论文分享:【2024 CVPR】Vision-and-Language Navigation via Causal Learning
贡献
本文提出跨模态因果Transformer(GOAT),首创的基于因果推断范式的方法。Causal learning 的一个重要话题是解决out-of-distribtution,本文就是将其引入VLN任务中,使其不仅限于增加数据集的规模和多样性,还可通过因果学习来提高模型的泛化能力。
方法
一、概述
数据集总是会biased,这无法避免,为了摆脱创建数据集、识别bias,创建新的数据集的循环里,本文提出何不转向去发展能够对抗和减小bias的无偏模型呢?
现有的方法主要关注引入更多的输入(如更多物体信息或者深度信息),或者去构建一个全局图来表示环境。这些方法忽视了潜在的数据偏见和任务背后的本质因果逻辑。人类可以很好执行指令和导航就是因为可以无偏观察学习事物内在因果关系,有良好的类比关联能力。
本文就率先将因果推理能力引入VLN任务中。
那么,如何开发这种因果推断能力?虽然没有单一答案,作者建议利用干预的概念(出自《为什么:关于因果关系的新科学》一书) - 这是一种使用do-operator来减轻混杂因素(Confounders)带来的负面影响的技术。在这里,混杂因素是同时影响输入和结果的变量,它们会创造虚假的相关性和偏差。干预使研究人员能够减轻混杂因素的影响,使模型在数据拟合过程中能够把握事件的因果关系。然而,考虑到VLN是一项涉及跨模态输入和长期决策过程的复杂任务,识别潜在的混杂因素并通过网络学习应用干预来消除偏差是具有挑战性的。
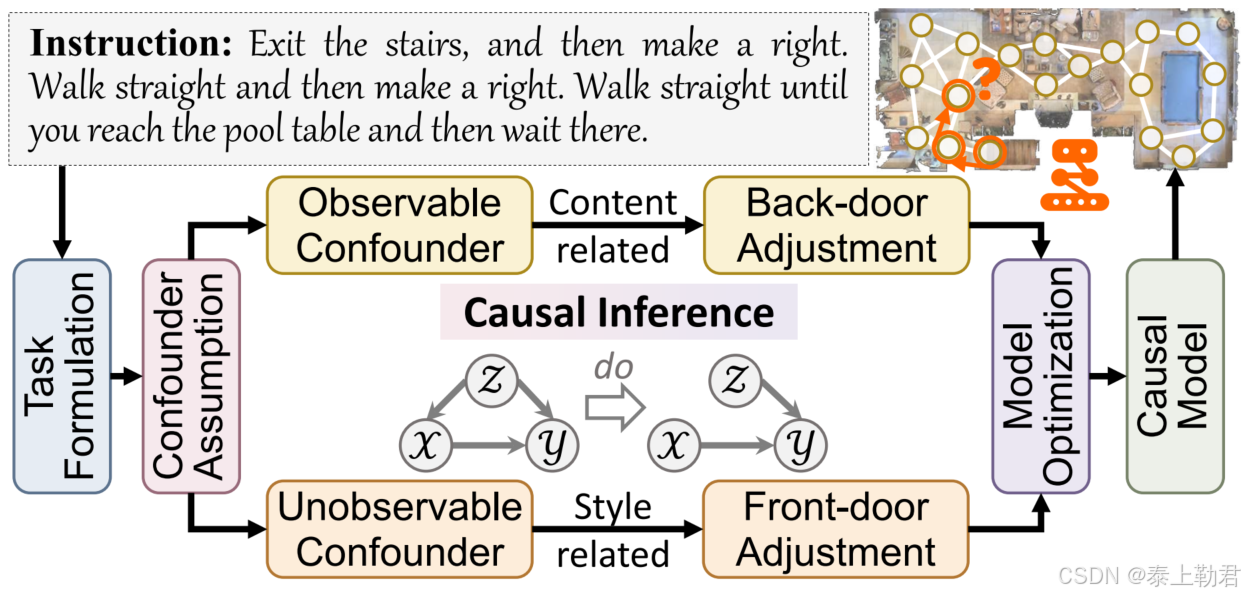
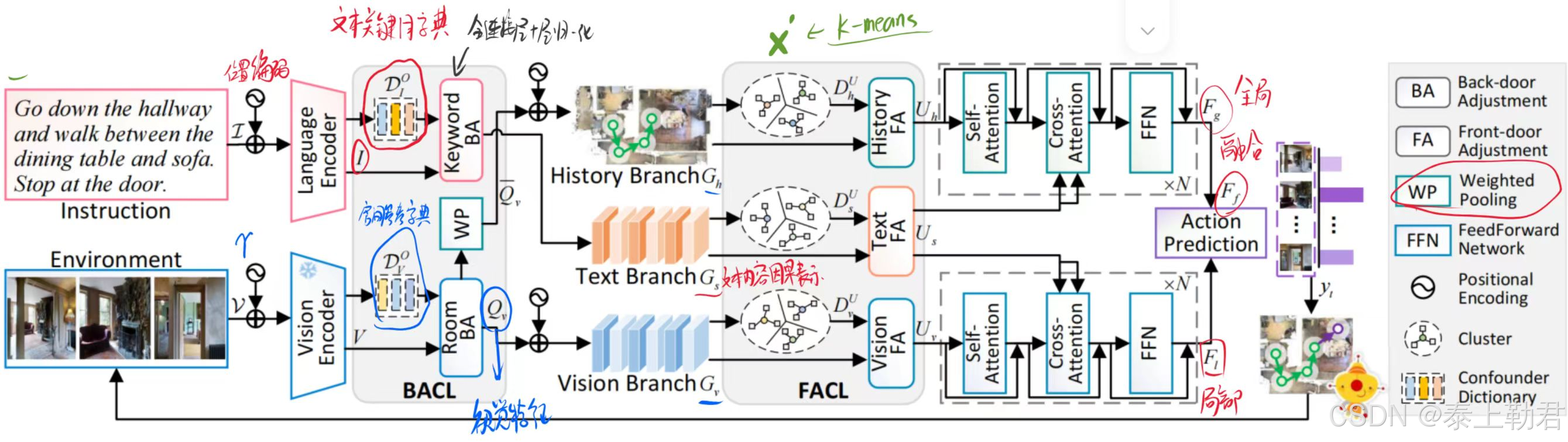
为了应对这个挑战,文本提出GOAT方法。如上图,作者将混杂因素分为可观察和不可观察的。
- 可观察的:内容相关,易于识别,如指令中关键词或者房间中的参考。
- 不可观察的:指难辩别但可能影响整个系统的复杂风格细微差别,如视觉中的装修风格、语言中的语句模式和历史中的轨迹趋势。
用上文所说的那本书中提及的 back-door adjustment (BACL)以及 front-door adjustment (FACL)来分别处理这两个混杂因素。此外,还涉及一个跨模态特征池化(CFP)模块来构建表示混杂因素的全局词典。使用了对比学习来优化CFP。
本文的贡献如下:
- 提出了一个统一的VLN结构因果模型,通过全面考虑隐藏在不同模态中的可观察和不可观察混杂因素。
- 提出BACL和FACL,使用后门和前门调整来实现端到端无偏差的跨模态干预和决策制定。
- 提出CFP,一个跨模态特征池化模块,旨在聚合序列特征以进行语义对齐和混杂因素字典构建。
- GOAT模型在多个VLN数据集(R2R、RxR、REVERIE和SOON)上展示了卓越的泛化能力,性能超过现有的最先进方法。提出了一个全面的因果学习流程以启发未来的研究。
二、预备知识
VLN的因果结构模型
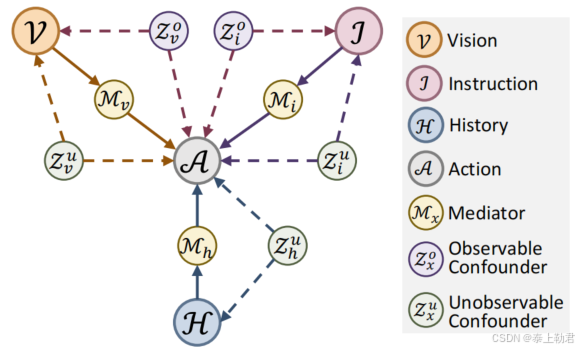
视觉观察 V \mathcal{V} V,语言指令 I \mathcal{I} I,决策历史 H \mathcal{H} H,和行动预测 A \mathcal{A} A。
为清晰起见,使用 X \mathcal{X} X表示输入( X = { V , I , H } \mathcal{X} = \{\mathcal{V}, \mathcal{I}, \mathcal{H}\} X={V,I,H})和 Y \mathcal{Y} Y表示输出( Y = A \mathcal{Y} = \mathcal{A} Y=A)。
混杂变量 Z \mathcal{Z} Z 。
在这个有向无环图中,起始点和结束点分别表示因果关系的起因和结果。
