万物对接大模型:【爆火】MCP原理与使用指南

###原文链接

OpenAI、谷歌、微软、阿里云、腾讯云、百度等国内外各大厂商都陆续宣布支持MCP服务。MCP是什么,为什么能获得高度的关注?
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司(核心产品是Claude大模型)推出的一种开源协议,在大语言模型(LLM)与开发环境之间建立统一的上下文交互标准。

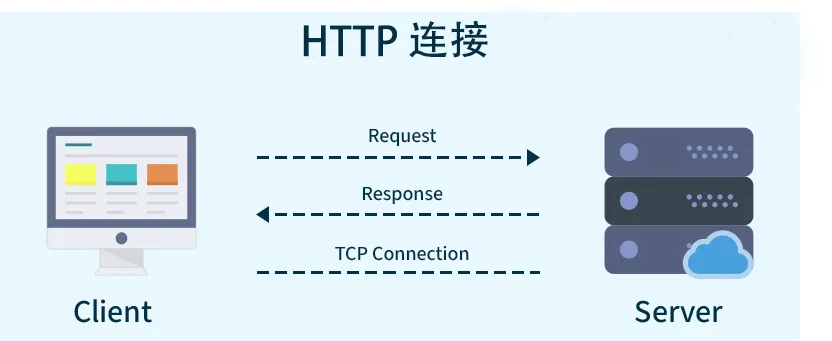
注意“协议”二字。在计算机技术领域,协议通常是指一组规则和约定,用于定义不同系统或组件之间如何进行交互和通信。例如有了http/https这种计算机网络协议,我们无论是访问百度、谷歌还是其他网站,都是通过该协议约定的规则和数据格式进行交互,而不是每访问一种网站,就要有一种与该网站建立连接和数据交互的方式,如果是这样,就很难发展起今天这么繁荣的互联网世界。
同理,LLM只是一个通过历史数据训练的,能接收我们的文字并输出文字的模型而已,而今天大家使用的任何一家公司的大模型都具有丰富的功能,比如能够联网搜索、生成LaTeX格式的数学公式、生成markdown文档、生成PPT等,这些能力就是将LLM与外部的数据、工具连接起来得到的。
类比于http/https协议,在大模型与外部数据源、工具交互这件事上,显然,我们需要一个统一的标准来让事情变得更简单、更高效。

MCP作为一种协议,其核心目标是为LLM与外部数据源、工具和应用之间的交互提供一个标准化的框架。
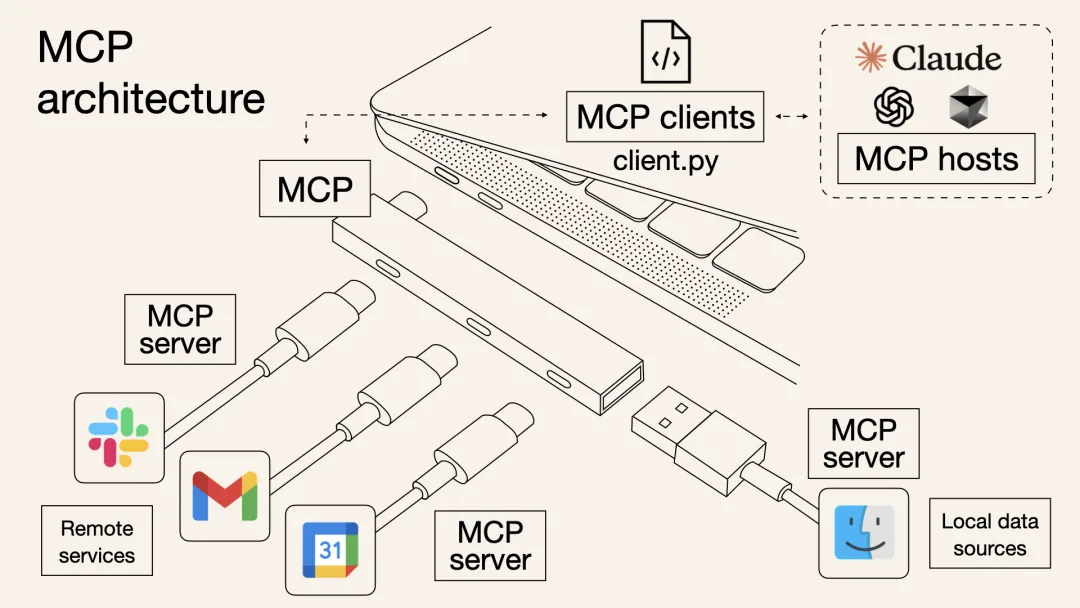
如下图,MCP就好比USB扩展坞,MCP的一端通过标准的USB接口与电脑连接,在另一端连接了各种电脑外设,这些外设只要遵循MCP扩展坞的接口标准,能够与扩展坞连接,也就与电脑建立了连接,然后电脑再与我们的AI应用比如DeepSeek进行交互,最终就实现了DeepSeek控制各种电脑外设的功能。所以说MCP为大模型和“万物”间建立了桥梁!
