中科院数据生成赋能具身导航!WCGEN:基于世界一致性数据生成的视觉语言导航

- 作者: Yu Zhong 1 , 2 ^{1,2} 1,2, Rui Zhang 1 , 2 ^{1,2} 1,2, Zihao Zhang 1 , 2 ^{1,2} 1,2, Shuo Wang 1 , 2 ^{1,2} 1,2, Chuan Fang 3 ^{3} 3, Xishan Zhang 1 , 2 ^{1,2} 1,2, Jiaming Guo 1 , 2 ^{1,2} 1,2, Shaohui Peng 4 , 2 ^{4,2} 4,2, Di Huang 1 , 2 ^{1,2} 1,2, Yanyang Yan 1 , 2 ^{1,2} 1,2, Xing Hu 1 , 2 ^{1,2} 1,2, Ping Tan 3 ^{3} 3, Qi Guo 1 , 2 ^{1,2} 1,2
- 单位: 1 ^{1} 1中科院计算技术研究所, 2 ^{2} 2中国科学院大学, 3 ^{3} 3香港科技大学, 4 ^{4} 4中科院软件所
- 论文标题:World-Consistent Data Generation for Vision-and-Language Navigation
- 论文链接:https://arxiv.org/pdf/2412.06413
主要贡献
- 提出了一种两阶段数据生成策略,包括轨迹阶段和导航点阶段,分别确保轨迹中各导航点之间的空间连贯性和单个导航点内全景图的空间一致性。
- 在轨迹阶段,通过点云技术和扩散模型生成参考图像,确保导航路径上的空间一致性。
- 在导航点阶段,采用角度合成方法和ControlNet逐步生成全景图,确保全景图的空间连贯性和环绕一致性。
- 通过大量实验验证了该方法在多个VLN数据集上的有效性,证明了其在提升智能体泛化能力方面的优势。
研究背景
- 视觉语言导航(VLN)任务要求智能体根据自然语言指令在复杂环境中导航。
- 该任务面临的主要挑战之一是数据稀缺,现有的VLN数据集大多基于Matterport3D环境构建,训练场景有限,导致智能体在未见过的环境中泛化能力较差。
- 尽管已有研究尝试通过数据增强来解决这一问题,但现有方法在生成多样化且世界一致的VLN数据方面仍存在不足。
相关工作
视觉语言导航
视觉-语言导航(VLN)是一项要求智能体根据自然语言指令在视觉环境中进行导航的复杂任务。早期的研究主要采用长短期记忆网络(LSTM)作为骨干网络,以更好地保留历史观察信息。然而,这些方法在处理较长导航路径时会面临严重的信息丢失问题。为了解决这一问题,研究人员引入了基于Transformer的架构,利用其强大的多模态表示能力来提取视觉和语言信息。近年来,许多研究进一步探索了通过拓扑图、3D感知或知识存储来提升VLN性能。例如:
- 拓扑图方法:通过构建环境的拓扑图来存储和利用导航过程中的关键信息。
- 3D感知方法:利用3D环境信息来增强智能体对环境的理解。
- 知识存储方法:通过存储和利用外部知识来辅助导航。
VLN的数据增强
VLN任务面临的一个主要挑战是数据稀缺。现有的VLN数据集大多基于Matterport3D环境构建,训练场景有限。为了克服这一问题,许多研究尝试通过数据增强来扩展训练数据集。主要方法包括:
