【从零实现高并发内存池】申请、释放内存过程联调测试 与 大于256KB内存申请全攻略
📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、申请内存过程联调测试
- 🏳️🌈二、释放内存过程联调测试
- 🏳️🌈三、大于256KB内存申请
- 👥总结
11111111
11111111
11111111
11111111
**** 11111111
测试代码
void TestConcurrentAlloc1() {void* p1 = ConcurrentAlloc(6);void* p2 = ConcurrentAlloc(8);void* p3 = ConcurrentAlloc(1);void* p4 = ConcurrentAlloc(7);void* p5 = ConcurrentAlloc(8);cout << p1 << endl;cout << p2 << endl;cout << p3 << endl;cout << p4 << endl;cout << p5 << endl;ConcurrentFree(p1, 6);ConcurrentFree(p2, 8);ConcurrentFree(p3, 1);ConcurrentFree(p4, 7);ConcurrentFree(p5, 8);
}
🏳️🌈一、申请内存过程联调测试
此处进行调试,我们需要调用封装的申请内存函数 ConcurrentAlloc()。每个线程第一次调用该函数都会通过TLS获取到自己专属的thread cache对象,然后每个线程就可以通过自己对应的thread cache申请对象了。
static void* ConcurrentAlloc(size_t size)
{// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}
当线程第一次申请内存时,需要通过TLS获取到自己专属的thread cache对象,然后通过thread cache对象进行内存申请。
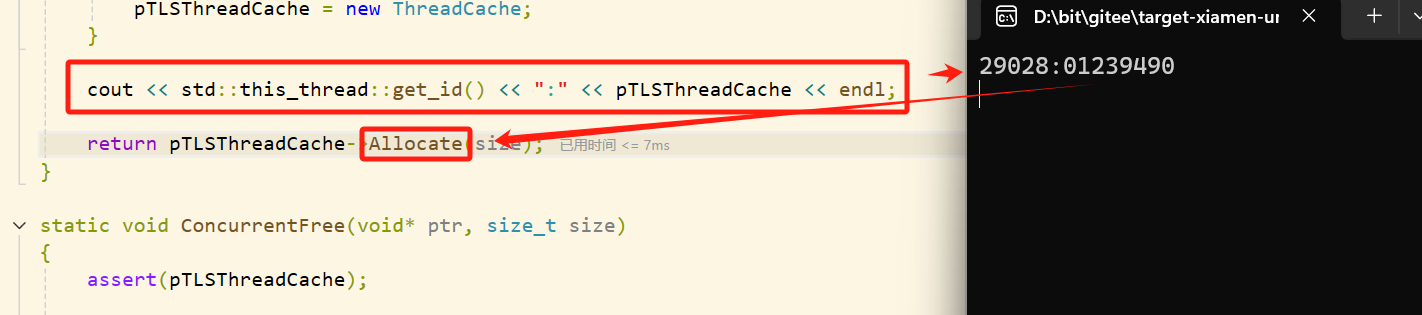
我们第一个申请的内存大小是
6字节经过 内存对齐 和 索引查找 后, 最后得到的结果是需要向0号桶中申请8字节的内存
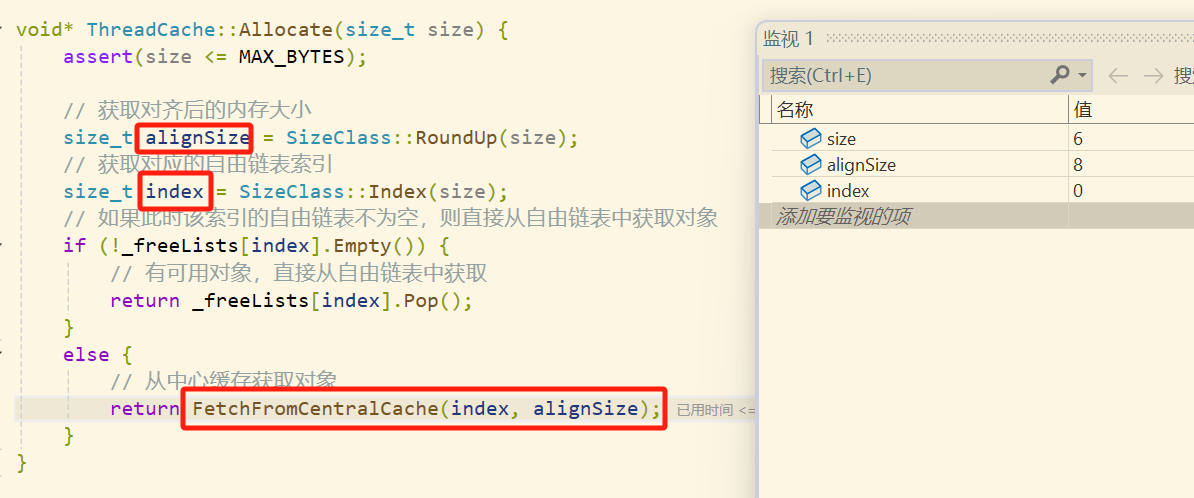
