文献总结:NIPS2023——车路协同自动驾驶感知中的时间对齐(FFNet)
FFNet
- 一、文献基本信息
- 二、背景介绍
- 三、相关研究
- 1. 以自车为中心的3D目标检测
- 2. 车路协同3D目标检测
- 3. 特征流
- 四、FFNet网络架构
- 1. 车路协同3D目标检测任务定义
- 2. 特征流网络
- 2.1 特征流生成
- 2.2 压缩、传输与解压缩
- 2.3 车辆传感器数据与基础设施特征流融合
- 3. 特征流网络训练流程
- 五、实验部分
- 1. 实验设置
- 2. 实验比较
- 3. 消融实验
- 六、总结
一、文献基本信息
| 文章标题 | Flow-Based feature fusion for vehicle-infrastructure cooperative 3d object detection |
|---|---|
| 会议 | NIPS(NeurIPS) |
| 作者 | Haibo Yu;Yingjuan Tang;Enze Xie;Jilei Mao;Ping Luo;Zaiqing Nie |
| 单位 | The University of Hongkong;Institute for AI Industry Research (AIR), Tsinghua University;Beijing Institute of Technology;Shanghai AI Laboratory |
| 日期 | 2023年11月3日 |
| 论文链接 | https://arxiv.org/abs/2311.01682 |
| 代码链接 | https://github.com/haibao-yu/FFNet-VIC3D |
摘要:使用自车和基础设施传感器的协同数据可以显著提升自动驾驶感知能力。然而,时间同步的不确定性和通信限制导致了融合无法对齐的问题,这限制了路侧数据的使用。为了解决上述问题,作者提出了一个新的协同检测框架——特征流网络(FFNet)特征流网络是一个基于流的特征融合网络,可以用特征预测模块来预测未来时刻的特征并帮助更好地同步车辆和路侧传感器特征。相比从静态图像传输提取特征,FFNet传输了时间一致的连续路侧图像特征流。此外,作者引入了一种自注意力训练方法,可以使FFNet根据基础设施传感器图像的序列,生成带有未来时刻预测能力的特征流。在DAIR-V2X数据集上的实验结果表明,FFNet比现有的协同检测方法好,且与原始数据相比仅仅需要1/100的传输成本。 |
文章整体框架:

