计算机视觉——利用AI幻觉检测图像是否是生成式算生成的图像
概述
俄罗斯的新研究提出了一种非常规方法,用于检测不真实的AI生成图像——不是通过提高大型视觉-语言模型(LVLMs)的准确性,而是故意利用它们的幻觉倾向。
这种新方法使用LVLMs提取图像的多个“原子事实”,然后应用自然语言推理(NLI),系统地衡量这些陈述之间的矛盾——有效地将模型的缺陷转化为检测违背常识的图像的诊断工具。

WHOOPS!数据集中两张图片与LVLM模型自动生成的陈述。左侧图片是真实的,导致描述一致,而右侧不寻常的图片导致模型产生幻觉,产生矛盾或错误的陈述。
当被要求评估第二张图片的真实性时,LVLM可以看出__有些不对劲__,因为图中的骆驼有三个驼峰,这在自然中是不存在的。
然而,LVLM最初将__超过2个驼峰__与__超过2个动物__混淆,因为这是在一张“骆驼图片”中看到三个驼峰的唯一方式。然后,它继续幻觉出比三个驼峰更不可能的事情(即“两个头”),并且从未详细说明似乎触发了它的怀疑的事情——那个不太可能的额外驼峰。
新研究的研究人员发现,LVLM模型可以本地执行这种评估,并且与经过微调用于此类任务的模型相比,表现相当甚至更好。由于微调复杂、昂贵且在下游应用方面相当脆弱,因此发现当前AI革命中最大的障碍之一的本地用途,是对文献中一般趋势的令人耳目一新的转变。
一、开放评估
作者强调,这种方法的重要性在于它可以使用_开源_框架部署。尽管像ChatGPT这样的先进且高投资模型可能会(论文承认)在该任务中提供更好的结果,但对于大多数人(尤其是业余爱好者和视觉特效社区)来说,文献的真正价值在于能够在本地实现中整合和开发新的突破;相反,所有注定用于专有商业API系统的项目都容易被撤回、随意涨价,并且审查政策更有可能反映公司的企业利益,而不是用户的需求和责任。
新论文的标题为__不要对抗幻觉,利用它们:使用NLI对原子事实进行图像真实性估计__,来自斯科尔科沃科学技术研究所(Skoltech)、莫斯科物理技术学院以及俄罗斯公司MTS AI和AIRI的五位研究人员。该工作有一个配套的GitHub页面。
二、方法
作者使用以色列/美国的WHOOPS!数据集进行该项目:

_WHOOPS!数据集中不可能图像的示例。值得注意的是,这些图像组合了合理的元素,它们的不可能性必须根据这些不兼容方面的组合来计算。
