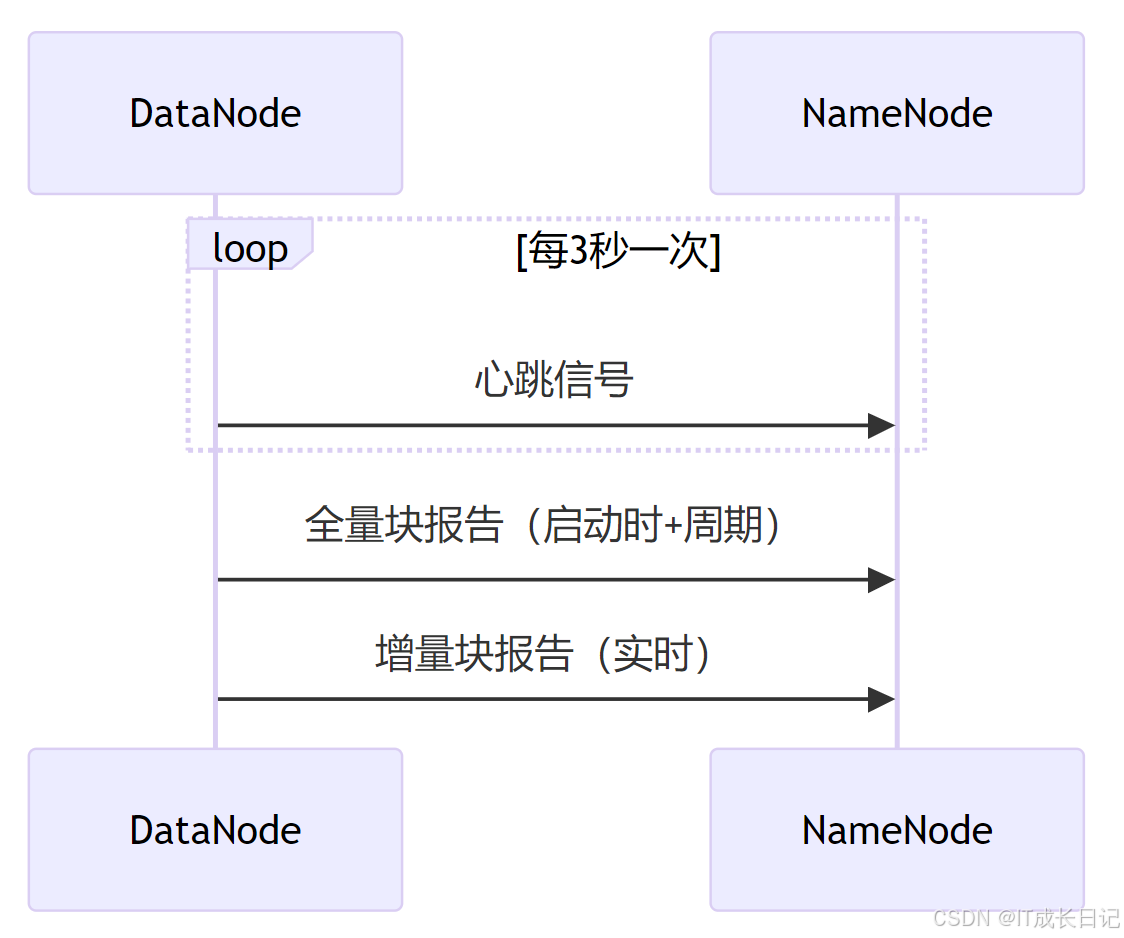
5.1 心跳机制(Heartbeat)
DataNode定期向NameNode发送心跳信号(默认3 秒一次),包含:
- 存储状态剩余磁盘空间、负载情况
- 数据块列表:当前存储的所有Block ID
- 缓存信息:如果启用了缓存
NameNode的响应可能包括:
- 指令删除某些数据块(如副本过多)
- 要求复制缺失的副本(如某些Block副本不足)
- 触发Balancer进行数据均衡
心跳超时判定:
- 如果超过10分钟(默认) 未收到心跳,NameNode会判定该DataNode宕机
- 宕机的DataNode上的数据块会被标记为“不可用”,并触发副本恢复
5.2 块汇报(BlockReport)
DataNode会定期(默认6小时)向NameNode发送完整的BlockReport,包含:
- 所有存储的Block ID
- 每个Block的长度、校验和、状态
作用:
- 帮助NameNode维护块映射表(BlockMap)
- 检测 副本缺失或损坏 的情况
- 确保数据一致性
5.3 故障检测与恢复
- DataNode宕机处理

- NameNode 会从存活的DataNode中选择副本进行重新复制
- 恢复优先级:先恢复高优先级数据(如系统关键文件)
- 数据损坏检测
- 客户端读取数据时,会校验Checksum,如果发现损坏:
- 自动切换到其他副本读取
- 报告NameNode,触发副本修复
