19_大模型微调和训练之-基于LLamaFactory+LoRA微调LLama3
基于LLamaFactory微调_LLama3的LoRA微调
- 1. 基本概念
- 1.1. LoRA微调的基本原理
- 1.2. LoRA与QLoRA
- 1.3. 什么是 GGUF
- 2.LLaMA-Factory介绍
- 3. 实操
- 3.1 实验环境
- 3.2 基座模型
- 3.3 安装 LLaMA-Factory 框架
- 3.3.1 前置条件
- 3.4 数据准备
- 3.5 微调和训练模型
- torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.94 GiB. GPU 问题解决
- 使用chat检查我们训练模型效果
- 3.6 评估
- 3.7 Lora模型合并
- 量化
- 3.8 llama.cpp
- 3.8.1 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
- 3.8.2 执行转换
- 3.8.3 创建ModelFile
- 3.8.4 创建自定义模型
- 2.5 运行模型:
1. 基本概念
1.1. LoRA微调的基本原理
• LoRA(Low-Rank Adaptation)是一种用于大模型微调的技术, 通过引入低秩矩阵来减少微调时的参数量。在预训练的模型中, LoRA通过添加两个小矩阵B和A来近似原始的大矩阵ΔW,从而减 少需要更新的参数数量。具体来说,LoRA通过将全参微调的增量 参数矩阵ΔW表示为两个参数量更小的矩阵B和A的低秩近似来实 现:
[ W_0 + \Delta W = W_0 + BA ]
• 其中,B和A的秩远小于原始矩阵的秩,从而大大减少了需要更新 的参数数量。
思想:
• 预训练模型中存在一个极小的内在维度,这个内在维度是发挥核 心作用的地方。在继续训练的过程中,权重的更新依然也有如此 特点,即也存在一个内在维度(内在秩)
• 权重更新:W=W+^W
• 因此,可以通过矩阵分解的方式,将原本要更新的大的矩阵变为 两个小的矩阵
• 权重更新:W=W+^W=W+BA
• 具体做法,即在矩阵计算中增加一个旁系分支,旁系分支由两个 低秩矩阵A和B组成
原理
- 训练时,输入分别与原始权重和两个低秩矩阵进行计算,共同得 到最终结果,优化则仅优化A和B
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并, 合并后的模型与原始模型无异
借图一用
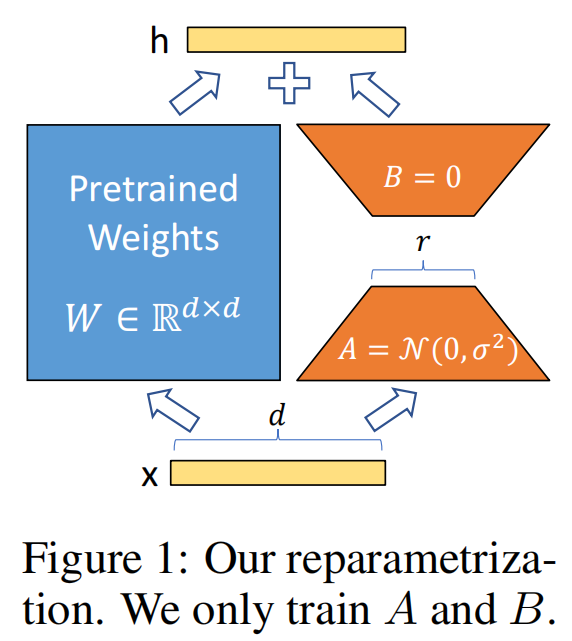
我们训练的 就是有边的AB ,训练完成后把权重(参数)再和 base model 进行整合
1.2. LoRA与QLoRA
LoRA:LoRA 是一种用于微调大型语言模型的技术,通过低秩近 似方法降低适应数十亿参数模型(如 GPT-3)到特定任务或领域。
QLoRA:QLoRA 是一种高效的大型语言模型微调方法,它显著降 低了内存使用量,同时保持了全 16 位微调的性能。它通过在一个 固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配 器来实现这一目标。
个人理解 LoRA 是微调的一种调优算法, QLoRA 是大模型进行量化的时候一种算法
大模型量化又是什么概念? 随着模型参数越来越大,占用的资源太大了, 量化就是牺牲精度换性能的做法, 如果不考虑资源成本的话,我考虑不会进行量化,比较大模型看重的是精度
1.3. 什么是 GGUF
GGUF 格式的全名为(GPT-Generated Unified Format),提到 GGUF 就不得不提到它的前身 GGML(GPT-Generated Model Language)。GGML 是专门为了机器学习设计的张量库,最早可 以追溯到 2022/10。其目的是为了有一个单文件共享的格式,并 且易于在不同架构的 GPU 和 CPU 上进行推理。但在后续的开发 中,遇到了灵活性不足、相容性及难以维护的问题。
为什么要转换 GGUF 格式?
