数据结构之队列及其应用
队列的实现形式
我们称某个数据序列是一个队列,也就是说这个数据序列必须满足如下的插入或删除数据的规则:
只能从这个数据序列的一端插入,从另一端删除(也可称为先入队的数据元素必须先出队)
队列的实现形式很多,不同的分类方式可以对队列的实现方式进行分类
按照新插入的队列元素是否可以重复使用之前队列中被删除元素的空间分类
顺序队列
建立顺序队列结构必须为其静态分配或动态申请一片连续的存储空间,并设置两个指针进行管理。一个是队头指针front,它指向队头元素;另一个是队尾指针rear
循环队列
在循环队列中,当队列为空时,有front=rear,而当所有队列空间全占满时,也有front=rear。为了区别这两种情况,规定循环队列最多只能有MaxSize-1个队列元素,当循环队列中只剩下一个空存储单元时,队列就已经满了。因此,队列判空的条件时front=rear,而队列判满的条件时front=(rear+1)%MaxSize
按照STL中不同的实现方式进行分类
STL中使用不同的数据结构设计出队列所需要的存取方式,这种设计思想称为适配器模式
适配器模式: 使用一个或多个类中方法来形成新的类
基于deque实现的队列
deque的实现结构:
先有一个中控数组,这个中控数组放入的第一个元素是从中间开始
中控数组中的元素的数据类型是 指针类型,指向一个个的 数据数组
数据数组的长度都是一样的,
如果要进行头插,申请一个数据数组,尽量在这个申请的数据数组的最后几位放置数据
如果要进行头删,只删第一个数组中前面的数据
如果要进行随机访问,求出( i - k ) / N 的结果为σ和 ( i - k ) % N 的结果为Σ
那么先找到中控数组放数据的第σ + 1个数据数组,再找到该数据数组的第∑ + 1个数据
即为第 i 个数据,
注意:其中 k 是第一个数据数组中的元素个数,N是数据数组的长度
deque的优点:面试不常考(手动狗头)
deque的缺点:
1. 从中间插入和删除的效率很低
2. 随机访问的效率很低
基于带头尾指针的单链表实现的队列
Queue对象只管理头尾指针,队列中的节点分为指针域和数据域,指针指向下一个节点
// 链式结构:表示队列
typedef struct QListNode { struct QListNode* _next; QDataType _data;
}QNode; // 队列的结构
typedef struct Queue { QNode* _front; QNode* _rear;
}Queue;此时可以用C语言实现这个队列中的基本操作
QueueNode * BuyQueueNode(QuDataType x){QueueNode * cur = (QueueNode *)malloc(sizeof(QueueNode));cur->_data = x;cur->_next = NULL;return cur;
}void QueueInit(Queue* q){q->_front = NULL;q->_rear = NULL;
}void QueuePush(Queue* q, QuDataType x){QueueNode * cur = BuyQueueNode(x);if (q->_front == NULL) {q->_front = q->_rear = cur;}else{q->_rear->_next = cur;q->_rear = cur;}
