4399后端一面

golang 协程实现
Golang 线程和协程的区别
备注:需要区分进程、线程(内核级线程)、协程(用户级线程)三个概念。
进程、线程 和 协程 之间概念的区别
对于 进程、线程,都是有内核进行调度,有 CPU 时间片的概念,进行 抢占式调度(有多种调度算法)
对于 协程(用户级线程),这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行 协作式调度,需要协程自己主动把控制权转让出去之后,其他协程才能被执行到。
goroutine 和协程区别
本质上,goroutine 就是协程。 不同的是,Golang 在 runtime、系统调用等多方面对 goroutine 调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的CPU § 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。Golang 的一大特色就是从语言层面原生支持协程,在函数或者方法前面加 go关键字就可创建一个协程。
其他方面的比较
1. 内存消耗方面
每个 goroutine (协程) 默认占用内存远比 Java 、C 的线程少。
goroutine:2KB
线程:8MB
2. 线程和 goroutine 切换调度开销方面
线程/goroutine 切换开销方面,goroutine 远比线程小
线程:涉及模式切换(从用户态切换到内核态)、16个寄存器、PC、SP…等寄存器的刷新等。
goroutine:只有三个寄存器的值修改 - PC / SP / DX.
协程底层实现原理
线程是操作系统的内核对象,多线程编程时,如果线程数过多,就会导致频繁的上下文切换,这些 cpu 时间是一个额外的耗费。所以在一些高并发的网络服务器编程中,使用一个线程服务一个 socket 连接是很不明智的。于是操作系统提供了基于事件模式的异步编程模型。用少量的线程来服务大量的网络连接和I/O操作。但是采用异步和基于事件的编程模型,复杂化了程序代码的编写,非常容易出错。因为线程穿插,也提高排查错误的难度。
协程,是在应用层模拟的线程,他避免了上下文切换的额外耗费,兼顾了多线程的优点。简化了高并发程序的复杂度。举个例子,一个高并发的网络服务器,每一个socket连接进来,服务器用一个协程来对他进行服务。代码非常清晰。而且兼顾了性能。
那么,协程是怎么实现的呢?
他和线程的原理是一样的,当 a线程 切换到 b线程 的时候,需要将 a线程 的相关执行进度压入栈,然后将 b线程 的执行进度出栈,进入 b线程 的执行序列。协程只不过是在 应用层 实现这一点。但是,协程并不是由操作系统调度的,而且应用程序也没有能力和权限执行 cpu 调度。怎么解决这个问题?
答案是,**协程是基于线程的。内部实现上,维护了一组数据结构和 n 个线程,真正的执行还是线程,协程执行的代码被扔进一个待执行队列中,由这 n 个线程从队列中拉出来执行。(GMP)**这就解决了协程的执行问题。那么协程是怎么切换的呢?答案是:golang 对各种 io函数 进行了封装,这些封装的函数提供给应用程序使用,而其内部调用了操作系统的异步 io函数,当这些异步函数返回 busy 或 bloking 时,golang 利用这个时机将现有的执行序列压栈,让线程去拉另外一个协程的代码来执行,基本原理就是这样,利用并封装了操作系统的异步函数。包括 linux 的 epoll、select 和 windows 的 iocp、event 等。
由于golang是从编译器和语言基础库多个层面对协程做了实现,所以,golang的协程是目前各类有协程概念的语言中实现的最完整和成熟的。十万个协程同时运行也毫无压力。关键我们不会这么写代码。但是总体而言,程序员可以在编写 golang 代码的时候,可以更多的关注业务逻辑的实现,更少的在这些关键的基础构件上耗费太多精力。
编写协程时需要关注哪些问题?
1. 并发安全
数据竞争:确保对共享数据的访问是安全的。可使用**互斥锁(sync.Mutex)或通道(channel)**来避免数据竞争。
使用Channel同步:通过通信共享内存(而非共享内存来通信)。
互斥锁(Mutex):使用sync.Mutex或sync.RWMutex保护临界区。
原子操作:对简单类型使用sync/atomic包。
启用竞态检测:编译或运行时添加-race标志(如go run -race main.go)。
2. 错误处理
错误传递:确保在协程中处理错误,并通过通道或其他机制将错误信息传递给主协程或其他协程。
3. 资源管理
协程泄漏:避免创建过多的协程,确保在不需要时及时退出,防止协程泄漏。
使用 sync.WaitGroup:在主程序中等待协程完成,避免程序过早退出。
4. 死锁
避免死锁:确保对锁的获取和释放是有序的,避免两个或多个协程互相等待,导致程序挂起。
5. 通道管理
关闭通道:在不再使用通道时,应关闭通道,以避免资源浪费和潜在的死锁。
选择结构:使用 select 语句可以在多个通道之间选择,有效处理多个并发操作。
6. 调度和性能
**合理的协程数量:**尽量避免创建过多协程,根据应用的需求合理调整协程数量,确保性能。
避免频繁切换:频繁的上下文切换可能会影响性能,尽量将相关任务放在同一个协程中执行。
7. 上下文管理
使用 context 包:在协程中使用 context.Context 可以管理协程的生命周期,处理取消信号以及超时。
Go语言中,有哪些方案可以保证并发安全?
