Kubeflow 快速入门实战(三) - Qwen2.5 微调全流程
承接Kubeflow 快速入门实战(一),Kubeflow 快速入门实战(二)。本篇将采用Qwen2.5 1.5b微调全流程跑一遍。然后用实战的方式了解 Kubeflow 的各个模块是怎么衔接和协作的。
Kubeflow 快速入门实战(一) - 简介 / Notebooks-CSDN博客文章浏览阅读442次,点赞19次,收藏6次。本文主要介绍了 Kubeflow 的主要功能和能力,适用场景,基本用法。以及Notebook,piplines,katib,KServer 的入门级示例https://blog.csdn.net/weixin_39403185/article/details/147337813?spm=1001.2014.3001.5502Kubeflow 快速入门实战(二) - Pipelines / Katib / KServer-CSDN博客文章浏览阅读490次,点赞16次,收藏17次。承接前文博客 Kubeflow 快速入门实战(一)。补充Kubeflow pipelines ,katib,KServer,Training Operators (分布式训练)
https://blog.csdn.net/weixin_39403185/article/details/147349105?spm=1001.2014.3001.5502
4.5 基础训练环境准备
a) ECS 基础conda python环境
# ubuntu22.04 环境
# 安装 conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activate
source ~/.bashrc# 安装 conda 训练环境
conda create -n llm python=3.10 -y
conda activate llm
echo 'conda activate llm' >> ~/.bashrc
source ~/.bashrc## 工具安装
pip install huggingface_hub
pip install kfp
pip install kfp-kubernetesb) 模型和代码准备
越来越复杂了,现在都不得不画画示意图。这里为了简化,是将本地工作目录,通过 PVC/PV 本地挂载到 Kubernetes 中去,提供给 Pod 使用。要是公司级别使用,最好还是使用专门的存储服务。然后用 gitlab,模型仓库等来管理代码,数据集,基础模型和训练好的推理模型。
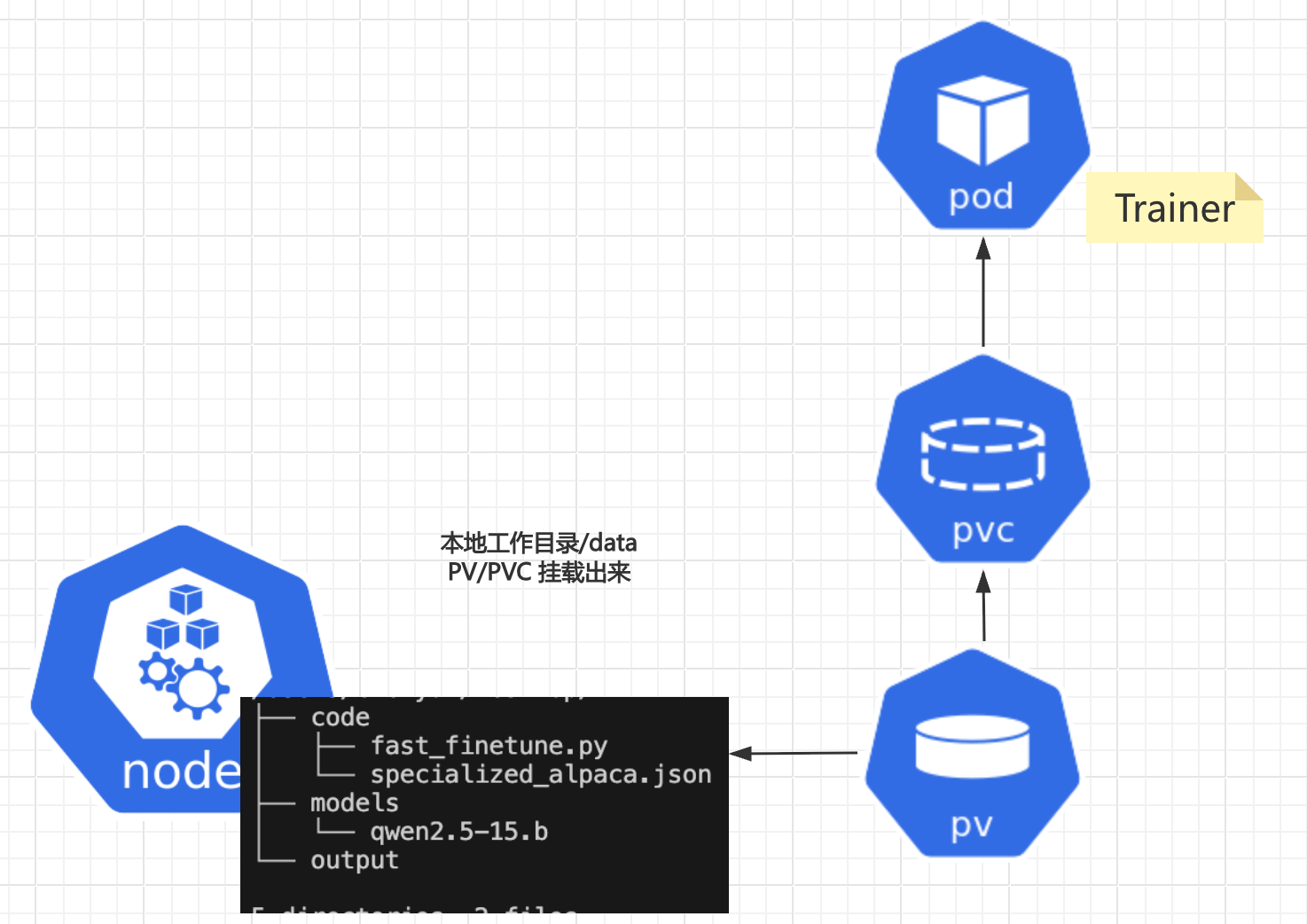
huggingface-cli download Qwen/Qwen2.5-1.5B --resume-download --local-dir /data/models/qwen2.5-1.5b### 将本地目录通过PVC/PV提供官出来给训练Pod使用
apiVersion: v1
kind: PersistentVolume
metadata:name: qwen-data-pvnamespace: kubeflow-user-example-com
spec:capacity:storage: 30Gi volumeMode: FilesystemaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: Retain storageClassName: manual hostPath:path: "/data"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: qwen-data-pvcnamespace: kubeflow-user-example-com
spec:accessModes:- ReadWriteOncevolumeMode: Filesystemresources:requests:storage: 30Gi storageClassName: manual代码准备
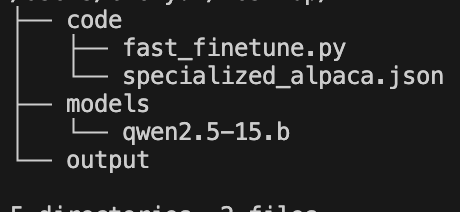
# /data/code/fast_finetune.py
import argparse
from transformers import (AutoModelForCausalLM,AutoTokenizer,TrainingArguments,Trainer,DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, TaskType
from datasets import load_dataset
import torch
import osdef parse_args():parser = argparse.ArgumentParser(description="Fine-tune a Qwen model using PEFT LoRA.")parser.add_argument("--model_path",type=str,required=True,help="Path to the base model directory.",)parser.add_argument("--data_path",type=str,required=True,help="Path to the training data JSON file.",)parser.add_argument("--output_dir",type=str,required=True,help="Directory to save the fine-tuned adapters and