Linux 学习 6 文件相关命令包含查询
文件
功能非常多,建议稍微了解一下有一个印象,在具体需要使用的时候知道有这么一个东西即可,具体使用的时候再思考如何达成你想要的操作
创建文件
可以采取以下三种方式创建
顺便介绍一下这几个命令
echo命令
echo "创建文件:sss" > text
这会将你写的字符串重定向到 text中,如果没有text则会自动创建
echo实际上只是个打印输出的命令,创建文件靠的是重定向操作符>来完成的,会将你想要打印输出的内容重定向到text中,>会覆盖掉文件的内容,如果你想以追加的模式进行可以使用>>来完成
稍微介绍一下echo命令的选项,虽然估计用不上
echo -n helloecho默认会自带一个换行以便于让你的提示符出现在下一行,-n可以关闭这个
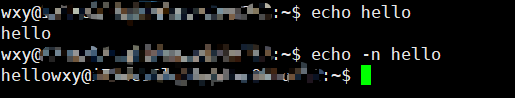
你可以注意到这里的字符串我没有加""字符串不是特别长包含空格或者转义字符就可以这样echo -e hello\n\n\necho默认不会解析转移字符,-e可以打开这个功能
touch命令
touch text
你可以使用这个命令来创建一个新文件
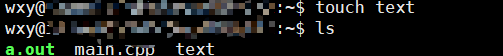
你也能一次创建几个
touch a b c
但是这其实不是touch的本意,虽然他可能是最经常的创建方式
touch英文是触摸,所以其实和这个意思差不多触摸一下文件,他的本意实际上是用来更新文件访问和修改时间的
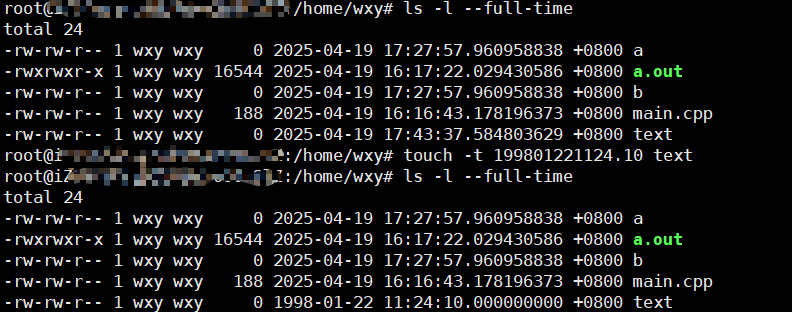
touch [OPTION]... FILES...
一般你也用不到这个操作
touch -a只更新访问时间touch -m只跟新修改时间touch -t你能自己指定时间
vim命令
这实际上是打开vim编辑器的命令
vim x.cpp #如果没有这个文件会创建,只要你选择保存退出即可
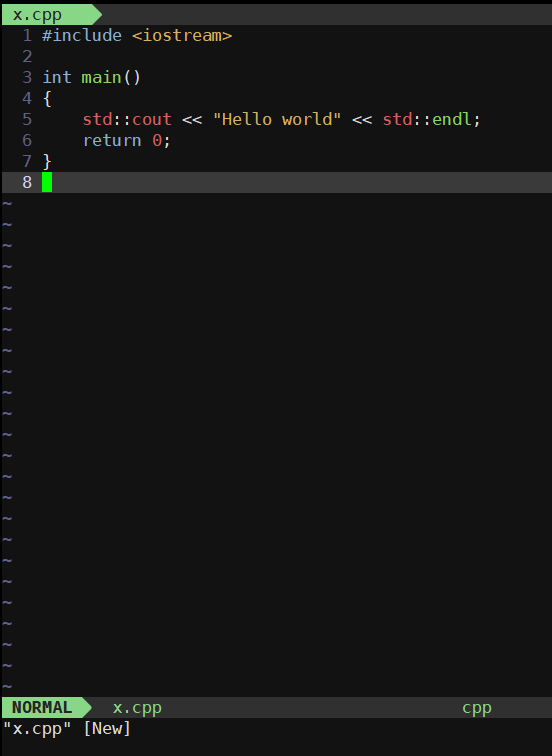
你可以看到vimplus自动给我们写了个hello world左下角也提示你了是新文件
查找文件
which命令
前面有简要的介绍过
这个可以用来查看可执行命令的地址
which bash
which -a vim # which默认只显示第一个找到的 -a可以全显示
find命令
这是一个功能十分强大的命令
find [搜索路径] [匹配条件] [操作]
搜索路径为你想要的搜索路径如果不指定就为当前目录
详细讲一下匹配条件
-
-name pattern查找名称符合pattern的文件这里支持普通通配符
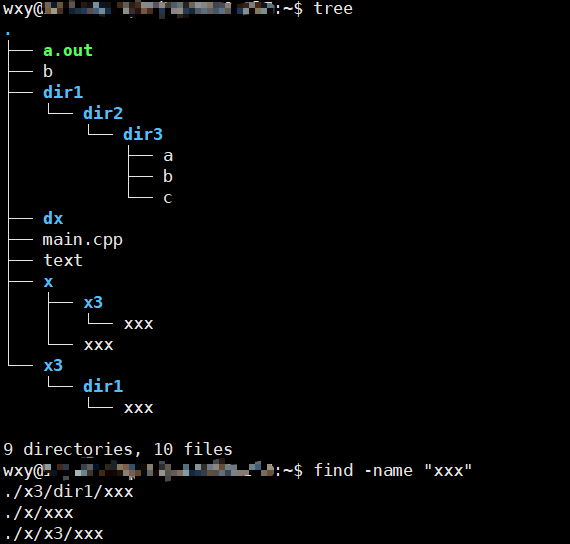
-
-type c查找类型为c的文件
默认会搜索所有类型的,支持以下类型

你可以采用,进行分格,指定多种类型 -
-size [+-]n[cwbkMG]查找满足大小条件的文件
+-代表大于或者小于,如果不指定则是等于
c:字节
w:双字
b:以512字节为单位的块
k:1024字节常见的1KB (小写的k)