二、背景介绍
3D目标检测是自动驾驶中的重要任务,其提供了周围障碍物的位置和类别等重要信息。传统3D目标检测方法依赖于自车传感器数据,这限制了感知范围,并且在长距离检测和盲点检测中表现不好,带来了许多安全隐患。为了解决这些挑战,车路协同自动驾驶范式得到了更多关注,尤其是基于相机和激光雷达的路侧传感器,这些传感器比自车安装的位置更高,提供了更广泛的感知视野。通过补充额外的路侧传感器数据,可能会获得更有意义的信息,并提高自动驾驶感知能力。在这篇文章中,作者聚焦于解决车路协同3D目标检测任务(vehicle-infrastructure cooperative 3D, VIC3d),来增强面对挑战性交通场景时,自动驾驶系统的安全性和性能。
车路协同目标检测问题可以定义为通信带宽限制下的多传感器感知问题,目前有两个主要的挑战:
- 基础设施数据可能被不同的车辆接收,自车接收的数据和路侧传感器的数据存在同步时间的不确定性(时延不是固定的)
- 车端和路侧设备的通信带宽是有限的
为了解决上述的两个挑战,现有的主要融合框架包括三个:
| 融合类型 | 说明 |
|---|---|
| 前融合(early fusion) | 传输原始数据进行融合 |
| 后融合(late fusion) | 传输检测结果进行融合 |
| 中间融合(middle fusion) | 传输提取特征进行融合 |
因为中间融合的方法相较于前融合降低了通信带宽的限制,相较于后融合有效提升了融合的精度,所以大部分学者采用的是中间融合的方案。然而,现有的中间融合方案忽视了时间同步的挑战,导致了时间融合的不对齐。因此,作者提出了FFNet来解决该问题,本文的贡献如下:
- 本文提出了一个基于流的特征融合框架来解决车路协同目标检测任务。FFNet传输特征流来为特征融合生成对齐特征,提供了一个简单且统一的操作来融合有价值的信息
- 文本引入了自监督训练方法来训练特征流生成器,使得具有特征预测能力的FFNet可以减少不同延迟的带来的融合错误。
- 本文在
DAIR-V2X数据集上对FFNet进行了验证,证明了其高的检测精度和较低的传输成本。
三、相关研究
1. 以自车为中心的3D目标检测
3D目标检测是以自车为中心的自动驾驶的基本任务。自车为中心的3D目标检测基于传感器的类别可以分为3类:基于相机的方法,基于激光雷达的方法和基于多传感器融合的方法。
- 基于相机的方法:例如FCOS3D直接从一张图像来检测3D边界框;或BEVFormer和 M 2 B E V M^2BEV M2BEV将3D图像投影到BEV视图,来实现多相机联合的3D目标检测。