之后我们会进入慢反馈环节,先计算要向
central cache申请多少个对象,因为这是第一次申请,所以只需要一个8字节对象
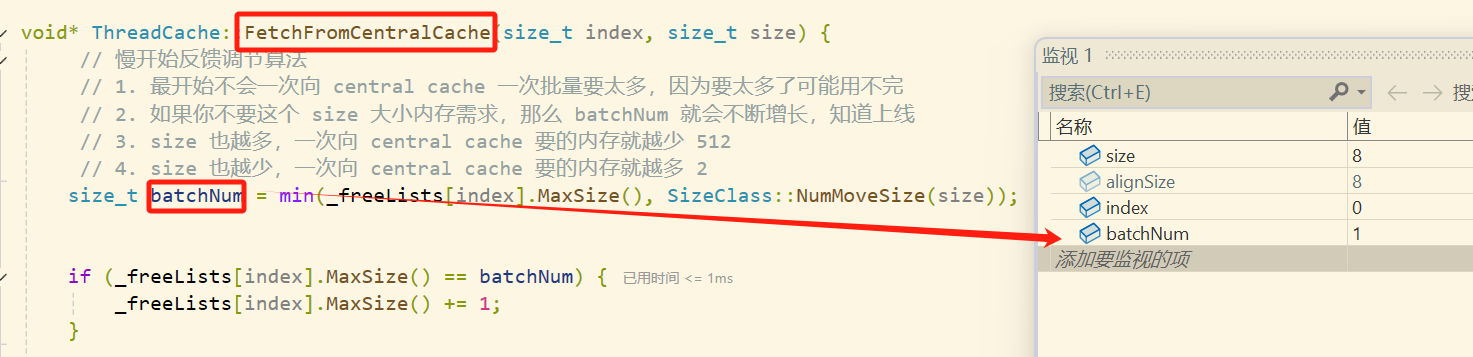
这里需要注意一点
然后满反馈环节发力,下一次申请 2 个对象,在下次申请 3 个,一直到512 个对象为止。 就比如说,我们这里依次创建在0号桶中创建了5个对象(这5个对象的大小都不超过8字节),按 1 + 2 + 3来说,我们就一共申请到了 6 个 8字节 的内存块,所以,当我们释放空间回自由链表的时候,0号桶中还剩余1个内存块

在thread cache向central cache申请对象之前,需要先将central cache的0号桶的锁加上,然后再从该桶获取一个非空的span。

在
central cache的第0号桶获取非空span时,先遍历对应的span双链表,看看有没有非空的span,但此时肯定是没有的,只能找page cache要
此时
central cache就需要向page cache申请内存了,但在此之前需要先把central cache第0号桶的锁解掉,然后再将page cache的大锁给加上,之后才能向page cache申请内存。
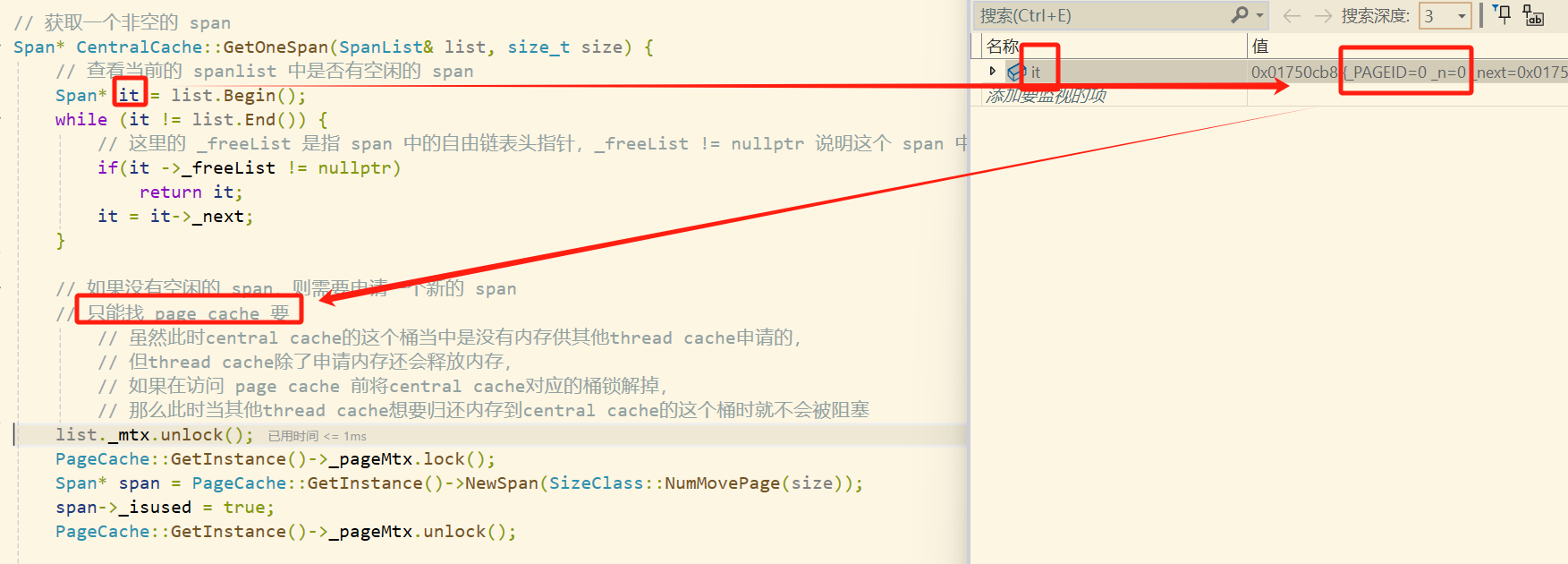
在向
page cache申请内存时,由于central cache一次给thread cache8字节对象的上限是512,对应就需要4096字节,所需字节数不足一页就按一页算,所以这里central cache就需要向page cache申请一页的内存块。
此时page cache的第1个桶以及之后的桶当中都是没有span的,因此page cache需要直接向堆申请一个128页的span。

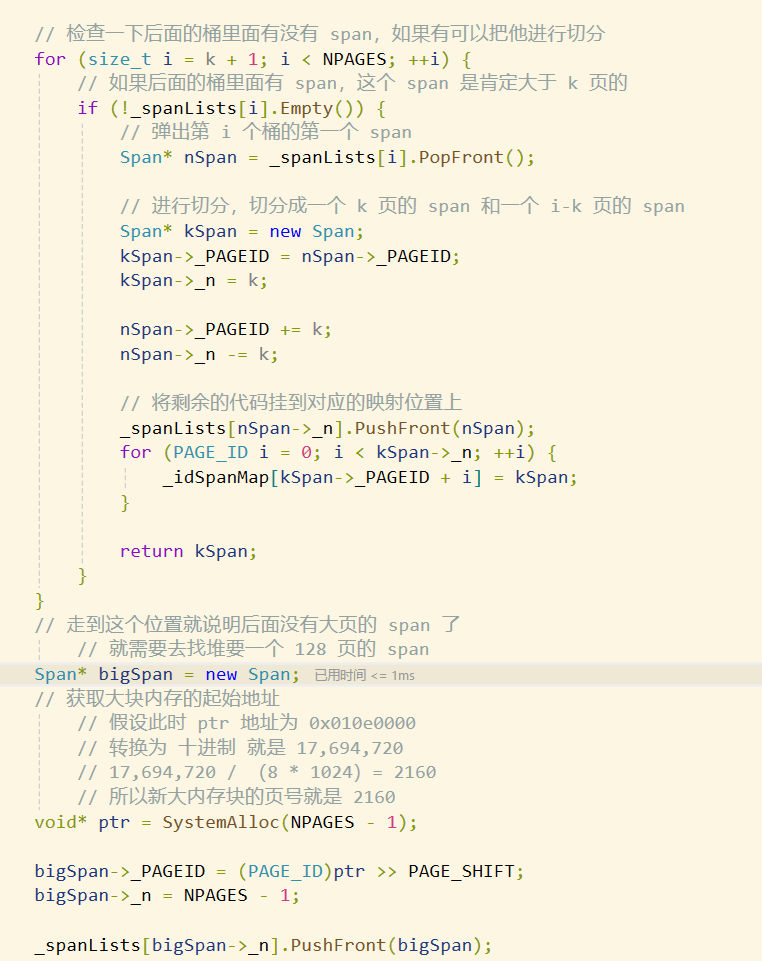
而 page cache 向对申请内存的途径就是利用库函数了
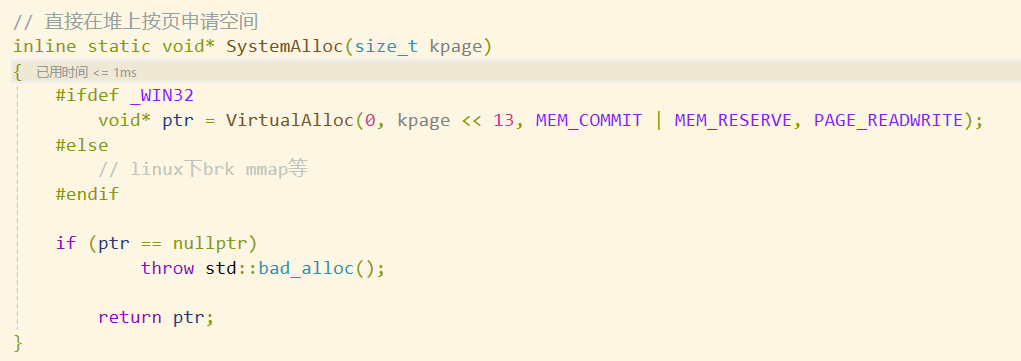
这之后我们就可以观察到,申请到了128页的内存块

这里的 _PAGEID 的算法可以演示一下,其实就是得到的内存块地址 除上 8K 的大小
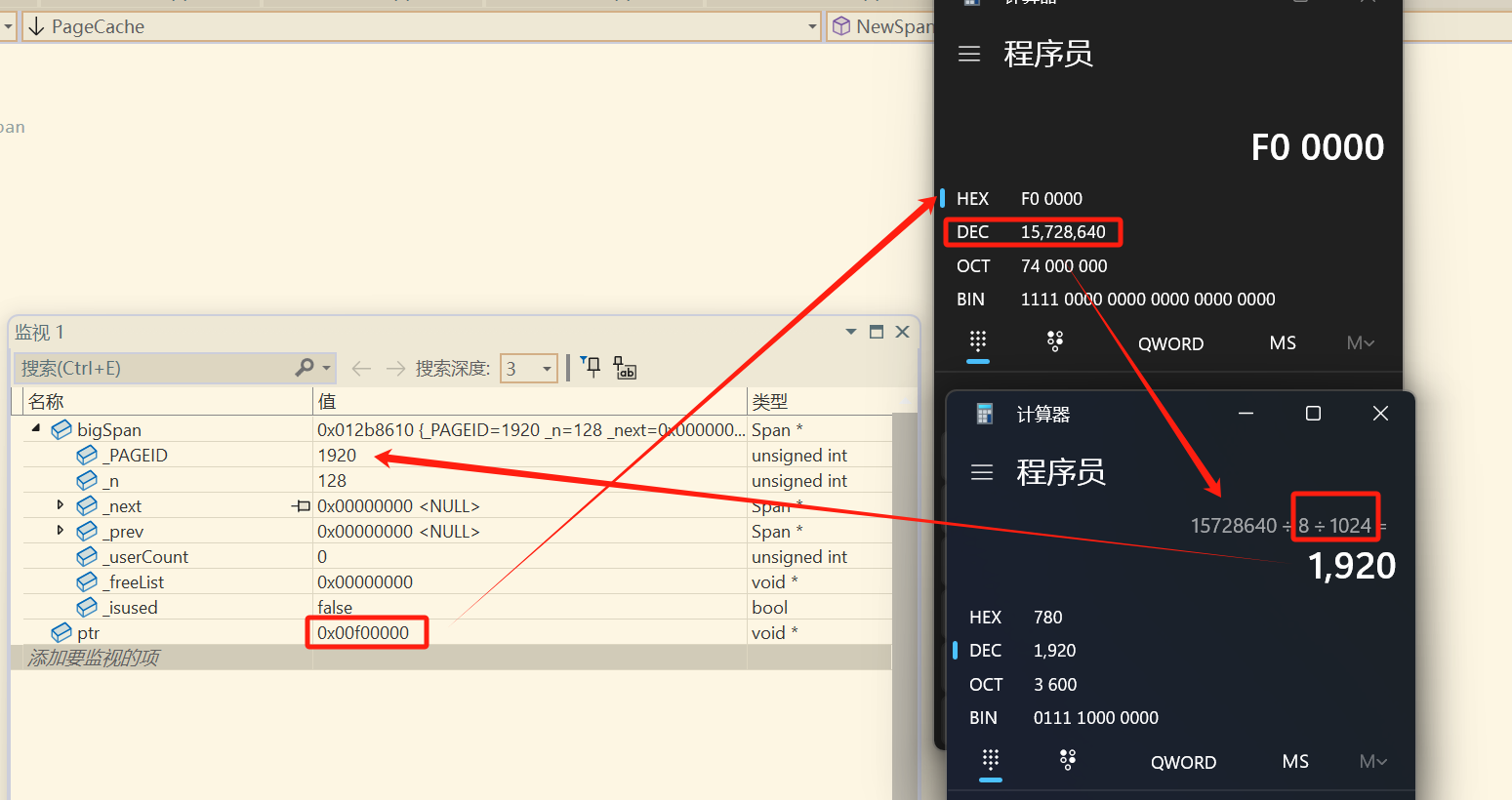