- 互斥锁(Mutex)
适用场景:保护临界区(共享变量、复杂数据结构等)。
实现方式:使用sync.Mutex或sync.RWMutex(读写锁)。
import "sync"type SafeCounter struct {mu sync.Mutexcount int
}func (c *SafeCounter) Increment() {c.mu.Lock()defer c.mu.Unlock() // 确保解锁c.count++
}func (c *SafeCounter) Value() int {c.mu.Lock()defer c.mu.Unlock()return c.count
}
关键点:
用defer确保锁释放,避免死锁。
读写分离时,优先使用RWMutex(读多写少场景)。
- 通道(Channel)
适用场景:协程间通信,传递数据所有权,避免共享内存。
实现方式:通过Channel同步操作,遵循“通过通信共享内存”原则。
func worker(taskCh <-chan int, resultCh chan<- int) {for task := range taskCh {resultCh <- task * 2 // 处理任务并发送结果}
}func main() {taskCh := make(chan int, 10)resultCh := make(chan int, 10)// 启动3个worker协程for i := 0; i < 3; i++ {go worker(taskCh, resultCh)}// 发送任务go func() {for i := 0; i < 10; i++ {taskCh <- i}close(taskCh) // 明确关闭Channel}()// 接收结果for i := 0; i < 10; i++ {fmt.Println(<-resultCh)}
}
关键点:
明确Channel的关闭责任(通常由发送方关闭)。
使用select处理多路通信或超时。
- 原子操作(Atomic)
适用场景:简单类型的并发安全操作(如计数器)。
实现方式:使用sync/atomic包提供的原子函数。
import "sync/atomic"var counter int64func atomicIncrement() {atomic.AddInt64(&counter, 1)
}func atomicValue() int64 {return atomic.LoadInt64(&counter)
}
优点:无锁操作,性能极高。
限制:仅支持基本类型(int32, int64, uintptr等)。
- 协程同步(WaitGroup)
适用场景:等待一组协程完成任务。
实现方式:使用sync.WaitGroup管理协程生命周期。
func processBatch(data []int) {var wg sync.WaitGroupwg.Add(len(data)) // 设置等待的协程数for _, item := range data {go func(item int) {defer wg.Done() // 确保计数器减1process(item)}(item)}wg.Wait() // 阻塞直到所有协程完成
}
注意:Add()必须在协程外调用,避免竞态条件。
- 上下文控制(Context)
适用场景:传递取消信号、超时或截止时间。
实现方式:使用context.Context树形结构管理协程的取消。
func longRunningTask(ctx context.Context) error {select {case <-ctx.Done():return ctx.Err() // 任务被取消或超时case result := <-doSomething():return result}
}func main() {ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)defer cancel()go func() {if err := longRunningTask(ctx); err != nil {fmt.Println("任务失败:", err)}}()
}
关键点:
在HTTP服务、数据库查询等I/O操作中强制传递Context。
使用WithCancel、WithTimeout派生子上下文。
- 并发安全的数据结构
适用场景:直接使用线程安全的数据结构减少锁竞争。
实现方式:使用sync.Map(适合读多写少)或第三方库(如go-concurrent-map)。
import "sync"var safeMap sync.Mapfunc storeData(key string, value interface{}) {safeMap.Store(key, value)
}func loadData(key string) (interface{}, bool) {return safeMap.Load(key)
}
注意:sync.Map的API与普通map不同,需熟悉其方法(Load、Store、Delete等)。
- 协程池(Worker Pool)
适用场景:限制并发数量,避免资源耗尽。
实现方式:使用缓冲Channel控制协程数量。
func workerPool(tasks <-chan int, workers int) {var wg sync.WaitGroupwg.Add(workers)for i := 0; i < workers; i++ {go func() {defer wg.Done()for task := range tasks {process(task)}}()}wg.Wait()
}func main() {tasks := make(chan int, 100)// 提交任务for i := 0; i < 100; i++ {tasks <- i}close(tasks)workerPool(tasks, 10) // 最多10个协程并发
}
优势:控制内存和CPU使用,避免协程爆炸。
Go语言中常见的原子操作有哪些?
