突破网页数据集获取难题:Web Unlocker API 助力 AI 训练与微调数据集全方位解决方案
突破网页数据集获取难题:Web Unlocker API 助力 AI 训练与微调数据集全方位解决方案
背景
随着AI技术的飞速发展,诸如DeepSeek R1、千问QWQ32、文小言、元宝等AI大模型迅速崛起。在AI大模型训练和微调、AI知识库建设中,数据集的获取已成为不可或缺的基础。尤其是在面对各式各样的网页数据结构时,将其整理成可用的数据集是一项极具挑战的任务。开发者不仅需要付出大量的开发和人工成本,还需应对复杂的网页数据获取难题。在这种情况下,一款能够自动化解决网页数据获取问题的工具变得尤为重要。
本文将介绍网页解锁器Web Unlocker API、网页抓取Web-Scraper以及搜索引擎结果页SERP API等工具,特别适合中小企业解决商业化网页数据集问题,展示其如何解决AI数据集网页抓取的难题,提供高效、自动化的数据获取解决方案。
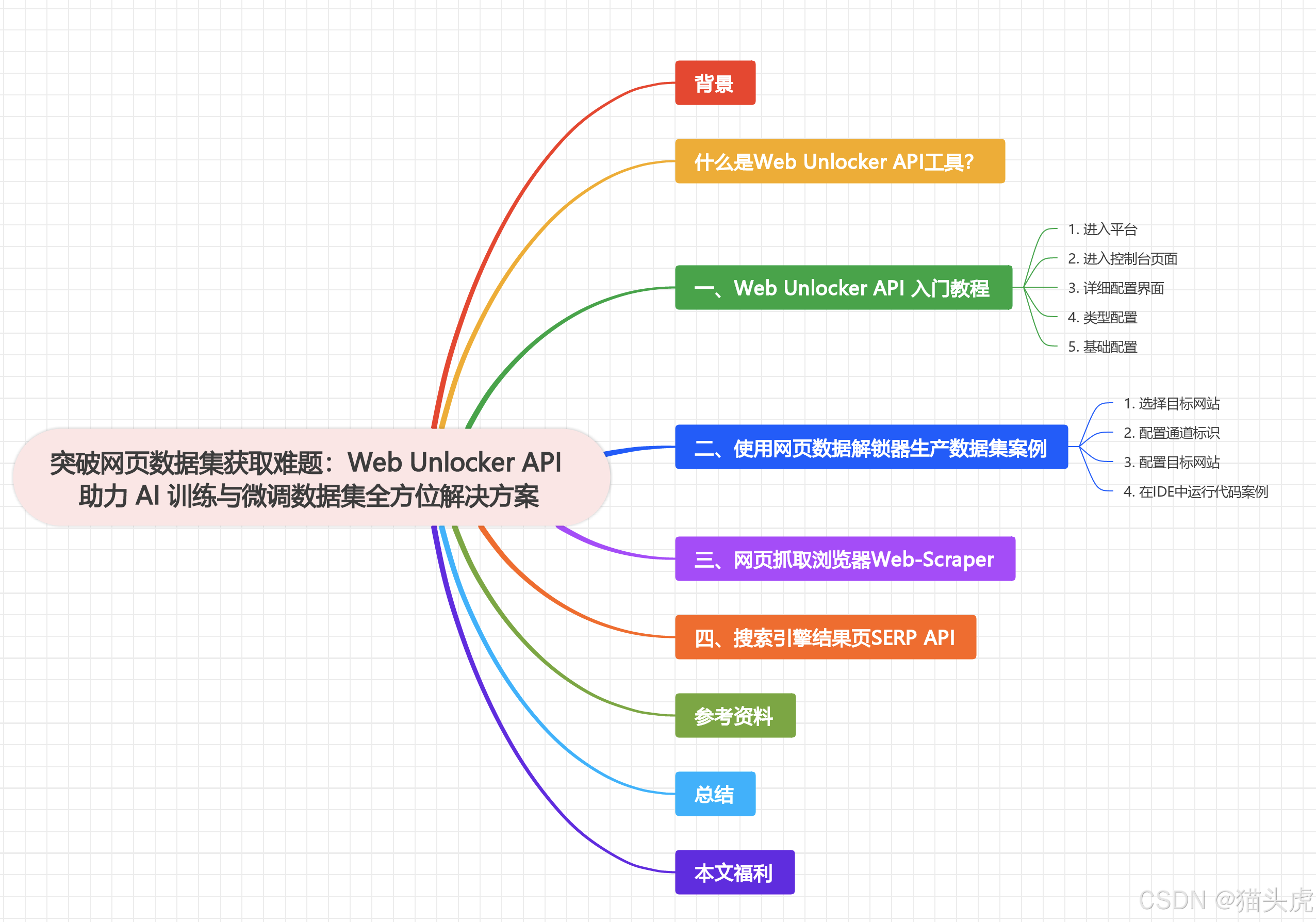
什么是Web Unlocker API工具?
Web Unlocker API是基于Bright Data的代理基础设施开发的,具备三个关键组件:请求管理、浏览器指纹伪装和内容验证。通过这些功能,它能够自动化处理所有网页解锁操作,包括CAPTCHA验证、浏览器指纹识别、自动重试机制以及请求头和cookies的定制。当你需要抓取像亚马逊这样具有高防护的网站数据时,这些功能尤为关键。
