【第四十一周】文献阅读:HippoRAG:受神经生物学启发的大型语言模型长期记忆机制
目录
- 摘要
- Abstract
- HippoRAG:受神经生物学启发的大型语言模型长期记忆机制
- 研究背景
- 方法论
- 海马体记忆索引理论(The Hippocampal Memory Indexing Theory)
- HippoRAG的工作机制
- 创新性
- 实验结果
- 局限性
- 总结
摘要
HippoRAG这篇论文提出了一种受人类大脑海马体索引理论启发的检索框架,旨在解决当前大型语言模型(LLM)在知识整合和长期记忆方面的局限性。传统的检索增强生成(RAG)方法虽然在静态知识检索上表现良好,但在需要跨段落整合新知识的复杂任务(如多跳问答)中表现不佳。HippoRAG通过模拟大脑中海马体与皮层的协同工作机制,设计了一个由知识图谱(KG)和个性化PageRank(PPR)算法组成的系统,实现了单步多跳检索,显著提升了效率与效果。HippoRAG的工作流程分为两个阶段:离线索引和在线检索。在离线阶段,模型利用LLM从文本中提取开放信息(OpenIE)构建无模式的知识图谱,作为“人工海马体索引”。在线检索时,系统首先从查询中提取关键实体,通过检索编码器将其映射到知识图谱的节点上,随后运行PPR算法在图中扩散概率,最终根据节点概率聚合生成段落排名。这种设计不仅模仿了人类记忆的“模式分离”和“模式完成”机制,还通过图搜索实现了高效的跨段落知识关联。
Abstract
The paper “HippoRAG” introduces a retrieval framework inspired by the hippocampal indexing theory of the human brain, aiming to address the limitations of current large language models (LLMs) in knowledge integration and long-term memory. While traditional Retrieval-Augmented Generation (RAG) methods perform well in retrieving static knowledge, they fall short in complex tasks requiring the integration of new knowledge across paragraphs, such as multi-hop question answering. HippoRAG emulates the cooperative mechanism between the hippocampus and the cortex in the brain through a system comprising a Knowledge Graph (KG) and a Personalized PageRank (PPR) algorithm, enabling single-step multi-hop retrieval that significantly improves efficiency and effectiveness. The workflow of