[文献阅读] EnCodec - High Fidelity Neural Audio Compression
[文献信息]:[2210.13438] High Fidelity Neural Audio Compression facebook团队提出的一个用于高质量音频高效压缩的模型,称为EnCodec。Encodec是VALL-E的重要前置工作,正是Encodec的压缩量化使得VALL-E能够出现,把语音领域带向大模型时代。
摘要
随着互联网流量的增长,音频压缩是一个越来越重要的问题。传统上,这是通过用信号处理变换分解输入并权衡不太可能影响感知的分量的质量来实现的。
该文介绍了一个最先进的实时,高保真,音频编解码器,Encodec。它包括一个流编码器-解码器(streaming encoder-decoder)架构,具有以端到端方式训练的量化潜在空间。
在结构上,Encodec在编码器和解码器之间加入了残差量化层RVQ,使得中间离散特征进一步量化,并且不损失大部分信息。为了加快解码速度,还设计了一个轻量级的Transformer模型来进一步预测下一步的量化特征,从而加快量化的速度。
训练上引入了一种新的损失平衡器机制来稳定训练:损失的权重现在定义了它应该代表的整体梯度的分数,从而将这个超参数的选择与损失的典型规模解耦。
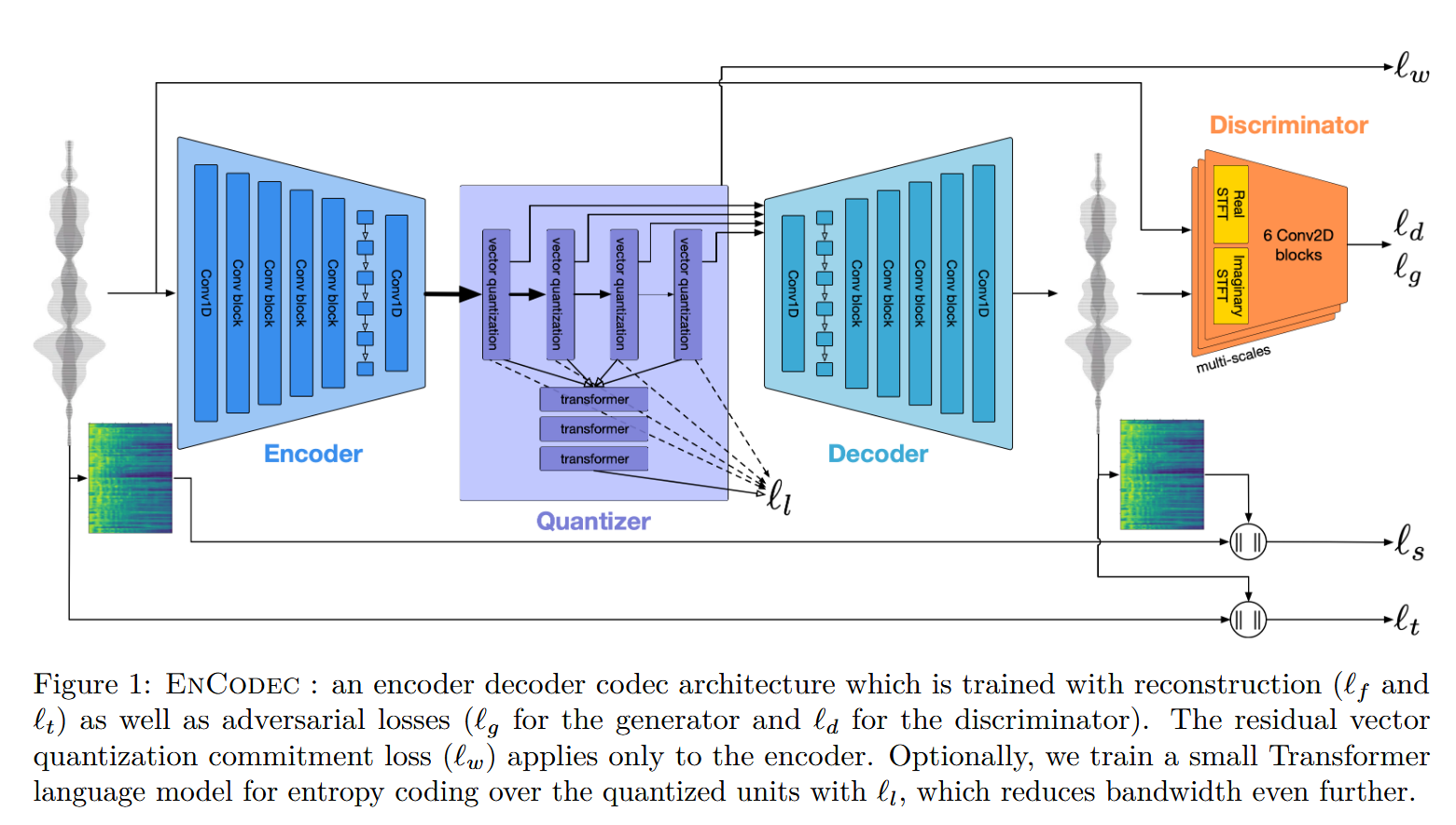
Encodec结构
论文的核心思想是使用神经网络来实现数据的压缩、音频数据的压缩。当遇到这种压缩问题的时候,我们最先想到的模型是AutoEncoder(自编码器)。AutoEncoder包含两个部分:Encoder和Decoder。Encoder负责将原始数据映射到低维度的潜空间,Decoder负责将潜空间中的变量映射成原始的数据。
为了进一步减少音频数据的大小,有利于数字存储和传输,模型中还需要包含量化的过程,将连续的音频信号转换为离散的数值。当然,量化过程也会导致一部分的信息损失。因此,设计的量化算法在减小文件大小的同时也要尽量减少对音质的影响。