然后我们将这个 128页 直接挂在 pagecache 上,虽然页数为 1 的哈希桶中依然没有内存,但是在页数为 128 的桶中,有刚刚挂上的新内存条
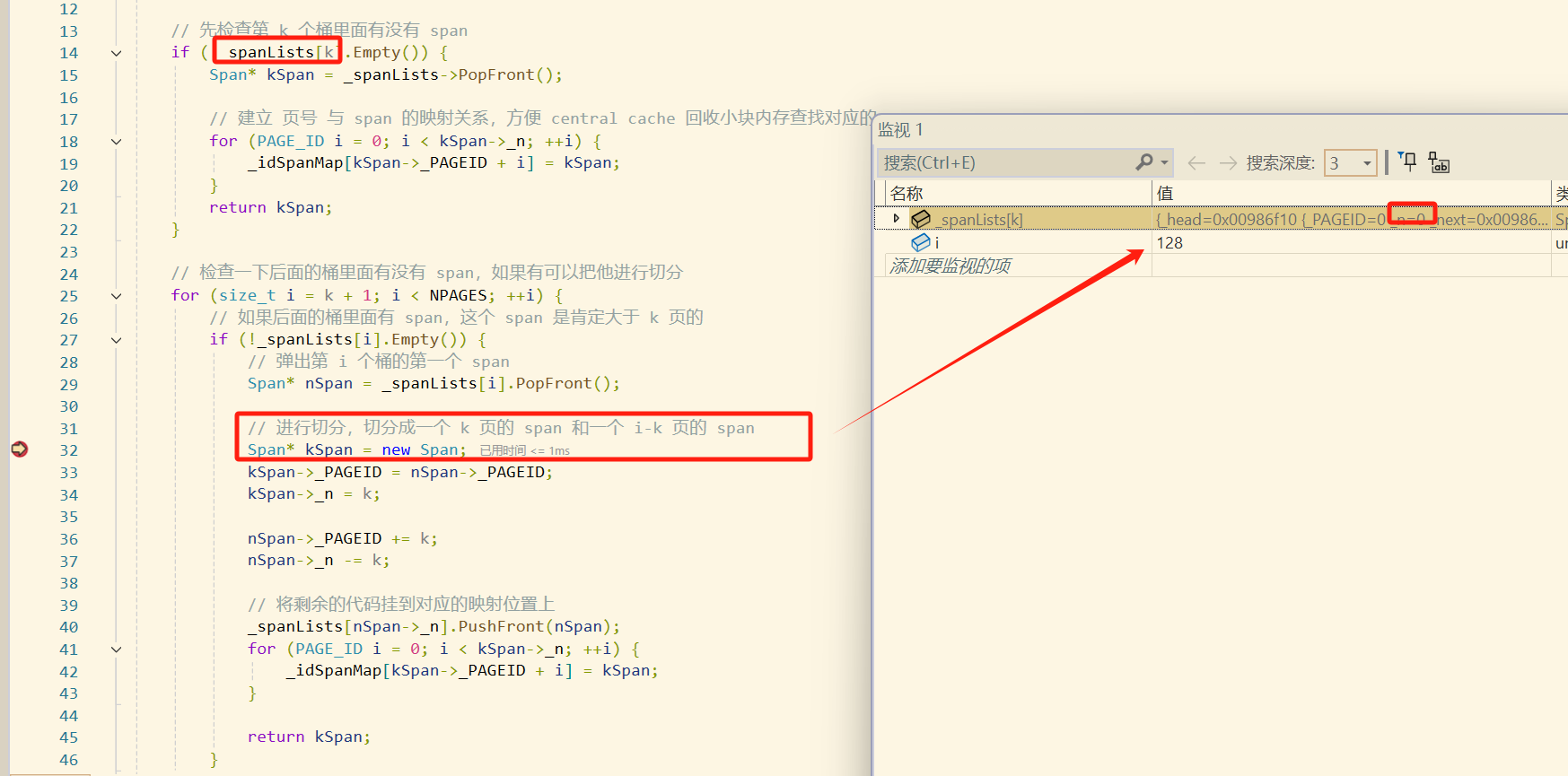
此时我们就可以把这个128页的span拿出来,切分成1页的span和127页的span,将1页的span返回给central cache,而把127页的span挂到page cache的第127号桶即可。
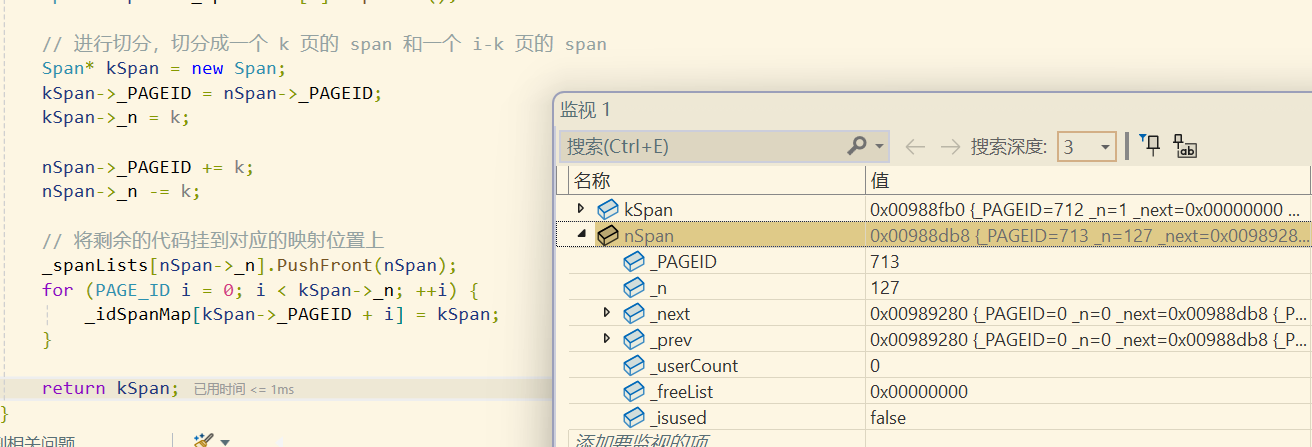
从page cache返回后,就可以把page cache的大锁解掉了,但紧接着还要将获取到的1页的span进行切分,因此这里没有立刻重新加上central cache对应的桶锁。

在进行切分的时候,先通过该span的起始页号得到该span的起始地址,然后通过该span的页数得到该span所管理内存块的总的字节数。

在确定内存块的开始和结束后,就可以将其切分成一个个8字节大小的对象挂到该span的自由链表中了。在调试过程中通过内存监视窗口可以看到,切分出来的每个8字节大小的对象的前四个字节存储的都是下一个8字节对象的起始地址。
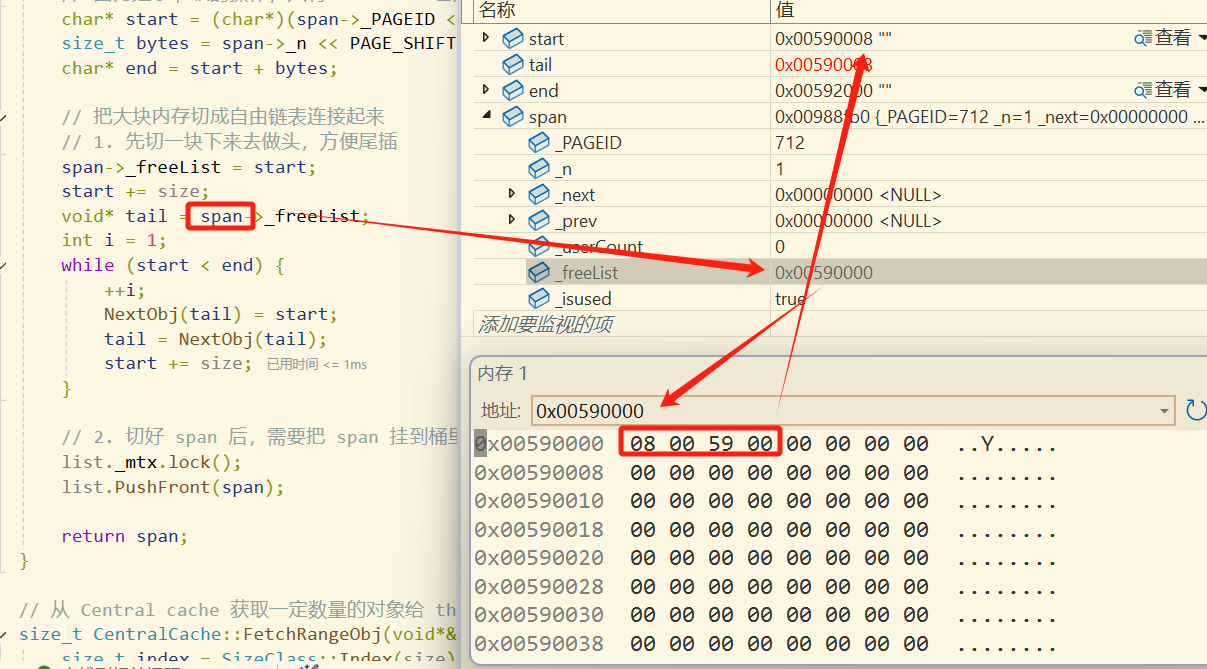
当切分结束后再开启central cache第0号桶的桶锁,然后将这个切好的span插入到central cache的第0号桶中,最后再将这个非空的span返回,此时就获取到了一个非空的span,并且这个 span 中每 8字节都会有连接
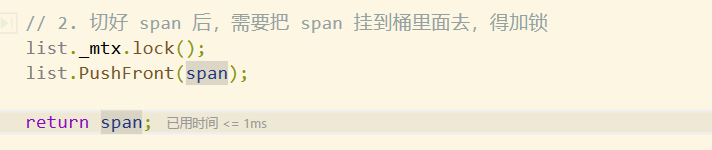
由于thread cache只向central cache申请了一个对象,因此拿到这个非空的span后,直接从这个span里面取出一个对象即可,此时该span的_useCount也由0变成了1。
由于此时thread cache实际只向central cache申请到了一个对象,因此直接将这个对象返回给线程即可。
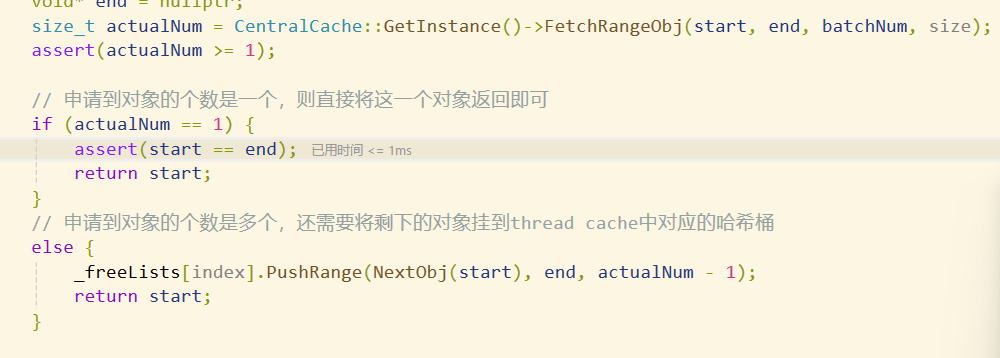
然后 p2 申请内存就会申请 2 个对象,在p4申请时又会申请3个对象,以此类推
🏳️🌈二、释放内存过程联调测试
刚刚申请完了5个8字节内存,现在将他们释放看看。
