面试题之如何设计一个秒杀系统?
系统痛点:
痛点分析:
- 瞬时并发量大:大量并发请求瞬间涌入,网站流量激增,可能压垮系统。
- 库存少:访问请求远大于库存,只有少量用户可以秒杀成功
- 架构设计原则:
- 系统隔离:
- 独立部署秒杀服务,避免影响主线业务流程
- 独立数据库/缓存集群等
- 独立域名/CDN等
- 分层削峰:
- 前端层:静态化、请求拦截
- 服务层:队列缓冲、异步处理
- 数据层:预减库存、最终一致
- 系统隔离:
业务流程:
用户 → CDN → 负载均衡 → 网关(限流) → 秒杀服务 → 消息队列 → 订单服务↘ Redis集群 ↘ 数据库集群实施与解决
系统设计图:
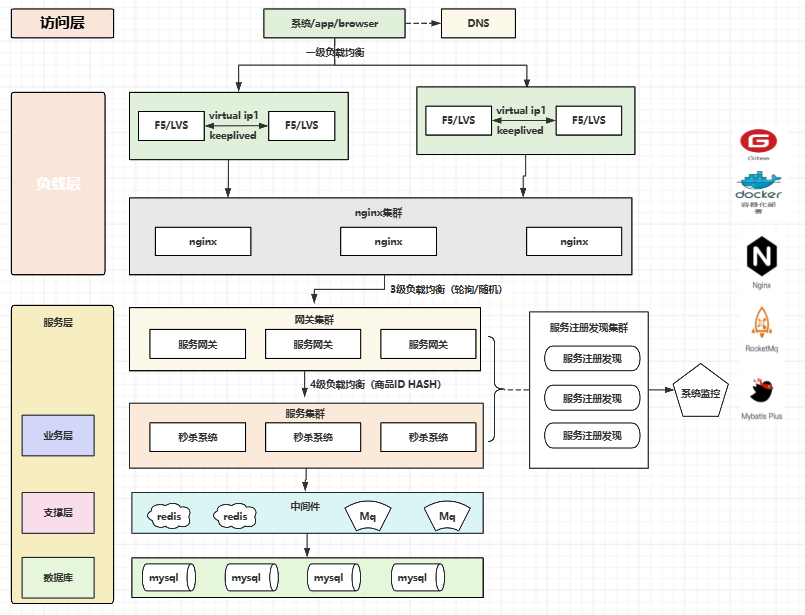
分层设计:
以上为秒杀系统的设计图:根据访问层、负债层、服务层、业务层支撑层、数据层阐述设计
访问层
当用户访问系统商品时,需要将商品从动态网页转为静态网页。减少动态请求到服务端的压力,服务端只需要处理秒杀即可
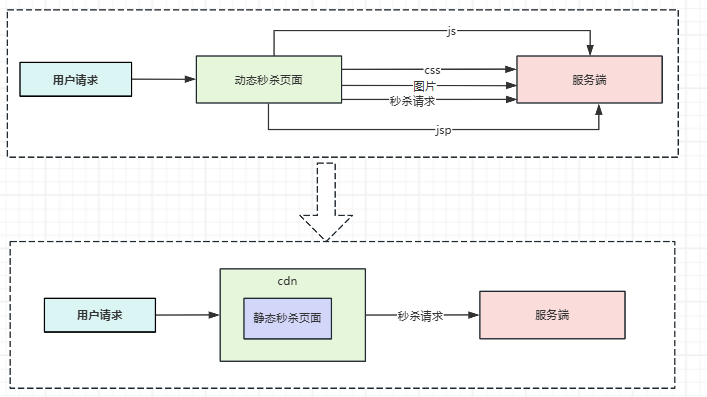
前端上做一些逻辑处理:
- 静态资源分离:将活动页静态化,部署到CDN上
- 活动前禁用按钮:减少不必要的资源请求
- 按钮防重复点击:当用户点击提交后,立即灰显禁用,限制用户多次提交页面
- 随机延迟请求:客户端随机添加微笑言辞
- 验证码/答题:通过滑动验证码、图形验证码等拦截机器人及防止用户控制多个设备进行提交
- 排队体验:增加等待中、抢购中的提示,防止 用户多次刷新
服务层
前端校验通过后,通过多台NG的转发,到后端处理秒杀功能,单台ng可以处理2-3万的数据量,一旦NG集群了,就需要在NG上方进行部署网络及硬件级别相关的F5/LVS等。通过NG校验及转发后,就会到服务端的网关集成器,比如ribbon或者loadbalancer进行客户端的负债均衡的转发,通过上面四级的负债均衡大概能处理每秒10+万的qps请求并发量。
- 网关限流操作:
- 限流熔断:NG/Lua实现IP/用户限流
- 请求过滤:恶意请求识别与拦截
- URL动态化:活动开始前不暴露真实的接口
- DNS轮询:让DNS服务商针对网站提供的域名绑定多个IP地址
- 支撑层
