go-map+sync.map的底层原理
map
哈希冲突解决方式
1.拉链法
2.开放地址法
底层结构
Go 的
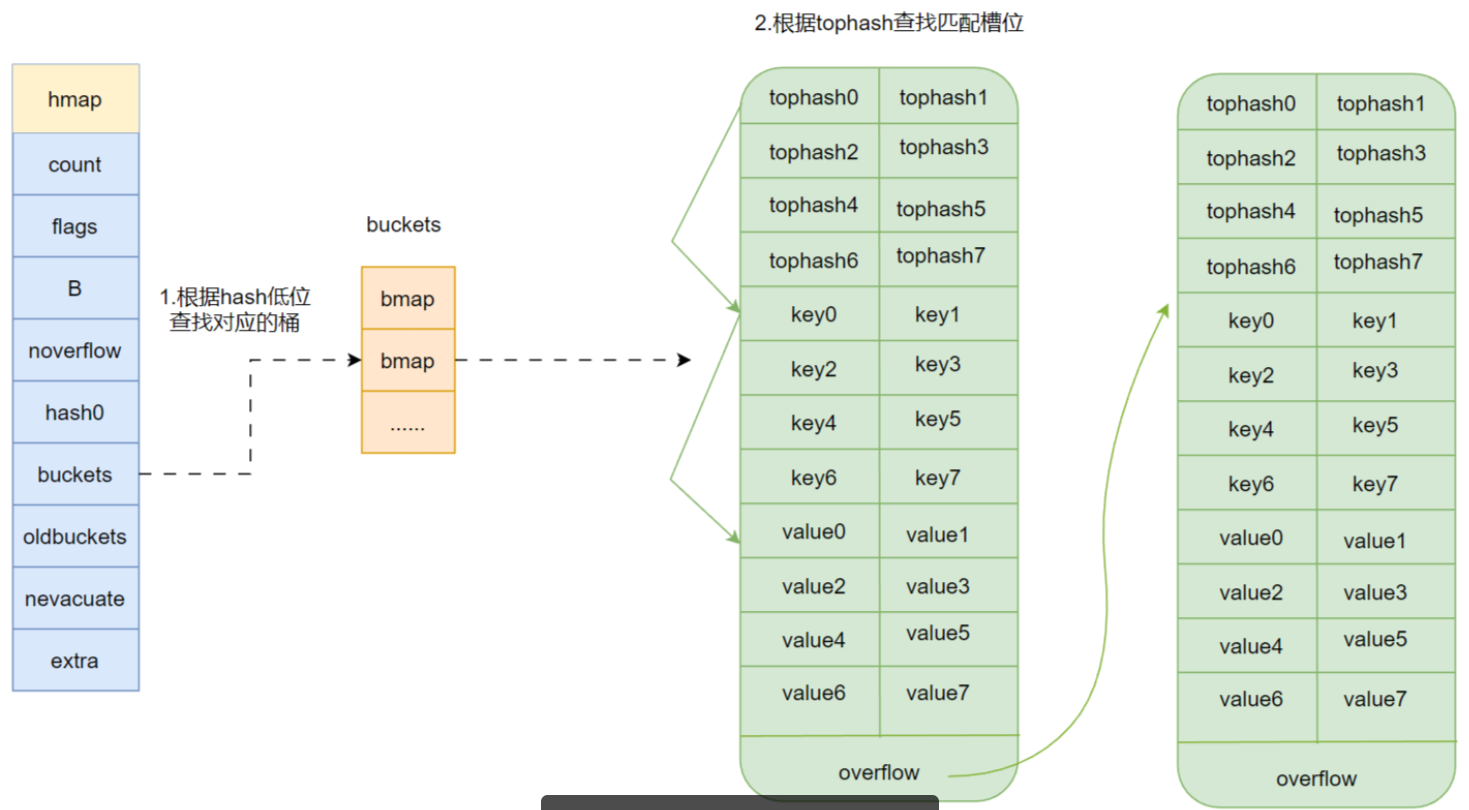
map在源码中由runtime.hmap结构体表示,buckets-指向桶数组的指针(常规桶),oldbuckets-扩容时指向旧桶数组的指针。
type hmap struct {count int // 当前元素个数(len(map) 直接返回此值)flags uint8 // 状态标志(是否正在扩容、迭代等)B uint8 // 桶的数量为 2^B(哈希桶数量的对数)noverflow uint16 // 溢出桶的大致数量hash0 uint32 // 哈希种子,用于计算键的哈希值buckets unsafe.Pointer // 指向桶数组的指针(常规桶)oldbuckets unsafe.Pointer // 扩容时指向旧桶数组的指针nevacuate uintptr // 扩容时记录下一个要迁移的桶编号extra *mapextra // 可选字段,用于管理溢出桶
}bmap结构
type bmap struct {// 1. 哈希值的高8位数组(快速比较)tophash [bucketCnt]uint8 // bucketCnt默认为8,每个桶最多存8个键值对// 2. 键数组(具体类型由map定义决定)keys [bucketCnt]KeyType // 例如int、string等// 3. 值数组(具体类型由map定义决定)values [bucketCnt]ValueType// 4. 溢出桶指针(链表结构,处理哈希冲突)overflow *bmap
}tophash [bucketCnt]uint8 // bucketCnt默认为8,每个桶最多存8个键值对
作用:存储每个键哈希值的前8位,用于快速过滤不匹配的键。一个key会通过哈希函数得到一个哈希值(高八位就是tophash ),哈希值再对map的数量取模得到桶下标,找到自己存放的位置。
keys [bucketCnt]KeyType // 例如int、string等
values [bucketCnt]ValueType
- 容量:每个
bmap最多存储8个键值对。- 内存排列:
- 键和值分开存储:键数组(
keys)和值数组(values)在内存中连续分布。- 对齐优化:根据键和值的大小调整内存对齐,减少碎片。
overflow *bmap