- 基于激光雷达的方法:例如VoxelNet, SECOND, 和PointPillars将激光雷达点云分成体素(voxels)或圆柱(pillars),并从中提取特征
- 基于多传感器融合的方法:同时利用相机和点云数据,采用基于点云的融合、基于相机的融合或基于公共空间的融合三类,来进行多传感器融合
与上述的方法不同,本文提出的方法以点云作为输入,利用路侧和车辆传感器的数据来克服单车视角的目标检测。
2. 车路协同3D目标检测
利用道路基础设施的信息进行目标检测,得到了工业界和学术界的广泛关注。作者总结了一些不同视角的方法:
- 车车视角:关注于车车协同的的算法用V2VNet,DiscoNet,StarNet和SyncNet,常用的数据集包括V2X-Sim、OPV2V、V2V4Real
- 路侧视角:Rope3D和BEVHeight、A9=Dataset
- 车路协同:V2X-Seq
现在的方法通过传输特征图或查询(queries)来实现协同检测,没有考虑时间同步的影响。在本文中,作者提出的基于流的融合框架来解决时间同步的问题,并且用简单统一的方法来降低传输损失。本研究和SyncNet有本质的区别(SyncNet通过传输共同特征并融合每一帧特征来消除时延)
3. 特征流
流是一个来源于数学的概念,表示着点随时间变化的运动。这已经被成功地运用到很多计算机视觉任务中,例如:光流、场景流和视频识别。作为一个从光流中拓展的概念,特征流描述了特征图随时间的变化,被广泛用于不同的视频理解任务。朱等人1提出了一种以流为引导的特征融合来提升视频检测准确率。本文中,作者引入特征流来进行特征预测,从而克服车路协同目标检测的时间同步问题。
四、FFNet网络架构
1. 车路协同3D目标检测任务定义
问题定义: 车路协同目标检测是通过利用路侧和车辆传感器数据在有限制的无线通信环境下定位和识别周围目标。本文以点云输入作为目标,车路协同的输入包括以下两个部分:
- 通过自车传感器在时间 t v t_{v} tv时捕捉到的点云 P v ( t v ) P_{v}(t_{v}) Pv(tv),相对位姿为 M v ( t v ) M_{v}(t_{v}) Mv(tv), P v ( ⋅ ) P_{v}\left( \cdot \right) Pv(⋅)表示自车激光雷达的捕捉函数。