}void QueuePop(Queue* q){if (q->_front == NULL) {return;}QueueNode* tmp = q->_front->_next;free(q->_front);q->_front = tmp;
}QuDataType QueueFront(Queue* q){return q->_front->_data;
}QuDataType QueueBack(Queue* q){return q->_rear->_data;
}int QueueEmpty(Queue* q){return q->_front == NULL;
}int QueueSize(Queue* q){QListNode * cur;int count = 0;for (cur = q->_front; cur; cur = cur->_next){count++;}return count;
}void QueueDestory(Queue* q){if (q->_front == NULL){return;}while (q->_front){QueuePop(q);}
}带头尾指针的单链表实现的队列的优点:头删尾插效率高
带头尾指针的单链表实现的队列的缺点:面试可能会跟面试官讨论(因为这种方式是实现队列最容易想到的方式)
基于两个顺序表实现的队列
队列的应用
队列这种FIFO的特性在很多场景下都适用,下面从Linux的调度策略中引出队列应用的场景之一
Linux的调度策略可以大致的分为三种
- SCHED_OTHER : 分时调度策略 ;
- SCHED_FIFO : 实时调度策略 , 先到先服务 ; 进程 一旦占有 CPU , 就一直运行 , 直到 有更高优先级的进程到达 时才放弃 CPU , 或者 进程自己放弃 CPU ;
- SCHED_RR : 实时调度策略 , 时间片轮转 ; 进程分配到 CPU 时间片用于执行 , 该时间片用完后 , 该进程 放到该优先级队列的末尾 , 等待系统重新分配时间片执行 ;
其中SCHED_OTHER就是本文重点讨论的一种调度策略,在操作系统中,每一个CPU都有一个运行队列,运行队列是一个类
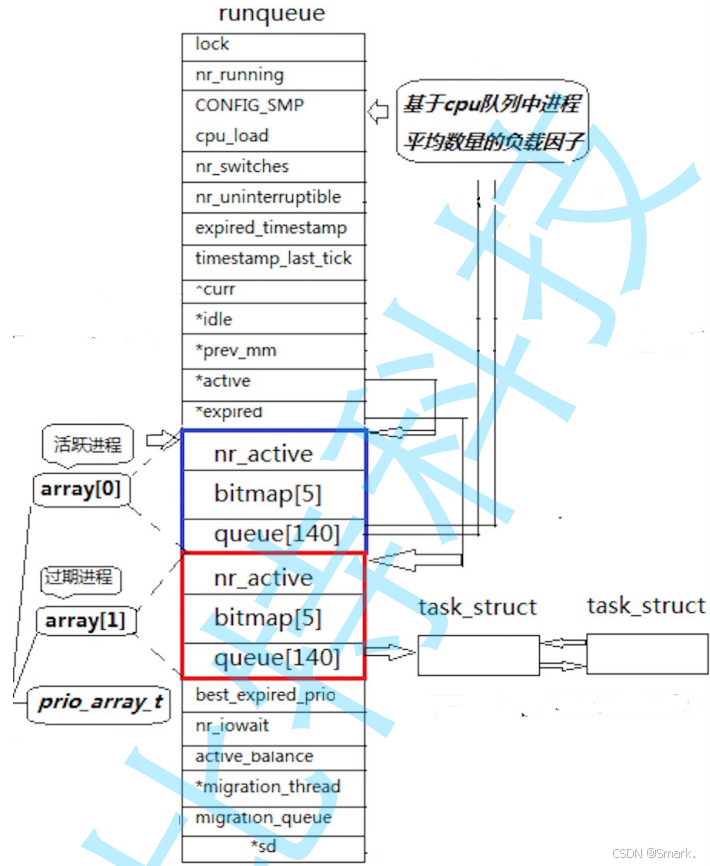
上图中蓝色的区域会维护一个具有140个队列的数组queue,queue这个数组中每个元素的类型都是task_struct *类型的,task_struct * 是Linux中进程PCB的地址,其中queue[100] 到queue[139]这四十个元素正好对应了进程的40个优先级,优先级序号只能从60到99中选取,
具体调度算法可见我的另外一篇博客(挖坑111/24/3/17/3h18m),这里要强调的是:
蓝色区域和红色区域会交替实现任务的出队和任务的进队,CPU的调度也就是找到两个区域内的queue数组的下标,再进一步找到这个下标指针后面跟的那个链表
一开始,active和expired这两个指针会分别指向蓝色区域和红色区域,
首先,蓝色区域中的queue的进程PCB进行调度(即只出不进),通过优先级找到第一个指针不为空的 i 号元素,即queue[i] != nullptr, 将queue[i]指向的链表的第一个进程PCB进行调度,一旦其中的所有进程都被调度结束,即queue[100] 到queue[139]均为空,则将会交换两个指针(如果有必要的话)
其次,在CPU处理上面的进程过程中,红色区域中的queue将会接收产生的新的进程(即只进不出)
此时实现了按照