至此我们对MCP有了宏观认识,读者朋友如果对协议的细节感兴趣,可参见官方文档:
🔗mcp社区
🔗mcp开发者

案例:DeepSeek通过MCP服务操作GitHub
首先安装Cline(一款AI助手插件),在VS Code扩展商店中搜索安装即可:
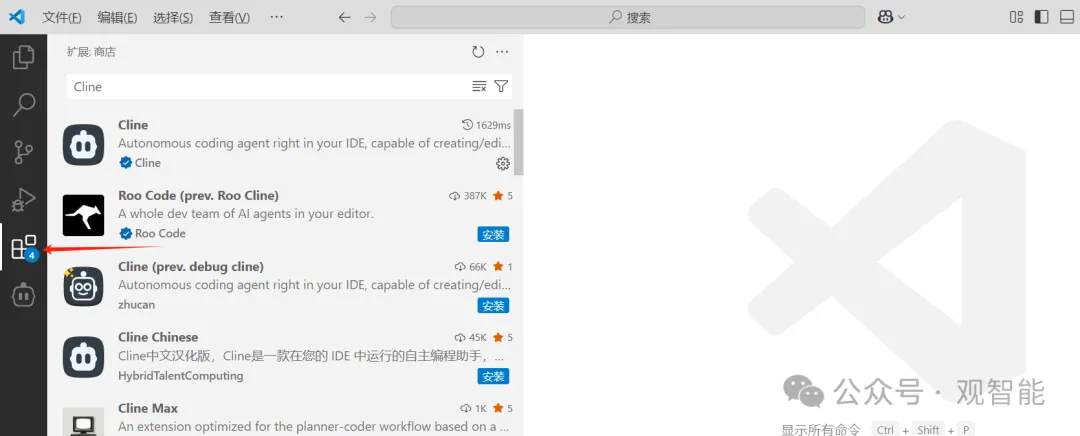
然后左侧工具栏会出现Cline的图标,点击进入Cline使用界面:
首先配置我们的大模型,点击设置图标,然后选择DeepSeek(当然,有很多模型来源可选择),填入我们在DeepSeek开放平台申请的API Key,然后再选择一个模型类型即可,这里是DeepSeek-chat(背后用的是DeepSeek-V3模型):