- 通过路侧基础设施传感器在时间 t i t_{i} ti时刻捕捉的点云 P i ( t i ) P_{i}(t_{i}) Pi(ti),相对位姿为 M i ( t i ) M_{i}(t_{i}) Mi(ti), P i ( ⋅ ) P_{i}\left( \cdot \right) Pi(⋅)表示路侧激光雷达的捕捉函数。路侧传感器捕捉到的历史帧也可以用来做协同检测。
⭐由于从路侧到车端的长距离传输需要大量的传输时间,因此时间 t i t_{i} ti是要早于时间 t v t_{v} tv的。
⭐此外,因为路侧设备的传输数据可以被不同的自动驾驶车路接收,所以延误 ( t v − t i ) (t_{v}-t_{i}) (tv−ti)是不确定的。
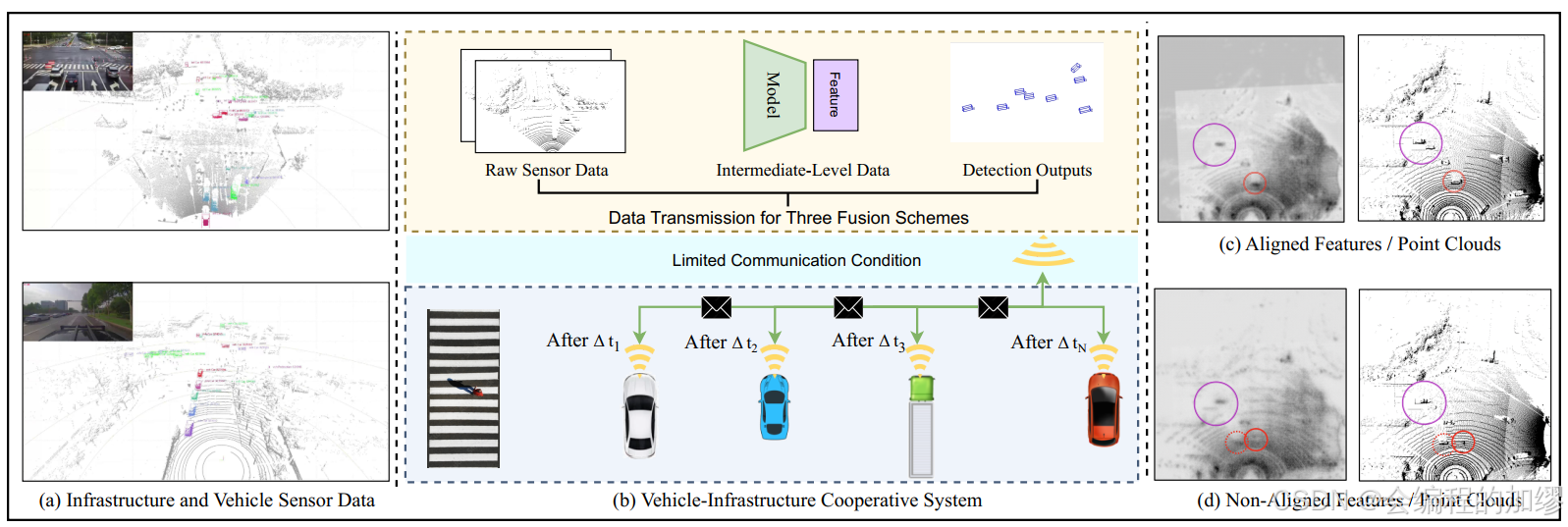
Challenges: 相较于单车自动驾驶,车路协同最大的挑战便是时间同步和传输成本。
Evaluation Metrics:
⚡平均精度的均值(mean Average Precision, mAP): 通过计算每个类别的平均精度(AP),然后对所有类别的AP取平均值
⚡平均比特(Average Byte, AB): 这个概念是作者自己在他的另一篇论文中定义的(DAIR-V2X),表示每次传输的数据量大小。
2. 特征流网络
特征流网络主要包括三个模块:
1️⃣特征流生成(路侧传感器);
2️⃣特征流的压缩、传输和解压(路侧);
3️⃣将特征流与车辆特征融合,得到检测结果;
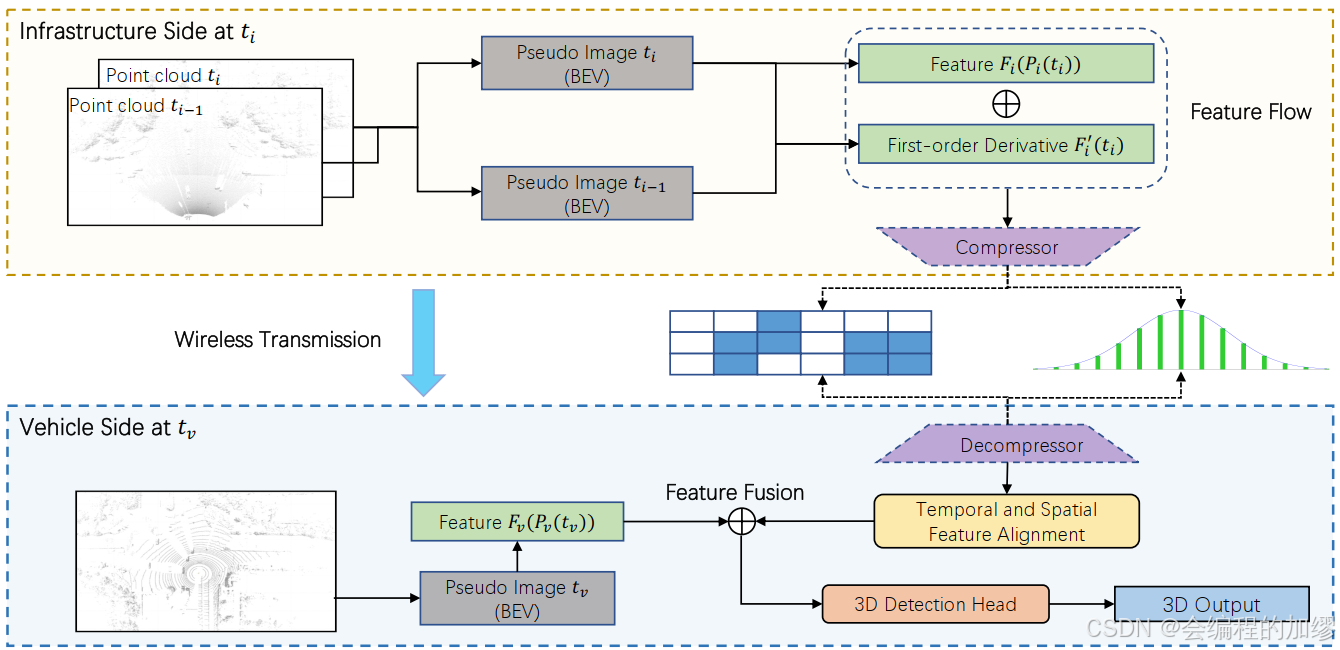
2.1 特征流生成
⭐ 作者将特征流作为一个预测函数,来描述路侧传感器获得的特征随时间的改变。具体来说,作者采用了当前的点云帧 P i ( t i ) Pi(t_{i}) Pi(ti)和路侧特征提取器 F i ( ⋅ ) F_{i}(\cdot) Fi(⋅),来表征未来时刻t的特征流:
F i ( t ) = F i ( P i ( t i ) ) , t ≥ t i F_{i}(t)=F_{i}(P_{i}(t_{i})),\ \ \ \ \ \ \ \ t\ge t_{i} Fi(t)=Fi(Pi(ti)), t≥ti
与之前传输前一帧特征 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi(Pi(ti))的方法相比,特征流可以直接预测车辆传感器数据在 t v t_{v} tv时刻的对齐特征。(⚡所以采用 F i ( t ) F_{i}(t) Fi(t),这里的 t t t可以是车辆数据的时间 t v t_{v} tv)
❓ 公式中那里到底是 t i t_{i} ti还是 t t t啊?