HippoRAG consists of two phases: offline indexing and online retrieval. In the offline phase, the model uses LLMs to extract Open Information (OpenIE) from texts to construct a schema-less knowledge graph acting as an “artificial hippocampal index.” During online retrieval, the system first extracts key entities from queries, maps them onto nodes in the knowledge graph via a retrieval encoder, then runs the PPR algorithm to diffuse probabilities across the graph, ultimately aggregating paragraph rankings based on node probabilities. This design not only mimics the “pattern separation” and “pattern completion” mechanisms of human memory but also achieves efficient cross-paragraph knowledge correlation through graph search.
HippoRAG:受神经生物学启发的大型语言模型长期记忆机制
Title: HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
Author: Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, Yu Su
Source: NeurIPS 2024
Link: https://openreview.net/forum?id=hkujvAPVsg
研究背景
当前LLM的长期记忆能力存在明显短板。尽管模型参数中编码了大量世界知识,但动态更新这些知识仍然是一个挑战。对于LLMs来说,“长期记忆”通常指的是模型能够持续地积累并有效利用大量知识的能力。然而,由于传统LLMs存在灾难性遗忘的问题(即当模型学习新知识时可能会忘记旧知识),它们很难实现真正的长期记忆。
传统的RAG方法通过检索外部文档增强生成,但在处理需要多步推理的任务时,往往需要多次检索和生成步骤,效率低下且成本高昂。此外,现有方法难以解决“路径发现”类问题(例如从数千名斯坦福教授中找出研究阿尔茨海默症的特定教授),而人类却能轻松完成这类任务。
因此,一些研究致力于探索如何让LLMs拥有更接近人类的长期记忆机制,比如HippoRAG。论文从神经科学的角度出发,借鉴了海马体索引理论。该理论认为,人类长期记忆依赖于海马体(存储关联索引)与新皮层(存储具体记忆内容)的交互。海马体通过密集连接的神经元网络实现快速关联检索,而新皮层负责处理感知输入。HippoRAG将这一机制转化为计算模型:LLM作为“人工新皮层”处理文本,知识图谱扮演“海马体索引”,检索编码器则模拟海马体周围区域的功能,负责节点间的关联。
