汽车行驶工况特征参数:从“速度曲线”到“驾驶DNA”的硬核解码
作为新能源汽车行业的从业者,你是否曾困惑于这些问题:
- 为什么同一款电动车,不同用户的实际续航差异高达30%?
- 如何精准量化驾驶行为对电池寿命的影响?
- 车企标定的“NEDC续航”与真实路况差距的根源是什么?
这些问题的答案,都藏在汽车行驶工况的核心特征参数中——它们不仅是车辆能耗的“基因密码”,更是连接虚拟仿真与真实场景的“数据桥梁”。本文将从工程实战视角,为你揭开这些参数背后的科学逻辑与行业应用。
一、汽车行驶工况:新能源车的“心电图”
如果把车辆比作人体,行驶工况曲线就是它的“心电图”——速度的每一次波动,都对应着电机、电池、电控系统的“生命体征”。在新能源汽车领域,这张“心电图”的价值远超传统燃油车:
- 电池管理:急加速时电池瞬间放电功率可达200kW以上,直接影响电池温升与寿命。
- 能耗预测:城市拥堵工况(平均速度15km/h)的能耗可能比高速匀速工况(80km/h)高40%。
- 算法优化:自动驾驶决策模块需要预判速度-加速度分布,规划最低能耗路径。
而这一切,都依赖于对七大核心特征参数的深度解析。
二、参数背后的工程密码:从实验室到真实世界
1. 平均速度:能耗模型的“基准线”
- 行业误区:多数人认为平均速度越高能耗越大,但在电动车中,中速区间(40-60km/h)反而可能最优。
- 实战案例:某车企通过分析10万条用户数据发现,当平均速度从30km/h提升至50km/h时,续航增加12%(得益于减少了频繁启停的能量损耗)。
2. 速度-加速度联合分布:驾驶风格的“指纹”
- 数据洞察:激进驾驶(加速度标准差>0.8m/s²)会导致电池峰值温度升高8℃,循环寿命下降15%。
- 技术应用:某BMS系统通过实时监测联合分布,动态调整SOC(电池荷电状态)估算策略,将续航预测误差从7%压缩至2%。
3. 减速段平均减速度:能量回收的“金矿”
- 量化价值:在WLTC工况下,制动能量回收可贡献高达25%的续航提升。
- 算法突破:某车型通过优化减速段识别算法(窗口长度从5秒缩短至0.5秒),能量回收效率提升18%。
三、行业级应用:数据驱动的新能源革命
1. 测试场景库构建
- 国际标准:联合国ECE R137法规要求,自动驾驶测试场景库必须包含速度标准差>15km/h的激进驾驶片段。
- 车企实践:某造车新势力基于20个城市的联合分布数据,构建了全球首个“中国式加塞工况”测试模块。
2. 用户画像与个性化服务
- 数据变现:某车企通过分析用户驾驶参数,推出“续航保险”服务——激进型用户支付更高保费,但可获得免费电池健康检测。
- 生态延伸:充电桩运营商利用平均速度数据,预测用户到达充电站时的剩余电量,动态调整充电价格。
3. 虚拟仿真与数字孪生
- 降本增效:某厂商通过将真实用户的速度标准差(σ=12.3km/h)注入仿真模型,将实车测试里程从100万公里减少至30万公里。
- 技术前沿:特斯拉“影子模式”持续采集全球车主的联合分布数据,用于训练下一代能耗预测神经网络。
四、给从业者的三个行动指南
-
建立数据思维
- 不要只盯着“平均速度”,速度-加速度的协方差矩阵可能隐藏着续航突变的关键信号。
- 推荐工具:Python的Seaborn库可快速绘制联合分布热力图(见示例代码)。
-
拥抱场景化工程
- 将NEDC/WLTC等标准工况与用户真实参数分布对比,找到优化“缺口”。
- 案例参考:某车型在σ_v>20km/h的工况下电机效率骤降,针对性升级后投诉率下降60%。
-
关注参数链式反应
- 速度波动(σ_v)→ 电池充放电频次 → 温度梯度 → 寿命衰减,这是一个需要跨部门协同的系统工程。
五、未来趋势:参数维度的升维战争
当行业还在争论平均速度的计算方法时,头部企业已开始探索:
- 高阶参数:速度分形维度(驾驶波动复杂性)、加速度功率谱密度(能量频域特征)
- 融合参数:速度-坡度-温度联合分布(山地工况建模)
- 动态参数:基于实时交通流的工况参数自适应预测
谁掌握了参数解析的深度,谁就握住了新能源时代的钥匙。
结语
在新能源汽车行业,没有“普通”的数据,只有“尚未挖掘”的金矿。从一条速度曲线中,我们可以解码电池寿命、重塑驾驶体验、甚至重构商业模式。本文仅揭示了冰山一角,后续将带来更多硬核专题:
- 《如何用联合分布破解冬季续航缩水之谜》
- 《基于行驶参数的电池健康度无损检测》
点击关注,开启你的新能源数据进化之旅。
配套资源
以下是汽车行驶工况核心特征参数的硬核解析,包括计算思路、公式及技术要点:
1. 平均速度(Average Speed)
计算思路
- 定义:车辆在测试周期内的总行驶距离与总时间的比值。
- 关键点:需排除停车时间(速度=0的时间段),仅统计车辆实际移动的时间。
公式
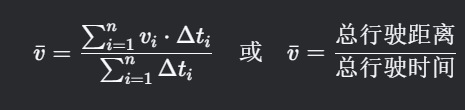
符号说明:
- v_i:第i个时间点的瞬时速度(单位:km/h 或 m/s)
- Delta t_i:第i个时间点的时间间隔(单位:s)
