深度学习-全连接神经网络-1
一、深度学习概述
1. 什么是深度学习
人工智能、机器学习和深度学习之间的关系:

机器学习是实现人工智能的一种途径,深度学习是机器学习的子集,区别如下:
传统机器学习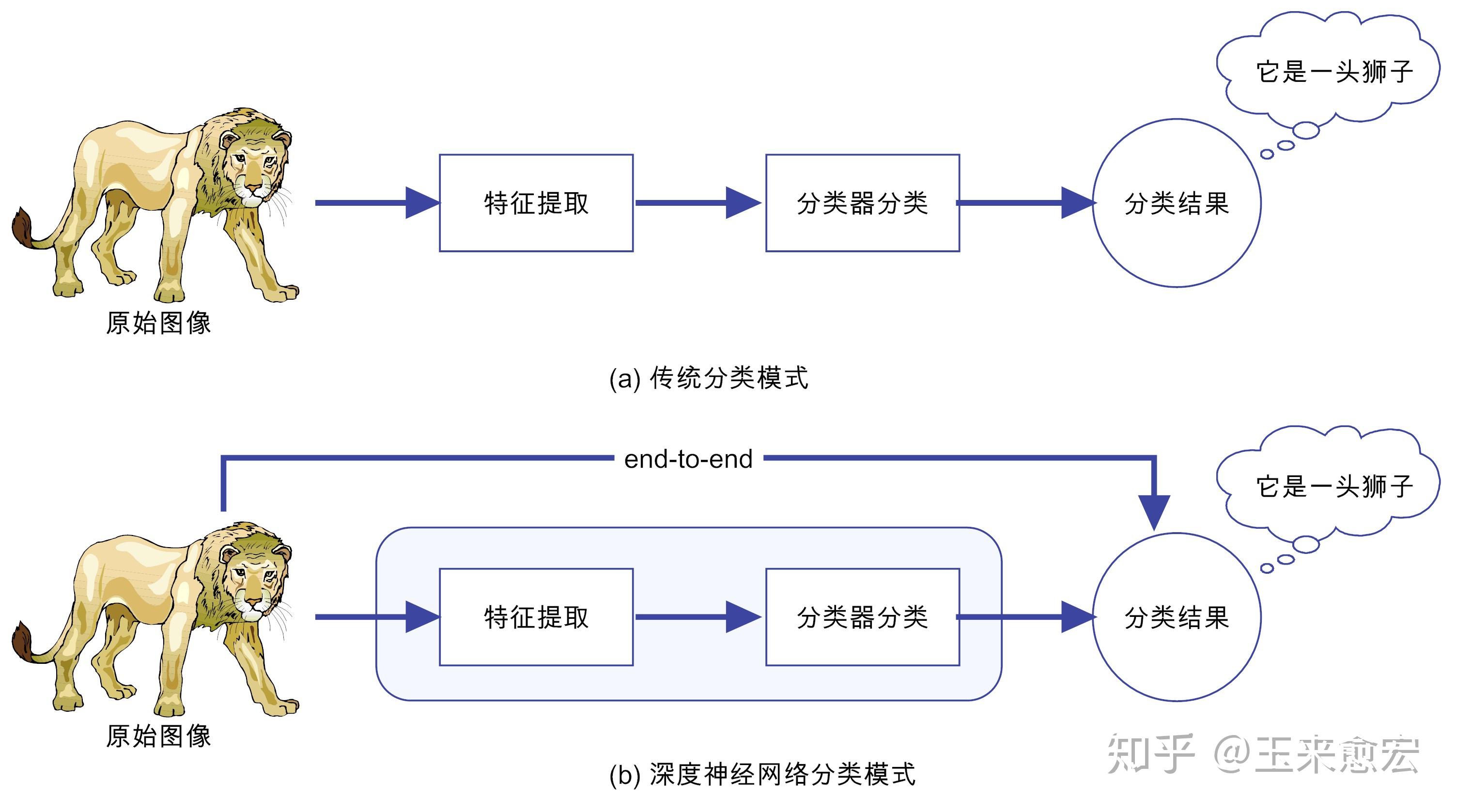 算法依赖人工设计特征、提取特征,而深度学习依赖算法自动提取特征。深度学习模仿人类大脑的运行方式,从大量数据中学习特征,这也是深度学习被看做黑盒子、可解释性差的原因。
算法依赖人工设计特征、提取特征,而深度学习依赖算法自动提取特征。深度学习模仿人类大脑的运行方式,从大量数据中学习特征,这也是深度学习被看做黑盒子、可解释性差的原因。
随着算力的提升,深度学习可以处理图像,文本,音频,视频等各种内容,主要应用领域有:
-
图像处理:分类、目标检测、图像分割(语义分割)
-
自然语言处理:LLM、NLP、Transformer
-
语音识别:对话机器人、智能客服(语音+NLP)
-
自动驾驶:语义分割(行人、车辆、实线等)
-
LLM:大Large语言Language模型Model
-
机器人:非常火的行业
有了大模型的加持,AI+各行各业。
2. 深度学习发展历史
深度学习其实并不是新的事物,深度学习所需要的神经网络技术起源于20世纪50年代,叫做感知机。当时使用单层感知机,因为只能学习线性可分函数,连简单的异或(XOR)等线性不可分问题都无能为力,1969年Marvin Minsky写了一本叫做《Perceptrons》的书,他提出了著名的两个观点:1.单层感知机没用,我们需要多层感知机来解决复杂问题 2.没有有效的训练算法。
20世纪80年代末期,用于人工神经网络的反向传播算法(也叫Back Propagation算法或者BP算法)的发明,给机器学习带来了希望,掀起了基于统计模型的机器学习热潮。这个热潮一直持续到今天。人们发现,利用BP算法可以让一个人工神经网络模型从大量训练样本中学习统计规律,从而对未知事件做预测。这种基于统计的机器学习方法比起过去基于人工规则的系统,在很多方面显出优越性。这个时候的人工神经网络,虽也被称作多层感知机(Multi-layer Perceptron),但实际是种只含有一层隐层节点的浅层模型。
2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念。
2012年,在著名的ImageNet图像识别大赛中,杰弗里·辛顿领导的小组采用深度学习模型AlexNet一举夺冠。AlexNet采用ReLU激活函数,从根本上解决了梯度消失问题,并采用GPU极大的提高了模型的运算速度。
同年,吴恩达教授和Jeff Dean主导的深度神经网络DNN技术在ImageNet评测中把错误率从26%降低到15%,再一次吸引了学术界和工业界对于深度学习领域的关注。
2016年,随着谷歌公司基于深度学习开发的AlphaGo以4:1的比分战胜了国际顶尖围棋高手李世石,深度学习的热度一时无两。后来,AlphaGo又接连和众多世界级围棋高手过招,均取得了完胜。这也证明了在围棋界,基于深度学习技术的机器人已经超越了人类。
2017年,基于强化学习算法的AlphaGo升级版AlphaGo Zero横空出世。其采用“从零开始”、“无师自通”的学习模式,以100:0的比分轻而易举打败了之前的AlphaGo。除了围棋,它还精通国际象棋等其它棋类游戏,可以说是真正的棋类“天才”。此外在这一年,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域均取得了显著的成果。所以,也有专家把2017年看作是深度学习甚至是人工智能发展最为突飞猛进的一年。
2019年,基于Transformer 的自然语言模型的持续增长和扩散,这是一种语言建模神经网络模型,可以在几乎所有任务上提高NLP的质量。Google甚至将其用作相关性的主要信号之一,这是多年来最重要的更新。
2020年,深度学习扩展到更多的应用场景,比如积水识别,路面塌陷等,而且疫情期间,在智能外呼系统,人群测温系统,口罩人脸识别等都有深度学习的应用。
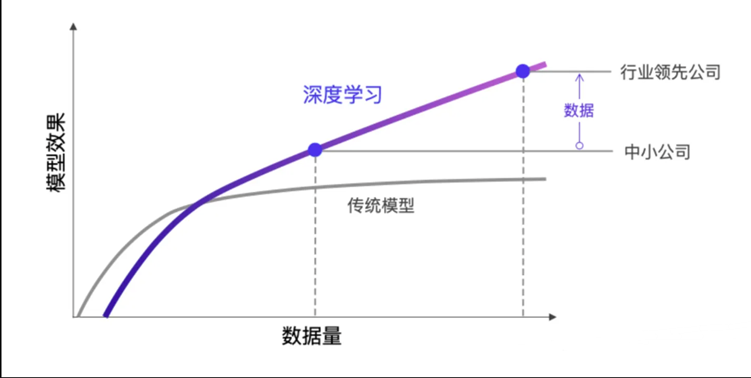
3. 深度学习的优势
二、神经网络
我们要学习的深度学习(Deep Learning)是神经网络的一个子领域,主要关注更深层次的神经网络结构,也就是深层神经网络(Deep Neural Networks,DNNs)。所以,我们需要先搞清楚什么是神经网络!