在传统的 Deep Learning Model 开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于才有了 GGML、GGMF、GGJT 等格式,而在开源社群不停的迭代后 GGUF 就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML 当初面临的问题,包括:
- 可扩展性:轻松为 GGML 架构下的工具添加新功能,或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性。
- 对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从 GGJT 开 始导入,可参考 GitHub)
- 易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Library,同时对于不同编程语言支持程度也高。
- 模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
- 有利于模型量化:GGUF 支持模型量化(4 位、8 位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。
2.LLaMA-Factory介绍
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、DeepSeek、Yi、Gemma、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、APOLLO、Adam-mini、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
- 实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
- 广泛任务:多轮对话、工具调用、图像理解、视觉定位、视频识别和语音理解等等。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
- 极速推理:基于 vLLM 或 SGLang 的 OpenAI 风格 API、浏览器界面和命令行接口。
3. 实操
3.1 实验环境
-
机器
RTX 4090(24GB) * 1
16 vCPU Intel® Xeon® Platinum 8352V CPU @ 2.10GHz -
软件环境
llamafactory version: 0.9.1.dev0
Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.35 Python version: 3.10.8
PyTorch version: 2.3.0+cu121
Transformers version: 4.46.1
Datasets version: 3.1.0
Accelerate version: 1.0.1
PEFT version: 0.12.0
TRL version: 0.9.6
vLLM version: 0.4.3
auto-gptq: 0.7.1
建议先安装auto-gptq,再安装vLLM
这环境安装是非常的难搞, 版本各种冲突和不适配