该数据集包含500张合成图像和超过10,874个注释,专门设计用于测试AI模型的常识推理和组合理解能力。它是由设计师与Midjourney和DALL-E系列等文本到图像系统合作创建的,这些设计师的任务是生成具有挑战性的图像——产生自然难以捕捉的场景:

WHOOPS!数据集中的进一步示例。
新方法分为三个阶段:首先,LVLM(具体为LLaVA-v1.6-mistral-7b)被提示生成多个简单陈述——称为“原子事实”——描述图像。这些陈述使用多样化束搜索生成,确保输出的多样性。
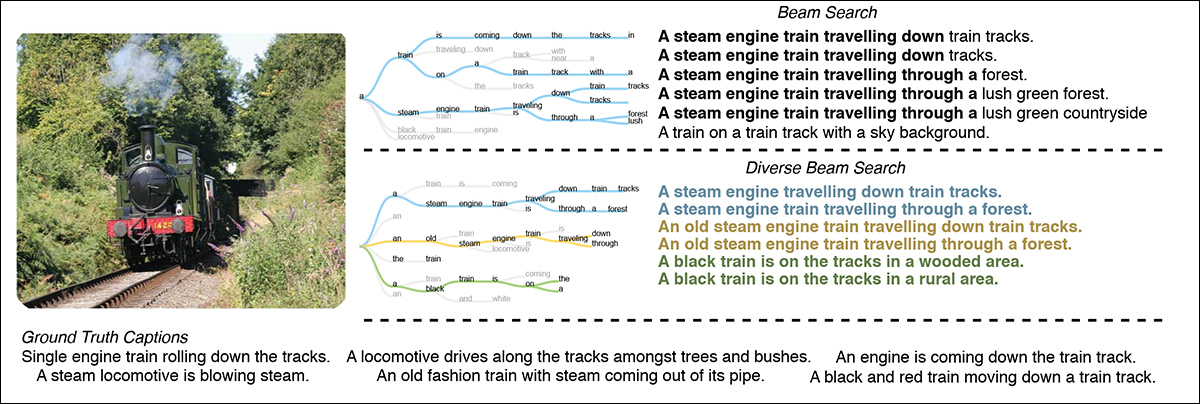
_多样化束搜索通过优化多样性增强目标,产生更多样化的标题选项。
接下来,使用自然语言推理模型系统地比较每个生成的陈述与其他所有陈述,该模型为陈述对分配分数,反映它们是否相互蕴含、矛盾或中立。
矛盾表明图像中存在幻觉或不真实元素:
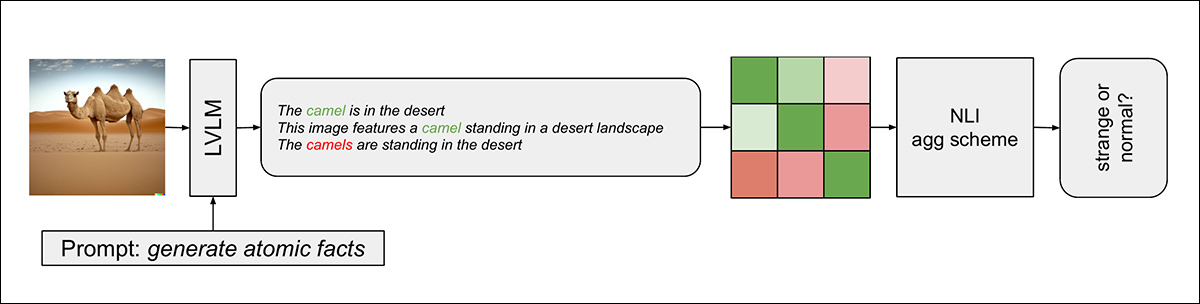
检测流程图。
最后,该方法将这些成对的NLI分数聚合为一个“现实分数”,量化生成陈述的整体一致性。
研究人员探索了不同的聚合方法,基于聚类的方法表现最佳。作者应用k-means聚类算法将各个NLI分数分为两个聚类,较低值聚类的质心被选为最终指标。
使用两个聚类直接与分类任务的二元性质一致,即区分真实图像和不真实图像。其逻辑类似于简单地选择最低分数;然而,聚类允许指标代表多个事实之间的平均矛盾,而不是依赖于单个离群值。
三、数据和测试
研究人员在WHOOPS!基准测试中测试了他们的系统,使用旋转的测试分割(即交叉验证)。测试的模型为BLIP2 FlanT5-XL和BLIP2 FlanT5-XXL,在分割中进行测试,以及BLIP2 FlanT5-XXL的零样本格式(即,无需额外训练)。
对于指令遵循基线,作者使用短语__“这不寻常吗?请用简短的句子简要说明”__提示LVLMs,先前研究发现这在识别不真实图像方面很有效。
测试的模型为LLaVA 1.6 Mistral 7B、LLaVA 1.6 Vicuna 13B以及两种大小(70亿/130亿参数)的InstructBLIP。
测试过程围绕102对真实和不真实(“奇怪”)图像进行。每对包含一张正常图像及其违背常识的对应图像。
三名人类标注者对图像进行了标注,达成92%的共识,表明人类对“奇怪”的定义有很强的共识。通过评估方法正确区分真实和不真实图像的能力来衡量其准确性。