传统的VLN方法专注于学习可观测的关联 P ( Y ∣ X ) P(\mathcal{Y}|\mathcal{X}) P(Y∣X),忽略了通过 混杂变量 Z \mathcal{Z} Z 引入的歧义,这些混杂变量位于背门路径 X ← Z → Y \mathcal{X} \leftarrow \mathcal{Z} \rightarrow \mathcal{Y} X←Z→Y 中。混杂变量是影响因果关系的外部变量,例如,频繁出现的内容或特定属性。
- Z → X \mathcal{Z} \rightarrow \mathcal{X} Z→X出现是因为输入数据的联合概率不可避免地受到现实世界中数据收集和模拟时有限资源的影响。
- Z → Y \mathcal{Z} \rightarrow \mathcal{Y} Z→Y存在,因为收集的环境、标注的指令或样本轨迹也会影响行动分布的概率。
这些混杂因素的联系在训练过程中提供了虚假的捷径,在新的情况下可能会造成损害。
- 可观察混杂变量包括那些可以被识别的实例(例如,房间参考 z v o z_v^o zvo和指导关键词 z i o z_i^o zio)
- 不可观察混杂变量由复杂的模式和与风格相关的元素组成,这些元素在定性上很难描述(例如,视觉中的装饰风格 z v u z_v^u zvu,语言中的句子模式 z i u z_i^u ziu,以及历史中的轨迹趋势 z h u z_h^u zhu)。
由于无法显式地建模不可观察的混杂变量 Z u \mathcal{Z}^u Zu,因此在 X \mathcal{X} X和 Y \mathcal{Y} Y之间插入了额外的中介变量 M \mathcal{M} M,以建立前门路径 X → M → Y \mathcal{X} \rightarrow \mathcal{M} \rightarrow \mathcal{Y} X→M→Y。
三、方法
Observable Causal Inference
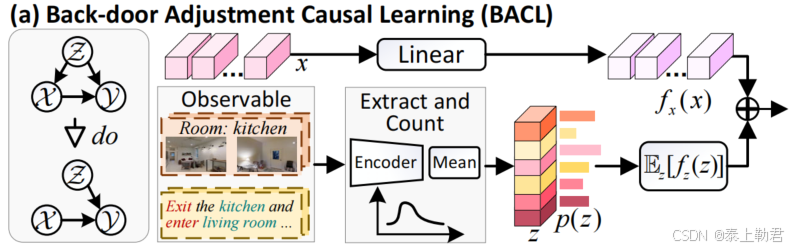
- Back-door Adjustment Causal Learning (BACL)
贝叶斯定理在典型的观测似然性中使用,表达式为:
P ( Y ∣ X ) = ∑ z P ( Y ∣ X , z ) P ( z ∣ X ) ‾ P(\mathcal{Y} \mid \mathcal{X}) = \sum_{\mathcal{z}} P(\mathcal{Y} \mid \mathcal{X}, \mathcal{z}) \underline{P(\mathcal{z} \mid \mathcal{X})} P(Y∣X)=z∑P(Y∣X,z)P(z∣X)
其中, P ( Y ∣ X ) P(\mathcal{Y} \mid \mathcal{X}) P(Y∣X) 是给定 X \mathcal{X} X 时 Y \mathcal{Y} Y 的概率。而 P ( z ∣ X ) P(\mathcal{z} \mid \mathcal{X}) P(z∣X) 是给定 X \mathcal{X} X 时 z \mathcal{z} z 的条件概率,这个公式可能引入bias,因此需要进行进一步的调整来进行因果分析。
操作符(Do-operator):该术语指的是在因果推断中常用的干预方法(通常表示为 d o ( X ) do(\mathcal{X}) do(X))。它提供了有科学依据的技术,用于通过切断 Z \mathcal{Z} Z 和 X \mathcal{X} X 之间的背门路径来确定因果效应。
根据因果推断中的不变性和独立性规则,下面的公式展示了如何调整因果效应。