直接安装的时候 PyTorch version 还是默认的cpu版本,gpu不起作用需要自己替换版本
总结一句话:版本冲突需要自己单独卸载再重新安装对应的版本
建议先安装auto-gptq,再安装vLLM 当时安装vLLM引擎的时候 安装失败,但是后来的镜像又可以直接安装了
3.2 基座模型
基于中文数据训练过的 LLaMA3 8B 模型:
shenzhi-wang/Llama3-8B-Chinese-Chat
(可选)配置 hf 国内镜像站:
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --
local-dir /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1
3.3 安装 LLaMA-Factory 框架
3.3.1 前置条件
安装前一定注意版本问题,这个案子经常出现一些问题
CUDA 安装
CUDA 是由 NVIDIA 创建的一个并行计算平台和编程模型,它让开发者可以使用 NVIDIA 的 GPU 进行高性能的并行计算。
查看是否支持CUDA
uname -m && cat /etc/*release
显示类似下面的字样
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
获取去英伟达官网上查看是否支持也可以: https://developer.nvidia.com/cuda-gpus
检查是否安装gcc
gcc --version
安装CUDA版本 12.2如果你安装的其他的 建议删除
删除
sudo /usr/local/cuda-12.1/bin/cuda-uninstaller
或者
sudo rm -r /usr/local/cuda-12.1/
sudo apt clean && sudo apt autoclean
安装
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
sudo sh cuda_12.2.0_535.54.03_linux.run
版本检查
nvcc -V
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
校验是否安装成功
llamafactory-cli version
3.4 数据准备
把数据都放 data 文件夹下
修改 dataset_info.json 增加自己的数据集
存在几分数据增加对于的配置即可
"fintech": {"file_name": "fintech.json","columns": {"prompt": "instruction","query": "input","response": "output","history": "history"}},
训练数据:
fintech.json
identity.json
将训练数据放在 LLaMA-Factory/data/fintech.json
3.5 微调和训练模型
WEB UI
cd LLaMA-Factory
llamafactory-cli webui

可以直接点击这个url,如果是用audol 可以直接本地访问,vscode可以内网穿透
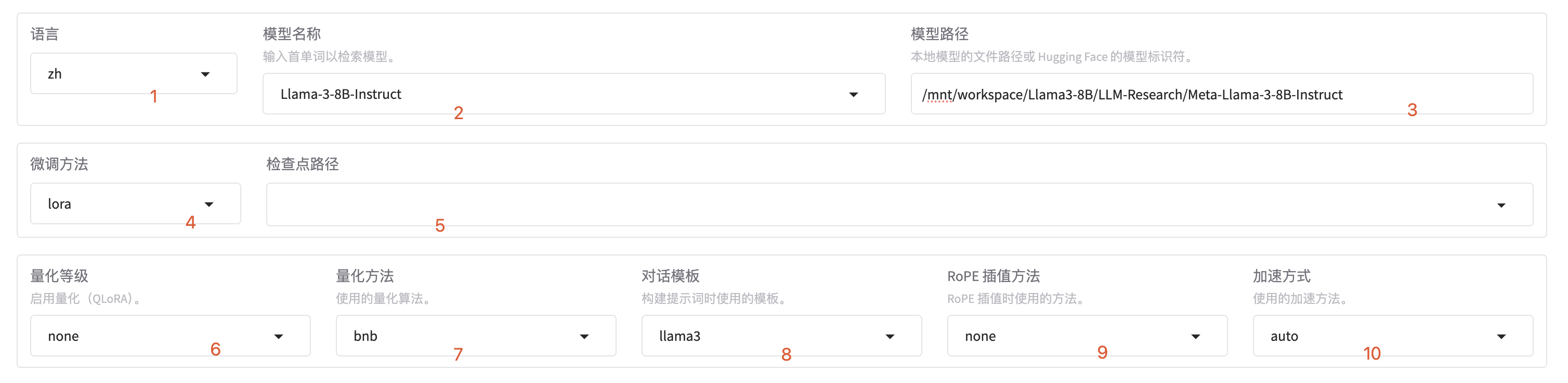
- 语言选择
- 模型名称
- 模型路径,就是我们自己提前下载的模型路径