M:1MB
G:1GB -
-user uname按用户的名字查找uname也可以是数字的用户ID -
-group gname按用户的组别来查找gname也能是数字的组ID -
-perm mode按权限查找,这里支持前面提到的数字权限 -
按时间查找
-atime n-amin n-cmin n-ctime n-mmin n-mtime n
其中a(access):文件访问时间c(change):文件属性发生改变的时间m(modify):文件内容发生改变的时间
min以分钟为单位,time以天为单位,同样支持[+-]用于指定大于和小于,如果没有则是等于
-
-maxdepth n闲置搜索深度为n -
组合查找
-a(and)与的逻辑-o(or)或的逻辑-!(not)非的逻辑
默认各种查找条件直接是与的逻辑
-
-exec 命令 {} \;允许你对搜索到的每一个文件执行命令操作
{}表示你当前匹配到的文件应用的位置\;表示命令结束(必须转义分号)# 将找到的 .log 文件移动到 backup 目录 find /var -name "*.log" -exec mv {} /backup \;还能使用
+代表所有文件一次传入当作参数,\;则是对每个文件依次处理find . -name "*.jpg" -exec cp {} /backup + #批量复制文件# 查找 30 天前的 .log 文件,压缩后删除 find /var/log -name "*.log" -mtime +30 \-exec gzip {} \; \-exec mv {}.gz /archive \;# 将所有 .png 转为 .jpg find ~/images -name "*.png" \-exec convert {} {}.jpg \; \-exec rm {} \;非常强大的命令
示例
# 1. 按名称查找文件
find . -name "*.txt" # 查找当前目录下所有 .txt 文件(区分大小写)
find /var -iname "readme*" # 查找忽略大小写(如 README.txt 或 readme.TXT)# 2. 按类型过滤
find /tmp -type d # 查找所有目录
find /usr/bin -type l # 查找所有符号链接
find ~ -type f -empty # 查找空文件# 3. 按时间搜索
find /var/log -mtime -7 # 查找 7 天内修改过的文件
find /backup -atime +30 # 查找 30 天前访问过的文件
find . -newer reference.txt # 查找比 reference.txt 更新的文件# 4. 按大小搜索
find /home -size +100M # 查找大于 100MB 的文件
find /tmp -size 0 -o -size -1k # 查找小于 1KB 的空文件# 5. 按权限/用户过滤
find /etc -perm 644 # 查找权限为 644 的文件
find / -user root # 查找属于用户 root 的文件