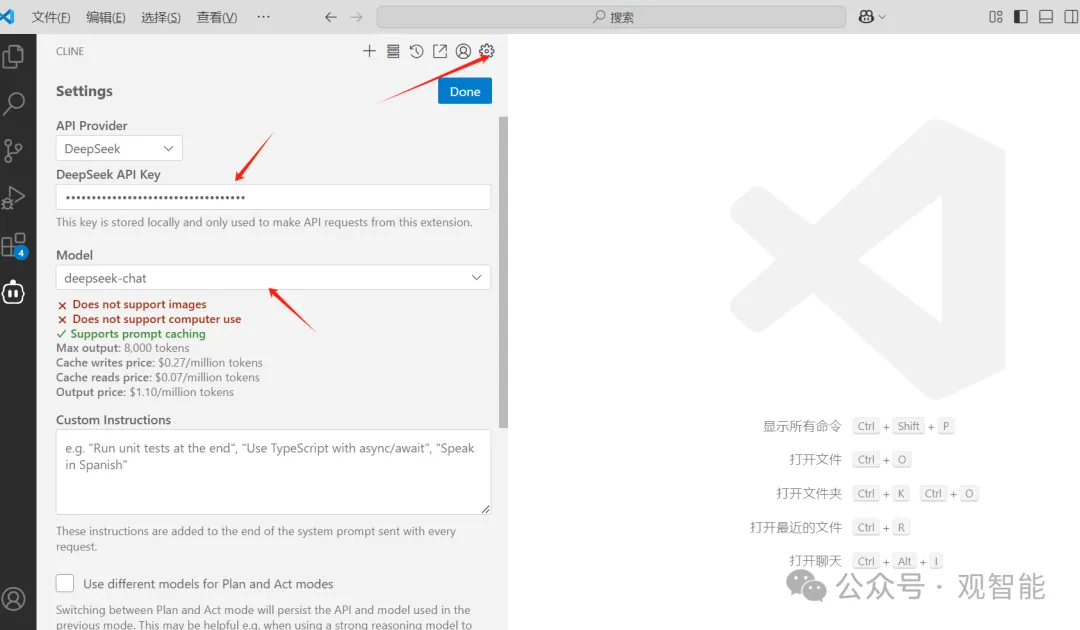
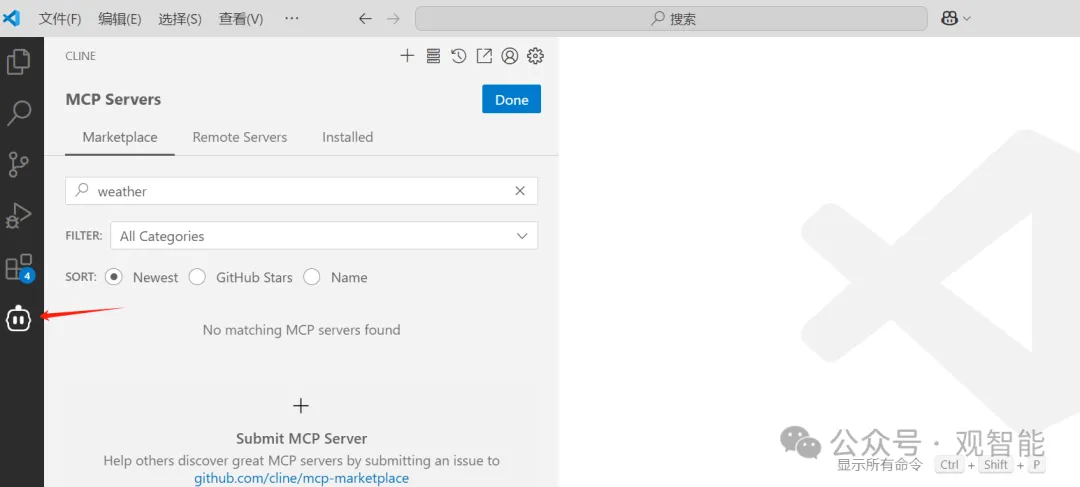
然后在Cline界面我们点击MCP服务商店的图标,可以看到很多公司都提供了它们的MCP服务,这里我们搜索GitHub字样:
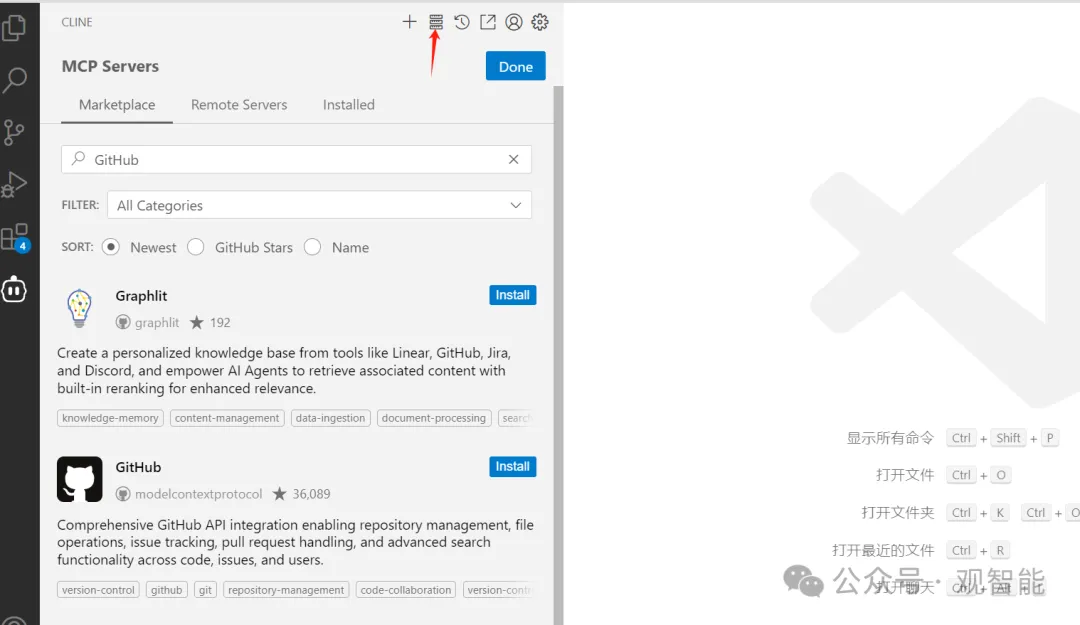
点击安装这个服务,安装过程中会要你提供操作GitHub的权限token,点击给出的链接去生成token即可,然后在对话框发送toekn,安装过程会继续下去,安装完成后来到已安装界面,点击配置按钮会跳出一个配置文件cline_mcp_settings.json:
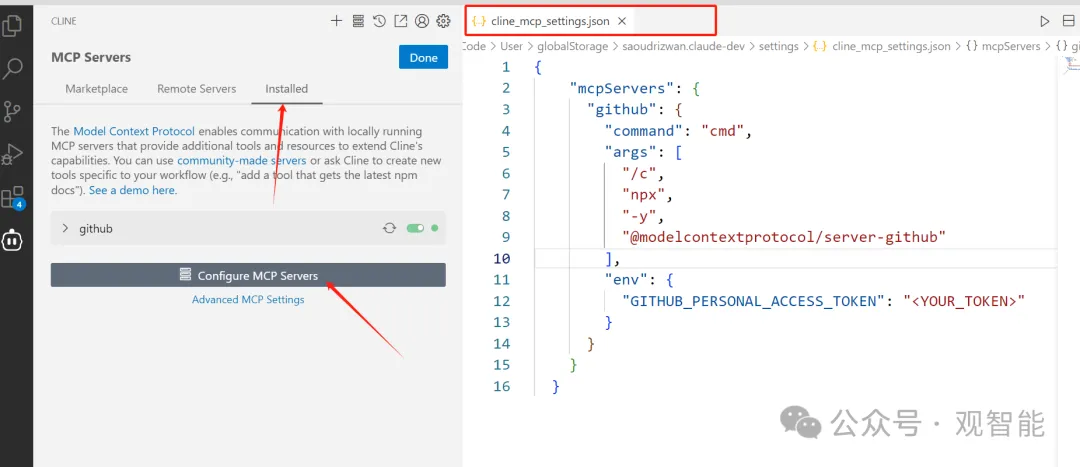