为了将特征流应用到传输和协同检测中,两个问题需要被解决:
1️⃣ 表达和传输随时间变化的连续特征流;
2️⃣ 使特征流具有预测能力;
考虑到 t v → t i t_{v}\to t_{i} tv→ti的时间间隔特别短,所以作者采用最简单的一阶导数来表征连续特征流随时间的变化,如下式:
F i ~ ( t i + Δ t ) ≈ F i ( P i ( t i ) ) + Δ t ∗ F i ′ ~ ( t i ) \tilde{F_{i}}(t_i+\Delta t) \approx F_{i}(P_{i}(t_{i})) + \Delta t * \tilde{F'_{i}}(t_{i}) Fi~(ti+Δt)≈Fi(Pi(ti))+Δt∗Fi′~(ti)
其中, F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′~(ti)表示特征流的一阶导数, Δ t \Delta t Δt表示未来的短时间。因此,我们仅需要获得特征 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi(Pi(ti))和特征流的一阶导数 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′~(ti)就可以估计特征流 F i ( t ) F_{i}(t) Fi(t)。当一个自动驾驶汽车接收到了 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi(Pi(ti))和 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′~(ti)在不确定的延误之后,本文能用最小的计算量来生成对齐车辆传感器数据的基础设施特征(因为它仅需要线性计算)。为了能使特征流具备预测能力,本文从基础设施历史帧 I i ( t i − N + 1 ) , … , I i ( t i − 1 ) , I i ( t i ) I_{i}(t_{i}-N+1), \dots,I_{i}(t_{i}-1),I_{i}(t_{i}) Ii(ti−N+1),…,Ii(ti−1),Ii(ti),用网络提取特征流 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′~(ti)的一阶导数。在本篇文章中, N N N为2,即表示两个连续的基础设施帧 P i ( t i − 1 ) P_{i}(t_{i}-1) Pi(ti−1)和 P i ( t i ) P_{i}(t_{i}) Pi(ti)
❓ 这么设置下来,与BEVFormer中的有何区别?