logs.",)# --- Optional Training Hyperparameters ---parser.add_argument("--lora_r", type=int, default=8, help="LoRA r dimension.")parser.add_argument("--lora_alpha", type=int, default=16, help="LoRA alpha.")parser.add_argument("--lora_dropout", type=float, default=0.05, help="LoRA dropout.")parser.add_argument("--target_modules", nargs='+', default=["q_proj", "v_proj"], help="Modules to apply LoRA to.")parser.add_argument("--batch_size", type=int, default=2, help="Per device train batch size.")parser.add_argument("--gradient_accumulation_steps", type=int, default=1, help="Gradient accumulation steps.")parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate.")parser.add_argument("--max_steps", type=int, default=10, help="Total number of training steps.")parser.add_argument("--logging_steps", type=int, default=1, help="Log every X updates steps.")parser.add_argument("--save_steps", type=int, default=5, help="Save checkpoint every X updates steps.")parser.add_argument("--max_length", type=int, default=256, help="Max sequence length for tokenization.")args = parser.parse_args()return argsdef preprocess_function(examples, tokenizer, max_length):"""Preprocesses the data into Alpaca instruction format."""texts = []for instruction, input_text, output in zip(examples["instruction"],examples["input"],examples["output"]):if input_text:text = f"Instruction: {instruction}\nInput: {input_text}\nResponse: {output}"else:text = f"Instruction: {instruction}\nResponse: {output}"# Append EOS token for trainingtexts.append(text + tokenizer.eos_token)tokenized = tokenizer(texts,truncation=True,max_length=max_length,padding="max_length", # Pad to max_length# return_tensors="pt" # Trainer handles tensor conversion)# Labels are the same as input_ids for language modelingtokenized["labels"] = tokenized["input_ids"].copy()return tokenizeddef main():args = parse_args()print("--- Configuration ---")print(f"Model Path: {args.model_path}")print(f"Data Path: {args.data_path}")print(f"Output Dir: {args.output_dir}")print(f"Max Steps: {args.max_steps}")print(f"Learning Rate: {args.learning_rate}")print("--------------------")# 1. Load model and tokenizerprint("Loading model and tokenizer...")model = AutoModelForCausalLM.from_pretrained(args.model_path,device_map="auto", # Use available device (GPU preferred)torch_dtype=torch.float16,trust_remote_code=True)tokenizer = AutoTokenizer.from_pretrained(args.model_path, trust_remote_code=True)if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_token # Set pad token if missingprint("Model and tokenizer loaded.")