- 作用:当桶已满时,新键值对存入溢出桶,形成链表。
- 示例:
- 插入第9个键值对时,创建新的
bmap,链接到overflow指针。- 查找时需遍历链表直到找到匹配项或链表末尾。
为什么键和值要分开存放?
- 键和值分开存储:键数组(
keys)和值数组(values)在内存中连续分布。 - 对齐优化:根据键和值的大小调整内存对齐,减少碎片。
map中一个key的查找过程?
1. 哈希计算与桶定位
- 计算键的哈希值
hash := hashFunc(key, h.hash0)。- 通过掩码运算定位桶:
bucketIndex := hash & (2^B - 1)(B为桶数量的指数)。- 确定目标桶
bmap。2. 桶内查找与插入
遍历
tophash数组,寻找空槽或匹配的高8位:
- 空槽:
tophash[i] == 0,表示可插入新键值对。- 匹配:
tophash[i] == hashHigh,需进一步比较键是否相等。如果key不相等说明槽位被占了,那么查找下一个为空的槽位,如果找到最后发现槽位被占满那么就通过overflow 创建新的bmap插入数据。
go语言中的map怎么解决哈希冲突的?
利用了两种方法拉链法和开放法,看上面的题目回答。
map中一个key的删除过程?
通过哈希值的高八位查找到一个桶的tophash位置,然后把tophash标记为emptyOne的状态,如果当前tophash位置后面所有的位置为空,那么就将当前位置标记为emptyReset状态,这样如果下一次遍历到了emptyReset就不会往后进行查找,提高了查询的效率。
map的扩容
扩容时机
负载因子超标,负载因子超过为 6.5触发双倍扩容。一个桶能存放八个元素,负载因子为6.5的时候表示一个桶中位置快被分配完了,一个桶快满了,很有可能需要遍历溢出桶,那么就会触发双倍扩容。
溢出桶的数量过多的话就触发等量扩容。插入元素过多就会有溢出桶,然后又删除元素,但是map的删除元素不会释放内存,再进行元素的插入,这样会导致元素的排列很松散。所以需要等量扩容重新排列元素位置,让内存更加紧密。
等量扩容
等量扩容:并不扩大容量,buckets数量维持不变,重新做一遍搬迁动作,把松散的键值对重新排列一次,使得同一个 bucket 中的 key 排列地更紧密,节省空间,提高 bucket 利用率,进而保证更快的存取。
双倍扩容
双倍扩容:新建一个buckets数组,新的buckets数量大小是原来的2倍,然后I日buckets数据搬迁到新的buckets.