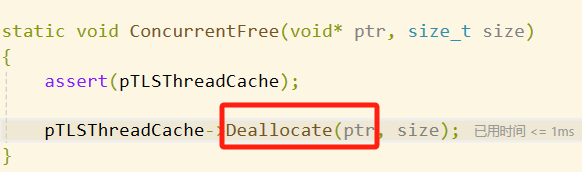
调用
thread cache的deallocate方法
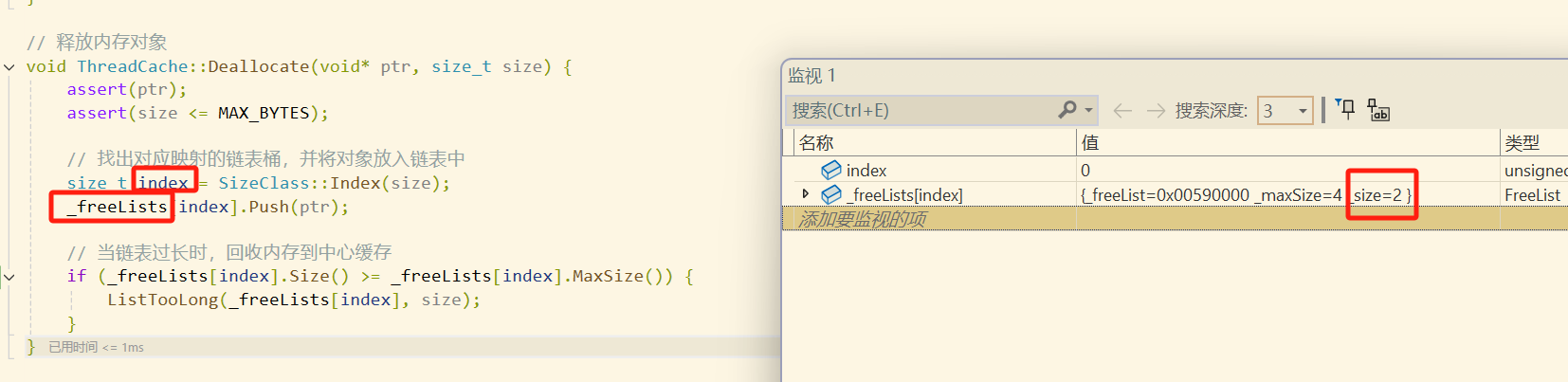
此时可以看到当我们将第一块内存返回到自由链表时,0号自由链表内的8字节内存块有2块,其中一块是刚刚还回来,另一块是之前p4申请时剩下的那一块
所以得一直到p3释放时,才会进入 将
自由链表内的过长内存块还给central cache的情况
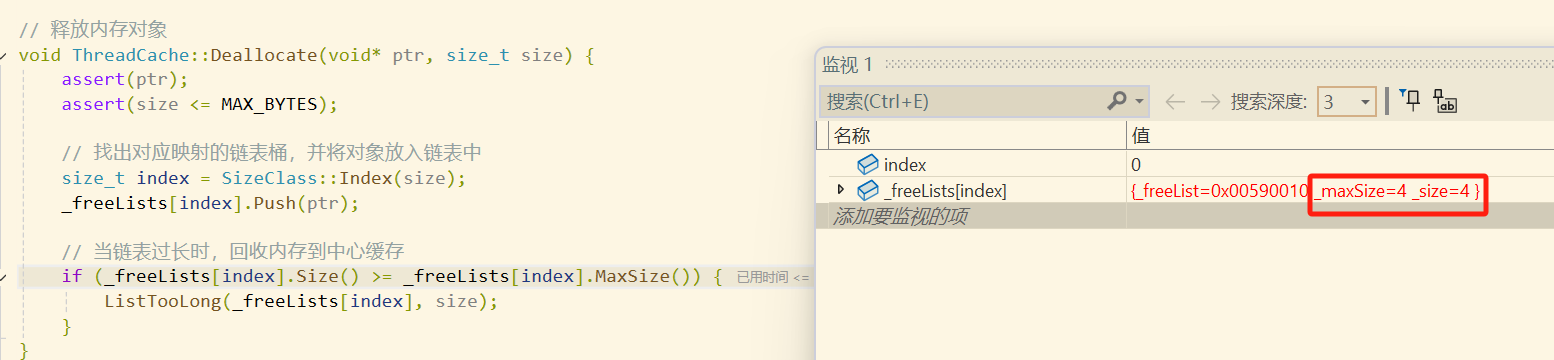
thread cache先是将第0号桶当中的对象弹出MaxSize个,在这里实际上就是全部弹出,此时该自由链表_size的值变为0,然后继续调用central cache当中的ReleaseListToSpans函数,将这三个对象还给central cache当中对应的span。
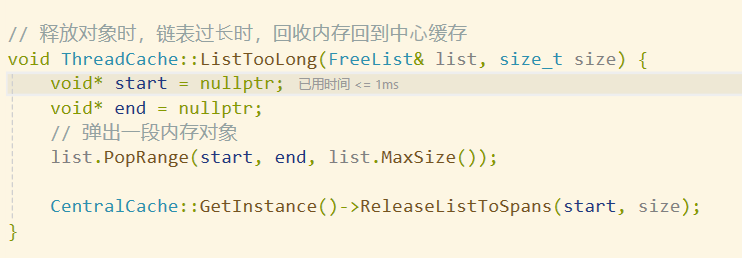
在进入
central cache的第0号桶还对象之前,先把第0号桶对应的桶锁加上,然后通过查page cache中的映射表找到其对应的span,最后将这个对象头插到该span的自由链表中,并将该span的_useCount进行–。当第一个对象还给其对应的span时,可以看到该span的_useCount减到了2。
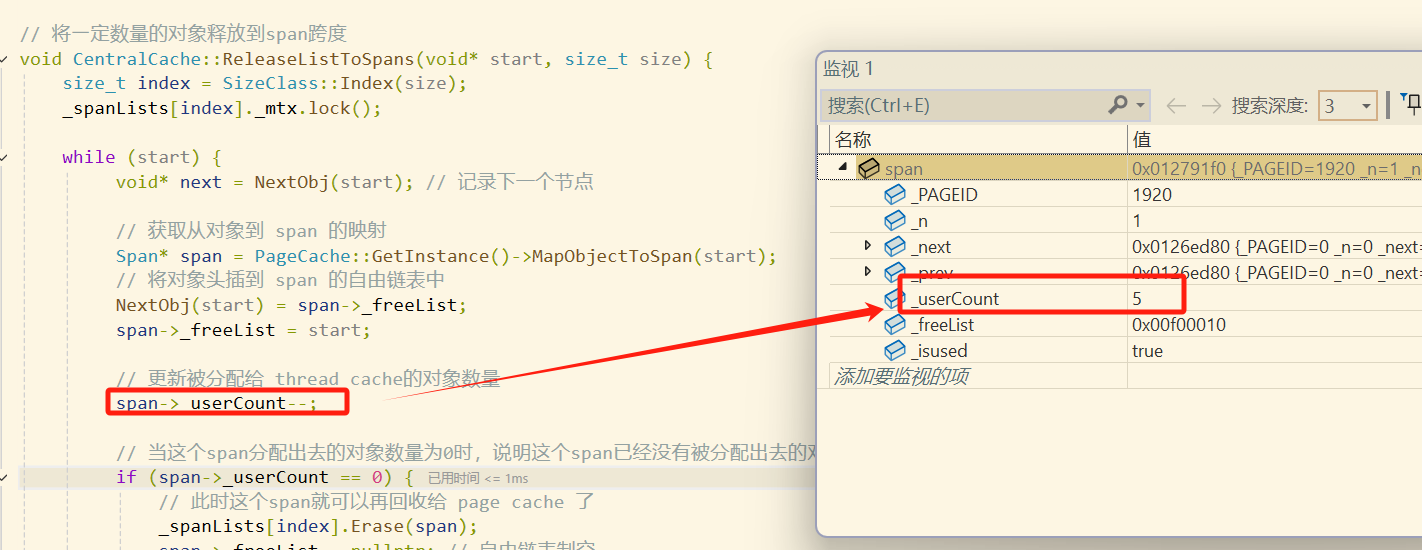 > 由于我们只进行了 5 次对象申请,并且这些对象大小对齐后大小都是8字节,因此我们申请一个span里的6个块。当我们将这三个对象都还给这个span时,以及多出的那个=一个,该span的_useCount就减为了2。
> 由于我们只进行了 5 次对象申请,并且这些对象大小对齐后大小都是8字节,因此我们申请一个span里的6个块。当我们将这三个对象都还给这个span时,以及多出的那个=一个,该span的_useCount就减为了2。
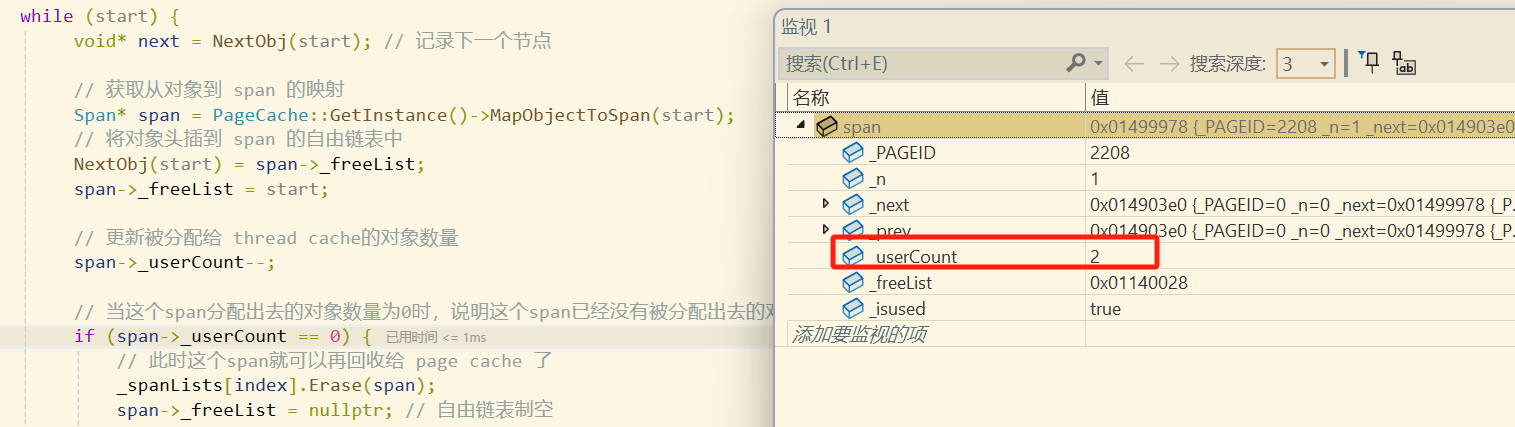
但是现在这种情况无法返回给 page cahce,我们需要一个完整的span吗,也就是userCount 为 0 的才可以。于是我们将 创建5 个内存块变成创建 3 个内存块
现在