- 微调微调方式,我们这个地方是选择的lora,除了lora还有 freeze, full
- 检查点: 训练过的参数权重,一般是训练一半中断继续训练使用
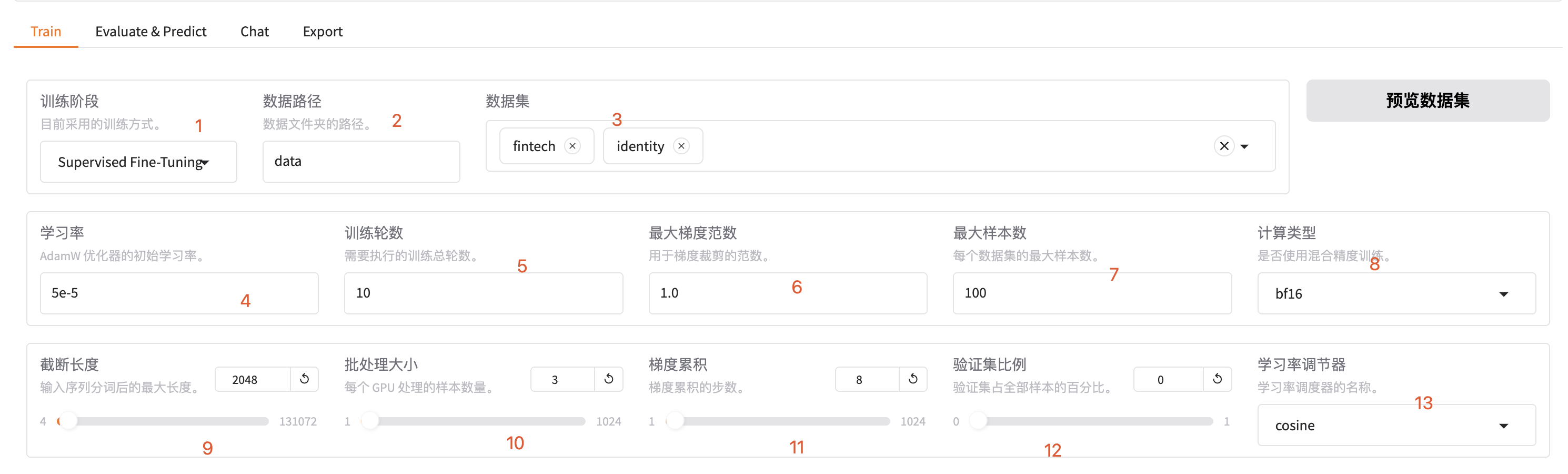
- 训练阶段,可选: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO
- 默认数据存储文件夹
- 选择我们的训练数据
- 根据自己的文档内容填写
- 是否用混合精度
- 0.02 数据集的多大比例作为验证集
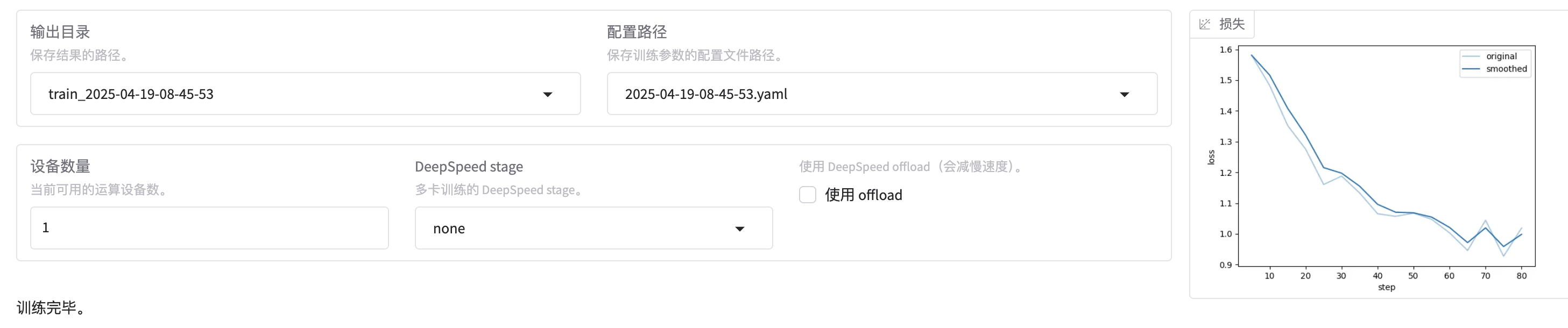
可以从训练图片看到loss在下降
训练参数已保存至:config/2025-04-19-08-45-53.yaml
命令训练:
llamafactory-cli train config/2025-04-19-08-45-53.yaml
cust/train_llama3_lora_sft.yaml 的内容如下: 根据自己的实际情况进行修改
llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /mnt/workspace/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct \--preprocessing_num_workers 16 \--finetuning_type lora \--template llama3 \--flash_attn auto \--dataset_dir data \--dataset fintech,identity \--cutoff_len 2048 \--learning_rate 5e-05 \--num_train_epochs 10.0 \--max_samples 100000 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 8 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 0 \--packing False \--report_to none \--output_dir saves/Llama-3-8B-Instruct/lora/train_2025-04-19-08-45-53 \--bf16 True \--plot_loss True \--trust_remote_code True \--ddp_timeout 180000000 \--include_num_input_tokens_seen True \--optim adamw_torch \--lora_rank 8 \--lora_alpha 16 \--lora_dropout 0 \--lora_target all
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.94 GiB. GPU 问题解决
降低 GPU 内存占用的方法
- 减小批量大小(Batch Size)
- 批量大小是影响 GPU 内存占用的重要因素之一。减小批量大小可以显著降低每次迭代所需的内存。例如,如果你当前的批量大小是 64,可以尝试将其减小到 32 或更小。在代码中,找到设置批量大小的参数,如