基于上述两点的考虑,论文中设计的神经网络采样了典型的编解码器架构,带有一个Encoder和一个Decoder。为了实现量化的过程,Encoder和Decoder之间插入了一个Quantizer(量化器)。
持续时间为d的音频信号可以由序列 $x∈[−1,1]^{C_a×T} $表示,其中Ca是音频通道的数量, T = d ⋅ f s r T=d⋅f_{sr} T=d⋅fsr 是给定采样率 f s r f_{sr} fsr 下的音频样本的数量。
EnCodec模型由三个主要组成部分组成:
- 编码器网络E输入音频提取并输出潜在表示 z ;
- 量化层Q使用矢量量化产生压缩表示 z q z_q zq ;
- 最后,解码器网络G从压缩的潜在表示 z q z_q zq 重建时域信号 x ^ \hat x x^。
Encoder和Decoder
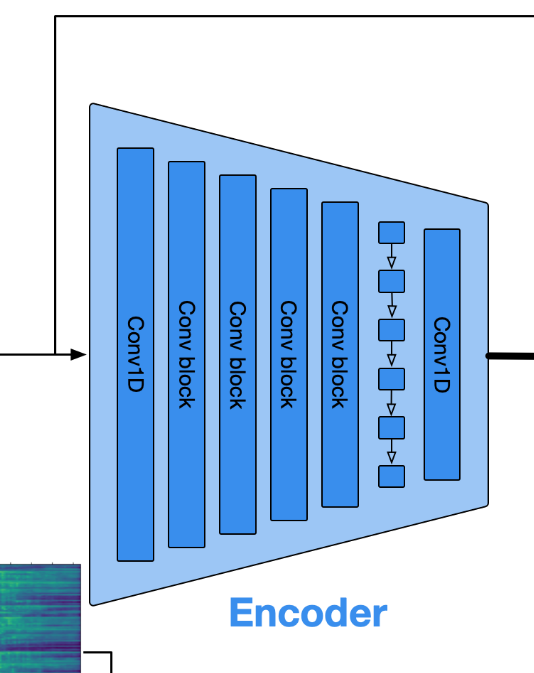
编码器模型E包括具有C个通道,kernel_size=7的1D卷积,其后是B个卷积块。 每个卷积块由单个残差单元组成,该残差单元之后是下采样层,该下采样层由步长卷积组成,其核大小K是步长S的两倍。 剩余单元包含两个核大小为3的卷积和一个跳跃连接。 每当发生下采样时,通道的数量就会加倍。 卷积块之后是用于序列建模的两层LSTM和具有7个核大小和D个输出通道的最终1D卷积层。
Encoder模型由1D卷积层和B个卷积块组成。1D卷积层的核大小为7,通道数为C。每个卷积块包含一个残差单元(residual unit)和一个步幅卷积的下采样层(downsampling layer consisting in a strided convolution)。核的大小是步幅的两倍。残差单元包括两个核大小为3的卷积和一个skip connection。每次下采样,通道数都会翻倍。卷积块后还会接一个两层LSTM进行序列建模。最后还会接一个1D卷积层。这个卷积层的核大小也是7,输出通道数为D。参照SoundStream的参数设置,1D卷积层的通道数C=32,卷积块的个数B=4,这4个卷积块的步幅(stride)分别是2、4、5、8。