与常规代理服务不同,Web Unlocker API的优势在于:你只需发送包含目标网站的API请求,系统就会返回干净的HTML/JSON响应。后台系统智能化地管理了寻找最佳代理网络、定制请求头、处理指纹验证以及绕过CAPTCHA等复杂操作。
正文:
一、Web Unlocker API 入门教程
Web Unlocker API提供了便捷的接口,用户只需通过简单的API请求,就可以解锁大多数网站并获取所需数据。通过Web Unlocker,你可以绕过IP封禁、验证码以及复杂的网页结构,轻松获取所需的网页数据。
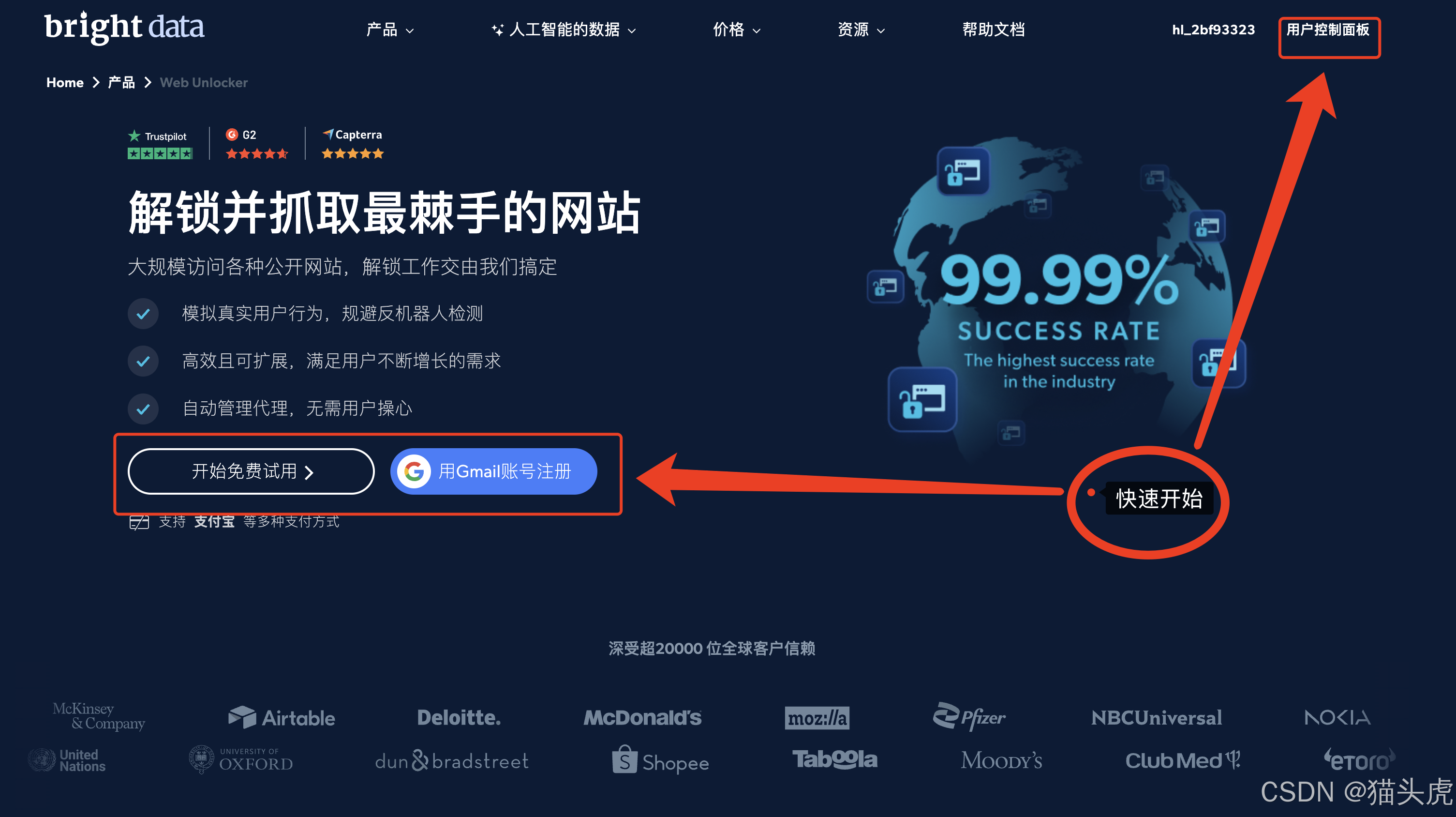
1. 进入平台
通过如下两个通道都可以快速进入用户控制台界面
两刀额度粉丝体验入口:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_maotouhu202504&promo=APIS25
2. 进入控制台页面
在控制台界面,点击左侧第一个菜单“Proxies & Scraping”,找到右侧的“网页解锁器”,点击开始使用即可进入详细配置界面。