- DataNode在磁盘扫描时也会检测损坏块,并上报NameNode
5.4 磁盘健康管理
DataNode会监控本地磁盘状态,避免因磁盘故障导致数据丢失:坏盘检测:
- 通过定期磁盘扫描或操作系统IO错误 检测坏盘
- 如果某个磁盘故障,DataNode会停止向该磁盘写入新数据,并且上报NameNode,迁移受影响的数据块
存储策略:
- 多磁盘存储:DataNode可以配置多个存储目录(dfs.datanode.data.dir),HDFS会轮询写入不同磁盘,避免单盘过载
- 磁盘均衡:HDFS提供diskbalancer工具,优化数据分布,防止部分磁盘写满
5.5 运维命令与监控
- 关键运维命令
| 命令 | 作用 |
| hdfs dfsadmin -report | 查看 DataNode 状态 |
| hdfs fsck / | 检查数据块健康状态 |
| hdfs dfs -count -q /path | 查看存储配额和剩余空间 |
| hdfs diskbalancer -plan | 执行磁盘均衡 |
- 监控指标
HDFS指标:
- Live Nodes:存活的DataNode数量
- Dead Nodes:宕机的DataNode数量
- Under Replicated Blocks:副本不足的块数
- Corrupt Blocks:损坏的块数
DataNode本地监控:
- 磁盘使用率(df -h)
- 网络流量(iftop/nload)
