第 3 期:逆过程建模与神经网络的作用(Reverse Process)
一、从正向扩散到逆向去噪:生成的本质
在上期中我们讲到,正向扩散是一个逐步加入噪声的过程,从原始图像 x_0到接近高斯分布的 x_T:
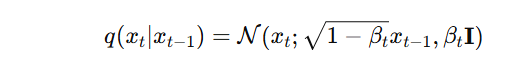
而我们真正关心的,是从纯噪声中逐步还原原图的过程,也就是逆过程:
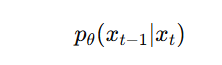
这个逆过程没有 closed form,我们只能用神经网络来近似学习它。
二、逆过程建模:从高斯中一步步采样
根据论文设定,我们假设每一步的逆过程仍是高斯分布:
![]()
也就是说:我们要学习的是每一步的均值和方差。
-
方差 Σ_θ通常被固定或共享
-
网络主要任务是输出 μ_θ,也就是引导去噪的方向
想象一下,你现在手上有一张全是雪点(噪声)的图片,你想一步一步去“擦掉”这些噪声,还原最初的图片,这就是神经网络的任务。
三、三种预测方式:预测 μ、ϵ 或 x_0?
论文中探讨了三种不同的预测方式,来指导我们如何训练神经网络 ϵ_θ:
方式一:预测噪声 ϵ\epsilonϵ(默认使用)
利用公式:
![]()
我们可以反推:
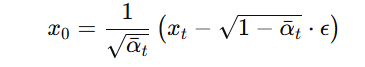
训练时的损失函数:
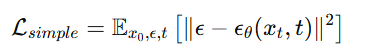
也就是说我们训练神经网络来预测加进去的噪声,然后反推出干净图像。
方式二:直接预测 x_0
由上面的公式我们可以看到,如果我们预测出 x_0,也能得到 ϵ 或 μ。
有些改进模型(如Guided Diffusion)使用这种方式,因为可以更直接地控制生成图像。
方式三:直接预测 μ_θ(x_t,t)
这种方式虽然看似最直接,但训练不如预测 ϵ稳定,因此实际使用中较少。
四、神经网络结构:用U-Net来建模 ϵ_θ(x_t,t)
DDPM中广泛使用 U-Net 结构来建模 ϵ_θ,原因如下:
-
图像到图像的任务中,U-Net有非常强的表现
-
可融合多层语义信息(通过跳跃连接)
-
可轻松嵌入时间步 ttt 信息(通过time embedding)
网络输入:
-
噪声图像 x_t
-
时间步编码 t
网络输出:
-
同样大小的图像,预测噪声 ϵ
五、采样过程简述:从高斯恢复图像
当模型训练好之后,采样过程是这样的:
-
从高斯分布中采样
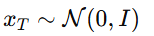
-
对 t=T,T−1,…,1:
-
用网络预测 ϵ_θ(x_t,t)
-
计算
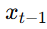 并加入随机项(保持多样性)
并加入随机项(保持多样性)
-
整个过程逐步“去除噪声”,最终得到 x_0,也就是生成图像。
代码演示:构造训练样本并训练模型
我们用 PyTorch 举例说明:
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt# 超参数
T = 1000 # 扩散步数
beta = torch.linspace(1e-4, 0.02, T) # 固定线性beta表
alpha = 1 - beta
alpha_bar = torch.cumprod(alpha, dim=0)# 加噪函数 q(x_t | x_0)
def q_sample(x_0, t, noise=None):if noise is None:noise = torch.randn_like(x_0)sqrt_alpha_bar = torch.sqrt(alpha_bar[t])[:, None, None, None]sqrt_one_minus = torch.sqrt(1 - alpha_bar[t])[:, None, None, None]return sqrt_alpha_bar * x_0 + sqrt_one_minus * noise
网络结构(最小U-Net)
class SimpleDenoiseModel(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Conv2d(1, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 1, 3, padding=1),)def forward(self, x, t):return self.net(x)
训练核心逻辑
model = SimpleDenoiseModel().to("cuda")
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)def get_loss(x_0, t):noise = torch.randn_like(x_0)x_t = q_sample(x_0, t, noise)noise_pred = model(x_t, t)return nn.MSELoss()(noise_pred, noise)# 示例训练循环
for epoch in range(10):for x, _ in dataloader:x = x.to("cuda")t = torch.randint(0, T, (x.size(0),), device="cuda").long()loss = get_loss(x, t)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch {epoch}: Loss = {loss.item():.4f}")
可视化一个加噪过程
def show_noisy_images(x_0, steps=[0, 200, 400, 600, 800, 999]):fig, axes = plt.subplots(1, len(steps), figsize=(15, 2))for i, t in enumerate(steps):xt = q_sample(x_0, torch.tensor([t]))axes[i].imshow(xt[0][0].cpu(), cmap="gray")axes[i].set_title(f"t = {t}")axes[i].axis("off")plt.tight_layout()plt.show()
小结
| 关键点 | 内容 |
|---|---|
| 学习目标 | 模型学习预测给定x_t时的噪声 ϵ |
| 网络输入 | x_t 和时间步 t |
| 网络输出 | 估计的 ϵ_θ(x_t,t) |
| 损失函数 | MSE between 预测噪声 和 真实噪声 |
| 实际操作 | 从 x_0采样,生成x_t,训练模型反推噪声 |
下一讲预告(第 4 期):
我们将深入解读为什么损失函数可以简化为预测噪声的 MSE,并且用变分下界(ELBO)的推导说明这个做法的理论基础!