Spark两种运行模式与部署
1. Spark 的运行模式
部署Spark集群就两种方式,单机模式与集群模式
单机模式就是为了方便开发者调试框架的运行环境。但是生产环境中,一般都是集群部署。
现在Spark目前支持的部署模式:
(1)Local模式:在本地部署单个Spark服务
(2)Standalone模式:Spark自带的任务调度模式
(3)Yarn模式:Spark使用Hadoop的YARN组件进行资源与任务调度。
(4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
如果资源是当前节点提供的就是单机模式,
如果资源是当前多个节点提供的就是集群模式/分布式模式,
如果资源是Yarn管理的就是Yarn部署环境(这个用的多)
如果资源是由Spark自己管理的就是Spark部署环境
2.Spark 的安装
下载地址:
1)官网地址:http://spark.apache.org/
2)文档查看地址:Redirecting…
3)下载地址:https://spark.apache.org/downloads.html
https://archive.apache.org/dist/spark/
2.1 Local 模式
1) 上传本地Spark的安装包并解压
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/这时候我们就把我们的环境安装好了
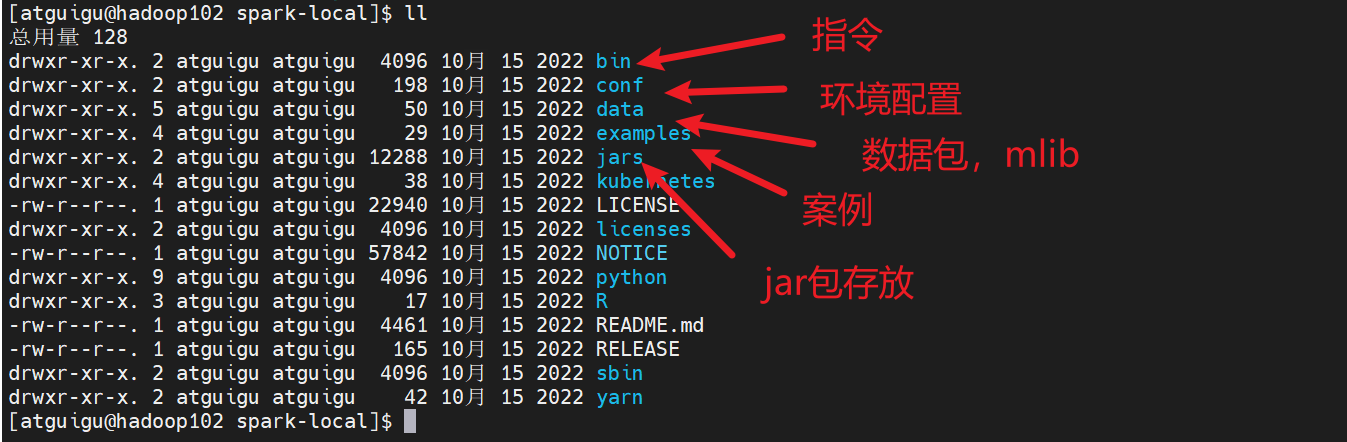
这时候我们要去运行一个案例试一下,看看能不能跑起来