3. 详细配置界面
这里分为三个小版块,分别为代理|抓取类型、基本配置、高级设置
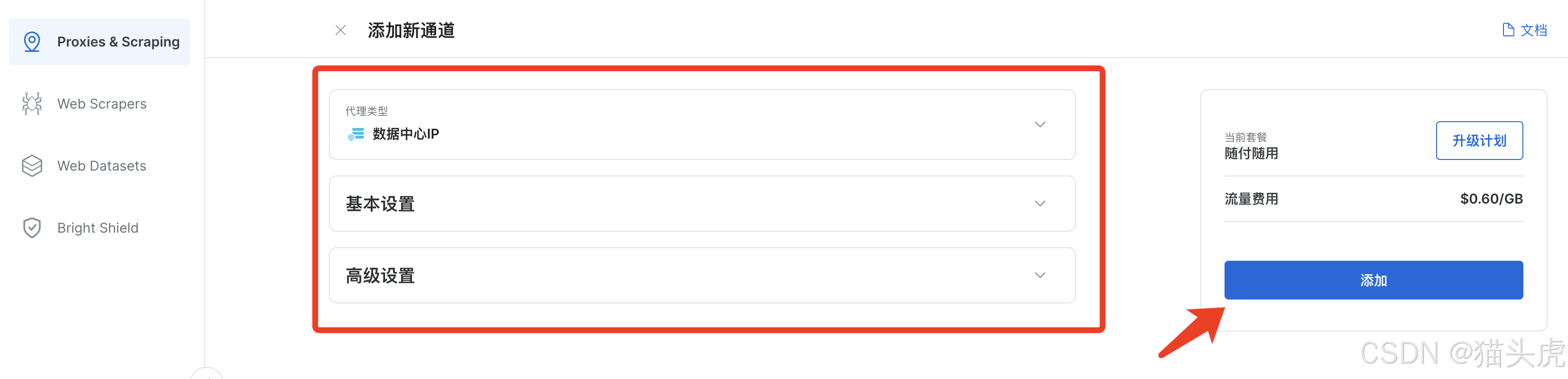
4. 类型配置
代理|抓取类型 选择网页解锁器
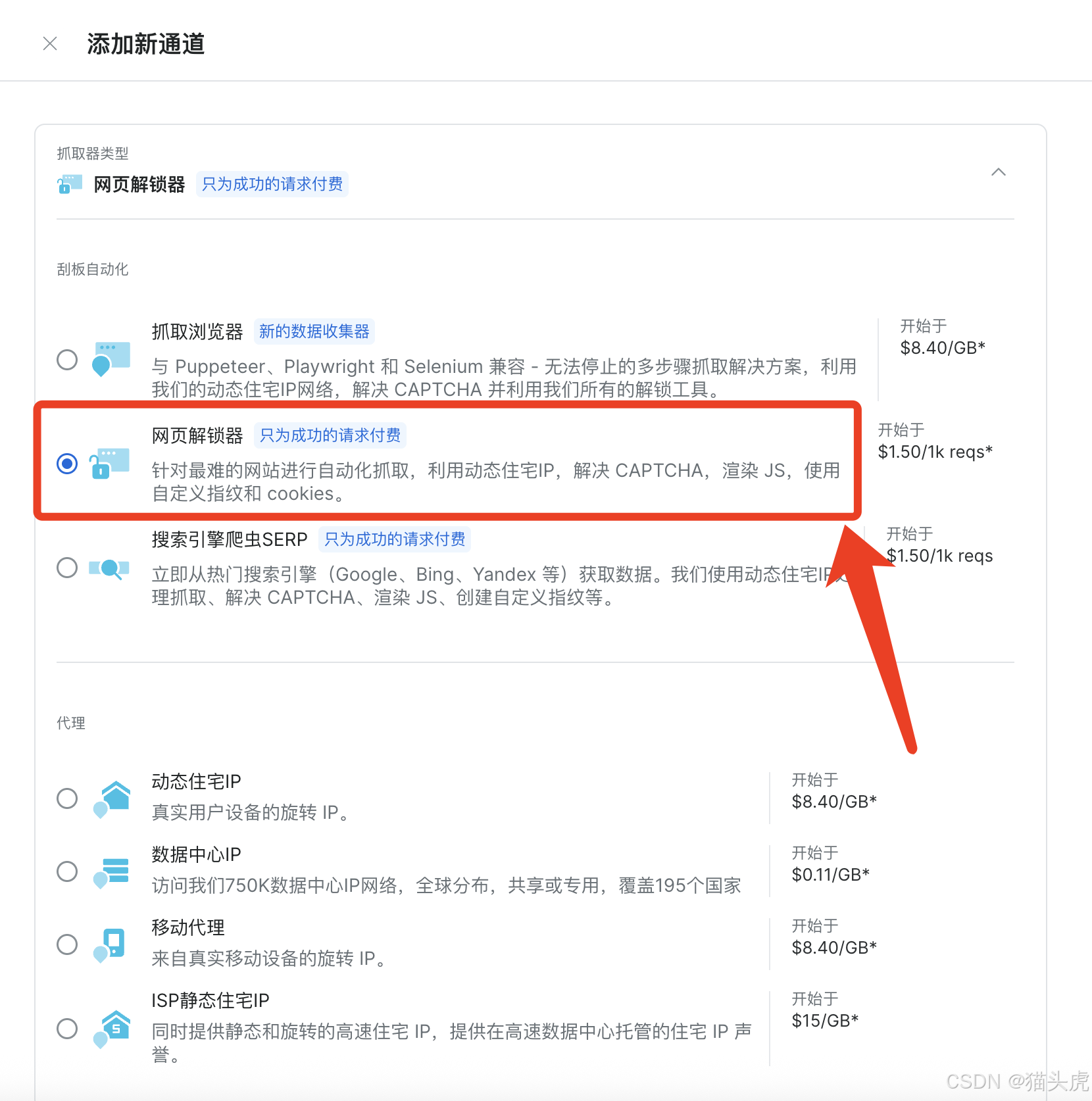
5. 基础配置
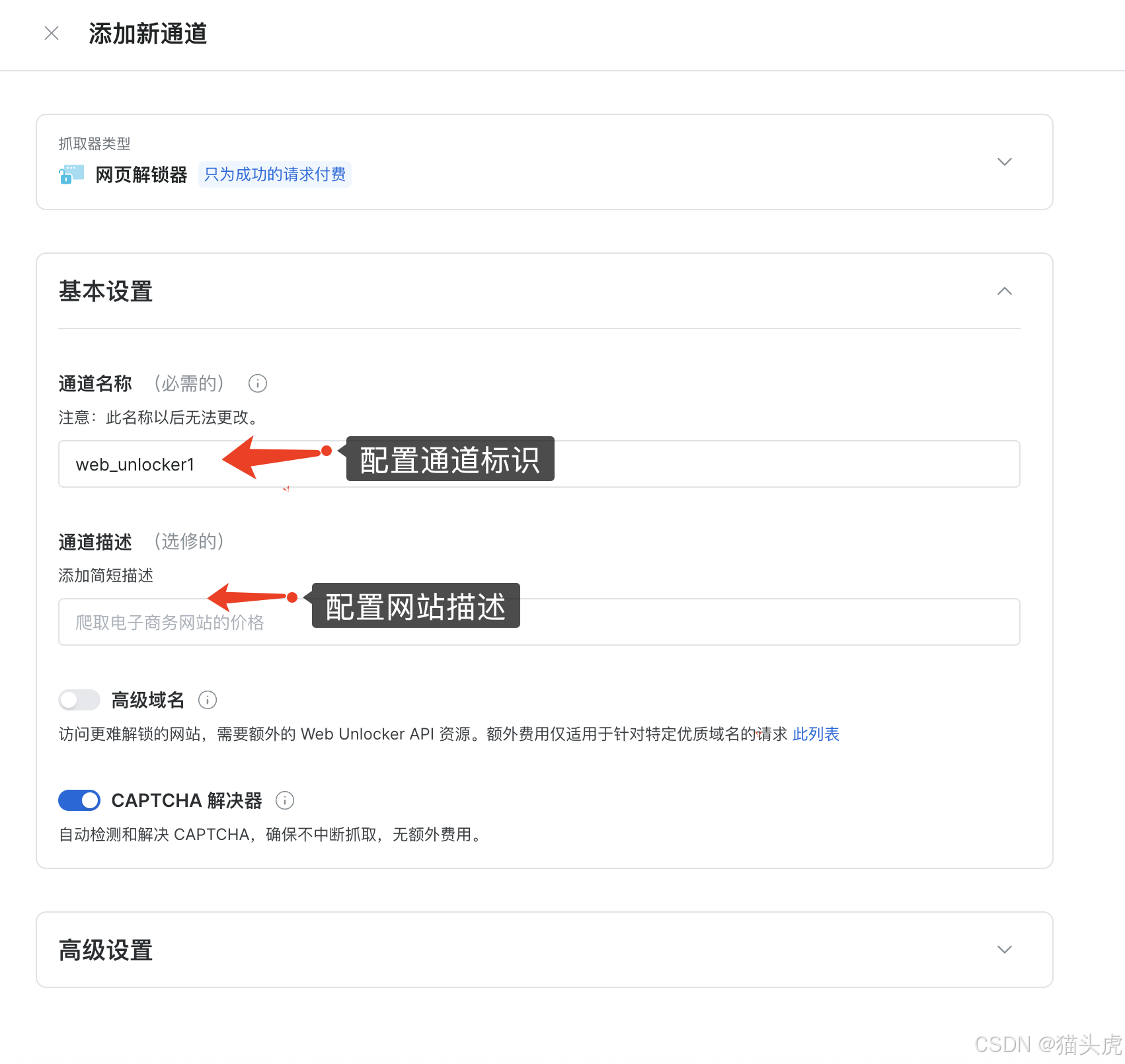
接下来一起来看看详细的使用案例
二、使用网页数据解锁器生产数据集案例
Web Unlocker API通过其简单易用的界面,用户能够在网页端快速设置目标网址,之后调用API自动化完成数据的解锁与获取。
1. 选择目标网站
目标网站:https://www.alignmentforum.org
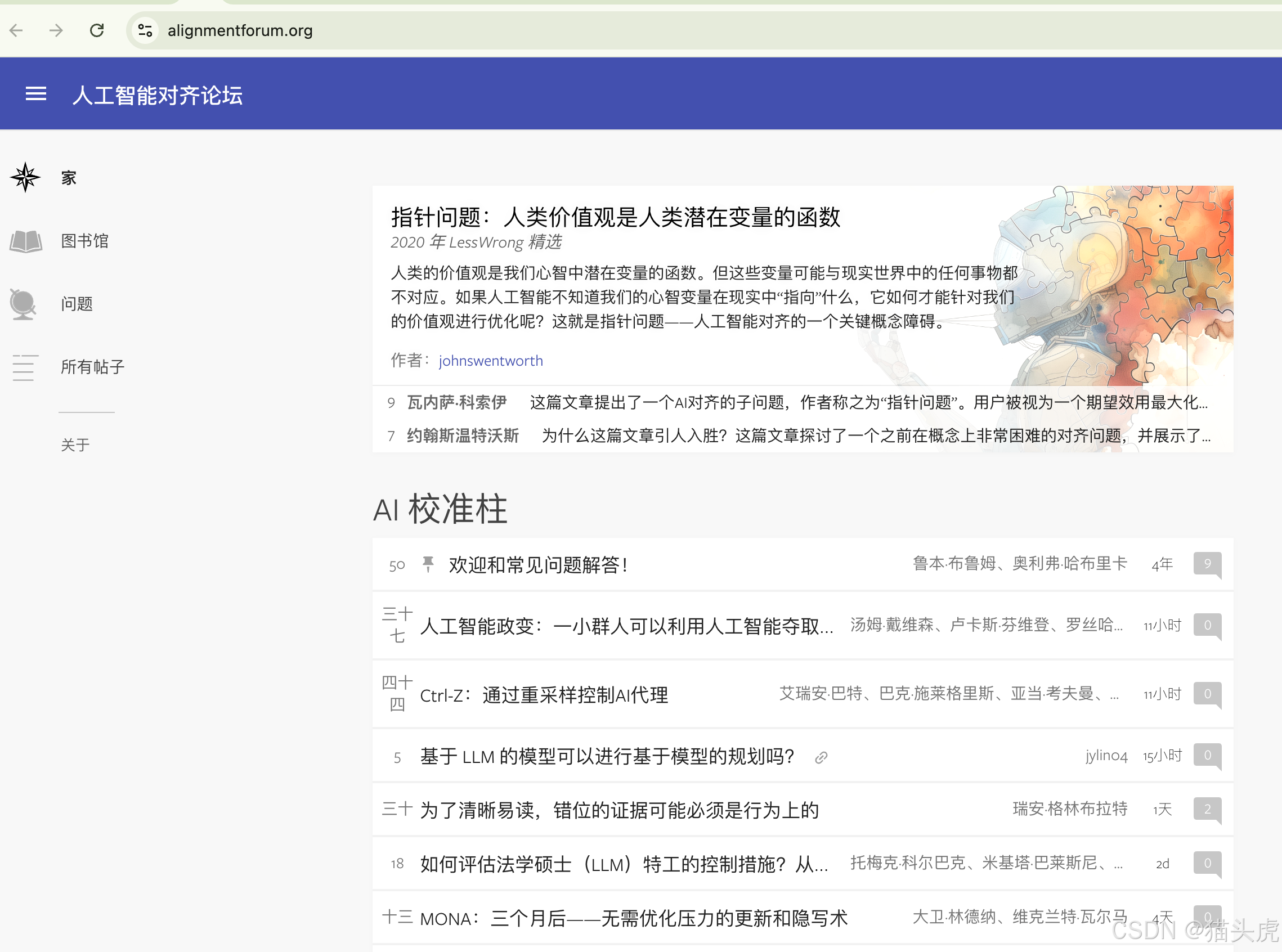
这个论坛专注于讨论AI对齐(AI Alignment)问题,特别是如何确保高级人工智能系统的目标与人类的价值观和利益保持一致。它汇聚了大量研究者和开发者,讨论AI安全性、伦理问题、未来发展等重要话题。
2. 配置通道标识
配置左侧的基本设置,之后点击右侧的添加通道即可
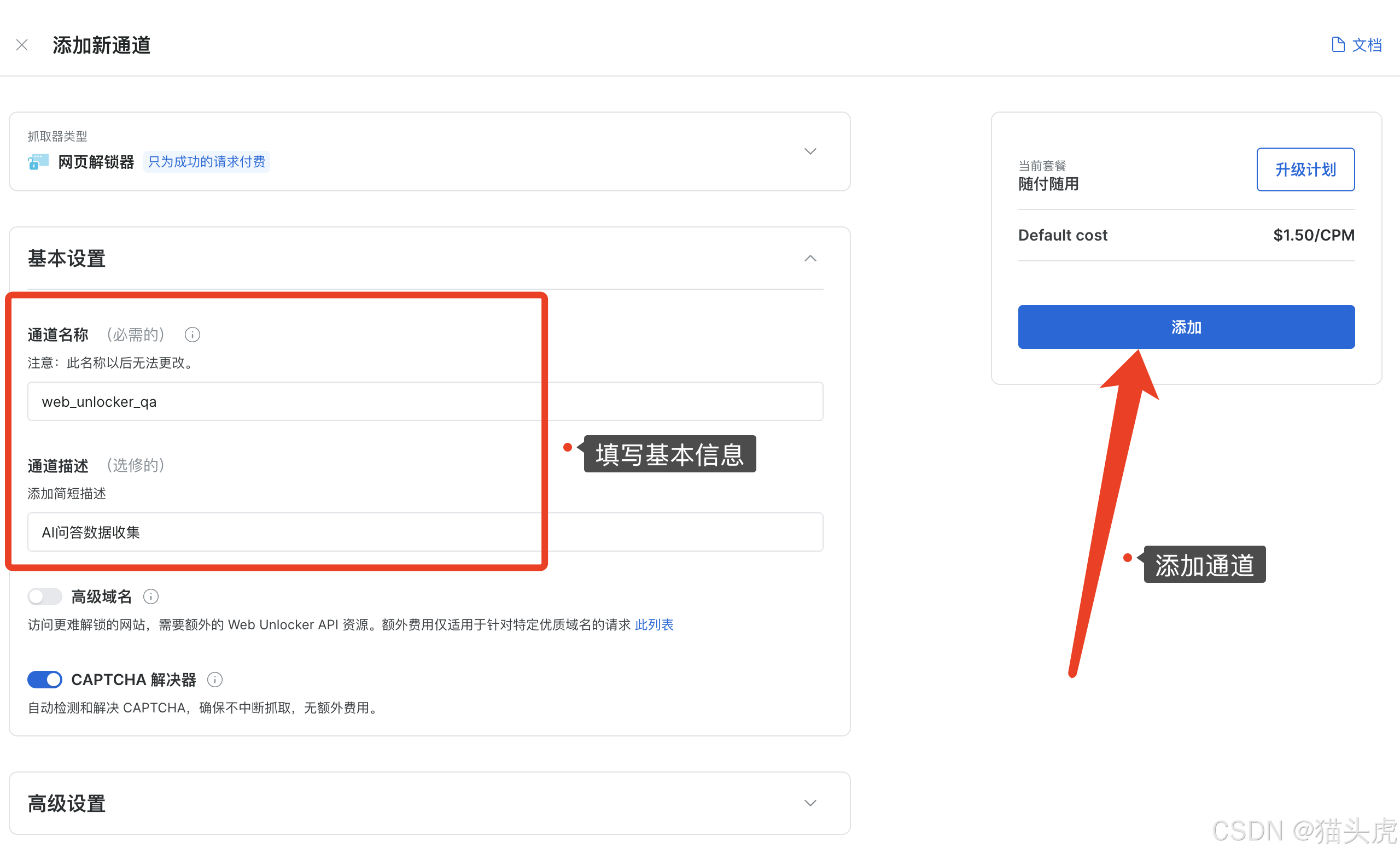