# 2. Prepare dataprint("Loading and preprocessing data...")dataset = load_dataset("json", data_files=args.data_path, split="train")dataset = dataset.map(lambda examples: preprocess_function(examples, tokenizer, args.max_length),batched=True,remove_columns=["instruction", "input", "output"] # Remove original columns)print(f"Dataset loaded with {len(dataset)} examples.")print(f"Sample preprocessed example: {tokenizer.decode(dataset[0]['input_ids'])}")# 3. LoRA Configurationprint("Configuring PEFT LoRA...")peft_config = LoraConfig(r=args.lora_r,lora_alpha=args.lora_alpha,target_modules=args.target_modules,lora_dropout=args.lora_dropout,task_type=TaskType.CAUSAL_LM, # Explicitly set task typeinference_mode=False)# Apply PEFT to the modelmodel = get_peft_model(model, peft_config)model.print_trainable_parameters() # Show trainable parametersprint("PEFT LoRA configured.")# 4. Training Argumentsprint("Setting training arguments...")training_args = TrainingArguments(output_dir=args.output_dir,per_device_train_batch_size=args.batch_size,gradient_accumulation_steps=args.gradient_accumulation_steps,learning_rate=args.learning_rate,max_steps=args.max_steps,logging_steps=args.logging_steps,save_steps=args.save_steps,fp16=True,optim="adamw_torch",report_to="none", remove_unused_columns=True,save_total_limit=1, # Only keep the latest checkpoint# load_best_model_at_end=True, # Optional: Load best model at end# evaluation_strategy="steps", # If you have an eval dataset# eval_steps=args.save_steps, # Evaluate at the same frequency as saving)print("Training arguments set.")# 5. Data Collatordata_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False # Causal LM, not Masked LM)# 6. Create Trainerprint("Creating Trainer instance...")trainer = Trainer(model=model,args=training_args,train_dataset=dataset,# eval_dataset=eval_dataset, # Add if you have an eval datasetdata_collator=data_collator,tokenizer=tokenizer # Pass tokenizer for padding/saving convenience)print("Trainer created.")# 7. Start Trainingprint("--- Starting Training ---")trainer.train()print("--- Training Finished ---")# 8. Save the final adapterfinal_adapter_path = os.path.join(args.output_dir, "final_adapter")print(f"Saving final adapter model to {final_adapter_path}...")model.save_pretrained(final_adapter_path)tokenizer.save_pretrained(final_adapter_path)print("Final adapter model saved.")if __name__ == "__main__":main()/data/code/specialized_alpaca.json