特别地,我们首先用Pillar Feature Net将两个连续的点云转换为BEV视图的两个伪图像(pseudo-images),每一帧的尺寸为[384, 288, 288] 。然后,我们拼接两个BEV伪图像为尺寸[768, 288, 288],将拼接后的伪图像输入到一个13层的主干网络和一个3层特征金字塔网络(FPN)中,像SECOND一样,生成估计的一阶导数 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′~(ti),其尺寸为[364, 288, 288]。(作者在附录中写了每一个网络的具体尺寸)
2.2 压缩、传输与解压缩
压缩:为了减少冗余信息,减少传输成本,作者采用了两个压缩器(compressors)来压缩特征 F i ( P i ( t i ) ) F_{i}(P_{i}(t_{i})) Fi(Pi(ti))和导数 F i ′ ~ ( t i ) \tilde{F'_{i}}(t_{i}) Fi′~(ti),在每个压缩器中利用三个Conv-Bn-ReLu块将特征尺寸从[384, 288, 288]压缩到[12, 36, 36]。本文在广播(broadcast)压缩特征流来使其与路侧的时间戳和标定文件相关联。同时,作者还采用注意力蒙版(attention mask)和量化技术(quantization techniques)进行进一步压缩,使特征关注感兴趣的区域。
解压缩:在接收到车辆发送的特征流后,车辆端采用两个解压器,每个解压器采用三个Deconv-Bn-ReLU块组成,将压缩的特征和一阶导变为原始尺寸[384, 288, 288]
2.3 车辆传感器数据与基础设施特征流融合
作者用特征流来预测基础设施在特征 t v t_{v} tv的特征,以对齐车辆的特征,如下:
F ~ i ( t v ) ≈ F i ( P i ( t i ) ) + ( t v − t i ) ∗ F i ′ ~ ( t i ) \tilde{F}_{i}(t_{v}) \approx F_{i}(P_{i}(t_{i}))+(t_{v}-t_{i})*\tilde{F'_{i}}(t_{i}) F~i(tv)≈Fi(Pi(ti))+(tv−ti)∗Fi′~(ti)
F i ~ ( t v ) \tilde{F_{i}}(t_{v}) Fi~(tv)表示特征流预测的路侧传感器在 t v t_{v} tv时刻的特征,这种线性的方法有效地补偿了不确定延迟,且仅需要很小的计算。随后,预测的路侧传感器在 t v t_{v} tv时刻的特征利用对应的标定文件,转换到车辆坐标系。既然得到了路侧传感器和车载传感器在 t v t_{v} tv时刻的BEV特征图,且他们都在车辆坐标系下,那么就可以将他们的特征进行融合。(如下图所示)在车辆兴趣区域外的特征都从车辆基础设施特征中删除,空的位置用0来填充。将车辆和路侧的设施进行拼接,并用Conv-Bn-Relu块来融合拼接后的特征。