1. 感知神经网络
神经网络(Neural Networks)是一种模拟人脑神经元网络结构的计算模型,用于处理复杂的模式识别、分类和预测等任务。生物神经元如下图:
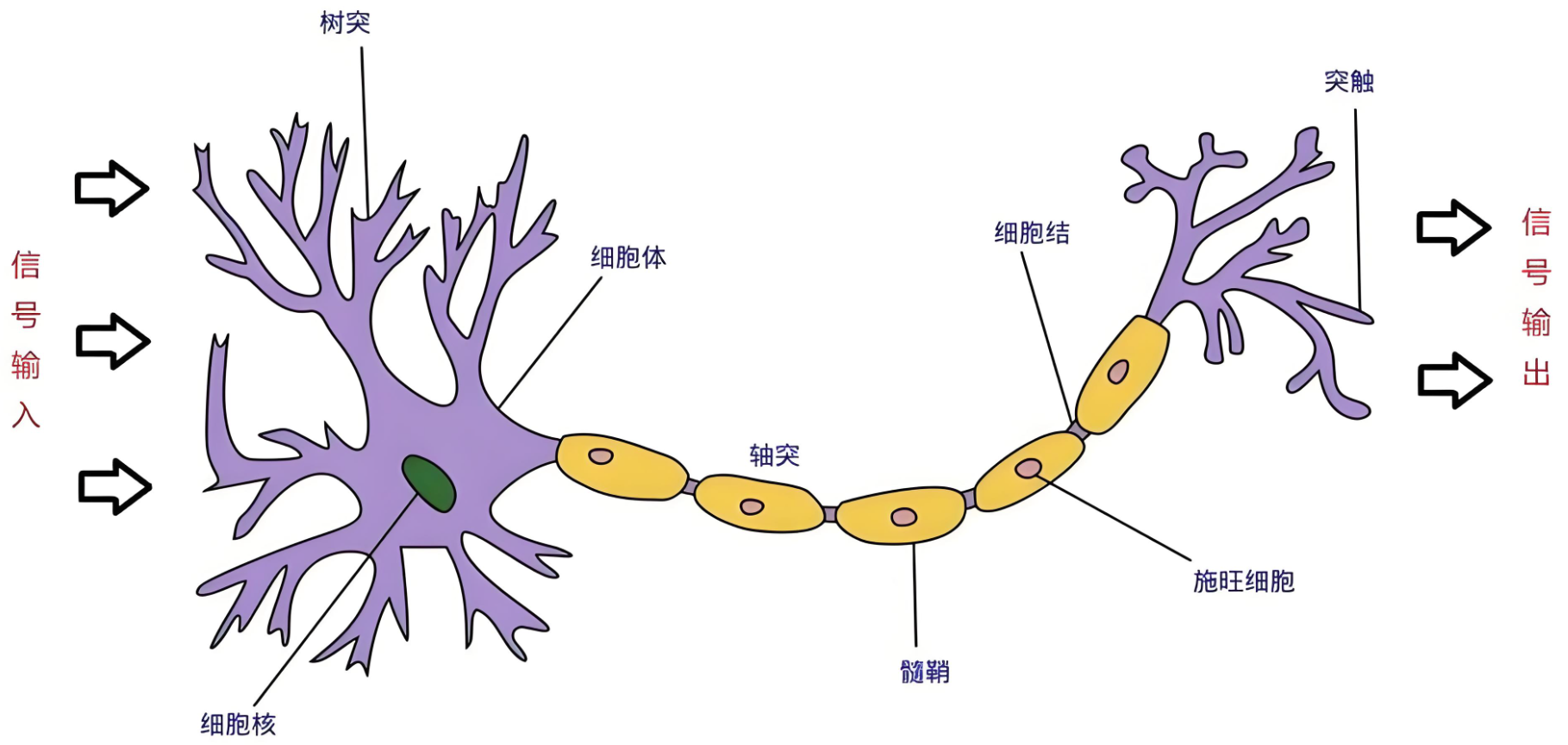
生物学:
人脑可以看做是一个生物神经网络,由众多的神经元连接而成
-
树突:从其他神经元接收信息的分支
-
细胞核:处理从树突接收到的信息
-
轴突:被神经元用来传递信息的生物电缆
-
突触:轴突和其他神经元树突之间的连接
人脑神经元处理信息的过程:
-
多个信号到达树突,然后整合到细胞体的细胞核中
-
当积累的信号超过某个阈值,细胞就会被激活
-
产生一个输出信号,由轴突传递。
神经网络由多个互相连接的节点(即人工神经元)组成。
2. 人工神经元
人工神经元(Artificial Neuron)是神经网络的基本构建单元,模仿了生物神经元的工作原理。其核心功能是接收输入信号,经过加权求和和非线性激活函数处理后,输出结果。
2.1 构建人工神经元
人工神经元接受多个输入信息,对它们进行加权求和,再经过激活函数处理,最后将这个结果输出。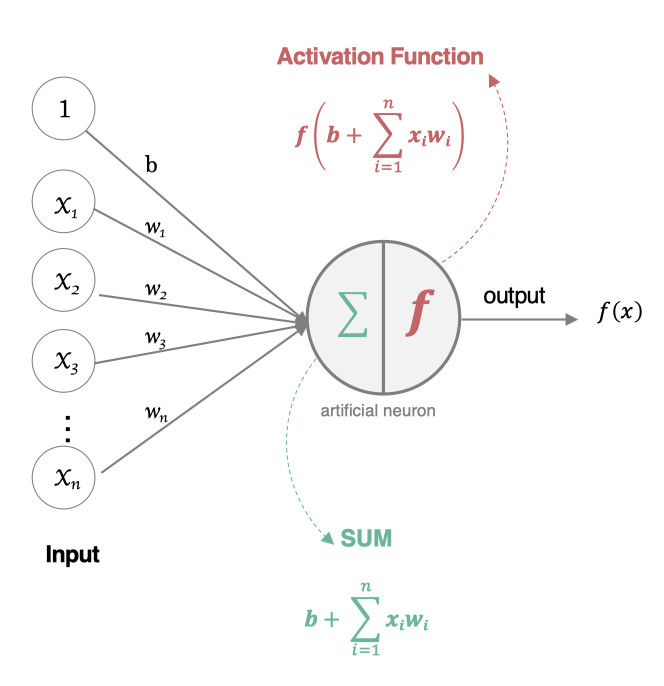
2.2 组成部分
-
输入(Inputs): 代表输入数据,通常用向量表示,每个输入值对应一个权重。
-
权重(Weights): 每个输入数据都有一个权重,表示该输入对最终结果的重要性。
-
偏置(Bias): 一个额外的可调参数,作用类似于线性方程中的截距,帮助调整模型的输出。
-
加权求和: 神经元将输入乘以对应的权重后求和,再加上偏置。
-
激活函数(Activation Function): 用于将加权求和后的结果转换为输出结果,引入非线性特性,使神经网络能够处理复杂的任务。常见的激活函数有Sigmoid、ReLU(Rectified Linear Unit)、Tanh等。
2.3 数学表示
如果有 n 个输入 权重分别为
偏置为 b,则神经元的输出 y 表示为:
其中,是激活函数。
例如:
线性回归:
线性回归不需要激活函数
逻辑回归:
2.4 对比生物神经元
人工神经元和生物神经元对比如下表:
| 生物神经元 | 人工神经元 |
|---|---|
| 细胞核 | 节点 (加权求和 + 激活函数) |
| 树突 | 输入 |
| 轴突 | 带权重的连接 |
| 突触 | 输出 |
3. 深入神经网络
神经网络是由大量人工神经元按层次结构连接而成的计算模型。每一层神经元的输出作为下一层的输入,最终得到网络的输出。
3.1 基本结构
神经网络有下面三个基础层(Layer)构建而成:
-
输入层(Input): 神经网络的第一层,负责接收外部数据,不进行计算。
-
隐藏层(Hidden): 位于输入层和输出层之间,进行特征提取和转换。隐藏层一般有多层,每一层有多个神经元。
-
输出层(Output): 网络的最后一层,产生最终的预测结果或分类结果
3.2 网络构建
我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个权重,经典如下:
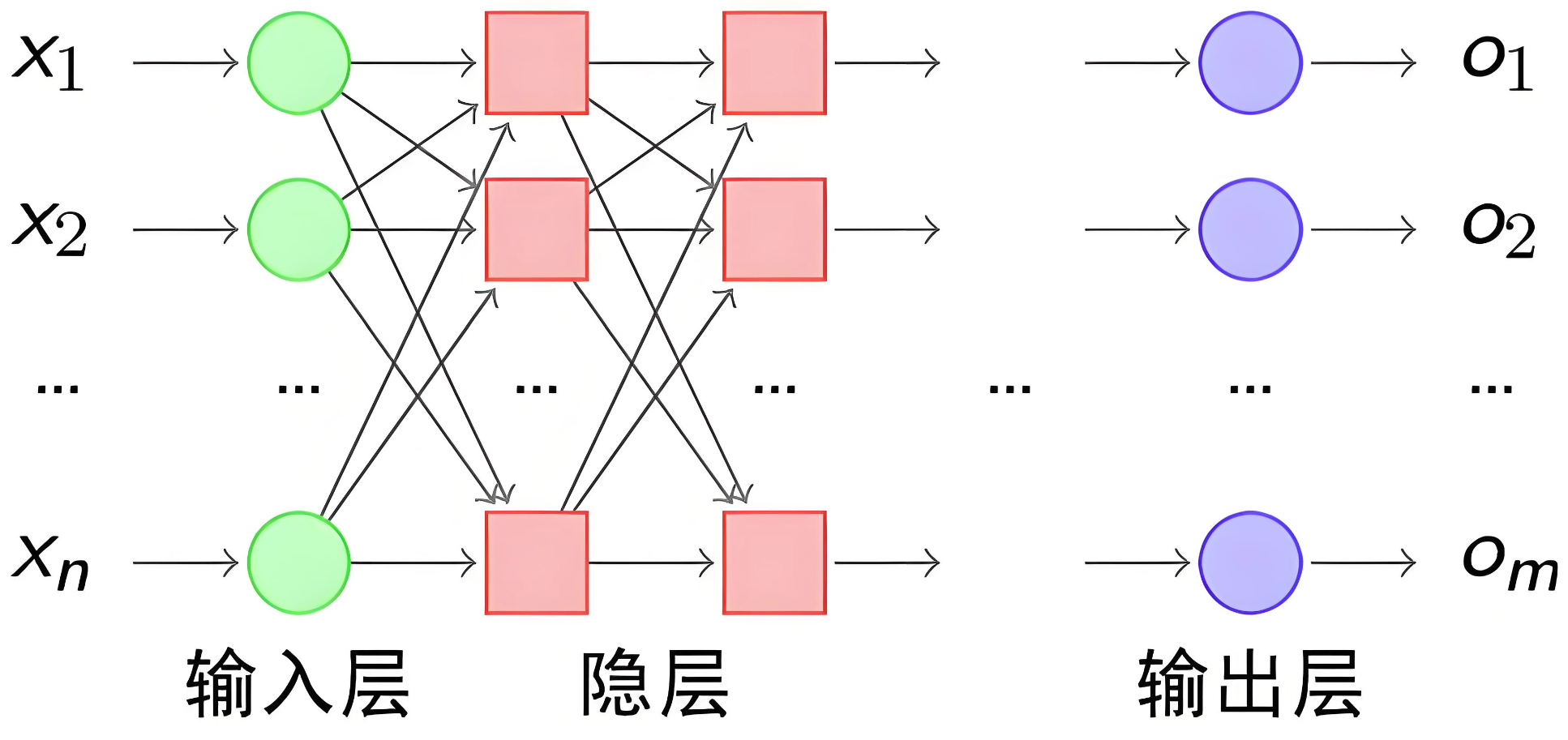
注意:同一层的各个神经元之间是没有连接的。
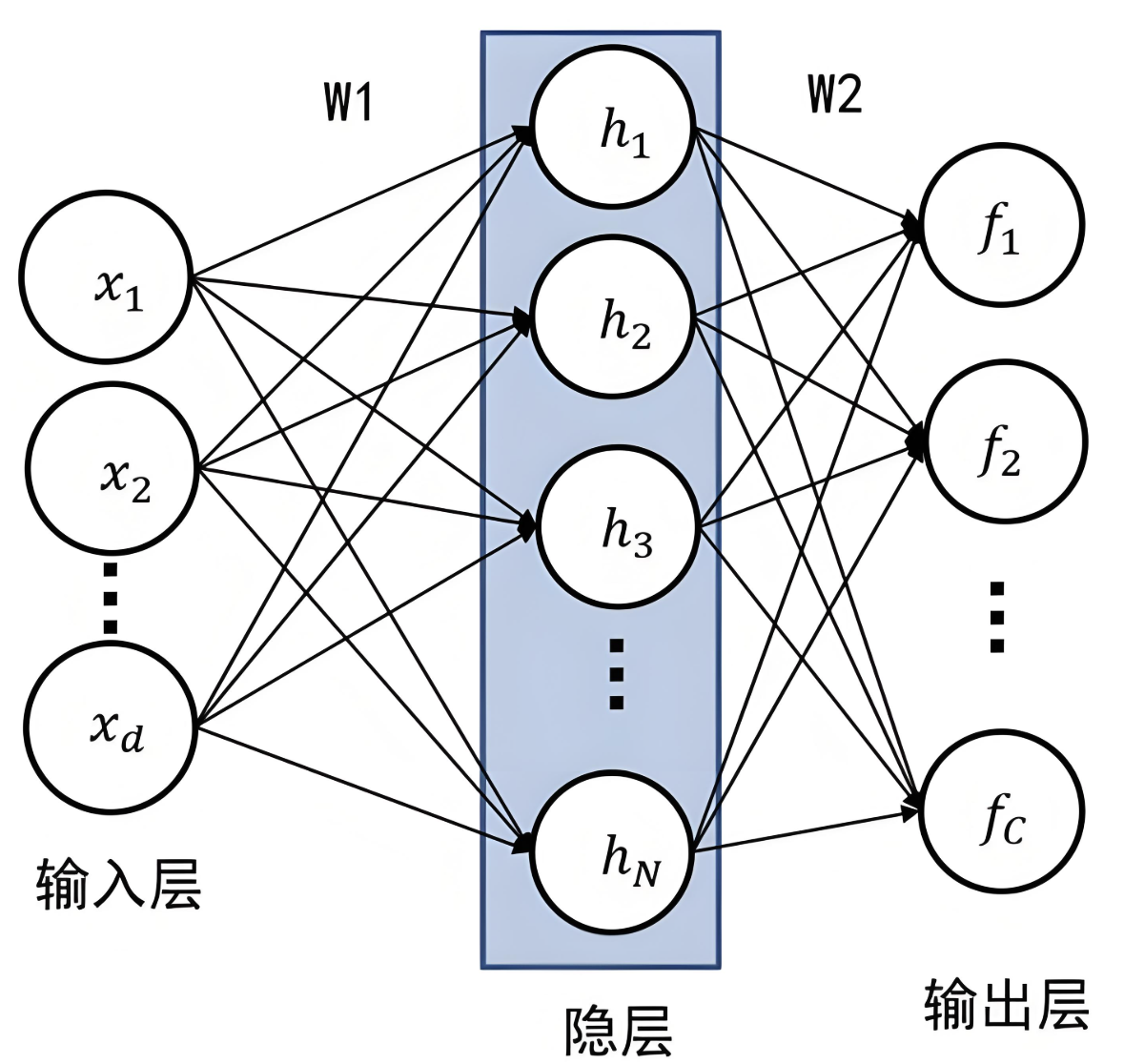
3.3 全连接神经网络
前馈神经网络(Feedforward Neural Network,FNN)是一种最基本的神经网络结构,其特点是信息从输入层经过隐藏层单向传递到输出层,没有反馈或循环连接。
全连接神经网络(Fully Connected Neural Network,FCNN)是前馈神经网络的一种,每一层的神经元与上一层的所有神经元全连接,常用于图像分类、文本分类等任务。
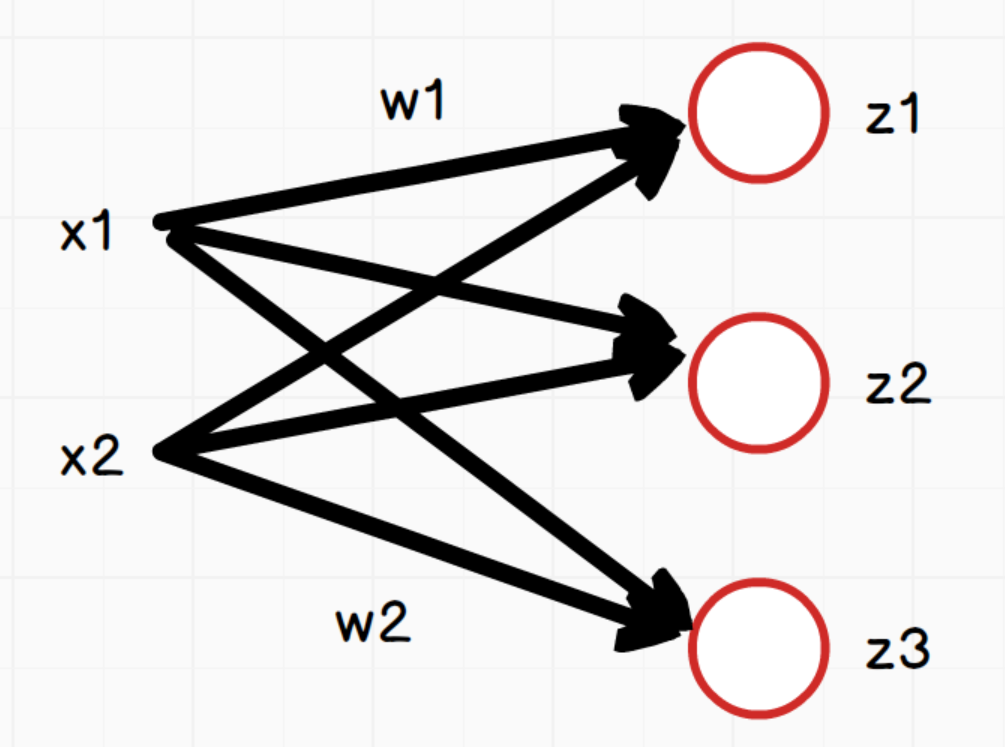
如上图,网络中每个神经元:
说明:三个等式中的w1和w2在这里只是为了方便表示对应x1和x2的权重,实际三个等式中的w值是不同的。