方法论
海马体记忆索引理论(The Hippocampal Memory Indexing Theory)
海马体记忆索引理论由Teyler和Discenna于1986年提出,旨在提供一个人类长期记忆功能描述的模型。这一理论解释了涉及人类长期记忆的不同组件及其相互作用的方式,以实现两个主要目标:模式分离(pattern separation)和模式完成(pattern completion)。
-
模式分离:
定义:确保不同感知经验的表示是独特的,即每种体验都有其独特的神经表征。
机制:这一过程主要在记忆编码时发生,帮助区分相似但不同的经历或信息,避免混淆。 -
模式完成:
定义:使得从部分刺激中检索完整记忆成为可能,即当只给出部分线索时能够回忆起完整的记忆内容。
机制:这一过程依赖于海马体中的神经网络结构,能够在接收到部分输入后识别并重建完整的记忆表征。
感知输入的处理: 记忆过程始于新皮层接收并处理感官输入,将这些原始刺激转化为更高层次的特征。这些特征更易于操作且通常是抽象的。
信息路由至海马体: 经过新皮层初步处理的信息会被导向旁海马区(PHR),在这里进行索引化,并最终传递给海马体。
海马体的作用: 海马体负责对重要的信号进行索引,并与其他相关信号建立联系。这个过程对于形成新的记忆至关重要。
模式完成驱动的记忆检索: 当海马体接收到来自PHR的部分感官信号时,它会利用其依赖上下文的记忆系统来识别相关的完整记忆。这个过程被认为是在CA3亚区中通过密集连接的神经网络实现的。海马体会将识别出的相关记忆回传至PHR,再由新皮层模拟或重现这些记忆,使得个体能够基于部分线索回忆起完整的记忆内容。
HippoRAG的工作机制
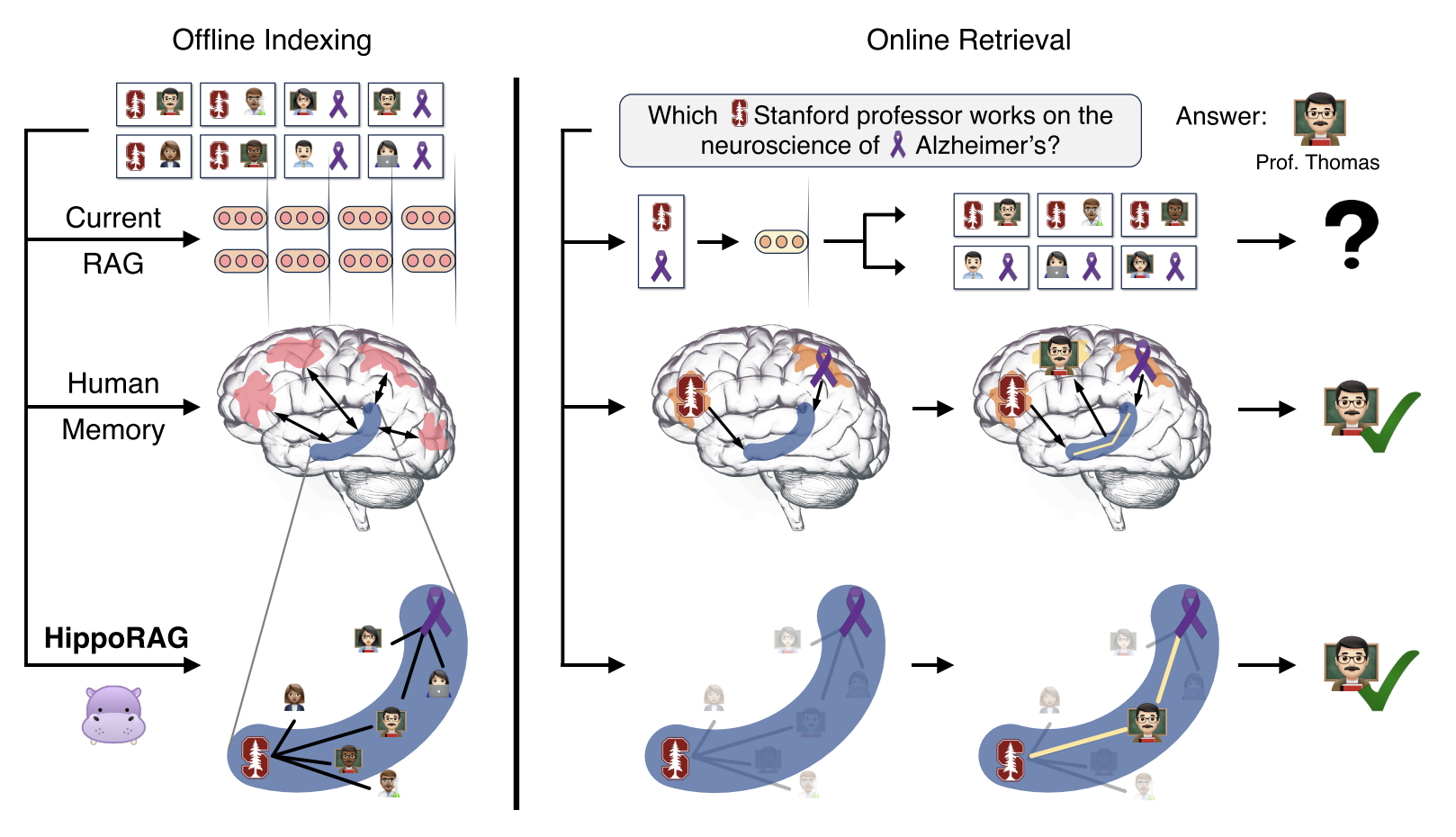
上面这张图展示了HippoRAG框架如何模仿人类记忆系统来增强大型语言模型(LLMs)的检索和推理能力:
| 离线索引阶段 | 在线检索阶段 | |
|---|---|---|
| Current RAG | 传统的RAG方法将多个文档被分割成段落(比如依据句子、段落或者文档边界),并通过编码器转换为向量表示。每个段落被存储在知识库中,以便后续检索。 | 传统的RAG系统可能会按照关键词检索出两条相关信息,但每条信息单独来看都不足以直接回答这个问题。 |
| Human Memory | 新皮层负责处理和存储信息,而海马体则负责将短期记忆转化为长期记忆。 | 当人类接收到一个问题时,大脑的新皮层首先处理这个信息。新皮层负责将感知输入转换为更易于操作的形式,然后通过旁海马区传递给海马体。海马体在此过程中执行模式分离(确保不同经验的记忆表示是独特的)和模式完成(根据部分线索回忆完整记忆)的功能。海马体利用其内部的神经网络结构识别与查询最相关的记忆,并将其送回新皮层进行综合处理。 |
| HippoRAG | HippoRAG框架模拟了人脑的记忆机制,特别是海马体的功能。图中显示了一个类似海马体的结构(蓝色区域),其中包含多个节点(代表实体)和边(代表关系)。这些节点和边构成了一个知识图谱,用于存储和检索信息。 | 使用LLM从查询中识别出关键概念(如“斯坦福大学”和“阿尔茨海默病”)。在知识图谱上运行个性化PageRank算法,以查询概念作为种子节点。该算法能够在知识图谱中探索路径,找到相关联的子图,从而实现多跳推理。根据算法的输出,识别出最相关的知识节点(例如Prof. Thomas),并将其作为答案返回给用户。这种方法可以在单一步骤内完成复杂的多跳推理,避免了传统RAG方法中所需的多次检索步骤。 |