创建完成后,可以查看更多代码案例,我这里选择 Python 案例
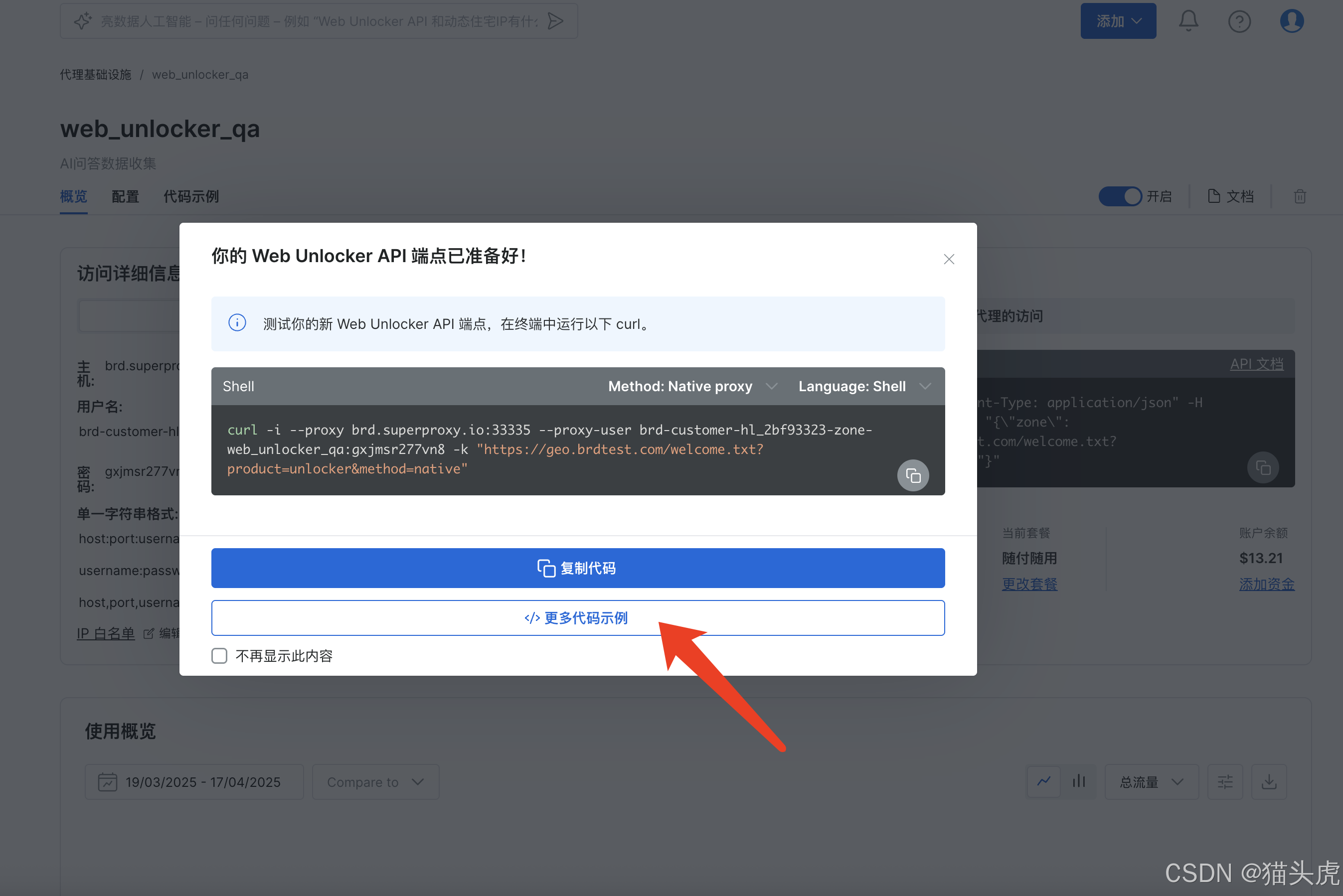
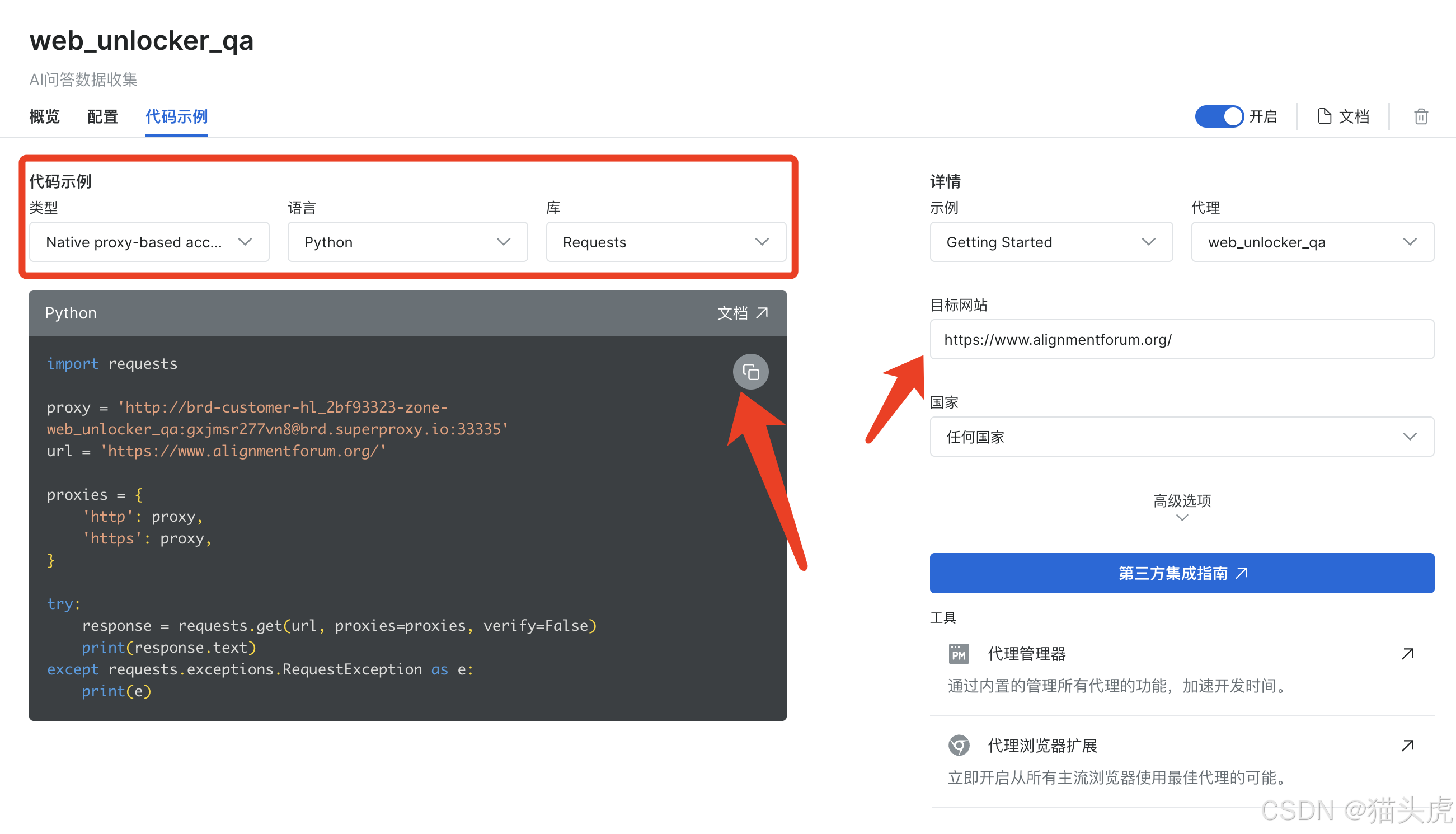
3. 配置目标网站
按照如下图所示,配置目标网站即可
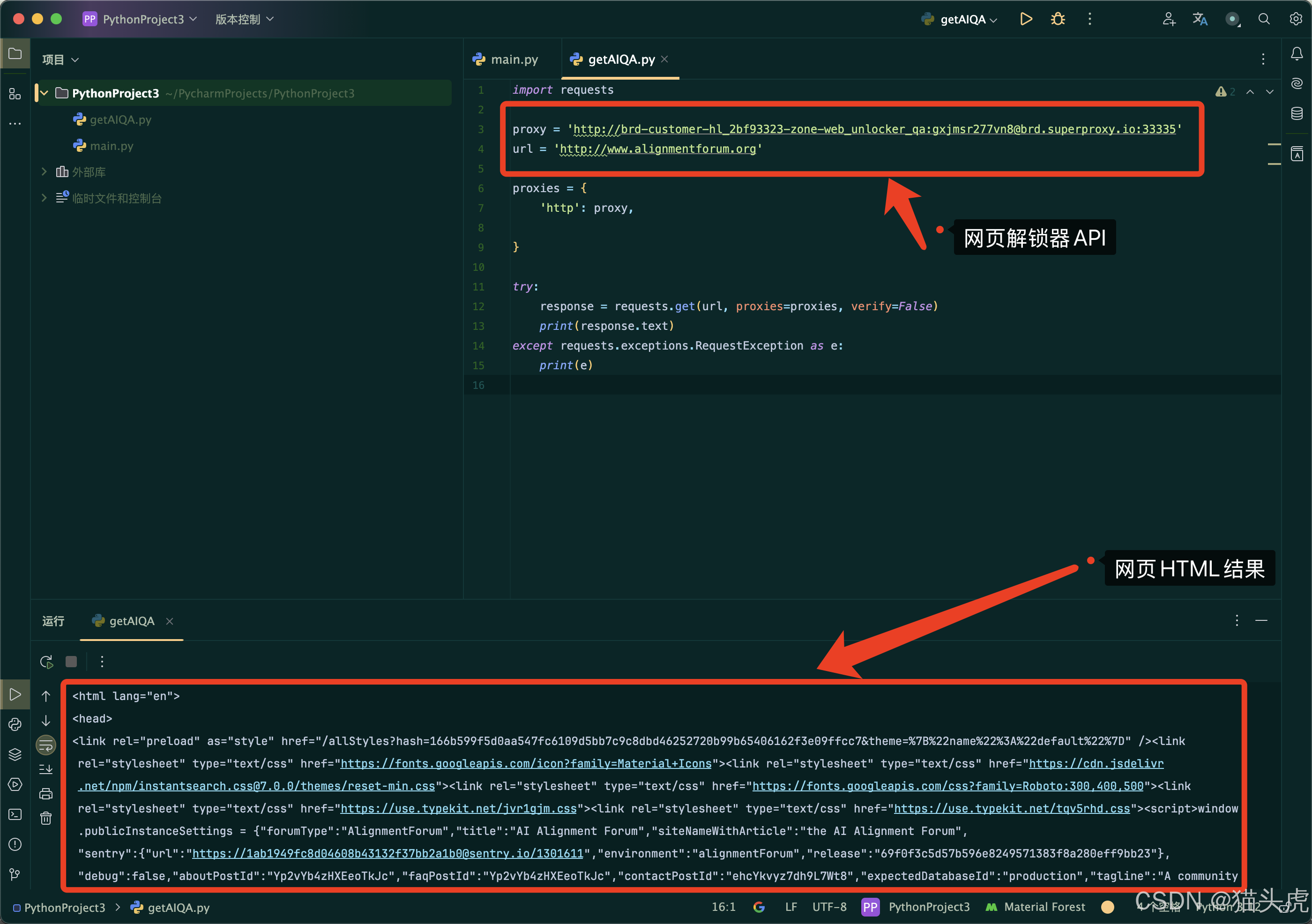
4. 在IDE中运行代码案例
接下来,复制左侧的代码案例,官方提供了一个基础的代码案例,运行效果如下:
虽然官方提供的代码案例相对基础,但也可以成功将网页数据提取,在实际使用过程中还需要将结果在做一次细粒度的清洗和处理,我做了部分字段提取,效果如下图所示:
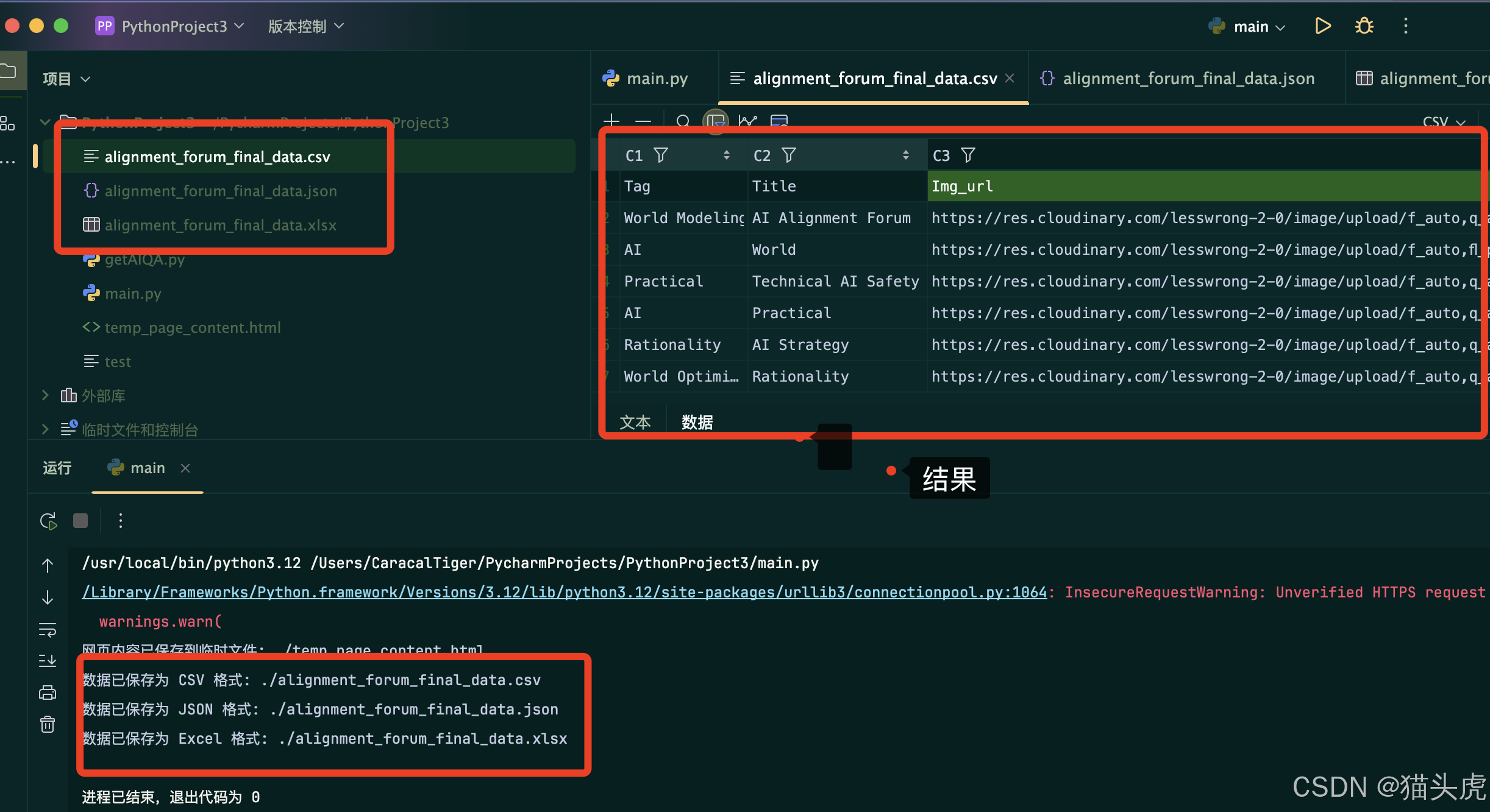
部分代码案例:
for category in categories:category_section = soup.find('div', {'class': category}) if category_section:tag = category_section.get('data-tag', '')title = category_section.find('h2').text if category_section.find('h2') else ''coords = category_section.get('data-coords', '')img_url = category_section.find('img')['src'] if category_section.find('img') else ''# 将数据整理到dataset中dataset.append({'Tag': tag,'Title': title,'Coords': coords,'Image URL': img_url})
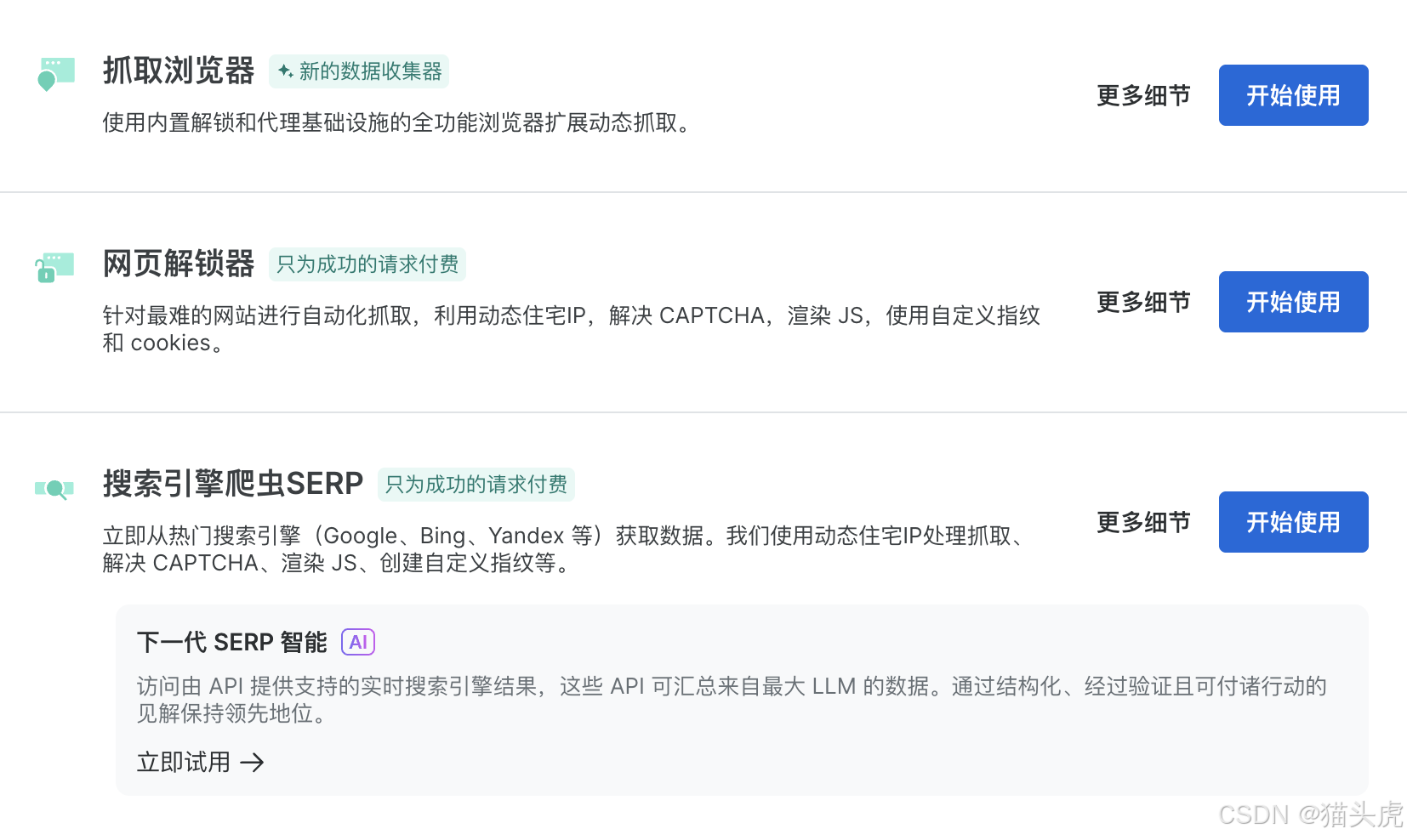
三、网页抓取浏览器Web-Scraper
Web Scraper API提供了强大的网页抓取功能,支持从简单到复杂的网页结构抓取,且支持动态内容加载。用户通过Web Scraper API能够精准地抓取目标网页上的所有数据,无论是商品信息、评论数据,还是其他类型的文本和图像信息。
网页抓取浏览器Web-Scraper的使用也很简单,直接在配置界面将网页解锁器切换为网页抓取浏览器即可。
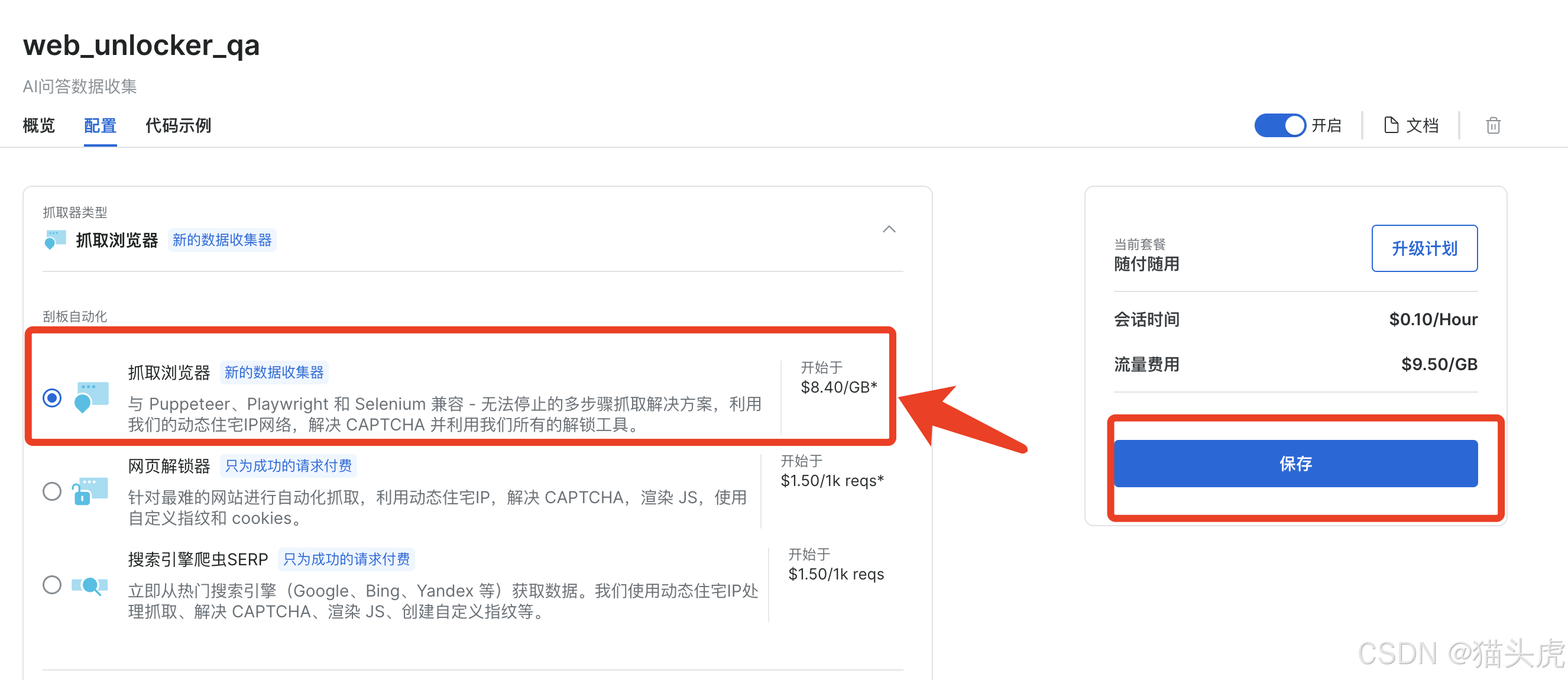
Scraping Browser 是网页解锁器抓取套件的一部分,旨在简化从浏览器进行的多步骤数据收集。
四、搜索引擎结果页SERP API