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10解释
--class 表示要执行的主类
--master local[2]
1)local:没有指定线程数,则就是单线程执行
2)local [K]:指定使用K个core来运行计算,比如local[2]就是运行两个2个Core来执行。
3) local[*]: 帮你按照当前最多核心数去运行。
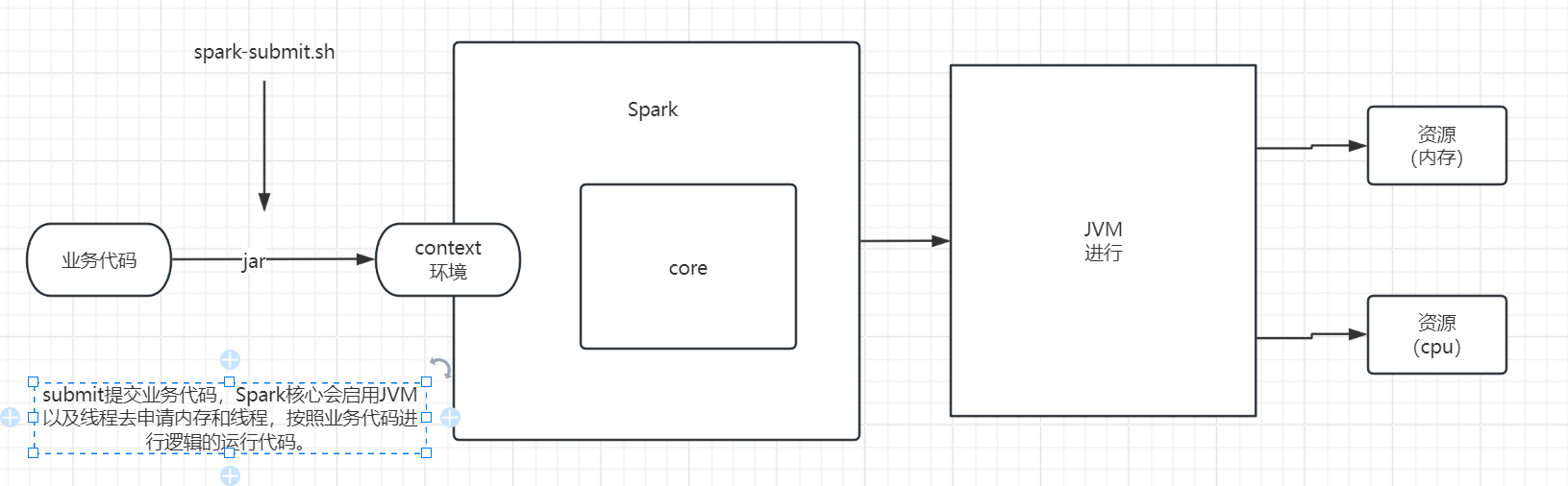 以上过程可以简化为,运行业务代码,启动进程,申请资源,执行计算,终止进程,资源释放。
以上过程可以简化为,运行业务代码,启动进程,申请资源,执行计算,终止进程,资源释放。
我们如何看到这个运行的过程呢?
我们可以在Spark运行的时候,另一个行命令行窗口输入jps查看正在运行的进程。
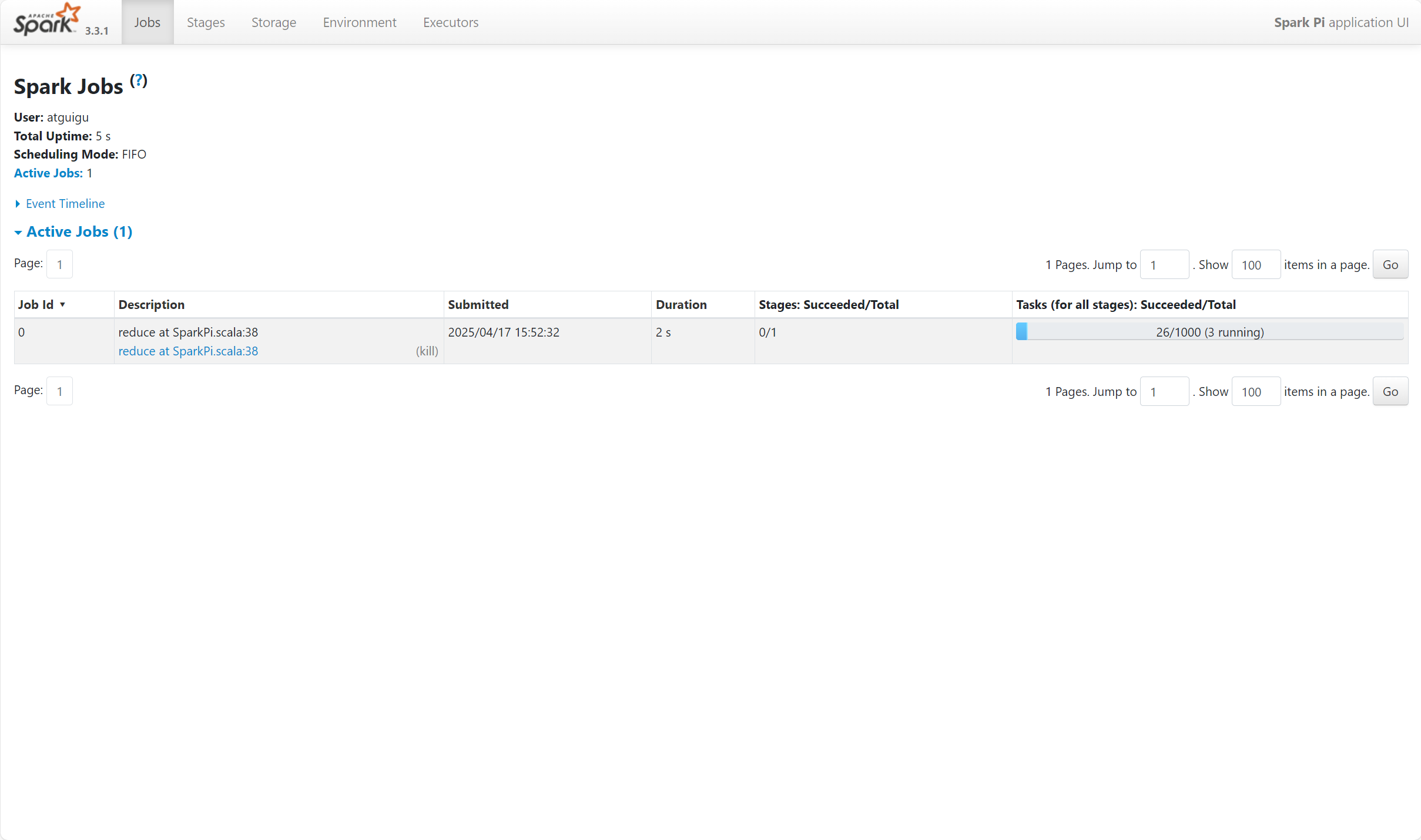
如果我们还想看一些比较详细的信息,可以在【主机名:4040】中查看正在运行的任务,想用这个查看提交的任务,必须保证有spark正在运行。
2.2 Yarn模式
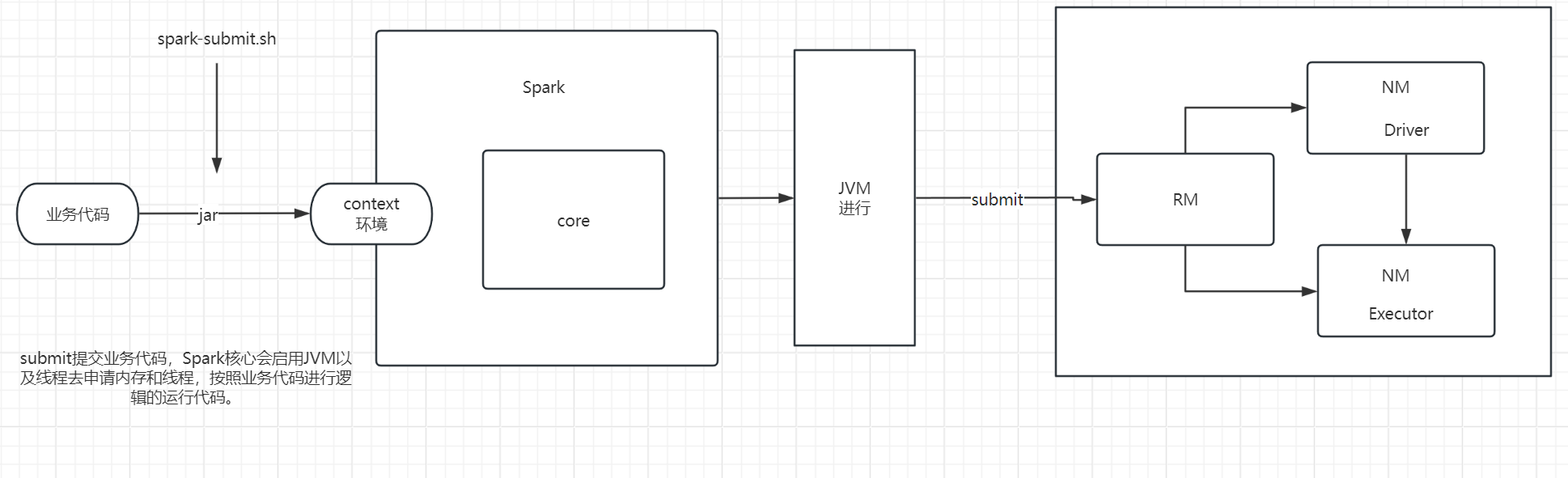
yarn模式就是由本地启动一个进程去提交一个任务给Yarn,然后Yarn分配给资源去运行
部署Yarn模式的步骤
1. 解压Spark
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/2. 进入到/opt/module, 修改目录名 spark-3.3.1-bin-hadoop3 为spark-yarn