重点来了:实际上在商店中安装一个服务就是在配置文件中添加该服务的配置信息,也就是说我们完全可以手动写这些配置信息,而一个服务本质上就是一个Python或Node.js程序,如上图的GitHub服务是用Node.js开发的,所以在运行命令里面用npx运行。所以我们可以编写自己的服务,也可以在其它地方找到服务,然后把相应配置信息填好来使用,比如在https://smithery.ai/这个网站上有很多服务,我们搜索一个苹果公司的服务:
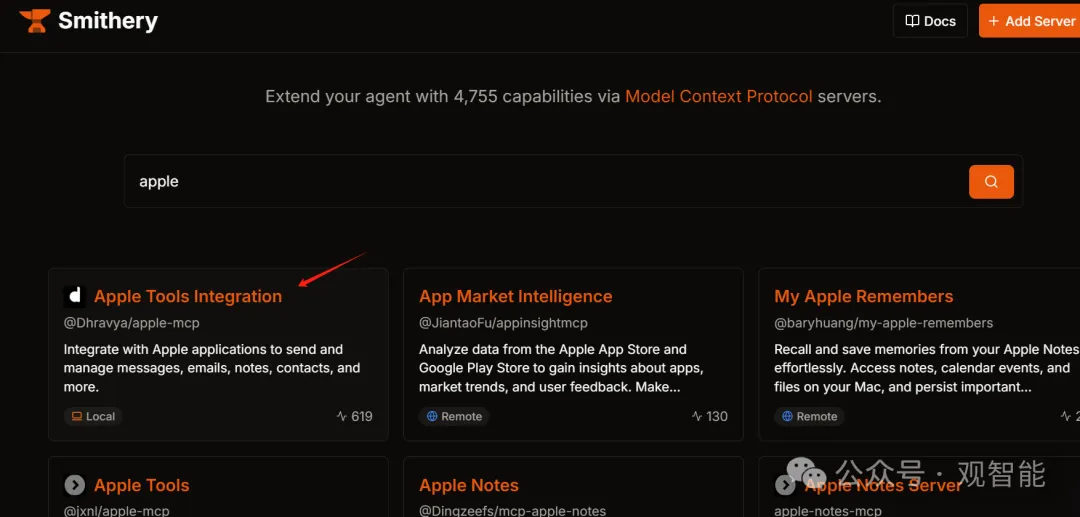
在安装方式那里找到符合我们的配置信息,可以复制下来到Cline中使用:

回到主题,安装完GitHub服务并且默认启用以及状态正常后就可以使用服务了(见下图):