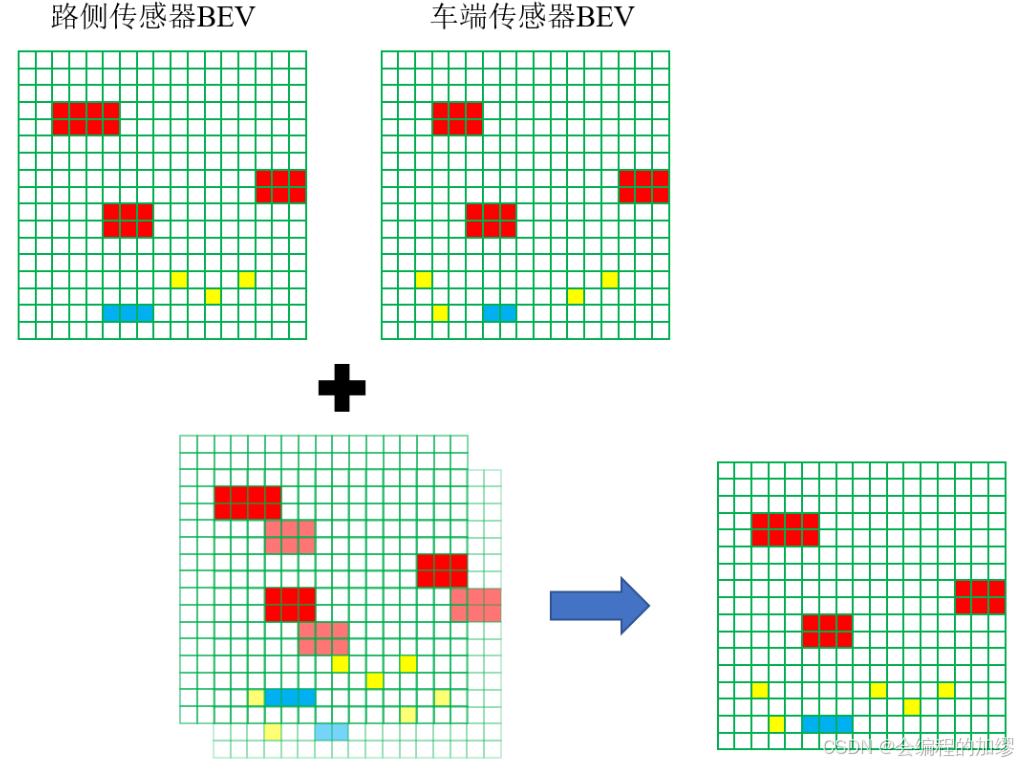
最后,将融合特征输入到3D检测头中,生成更加准确的位置和识别结果。
3. 特征流网络训练流程
FFNet的训练流程包括两个阶段:
1️⃣ 用端到端的方式训练基础的融合框架(不考虑延迟):这一阶段的目标是使FFNet融合基础设施特征和车辆特征来增强检测性能。具体来说,作者利用从车端和路侧获得的协同数据和标注数据来训练FFNet。
2️⃣ 用自监督训练来训练特征流生成器:通过基础设施序列帧的时间关联,来利用自监督学习来训练特征生成器。这个想法是通过邻近的基础设施帧来构造真值,且不需要额外的手动标注。具体而言,作者生成了训练特征对 D = { d t i , k = ( P i ( t i − 1 ) , P i ( i ) , P i ( t i + k ) ) } D=\{d_{t_{i},k}=(P_{i}(t_{i}-1),P_{i}(i),P_{i}(t_{i}+k))\} D={dti,k=(Pi(ti−1),Pi(i),Pi(ti+k))},其中, P i ( t i − 1 ) P_{i}(t_{i}-1) Pi(ti−1) 和 P i ( i ) P_{i}(i) Pi(i)是两个连续的基础设施点云帧, P i ( t i + k ) ) P_{i}(t_{i}+k)) Pi(ti+k))是 P i ( t i ) P_{i}(t_{i}) Pi(ti)的第 ( k + 1 ) (k+1) (k+1)帧
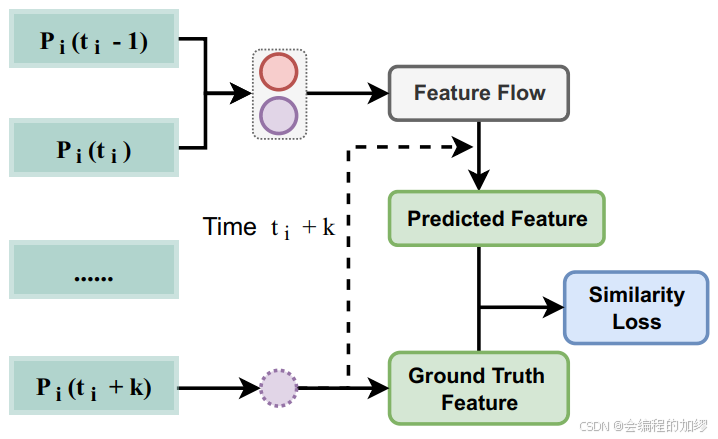
并且,作者构建了一个损失函数来优化特征生成器,该损失函数的目标是 t i + k t_{i}+k ti+k时刻预测的特征流尽可能地接近 t i + k t_i+k ti+k时刻的特征(作者是通过余弦相似性实现的)。
五、实验部分
1. 实验设置
数据集:作者使用了公开的真实世界DAIR-V2X数据集,该数据集包含100多个场景,以及在28个具有挑战性的交通路口从基础设施和车辆传感器(摄像头和激光雷达)采集的18000个数据对。该数据集包含9311对具有车路协同视角的协同3D标注数据,其中每个物体都被标注了相应的类别(轿车、公交车、卡车或厢式货车)。数据集按5 : 2 : 3的比例划分为训练集、验证集和测试集,所有模型均在验证集上进行评估。此外,原始传感器数据仅对测试集开放。
