PyTorch 线性回归详解:模型定义、保存、加载与网络结构
目录
- 前言
- 一、pytorch框架线性回归
- 1.1 pytorch模型的定义
- 1.2 nn.Sequential()
- 1.2.1 nn.Linear
- 1.2.2 nn.Sequential
- 1.3 nn.ModuleList()
- 1.4 nn.ModuleDict()
- 1.5 nn.Module
- 二、pytorch模型的保存
- 2.1 保存模型的权重和其他参数
- 2.1.1 torch.save()保存字典
- 总结
前言
书接上文
自求导实现线性回归与PyTorch张量详解-CSDN博客文章浏览阅读1.1k次,点赞34次,收藏19次。本文围绕自求导方法实现线性回归算法展开,详细介绍了算法的理论基础、参数初始化、损失函数设计、迭代过程及反向传播求导机制,并通过Python代码实现线性回归模型训练和可视化,直观呈现模型优化轨迹和损失变化。同时,文章深入讲解了PyTorch框架中的tensor概念,解析了tensor的存储结构、数据类型、步长和偏移,重点阐述了tensor连续性与非连续性的区别及其对计算效率的影响,并介绍了contiguous()方法用于解决非连续tensor问题,结合丰富代码示例,帮助读者理解并掌握PyTorch tensohttps://blog.csdn.net/qq_58364361/article/details/147292669?spm=1011.2415.3001.10575&sharefrom=mp_manage_link
一、pytorch框架线性回归
从以下5个方面对深度学习框架Pytorch框架线性回归进行介绍
1.pytorch模型的定义
2.pytorch模型的保存
3.pytorch模型的加载
4.pytorch模型网络结构的查看
5.pytorch框架线性回归的代码实现
上面这5方面的内容,让大家,掌握并理解pytorch框架实现线性回归的过程。
1.1 pytorch模型的定义
torch.nn下的容器
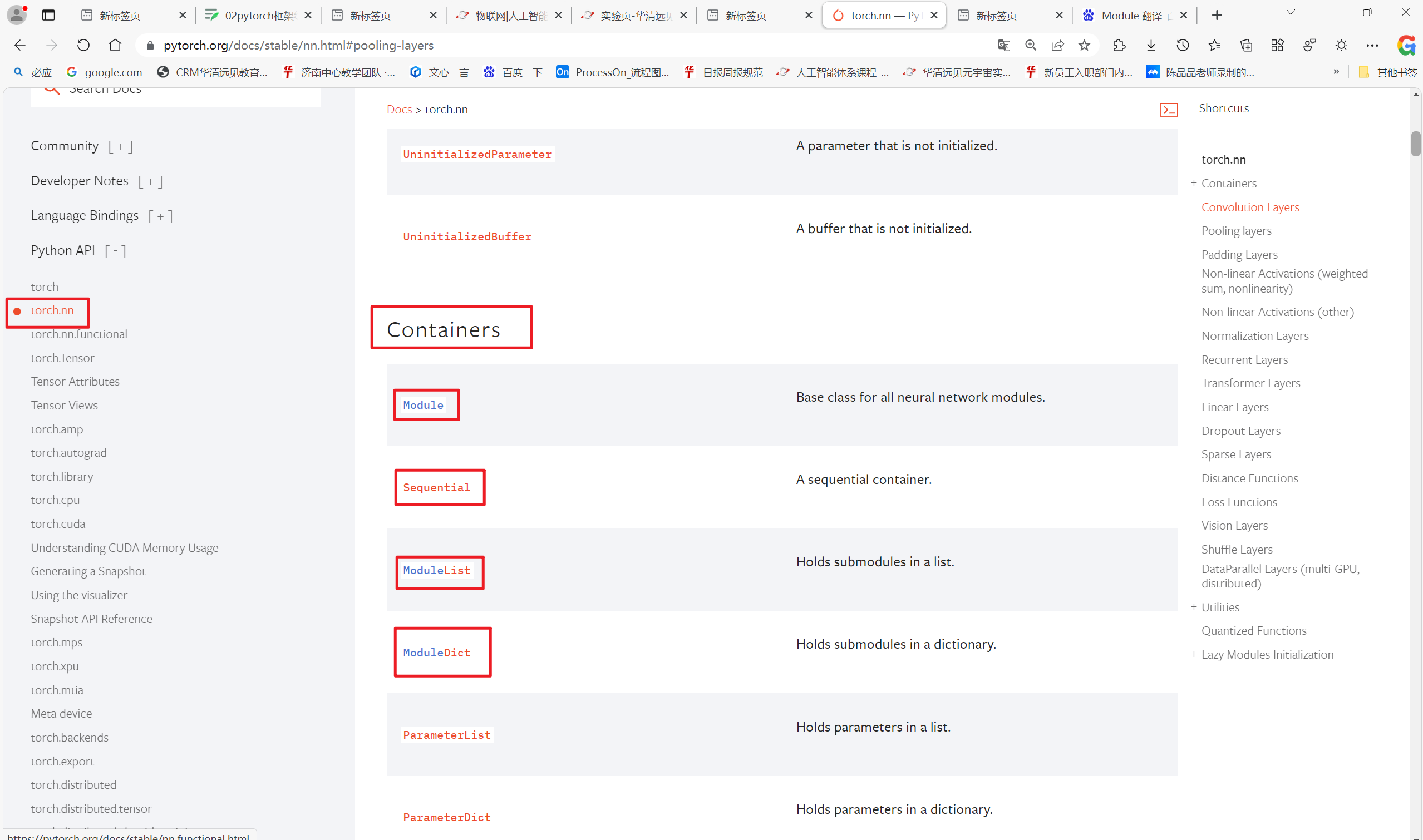
1.2 nn.Sequential()
在nn.Containers下的nn.Sequential()
nn.Sequential()是pytorch的容器,按照顺序组合多个网络层,有forward方法。
注意:forward 方法是输入数据后进行模型调用的(pytorch包含的,如果有forward自动调用,如果没有不调用)

1.2.1 nn.Linear

import torch
import torch.nn as nn# 定义一个线性层,输入特征维度为3,输出特征维度为200
m = nn.Linear(3, 200)# 构造输入张量,包含4个样本,每个样本3个特征,数据类型为float32
input = torch.tensor([[1, 2, 3],[3, 4, 5],[6, 7, 8],[9, 10, 11]], dtype=torch.float32)# 将输入数据传入线性层,得到输出张量
output = m(input)# 打印输出张量的形状,结果应为(4, 200),4个样本每个样本200个特征
print(output.shape)D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_18.py
torch.Size([4, 200])进程已结束,退出代码为 01.2.2 nn.Sequential

import torch
import numpy as np# 定义包含10组样本的二维数据集,每组包括输入特征和目标值
data = [[-0.5, 7.7],[1.8, 98.5],[0.9, 57.8],[0.4, 39.2],[-1.4, -15.7],[-1.4, -37.3],[-1.8, -49.1],[1.5, 75.6],[0.4, 34.0],[0.8, 62.3]]
# 转换为NumPy数组,方便切片操作
data = np.array(data)# 提取输入特征x和目标值y
x_data = data[:, 0]
y_data = data[:, 1]# 转换为PyTorch张量,数据类型为float32,满足模型输入要求
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)# 导入神经网络模块
import torch.nn as nn# 构建线性回归模型,包含一个输入节点和一个输出节点的线性层
model = nn.Sequential(nn.Linear(1, 1))# 定义均方误差损失函数,用于回归任务衡量误差
criterion = nn.MSELoss()# 采用随机梯度下降优化器,设置学习率为0.01,用于优化模型参数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型,循环500次迭代
epoches = 500
for n in range(1, epoches + 1):# 将一维输入张量升维为二维,以适应Linear层输入要求(batch_size, 1)x_train_2d = x_train.unsqueeze(1)# 前向传播计算预测输出,输出形状为(batch_size, 1)y_pre = model(x_train_2d)# 计算预测值与真实值的均方误差,需将预测输出压缩为一维loss = criterion(y_pre.squeeze(1), y_train)# 梯度清零,防止梯度累积影响更新optimizer.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()# 每第1轮及之后每隔10轮输出一次当前迭代次数和损失值if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
