大模型基础
1、提示词
典型构成:
- **角色**:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学数学老师」
- **指示**:对任务进行描述
- **上下文**:给出与任务相关的其它背景信息(尤其在多轮交互中)
- **例子**:必要时给出举例,学术中称为 Few-Shot Learning 或 In-Context Learning;对输出正确性有很大帮助
- **输入**:任务的输入信息;在提示词中明确的标识出输入
- **输出**:输出的风格、格式描述,引导只输出想要的信息,以及方便后继模块自动解析模型的输出结果,比如(JSON、XML)
2、大模型的能力
大模型的核心能力通常包括但不限于以下方面:
- 指令跟随(Instruction Following):模型能否准确理解并执行用户的指令(如“写一首诗”“总结这篇文章”)。
- 上下文理解(Context Awareness):能否结合对话历史或长文本上下文生成连贯回复。
- 多轮对话(Multi-turn Dialogue):在复杂对话中保持逻辑一致性。
- 多语言处理(Multilingual Capabilities):对中文、英文等不同语言的生成和理解能力。
- 逻辑推理(Reasoning):解决数学问题、代码调试等需要分步推理的任务。
- 创造性生成(Creativity):生成诗歌、故事、广告文案等多样化内容。
- 安全与合规(Safety):避免生成有害、偏见或违法内容。
3、大模型性能评估
1)BLEU
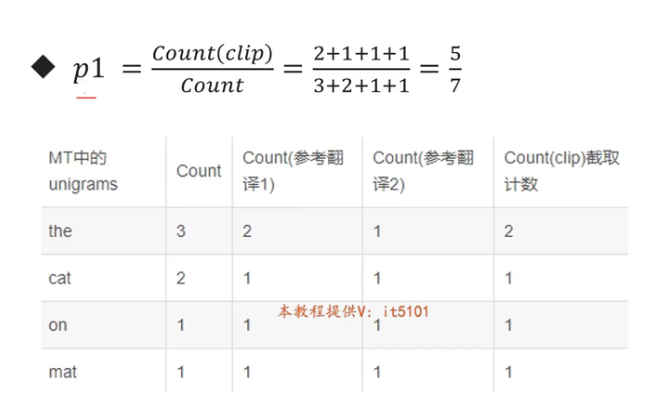
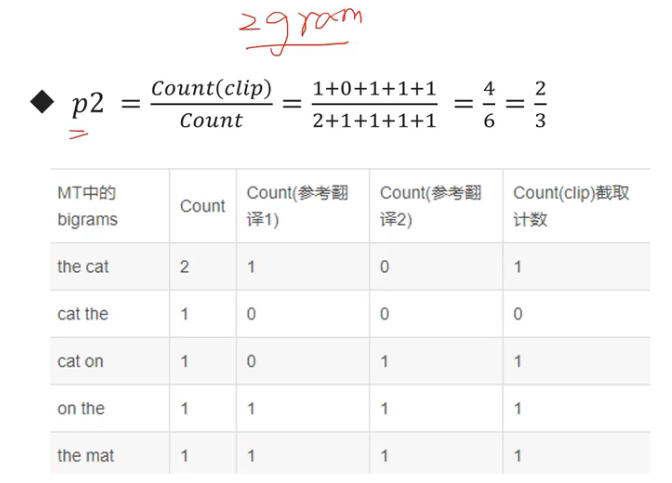
Pn:n-gramm的精确率;n通常为1、2、3,Pn=标签中n个单词出现的个数之和 / 结果中n个单词出现的个数之和
∑Wn*logPn:多项logPn求和,然后取平均值
exp avg:e的avg次幂
BP:长度惩罚,防止生成过短,造成得分虚高


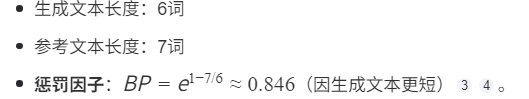
 2)ROUGE-L
2)ROUGE-L
ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation based on Longest Common Subsequence)是一种基于最长公共子序列(LCS)的文本相似度评估指标,主要用于自动文摘、机器翻译等任务的生成质量评估46。
LCS要保持单词的顺序不变,可以跨词,但不能颠倒顺序
ROUGE-L通过召回率(Recall)、精确率(Precision)和F1值综合评分:


4、如何测试RAG的精确率、召回率?
1)检索阶段
① 构建数据集
② 计算RAG的准确率、召回率、F1
准确率:检索结果中真正相关的文档占比。例如:
- 检索返回5篇文档,其中3篇与问题相关 → Precision = 3/5 = 0.6。
召回率:系统找到相关文档的能力。
- 数据集中共有10篇相关文档,检索到3篇 → Recall = 3/10 = 0.3。
F1 : 精确率和召回率的调和平均数,平衡两者。
F1=2×(Precision×Recall / Precision+Recall)
2)生成阶段
① 自动评估
- 使用BLEU/ROUGE对比生成答案与参考答案。
② 人工评估
- 设计评分表(如1-5分制),评估生成答案的正确性、流畅性、有用性。