central cache就需要将这个span进一步还给page cache,而在将该span交给page cache之前,会将该span的自由链表以及前后指针都置空。并且在进入page cache之前会先将central cache第0号桶的桶锁解掉,然后再加上page cache的大锁,之后才能进入page cache进行相关操作。
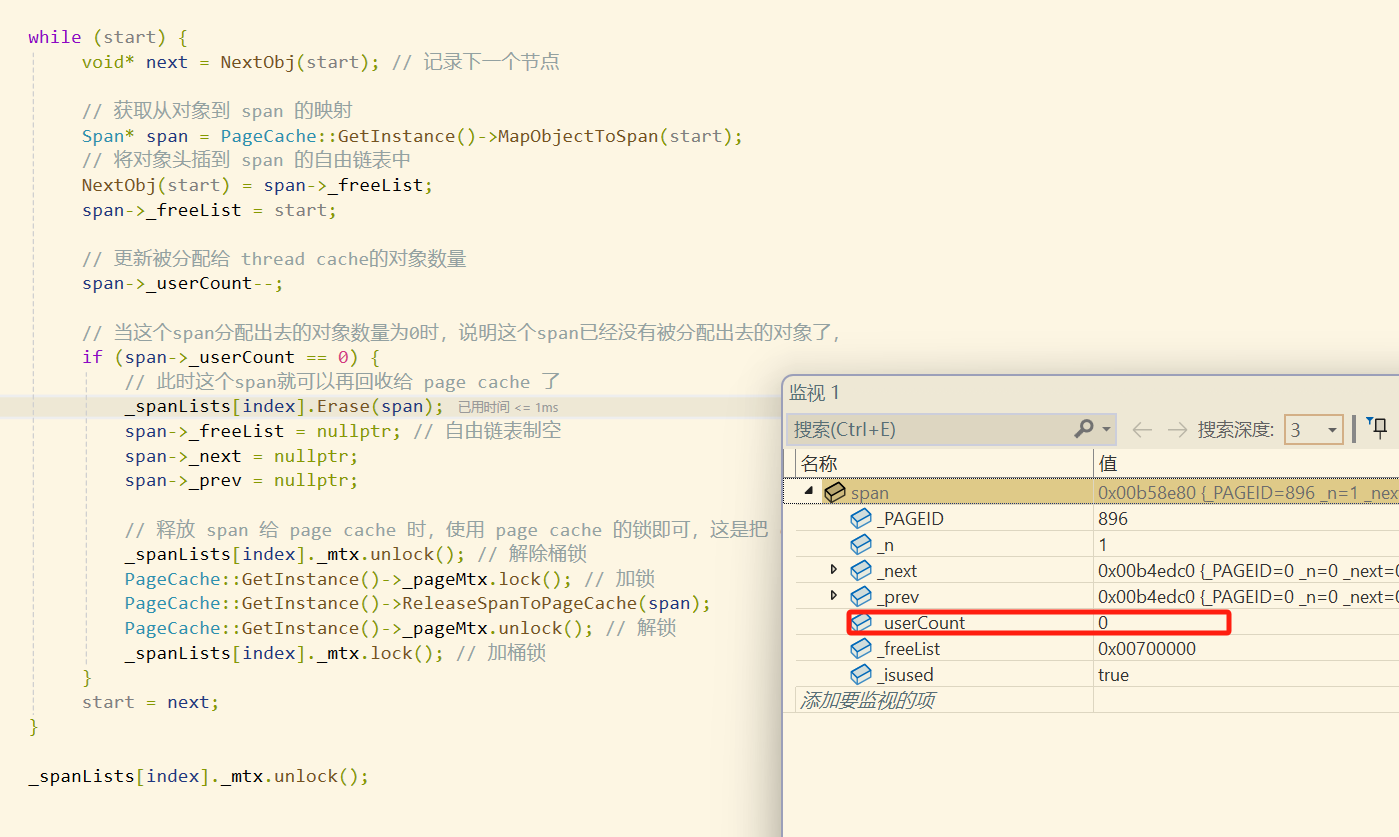
由于这个一页的span是从128页的span的头部切下来的,在向前合并时由于前面的页还未向系统申请,因此在查映射关系时是无法找到的,此时直接停止了向前合并。 同理, 在向后合并时由于后面的页还未向系统申请,因此在查映射关系时是无法找到的,此时直接停止了向后合并
将这个1页的span插入到第1号桶,然后建立该span与其首尾页的映射,便于下次被用于合并,最后再将该span的状态设置为未被使用的状态即可。
🏳️🌈三、大于256KB内存申请
前面说到,每个线程的thread cache是用于申请小于等于256KB的内存的,而对于大于256KB的内存,我们可以考虑直接向page cache申请,但page cache中最大的页也就只有128页,因此如果是大于128页的内存申请,就只能直接向堆申请了

注意:当申请的内存大于256KB时,虽然不是从thread cache进行获取,但在分配内存时也是需要进行向上对齐的,对于大于256KB的内存我们可以直接按页进行对齐。
// 计算对齐后的内存大小static inline size_t RoundUp(size_t size) {if (size <= 128) {return _RoundUp(size, 8); // 对齐到 8 字节}else if (size <= 1024) {return _RoundUp(size, 16); // 对齐到 16 字节}else if (size <= 8 * 1024) {return _RoundUp(size, 128); // 对齐到 128 字节}else if (size <= 64 * 1024) {return _RoundUp(size, 1024);}else if (size <= 256 * 1024) {return _RoundUp(size, 8 * 1024);}else {return _RoundUp(size, 1 << PAGE_SHIFT);}}