该系统使用三折交叉验证进行评估,使用固定种子随机打乱数据。作者在训练期间调整了蕴含分数(逻辑上一致的陈述)和矛盾分数(逻辑上冲突的陈述)的权重,而“中立”分数则固定为零。最终准确性是通过所有测试分割的平均值计算得出的。
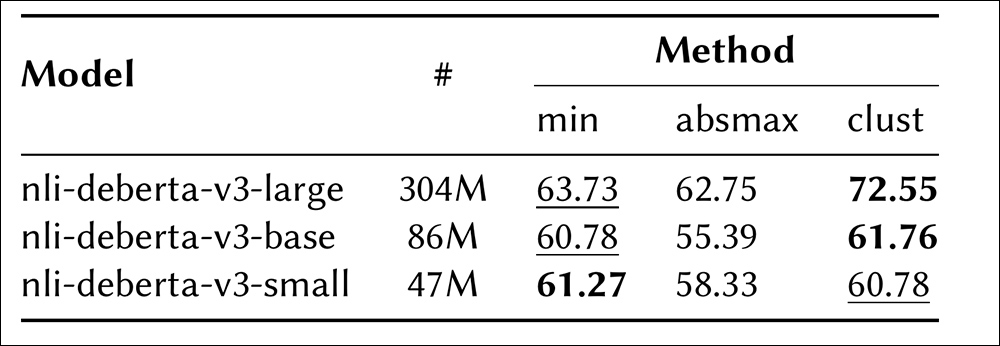
在五个生成事实的子集上,不同NLI模型和聚合方法的准确性比较。
关于上图中显示的初步结果,论文指出:
“[‘clust’]方法表现最佳。这意味着聚合所有矛盾分数至关重要,而不是只关注极端值。此外,最大的NLI模型(nli-deberta-v3-large)在所有聚合方法中均优于其他模型,表明它更有效地捕捉了问题的本质。”
作者发现,最佳权重始终倾向于矛盾而非蕴含,表明矛盾对于区分不真实图像更具信息量。他们的方法超越了所有其他测试的零样本方法,接近经过微调的BLIP2模型的性能:
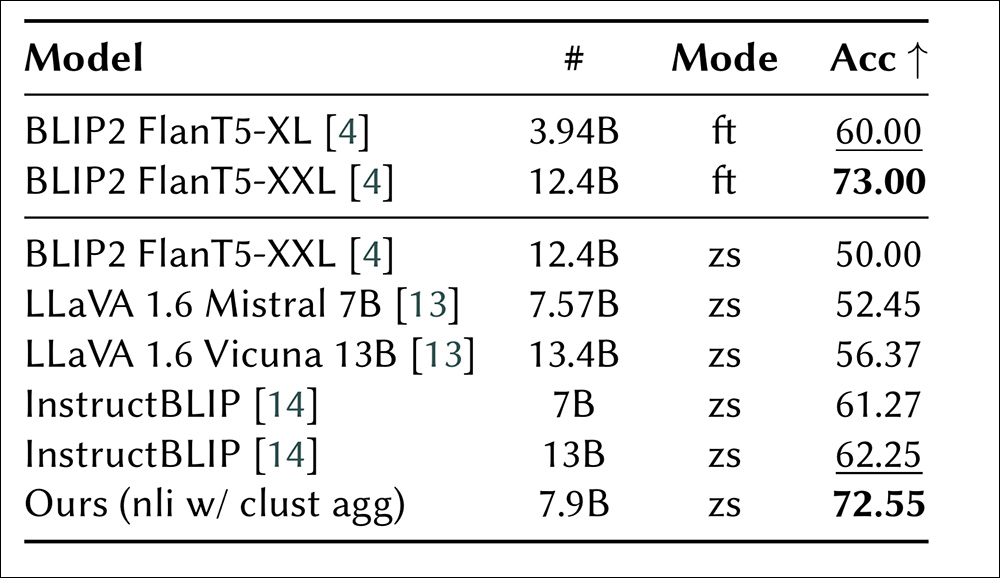
WHOOPS!基准测试中各种方法的性能。微调(ft)方法位于顶部,而零样本(zs)方法列在下方。模型大小表示参数数量,准确性用作评估指标。
他们还注意到,出乎意料的是,InstructBLIP在给定相同提示的情况下比类似的LLaVA模型表现更好。尽管承认GPT-4o的准确性更高,但论文强调作者倾向于展示实用的开源解决方案,并且似乎可以合理地声称明确利用幻觉作为诊断工具的新颖性。
结论
然而,作者承认他们的项目得益于2024年的FaithScore,这是德克萨斯大学达拉斯分校和约翰霍普金斯大学的合作项目。

FaithScore评估的说明。首先,识别LVLM生成答案中的描述性陈述。接下来,这些陈述被分解为单独的原子事实。最后,将原子事实与输入图像进行比较以验证其准确性。下划线文本突出显示客观描述性内容,而蓝色文本表示幻觉陈述,使FaithScore能够提供可解释的事实正确性度量。 来源:https://arxiv.org/pdf/2311.01477
FaithScore通过验证与图像内容的一致性来衡量LVLM生成描述的忠实度,而新论文的方法明确利用LVLM幻觉,通过自然语言推理检测不真实图像,即通过生成事实中的矛盾。
新工作自然依赖于当前语言模型的怪癖,以及它们产生幻觉的倾向。如果模型开发最终产生了一个完全不产生幻觉的模型,那么即使新工作的一般原则也将不再适用。然而,这仍然是一个具有挑战性的前景。