- 异步处理:请求先入队列,异步处理订单
- 缓存预热:提前加载热点数据到redis
- 分层校验:
- 第一层:用户资格校验(是否登录、黑名单等)
- 第二层:库存校验(redis预扣减库存)
- 第三层:最终校验(数据库确认)
- 接口防重校验:(防止绕过前端的恶意用户刷单,setNX保证同一个时间、同一个商品、同一用户只能下单成功一次)
- 库存方案:
- 库存分段:将库存拆分成多个段(如1000库存拆成10个100)
- 预扣库存:redis预减库存(LUA脚本进行数据操作),异步(秒杀时客户端将请求放到MQ消息中发送给MQ服务端,消息者通过消费队列来进行下单操作并持久化到数据库)同步到DB
- 库存回滚:支付超时后自动释放库存
- 数据一致性:
- 最终一致性:通过消息队列异步处理
- 事务消息:通过rocketMQ事务宝恒下单与扣减库存
- 对账系统:定期核对redis与数据库的库存告警监控
- 日志监控:防止系统出现问题后处理
限流相关:
- 核心要点:
- NG需要配置限流,防止恶意绕过我们前端的一些D DOS攻击;
- 网关sentinel对不同的服务节点限流和熔断机制;
- 通过MQ的来削峰,通过MQ来减轻下游的服务压力
- 降级方案
- 服务降级:关闭非核心功能(如评论、推荐)
- 限流策略:
- 令牌桶/漏桶算法
- 队列泄洪(固定长度队列)
- 熔断机制:hystrix/sentiel实现
数据库:
- 读写分离、数据量大时需要涉及到分库分表操作
- redis集群:
- 库存预扣:DECR原子操作
- 分布式锁:防止超卖
- MQ队列:
- 通过异步处理降低数据压力
- 数据库优化:
- 分库分表
- 使用乐观锁(version字段)
- 库存字段无符号设计(避免负数)
部署相关:
这种秒杀系统一般配合docker、 K8S相关的云服务器的动态伸缩部署,当秒杀开始时,自动扩容服务器节点,结束后,自动缩减节点,有效的利用服务器资源和成本。
面试相关:
Q:如何防止超卖?
- redis原子操作,通过redis的decr操作来扣减库存,当不小于零则返回成功
- 数据库乐观锁,通过mysql更新脚本时直接设置参数完成
- 分布式锁:通过redisson实现,处理秒杀逻辑
Q:流量激增时,引发redis雪崩、击穿、穿透?