3. 修改hadoop配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml,添加如下内容
vim yarn-site.xml<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4. 分发配置文件
xsync /opt/module/hadoop/etc/hadoop/yarn-site.xml5. 修改/opt/module/spark-yarn/conf/spark-env.sh,添加了YARN_CONF_DIR配置,保证就是能找到yarn位置
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop (需要改成自己对应的配置地址)
6. 启动HDFS集群和YARN集群
sbin/start-dfs.sh
sbin/start-yarn.sh7. 然后执行一下上面的那个案例
看看与local模式有什么不同
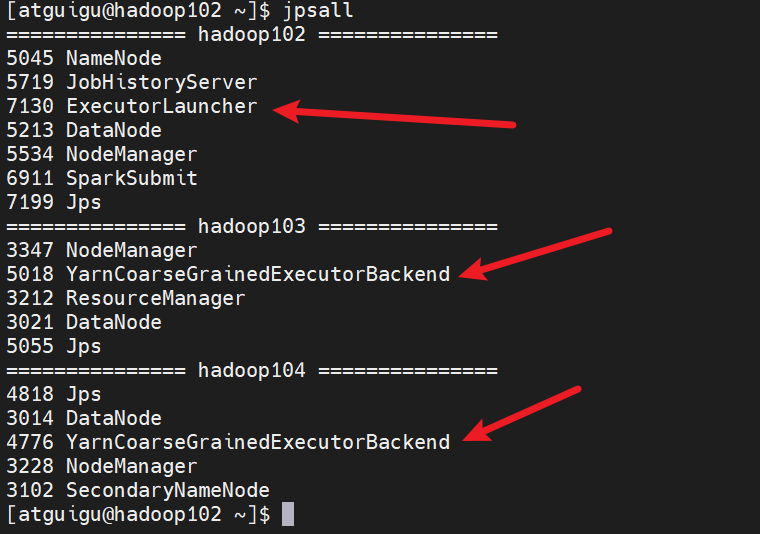
能看到和上图中的driver对应起来了
ExecutorLauncher--》driver
YarnCoarseGrainedExecutorBackend--》executor
2.3 配置历史服务配置
1)修改spark-default.conf.template名称
mv spark-defaults.conf.template spark-defaults.conf2)修改spark-default.conf文件,配置日志存储路径
vim spark-defaults.confspark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
然后去hadoop102:9870里创建一个新的文件directory
3)修改spark-env.sh文件,添加如下配置:
vim spark-env.shexport SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
# 参数1含义:WEBUI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径(读)
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
配置查看历史日志
为了能从Yarn上关联到Spark历史服务器,需要配置spark历史服务器关联路径。
1)修改配置文件/opt/module/spark-yarn/conf/spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
2)重启Spark历史服务
sbin/stop-history-server.sh
sbin/start-history-server.sh 3)提交任务到Yarn执行
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10
4)Web页面查看日志:http://hadoop103:8088/cluster
然后点击页面的history就能跳转到http:hadoop102:18080/