P ( Y ∣ d o ( X ) ) = ∑ z P ( Y ∣ d o ( X ) , z ) P ( z ∣ d o ( X ) ) = ∑ z P ( Y ∣ X , z ) P ( z ) ‾ (1,2) \begin{aligned} P(\mathcal{Y} \mid do(\mathcal{X})) &= \sum_{\mathcal{z}} P(\mathcal{Y} \mid do(\mathcal{X}), \mathcal{z}) P(\mathcal{z} \mid do(\mathcal{X})) \\ &= \sum_{\mathcal{z}} P(\mathcal{Y} \mid \mathcal{X}, \mathcal{z}) \underline{P(\mathcal{z})} \end{aligned} \tag{1,2} P(Y∣do(X))=z∑P(Y∣do(X),z)P(z∣do(X))=z∑P(Y∣X,z)P(z)(1,2)
**这种干预是通过阻塞背门路径 Z → X \mathcal{Z} \rightarrow \mathcal{X} Z→X实现的,使得 X \mathcal{X} X有更多机整合与因果相关的因素用于预测。**过去在VQA等领域直接使用 NWGM近似 方法直接追求因果学习来获取最终的输出,但是这些方法的限制在于它们只对网络的最后 Softmax 层进行了干预,忽略了浅层中可能存在的biased特征。
条件概率是隐含在训练好的神经网络进行的模式识别当中的,作者讲因果假设的目标效应释放到learned features而不仅仅是outputs。获得的无偏的特征就会得到无偏的预测。
那具体的网络模块可以公式化为线性层 f ( x , z ) = f x ( x ) + f z ( z ) f(x, z)=f_x(x) + f_z(z) f(x,z)=fx(x)+fz(z),公式(2)的具体实现可为:
B ( x , z ) = E z [ f ( x , z ) ] (3) \mathcal{B}(x, z) = \mathbb{E}_z[f(x, z)] \tag{3} B(x,z)=Ez[f(x,z)](3)
通过公式(3),公式变为: f x ( x ) + E z [ f z ( z ) ] f_x(x) + \mathbb{E}_z[f_z(z)] fx(x)+Ez[fz(z)],求解 E z [ f z ( z ) ] \mathbb{E}_z[f_z(z)] Ez[fz(z)] 有两个常见的方法:基于统计的方法和基于注意力的方法。
-
基于统计的方法:通过对每个 z i z_i zi 进行加权求和来计算
E z [ f z ( z ) ] = ∑ i ∣ z i ∣ ∑ j ∣ z j ∣ f z ( z i ) (4) \mathbb{E}_z[f_z(z)] = \sum_i \frac{|z_i|}{\sum_j |z_j|} f_z(z_i) \tag{4} Ez[fz(z)]=i∑∑j∣zj∣∣zi∣fz(zi)(4) -
基于注意力的方法:通过对每个 z i z_i zi 的加权指数求和来计算
E z [ f z ( z ) ] = ∑ i exp ( h z i T ) ∑ j exp ( h z j T ) f z ( z i ) (5) \mathbb{E}_z[f_z(z)] = \sum_i \frac{\exp(h z_i^T)}{\sum_j \exp(h z_j^T)} f_z(z_i) \tag{5} Ez[fz(z)]=i∑∑jexp(hzjT)exp(hziT)fz(zi)(5)
其中 ∣ z i ∣ |z_i| ∣zi∣ 表示属于训练集中第 i i i 类的 z z z 的数量, h h h 代表隐藏层特征。
- BACL in Text Content
在VLN指令(例如“退出办公室,右转进入厨房”)中,方向(如“退出”和“右转”)和地标(如“办公室”和“厨房”)是重要的指导元素,这些词语在指令构建和动作分配中扮演着重要角色。这些词语常常是指令错误和动作分布的根源,因此它们被认为是可观察的混淆因子。