SERP API专注于抓取搜索引擎结果页面(Search Engine Result Pages,SERP)。它提供了针对Google、Bing等主流搜索引擎的定制化接口,帮助你快速获取搜索引擎的结果数据,适用于SEO分析、市场研究、领域知识库构建等多种场景。
同理,切换到搜索引擎结果页SERP API工具,也只需切换配置,保存通道信息即可
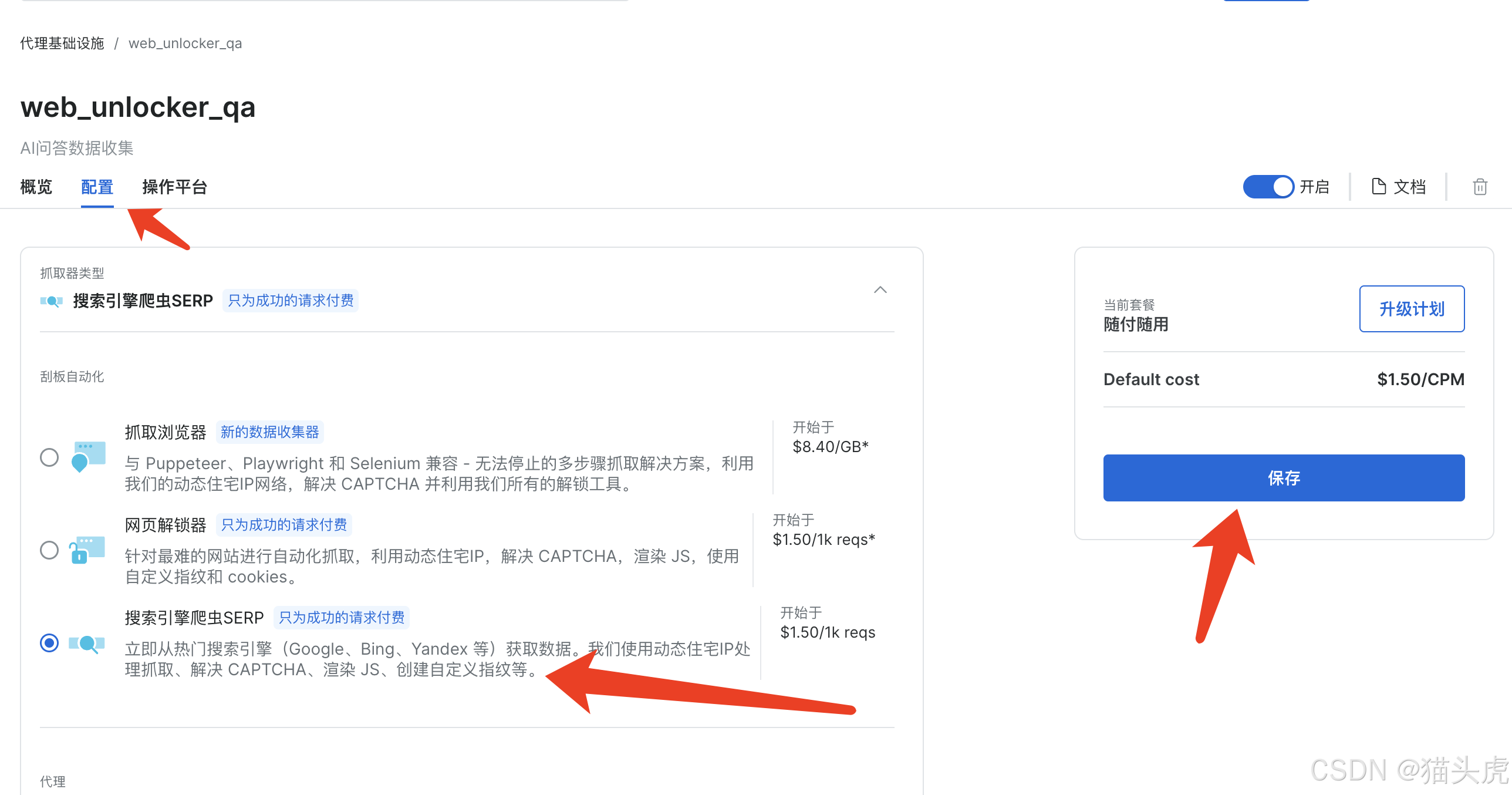
之后进入测试页
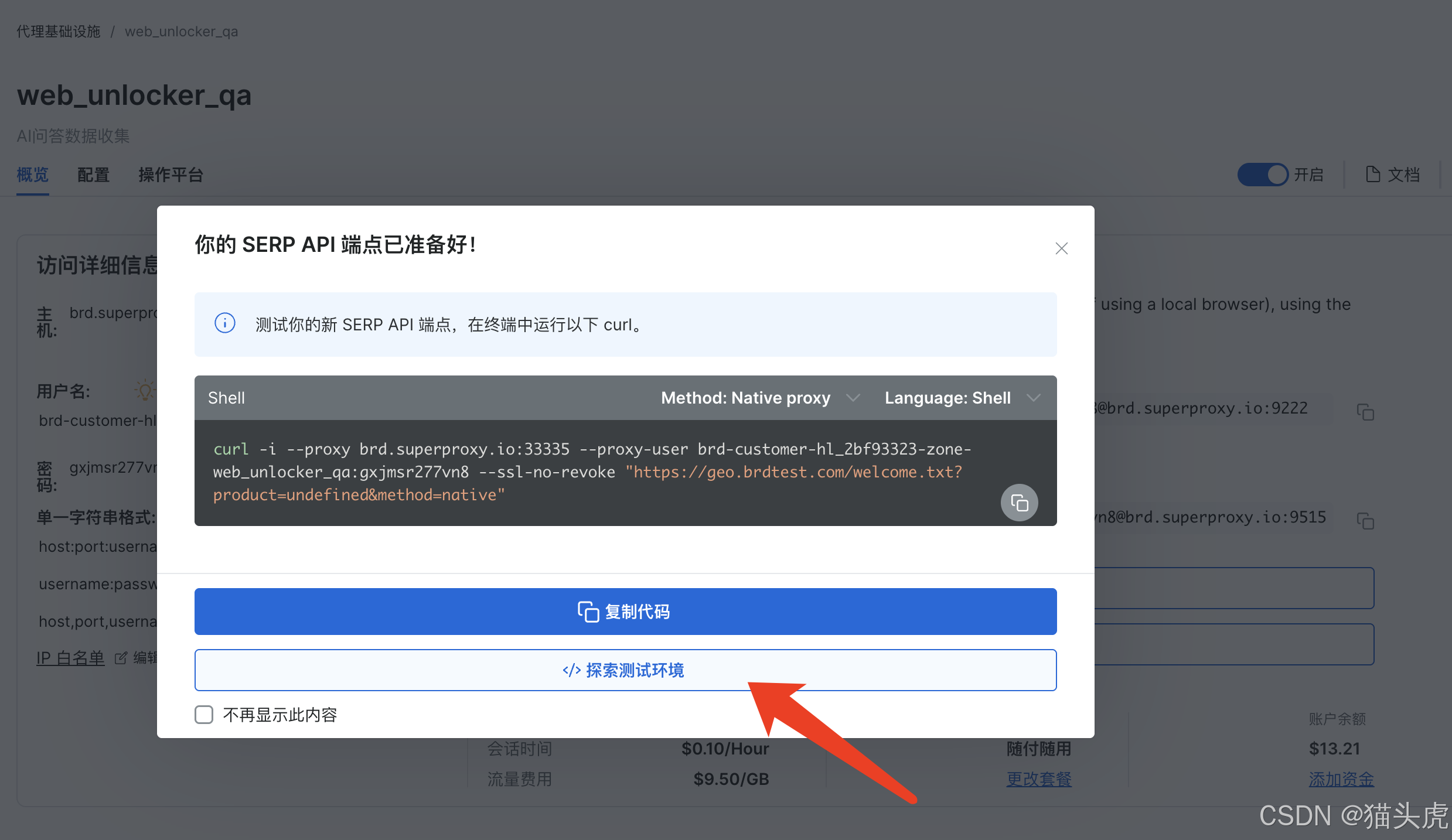
接下来的操作很简单,直接配置关键词搜索即可,比如我这里搜索热门的MCP协议和A2A协议,很快就输出了网页和代码的双结果,如下图所示:
值得一提的是,左侧还有很多查询器可以切换,可以根据实际情况调整
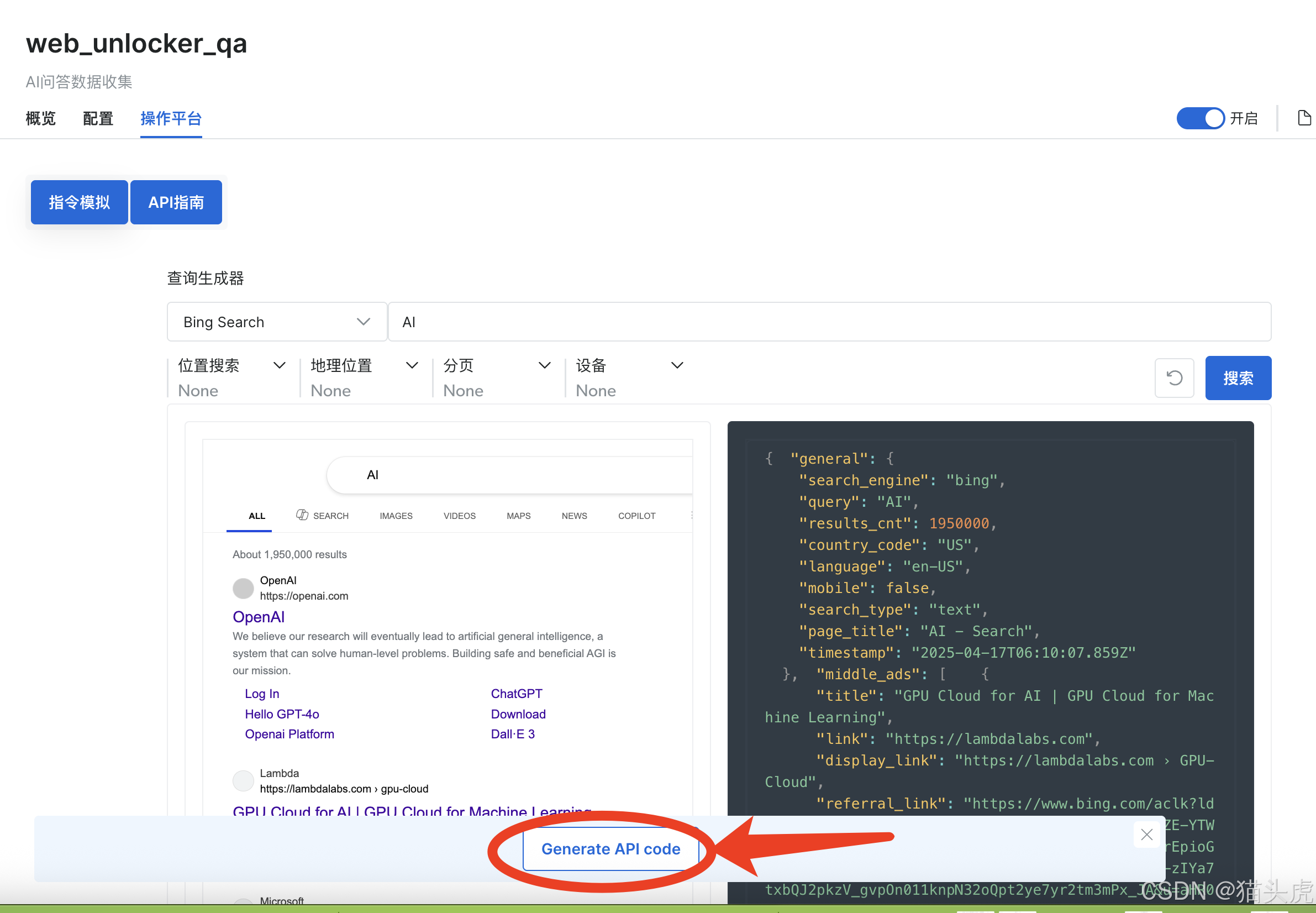
另外 搜索引擎结果页SERP API 不仅支持在线调用,还支持API方式,点击界面下方的API代码,就可以快速生产可直接运行的多语言代码
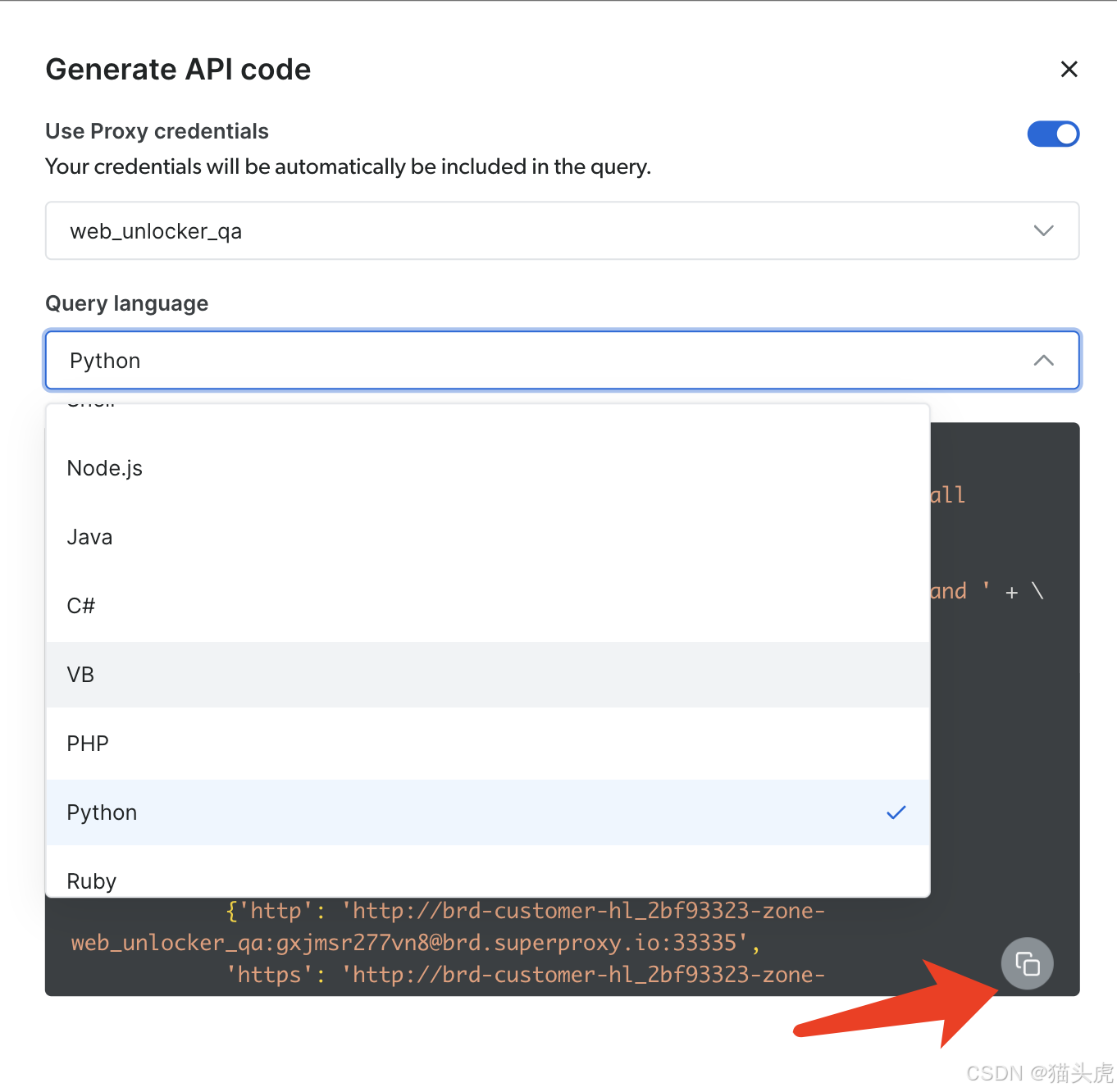
点击右下角的菜单即可快速将代码 复制到IDE运行
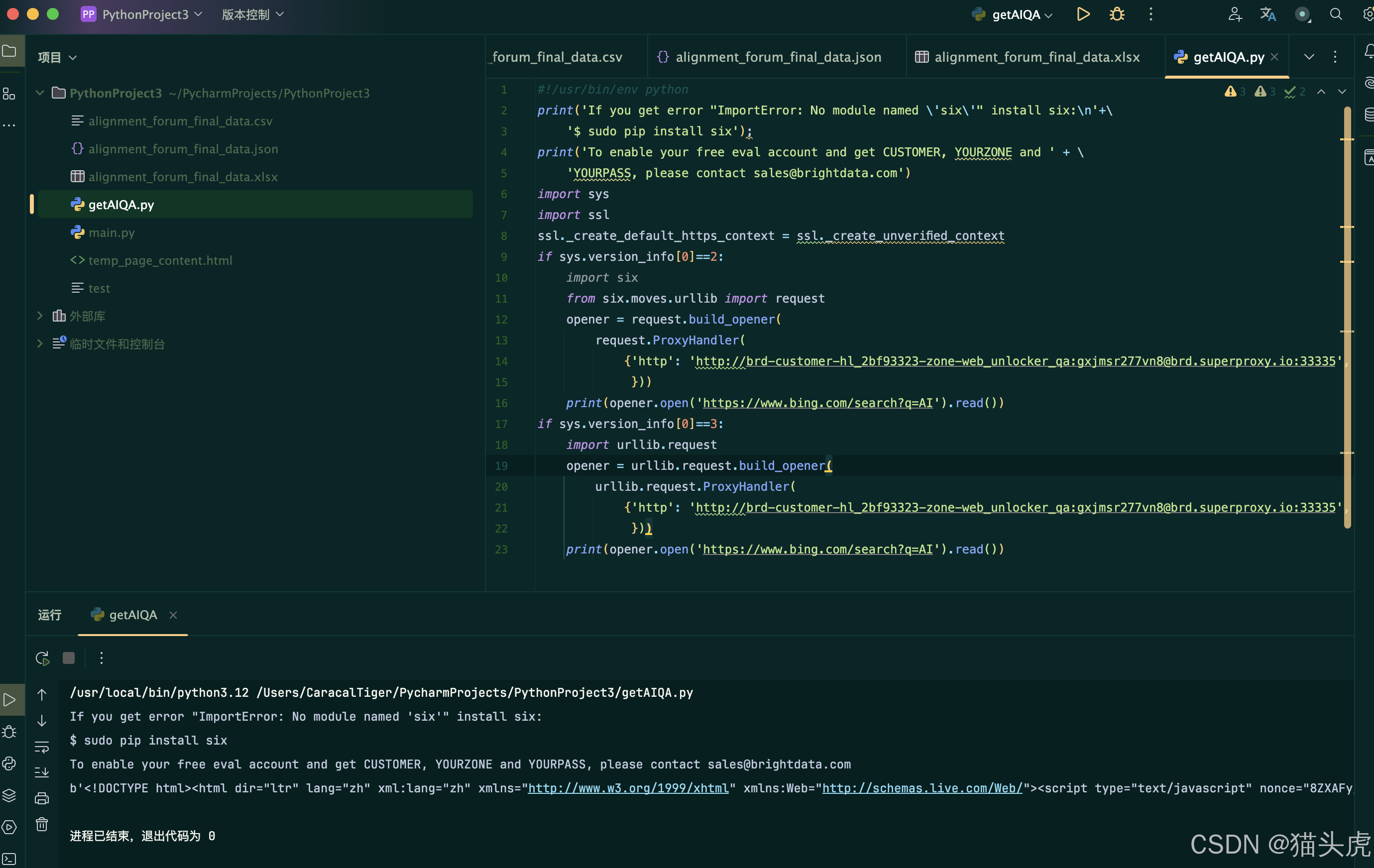