- 基于Matterport3D的数据增强:通过混合场景或编辑视觉观察来生成新的训练数据。然而,这些方法受到Matterport3D环境的限制,无法显著提升导航性能。
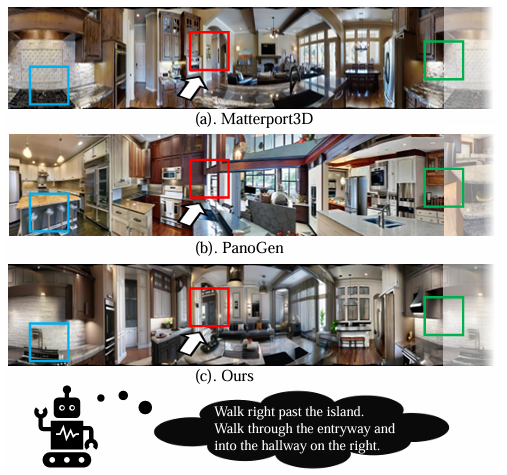
- 基于文本描述的全景图生成:如PanoGen,通过利用Stable Diffusion模型从文本描述中生成全景图。尽管这种方法在一定程度上提升了性能,但生成的全景图存在3D世界不一致性,可能导致智能体在导航过程中产生混淆。
- 利用网络资源:一些方法尝试从网络中收集数据以减少训练偏差,但这些数据通常质量较差,碎片化且噪声较多,与结构化的VLN数据存在较大差距。
- 引入新的3D环境:通过引入新的3D环境来收集更多训练数据。尽管这些方法取得了显著的性能提升,但由于3D环境的开发成本较高且资源稀缺,进一步扩展的难度较大。
基于扩散模型的图像生成
- 去噪扩散模型(Denoising Diffusion Models)是一类强大的生成模型,能够捕捉真实世界2D图像中的复杂分布。
- 近年来,基于扩散模型的图像生成技术取得了显著进展,广泛应用于图像修复、超分辨率、视频生成等领域。特别是,ControlNet框架的提出使得扩散模型能够进行图像到图像的翻译任务,从而实现任务特定的图像生成。
- 本文利用预训练的ControlNet模型,通过深度信息引导合成新的导航点图像,以确保生成图像的空间一致性和物理合理性。
研究方法
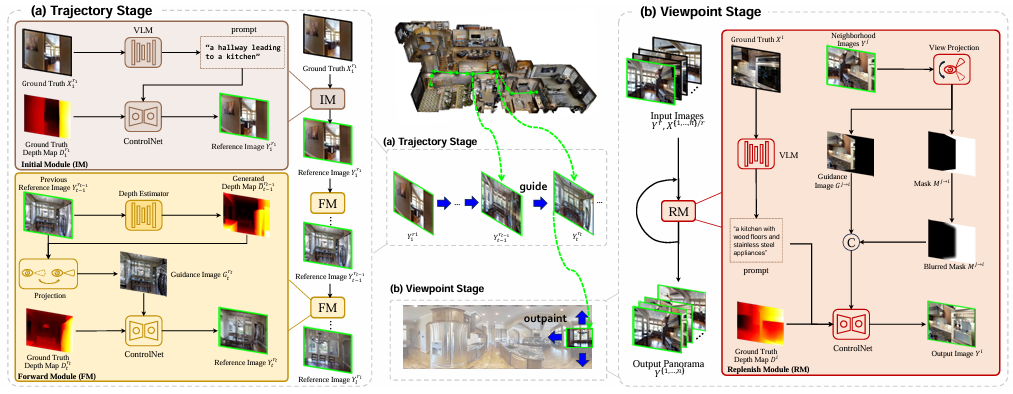
- 本文提出了**世界一致性数据生成(WCGEN)**框架,旨在生成多样化且世界一致的视觉-语言导航(VLN)数据,以提升智能体在新环境中的泛化能力。
- WCGEN框架通过一个两阶段生成策略来实现这一目标,具体包括轨迹阶段(Trajectory Stage)和导航点阶段(Viewpoint Stage)。
轨迹阶段
轨迹阶段的目标是确保导航路径上各导航点之间的空间连贯性。为此,WCGEN设计了两个模块:初始模块(Initial Module, IM)和前向模块(Forward Module, FM),分别用于生成第一个导航点的参考图像和后续导航点的参考图像。
初始模块
初始模块负责生成第一个导航点的参考图像。它以Matterport3D数据集提供的真实参考图像 X r 1 1 X_{r1}^1 Xr11 和对应的深度信息 D r 1 1 D_{r1}^1 Dr11 作为输入,目标是生成合成的参考图像 Y r 1 1 Y_{r1}^1 Yr11。具体步骤如下:
- 使用BLIP-2模型提取 X r 1 1 X_{r1}^1 Xr11 的上下文描述文本。
- 以该描述文本作为提示(prompt),结合深度信息 D r 1 1 D_{r1}^1 Dr11,通过ControlNet进行深度到图像的合成,生成输出 Y r 1 1 Y_{r1}^1 Yr11。
前向模块
前向模块用于生成后续导航点的参考图像。假设第 t − 1 t-1 t−1 个导航点的参考图像 Y r t − 1 t − 1 Y_{r_{t-1}}^{t-1} Yrt−1t−1 已经生成,前向模块将生成第 t t t 个导航点的参考图像 Y r t t Y_{r_t}^t Yrtt。具体步骤如下:
- 点云投影:首先,使用预训练的深度估计器计算 Y r t − 1 t − 1 Y_{r_{t-1}}^{t-1} Yrt−1t−1 的深度信息 D ~ r t − 1 t − 1 \tilde{D}_{r_{t-1}}^{t-1} D~rt−1t−1。然后,利用相机参数将 Y r t − 1 t − 1 Y_{r_{t-1}}^{t-1} Yrt−1t−1 和 D ~ r t − 1 t − 1 \tilde{D}_{r_{t-1}}^{t-1} D~rt−1t−1 转换为第 t t t 个导航点的引导图像 G r t t G_{r_t}^t Grtt。具体计算如下:
P = K − 1 ⋅ [ u ⋅ D ~ r t − 1 t − 1 ( u , v ) v ⋅ D ~ r t − 1 t − 1 ( u , v ) D ~ r t − 1 t − 1 ( u , v ) ] P = K^{-1} \cdot \begin{bmatrix} u \cdot \tilde{D}_{r_{t-1}}^{t-1}(u,v) \\ v \cdot \tilde{D}_{r_{t-1}}^{t-1}(u,v) \\ \tilde{D}_{r_{t-1}}^{t-1}(u,v) \end{bmatrix} P=K−1⋅ u⋅D~rt−1t−1(u,v)v⋅D~rt−1t−1(u,v)D~rt−1t−1(u,v)
P w = R ⋅ P + T P_w = R \cdot P + T Pw=R⋅P+T
P w ′ = R t − 1 → t ⋅ ( P w + T t − 1 → t ) P_w' = R_{t-1 \to t} \cdot (P_w + T_{t-1 \to t}) Pw′=Rt−1→t⋅(Pw+Tt−1→t)
其中, K K K 表示相机内参, R R R 和 T T T 分别表示旋转矩阵和平移向量。 - 图像生成:由于投影后的引导图像 G r t t G_{r_t}^t Grtt 可能存在缺失像素,因此使用ControlNet结合深度信息 D r t t D_{r_t}^t Drtt 进行图像到图像的生成,输出 Y r t t Y_{r_t}^t Yrtt。如果导航点差异过大,导致没有重叠部分,则直接进行文本到图像的生成,类似于初始模块的过程。
导航点阶段
导航点阶段的目标是确保单个导航点内全景图的空间连贯性和环绕一致性。
Replenish Module:基于参考图像逐步生成全景图。对于第 t t t 个导航点,导航点阶段以参考图像 Y r t t Y_{r_t}^t Yrtt 和真实图像 X { 1 , . . . , n } / r X_{\{1,...,n\}/r} X{1,...,n}/r 作为输入,逐步生成每个导航点图像 Y i t Y_i^t Yit。具体步骤如下:
- 邻接集合构建:收集与目标导航点图像相邻的已生成导航点图像,形成邻接集合 S i S_i Si。
- 角度合成:对于邻接集合中的每个图像 Y j ∈ S i Y_j \in S_i Yj∈Si,通过角度合成方法将其映射到目标导航点 i i i,生成引导图像 G j → i G_{j \to i} Gj→i 和二值掩码 M j → i M_{j \to i} Mj→i。具体计算如下:
v sphere = K − 1 ⋅ v pixel ⋅ 1 ∥ K − 1 ⋅ v pixel ∥ v_{\text{sphere}} = K^{-1} \cdot v_{\text{pixel}} \cdot \frac{1}{\|K^{-1} \cdot v_{\text{pixel}}\|} vsphere=K−1⋅vpixel⋅∥K−1⋅vpixel∥1
v sphere ′ = R j → i ⋅ R ⋅ v sphere v'_{\text{sphere}} = R_{j \to i} \cdot R \cdot v_{\text{sphere}} vsphere′=Rj→i⋅R⋅vsphere
v pixel ′ = K ⋅ v sphere ′ v'_{\text{pixel}} = K \cdot v'_{\text{sphere}} vpixel′=K⋅vsphere′ - 图像外扩:使用ControlNet结合深度信息 D i D_i Di、模糊掩码 M ^ j → i \hat{M}_{j \to i} M^j→i 和目标导航点图像的描述文本,生成输出 Y i Y_i Yi。如果邻接集合中有多个图像,则通过加权求和的方式合并引导图像和掩码。
指令生成
- 为了实现更好的视觉-语言对齐,需要为生成的全景图生成新的指令。
- 本文采用mPLUG-2模型,通过在Matterport3D训练集上进行微调,生成与生成全景图匹配的指令。
- 这有助于提升VLN智能体的视觉-语言定位能力,从而增强其泛化能力。
实验
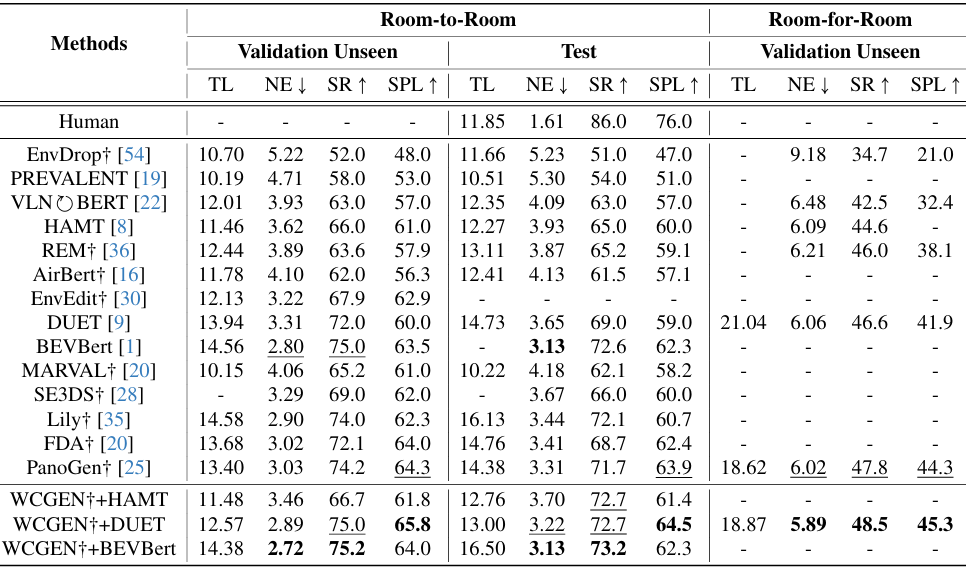
实验在多个VLN数据集上进行,包括R2R、R4R、REVERIE和CVDN。使用标准的导航性能指标(如轨迹长度TL、导航误差NE、成功率SR、路径长度归一化的成功率SPL等)进行评估。
-
细粒度导航
- 在R2R和R4R数据集上,WCGEN显著提升了DUET和HAMT模型的性能。
- 例如,在R2R验证集未见环境中,DUET模型的SPL指标提升了5.8%,在R4R验证集未见环境中提升了3.4%。
-
粗粒度导航
- 在CVDN和REVERIE数据集上,WCGEN同样表现出色。
- 例如,在CVDN验证集未见环境中,目标进展(GP)指标比PanoGen提升了0.54%。
-
生成质量评估
- 通过Inception Score(IS)和Fréchet Inception Distance(FID)评估生成图像的质量。
- WCGEN在这些指标上优于其他数据增强方法,生成的图像更具真实感和物理一致性。
-
消融研究
- 证明了WCGEN中各个模块的有效性。
- 例如,去掉轨迹阶段的Forward Module会导致性能显著下降,表明轨迹阶段在确保空间一致性方面的重要性。

结论
- 本文提出的WCGEN框架通过两阶段生成策略,成功生成了多样化且世界一致的VLN数据,显著提升了智能体在新环境中的泛化能力。
- 该方法在多个VLN数据集上取得了新的最佳性能,证明了其在视觉-语言导航任务中的有效性和潜力。