atomic 的基础方法
原子操作主要是两类:修改和加载存储。修改很好理解,就是在原来值的基础上改动;加载存储就是读写。
atomic 提供了 AddXXX、CompareAndSwapXXX、SwapXXX、LoadXXX、StoreXXX(修改) 等方法。
由于 Go 暂时还不支持泛型,所以很多方法的实现都很啰嗦,比如 AddXXX 方法,针对 int32、int64、uint32 基础类型,每个类型都有相应的实现。等 Go 支持泛型之后,相信 atomic 的 API 就会清爽很多。
需要注意的是,atomic 的操作对象是地址,所以传参的时候,需要传变量的地址,不能传变量的值。
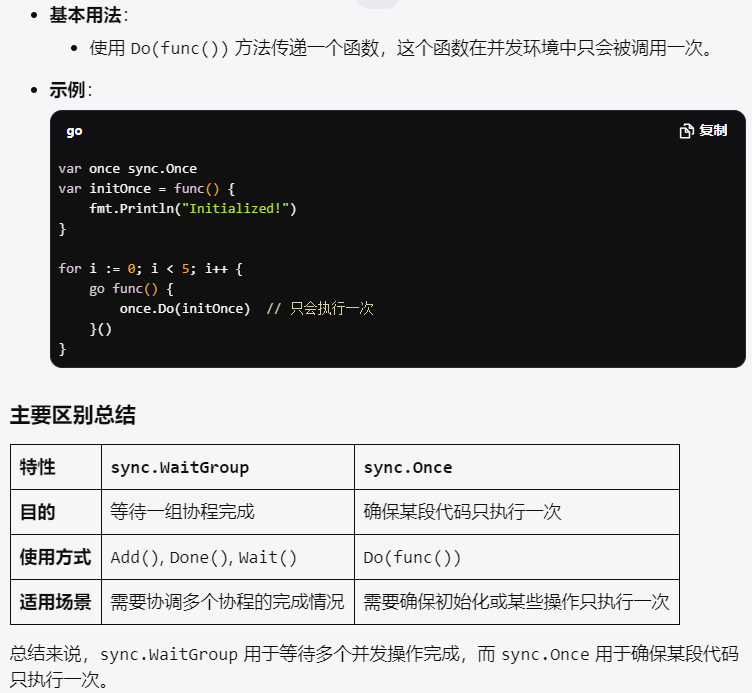
Go中的sync.WaitGroup和sync.Once有什么区别?
如果第三方接口返回的数据类型不确定,你会如何设计数据结构?
设计一个可以处理不确定数据类型的结构时,可以考虑以下几种方式:
1. 使用空接口 (interface{})
- Go的空接口可以接受任何类型的数据,因此可以将返回结果存储为
interface{}类型。
type ApiResponse struct {Data interface{} `json:"data"`
}
2. 使用类型断言
- 当需要访问具体数据时,可以使用类型断言来确定实际的数据类型。
response := ApiResponse{Data: someData}switch data := response.Data.(type) {
case string:fmt.Println("String data:", data)
case int:fmt.Println("Integer data:", data)
case []interface{}:fmt.Println("Array data:", data)
default:fmt.Println("Unknown type")
}
3. 使用结构体嵌套
- 如果已知返回数据可能符合某些结构,可以定义多个结构体类型,并在主响应结构体中嵌套这些结构体。
type StringResponse struct {Data string `json:"data"`
}type IntResponse struct {Data int `json:"data"`
}type ApiResponse struct {StringData *StringResponse `json:"stringData,omitempty"`IntData *IntResponse `json:"intData,omitempty"`
}
4. 使用 JSON 解析
- 如果返回的数据是 JSON 格式,可以使用
json.RawMessage来延迟解析。这样可以先读取原始数据,再根据需要解析成具体的结构体。
type ApiResponse struct {Data json.RawMessage `json:"data"`
}// 在使用时根据具体结构解析
var intData IntResponse
json.Unmarshal(response.Data, &intData)
5. 接口和多态
- 定义一个接口,所有可能的返回类型都实现这个接口。这样可以通过接口类型处理不同的返回数据。
type ResponseData interface {Process() // 定义一个处理方法
}type StringData struct {Value string
}func (s StringData) Process() {fmt.Println("Processing string:", s.Value)
}type IntData struct {Value int
}func (i IntData) Process() {fmt.Println("Processing int:", i.Value)
}
如果你请求第三方接口时出现超时,你会如何处理?
在请求第三方接口时,如果出现超时,可以采取以下几种处理策略:
1. 设置请求超时
- 在发起请求时,设置合理的超时时间,以防止请求无限期挂起。
client := &http.Client{Timeout: 5 * time.Second, // 设置超时时间
}
resp, err := client.Get("https://api.example.com")
if err != nil {// 处理超时或其他错误log.Println("Request failed:", err)return
}
2. 使用上下文(Context)管理请求
- 使用
context.Context可以更灵活地管理请求的超时和取消。
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()req, err := http.NewRequestWithContext(ctx, "GET", "https://api.example.com", nil)
if err != nil {log.Println("Error creating request:", err)return
}resp, err := client.Do(req)
if err != nil {// 处理超时或其他错误log.Println("Request failed:", err)return
}
3. 重试机制
- 对于超时等临时性错误,实施重试机制可以提高请求成功的概率。
maxRetries := 3
for i := 0; i < maxRetries; i++ {resp, err := client.Do(req)if err == nil {// 请求成功break}log.Println("Retrying request due to error:", err)time.Sleep(time.Second) // 等待一段时间后重试
}
4. 记录和监控
- 记录请求的超时事件,以便进行后续分析和监控。可以使用日志系统或监控工具来捕获这些信息。
if err != nil {log.Printf("Request to %s timed out: %v", req.URL, err)
}
5. 用户友好的反馈
- 当请求超时时,提供用户友好的反馈,告知用户出现了问题,并建议重试或稍后再试。
6. 后备策略
- 如果请求超时,可以考虑使用本地缓存的数据或备用服务,以保持系统的可用性。
总结
处理第三方接口请求超时时,设置合理的超时时间、使用上下文管理请求、实施重试机制以及记录和监控都是有效的策略。通过这些方法,可以提高系统的鲁棒性和用户体验。
在Go语言中,如何使用Context实现请求超时?