向量x为:[x_1,x_2]
向量w:\begin{pmatrix}w_1,w_2\\w_1,w_2\\w_1,w_2 \end{pmatrix},其形状为(3,2),3是神经元节点个数,2是向量x的个数
向量z:[z_1,z_2,z_3]
向量b:[b_1,b_2,b_3]
所以用向量表示为:
3.3.1 特点
-
全连接层: 层与层之间的每个神经元都与前一层的所有神经元相连。
-
权重数量: 由于全连接的特点,权重数量较大,容易导致计算量大、模型复杂度高。
-
学习能力: 能够学习输入数据的全局特征,但对于高维数据却不擅长捕捉局部特征(如图像就需要CNN)。
3.3.2 计算步骤
-
数据传递: 输入数据经过每一层的计算,逐层传递到输出层。
-
激活函数: 每一层的输出通过激活函数处理。
-
损失计算: 在输出层计算预测值与真实值之间的差距,即损失函数值。
-
反向传播(Back Propagation): 通过反向传播算法计算损失函数对每个权重的梯度,并更新权重以最小化损失。
3.3.3 创建全连接神经网络
创建一个最基本的全连接神经网络(也称为多层感知机,MLP)通常需要以下步骤和方法:
-
定义网络结构
-
输入层:确定输入数据的维度。例如,对于一个简单的图像分类任务,输入层的维度可能是图像的像素数量。
-
隐藏层:定义一个或多个隐藏层,每个隐藏层包含一定数量的神经元。隐藏层的数量和每个隐藏层的神经元数量可以根据任务需求调整。
-
输出层:根据任务目标确定输出层的神经元数量。例如,对于一个二分类问题,输出层通常有一个神经元;对于多分类问题,输出层的神经元数量等于类别数。
-
选择激活函数
-
隐藏层激活函数:常用的激活函数有ReLU(Rectified Linear Unit)、Sigmoid、Tanh等。ReLU是最常用的激活函数,因为它可以有效缓解梯度消失问题。
-
输出层激活函数:根据任务类型选择合适的激活函数。例如,对于二分类任务,输出层通常使用Sigmoid函数;对于多分类任务,输出层使用Softmax函数。
-
初始化权重和偏置
-
权重初始化:权重的初始化方法对网络的训练效果有重要影响。常见的初始化方法包括随机初始化(如Xavier初始化或He初始化)和零初始化(通常不推荐,因为会导致梯度消失)。
-
偏置初始化:偏置通常初始化为0或小的常数。
-
定义损失函数
-
二分类任务:通常使用二元交叉熵损失函数(Binary Cross-Entropy Loss)。
-
多分类任务:通常使用多类交叉熵损失函数(Categorical Cross-Entropy Loss)。
-
回归任务:通常使用均方误差损失函数(Mean Squared Error, MSE)。
-
选择优化器
-
SGD(随机梯度下降):最简单的优化器,通过计算梯度来更新权重。
-
Adam:一种自适应学习率的优化器,结合了RMSprop和Momentum的优点,通常在训练深度神经网络时表现良好。
-
其他优化器:如RMSprop、Adagrad等。
-
前向传播
-
在前向传播过程中,输入数据通过每一层的线性变换(权重乘法和偏置加法)和非线性激活函数,最终得到输出结果。
-
计算损失
-
使用定义的损失函数计算模型的输出与真实标签之间的差异。
-
反向传播
-
通过计算损失函数对每个权重和偏置的梯度,利用链式法则反向传播这些梯度,更新网络的权重和偏置。
-
训练模型
-
迭代地执行前向传播、计算损失和反向传播,直到模型的性能不再提升或达到预定的训练轮数。
示例:创建一个全连接神经网络,主要步骤包括:
-
定义模型结构。
-
初始化模型、损失函数和优化器。
-
准备数据。
-
训练模型。
-
(可选)评估模型。
你可以根据实际任务调整网络结构、损失函数和优化器等。
import torch
from torch import nn
from torch import optim
from torch.nn import functional as Ftorch.manual_seed(42)# 定义全连接神经网络模型