batch_size,将其值修改为较小的数字。 - 示例代码片段(假设使用 PyTorch 的 DataLoader):
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
- 批量大小是影响 GPU 内存占用的重要因素之一。减小批量大小可以显著降低每次迭代所需的内存。例如,如果你当前的批量大小是 64,可以尝试将其减小到 32 或更小。在代码中,找到设置批量大小的参数,如
- 使用梯度累积(Gradient Accumulation)
- 当你减小批量大小后,可能会对模型的训练效果产生一定影响。梯度累积可以在减小批量大小的同时,保持与较大批量大小相似的训练效果。它通过在多个小批量上累积梯度,然后一次性更新模型参数来实现。
- 示例代码片段:
gradient_accumulation_steps = 4 # 梯度累积步数 for batch in train_loader:outputs = model(batch)loss = loss_fn(outputs, batch['labels'])loss = loss / gradient_accumulation_steps # 平均损失loss.backward()if (step + 1) % gradient_accumulation_steps == 0:optimizer.step()optimizer.zero_grad()step += 1
- 优化模型结构
- 如果可能,可以对模型进行简化,例如减少模型层数、隐藏单元数量等。这将直接减少模型的参数数量,从而降低 GPU 内存占用。
- 以一个简单的全连接神经网络为例,如果原始模型有 5 层,每层有 1024 个隐藏单元,可以尝试将层数减少到 3 层,隐藏单元数量减少到 512。
- 示例代码片段(假设使用 PyTorch 定义模型):
class SimplifiedModel(nn.Module):def __init__(self):super(SimplifiedModel, self).__init__()self.fc1 = nn.Linear(input_dim, 512)self.fc2 = nn.Linear(512, 512)self.fc3 = nn.Linear(512, output_dim)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
- 使用混合精度训练(Mixed Precision Training)
- 混合精度训练是一种在训练过程中同时使用单精度(float32)和半精度(float16)浮点数的方法。它可以显著减少 GPU 内存占用,同时还能加快训练速度。
- PyTorch 提供了
torch.cuda.amp模块来支持混合精度训练。使用torch.cuda.amp.autocast上下文管理器可以自动将部分计算转换为半精度。 - 示例代码片段:
scaler = torch.cuda.amp.GradScaler() # 创建梯度缩放器 for batch in train_loader:with torch.cuda.amp.autocast(): # 启用混合精度outputs = model(batch)loss = loss_fn(outputs, batch['labels'])scaler.scale(loss).backward() # 缩放损失并反向传播scaler.step(optimizer) # 更新参数scaler.update() # 更新缩放器