1.3 nn.ModuleList()
nn.ModuleList() 和python的基础数据类型list类似,不按照顺序,没有forward方法,不可以定义名字,可以用append加网络。
如果使用需要重写继承nn.Module
import torch
import numpy as np# 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
# 转换为 NumPy 数组
data = np.array(data)
# 提取 x_data 和 y_data
x_data = data[:, 0]
y_data = data[:, 1]
# 将数据转换为 Tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)# 构建模型
import torch.nn as nn # 导入 PyTorch 的神经网络模块# 使用 ModuleList 的线性模型
class LinearModel(nn.Module):# 初始化方法def __init__(self):super(LinearModel, self).__init__()# 定义一个包含一个线性层的 ModuleListself.layers = nn.ModuleList([nn.Linear(1, 1)])# 前向传播方法def forward(self, x):# 遍历所有层进行计算for layer in self.layers:x = layer(x)return x# 初始化模型
model = LinearModel()# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 迭代训练
epoches = 500
for n in range(1, epoches + 1):# 增加维度以匹配模型输入x_train_add_dim = x_train.unsqueeze(1)# 前向传播y_pre = model(x_train_add_dim)# 计算损失loss = criterion(y_pre.squeeze(1), y_train)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()# 打印损失if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
1.4 nn.ModuleDict()
nn.ModuleDict(),和dict类似,不按照顺序,没有forward方法,可以定义每层的名字
import torch
import numpy as np# 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
# 转换为 NumPy 数组
data = np.array(data)
# 提取 x_data 和 y_data
x_data = data[:, 0]
y_data = data[:, 1]
# 将数据转换为 Tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)import torch.nn as nn# 使用 ModuleList 的线性模型
class LinearModelDict(nn.Module):def __init__(self):super(LinearModelDict, self).__init__()self.layers_dict = nn.ModuleDict({'linear1': nn.Linear(1, 1)}) # 定义一个包含线性层的 ModuleDictdef forward(self, x):for key in self.layers_dict:x = self.layers_dict[key](x) # 遍历 ModuleDict 中的每一层并应用到输入数据 xreturn x# 初始化模型
model = LinearModelDict()# 定义损失函数
criterion = nn.MSELoss()
# 选择优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降(SGD)优化器# 迭代训练
epoches = 500
for n in range(1, epoches + 1):x_train_add_dim = x_train.unsqueeze(1) # 增加维度以适应模型输入y_pre = model(x_train_add_dim) # 前向传播,获取预测值# 计算损失loss = criterion(y_pre.squeeze(1), y_train) # 计算预测值和真实值之间的均方误差# 梯度更新optimizer.zero_grad() # 清空之前的梯度# 计算损失函数对模型参数的梯度loss.backward() # 反向传播,计算梯度# 根据优化算法更新参数optimizer.step() # 更新模型参数if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
1.5 nn.Module
直接重写继承nn.Module
import torch
import numpy as np# 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
# 转换为 NumPy 数组
data = np.array(data)
# 提取 x_data 和 y_data
x_data = data[:, 0]
y_data = data[:, 1]