class MyFcnn(nn.Module):def __init__(self, input_size):# 父类初始化super(MyFcnn, self).__init__()# 定义线性层1self.fc1 = nn.Linear(input_size, 64)# 初始化w权重nn.init.kaiming_uniform_(self.fc1.weight)# 初始化b偏置nn.init.zeros_(self.fc1.bias)# 定义线性层2,输入要和第一层的输出一致self.fc2 = nn.Linear(64, 32)# 初始化w权重nn.init.kaiming_uniform_(self.fc2.weight)# 初始化b偏置nn.init.zeros_(self.fc2.bias)# 定义线性层3,输入要和第二层的输出一致self.fc3 = nn.Linear(32, 1)# 初始化w权重nn.init.xavier_uniform_(self.fc3.weight)# 初始化b偏置nn.init.zeros_(self.fc3.bias)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = F.sigmoid(self.fc3(x))return x# 初始化模型
input_size = 10
model = MyFcnn(input_size)
print(model)
# 定义损失函数
criterion = nn.BCELoss()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)# 训练模型
def train():model.train()# 数据准备# 100个样本,每个样本10个特征x = torch.randn(100, input_size)# 随机生成二分类标签y = torch.randint(0, 2, (100, 1)).float()# 迭代次数epochs = 10for epoch in range(epochs):# 前向传播y_pred = model(x)# 计算损失loss = criterion(y_pred, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新梯度optimizer.step()# 打印训练信息print(f"Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}")# 模型验证
X_test = torch.randn(20, input_size) # 20个测试样本
y_test = torch.randint(0, 2, (20, 1)).float() # 测试标签def eval():model.eval()with torch.no_grad():y_pred = model(X_test)y_pred = (y_pred > 0.5).float()accuracy = (y_pred == y_test).float().mean().item()print(f"Test Accuracy: {accuracy:.4f}")if __name__ == '__main__':train()eval()三、 激活函数
激活函数的作用是在隐藏层引入非线性,使得神经网络能够学习和表示复杂的函数关系,使网络具备非线性能力,增强其表达能力。
1. 基础概念
通过认识线性和非线性的基础概念,深刻理解激活函数存在的价值。
1.1 线性理解
如果在隐藏层不使用激活函数,那么整个神经网络会表现为一个线性模型。我们可以通过数学推导来展示这一点。
假设:
-
神经网络有L 层,每层的输出为
。
-
每层的权重矩阵为
,偏置向量为
。
-
输入数据为
,输出为
。
一层网络的情况
对于单层网络(输入层到输出层),如果没有激活函数,输出可以表示为:
两层网络的情况
假设我们有两层网络,且每层都没有激活函数,则:
-
第一层的输出:
-
第二层的输出:
将代入到
中,可以得到:
我们可以看到,输出是输入\mathbf{x}的线性变换,因为:
其中
,
。
多层网络的情况
如果有L层,每层都没有激活函数,则第l层的输出为:
通过递归代入,可以得到:
表达式可简化为:
其中,是所有权重矩阵的乘积,
是所有偏置项的线性组合。
如此可以看得出来,无论网络多少层,意味着:
整个网络就是线性模型,无法捕捉数据中的非线性关系。
激活函数是引入非线性特性、使神经网络能够处理复杂问题的关键。
1.2 非线性可视化
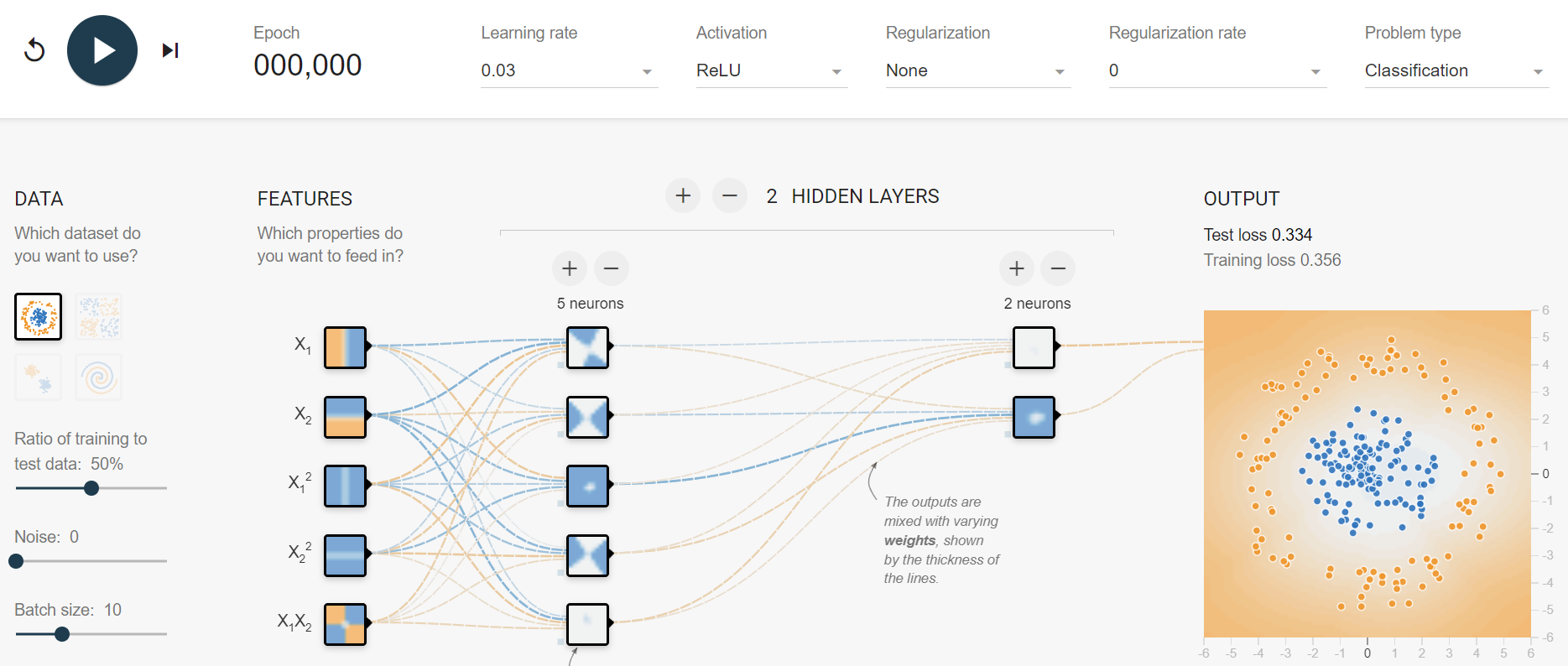
我们可以通过可视化的方式去理解非线性的拟合能力:A Neural Network Playground
2. 常见激活函数
激活函数通过引入非线性来增强神经网络的表达能力,对于解决线性模型的局限性至关重要。由于反向传播算法(BP)用于更新网络参数,因此激活函数必须是可微的,也就是说能够求导的。
2.1 sigmoid
Sigmoid激活函数是一种常见的非线性激活函数,特别是在早期神经网络中应用广泛。它将输入映射到0到1之间的值,因此非常适合处理概率问题。
2.1.1 公式
Sigmoid函数的数学表达式为:
其中,e 是自然常数(约等于2.718),x 是输入。
2.1.2 特征
-
将任意实数输入映射到 (0, 1)之间,因此非常适合处理概率场景。
-
sigmoid函数一般只用于二分类的输出层。
-
微分性质: 导数计算比较方便,可以用自身表达式来表示:
2.1.3 缺点
-
梯度消失:
-
在输入非常大或非常小时,Sigmoid函数的梯度会变得非常小,接近于0。这导致在反向传播过程中,梯度逐渐衰减。
-
最终使得早期层的权重更新非常缓慢,进而导致训练速度变慢甚至停滞。
-
-
信息丢失:输入100和输入10000经过sigmoid的激活值几乎都是等于 1 的,但是输入的数据却相差 100 倍。
-
计算成本高: 由于涉及指数运算,Sigmoid的计算比ReLU等函数更复杂,尽管差异并不显著。
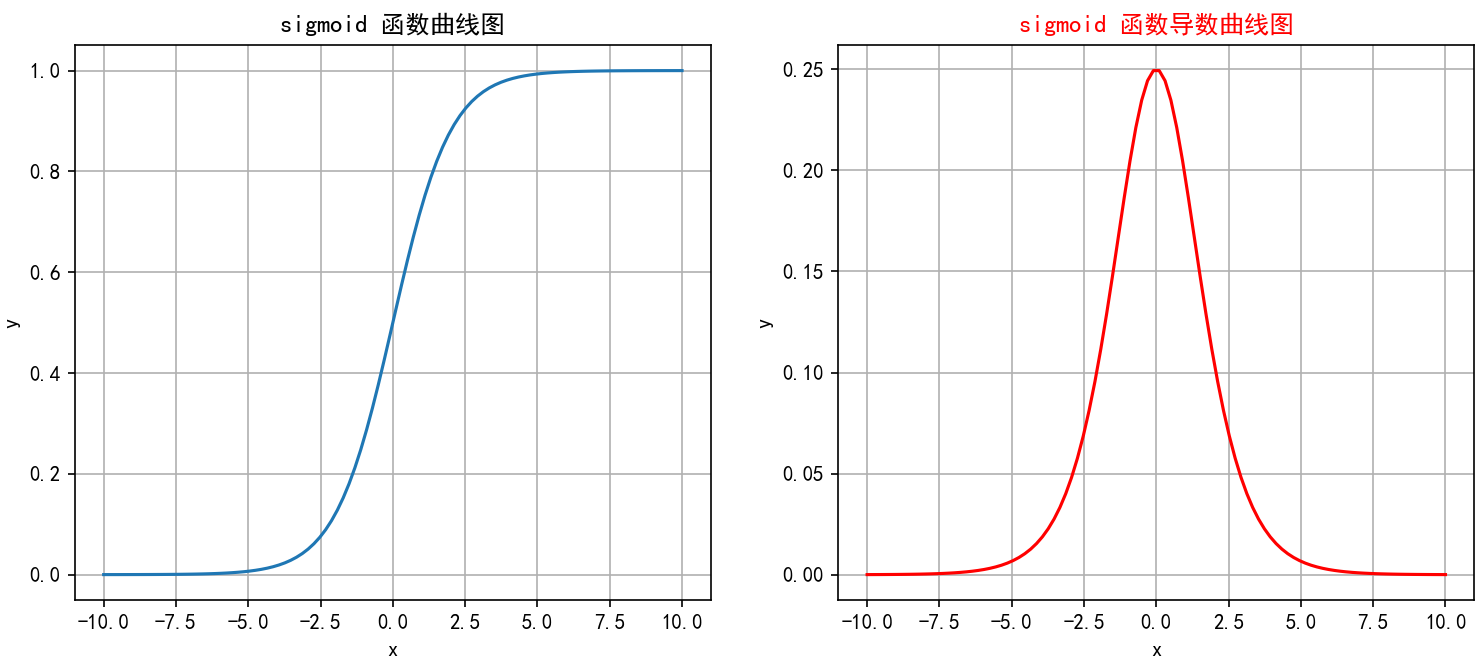
2.1.4 函数绘制
通过代码实现函数和导函数绘制:
import torch
import matplotlib.pyplot as plt# plt支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test001():# 一行两列绘制图像_, ax = plt.subplots(1, 2)# 绘制函数图像x = torch.linspace(-10, 10, 100)y = torch.sigmoid(x)# 网格ax[0].grid(True)ax[0].set_title("sigmoid 函数曲线图")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 在第一行第一列绘制sigmoid函数曲线图ax[0].plot(x, y)# 绘制sigmoid导数曲线图x = torch.linspace(-10, 10, 100, requires_grad=True)# y = torch.sigmoid(x) * (1 - torch.sigmoid(x))# 自动求导torch.sigmoid(x).sum().backward()ax[1].grid(True)ax[1].set_title("sigmoid 函数导数曲线图", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("y")# ax[1].plot(x.detach().numpy(), y.detach())# 用自动求导的结果绘制曲线图ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())# 设置曲线颜色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test001()
运行结果:
2.2 tanh