Decoder与Encoder是对称的设计,将Encoder中卷积下采样改为上采样就可以了。
Non-streamable 在不可流处理的设置中,我们为每个卷积使用一个总的填充K − S,在第一个时间步长之前和最后一个时间步长之后平均分配(如果K − S是奇数,则在之前再分配一个)。 我们进一步将输入分割为1秒的块,重叠10 ms以避免点击,并在将每个块馈送到模型之前对其进行归一化,在解码器的输出上应用逆运算,增加可忽略的带宽开销以传输比例。 我们使用层标准化(Ba等人, 2016),计算还包括时间维度的统计量,以便保持相对尺度信息。
Streamable 对于流式设置,所有填充都放在第一个时间步长之前。 对于步长为s的转置卷积,我们输出s个第一个时间步,并将剩余的s个步骤保存在内存中,以便在下一帧可用时完成,或者在流结束时丢弃它。 由于这种填充方案,一旦接收到前320个样本(13 ms),模型就可以输出320个样本(13 ms)。 我们将层归一化替换为在时间维度上计算的统计数据,并使用权重归一化(Salimans & Kingma,2016),因为前者不适合流媒体设置。 我们注意到,通过保持一种形式的标准化,客观指标会有一个小的增益,如表A.3所示
考虑到音频流式实时传输的需求,模型有两种变体:流式变体和非流式变体。二者的区别仅仅在于填充的位置和归一化的方式。在流式变体中,所有的填充都会放在第一个时间步之前。模型可以在接收到第一批320个样本(13毫秒)后立即输出。除了这个,流式变体还使用weight normalization(权重归一化)来代替对时间维度进行统计的layer normalization(层归一化)。
在这里,我们需要解释一下为什么说第一批样本是320个,为什么它的持续时间是13ms?