对于之前的申请对象的逻辑就需要进行修改了,当申请对象的大小大于256KB时,就不用向thread cache申请了,这时先计算出按页对齐后实际需要申请的页数,然后通过调用NewSpan申请指定页数的span即可。
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES) {size_t alignSize = SizeClass::RoundUp(size);size_t kpage = alignSize >> PAGE_SHIFT;PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kpage);PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_PAGEID << PAGE_SHIFT);return ptr;}// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}
也就是说,申请大于256KB的内存时,会直接调用page cache当中的NewSpan函数进行申请 ,因此这里我们需要再对NewSpan函数进行改造,当需要申请的内存页数大于128页时,就直接向堆申请对应页数的内存块。而如果申请的内存页数是小于128页的,那就在page cache中进行申请,因此当申请大于256KB的内存调用NewSpan函数时也是需要加锁的,因为我们可能是在page cache中进行申请的。
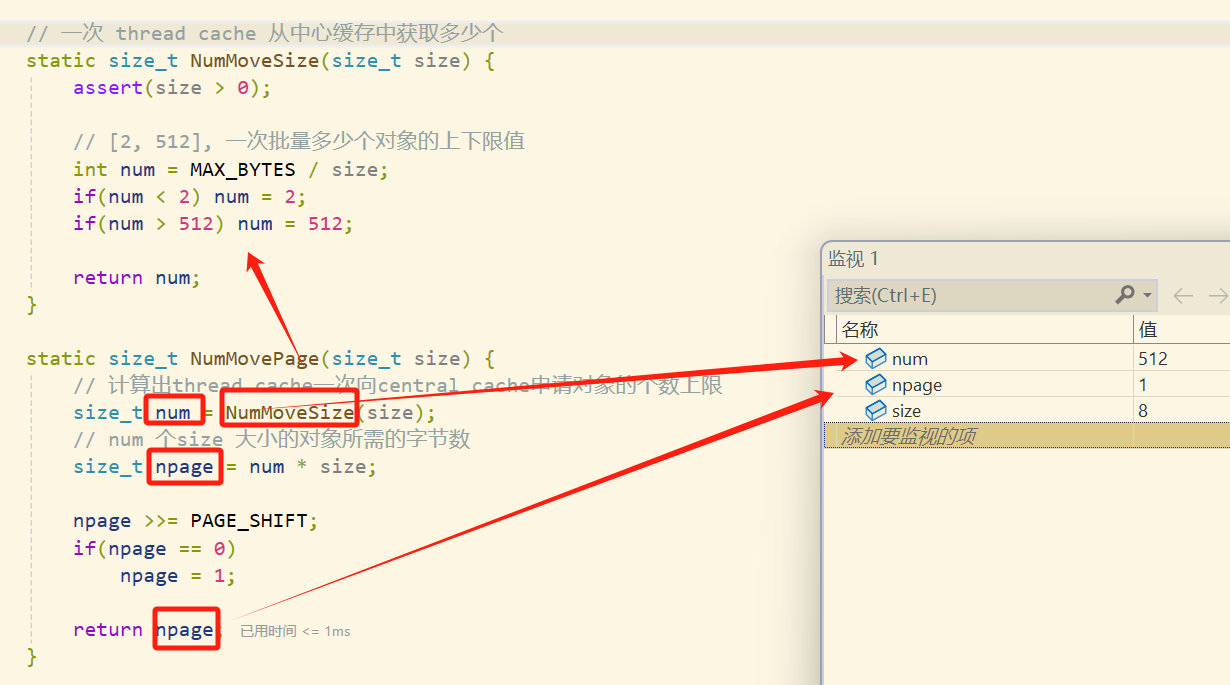
// 获取一个 k 页的 span
Span* PageCache::NewSpan(size_t k) {assert(k > 0);if (k > NPAGES - 1) {void* ptr = SystemAlloc(k);Span* span = new Span;span->_PAGEID = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;_idSpanMap[span->_PAGEID] = span;return span;}// 先检查第 k 个桶里面有没有 spanif (!