tanh(双曲正切)是一种常见的非线性激活函数,常用于神经网络的隐藏层。tanh 函数也是一种S形曲线,输出范围为(−1,1)。
2.2.1 公式
tanh数学表达式为:
2.2.2 特征
-
输出范围: 将输入映射到(-1, 1)之间,因此输出是零中心的。相比于Sigmoid函数,这种零中心化的输出有助于加速收敛。
-
对称性: Tanh函数是关于原点对称的奇函数,因此在输入为0时,输出也为0。这种对称性有助于在训练神经网络时使数据更平衡。
-
平滑性: Tanh函数在整个输入范围内都是连续且可微的,这使其非常适合于使用梯度下降法进行优化。
2.2.3 缺点
-
梯度消失: 虽然一定程度上改善了梯度消失问题,但在输入值非常大或非常小时导数还是非常小,这在深层网络中仍然是个问题。这是因为每一层的梯度都会乘以一个小于1的值,经过多层乘积后,梯度会变得非常小,导致训练过程变得非常缓慢,甚至无法收敛。
-
计算成本: 由于涉及指数运算,Tanh的计算成本还是略高,尽管差异不大。
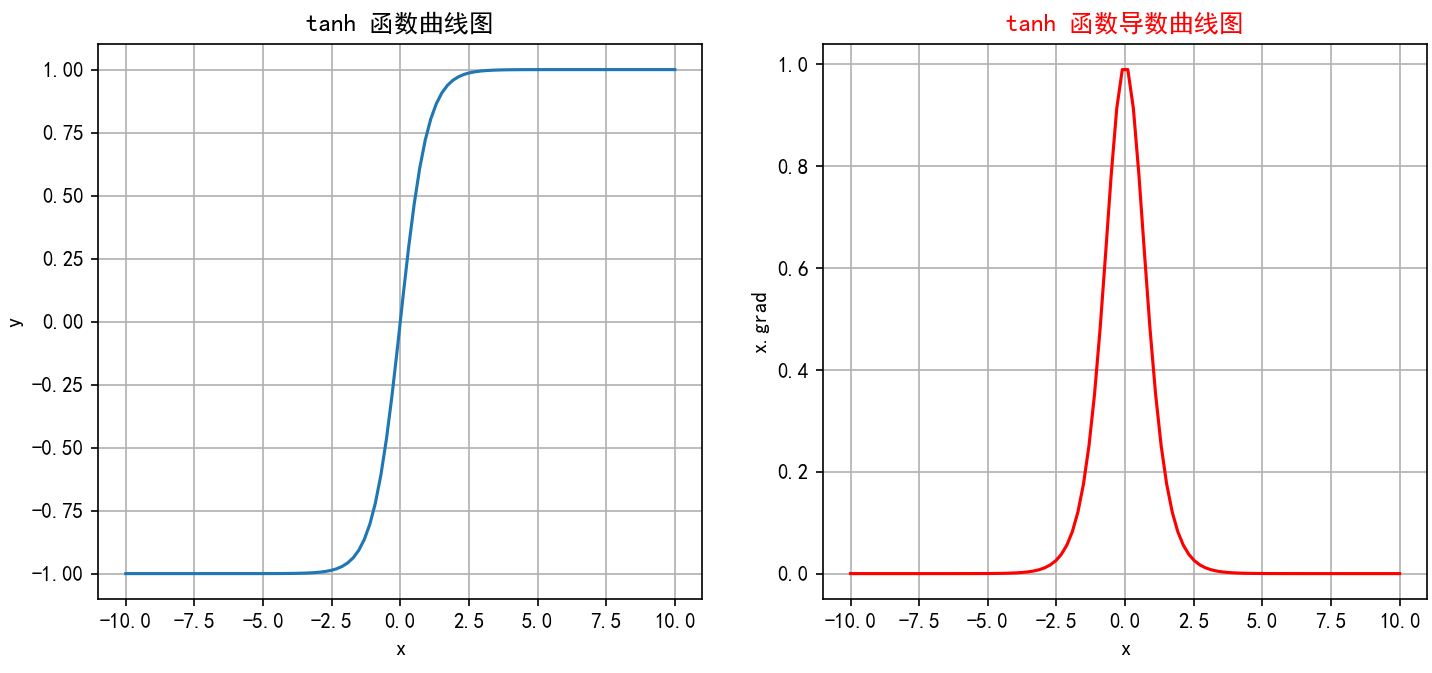
2.2.4 函数绘制
绘制代码:
import torch
import matplotlib.pyplot as plt# plt支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test001():# 一行两列绘制图像_, ax = plt.subplots(1, 2)# 绘制函数图像x = torch.linspace(-10, 10, 100)y = torch.tanh(x)# 网格ax[0].grid(True)ax[0].set_title("tanh 函数曲线图")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 在第一行第一列绘制tanh函数曲线图ax[0].plot(x, y)# 绘制tanh导数曲线图x = torch.linspace(-10, 10, 100, requires_grad=True)# y = torch.tanh(x) * (1 - torch.tanh(x))# 自动求导:需要标量才能反向传播torch.tanh(x).sum().backward()ax[1].grid(True)ax[1].set_title("tanh 函数导数曲线图", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")# ax[1].plot(x.detach().numpy(), y.detach())# 用自动求导的结果绘制曲线图ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())# 设置曲线颜色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test001()
绘制结果:
2.3 ReLU
ReLU(Rectified Linear Unit)是深度学习中最常用的激活函数之一,它的全称是修正线性单元。ReLU 激活函数的定义非常简单,但在实践中效果非常好。
2.3.1 公式
ReLU 函数定义如下:
即ReLU对输入x进行非线性变换:
2.3.2 特征
-
计算简单:ReLU 的计算非常简单,只需要对输入进行一次比较运算,这在实际应用中大大加速了神经网络的训练。
-
ReLU 函数的导数是分段函数:
-
缓解梯度消失问题:相比于 Sigmoid 和 Tanh 激活函数,ReLU 在正半区的导数恒为 1,这使得深度神经网络在训练过程中可以更好地传播梯度,不存在饱和问题。
-
稀疏激活:ReLU在输入小于等于 0 时输出为 0,这使得 ReLU 可以在神经网络中引入稀疏性(即一些神经元不被激活),这种稀疏性可以减少网络中的冗余信息,提高网络的效率和泛化能力。
2.3.3 缺点
神经元死亡:由于ReLU在x≤0时输出为0,如果某个神经元输入值是负,那么该神经元将永远不再激活,成为“死亡”神经元。随着训练的进行,网络中可能会出现大量死亡神经元,从而会降低模型的表达能力。