解答:编码器中包含四个卷积块,这四个卷积块的步幅分别为2、4、5、8。也就是说,通过这四个卷积块后生成的一个数据点原来实际对应的是: 2×4×5×8=320 个数据点。所以说,流式变体的模型接收到了320个样本之后,就可以开始输出了。持续时间是13ms这个结论,是针对24kHz的音频来说的。对于24kHz的音频,一秒有24k个样本点。那如果数据仅有320个样本点的话,对应的时间就应该是: 秒毫秒320/24000=0.0133秒=13.3毫秒 。13.3毫秒其实就是一帧的持续时间。
残差向量量化RVQ
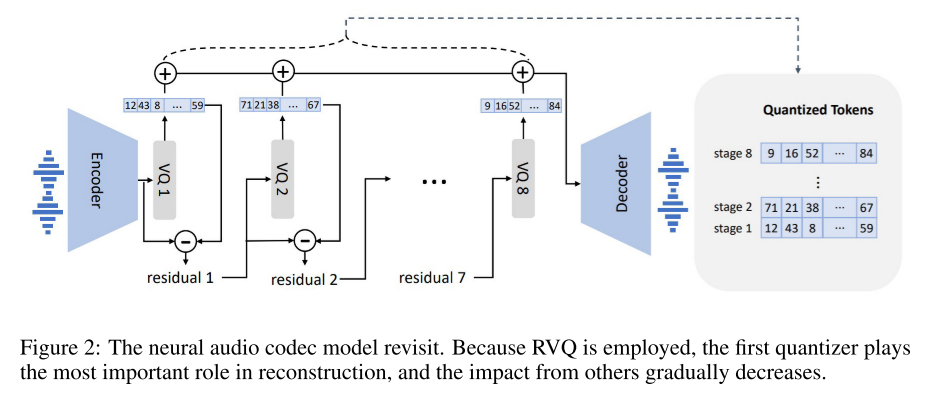
图来自VALL-E https://arxiv.org/abs/2301.02111。
对于一层量化,从Encoder输出的向量会与码本codebook中的向量进行对比,找到最相似的那个向量,记录它的下标。
**残差量化:**但是一层的量化损失太多信息,于是将原始向量与量化向量做差,对差值向量进一步量化,通过8层的残差量化,既能减少codebook的大小,又能减少信息的损失。
第一个block包含最重要的信息,后续的block则负责精确还原语音时的细节信息
同时,多层的残差量化让模型有了更多的选择性,训练时可以随机采样出前面k个block进行训练,保证在丢弃后若干个不重要的block时,模型仍然能够保持一定的精度。此时,模型可以在低比特率时选择性地丢弃后面的blocks,实现了对比特率的动态适应。
RVQ的训练策略:
- codebook的更新策略:在训练过程中,每当codebook中的一个entry被选中用来代表一个输入向量时,这个entry就会根据输入数据进行更新。更新是通过计算entry的新值和旧值的指数移动平均来实现的。指数移动平均的衰减系数 β=0.99 。如果某个codebook的entry在当前批次数据中没有被任何输入向量选择,那么它可能被替换。替换通常是通过在当前批次数据中随机选择一个输入向量来完成的。
- 梯度计算:使用Straight-Through Estimator(直通估计器)计算量化步骤对应的梯度。在STE中,即便量化步骤是不可微的(选择最近的codebook entry),我们仍然可以“假装”这个步骤是恒等操作,从而可以通过它传递梯度。
- 损失函数:quantizer的输入与输出之间的均方误差,梯度只对其输入计算,这个损失会被添加到总的训练损失中
训练
总损失由以下构成:
重建损失项(Reconstruction Loss),感知损失项(Discriminative Loss)(通过鉴别器)和RVQ commitment 损失(RVQ commitment Loss)
重构损失包含时域重构损失和频域重构损失。
频域重构损失计算的是mel-spectrogram之间的差异。损失函数采用的是重构语音和目标语音在多个时间尺度上计算出的L1损失和L2损失的线性组合。