_spanLists[k].Empty()) {Span* kSpan = _spanLists->PopFront();// 建立 页号 与 span 的映射关系,方便 central cache 回收小块内存查找对应的 spanfor (PAGE_ID i = 0; i < kSpan->_n; ++i) {_idSpanMap[kSpan->_PAGEID + i] = kSpan;}return kSpan;}// 检查一下后面的桶里面有没有 span,如果有可以把他进行切分for (size_t i = k + 1; i < NPAGES; ++i) {// 如果后面的桶里面有 span,这个 span 是肯定大于 k 页的if (!_spanLists[i].Empty()) {// 弹出第 i 个桶的第一个 spanSpan* nSpan = _spanLists[i].PopFront();// 进行切分,切分成一个 k 页的 span 和一个 i-k 页的 spanSpan* kSpan = new Span;kSpan->_PAGEID = nSpan->_PAGEID;kSpan->_n = k;nSpan->_PAGEID += k;nSpan->_n -= k;// 将剩余的代码挂到对应的映射位置上_spanLists[nSpan->_n].PushFront(nSpan);for (PAGE_ID i = 0; i < kSpan->_n; ++i) {_idSpanMap[kSpan->_PAGEID + i] = kSpan;}return kSpan;}}// 走到这个位置就说明后面没有大页的 span 了// 就需要去找堆要一个 128 页的 spanSpan* bigSpan = new Span;// 获取大块内存的起始地址// 假设此时 ptr 地址为 0x010e0000// 转换为 十进制 就是 17,694,720// 17,694,720 / (8 * 1024)= 2160// 所以新大内存块的页号就是 2160void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_PAGEID = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);