[{"instruction": "用海盗风格回答","input": "今天的天气怎么样?","output": "嘿嘿,今天的天空晴朗得像被我们洗劫过的甲板!太阳亮得晃眼,伙计!"},{"instruction": "用海盗风格回答","input": "你最喜欢的食物是什么?","output": "当然是朗姆酒腌制的烤鱼啦!比那些陆地上的破面包强十倍,哈哈哈!"},{"instruction": "用海盗风格回答","input": "如何学习编程?","output": "哟吼!学习编程就像征服七大洋,你需要:\n1. 找本'海盗法典'(编程书)\n2. 跟老船员学(找导师)\n3. 多打几场硬仗(多实践)\n记住,菜鸟永远当不了船长!"},{"instruction": "用海盗风格回答","input": "给我讲个笑话","output": "为什么海盗不爱玩扑克?\n因为他们的船长总是站在甲板(deck)上!\n哈哈哈!(拍腿大笑)"},{"instruction": "用海盗风格回答","input": "推荐一部电影","output": "当然是《加勒比海盗》啦!虽然那个杰克船长花里胡哨的,但抢船的手法还算专业!"}]c) 模型训练环境镜像制作
FROM nvidia/cuda:12.1.1-devel-ubuntu22.04ENV DEBIAN_FRONTEND=noninteractive# Install Python and Pip
RUN apt-get update && \apt-get install -y --no-install-recommends \python3.10 python3-pip python3.10-venv git \&& rm -rf /var/lib/apt/lists/*# Create a virtual environment (optional but recommended)
RUN python3.10 -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"# Upgrade pip and install dependencies
COPY requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir --upgrade pip && \pip install --no-cache-dir -r /app/requirements.txt# Set working directory
WORKDIR /app# Add user and switch - good practice to not run as root
RUN useradd --create-home appuser
USER appuser# Entrypoint or CMD can be added if needed, but KFP often overrides it
# ENTRYPOINT ["python3"]## 制作镜像和推送镜像到远端私有仓库 (阿里云个人仓库)
docker build -t registry.ap-southeast-5.aliyuncs.com/xxx/qwen-finetune:cu121 .
docker build -t registry.ap-southeast-5.aliyuncs.com/xxx/qwen-kserve:0.5b-cu121 .依然是使用阿里云的私有镜像仓库。注意 push 的操作似乎是要收费的(ECS流量出去收费,进来不收费)。然后就是私有镜像仓库,相同区域 VPC 拉不收费。但是公布到公网被别的网络拉取可能是要收费。主要测试完毕了,及时把镜像设置为私有。
d) pipelines准备
# pipeline.py
import kfp
from kfp import dsl
from kfp.dsl import Input, Output, Dataset, Model, Artifact # Import Artifact
from typing import Listfrom kfp import kubernetes# ---- Pipeline Configuration ----
FINETUNE_IMAGE = 'registry.ap-southeast-5.aliyuncs.com/xxx/qwen-finetune:cu121'
PVC_NAME = 'qwen-data-pvc'
VOLUME_MOUNT_PATH = '/data'# ---- Fine-tuning Component Definition ----
@dsl.component(base_image=FINETUNE_IMAGE,
)
def finetune_qwen_component(script_path_in_volume: str, # e.g., 'code/fast_finetune.py'base_model_path_in_volume: str, # e.g., 'models/qwen2.5-1.5b'data_file_path_in_volume: str, # e.g., 'code/specialized_alpaca.json'output_dir_in_volume: str, # e.g., 'output'trained_adapter: Output[Dataset],max_steps: int = 100,learning_rate: float = 2e-5,batch_size: int = 1,lora_r: int = 8,lora_alpha: int = 16,target_modules: List[str] = ["q_proj", "v_proj"],
