NLP 梳理03 — 停用词删除和规范化
一、说明
前文我们介绍了标点符号删除、文本的大小写统一,本文介绍英文文章的另一些删除内容,停用词删除。还有规范化处理。
二、什么是停用词,为什么删除它们?
2.1 停用词的定义
停用词是语言中的常用词,通常语义意义不大,但经常使用。英文中的例子包括 “the”、“is”、“in”、“and”、“to” 等。
2.2 为什么要删除停用词?
删除停用词,有以下考虑:
- 1 从增强模型性能上考虑
停用词可能会在分析中引入噪声。
删除它们使模型能够专注于有意义的单词,从而提高准确性。 - 2 降维目的
停用词会添加不必要的标记,从而增加数据集的大小。
通过删除非索引字,可以降低特征空间的维数,从而提高模型的效率。
example_text = "The cat is sitting in the garden."
important_words = ["cat", "sitting", "garden"] # Stopwords removed
三、归一化技术简介
文本处理中的规范化是将文本转换为一致的标准格式以减少可变性的过程。
3.1 归一化技术
1 删除多余的空格
单词之间的多个空格可能会导致分析过程中出现问题。规范化会删除这些多余的空格。
2. 将文本转换为一致的格式
将文本小写可确保一致性。
替换缩写(例如,将 “don’t” 替换为 “do not”)。
3.2 标准化的重要性
维护数据的完整性。
减少由文本格式变化引起的歧义。
example_text = " This is an example text! "
normalized_text = "this is an example text"
四、使用 NLTK、spaCy 或自定义列表删除停用词
4.1 使用 NLTK 删除非索引字
I:下载 NLTK 资源
import nltk # Download necessary NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
II:文本处理
from nltk.corpus import stopwords text = "The quick brown fox jumps over the lazy dog."
words = nltk.word_tokenize(text) # Tokenize the input text
stop_words = set(stopwords.words('english')) # Get the set of English stopwords # Filter out stopwords from the tokenized words
filtered_words = [word for word in words if word.lower() not in stop_words] print("Original:", words)
print("Filtered:", filtered_words)
输出:
Original: [‘The’, ‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘over’, ‘the’, ‘lazy’, ‘dog’, ‘.’]
Filtered: [‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘lazy’, ‘dog’, ‘.’]
4.2.使用 spaCy 删除停用词
import spacynlp = spacy.load("en_core_web_sm")text = "The quick brown fox jumps over the lazy dog."
doc = nlp(text)
filtered_words = [token.text for token in doc if not token.is_stop]print("Original:", [token.text for token in doc])
print("Filtered:", filtered_words)
输出:
Original: [‘The’, ‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘over’, ‘the’, ‘lazy’, ‘dog’, ‘.’]
Filtered: [‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘lazy’, ‘dog’, ‘.’]
示例 1:在数据集中实施停用词删除并规范化文本
在自然语言处理 (NLP) 中,预处理对于在分析之前提高文本数据的质量至关重要。本教程重点介绍如何使用 Python 和 NLTK 库实现非索引字删除和文本规范化。
- 设置和导入
首先,确保导入必要的库并下载所需的 NLTK 数据。
import re
import nltk
from nltk.corpus import stopwords # Download necessary NLTK resources
nltk.download('stopwords')
nltk.download('punkt')
- 文本清理功能
定义一个函数,该函数对文本执行多个预处理步骤:转换为小写、删除标点符号、分词和筛选出非索引字。
import string
import nltkdef remove_punctuation(text):return "".join(char for char in text if char not in string.punctuation)def clean_text(text, stop_words):# Convert to lowercasetext = text.lower()# Remove punctuation text = remove_punctuation(text)# Remove punctuation # text = re.sub(r'[\W_]+', ' ', text)# Tokenize textwords = nltk.word_tokenize(text)# Remove stopwordsfiltered_words = [word for word in words if word not in stop_words]return " ".join(filtered_words)
五、删除停用词并规范化文本示例(1)
使用 NLTK 设置英文停用词,并将清理功能应用于每个示例文本。打印清理后的结果以进行比较。
sample_texts = [ "The quick brown fox jumps over the lazy dog.", "This is an example of text preprocessing!", "Stopword removal and normalization are essential steps in NLP."
]stop_words = set(stopwords.words('english')) for text in sample_texts: cleaned_text = clean_text(text, stop_words) print("Original:", text) print("Cleaned:", cleaned_text) print()
- 输出
当您运行上述代码时,您将看到原始文本及其清理后的版本,展示了停用词删除和文本规范化的有效性。
Original: The quick brown fox jumps over the lazy dog.
Cleaned: quick brown fox jumps lazy dogOriginal: This is an example of text preprocessing!
Cleaned: example text preprocessingOriginal: Stopword removal and normalization are essential steps in NLP.