请求主动取消
package mainimport ("context""fmt""sync""time"
)func func1(ctx context.Context, wg *sync.WaitGroup) error {defer wg.Done()respC := make(chan int)// 处理逻辑go func() {time.Sleep(time.Second * 5)respC <- 10}()// 取消机制select {//等于ctx的超时退出case <-ctx.Done():fmt.Println("cancel")return nil//等待睡眠5S的线程退出 case r := <-respC:fmt.Println(r)return nil}
}func main() {wg := new(sync.WaitGroup)ctx, cancel := context.WithCancel(context.Background())wg.Add(1)go func1(ctx, wg)time.Sleep(time.Second * 2)// 触发取消cancel()// 等待goroutine退出wg.Wait()
}
请求超时取消
package mainimport ("context""fmt""sync""time"
)func func1(ctx context.Context, wg *sync.WaitGroup) error {defer wg.Done()respC := make(chan int)// 处理逻辑go func() {time.Sleep(time.Second * 5)respC <- 10}()// 取消机制select {//等于ctx的超时退出case <-ctx.Done():fmt.Println("cancel")return nil//等待睡眠5S的线程退出 case r := <-respC:fmt.Println(r)return nil}
}func main() {wg := new(sync.WaitGroup)ctx, _ := context.WithTimeout(context.Background(), 3*time.Second)wg.Add(1)go func1(ctx, wg)// 等待goroutine退出wg.Wait()
}
Go语言中常用的ORM框架有哪些?
GORM
GORM 是 Golang 中最受欢迎的 ORM 框架之一,提供了丰富的功能和易于使用的 API。以下是 GORM 的一些主要特点:
支持多种数据库:GORM 支持 MySQL、PostgreSQL、SQLite 等多种主流数据库。
数据表映射:使用结构体定义数据模型,支持自动创建和更新数据库表结构。
查询构建器:提供丰富的查询构建器,通过链式调用构建复杂查询语句。
事务支持:提供事务支持,确保数据一致性。
钩子函数:允许在模型生命周期中添加钩子函数,执行自定义逻辑。
package mainimport (
"gorm.io/driver/mysql"
"gorm.io/gorm"
)type User struct {
gorm.Model
Name string
Email string
}func main() {
dsn := "your-database-connection-string"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err != nil {
panic("failed to connect to database")
}
db.AutoMigrate(&User{})
user := User{Name: "John Doe", Email: "john@example.com"}
db.Create(&user)
}
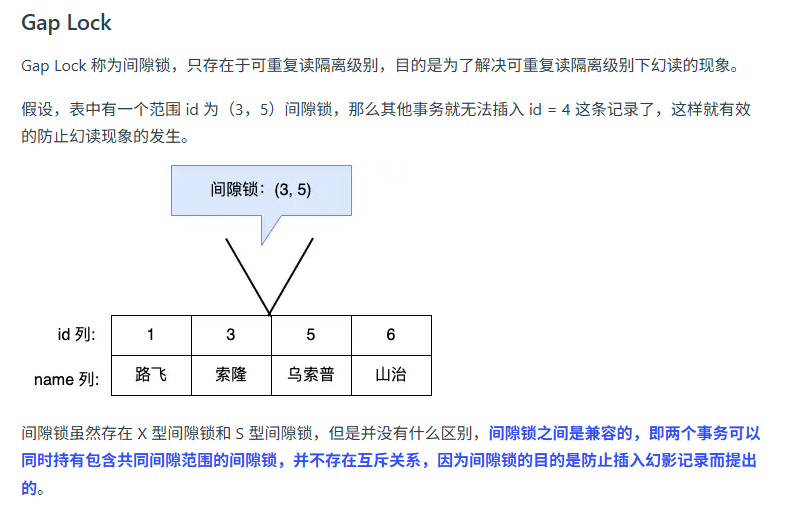
MySQL中常见的锁类型有哪些?