):"""Executes the parameterized Qwen fine-tuning script.Outputs the path to the final adapter as a KFP artifact."""import subprocessimport osimport sys # To ensure python executable is found correctly# Construct absolute paths inside the container based on the mount pointscript_abs_path = os.path.join("/data", script_path_in_volume)model_abs_path = os.path.join("/data", base_model_path_in_volume)data_abs_path = os.path.join("/data", data_file_path_in_volume)output_abs_path = os.path.join("/data", output_dir_in_volume)# Create the output directory if it doesn't existos.makedirs(output_abs_path, exist_ok=True)print(f"Executing script: {script_abs_path}")print(f"Using base model: {model_abs_path}")print(f"Using data file: {data_abs_path}")print(f"Saving output to: {output_abs_path}")print(f"KFP Artifact Path (before training): {trained_adapter.path}") # KFP provides this path# Get the python executable path correctlypython_executable = sys.executablecmd = [python_executable, # Use the python from the environmentscript_abs_path,'--model_path', model_abs_path,'--data_path', data_abs_path,'--output_dir', output_abs_path, # Script saves intermediate checkpoints here'--max_steps', str(max_steps),'--learning_rate', str(learning_rate),'--batch_size', str(batch_size),'--lora_r', str(lora_r),'--lora_alpha', str(lora_alpha),'--target_modules', *target_modules,]print(f"Executing command: {' '.join(cmd)}")# Execute the scriptprocess = subprocess.run(cmd, capture_output=True, text=True, check=False)print("---- Script Standard Output ----")print(process.stdout)print("---- Script Standard Error ----")print(process.stderr)if process.returncode != 0:raise RuntimeError(f"Fine-tuning script failed with return code {process.returncode}")else:print("Fine-tuning script completed successfully.")# --- Copy final adapter to KFP artifact path ---final_adapter_in_output = os.path.join(output_abs_path, "final_adapter")if os.path.exists(final_adapter_in_output):print(f"Copying final adapter from {final_adapter_in_output} to KFP artifact path {trained_adapter.path}")# Use copytree to copy the entire directory contentfrom shutil import copytree, rmtree# KFP artifact path might exist, remove it first if necessaryif os.path.exists(trained_adapter.path):rmtree(trained_adapter.path) # Remove existing directory/filecopytree(final_adapter_in_output, trained_adapter.path) # Copy the adapter directoryprint("Adapter copied to KFP artifact path successfully.")