Kubernetes相关的名词解释Metrics Server组件(7)
什么是Metrics Server?
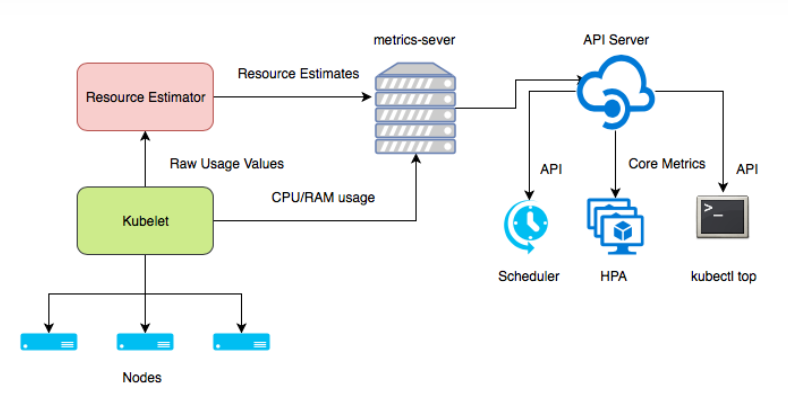
Metrics Server 是 Kubernetes 集群中的一个关键组件,主要用于资源监控和自动扩缩容。
kubernetes 从1.8版本开始不再集成cadvisor,也废弃了heapster,使用metrics server来提供metrics。那么......
什么又是单纯的Metrics?
Metrics 是 Kubernetes 中的基础监控数据。或者将Metrics定义为“基础指标”,"单纯的 metrics"(或基础指标)指的是:
-
核心资源使用数据:主要是 CPU 和内存的使用量/使用率
-
系统级指标:节点和 Pod 层面的基础性能数据
-
短期实时数据:当前或近期的资源使用情况,不包含长期历史数据
这些指标是 Kubernetes 自身运行和调度决策的基础依据。
Metrics 与 Metrics Server 的关系
依赖关系
-
Metrics 是数据:指实际的指标数据本身(如 CPU 使用率 75%)
-
Metrics Server 是服务:负责收集、聚合和暴露这些指标数据的组件
功能对应关系
| Metrics (指标数据) | Metrics Server (服务组件) |
|---|---|
| CPU 使用率 | 收集节点/Pod 的 CPU 数据 |
| 内存使用量 | 聚合内存指标 |
| 短期时间序列 | 通过 API 暴露这些数据 |
工作流程示例
-
数据产生:Kubelet 收集节点和 Pod 的原始 metrics(如 CPU 使用 nanoseconds)
-
数据收集:Metrics Server 定期从各节点 Kubelet 拉取这些 metrics
-
数据处理:Metrics Server 聚合原始数据(如转换为 millicores)
-
数据暴露:通过 Metrics API 提供格式化的指标数据
Metrics 是 Kubernetes 中的基础监控数据,而 Metrics Server 是官方提供的标准化组件,专门用于收集和暴露这些核心指标,两者是"数据"与"数据服务提供者"的关系。
Metrics Server主要用途
-
资源指标收集:从 Kubelets 收集节点和 Pod 的 CPU、内存等核心资源使用指标
-
Metrics API 实现:提供 Kubernetes Metrics API 的实现,使其他组件可以查询这些指标
-
Horizontal Pod Autoscaler (HPA) 支持:为 HPA 提供自动扩缩所需的指标数据
-
Vertical Pod Autoscaler (VPA) 支持:为垂直扩缩容提供基础指标
Metrics Server工作原理
-
定期从每个节点上的 Kubelet 收集指标数据(默认每60秒一次)
-
将数据聚合后存储在内存中(不持久化存储)
-
通过 Kubernetes Metrics API 暴露这些数据
与监控系统的区别
Metrics Server 不同于 Prometheus 等完整监控系统:
-
设计轻量级,只关注核心资源指标
-
数据不持久化,只保留短期历史
-
专为自动扩缩容等 Kubernetes 内部功能设计
Kubernetes 安装完成后会默认安装Metrics Server吗?
Kubernetes 核心安装通常不会默认包含 Metrics Server。
检查是否已安装
kubectl get pods -n kube-system | grep metrics-server
kubectl get apiservices | grep metrics.k8s.io如果没有任何输出,则表示未安装。
为什么不是默认安装?
资源考虑:不是所有集群都需要自动扩缩容功能
权限问题:需要一定的集群权限
灵活性:允许用户选择不同的监控方案
大多数生产环境都会安装 Metrics Server,但它确实不是 Kubernetes 核心组件的一部分。
Metrics Server有什么替代品么?
Metrics Server 是 Kubernetes 生态中官方推荐的核心指标收集方案,但它并不是唯一选择。以下是相关产品和替代方案的分类说明:
| 方案类型 | 典型产品 | 指标范围 | 数据存储 | HPA支持 | 额外功能 |
|---|---|---|---|---|---|
| 官方轻量级 | Metrics Server | 仅核心资源指标 | 内存 | 是 | 无 |
| Prometheus生态 | Prometheus+Adapter | 自定义指标 | 长期 | 是 | 报警、记录规则 |
| 全功能监控 | Datadog/Sysdig | 全栈指标 | 长期 | 是 | APM、日志、安全 |
| 云服务商方案 | CloudWatch/Stackdriver | 混合指标 | 长期 | 是 | 云服务集成 |
选择建议
-
基础需求:只需要 HPA 的 CPU/内存扩缩 → Metrics Server 足够
-
自定义指标:需要基于业务指标扩缩 → Prometheus + Adapter
-
企业监控:已有监控体系 → 选择对应厂商的集成方案
-
云环境:优先使用云厂商提供的托管方案