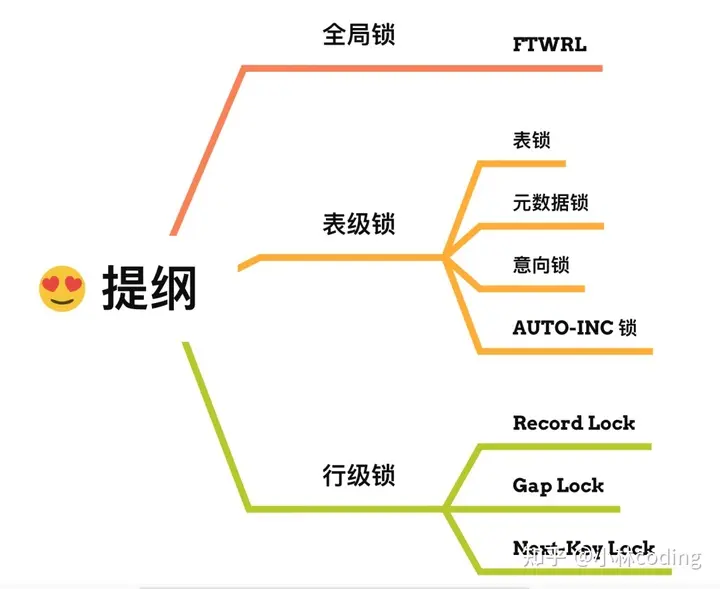



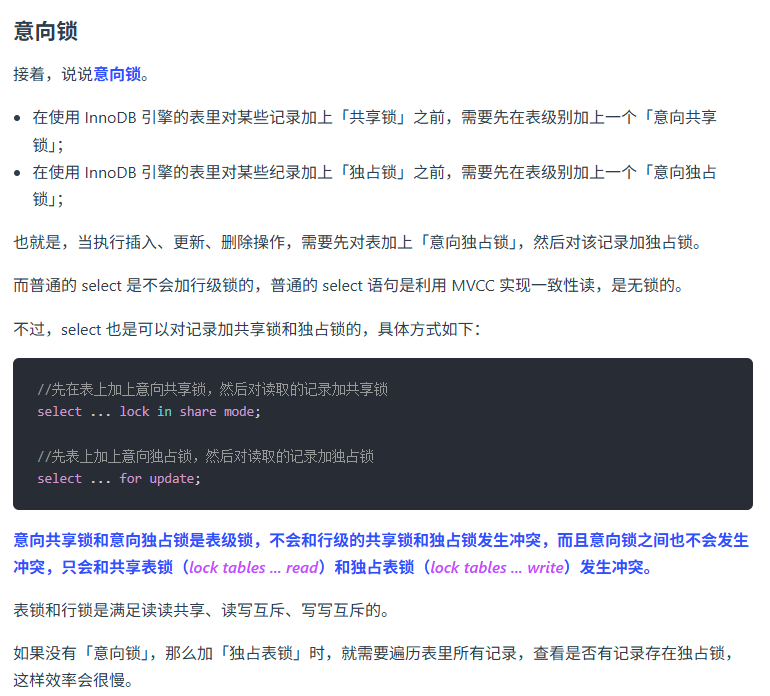


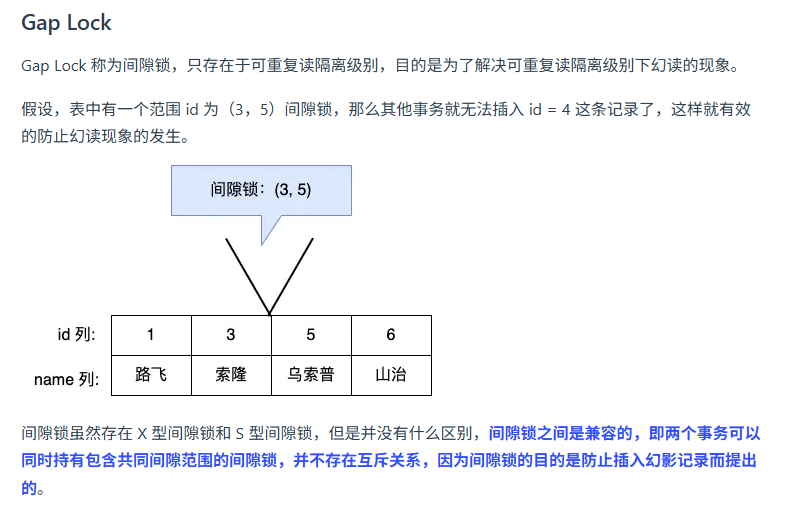
MySQL中的间隙锁是如何产生的?
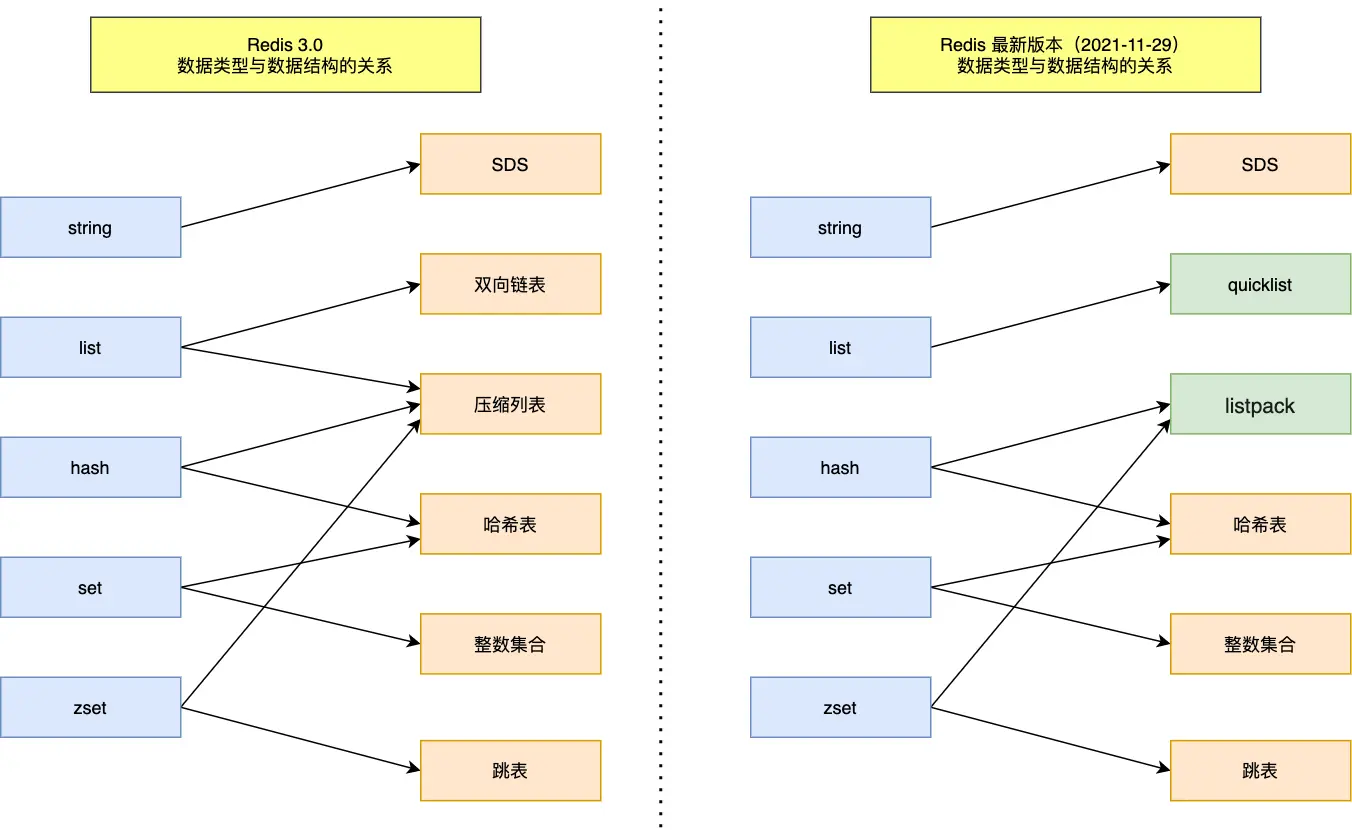
Redis中常见的数据存储结构有哪些?

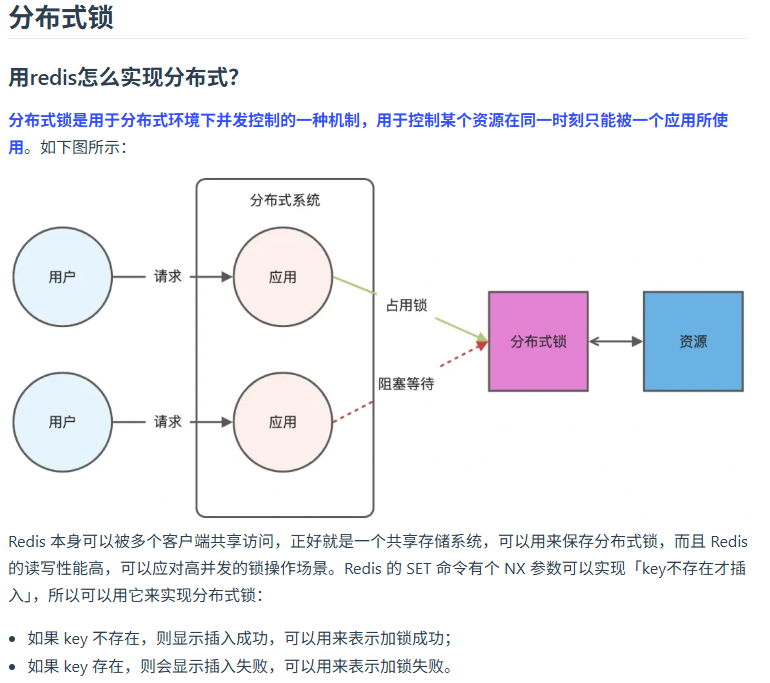
如果有多个服务器需要加锁处理接口请求,你会怎么做?
在分布式系统中处理多个服务器间的加锁请求时,需借助分布式锁来保证资源访问的互斥性。以下是实现分布式锁的关键步骤和常见方案:
- 选择合适的分布式锁实现
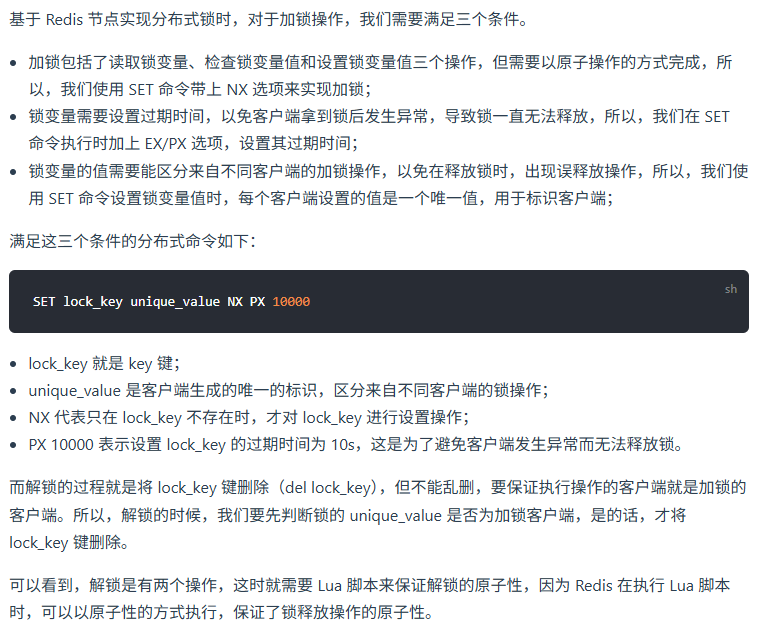
基于Redis的分布式锁
核心命令:使用 SET key unique_value NX EX timeout 原子性设置锁,避免死锁。
唯一标识:用UUID或请求ID作为unique_value,确保锁归属。
释放锁:通过Lua脚本校验unique_value后删除,保证原子性。
续期机制:通过后台线程(如Redisson的看门狗)自动延长锁超时时间。
高可用:采用Redis集群或RedLock算法(需权衡争议)。
- 关键注意事项
超时与死锁:锁必须设置超时,避免进程崩溃导致死锁,同时需处理业务超时(如续期机制)。
网络分区:考虑脑裂问题,选择CP系统(如ZooKeeper/ETCD)或通过Fencing Token(如Redis + 版本号)增强安全。
可重入性:同一线程多次获取锁需支持重入(如Redisson的计数机制)。