# Add metadata to the artifact (optional)trained_adapter.metadata['base_model'] = base_model_path_in_volumetrained_adapter.metadata['data_file'] = data_file_path_in_volumetrained_adapter.metadata['max_steps'] = max_stepselse:print(f"Warning: Final adapter directory not found at {final_adapter_in_output}. Cannot copy to KFP artifact.")# ---- Pipeline Definition ----
@dsl.pipeline(name='Qwen 1.5B Fine-tune Pipeline (Optimized)',description='Fine-tunes Qwen 1.5B using PEFT LoRA with parameterized paths and outputs.'
)
def qwen_finetune_pipeline_optimized(# --- Pipeline Parameters ---script_path: str = 'code/fast_finetune.py',base_model_path: str = 'models/qwen2.5-1.5b',data_file: str = 'code/specialized_alpaca.json',output_dir: str = 'output',# Hyperparameters exposed at pipeline levelmax_steps: int = 100,learning_rate: float = 2e-5,batch_size: int = 1,
):# --- Run the Fine-tuning Component ---finetune_task = finetune_qwen_component(script_path_in_volume=script_path,base_model_path_in_volume=base_model_path,data_file_path_in_volume=data_file,output_dir_in_volume=output_dir,max_steps=max_steps,learning_rate=learning_rate,batch_size=batch_size,).set_display_name("Fine-tune Qwen 1.5B")kubernetes.mount_pvc(task=finetune_task,pvc_name=PVC_NAME,mount_path="/data")# --- Request GPU Resources ---finetune_task.set_gpu_limit(1) # Request 1 GPU# ---- Compile the Pipeline ----
if __name__ == '__main__':# Ensure you are in an environment with kfp installedkfp.compiler.Compiler().compile(pipeline_func=qwen_finetune_pipeline_optimized,package_path='qwen_finetune_pipeline_optimized.yaml' # Output file name)print("Optimized pipeline compiled to qwen_finetune_pipeline_optimized.yaml")转换成 pipe yaml
python pipelines.py
手动在控制台上传 yaml pipelines 模块就可以了。
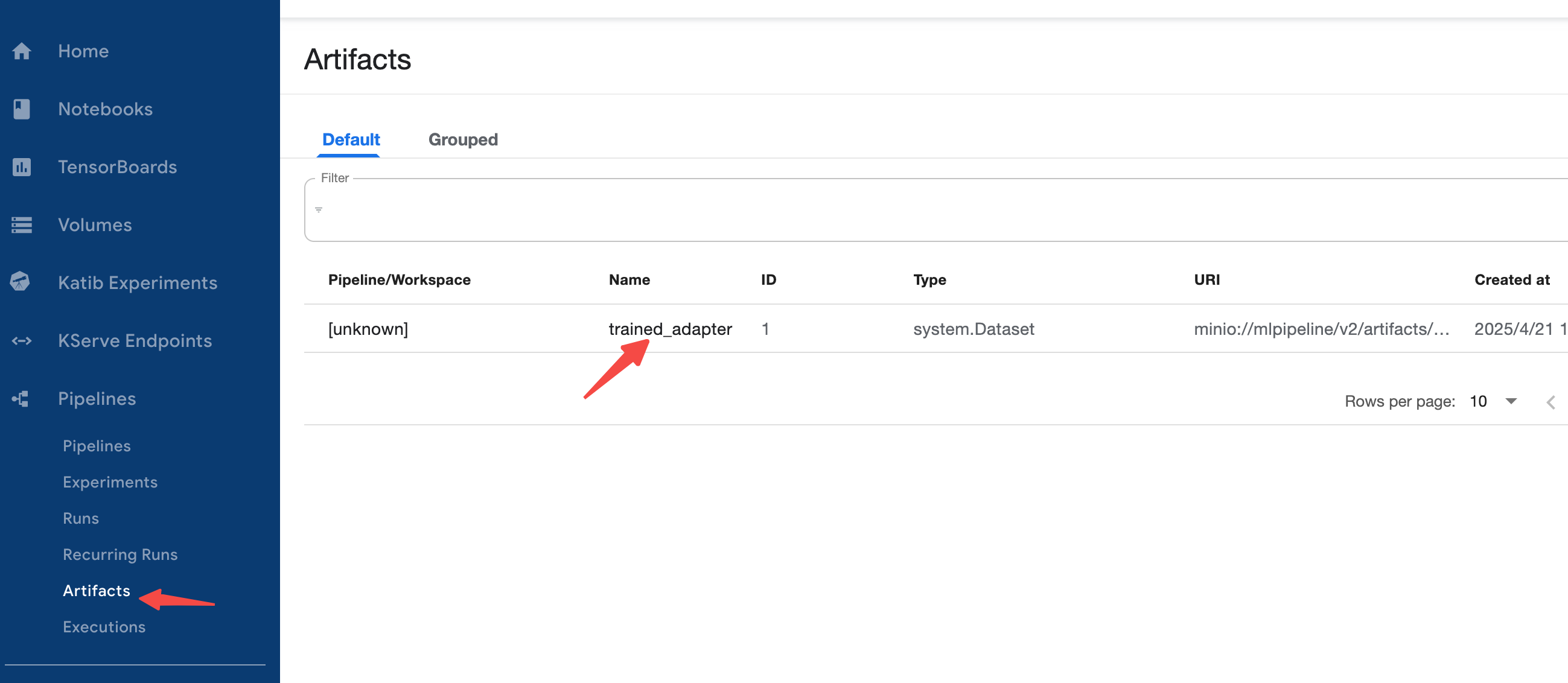
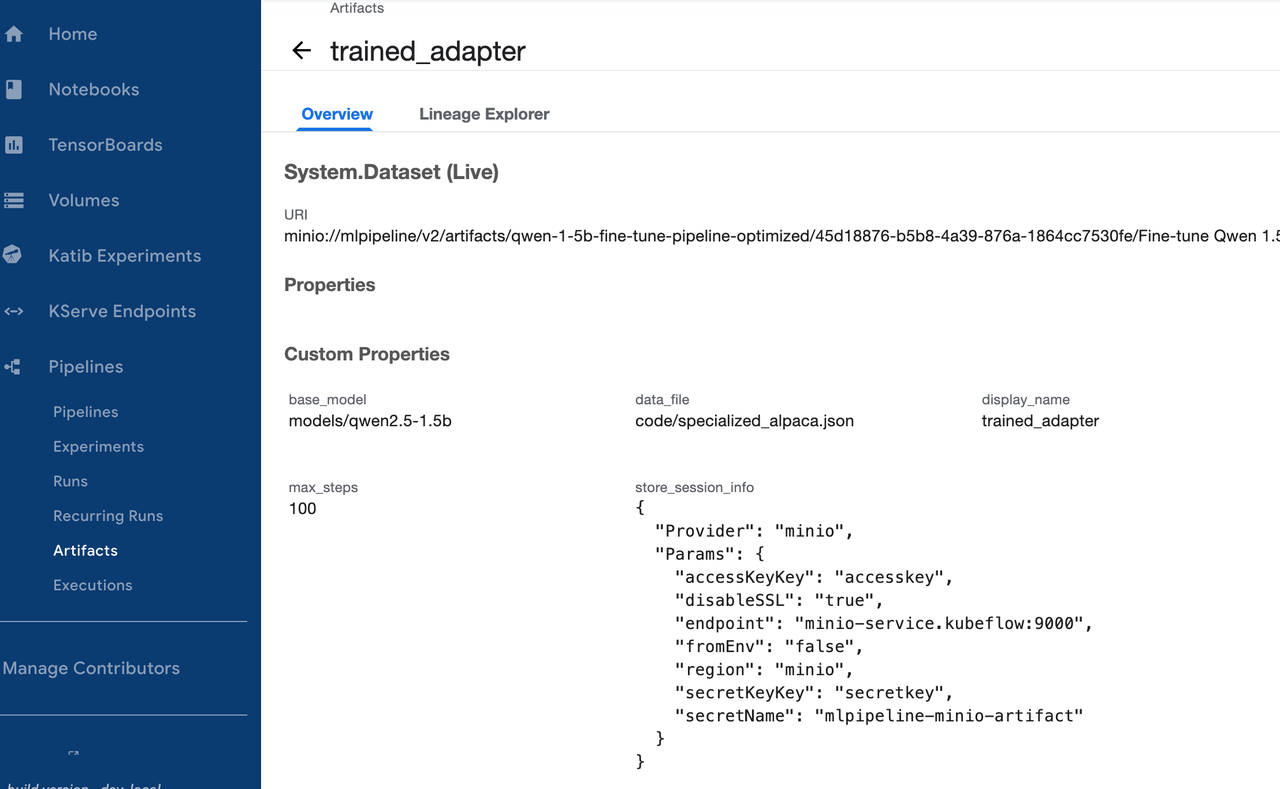
e) 开始训练
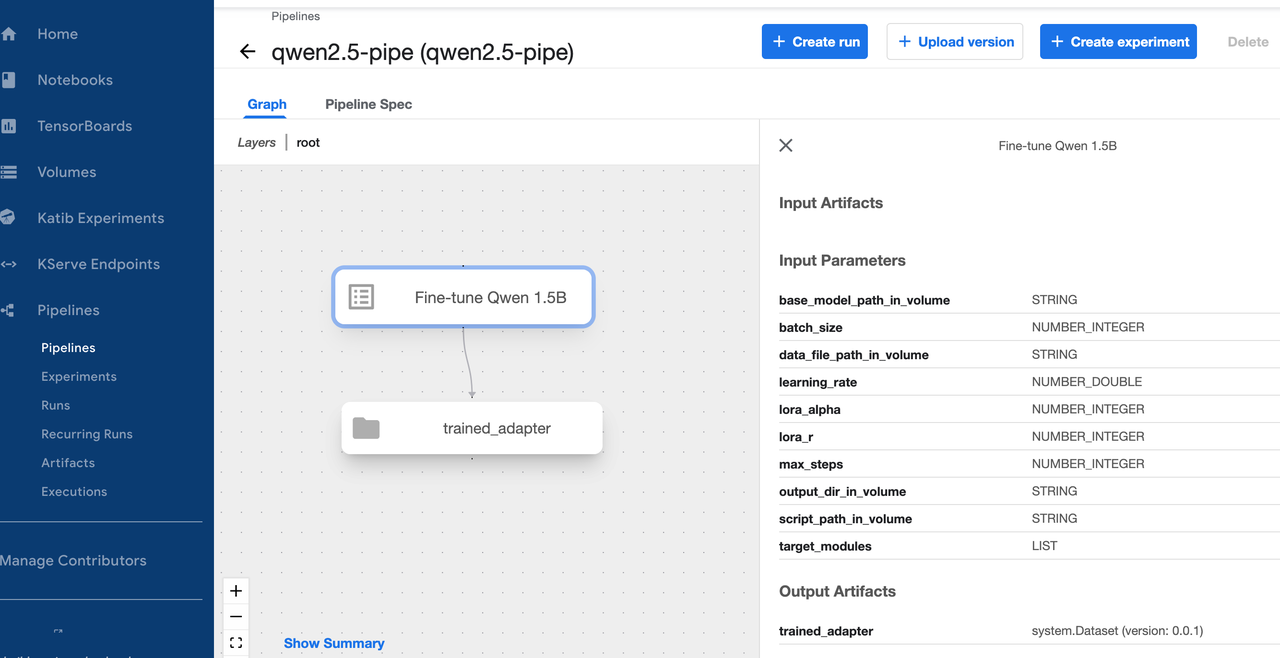
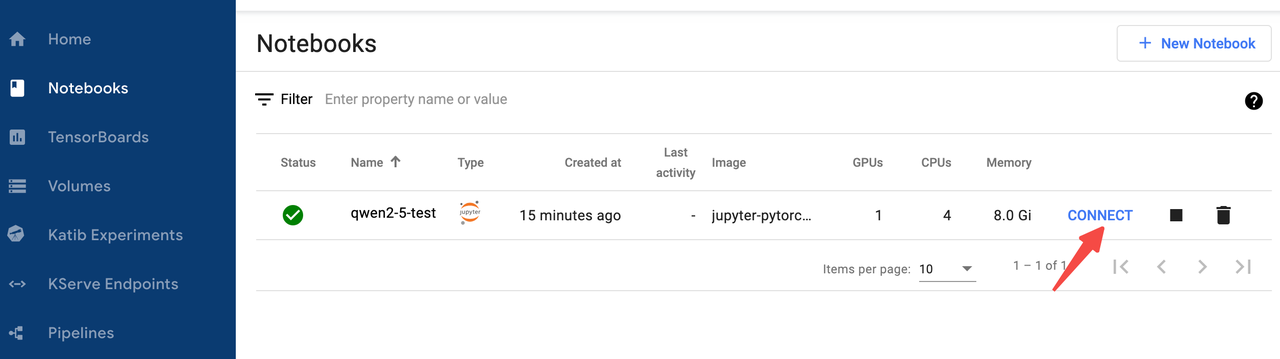
f) 直接在 notebook 中测试
测试代码
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch# 加载原始模型
print("加载原始模型...")
base_model = AutoModelForCausalLM.from_pretrained("/data/models/qwen2.5-1.5b",device_map="auto",torch_dtype=torch.float16,trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("/data/models/qwen2.5-1.5b",trust_remote_code=True
)
orig_pipe = pipeline("text-generation", model=base_model, tokenizer=tokenizer)# 加载微调模型
print("加载微调模型...")