- 内存和CPU使用率(top/htop)
6 DataNode的配置优化
6.1 关键配置参数
<!-- hdfs-site.xml -->
<property><name>dfs.datanode.data.dir</name><value>/data1/hdfs,/data2/hdfs</value>
</property>
<property><name>dfs.datanode.balance.bandwidthPerSec</name><value>10m</value> <!-- 平衡带宽 -->
</property>6.2 多目录配置策略
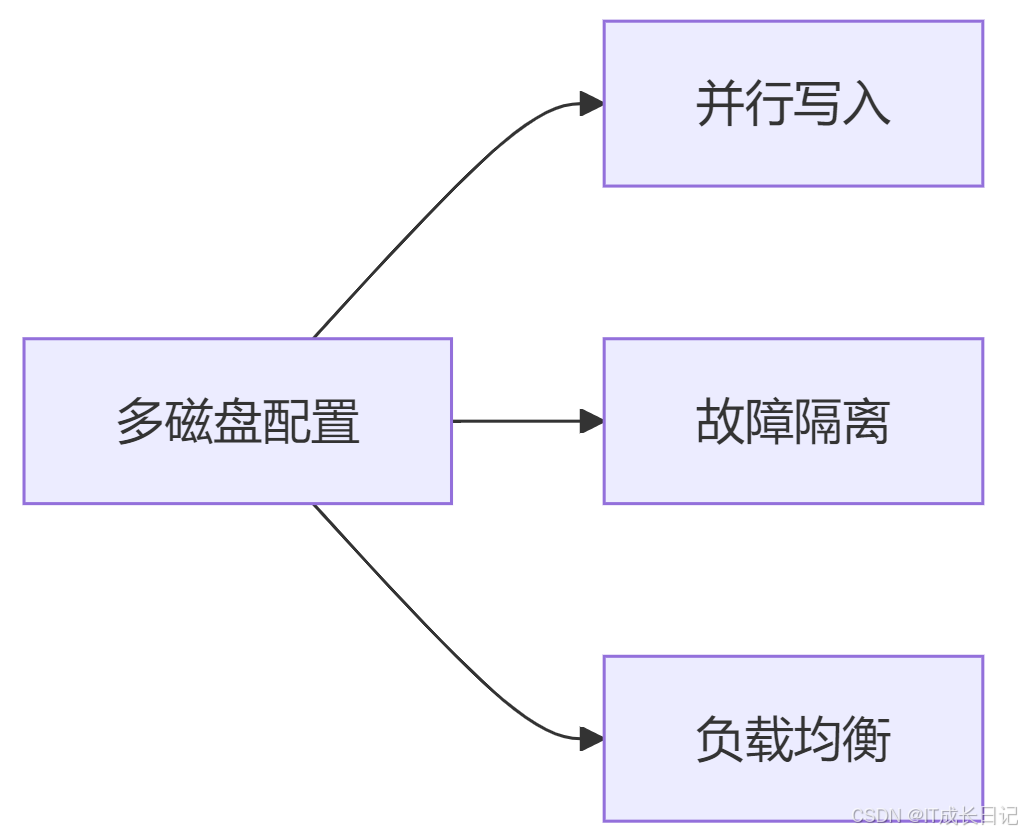
7 常见问题处理
7.1 磁盘空间不足
# 查看各目录使用情况
hdfs dfsadmin -report
# 临时解决方案
hdfs dfsadmin -setSpaceQuota 1T /user/data7.2 块损坏恢复
# 检查损坏块
hdfs fsck / -list-corruptfileblocks
# 删除损坏块
hdfs fsck / -delete8 DataNode与HDFS生态
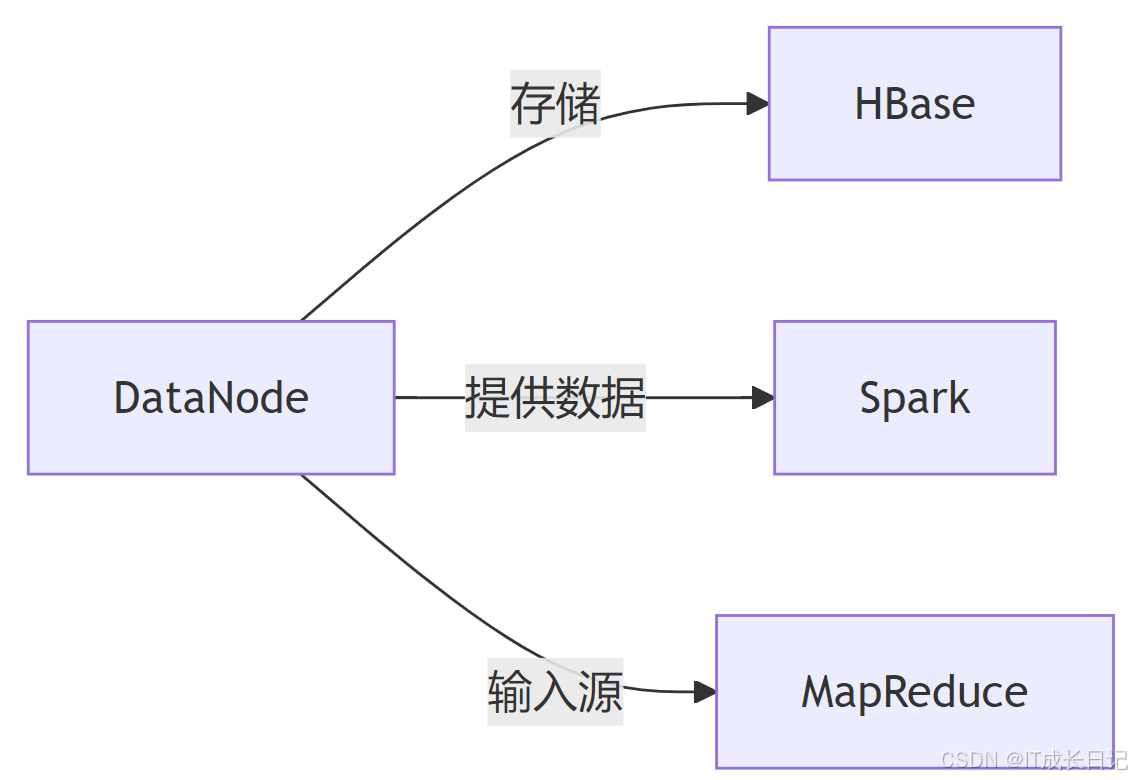
9 总结
DataNode作为HDFS的数据存储基石,其稳定运行直接关系到整个HDFS集群的可靠性。理解DataNode的工作机制,对于优化存储性能、排查数据问题具有重要意义。