性能与可靠性权衡:Redis性能高但需处理异步复制问题;ZooKeeper/ETCD强一致但吞吐较低。
数据库锁
在数据库层面实现锁定:
行级锁:
使用数据库的行级锁(如 InnoDB 的 SELECT … FOR UPDATE)来锁定特定的行。
表级锁:
使用 LOCK TABLES 来锁定整个表,适合低并发场景。
3. 消息队列
使用消息队列来串行化请求处理:
将请求发送到消息队列,消费者按顺序处理请求,确保每个请求在处理时是唯一的。
4. 乐观锁
在数据表中加入版本号或时间戳字段,通过比较版本号或时间戳来判断数据是否被其他请求修改。
UPDATE table SET value = ?, version = version + 1 WHERE id = ? AND version = ?
- 应用层锁
在应用层实现锁定机制,例如使用内存数据库(如 Redis)来维护锁的状态。
如何实现分布式锁?在Redis中,分布式锁会用到哪些命令?

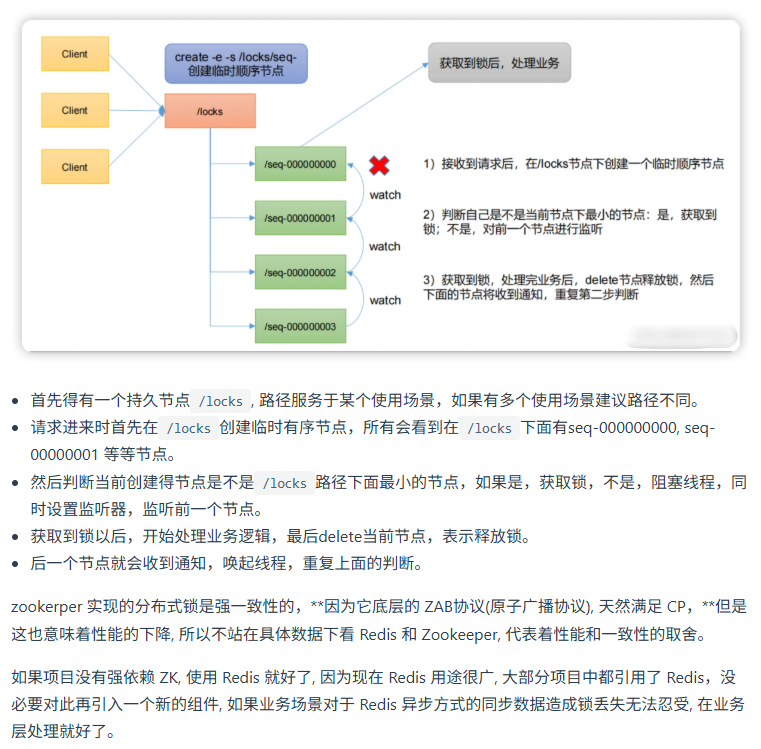
如果分布式锁没有正常释放,你会如何进行容灾处理?
- 预防阶段:设计健壮的锁机制
(1) 强制设置锁超时时间
自动过期:无论基于 Redis(EX 参数)、ZooKeeper(临时节点)还是 ETCD(Lease 租约),必须设置锁超时时间(TTL),确保锁最终自动释放。
超时时间估算:根据业务逻辑的最大耗时合理设置 TTL(如业务平均耗时的 3 倍),避免过早释放或长期不释放。
(2) 实现锁续期(续租)
心跳续期:若业务处理时间可能超过 TTL,需通过后台线程定期续期(如 Redisson 的看门狗机制、ETCD 的 KeepAlive)。