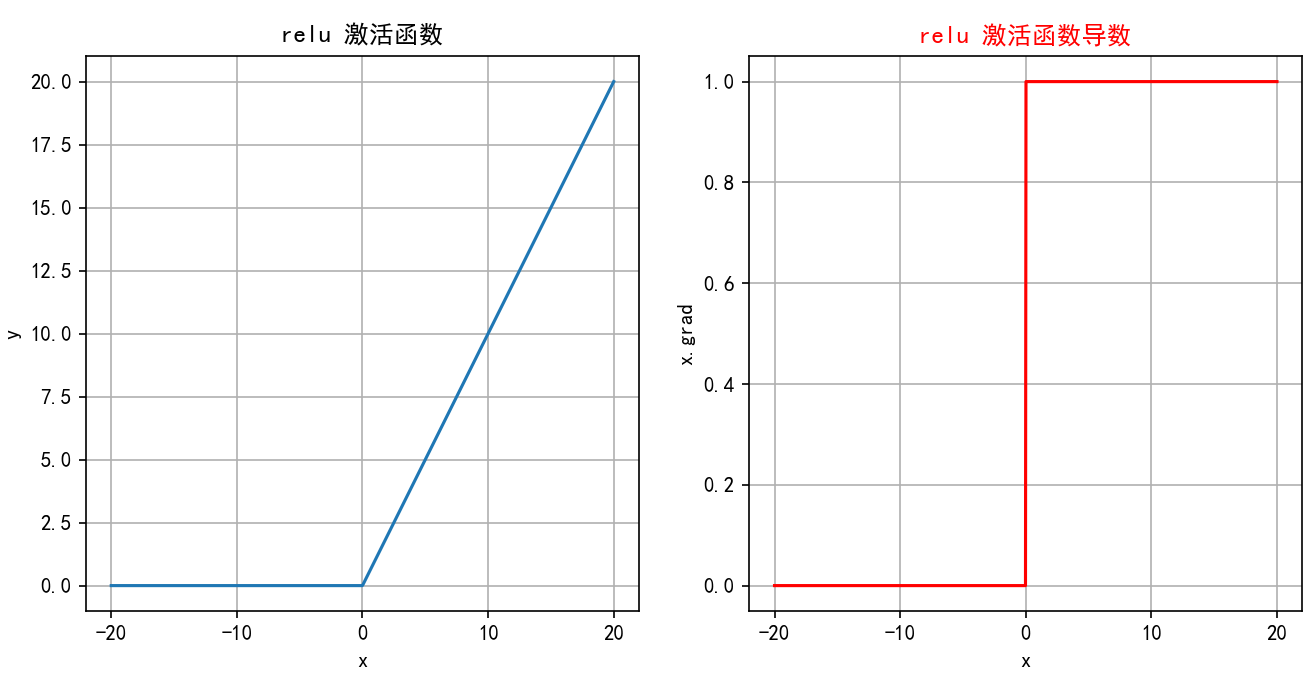
2.3.4 函数绘图
参考代码如下:
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 中文问题
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test006():# 输入数据xx = torch.linspace(-20, 20, 1000)y = F.relu(x)# 绘制一行2列_, ax = plt.subplots(1, 2)ax[0].plot(x.numpy(), y.numpy())# 显示坐标格子ax[0].grid()ax[0].set_title("relu 激活函数")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 绘制导数函数x = torch.linspace(-20, 20, 1000, requires_grad=True)F.relu(x).sum().backward()ax[1].plot(x.detach().numpy(), x.grad.numpy())ax[1].grid()ax[1].set_title("relu 激活函数导数", color="red")# 设置绘制线色颜色ax[1].lines[0].set_color("red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")plt.show()if __name__ == "__main__":test006()执行结果如下:
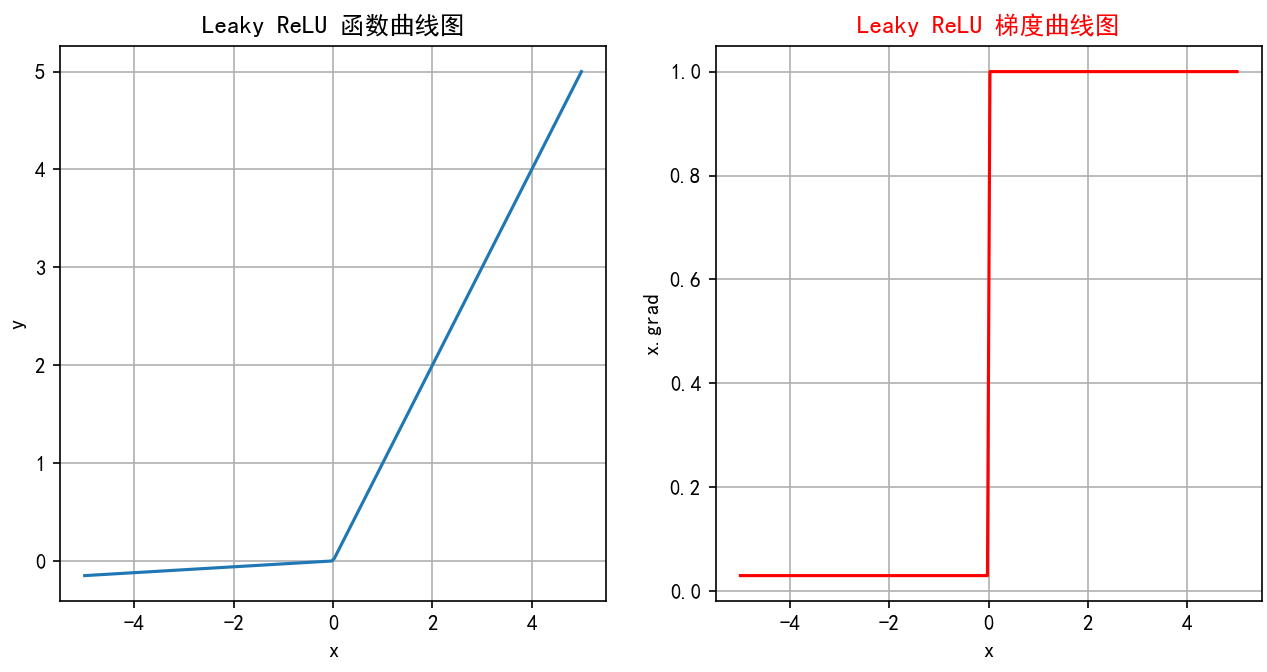
2.4 LeakyReLU
Leaky ReLU是一种对 ReLU 函数的改进,旨在解决 ReLU 的一些缺点,特别是Dying ReLU 问题。Leaky ReLU 通过在输入为负时引入一个小的负斜率来改善这一问题。
2.4.1 公式
Leaky ReLU 函数的定义如下:
其中,是一个非常小的常数(如 0.01),它控制负半轴的斜率。这个常数
是一个超参数,可以在训练过程中可自行进行调整。
2.4.2 特征
-
避免神经元死亡:通过在
区域引入一个小的负斜率,这样即使输入值小于等于零,Leaky ReLU仍然会有梯度,允许神经元继续更新权重,避免神经元在训练过程中完全“死亡”的问题。
-
计算简单:Leaky ReLU 的计算与 ReLU 相似,只需简单的比较和线性运算,计算开销低。
2.4.3 缺点
-
参数选择:
是一个需要调整的超参数,选择合适的\alpha 值可能需要实验和调优。
-
出现负激活:如果
2.4.4 函数绘制
参考代码:
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 中文设置
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test006():x = torch.linspace(-5, 5, 200)# 设置leaky_relu的负斜率超参数slope = 0.03y = F.leaky_relu(x, slope)# 一行两列_, ax = plt.subplots(1, 2)# 开始绘制函数曲线图ax[0].plot(x, y)ax[0].set_title("Leaky ReLU 函数曲线图")ax[0].set_xlabel("x")ax[0].set_ylabel("y")ax[0].grid(True)# 绘制leaky_relu的梯度曲线图x = torch.linspace(-5, 5, 200, requires_grad=True)F.leaky_relu(x, slope).sum().backward()ax[1].plot(x.detach().numpy(), x.grad)ax[1].set_title("Leaky ReLU 梯度曲线图", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")ax[1].grid(True)# 设置线的颜色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test006()