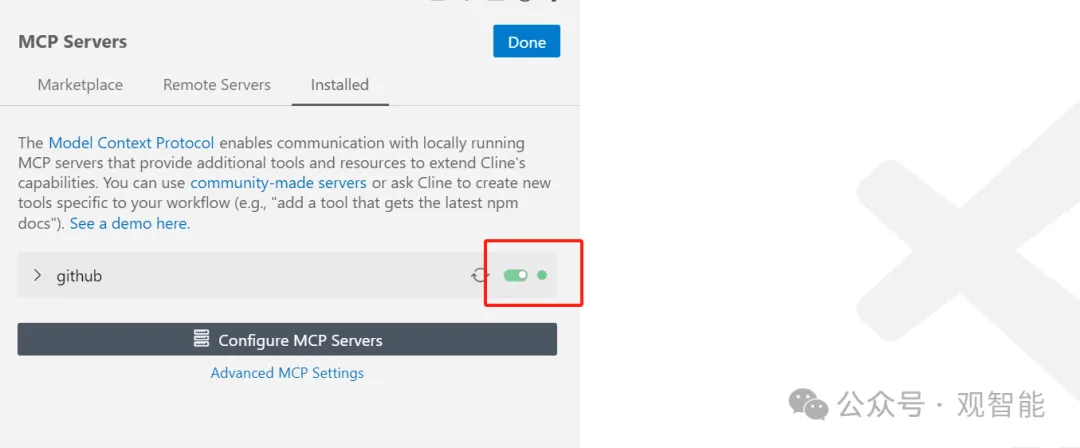
首先我问了句“你好”,然后MCP客户端(这里可以认为就是Cline)把“你好”和目前仅有的GitHub服务的相关信息都作为提示词给了大模型,提示词的内容用json组织(MCP协议中各个参与者之间的通信消息都采用JSON-RPC格式),大致内容表达的是:
用户的问题:“你好”;服务:“Github”(当然,如果你安装了多个服务,它都会列出来);GitHub的工具:create_repository(创建仓库)、create_branch(创建分支)…(注:由此可以看出MCP服务是一个具体的程序,比如你安装后在本地运行的一个叫GitHub的Python程序,而工具就是该程序下的一个个函数或称方法,如上面的创建新仓库函数、创建分支函数);请判断该调用哪个工具完成任务。