续期失败策略:若续期失败(如网络中断),应主动中断业务并释放资源,避免数据不一致。
2. 检测阶段:监控与告警
(1) 锁状态监控
关键指标:
锁持有时间超过阈值(如 TTL 的 80%)。
同一锁的频繁竞争失败(可能表示锁未释放或热点资源)。
工具:通过 Prometheus + Grafana 监控 Redis/ZooKeeper/ETCD 的锁状态,或集成 APM(如 SkyWalking)。
(2) 告警机制
规则:当锁持有时间异常或死锁频率升高时,触发告警(邮件、短信、钉钉等)。
定位问题:记录锁持有者的标识(如 IP、线程 ID、UUID),便于快速定位故障节点。
3. 恢复阶段:自动与手动容灾
(1) 自动容灾
锁超时自动释放:依赖 TTL 机制自动清理过期锁。
守护进程清理:部署独立服务定期扫描并释放“僵尸锁”(需校验锁归属,避免误删)。
(2) 手动容灾
管理接口:提供运维 API 或 Dashboard,手动查询并释放指定锁。
4. 业务层容错设计
(1) 幂等性
所有受锁保护的接口设计为幂等,确保即使锁失效导致重复请求,也不会产生副作用。
(2) 熔断降级
若锁服务不可用(如 Redis 宕机),启用熔断策略(如本地排队、直接拒绝请求),避免级联故障。
5. 根因分析与优化
(1) 故障复盘
日志分析:检查锁未释放的原因(如进程崩溃、代码未执行 finally 块)。
复现测试:通过 Chaos Engineering 模拟节点宕机、网络延迟,验证锁机制的可靠性。
(2) 长期优化
切换锁实现:若 Redis 锁在高并发下问题频发,可换用 ZooKeeper/ETCD 实现强一致性锁。
去锁化设计:考虑无锁方案(如 CAS 操作、消息队列串行化)。
如果加了分布式锁后,业务长时间被阻塞,如何减少服务不可用的时间?