首先设定文本关键词字典:
D I O = [ z i , 1 o , z i , 2 o , … , z i , K o ] D_I^O = [z^o_{i,1}, z^o_{i,2}, \dots, z^o_{i,K}] DIO=[zi,1o,zi,2o,…,zi,Ko]
其中 K K K 类别用于存储混淆因子特征。方向词和地标词通过其词性标签进行提取。
使用预训练的RoBERTa模型来获取每个提取的单词/token f i o f^o_{i} fio 的特征表示。由于同一个词在不同句子中可能有不同的特征,计算每个关键词的平均特征表示:
z i , n o = 1 ∣ z i , n o ∣ ∑ j f i , n , j o z^o_{i,n} = \frac{1}{|z^o_{i,n}|} \sum_j f^o_{i,n,j} zi,no=∣zi,no∣1j∑fi,n,jo
文本内容的因果表示 G s G_s Gs 的计算公式如下:
I = RoBERTa ( ψ t ( I ) + ψ t ( P ) ) , Z k = LN ( φ k ( D I O ) ) (6) I = \text{RoBERTa}(\psi_t(\mathcal{I}) + \psi_t(\mathcal{P})), \quad Z_k = \text{LN}(\varphi_k(D_I^O)) \tag{6} I=RoBERTa(ψt(I)+ψt(P)),Zk=LN(φk(DIO))(6)
G s = LN ( φ i ( B ( I , Z k ) ) ) (7) G_s = \text{LN}(\varphi_i(\mathcal{B}(I, Z_k))) \tag{7} Gs=LN(φi(B(I,Zk)))(7)
其中, ψ ( ⋅ ) \psi(\cdot) ψ(⋅) 和 φ ( ⋅ ) \varphi(\cdot) φ(⋅) 分别表示可学习的嵌入层和全连接层。绝对位置编码 P \mathcal{P} P 用来表示位置的信息,而层归一化(LN)用于稳定训练过程中的隐藏状态。
这样做直观上来看,文本关键词字典是从整个训练集的指令上进行获取的,然后和指令一同参与编码,从而引入了可见的混淆因素,即动作分布和地标分布。
- BACL in Vision Content
图像包含的房间信息被认为是可观察的混淆因子。使用了 CLIP 模型提取图像特征。由于房间标签并未直接提供,使用预训练的VQA模型 BLIP 来捕获每张图像的房间信息,BLIP 模型通过查询固定的问题“这是什么样的房间?”来获得图像中的房间类别信息。
通过 BLIP 模型获取每张图像的房间类型后,计算每个房间类型的平均值,形成一个视觉房间参考字典:
D V O = [ z v , 1 o , z v , 2 o , … , z v , M o ] D^O_V = [z^o_{v,1}, z^o_{v,2}, \dots, z^o_{v,M}] DVO=[zv,1o,zv,2o,…,zv,Mo]
其中 M M M 是房间类型的数量。
进一步构建一个矩阵 γ \gamma γ 来表示每个图像相对于智能体的位置变化方向。该矩阵的计算公式为:
γ = [ ( s i n θ i , c o s θ i , s i n η i , c o s η i ) ] i = 1 36 \gamma = [(sin\theta_i, cos\theta_i, sin\eta_i, cos\eta_i)]_{i=1}^{36} γ=[(sinθi,cosθi,sinηi,cosηi)]i=136
其中 θ \theta θ 和 η \eta η 分别表示图像相对于智能体的方位角和俯仰角。如果是目标导向的任务,额外的目标物体特征会与图像特征一起进行拼接。
使用一个两层的Transformer编码器来捕获空间依赖性,并生成最终的视觉特征。
整个过程通过以下公式描述:
V = CLIP ( V ) , Z r = LN ( φ r ( D V O ) ) (8) V = \text{CLIP}(\mathcal{V}), \quad Z_r = \text{LN}(\varphi_r(D^O_V)) \tag{8} V=CLIP(V),Zr=LN(φr(DVO))(8)
V v = LN ( φ v ( B ( V , Z r ) ) ) (9) V_v = \text{LN}(\varphi_v(\mathcal{B}(V, Z_r))) \tag{9} Vv=LN(φv(B(V,Zr)))(9)
Q v = Trans ( V v + ψ d ( γ ) ) (10) Q_v = \text{Trans}(V_v + \psi_d(\gamma)) \tag{10} Qv=Trans(Vv+ψd(γ))(10)
Unobservable Causal Inference
- Front-door Adjustment Causal Learning (FACL)
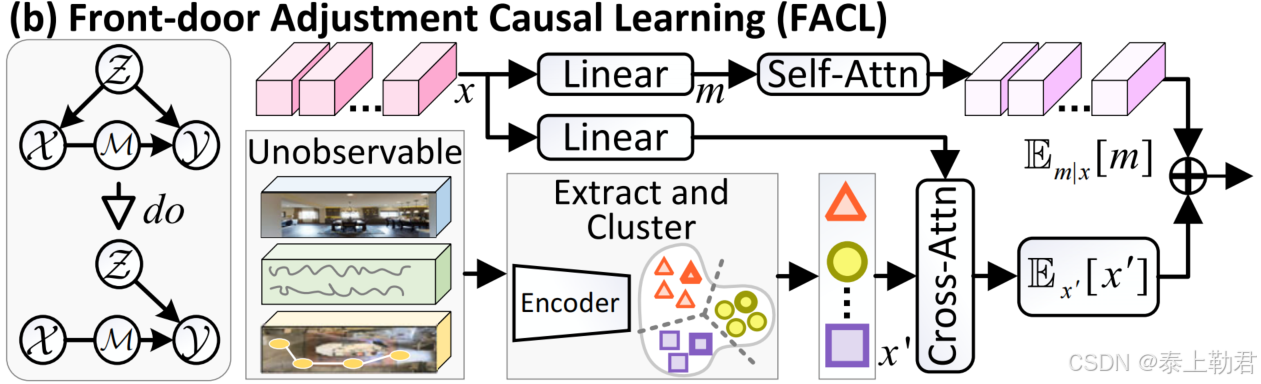
对于无法观测的混杂因素采用前门调整技术来解决。在前门路径上 X → M → Y \mathcal{X} \rightarrow \mathcal{M} \rightarrow \mathcal{Y} X→M→Y插入了一个额外的中介 M \mathcal{M} M。
因此模型的推理可被表示成两个部分:
- 特征选择器 X → M \mathcal{X} \rightarrow \mathcal{M} X→M
- 动作预测器 M → Y \mathcal{M} \rightarrow \mathcal{Y} M→Y
在VLN中,基于注意力的模型 P ( Y ∣ X ) = ∑ m P ( Y ∣ m ) P ( m ∣ X ) P(\mathcal{Y}|\mathcal{X}) = \sum_m P(\mathcal{Y}|m) P(m|\mathcal{X}) P(Y∣X)=∑mP(Y∣m)P(m∣X)选择输入中的关键区域 M \mathcal{M} M 来预测后续的行动 Y \mathcal{Y} Y, 这里 m m m 是从输入中选择的关键区域。
为了消除未观察到的混淆因子 Z \mathcal{Z} Z 带来的虚假相关性,模型同时对输入 X \mathcal{X} X 和中介 M \mathcal{M} M 做了一个 “do-operator” 操作。
P ( Y ∣ d o ( X ) ) = ∑ m P ( Y ∣ d o ( m ) ) P ( m ∣ d o ( X ) ) = ∑ x ′ P ( x ′ ) ∑ m P ( Y ∣ m , x ′ ) P ( m ∣ X ) = E x ′ E m ∣ x [ P ( Y ∣ x ′ , m ) ] \begin{align} P(\mathcal{Y}|do(\mathcal{X})) &= \sum_m P(\mathcal{Y}|do(m)) P(m|do(\mathcal{X}))\tag{11} \\ &= \sum_{x'} P(x') \sum_m P(\mathcal{Y}|m, x') P(m|\mathcal{X}) \tag{12}\\ &= \mathbb{E}_{x'} \mathbb{E}_{m|\mathcal{x}} \left[ P(\mathcal{Y}|x', m) \right] \tag{13} \end{align} P(Y∣do(X))=m∑P(Y∣do(m))P(m∣do(X))=x′∑P(x′)m∑P(Y∣m,x′)P(m∣X)=Ex′Em∣x[P(Y∣x′,m)](11)(12)(13)
x ′ x^′ x′ 表示整个特征空间的的潜在输入样本,不同于当前的输入 X = x \mathcal{X}=x X=x.