}
因此当释放对象时,我们需要先找到该对象对应的span,但是在释放对象时我们只知道该对象的起始地址。这也就是我们在申请大于256KB的内存时,也要给申请到的内存建立span结构,并建立起始页号与该span之间的映射关系的原因。此时我们就可以通过释放对象的起始地址计算出起始页号,进而通过页号找到该对象对应的span。
// 在堆上释放空间
inline static void SystemFree(void* ptr)
{#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);#else// linux下brk mmap等#endif
}static void ConcurrentFree(void* ptr, size_t size){if (size > MAX_BYTES) {Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else {assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}
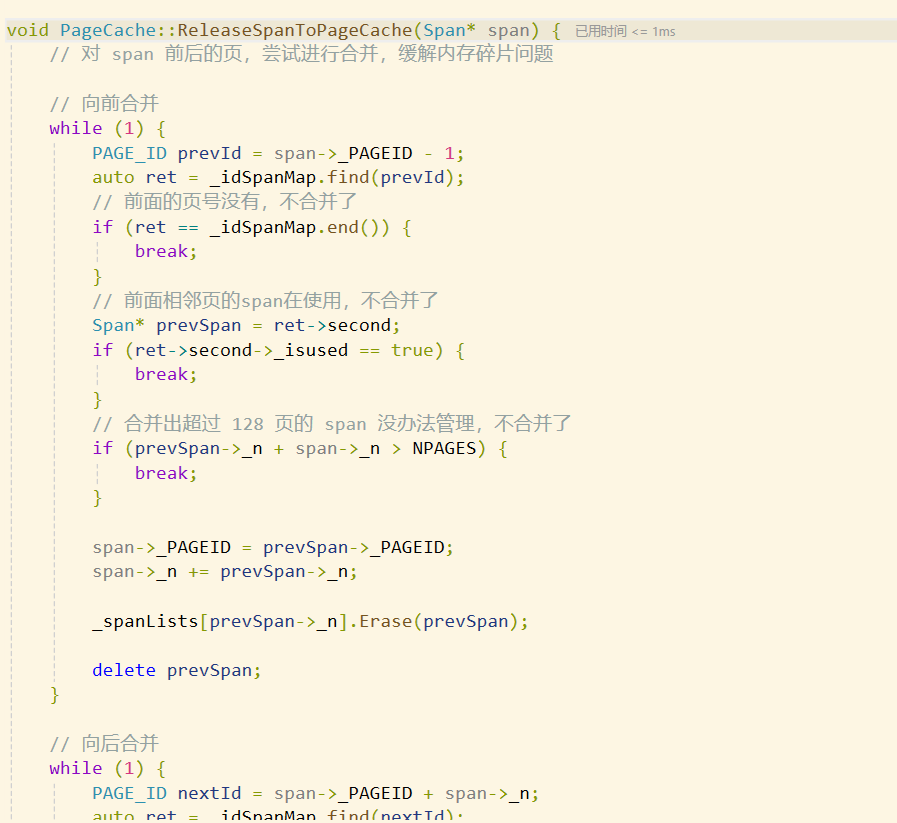
因此page cache在回收span时也需要进行判断,t>如果该span的大小是小于等于128页的,那么直接还给page cache就行了,page cache会尝试对其进行合并</fon。而如果该span的大小是大于128页的,那么说明该span是直接向堆申请的,我们直接将这块内存释放给堆,然后将这个span结构进行delete就行了。
void PageCache::ReleaseSpanToPageCache(Span* span) {// 大于 128 page 的直接向堆申请内存,直接释放if (span->_n > NPAGES - 1) {void* ptr = (void*)(span->_PAGEID << PAGE_SHIFT);SystemFree(ptr);delete span;return;}
👥总结
本篇博文对 【从零实现高并发内存池】申请、释放内存过程联调测试 与 大于256KB内存申请全攻略 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~