然后大模型接到该提示词后,判断“你好”只是在打招呼,不需要使用什么MCP服务,所以就直接回复了你:
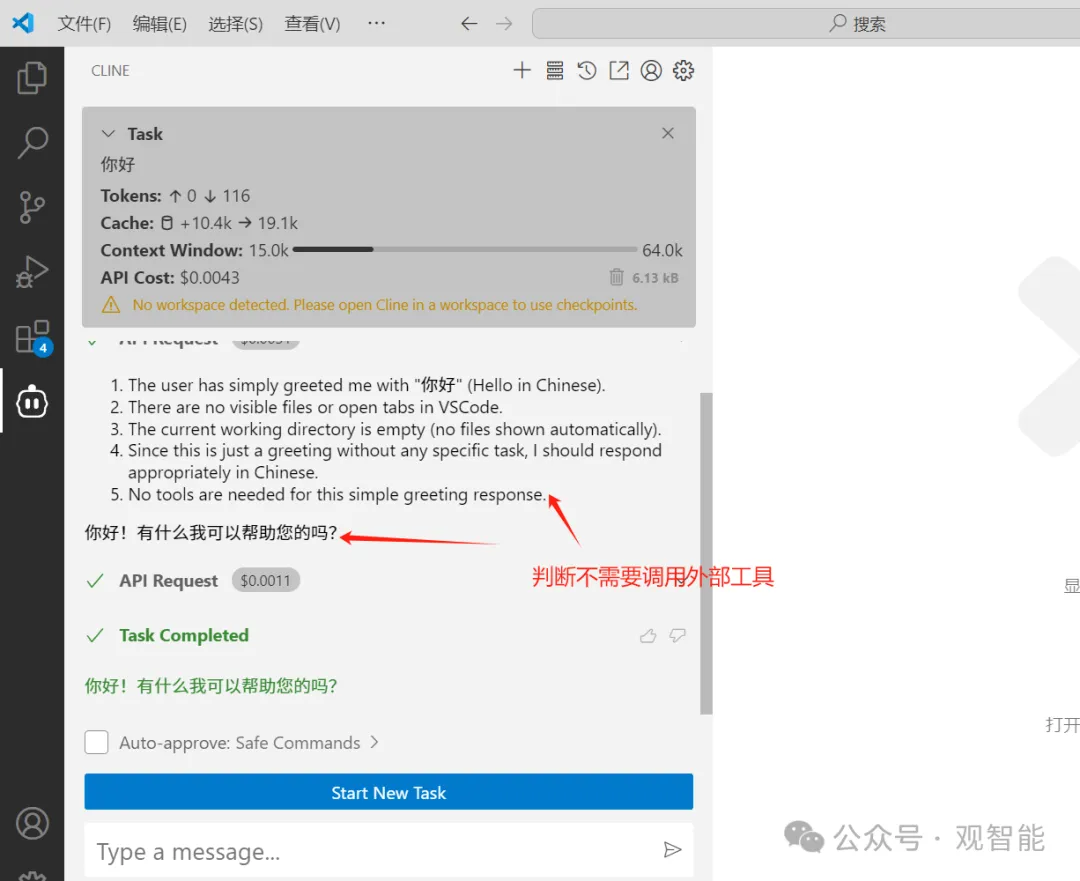
接下来,我要求创建一个叫“test_2025”的仓库,于是上面的过程再次重复,此时大模型判断出需要调用GitHub服务下的create_repository工具,并且用户给出的参数是name:“test_2025”…,于是便给MCP Client返回了相关信息:
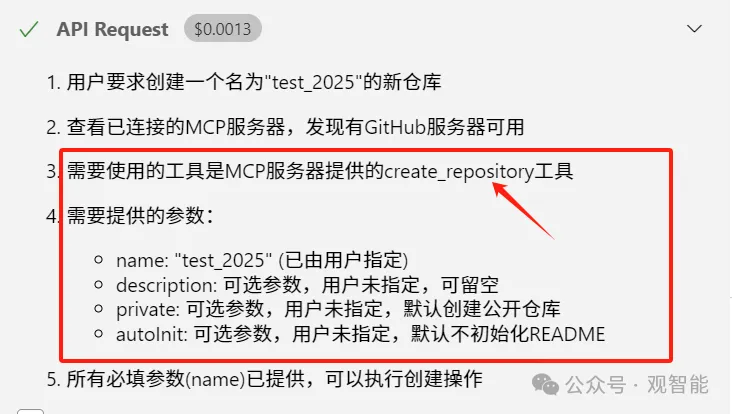
MCP Client拿到大模型的返回信息后便把该信息组织成如下格式(即向MCP Server发出的请求信息):