m \mathbf{m} m 来表示由特征提取器作用于当前输入所获得的采样特征,而 x ′ \mathbf{x'} x′ 则表示由基于 K-means 的特征选择器从整个训练样本中随机采样的交叉采样特征。
基于线性映射模型,公式(13)变为: E m ∣ x [ m ] + E x ′ [ x ′ ] \mathbb{E}_{m|\mathcal{x}}[\mathbf{m}] + \mathbb{E}_{x'}[\mathcal{\mathbf{x'}}] Em∣x[m]+Ex′[x′]。这里, E m ∣ x [ m ] \mathbb{E}_{m|\mathcal{x}}[\mathbf{m}] Em∣x[m] 和 E x ′ [ x ′ ] \mathbb{E}_{x'}[\mathcal{\mathbf{x'}}] Ex′[x′] 分别表示在不同条件下,基于当前输入和交叉输入采样特征的期望值。这个期望值计算很复杂难以通过一个闭式解来得到(即一个简单的数学公式来表示),因此用查询机制(query mechanism)来估算。
查询机制将输入 x \mathcal{x} x 传递到两个查询集:
- g 1 = q 1 ( x ) \mathcal{g}_1 = q_1(\mathcal{x}) g1=q1(x)
- g 2 = q 2 ( x ) g_2 = q_2(\mathcal{x}) g2=q2(x)
这两个查询集分别将输入映射到不同的查询空间,接下来,前门调整(front-door adjustment)通过如下方式进行近似:
E x ′ [ x ′ ] ≈ ∑ x ′ P ( x ′ ∣ g 1 ) x ′ = ∑ i exp ( g 1 x i ′ T ) ∑ j exp ( g 1 x j ′ T ) x i ′ (14) \mathbb{E}_{x'}[\mathcal{x}'] \approx \sum_{x'} P(x'|g_1)\mathcal{x}' = \sum_i \frac{\exp(g_1 x_i^{'T})}{\sum_j \exp(g_1 x_j^{'T})} x_i' \tag{14} Ex′[x′]≈x′∑P(x′∣g1)x′=i∑∑jexp(g1xj′T)exp(g1xi′T)xi′(14)
这表示对输入 x \mathcal{x} x 进行查询集 g 1 g_1 g1 的调整,其中 P ( x ′ ∣ g 1 ) P(x'|g_1) P(x′∣g1) 是给定查询集 g 1 g_1 g1 时,输入 x \mathcal{x} x 的分布,最终通过加权求和得到 x ′ \mathcal{x}' x′ 的期望。
E m ∣ x [ m ] ≈ ∑ m P ( m ∣ g 2 ) m = ∑ i exp ( g 2 m i T ) ∑ j exp ( g 2 m j T ) m i (15) \mathbb{E}_{m|\mathcal{x}}[m] \approx \sum_m P(m|g_2)m = \sum_i \frac{\exp(g_2 m_i^T)}{\sum_j \exp(g_2 m_j^T)} m_i \tag{15} Em∣x[m]≈m∑P(m∣g2)m=i∑∑jexp(g2mjT)exp(g2miT)mi(15)
类似地,这表示对 m m m 进行查询集 g 2 g_2 g2 的调整,通过给定查询集 g 2 g_2 g2 估算出 m m m 的期望。
该过程可以通过使用多头注意力机制实现,从而将因果调整无缝集成到现有的基于Transformer的框架中,只需要进行最小的修改。
F ( x , x ′ ) = E x ′ [ x ′ ] + E m ∣ x [ m ] (16) \mathcal{F}(x, x') = \mathbb{E}_{x'}[\mathbf{x'}] + \mathbb{E}_{m|x}[\mathbf{m}] \tag{16} F(x,x′)=Ex′[x′]+Em∣x[m](16)
- FACL in Text, Vision, and History
考虑到VLN的特性,本文提出从三个输入类型(视觉、语言和历史)中消除不可观测的混淆因子。首先,基于图方法,构建了视觉序列 G v = { [ S T O P ] , [ M E M ] , Q v } G_v = \{[STOP], [MEM], Q_v\} Gv={[STOP],[MEM],Qv} 和历史序列 G h = { [ S T O P ] , [ M E M ] , { Q ‾ t } t = 1 T } G_h = \{[STOP], [MEM], \{\overline{Q}_t\}_{t=1}^T\} Gh={[STOP],[MEM],{Qt}t=1T},通过增加额外的 token 来表示停止和递归记忆状态。 Q ‾ t \overline{Q}_t Qt 表示在第 t t t 步时全景特征学习权重之和。