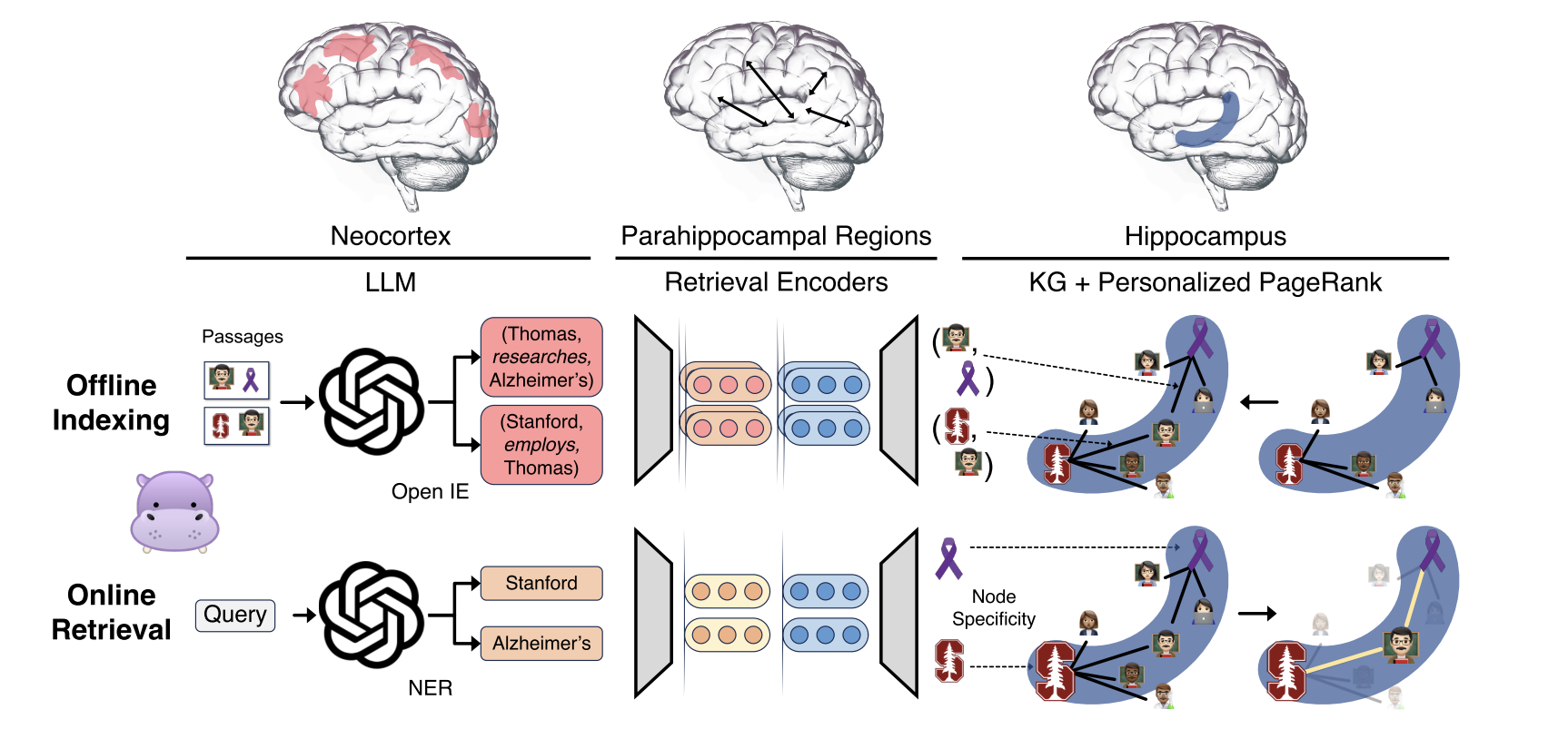
HippoRAG的核心创新在于将神经科学与信息检索技术结合。其方法论可分为三部分:
离线索引:使用指令调优的LLM(如GPT-3.5)从文本中提取名词短语节点和关系边,构建开放知识图谱。例如,从段落“Alhandra出生于Vila de Xira”中提取三元组(Alhandra, born in, Vila de Xira)。为了增强图的连通性,系统还通过检索编码器(如Contriever)添加同义关系边,例如将“Stanford University”与“Stanford”节点连接。
知识图谱构建:
import json
import torch
from transformers import AutoTokenizer, AutoModel
import igraph as igclass HippoRAGIndexer:def __init__(self, llm_model="gpt-3.5-turbo", retriever_model="facebook/contriever"):# 初始化LLM(实际使用时需替换为API调用)self.llm = LLMClient(llm_model) # 初始化检索编码器self.retriever_tokenizer = AutoTokenizer.from_pretrained(retriever_model)self.retriever_model = AutoModel.from_pretrained(retriever_model)def extract_triples(self, text, named_entities):"""使用LLM从文本中提取开放关系三元组"""prompt = f"""Convert the following paragraph into JSON with named entities and triples:Paragraph: {text}Named Entities: {named_entities}"""response = self.llm.generate(prompt)return json.loads(response)["triples"]def build_knowledge_graph(self, passages):"""构建知识图谱"""graph = ig.Graph(directed=True)node_to_id = {}passage_to_nodes = {}for passage_id, passage in enumerate(passages):# Step 1: 提取命名实体named_entities = self.extract_named_entities(passage)# Step 2: 提取三元组triples = self.extract_triples(passage, named_entities)# Step 