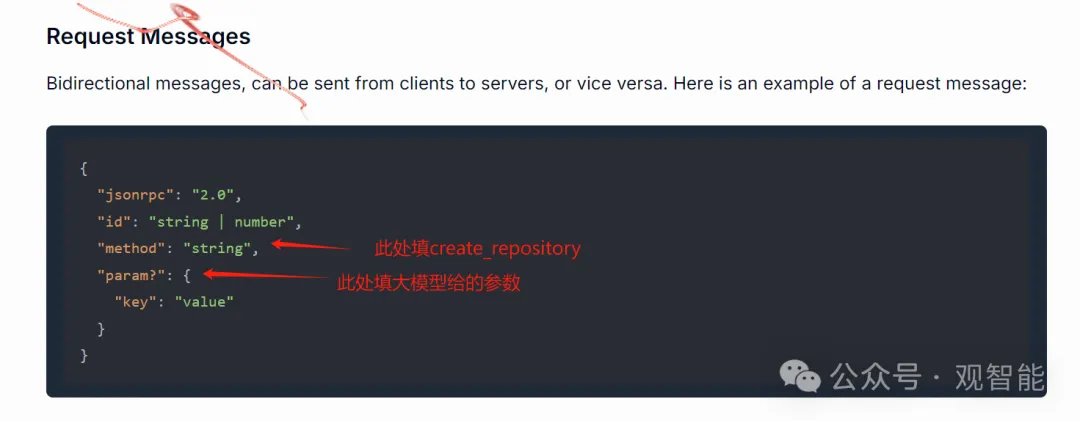
MCP Server(这里即我们安装的GitHub服务)拿到请求信息后则调用相应工具执行相应动作,然后把执行的结果组织成如下格式:
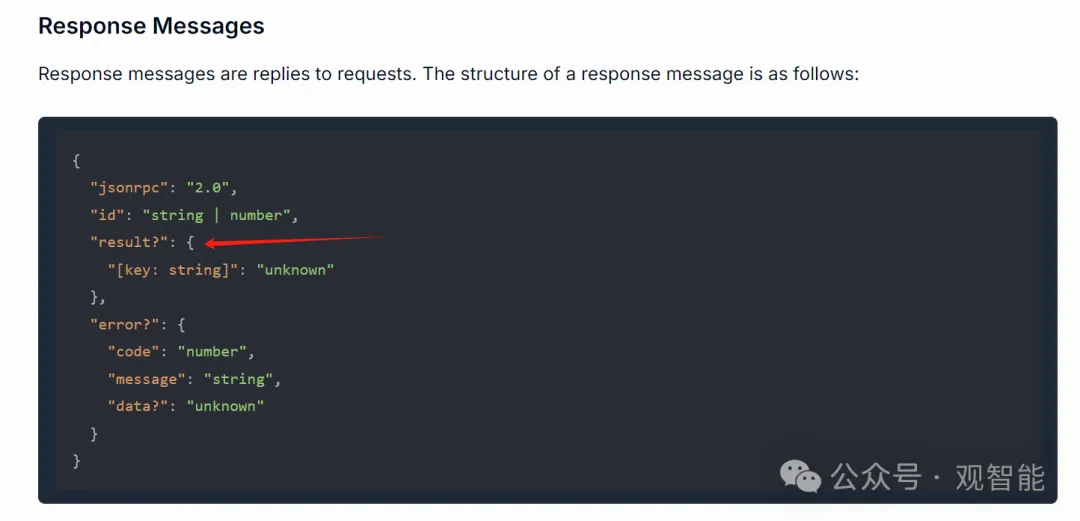
MCP Client拿到响应信息后再结合用户的问题把相关内容都发给大模型,大模型再总结出我们最终看到的结果。
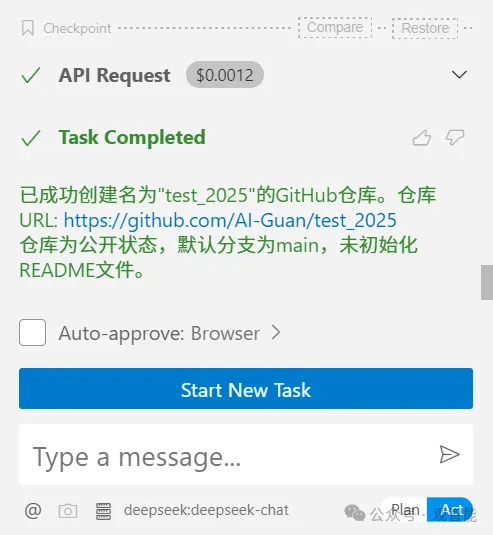

这样就完成了用大模型操作GitHub仓库的功能需求。这个过程也可以看出MCP比较费token,比如MCP Client把用户的问题和所有服务的工具信息提供给大模型让大模型判断需不需要调用工具的操作。