find /usr/bin -perm /u=x # 查找可执行文件# 6. 逻辑组合(AND/OR/NOT)
find . -name "*.jpg" -o -name "*.png" # 查找 .jpg 或 .png 文件(-o 表示 OR)
find /var -name "*.log" -size +1M ! -empty # 查找非空且大于 1MB 的 .log 文件
find . -type f ! -path "*/tmp/*" # 排除目录(! 表示 NOT)# 7. 对结果执行操作
find /tmp -name "*.tmp" -delete # 删除所有 .tmp 文件
find . -name "*.txt" -exec cp {} ~/backup \; # 将 .txt 文件复制到 backup 目录
find . -name "*.sh" -exec chmod +x {} \; # 更改所有 .sh 文件为可执行# 8. 使用正则表达式
find /logs -regex ".*/[0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\.log" # 查找日期格式的文件
find . -type f ! -regex ".*\.\(bak\|tmp\)$" # 排除 .bak 或 .tmp 文件# 9. 限制搜索深度
find /var -maxdepth 2 -name "*.conf" # 只搜索 2 层子目录
find . -path "*/.git" -prune -o -name "*.py" -print # 跳过 .git 目录# 10. 高级组合示例
find /var/log -name "*.log" -mtime -7 -size +10M -exec gzip {} \; # 查找并压缩符合条件的日志文件
find src/ -name "*.py" ! -path "*/tests/*" -exec wc -l {} \; # 统计代码行数(排除测试目录)
查看文件内容
cat命令
连接文件并在标准输出上打印, 其实就是打印文件内容
cat [OPTION]... [FILES]...
你也能一次多指定几个文件他们会拼接到一起

只介绍一个-n选项可以显示行号
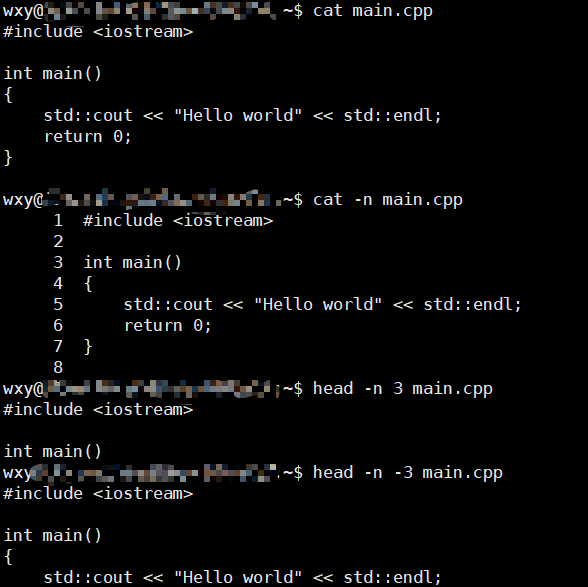
head命令
可以用来查看文件的前几行
head [OPTION]... [FILES]...
将每个文件的前10行打印出来,如果有多个文件则会显示标题名
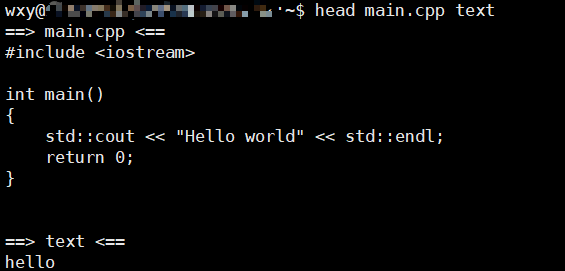
同样介绍一个-n即可,可以设定你想打印的行数支持负数
注意看我的示例head -n 3只会打印前面三行head -n -3除了后三行都打印
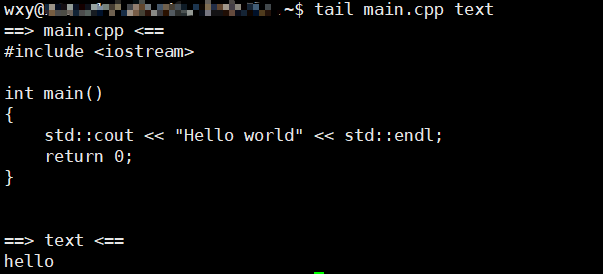
tail命令
打印文件的后几行
tail [OPTION]... [FILES]...