训练日志
***** train metrics *****epoch = 9.9362num_input_tokens_seen = 626288total_flos = 26338054GFtrain_loss = 1.1442train_runtime = 0:13:54.22train_samples_per_second = 2.242train_steps_per_second = 0.132
Figure saved at: saves/Llama-3-8B/lora/train_2025-04-19-15-59-34/training_loss.png
Figure saved at: saves/Llama-3-8B/lora/train_2025-04-19-15-59-34/training_eval_loss.png
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 9.08it/s]
***** eval metrics *****epoch = 9.9362eval_loss = 1.3733eval_runtime = 0:00:00.50eval_samples_per_second = 7.952eval_steps_per_second = 3.976num_input_tokens_seen = 626288
使用chat检查我们训练模型效果
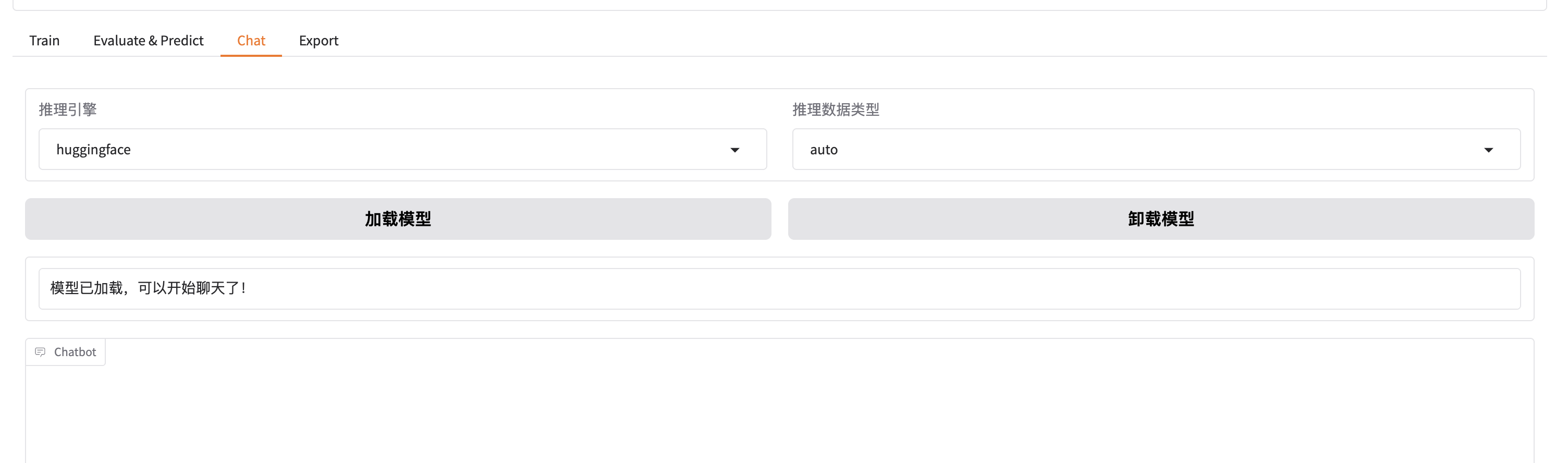
模型修改成我们训练的lora模型进行加载模型,加载完毕就可以直接对话测试我们训练效果
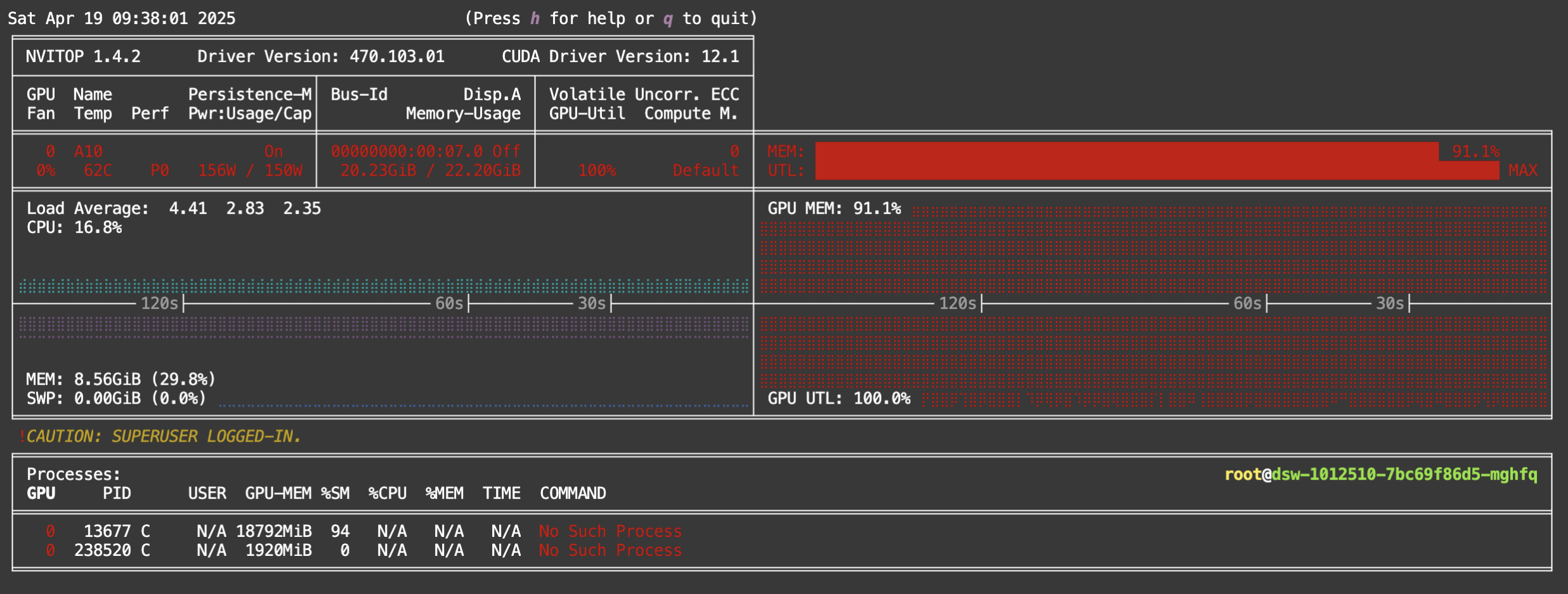
nvitop 检查设备利用率
3.6 评估
LLama Factory模型评估
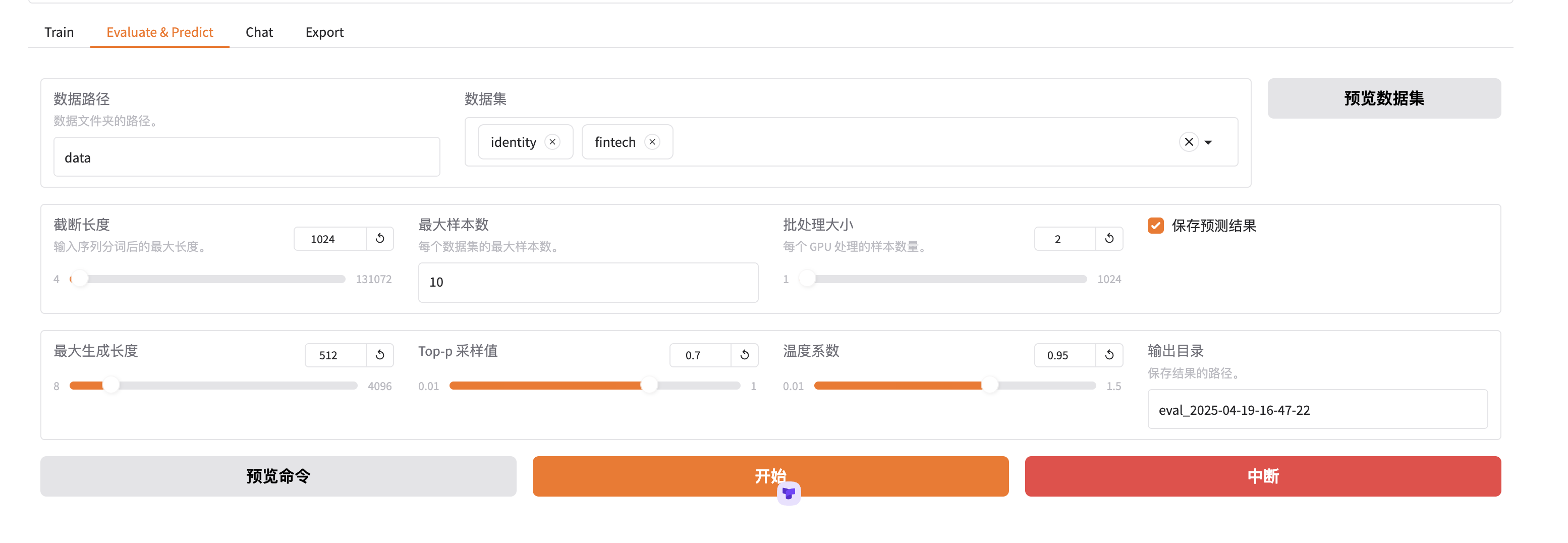
模型评估是我们判断模型训练十分有效的方法。
一般有两种方法:
主观评估: 让相关的领域(如医疗问诊系统)专家,让专家提供一些测试问题,根据模块给出的答案进行判断模型是否有效。
客观评估: 事先准备好评估模型使用的测试数据(该数据不要出现在训练集中),然后让训练好的模型去处理这批测试数据,根据得到的输出和数据集的标签计算得分。根据得分输出评估结果。
{
精度指标"predict_bleu-4": 29.408524999999997, 生成指标 问答和翻译场景,按照4个单词生成的指标"predict_model_preparation_time": 0.0055,"predict_rouge-1": 48.65773,"predict_rouge-2": 28.11527,"predict_rouge-l": 40.571055,性能指标"predict_runtime": 54.332, 总运行时间(秒)"predict_samples_per_second": 0.368, 每秒处理的样本出"predict_steps_per_second": 0.184。没秒处理的步骤数
}
这些指标用于评估模型性能,帮助优化。