3: 添加节点和边到图谱passage_nodes = set()for (head, rel, tail) in triples:for entity in [head, tail]:if entity not in node_to_id:node_to_id[entity] = len(node_to_id)graph.add_vertex(name=entity)graph.add_edge(node_to_id[head], node_to_id[tail], label=rel)passage_nodes.update([head, tail])passage_to_nodes[passage_id] = passage_nodes# Step 4: 添加同义边(基于检索编码器相似度)self._add_synonym_edges(graph, node_to_id)return graph, passage_to_nodesdef _add_synonym_edges(self, graph, node_to_id, similarity_threshold=0.8):"""基于语义相似度添加同义边"""nodes = list(node_to_id.keys())embeddings = self._get_embeddings(nodes)for i in range(len(nodes)):for j in range(i+1, len(nodes)):sim = cosine_similarity(embeddings[i], embeddings[j])if sim > similarity_threshold:graph.add_edge(node_to_id[nodes[i]], node_to_id[nodes[j]], label="SYNONYM")def _get_embeddings(self, texts):"""获取检索编码器的嵌入向量"""inputs = self.retriever_tokenizer(texts, padding=True, return_tensors="pt")with torch.no_grad():outputs = self.retriever_model(**inputs)return outputs.last_hidden_state.mean(dim=1)
在线检索:首先从查询中提取命名实体(如“斯坦福教授”和“阿尔茨海默症”),通过检索编码器将其映射到知识图谱的节点上。随后,PPR算法以这些节点为起点在图上游走,计算其他节点的关联概率。例如,查询“研究阿尔茨海默症的斯坦福教授”会激活图中“Thomas Südhof”节点(因其同时关联斯坦福和阿尔茨海默症研究)。最后,系统根据节点概率对段落重新排序,返回最相关的文档。
PPR算法:
class HippoRAGRetriever:def __init__(self, indexer, graph, passage_to_nodes):self.indexer = indexerself.graph = graphself.passage_to_nodes = passage_to_nodesself.node_to_passages = self._build_node_passage_map()def retrieve(self, query, top_k=5):"""核心检索流程"""# Step 1: 提取查询实体query_entities = self.indexer.extract_named_entities(query)# Step 2: 映射到知识图谱节点query_nodes = self._map_to_graph_nodes(query_entities)# Step 3: 运行个性化PageRankppr_scores = self._run_ppr(query_nodes)# Step 4: 计算段落得分passage_scores = self._score_passages(ppr_scores)return sorted(passage_scores.items(), key=lambda x: -x[1])[:top_k]def _run_ppr(self, query_nodes, damping=0.5):"""个性化PageRank算法"""personalization = {node: 1.0/len(query_nodes) for node in query_nodes}return self.graph.personalized_pagerank(reset_vertices=personalization,damping=damping)def _score_passages(self, ppr_scores):"""聚合节点得分到段落"""passage_scores = {}for passage_id, nodes in self.passage_to_nodes.items():score = sum(ppr_scores[self.graph.vs.find(name=node).index] for node in nodes)passage_scores[passage_id] = scorereturn passage_scoresdef _map_to_graph_nodes(self, entities):"""将查询实体映射到图谱节点"""entity_embeddings = self.indexer._get_embeddings(entities)node_embeddings = self.indexer._get_embeddings(self.graph.vs["name"])query_nodes = []for i, entity in enumerate(entities):similarities = torch.matmul(entity_embeddings[i], node_embeddings.T)best_node_idx = torch.argmax(similarities).item()query_nodes.append(self.graph.vs[best_node_idx]["name"])return query_nodes
节点特异性:受神经生物学启发,论文提出“节点特异性”概念,用于调整常见节点的权重(类似逆文档频率)。例如,“斯坦福”节点若出现在较少段落中,其权重会高于高频节点,从而在检索中优先激活稀有但重要的关联。
创新性
HippoRAG的创新性体现在以下几个方面:
单步多跳检索:传统方法需多次检索迭代才能完成多跳推理,而HippoRAG通过图搜索在单步内实现。实验显示,其在MuSiQue和2WikiMultiHopQA数据集上的检索召回率比最优基线分别提升3%和20%,且速度提高6-13倍。
生物启发的设计:模型首次将海马体索引理论完整映射到计算框架中,包括模式分离(通过OpenIE细粒度提取知识)和模式完成(通过PPR模拟关联激活)。
路径发现能力:现有方法难以解决的“路径发现”问题(如从分散线索中定位目标),HippoRAG能通过图关联有效处理。例如,它能从“斯坦福”和“阿尔茨海默症”两个独立线索中准确找到目标教授,而基线模型则完全失败。
成本效率:相比迭代检索方法IRCoT,HippoRAG的在线检索成本降低10-30倍,为实际部署提供了可行性。
实验结果
论文在三个多跳问答数据集(MuSiQue、2WikiMultiHopQA和HotpotQA)上验证了HippoRAG的性能:
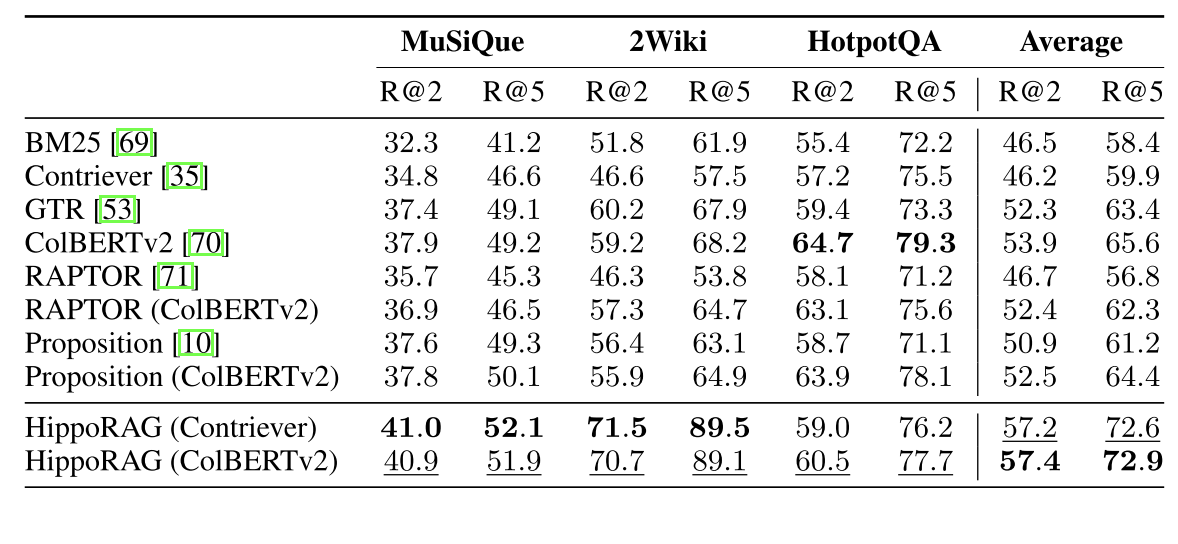
单步检索:HippoRAG在2WikiMultiHopQA上的R@5达到89.1%,远超ColBERTv2(68.2%)。在更具挑战性的“全支持文档检索”(AR@5)指标上,其优势进一步扩大至75.7%(基线37.1%)。
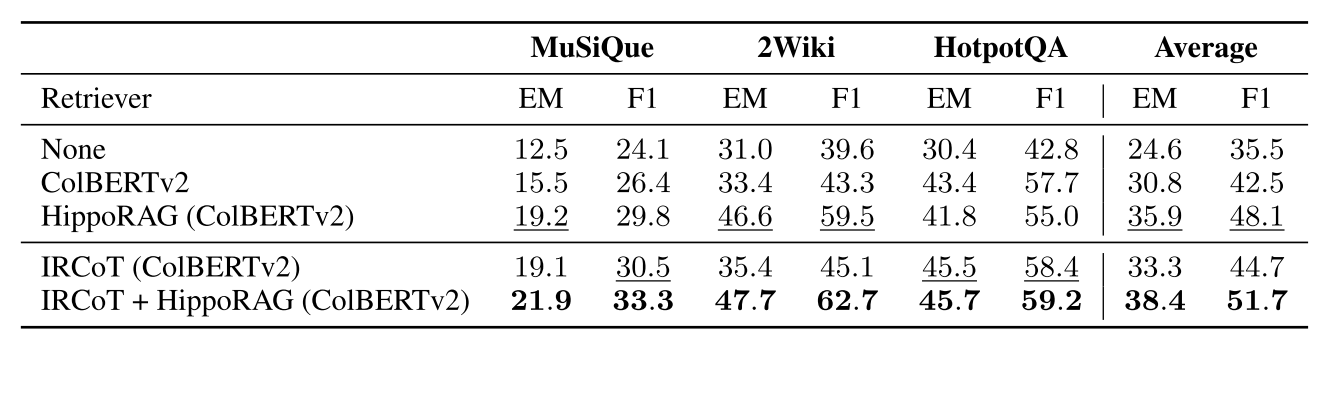
与迭代检索结合:将HippoRAG作为IRCoT的检索器时,性能进一步提升(如2WikiMultiHopQA的F1提高17%)。
效率对比:HippoRAG的在线检索耗时仅3分钟(IRCoT需20-40分钟),且API成本仅为0.1美元(IRCoT为1-3美元)。
此外,消融实验表明:
替换OpenIE模块为REBEL模型会导致性能骤降,凸显LLM在知识提取中的灵活性优势。
移除同义边或节点特异性会损害效果,尤其在实体中心的数据集(如2WikiMultiHopQA)上。
其中,PPR算法是关键,其性能远超简单邻居检索方法。
局限性
尽管成果显著,HippoRAG仍有以下局限:
概念与上下文权衡:模型过度依赖命名实体,可能忽略重要上下文线索。例如,查询“质子数量发现者”因未提取“原子序数”概念而失效。论文提出不确定性集成方法缓解该问题,但未完全解决。
OpenIE质量:LLM在长文档中的信息提取一致性较差(F1从71.8降至53.9),且可能遗漏关键信息(如歌曲名“Don’t Let Me Wait Too Long”)。
扩展性:尽管Llama-3.1-70B可替代GPT-3.5降低索引成本,但超大规模知识图谱的构建与检索效率仍需验证。
错误分析:48%的错误源于NER遗漏查询关键信息,28%来自OpenIE提取不完整,24%因PPR在混杂信号中失效。
总结
HippoRAG为LLM的长期记忆问题提供了新颖的解决方案。其生物启发的设计不仅实现了高效的单步多跳检索,还揭示了神经科学与AI结合的潜力。实验证明,该方法在性能、成本和速度上均显著优于现有技术,尤其擅长解决需要复杂知识整合的“路径发现”问题。然而,其在上下文敏感性、长文档处理和大规模扩展上的局限性,也为未来研究指明了方向——例如改进OpenIE的鲁棒性,或引入关系感知的图搜索算法。总体而言,这篇论文为构建更接近人类记忆机制的AI系统迈出了重要一步。