与head非常相似打印文件的后10行,如果多个文件则会按文件名分割
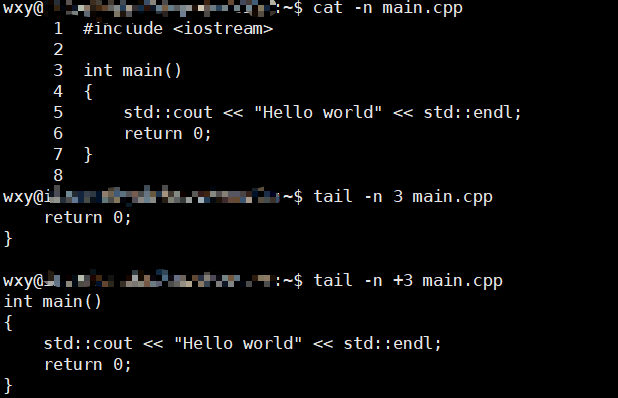
同样也支持-n参数不过这里支持的是+n代表跳过前面的n-1行这一点与head有所不同
你可以看到-n 3只打印了后三行而-n +3跳过了前面的3-1=2行开始打印,你可以理解为从第n行开始打印
less命令
如果没有less可以试试more
less text #浏览text
less text1 text2 # 浏览text1和text2

也支持一下vim的命令例如10G gg 也支持搜索什么的你可以试一试
不过感觉你估计不会用,感觉想更加轻便的vim
重定向
重定向允许我们控制命令的输入来源和输出去向
linux支持三种标准数据流
- 标准输入(stdin) - 文件描述符 0(默认来自键盘)
- 标准输出(stdout) - 文件描述符 1(默认输出到终端)
- 标准错误(stderr) - 文件描述符 2(默认输出到终端)
输出重定向
- 覆盖式输出重定向
>
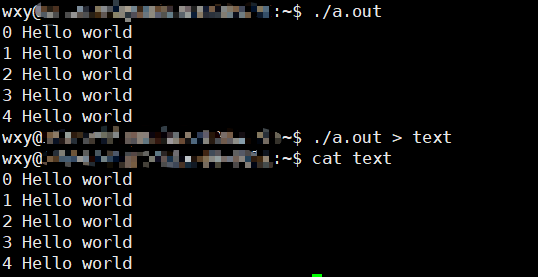
这个在创建文件的时候见过,会将你输出的内容重定向到指定的文件里
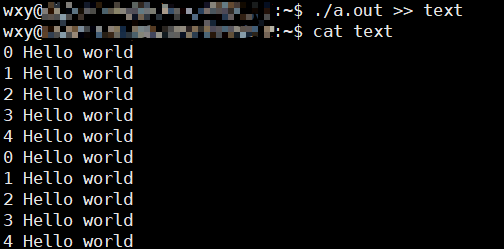
我写了个简单的cpp程序打印5行hello world 你甚至可以把这个内容重定向到文件里
- 追加式输出重定向
>>
不会覆盖而是追加
我又追加了一次出现了两次内容
- 标准错误重定向
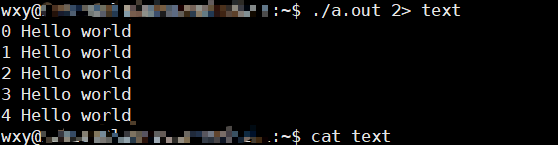
2>或2>>
由于没有错误,你可以看到正常输出还是能输出,因为没有错误text被清空了
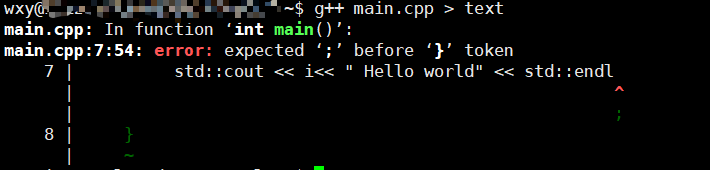
我现在删除了一个分号,你可以看到在编译的时候会报错,这是错误信息是无法通过>重定向到text中的
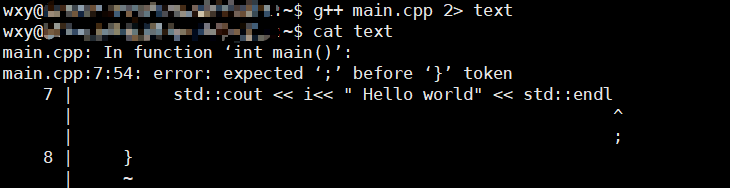
用错误重定向即可
- 同时重定向stdout和stderr
有可能你不知道会不会出错,你想把运行的结果都保留就可以用这个
有两种写法
command > output.log 2>&1
command &> output.log
第一种你可以理解为先将标准输出定向到文件,在用2>你可以将错误输出定位到&1这代表了当前的标准输出,所有他们重定向到一起了都指向文件
注意顺序很重要你如果写成command 2>&1 > file那么错误输出会先定向到标准输出,而标准输出定向到文件去了,错误输出还在原地,你可以理解为类似指针的操作或者直接采用第二种简洁的形式
输入重定向<
你可以读取文件的内容来使用命令
command < input.txt
注意必须要接受标准输入的命令才能这样像ls mv这样的命令都不行
使用<<<传递一个字符串作为输入
grep "hello" <<< "hello world"
组合命令
主要有一下三种
cmd1 ; cmd2先执行1再执行2cmd1 | cmd2管道操作,将cmd1的输出结果输入到cmd2中 这需要cmd2支持标准输入才行cmd1 | args cmd2可以将标准输入的每一行转换成cmd2的参数
搜索文件内容grep命令
grep [OPTION...] PATTERNS [FILE...]