这里我用的训练数据进行的评估,实际不应该这么操作,应该用专门的测试集进行评估
客观指标:不应该完全追求更高的分数,如果分数过高,会导致模型创造性更差,简单的理解就是分数越高,和我们样本数据更相近,因此创作力更差
命令
llamafactory-cli train \--stage sft \--model_name_or_path /mnt/workspace/LLaMA-Factory/merge-llama3-8-01 \--preprocessing_num_workers 16 \--finetuning_type lora \--quantization_method bnb \--template default \--flash_attn auto \--dataset_dir data \--eval_dataset identity,fintech \--cutoff_len 1024 \--max_samples 10 \--per_device_eval_batch_size 2 \--predict_with_generate True \--max_new_tokens 512 \--top_p 0.7 \--temperature 0.95 \--output_dir saves/Llama-3-8B/lora/eval_2025-04-19-16-47-22 \--trust_remote_code True \--do_predict True
3.7 Lora模型合并
当我们训练完成我们需要把lora模型和llama3模型进行合并,方便我们后面使用
因为我们训练完成后我们测试的是两个模型,一个base mode 和lora 模型
模型合并只能把适配base mode的lora模型进行合并
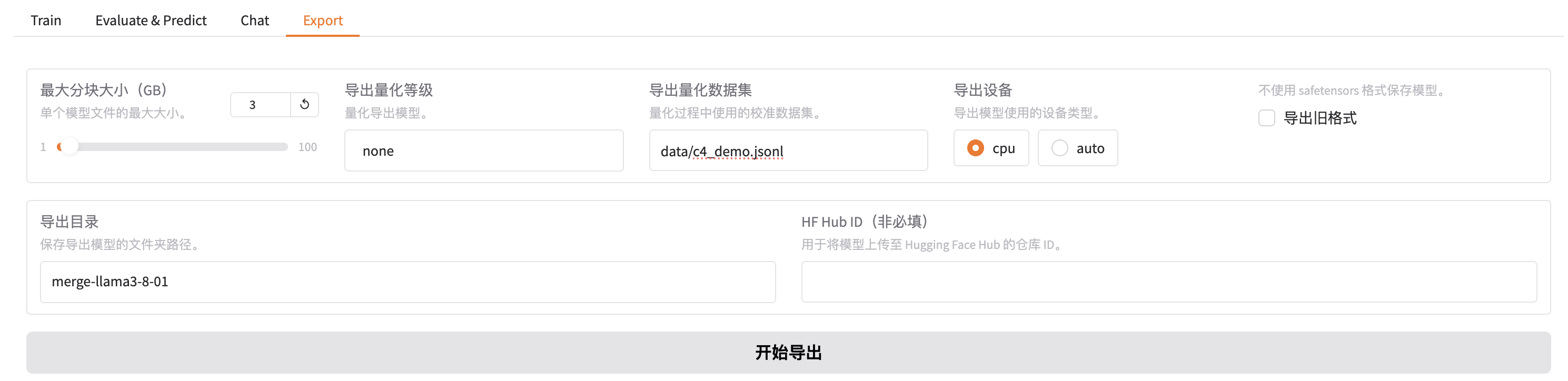
Lora模型合并
将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。注意:不要使用量化后的模型或 参数进行合并。
以下是 merge_llama3_lora_sft.yaml 的内容:
#model(基座模型)
model_name_or_path: /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct
#lora(自己训练的lora模型部分)
adapter_name_or_path: /root/autodl-tmp/LLaMA-Factory/saves/Llama-3-8B-Instruct/lora/train_2024-11-22-17-18-42
template: llama3
finetuning_type: lora#export
export_dir: /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-merged
export_size: 4
export_device: cuda
export_legacy_format: false
修改好配置文件 运行下面命令进行合并
llamafactory-cli export cust/merge_llama3_lora_sft.yaml
使用合并后的模型进行预测时,您不再需要加载 LoRA Adapter。
量化