# 将数据转换为 Tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)import torch.nn as nn# 定义线性模型
class LinearModel(nn.Module):def __init__(self):super(LinearModel, self).__init__()self.layers = nn.Linear(1, 1) # 定义一个线性层,输入和输出维度都是1def forward(self, x):x = self.layers(x) # 将输入 x 通过线性层return x# 初始化模型
model = LinearModel()# 定义损失函数
criterion = nn.MSELoss() # 均方误差损失函数
# 选取优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器,学习率为0.01# 迭代训练
epoches = 500
for n in range(1, epoches + 1):x_train_add_dim = x_train.unsqueeze(1) # 增加维度以适应模型输入y_pre = model(x_train_add_dim) # 前向传播,获取预测值# 计算损失loss = criterion(y_pre.squeeze(1), y_train) # 计算预测值和真实值之间的均方误差# 梯度更新optimizer.zero_grad() # 清空之前的梯度# 计算损失函数对模型参数的梯度loss.backward() # 反向传播,计算梯度# 根据优化算法更新参数optimizer.step() # 更新模型参数if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
二、pytorch模型的保存
有两种保存方式
2.1 保存模型的权重和其他参数
保存:使用torch.save()保存,该函数将模型的状态字典保存到文件中,其中包括模型的权重和其他参数。

model是模型名称可以换成其他名称。
model.state_dict()返回模型的状态字典,其中包含模型的所有参数,然后,torch.save()函数将这个状态字典保存到名为model.pth的文件中 pth是pytorch的标准的一个模型文件,不加路径就是当前路径,加了路径就是指定的路径。
2.1.1 torch.save()保存字典
import torch
import numpy as np# 准备数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
data = np.array(data)
x_data = data[:, 0] # 获取 x 数据
y_data = data[:, 1] # 获取 y 数据
x_train = torch.tensor(x_data, dtype=torch.float32) # 将 x 数据转换为 PyTorch 张量
y_train = torch.tensor(y_data, dtype=torch.float32) # 将 y 数据转换为 PyTorch 张量from torch.utils.data import DataLoader, TensorDataset# 创建 TensorDataset,用于将 x_train 和 y_train 打包成数据集
dataset = TensorDataset(x_train, y_train)
# 创建 DataLoader,用于批量加载数据
dataloader = DataLoader(dataset, batch_size=2, shuffle=False)import torch.nn as nn# 定义线性模型
class LinearModel(nn.Module):def __init__(self):super(LinearModel,self,).__init__()# 定义一个线性层self.layers = nn.Linear(1, 1)def forward(self,x):# 前向传播函数x = self.layers(x) # 通过线性层return x# 实例化线性模型
model = LinearModel()# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
# 定义训练轮数
epoches = 500
# 训练模型
for n in range(1, epoches + 1):epoch_loss = 0# 迭代 DataLoaderfor batch_x, batch_y in dataloader:# 增加维度x_batch_add_dim = batch_x.unsqueeze(1)# 预测y_pre = model(x_batch_add_dim)# 计算损失batch_loss = criterion(y_pre.squeeze(1), batch_y)# 梯度清零optimizer.zero_grad()# 反向传播batch_loss.backward()# 更新参数optimizer.step()epoch_loss = epoch_loss + batch_loss# 计算平均损失avg_loss = epoch_loss / (len(dataloader))# 每 100 轮保存一次模型if n % 100 == 0 or n == 1:torch.save(model.state_dict(), f'model.pth_{n}')print(f"epoches:{n},loss:{avg_loss}")
总结
本文详细介绍了使用PyTorch框架实现线性回归的五个关键方面:模型定义(包括nn.Sequential, nn.Linear, nn.ModuleList, nn.ModuleDict, nn.Module等容器的使用)、模型保存(通过torch.save()保存模型权重和其他参数)、模型加载、模型网络结构的查看以及线性回归的具体代码实现。通过对这些内容的学习,读者可以掌握并理解PyTorch框架下线性回归的完整流程,并能够灵活运用各种模型定义方法和保存策略。