为了压缩特征序列并生成全局特征 x ′ \mathbf{x}' x′ 以用于交叉采样,本文提出了CFP模块(下一部分提到的),并使用注意力池化机制构建视觉、历史和指令因果词典( D v U , D h U , D s U D_v^U, D_h^U, D_s^U DvU,DhU,DsU )。
接下来,基于公式(16),计算因果增强特征 R v , R h , R s R_v, R_h, R_s Rv,Rh,Rs。
R v = F ( G v , D v U ) , R h = F ( G h , D h U ) , R s = F ( G s , D s U ) (17) R_v = \mathcal{F}(G_v, D_v^U), \quad R_h = \mathcal{F}(G_h, D_h^U), \quad R_s = \mathcal{F}(G_s, D_s^U) \tag{17} Rv=F(Gv,DvU),Rh=F(Gh,DhU),Rs=F(Gs,DsU)(17)
此外,为了提高学习过程的稳定性,本文引入了自适应门融合(AGF)方法,通过将不同模态的因果增强特征与原始上下文特征融合,增强模型的稳定性。
公式(18)和(19)表示了如何通过Sigmoid函数和逐元素相乘来融合因果增强特征与原始特征:
权重因子: ω x = δ ( R x W x + G x W g + b ) (18) 权重因子:\omega_x = \delta(R_x W_x + G_x W_g + b) \tag{18} 权重因子:ωx=δ(RxWx+GxWg+b)(18)
融合特征: U x = ω x ⊙ R x + ( 1 − ω x ) ⊙ G x (19) 融合特征:U_x = \omega_x \odot R_x + (1 - \omega_x) \odot G_x \tag{19} 融合特征:Ux=ωx⊙Rx+(1−ωx)⊙Gx(19)
接下来,使用从METER中获取的交叉注意力编码器 C C C 提取得到局部特征 F l F_l Fl 和全局特征 F g F_g Fg:
F l = C ( U v , U s , U s ) , F g = C ( U h , U s , U s ) (20) F_l = \mathcal{C}(U_v, U_s, U_s), \quad F_g = \mathcal{C}(U_h, U_s, U_s) \tag{20} Fl=C(Uv,Us,Us),Fg=C(Uh,Us,Us)(20)
然后进行动态融合,在用全局和局部融合后的特征进行动作预测(softmax):
F f = D F ( F l , F g ) , y t = S F ( F f ) (21) F_f = \mathcal{DF}(F_l, F_g), \quad y_t = \mathcal{SF}(F_f) \tag{21} Ff=DF(Fl,Fg),yt=SF(Ff)(21)
使用交叉熵损失函数来优化模型:
L c e = ∑ t = 1 T − log P ( y t ∗ ∣ I , V t , H 1 : t − 1 ) (22) \mathcal{L}_{ce} = \sum_{t=1}^T - \log P(y_t^* | \mathcal{I}, \mathcal{V}_t, \mathcal{H}_{1:t-1}) \tag{22} Lce=t=1∑T−logP(yt∗∣I,Vt,H1:t−1)(22)
Cross-modal Feature Pooling
在VLN中实现前门调整的一个挑战是构建高效的字典,用于从长序列中提取全局特征。这需要将不同长度的顺序特征压缩到一个统一的特征空间中,以有效表示每个样本。
给定 H ∈ R L × d h H \in \mathbb{R}^{L \times d_h} H∈RL×dh 为序列特征,使用以下的注意力池化方法来有效地压缩序列长度:
A = T ( H ) , α = S F ( A W a ) , H ‾ = T ( α T H ) (23) A = \mathcal{T}(H), \quad \alpha = \mathcal{SF}(A W_a), \quad \overline{H} = \mathcal{T}(\alpha^T H) \tag{23} A=T(H),α=SF(AWa),H=T(αTH)(23)
- 其中, T \mathcal{T} T 表示双曲正切激活函数(Tanh),
- W a ∈ R d h × 1 W_a \in \mathbb{R}^{d_h \times 1} Wa∈Rdh×1 是可学习的注意力矩阵
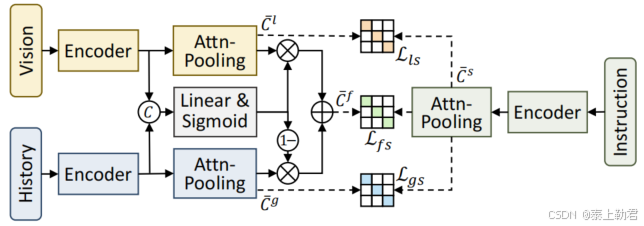