Cleaned: stopword removal normalization essential steps nlp
结果分析
观察如何删除 “the”、“is” 和 “and” 等非索引字。
请注意规范化的影响,例如一致的小写和删除标点符号。
五、删除停用词并规范化文本示例(2)
示例 2:试验 spaCy 的 Property属性is_stop
利用 spaCy 的内置功能来识别非索引字,深入了解文本预处理。
- 设置
在开始之前,请确保您已安装 spaCy 并下载了英语模型。您可以在终端中使用以下命令执行此作:
pip install spacy
python -m spacy download en_core_web_sm
设置 spaCy 后,您可以导入库并加载英文模型:
import spacy # Load the English NLP model
nlp = spacy.load("en_core_web_sm")
- 文本分析
定义一个函数,该函数处理输入文本并利用 spaCy 的属性is_stop来标识非索引字和非非停用词。
def identify_stopwords(text): # Process the input text with spaCy doc = nlp(text) stopwords = [token.text for token in doc if token.is_stop] non_stopwords = [token.text for token in doc if not token.is_stop] return stopwords, non_stopwords
接下来,创建一个要分析的示例句子列表:
sample_sentences = [ "The quick brown fox jumps over the lazy dog.", "This is another example for testing purposes.", "Natural Language Processing is fascinating and powerful."
] # Analyze each sentence for stopwords
for sentence in sample_sentences: stopwords, non_stopwords = identify_stopwords(sentence) print(f"Original Sentence: {sentence}") print(f"Stopwords: {stopwords}") print(f"Non-Stopwords: {non_stopwords}") print()
示例输出
当您运行代码时,输出将显示原始句子以及识别的停用词和非停用词,从而深入了解其重要性。
Original Sentence: The quick brown fox jumps over the lazy dog.
Stopwords: ['The', 'over', 'the']
Non-Stopwords: ['quick', 'brown', 'fox', 'jumps', 'lazy', 'dog', '.']Original Sentence: This is another example for testing purposes.
Stopwords: ['This', 'is', 'another', 'for']
Non-Stopwords: ['example', 'testing', 'purposes', '.']Original Sentence: Natural Language Processing is fascinating and powerful.
Stopwords: ['is', 'and']
Non-Stopwords: ['Natural', 'Language', 'Processing', 'fascinating', 'powerful', '.']
六、删除停用词并规范化文本示例(3)
示例 3:使用 spaCy 进行分词和语言分析
此 Python 脚本演示了使用 spaCy(一个强大的语言分析库)进行自然语言处理 (NLP)。该脚本执行标记化并从给定句子中提取各种语言特征。
加载 spaCy 的英语语言模型
nlp = spacy.load(“en_core_web_sm”)
加载小型英语模型 (en_core_web_sm),该模型提供预先训练的单词嵌入、POS 标记、依赖项解析等。
2. 处理文本
doc = nlp(“Big Brother is watching…probably on his new OLED TV.”)
函数nlp()处理文本并创建一个包含结构化语言数据的对象Doc。
3. 迭代标记并提取特征(使用适当的表格显示打印)
from tabulate import tabulate # Install via: pip install tabulate# Prepare data for tabulation
data = []
headers = ["Token", "Lemma", "POS", "Tag", "Dep", "Shape", "Alpha", "Stopword"]for token in doc:data.append([token.text, token.lemma_, token.pos_, token.tag_, token.dep_,token.shape_, token.is_alpha, token.is_stop])# Print as a table
print(tabulate(data, headers=headers, tablefmt="fancy_grid"))
输出:
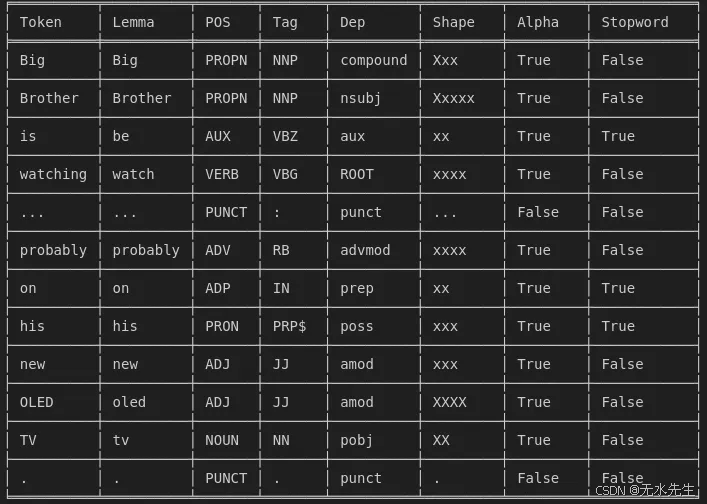
循环迭代文本中的每个标记(单词或标点符号)并打印以下属性:
token.text→ 原词
token.lemma_→ 单词 (lemma) 的基本形式
token.pos_→ 词性 (POS)
token.tag_→ 详细的 POS 标签
token.dep_→ 与根词的依赖关系
token.shape_→ Word 形状(例如,“Xxxx”代表“Apple”)
token.is_alpha→ 令牌是字母 ( 还是TrueFalse)
token.is_stop→ 令牌是停用词 ( 或TrueFalse)
七、结论
本教程介绍了停用词删除和规范化在文本预处理中的重要性。使用 NLTK 和 spaCy 等库,我们实施了实用的解决方案来清理和准备 NLP 任务的文本。