在IDE中运行的效果如下图所示
参考资料
- 粉丝专属体验入口:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_maotouhu202504&promo=APIS25
- Web Unlocker API:https://www.bright.cn/products/web-unlocker
- Web Scraper API:https://www.bright.cn/products/web-scraper
- SERP API:https://www.bright.cn/products/serp-api
- 文档:https://docs.brightdata.com/scraping-automation/web-unlocker
总结
本文介绍的三个强大工具——Web Unlocker API、Web-Scraper 和 SERP API,在自动化网页数据抓取和AI数据集构建中各具特色,极大降低了网页数据获取的复杂性和成本。
-
Web Unlocker API 通过智能代理、浏览器指纹伪装和CAPTCHA绕过,解决了高防护网站的数据获取难题,帮助企业快速、高效地解锁并提取所需数据。
-
Web-Scraper 提供了强大的网页抓取功能,支持动态内容加载,帮助用户精准抓取从简单到复杂的网页数据。
-
SERP API 专注于搜索引擎结果页面的数据抓取,适用于SEO分析、市场研究等场景,能够快速获取Google、Bing等搜索引擎的结果数据。它在领域知识库构建中尤为重要,通过抓取和分析搜索引擎的相关数据,帮助企业和开发者获取行业最新信息,构建更加丰富和高效的知识库。
这三个工具不仅为AI大模型的训练和微调提供了高效的数据支持,还帮助开发者在构建AI知识库和领域知识库时节省了大量的时间和精力,确保了数据获取的高效性和合规性。无论是在AI开发、市场研究,还是信息采集领域,这些工具都能够为企业和开发者提供极具价值的解决方案。
本文福利:
🚀 无需攻克反爬难关,不必组建技术团队,亮数据网络解锁器与SERP API为中小企业量身打造:
✅ 零门槛接入:仅需三行代码即可获取全网旅游数据,告别IP封禁与验证码困扰。
✅ 成本直降60%:动态IP+智能调度,数据成本低至$0.5/千条,比自建方案节省$15,000+/年。
✅ 合规无忧保障:GDPR认证+全程加密,规避法律风险。
粉丝专属体验入口:https://www.bright.cn/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_maotouhu202504&promo=APIS25 体验就送2刀额度