对于视觉、历史、局部-全局融合和文本特征,使用了一个 Transformer 层作为编码器,随后通过注意力池化来获得平坦化的特征 C ‾ l , C ‾ g , C ‾ f , C ‾ S \overline{C}^l, \overline{C}^g, \overline{C}^f, \overline{C}^S Cl,Cg,Cf,CS,分别对应视觉、历史、局部全局融合和文本特征。
接下来,采用对比学习来优化这个跨模态特征池化(CFP)模块,同时提高不同模态的语义对齐度。对比损失函数 L l s \mathcal{L}_{ls} Lls 定义为:
L l s = − 1 2 B ∑ j = 1 B log ( exp ( ⟨ C ‾ j l , C ‾ j s ⟩ / t ) ∑ k = 1 B exp ( ⟨ C ‾ j l , C ‾ k s ⟩ / t ) ) − 1 2 B ∑ k = 1 B log ( exp ( ⟨ C ‾ k l , C ‾ k s ⟩ / t ) ∑ j = 1 B exp ( ⟨ C ‾ j l , C ‾ k s ⟩ / t ) ) (24) \begin{align} \mathcal{L}_{ls} = &- \frac{1}{2B} \sum_{j=1}^{B} \log \left( \frac{\exp(\langle \overline{C}_j^l, \overline{C}_j^s \rangle / t)}{\sum_{k=1}^{B} \exp(\langle \overline{C}_j^l, \overline{C}_k^s \rangle / t)} \right) \\ & - \frac{1}{2B} \sum_{k=1}^{B} \log \left( \frac{\exp(\langle \overline{C}_k^l, \overline{C}_k^s \rangle / t)}{\sum_{j=1}^{B} \exp(\langle \overline{C}_j^l, \overline{C}_k^s \rangle / t)} \right) \end{align} \tag{24} Lls=−2B1j=1∑Blog(∑k=1Bexp(⟨Cjl,Cks⟩/t)exp(⟨Cjl,Cjs⟩/t))−2B1k=1∑Blog ∑j=1Bexp(⟨Cjl,Cks⟩/t)exp(⟨Ckl,Cks⟩/t) (24)
其中, B B B 为批量大小, t t t 为温度参数, C ‾ j l , C ‾ j s \overline{C}_j^l, \overline{C}_j^s Cjl,Cjs 分别为视觉和文本特征的表示。该公式衡量了在视觉-文本对比学习任务中的相似度。
类似地,使用 L g s \mathcal{L}_{gs} Lgs 和 L f s \mathcal{L}_{fs} Lfs 计算其他类型的对比损失,通过替换 C ‾ l \overline{C}^l Cl 为 C ‾ g \overline{C}^g Cg 和 C ‾ f \overline{C}^f Cf 来计算。最终,跨模态特征池化损失 L C F P \mathcal{L}_{CFP} LCFP 是所有对比损失的总和:
L C F P = L l s + L g s + L f s \mathcal{L}_{CFP} = \mathcal{L}_{ls} + \mathcal{L}_{gs} + \mathcal{L}_{fs} LCFP=Lls+Lgs+Lfs
这里, L C F P \mathcal{L}_{CFP} LCFP 综合了视觉、语言和历史模态的对比损失,帮助模型更好地学习跨模态的表示。
为了使网络更好地适应 VLN 的特性,并促进前门混淆因子字典的构建,模型在预训练阶段使用其他辅助任务与 CFP 模块共同训练。训练好的注意力池化模块将用于提取不同模态的全局特征。
在微调阶段,采用 BACL 和 FACL 方法,并结合已经建立的干预字典来进一步优化模型。
Causal Learning Pipeline
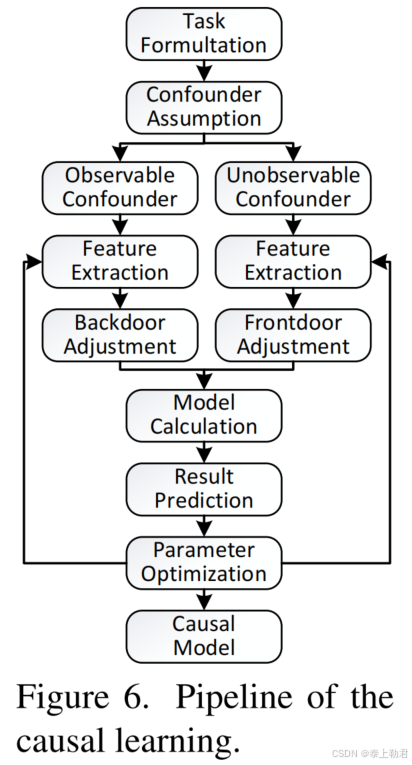
作者总结了一个因果学习流程。
首先,从「任务制定」(Task Formulation)开始,在此阶段精确定义具体任务及其目标。接着,显性混杂因素(Observable Confounder)与隐性混杂因素(Unobservable Confounder)被明确假设。针对这些混杂因素,可根据任务具体需求,同时或先后采用后门调整(Backdoor Adjustment)和前门调整(Frontdoor Adjustment)策略。然后,流程进入模型计算(Model Calculation)与结果预测(Result Prediction)阶段。在整个网络优化过程中,网络参数与混杂因素的特征都会被持续更新。最终,通过这一迭代过程,我们得以构建出一个能够生成无偏特征的稳健因果模型(Causal Model),从而提升 AI 系统的泛化能力。