实施细节:作者使用MMDetection3D作为代码库,在DAIR-V2X训练集上对特征融合基础模型进行了40个epoch的训练,学习率为0.001,权重衰减为0.01。为了构建用于训练特征流生成器的D,我们从训练部分中选取每一对数据,并在范围内随机设置k值。关于k和D的更多信息可在3.3节中找到。FFNet的预训练使用已训练好的特征融合基础模型。我们在 D u D_{u} Du上对特征流生成器进行了10个epoch的训练,学习率为0.001,权重衰减为0.01。所有训练和评估均在NVIDIA GeForce RTX 3090 GPU上进行。检测性能使用KITTI评估检测指标进行衡量,分别包括鸟瞰图(BEV)平均精度均值(mAP)以及交并比(IoU)为0.5和0.7时的3D mAP。对于位于矩形区域[0, -39.12, 100, 39.12]内的物体,仅考虑汽车类别。附录中提供了关于FFNet和融合方法的更多实现细节。
2. 实验比较
作者将FFNet与四类融合方法进行了比较:非融合方法(例如,PointPillars[17]和AutoAlignV2[4])、早期融合、晚期融合、中期融合(例如,DiscoNet[20])以及V2VNet[19]。
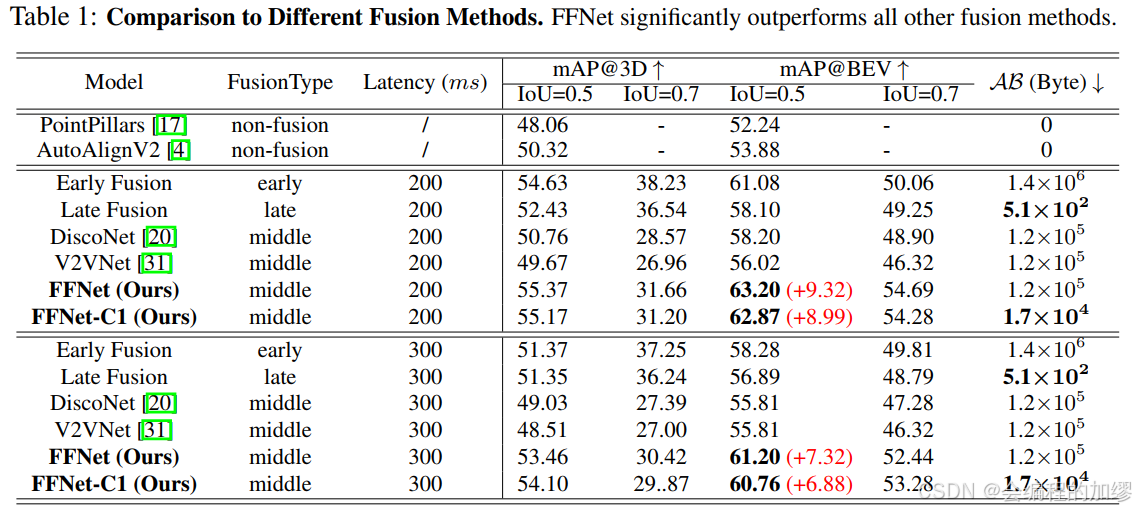
3. 消融实验
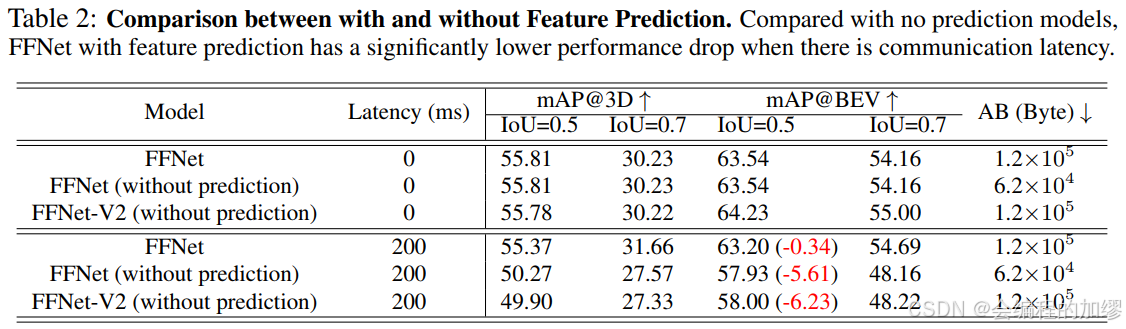
对比了有无特征流的特征预测的效果,发现在有延迟的情况下,特征流模块的预测效果较为明显。
六、总结
总结: 本文介绍了FFNet,这是一种创新的用于车路协同3D(VIC3D)目标检测的中级协同框架。FFNet通过利用压缩的特征流进行协同检测,有效地解决了与时间异步和传输成本相关的挑战。通过在DAIR-V2X数据集上进行的大量实验,FFNet展现出相较于现有最先进方法更优越的性能。此外,FFNet可以扩展到各种模态,包括图像和多模态数据,使其成为一种通用的解决方案。而且,FFNet在多车协同感知领域具有很大的潜力,并通过利用额外的帧来增强特征预测能力。所提出的FFNet框架结合了特征预测和自监督学习,为VIC3D目标检测提供了一条很有前景的途径,并且在未来解决各种协同感知任务方面具有潜力。 |
今天给大家带来的分享就到这里,欢迎大家交流讨论!补充一点:该文中的FFNet,在作者2025年发表在AAAI的另一篇文章(见该博客)中,也是用了该思想来进行时序融合。
Xizhou Zhu, Yujie Wang, Jifeng Dai, Lu Yuan, and Yichen Wei. Flow-guided feature aggregation for video
object detection ↩︎