grep会将匹配上pattern的每一行打印出来
介绍一下四种正则匹配模式
-F匹配固定字符串,将pattern 视为一个固定的字符串-G基本正则表达式 默写特殊的字符需要转义例如{} + * ()都需要转义,更高级的断言就更没法用-E大部分无需转义,仅有高级功能无法支持例如贪婪匹配懒惰匹配断言等-P支持基本所有功能
默认是使用-G模式
正则表达式的用法可以在这里看到
在介绍几个可选项
-n 显示行号
-c 只显示匹配的行的次数
-i 忽略大小写
-v 显示不匹配的行
-o 只输出匹配的内容
你可以自由组合编写你需要的正则表达式匹配文件内容
示例
# 搜索包含"error"的行(显示行号)
grep -n "error" logfile.log# 统计出现次数
grep -c "pattern" file.txt# 同时匹配A和B(AND逻辑)
grep "A" file | grep "B"# 匹配A或B(OR逻辑)
grep -E "A|B" file
# 提取IP地址(-o只输出匹配部分)grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' access.log# 匹配有效邮箱地址
grep -E '\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}\b' users.txt# 查找未闭合的HTML标签(简易版)
grep -P '<(\w+)[^>]*>(?!(.*</\1>))' page.html
链接ln命令
硬链接
本质:是文件系统的目录条目,指向同一个 inode
特点:
- 不能跨文件系统创建
- 不能链接到目录
- 删除原文件后,硬链接仍然有效
- 所有硬链接地位平等(没有"原始文件"概念)
inode:硬链接与原文件共享相同的 inode 编号
换句话说你可以通过不同的条目访问相同的文件,物理空间上只有一个文件
ln 源文件 硬链接名
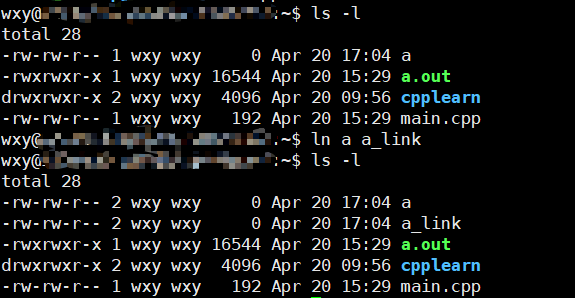
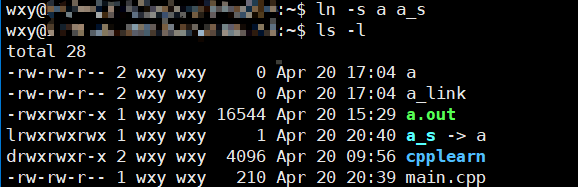
你可以看到
文件a的硬链接数从1变成了2
你可以注意到所有新建的目录硬链接数都是2 因为默认
.会是另一个硬链接,同理新目录会因为存在..而增加父目录的硬链接数
软链接
本质:是一个特殊文件,包含指向目标文件的路径
特点:
-
可以跨文件系统
-
可以链接到目录
-
删除原文件后,软链接将失效(成为"悬空链接")
-
有明确的原始文件概念
inode:软链接有自己的 inode
可以理解为windows的快捷方式
ls -s a a_link #创建文件a的软链接