运行结果:
2.5 softmax
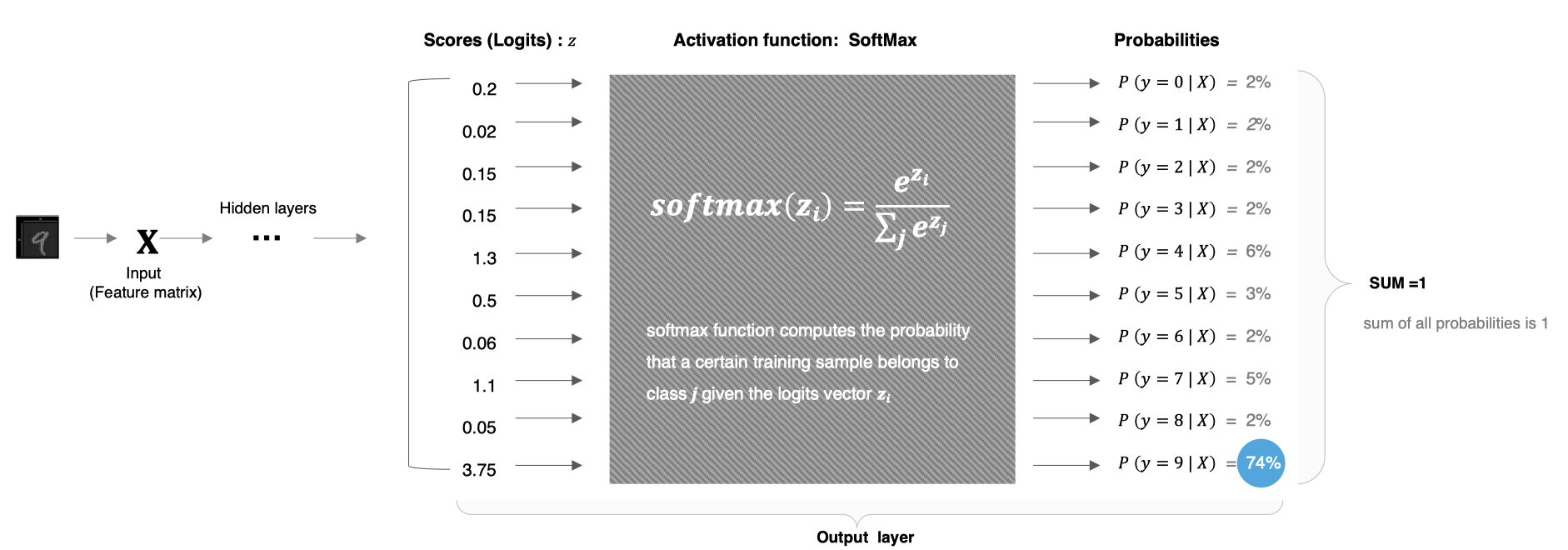
Softmax激活函数通常用于分类问题的输出层,它能够将网络的输出转换为概率分布,使得输出的各个类别的概率之和为 1。Softmax 特别适合用于多分类问题。
2.5.1 公式
假设神经网络的输出层有n个节点,每个节点的输入为z_i,则 Softmax 函数的定义如下:
给定输入向量
1.指数变换:对每个 z_i进行指数变换,得到 ,使z的取值区间从
变为
2.将所有指数变换后的值求和,得到
3.将t中每个 除以归一化因子s,得到概率分布:
即:
从上述公式可以看出:
-
每个输出值在 (0,1)之间
-
Softmax()对向量的值做了改变,但其位置不变
-
所有输出值之和为1,即
2.5.2 特征
-
将输出转化为概率:通过Softmax,可以将网络的原始输出转化为各个类别的概率,从而可以根据这些概率进行分类决策。
-
概率分布:Softmax的输出是一个概率分布,即每个输出值
都是一个介于0和1之间的数,并且所有输出值的和为 1:
-
突出差异:Softmax会放大差异,使得概率最大的类别的输出值更接近1,而其他类别更接近0。
-
在实际应用中,Softmax常与交叉熵损失函数Cross-Entropy Loss结合使用,用于多分类问题。在反向传播中,Softmax的导数计算是必需的。

2.5.3 缺点
-
数值不稳定性:在计算过程中,如果z_i的数值过大,e^{z_i}可能会导致数值溢出。因此在实际应用中,经常会对z_i进行调整,如减去最大值以确保数值稳定。
解释:
是一个非正数,由于
的形式,当
接近
时,
的值会接近 1,而当
这种调整不会改变Softmax的概率分布结果,因为从数学的角度讲相当于分子、分母都除以了
。
在 PyTorch 中,torch.nn.functional.softmax 函数就自动处理了数值稳定性问题。
-
难以处理大量类别:Softmax在处理类别数非常多的情况下(如大模型中的词汇表)计算开销会较大。
2.5.4 代码实现
代码参考如下:
import torch
import torch.nn as nn# 表示4分类,每个样本全连接后得到4个得分,下面示例模拟的是两个样本的得分
input_tensor = torch.tensor([[-1.0, 2.0, -3.0, 4.0], [-2, 3, -3, 9]])softmax = nn.Softmax()
output_tensor = softmax(input_tensor)
# 关闭科学计数法
torch.set_printoptions(sci_mode=False)
print("输入张量:", input_tensor)
print("输出张量:", output_tensor)
输出结果:
输入张量: tensor([[-1., 2., -3., 4.],[-2., 3., -3., 9.]])
输出张量: tensor([[ 0.0059, 0.1184, 0.0008, 0.8749],[ 0.0000, 0.0025, 0.0000, 0.9975]])3. 如何选择
更多激活函数可以查看官方文档:torch.nn — PyTorch 2.6 documentation
那这么多激活函数应该如何选择呢?实际没那么纠结
3.1 隐藏层
-
优先选ReLU;
-
如果ReLU效果不咋地,那么尝试其他激活,如Leaky ReLU等;
-
使用ReLU时注意神经元死亡问题, 避免出现过多神经元死亡;
-
不使用sigmoid,尝试使用tanh;
3.2 输出层
-
二分类问题选择sigmoid激活函数;
-
多分类问题选择softmax激活函数;