2. 行驶速度分布(Speed Profile)
计算思路
- 定义:速度随时间变化的序列(时间-速度曲线)。
- 关键点:需按固定采样频率(如1Hz)采集速度数据,构建离散时间序列。
公式

技术要点:
- 数据清洗:剔除异常值(如负速度或超物理极限速度)。
- 插值处理:对缺失数据采用线性插值或样条插值。
3. 最大速度与最小速度(Max/Min Speed)
计算思路
- 定义:测试周期内速度的全局最大值和最小值。
- 关键点:需排除瞬态噪声(如传感器误差导致的异常峰值)。
公式

4. 速度标准偏差(Speed Standard Deviation)
计算思路
- 定义:速度序列的离散程度,反映驾驶激烈程度。
- 关键点:使用无偏估计(样本标准差)。
公式
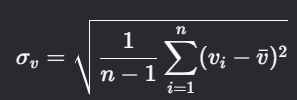
5. 加速度标准偏差(Acceleration Standard Deviation)
计算思路
- 定义:加速度序列的波动性,表征驾驶平稳性。
- 关键点:加速度通过速度差分计算,需平滑处理以减少噪声。
公式
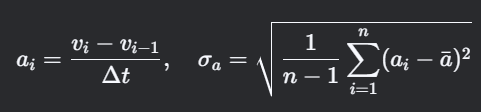
技术要点:
- 加速度计算需采用中心差分法或低通滤波(如Savitzky-Golay滤波器)抑制高频噪声。
6. 减速段平均减速度(Mean Deceleration in Braking Phases)
计算思路
- 定义:所有减速阶段((a < 0))的减速度绝对值均值。
- 关键点:需识别连续减速区间(如加速度连续负值超过阈值)。
公式
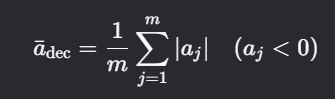
技术要点:
- 减速段识别算法:滑动窗口检测连续负加速度区间(如窗口长度≥3秒)。
7. 速度-加速度联合分布(Speed-Acceleration Joint Distribution)
计算思路
- 定义:速度与加速度的二维概率密度分布,反映驾驶工况的动力学特征。
- 关键点:分箱统计或核密度估计(KDE)。
公式
分箱统计法:
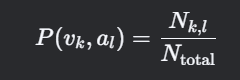
- N_k,l:速度落在第k个区间且加速度落在第l个区间的样本数。
- 区间划分:速度按10 km/h间隔分箱,加速度按0.1 m/s²间隔分箱。
核密度估计(KDE):
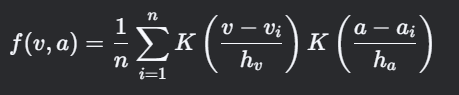
- K:高斯核函数
- h_v, h_a:带宽参数(通过Silverman法则优化)。
关键计算流程总结
- 数据预处理:
- 剔除异常值,插值补全缺失数据。
- 对速度序列进行平滑滤波(如移动平均)。
- 基础参数计算:
- 平均速度、极值、标准差。
- 加速度计算:
- 差分法或滤波法生成加速度序列。
- 减速段提取:
- 滑动窗口识别连续负加速度区间。
- 联合分布建模:
- 分箱统计或核密度估计生成二维分布矩阵。
示例代码(Python)
import numpy as np
import pandas as pd
from scipy import stats# 1. 加载速度时间序列数据(示例)
time = np.arange(0, 3600, 1) # 1小时数据,1Hz采样
speed = np.random.uniform(0, 120, 3600) # 模拟速度数据(0-120 km/h)# 2. 计算平均速度(排除停车时间)
moving_mask = speed > 0 # 排除速度为0的时间
avg_speed = np.mean(speed[moving_mask])# 3. 计算加速度(中心差分法)
dt = 1 # 1秒间隔
accel = np.gradient(speed[moving_mask], dt)# 4. 减速段平均减速度
decel_mask = accel < 0
mean_decel = np.mean(np.abs(accel[decel_mask])) if np.any(decel_mask) else 0# 5. 速度-加速度联合分布(分箱统计)
v_bins = np.arange(0, 130, 10) # 速度分箱(0-120 km/h,10 km/h间隔)
a_bins = np.arange(-3, 3.1, 0.1) # 加速度分箱(-3~3 m/s²,0.1间隔)
joint_dist, v_edges, a_edges = np.histogram2d(speed[moving_mask], accel, bins=[v_bins, a_bins], density=True
)
应用场景
- 能耗建模:联合分布用于构建车辆能耗MAP图。
- 驾驶风格分析:标准差参数量化驾驶激进程度。
- 测试工况设计:基于统计特征复现实路驾驶循环(如WLTC、NEDC)。
通过上述方法,可全面量化汽车行驶工况的动力学特征,支撑新能源汽车的算法开发与性能验证。