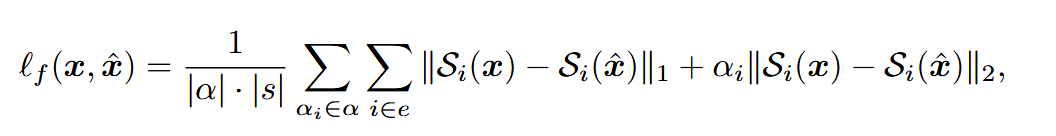
为了进一步提高所生成样本的质量,引入了一个基于多尺度STFT(MS-STFT)鉴别器的感知损失项
生成器的对抗性损失(adversarial loss)构造如下:
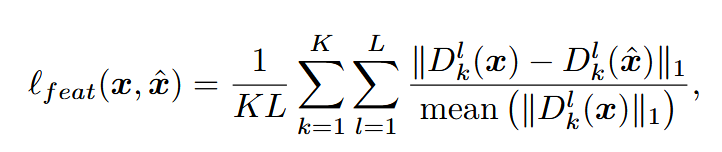
残差量化器损失
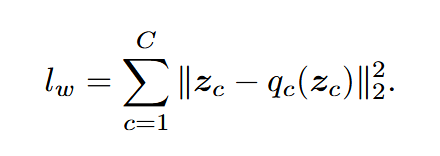
为了稳定训练,特别是来自鉴别器的梯度的变化尺度,引入了损失平衡器
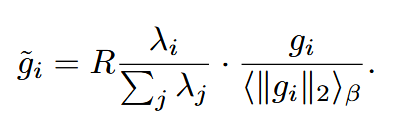
结果
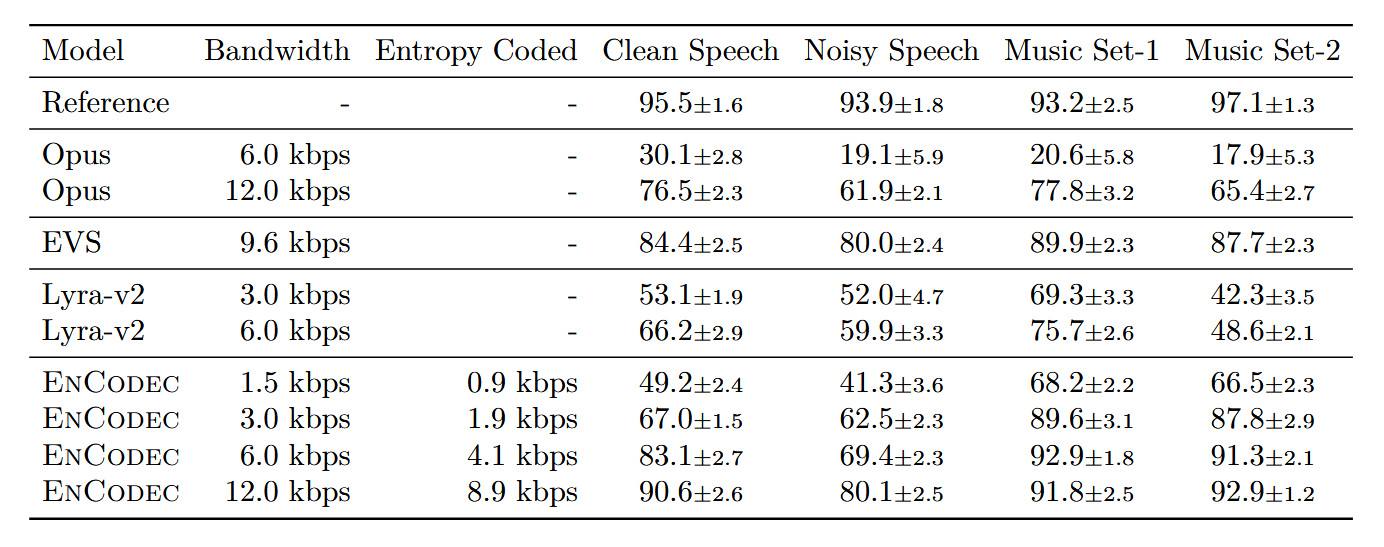
实验
huggingface上用于音频编码解码模型Encodec的官方示例 Encodec (编码) — EnCodec
加载模型,和预处理器processor。
processor 对音频数据进行预处理。将音频数据的采样率设置为与处理器一致(24kHz)。
选取一个样本。
from datasets import load_dataset, Audio
from transformers import EncodecModel, AutoProcessor
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")model = EncodecModel.from_pretrained("facebook/encodec_24khz")
processor = AutoProcessor.from_pretrained("facebook/encodec_24khz")librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=processor.sampling_rate))
audio_sample = librispeech_dummy[-1]["audio"]["array"]
inputs = processor(raw_audio=audio_sample, sampling_rate=processor.sampling_rate, return_tensors="pt")对inputs编码,编码为离散特征
# 编码
encoder_outputs = model.encode(inputs["input_values"], inputs["padding_mask"])print(encoder_outputs)
对编码的中间特征解码,还原回音频数据。
# 解码
audio_values = model.decode(encoder_outputs.audio_codes, encoder_outputs.audio_scales, inputs["padding_mask"])[0]print(audio_values)