- 缓存雪崩(Cache Avalanche)
- 定义:大量缓存数据同时过期,导致所有请求直接打到数据库,引发数据库压力激增甚至崩溃。
- 场景:双11零点,大量商品缓存设置相同TTL同时失效。
- 缓存击穿(Cache Breakdown)
- 定义:某个热点key突然失效,同时有大量并发请求访问这个key,直接冲击数据库。
- 场景:明星离婚新闻的缓存key失效瞬间,千万请求同时涌入。
- 缓存穿透(Cache Penetration)
- 定义:查询根本不存在的数据,缓存和数据库都找不到,导致每次请求都穿透到数据库。
- 场景:恶意攻击者伪造不存在的商品ID发起请求。
解决方案
| 问题类型 | 核心原因 | 解决方案 | 技术实现示例 |
|---|---|---|---|
| 雪崩 | 大量key同时失效 | 1. 差异化过期时间 2. 永不过期+后台更新 3. 多级缓存 | setex(key, 300 + random(60), value) |
| 击穿 | 热点key失效 | 1. 互斥锁 2. 逻辑过期 3. 永不过期 | RLock lock = redisson.getLock(key) |
| 穿透 | 查询不存在数据 | 1. 布隆过滤器 2. 空值缓存 3. 参数校验 |
|
- 缓冲雪崩解决:
- 过期时间随机化
- 永不过期策略
- 多级缓冲
-
浏览器缓存 → CDN缓存 → Nginx缓存 → Redis集群 → JVM缓存 → DB
-
- 缓冲击穿
- 分布式锁互斥(获取key时锁定单线程获取)
- 逻辑过期+异步刷新
- 缓冲穿透:
- 布隆过滤器
- 空值缓存
防护组合方案
流程图:
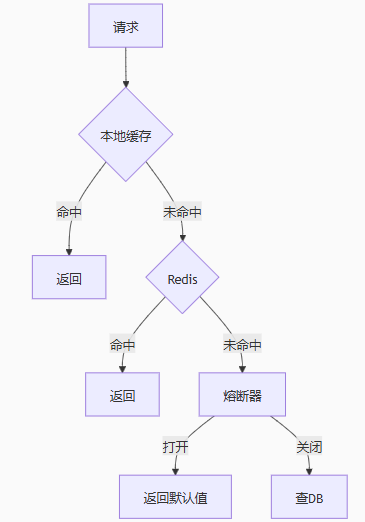
- 热点key探测+动态保护
- 实时监控key访问频率
- 自动将热点key迁移到本地缓冲
- 对热点key实施特殊保护策略
- 集群化解决方案
- redis cluster 分片存储
- 多副本读写分离
- 异地多活架构
Q:布隆过滤器如何防止穿透?
布隆过滤器(Bloom Filter)是解决缓存穿透问题的经典方案。
- 核心原理:
-
空间换时间:使用位数组(bit array)和多个哈希函数,用极小空间存储数据存在性信息
-
预检机制:在查询缓存/数据库前先检查布隆过滤器
-
确定性回答:
-
"可能存在"(可能有误判)
-
"绝对不存在"(100%准确)
-
-
-
业务流程
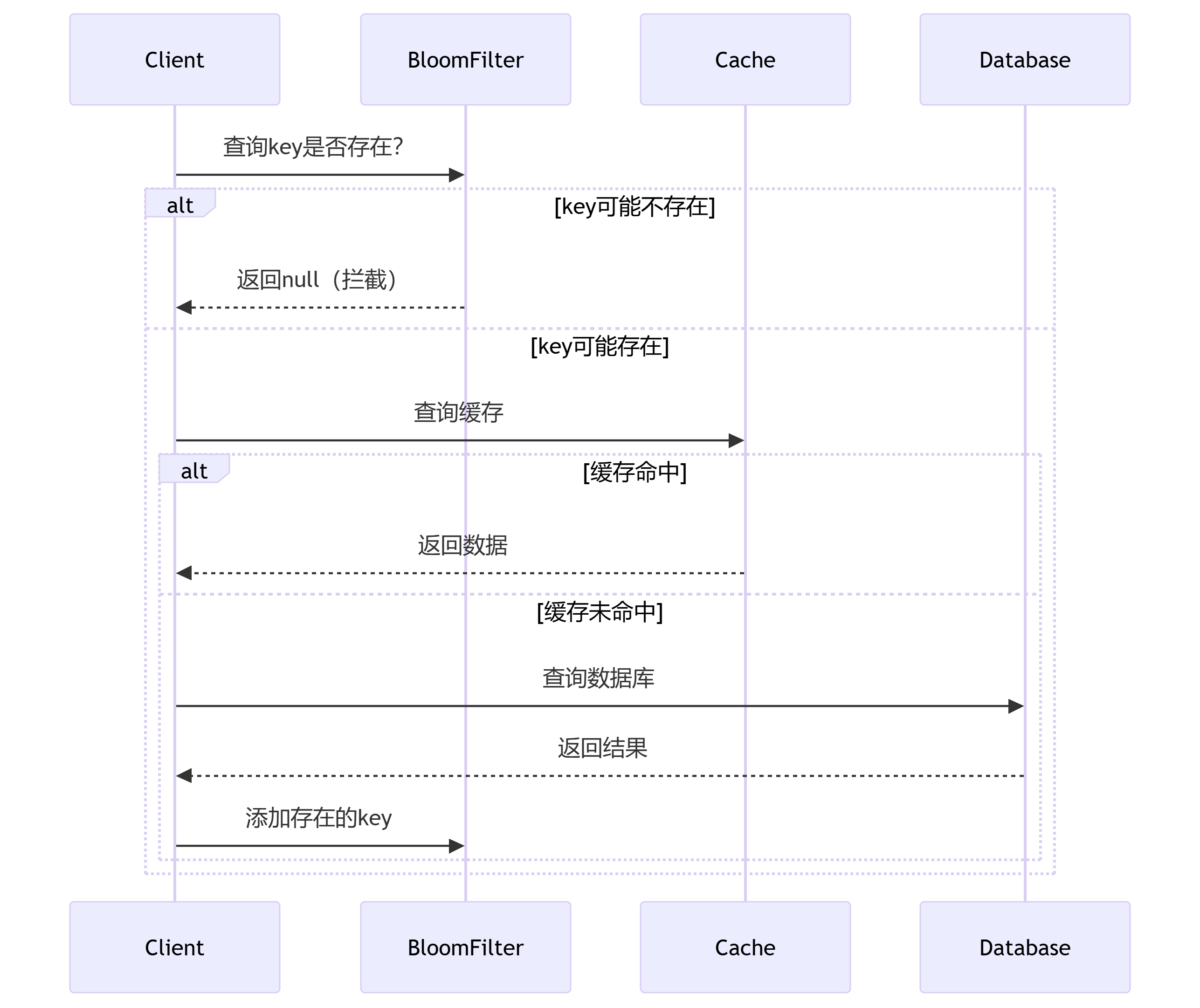
- 注意:
-
误判率权衡:
-
误判率越低,需要的空间越大
-
典型设置:0.1%-1%(1%误判率下,每个元素约需9.6 bits)
-
-
不支持删除:
-
标准布隆过滤器不支持删除操作
-
需要删除功能可使用变体(Counting Bloom Filter)
-
-
数据预热:
-
系统启动时需要预加载有效key
-
对于新增数据需要同步更新过滤器
-
-
动态扩容:
-
当元素数量超过预期时,需要重建过滤器
-
考虑使用分片布隆过滤器(Scalable Bloom Filter)
-
-
| 方案 | 内存占用 | 查询时间复杂度 | 误判率 | 实现复杂度 |
|---|---|---|---|---|
| 原生布隆过滤器 | 低 | O(k)* | 可配置 | 中 |
| Redis布隆过滤器 | 中 | O(k) | 可配置 | 低 |
| 布谷鸟过滤器 | 较低 | O(1) | 更低 | 高 |
| 空值缓存 | 高 | O(1) | 无 | 低 |
Q:限流中的算法:滑动窗口算法、令牌桶算法、漏桶算法?只有获取令牌才能操作?
缺点:令牌如果太少了 会导致用户取消购买
三大算法核心对比
| 算法 | 核心原理 | 特点 | 适用场景 | 是否需获取令牌 |
|---|---|---|---|---|
| 滑动窗口 | 统计单位时间内实际请求量 | 精确控制瞬时流量,需存储时间戳数据 | API限流、秒杀系统 | ❌ 直接计数 |
| 令牌桶 | 以恒定速率生成令牌,请求消耗令牌 | 允许突发流量,平滑限流 | 网络流量控制、接口平滑限流 | ✅ 必须获取令牌 |
| 漏桶 | 以恒定速率处理请求,超量请求排队/丢弃 | 严格限制流出速率,无法应对突发流量 | 保护下游系统、流量整形 | ❌ 排队机制 |
- 滑动窗口:
-
精确控制任意时间窗口内的请求量
-
需要存储时间戳数据(内存开销较大)
-
Redis可通过
ZSET+Lua脚本实现分布式版本 -
通过计数控制,没有真正令牌概念
-
-
令牌算法
-
突发流量处理:当桶中有足够令牌时,允许短时间内超过平均速率
-
平滑限流:长期来看平均速率被严格控制
-
必须显式获取令牌才能执行业务逻辑
-
令牌桶的必须性:
-
显式获取:业务逻辑必须显式调用acquire()获取令牌
-
阻塞与非阻塞
-
非阻塞:tryAcquire()立即返回成功/失败
-
阻塞:acquire()可能等待知道令牌可用
-
-
预热模式(Guava rateLimiter)
-
-
-
漏桶算法:
-
严格输出控制:无论输入多快,输出速率恒定
-
请求排队:超限请求可以选择排队而非直接拒绝
-
无需获取令牌,但需要等待漏桶处理
-
通过水位控制,请求相当于水滴
-
-
实践建议方案:
-
redis+lua分布式令牌桶
-
自适应限流(结合多个算法)
-
请求入口 → 滑动窗口(防突发) → 令牌桶(平滑控制) → 漏桶(保护下游)
↘ 动态调整限流阈值 ↗
-
-
其他建议:
-
需要允许突发流量:令牌桶算法
-
严格限制瞬时流量:滑动窗口算法
-
保护脆弱下游系统:漏桶算法
-
分布式环境:redis实现+定期同步
-
超高并发场景:本地限流+全局分层设计
-
-
Q:幂等接口的实现方式?