模型量化是一种将模型参数从高精度(32 位浮点数,FP32)转换为低精度(如 16 位浮点数,FP16 或 8 位整数,INT8)的过程,用于加速推理过程和减少模型大小。
将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。注意:不要使用量化后的模型或 quantization_bit 参数进行合并。
这是一个牺牲精度换取性能的过程
3.8 llama.cpp
llama cpp 也可以完成大模型的部署,但是我们这里不用他的部署,不介绍了
将hf模型转换为GGUF
3.8.1 需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
git clone https://github.com/ggerganov/llama.cpp.git
pip install -r llama.cpp/requirements.txt
3.8.2 执行转换
# 如果不量化,保留模型的效果
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype f16 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf.gguf# 如果需要量化(加速并有损效果),直接执行下面脚本就可以
python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype q8_0 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf_q8_0.gguf
这里--outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。q4_0:这是最初的量化方案,使用4位精度。q4_1和q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景。q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较慢。q6_k和q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户。fp16和f32:不量化,保留原始精度。
安装ollama 不在详细介绍
安装
curl -fsSL https://ollama.com/install.sh | sh
启动 ollama
ollam start
ollama serve
ollam run LLamas 具体的大模型名称
3.8.3 创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下
#GGUF文件路径
FROM /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-gguf8.gguf
3.8.4 创建自定义模型
使用ollama create命令创建自定义模型
ollama create llama-3-8B-Instruct --file ./ModeFile
llama-3-8B-Instruct 这个名字是自己创建的
2.5 运行模型:
ollama run llama-3-8B-Instruct
我们就可以直接进行对话了和原来的一样的,不再赘述。