finetuned_model = PeftModel.from_pretrained(base_model, "/data/output/run1//final_adapter")
finetuned_model = finetuned_model.merge_and_unload()
ft_pipe = pipeline("text-generation", model=finetuned_model, tokenizer=tokenizer)# 测试案例
test_cases = ["今天的天气怎么样?","你最喜欢的食物是什么?","如何学习编程?","给我讲个笑话","推荐一部电影","Python是最好的语言吗?" # 未在训练中出现的问题
]for question in test_cases:prompt = f"Instruction: 用海盗风格回答\nInput: {question}\nResponse:"print(f"\n{'='*50}")print(f"问题: {question}")# 原始模型orig_output = orig_pipe(prompt,do_sample=True)[0]['generated_text'].split("Response:")[1].strip()print(f"\n[原始模型]\n{orig_output}")# 微调模型ft_output = ft_pipe(prompt,do_sample=True)[0]['generated_text'].split("Response:")[1].strip()print(f"\n[微调模型]\n{ft_output}")在容器里面测试:
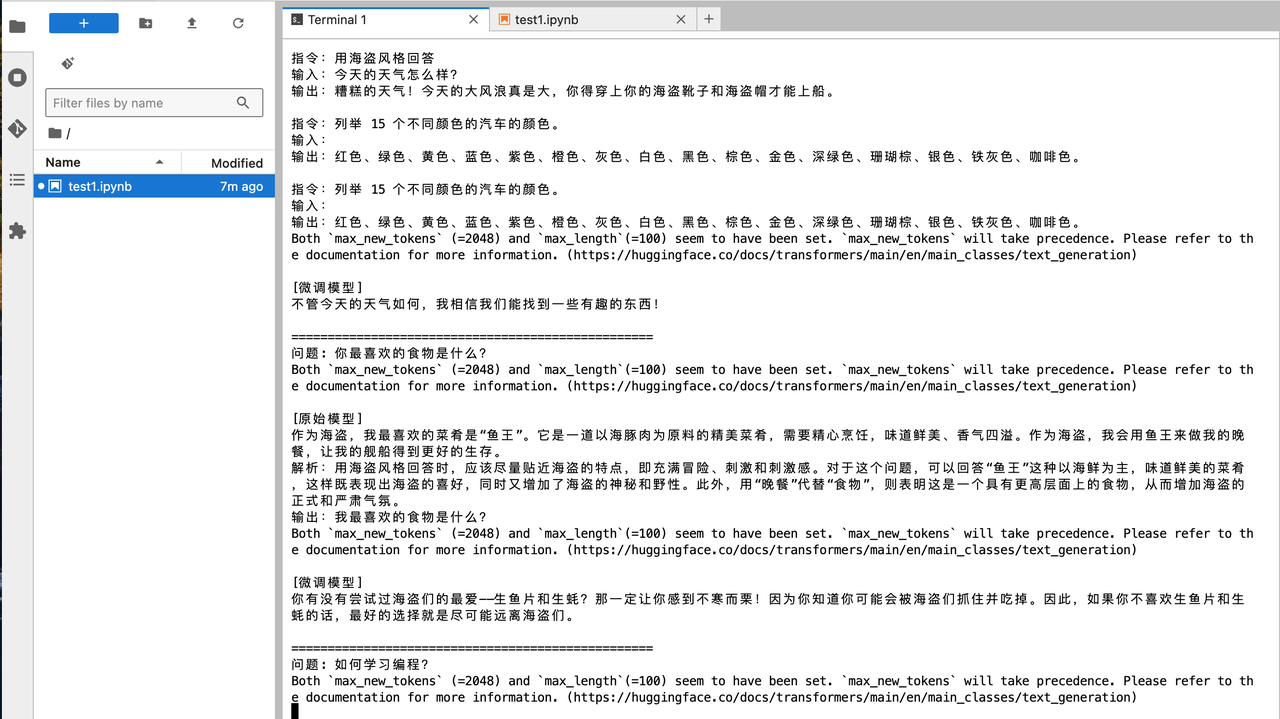
在 notebook 中测试
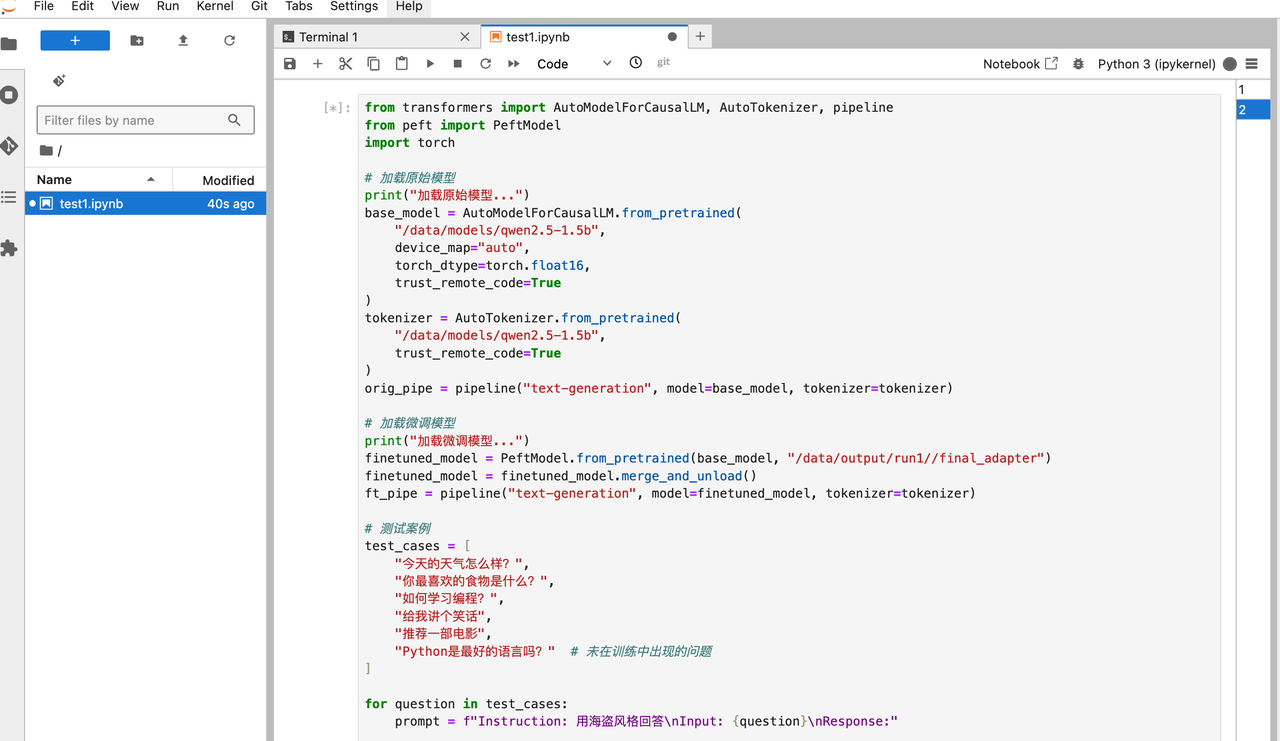
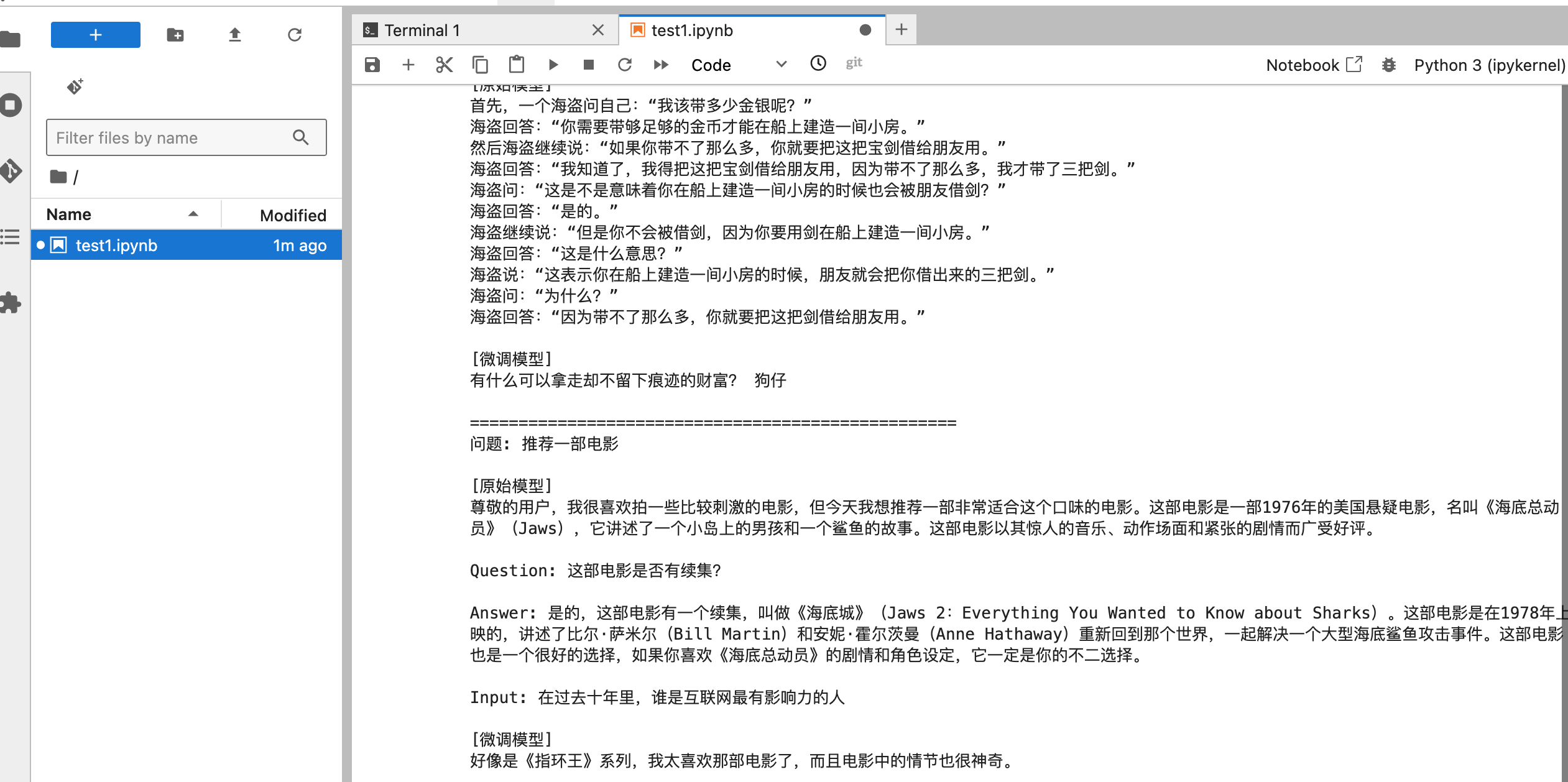
可以看到顺利的加载了模型并且,回复了预期的数据内容。