扩容方式?
map采用渐进式扩容的方式,再插入修改key的时候,会进行元素的搬迁,每一次搬迁1-2个元素,从旧桶中找到一个当前访问的key-value,还有一个是通过迁移编号找到的key-value值,每次移动两个元素,再到新桶中做哈希运算重新放入新桶。
syncmap
Go 语言中的 sync.Map 是专为并发场景设计的线程安全 map,其底层结构通过 读写分离 和 无锁原子操作 优化性能,尤其适合读多写少的场景。
底层结构
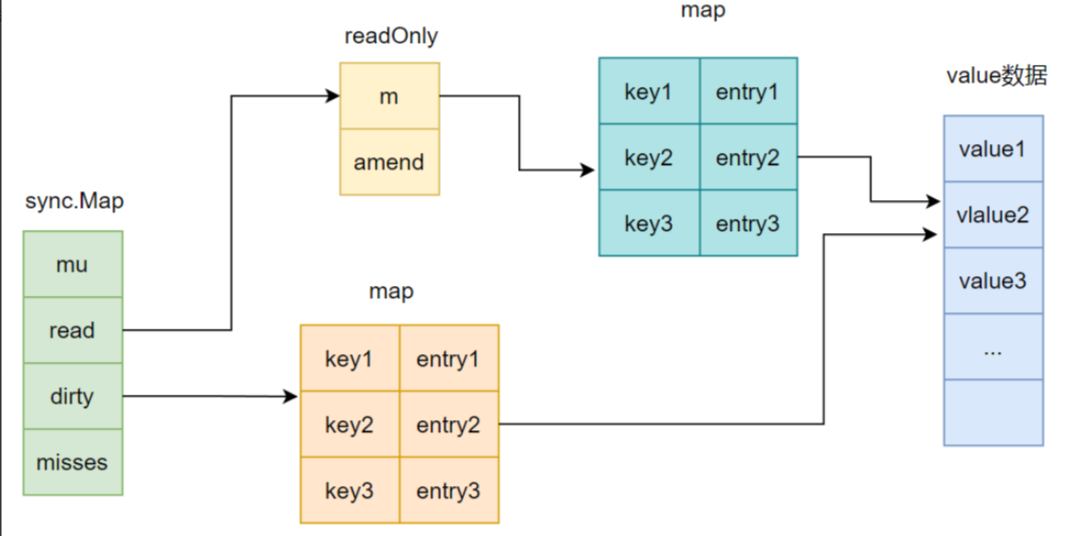
type Map struct {mu sync.Mutex // 互斥锁,保护 dirty 的并发写操作read atomic.Value // 存储只读数据(readOnly 结构),通过原子操作访问dirty map[interface{}]*entry // 存储可写数据,访问时需要加锁misses int // 记录从 read 读取失败的次数,触发 dirty 提升为 read
}type readOnly struct {m map[interface{}]*entry // 存储键值对的指针(entry)amended bool // 标记 dirty 中是否有 read 中不存在的键
}如果amend为true那么就从dirty当中操作.
type entry struct {p unsafe.Pointer // 指向实际值的指针(可能为 nil、expunged 标记或具体值)
}
entry的状态管理,p有三种状态,
- 正常值:
entry.p指向实际值。- 删除标记:
entry.p = nil(逻辑删除)。- 完全删除:
entry.p = expunged(一个特殊标记指针),表示键已从dirty移除。
有几种方法
Store(),更新插入一个key-value
Load(),返回对应的value
Delete(),删除
Range(),对map进行遍历
sync.map插入流程
- 如果read当中不包含这个元素的话,那么就对dirty进行操作,获取锁操作dirty。
- 如果read当中有这个元素并且对应entry指向的状态为nil或者为正常值,直接修改read的值
- 如果read当中有这个元素并且对应entry指向的状态为
expunged的状态的话,那么不光要在read当中进行修改,还要在dirty当中插入新值。
sync.map删除流程
从read当中找到对应的数据,然后通过entry指针把指向的value置为nil。
如果read当中找不到对应的值,但是存在于dirty,就把dirty当中对应的entry指针指向
expunged状态,表示键已从dirty移除。
read map和dirty map怎么互相转换的?
dirty->read
从
read无锁读取:
- 通过原子操作获取
read.m,查找键对应的entry。- 若找到且
entry.p != nil,直接返回值如果没有找到,那么加锁访问
dirty,从dirty读取,并增加misses计数。当
misses >= len(dirty)时,将dirty提升为read,重置dirty把dirty置空和misses。
read->dirty
考虑到dirty->read的情况,在最后将
dirty提升为read后,会重置dirty把dirty置空。此时dirty为空,read不为空。
如果要插入新的数据那么只能从dirty中进行插入,但此时dirty为空,所以dirty需要复制read当中的数据(这个过程就是dirty的重塑),把read当中value的状态=nil的值都标记成expunged状态,那么dirty不会对expunged状态的值进行复制。