幂等接口方案
幂等接口是指对同一操作的多次执行与一次执行的效果相同。在消息队列场景下,由于网络抖动、消费者重试等原因可能导致消息重复消费,必须实现幂等处理。
- 基础实现方案:
- 唯一标识法:使用所有的幂等接口
- 数据库唯一标识:根据数据库主键ID创建
- 乐观锁实现:在更新数据库标识时确定
- 高级实现方案:
- 状态机幂等:所有状态流转的业务
- token机制:防止表单重复提交
- 分布式锁实现
- 消息队列幂等消费
- 幂等接口注意:
- 方案选择建议:
- 创建操作:唯一约束法
- 更新操作:乐观锁/状态机
- 删除操作:标记删除+状态检查
- 复杂操作:分布式锁+唯一ID
- 设计要点:
- 前端防重:提交按钮禁用、Token机制
- 网络层:合理设置HTTP方法(PUT/DELETE天然幂等)
- 超时处理:设置合理的请求过期时间
- 结果查询:为异步操作提供查询接口
- 性能优化:
- redis代替数据库做幂等校验
- 本地缓冲+分布式缓冲多级校验
- 非关键业务可适当降低幂等要求
- 方案选择建议:
消息队列幂等方案对比
| 方案 | 实现复杂度 | 适用场景 | 优缺点 |
|---|---|---|---|
| 唯一消息ID | 低 | 所有消息场景 | 简单但需存储ID状态 |
| 业务状态机 | 中 | 有状态流转的业务 | 精准但实现复杂 |
| 数据库唯一约束 | 低 | 数据库操作场景 | 依赖数据库能力 |
| 乐观锁 | 中 | 更新操作场景 | 需设计version字段 |
| 分布式锁 | 高 | 高并发敏感场景 | 强一致但性能有损耗 |
- 具体实现:
- 唯一消息ID+去重表
- 检查消息ID是否已处理
- 开始处理(在事务中标记消息为处理中)
- 业务处理
- 标记处理成功
- 处理失败回滚
- 业务状态机实现幂等
- 根据业务数据的状态机进行检查,判断是否处理及处理成功,在进入处理
- redis原子操作
- setNX数据锁定在进行操作
- 分布式锁+幂等表
- 通过redis等生成唯一业务ID
- 获取分布式锁
- 检查幂等记录后进行业务处理
- 创建处理中的记录
- 执行业务逻辑
- 更新幂等记录
- kafka exactly once语义
- 生产者配置
- 消费者配置
- 消费者幂等处理
- 使用业务唯一键保证幂等
- 唯一消息ID+去重表
- 最佳实践
- 消息ID生成规则
- 生产者生成全局唯一ID(UUID、Snowflake)
- 建议格式:业务前缀:唯一标识
- 设计去重表,添加唯一ID 业务类型 状态 和存储业务结果等
- 过期策略
- redis设置合理TTL(通常为2-72)小时
- 数据库定期清理一完成记录(如一个月前的数据)
- 异常处理:
- 网络异常时做好状态回滚
- 设置最大重试次数避免死循环
- 对关键业务实现步长机制
- 监控指标
- 消息重复率
- 幂等拦截次数
- 平均处理延时
- 存储空间使用量
- 消息ID生成规则
不同消息队列实现对比
| 消息系统 | 幂等特点 | 推荐方案 |
|---|---|---|
| Kafka | 支持Exactly-Once语义 | 消息ID+生产者幂等+事务ID |
| RabbitMQ | 需自行实现幂等 | 去重表+消费者确认 |
| RocketMQ | 支持消息去重(商业版) | 唯一KEY+状态检查 |
| Pulsar | 支持消息去重(基于序列号) | 序列号检查+业务状态机 |
Q:批量消费,入库?
Q:库存拆分?