在分布式锁场景中,若业务因锁竞争长时间阻塞导致服务不可用,可通过以下系统性优化策略减少阻塞时间:
1. 精细化锁设计
(1) 缩小锁粒度
- 场景:大范围锁(如全局锁)导致高竞争。
- 优化:根据业务拆分锁粒度(如按用户ID、订单号等维度加锁)。
// 错误:全局锁导致所有用户操作串行化 String lockKey = "global_order_lock";// 优化:按用户ID分片锁 String userId = "user_123"; String lockKey = "order_lock:" + userId; // 锁粒度细化到用户级别
(2) 读写锁分离
- 场景:读多写少时,读操作无需互斥。
- 优化:使用读写锁(如Redisson的
RReadWriteLock),允许多个读锁并行。RReadWriteLock rwLock = redisson.getReadWriteLock("resource_rw_lock"); RLock readLock = rwLock.readLock(); readLock.lock(); // 多个读操作可并行 try {// 读业务逻辑 } finally {readLock.unlock(); }
2. 超时与重试策略优化
(1) 双重超时控制
- 锁获取超时:设置尝试获取锁的最长时间,超时后快速失败。
- 锁持有超时:设置锁自动释放时间(TTL),避免死锁。
# Redisson示例(Java语法类似) RLock lock = redisson.getLock("resource_lock"); try {// 尝试获取锁,最多等待2秒,锁持有超时10秒boolean acquired = lock.tryLock(2, 10, TimeUnit.SECONDS);if (acquired) {// 业务逻辑(需在10秒内完成)} else {throw new BusyException("系统繁忙,请重试");} } finally {lock.unlock(); }
(2) 智能重试机制
- 指数退避:避免高频重试导致雪崩。
int maxRetries = 3; long initialDelay = 100; // 初始延迟100ms for (int i = 0; i < maxRetries; i++) {if (tryAcquireLock()) break;Thread.sleep(initialDelay * (1 << i)); // 指数退避:100ms, 200ms, 400ms } - 随机抖动(Jitter):在重试间隔中加入随机性,分散并发请求。
3. 异步化与降级处理
(1) 异步抢锁
- 非阻塞模型:将锁竞争与业务处理解耦,避免线程长时间阻塞。
// 使用CompletableFuture异步获取锁 CompletableFuture.supplyAsync(() -> {return tryAcquireLockAsync(); // 非阻塞方式尝试获取锁 }).thenApply(acquired -> {if (acquired) {// 异步处理业务} else {return "系统繁忙,稍后重试";} });
(2) 熔断降级
- 阈值触发:当锁竞争失败率超过阈值(如50%),触发熔断,直接返回降级结果。
CircuitBreaker breaker = new CircuitBreaker(failureThreshold: 0.5, timeoutMs: 5000 );if (breaker.allowRequest()) {try {acquireLock();// 业务逻辑} catch (LockTimeoutException e) {breaker.recordFailure();} } else {return "服务降级:快速返回缓存数据"; }
4. 锁竞争公平性优化
(1) 公平锁机制
- 场景:高并发下防止线程饥饿。
- 方案:使用公平锁(如ZooKeeper临时顺序节点、Redis + Redisson公平锁)。
// Redisson公平锁示例 RLock fairLock = redisson.getFairLock("fair_lock"); fairLock.lock(); // 按请求顺序分配锁
(2) 队列化请求
- 请求排队:将竞争锁的请求放入队列,按顺序处理。
# RabbitMQ示例:将请求序列化到队列 channel.queue_declare(queue='order_queue') channel.basic_publish(exchange='',routing_key='order_queue',body=json.dumps(order_data) )
5. 业务逻辑优化
(1) 缩短临界区代码
- 优化重点:仅对必须互斥的代码段加锁,减少锁持有时间。
// 错误:锁覆盖整个业务方法 public void process() {lock.lock();try {// 非关键操作(如日志记录)log.info("Start processing");// 关键操作(需加锁)updateDatabase();} finally {lock.unlock();} }// 优化:仅锁住关键代码 public void process() {log.info("Start processing"); // 无锁操作lock.lock();try {updateDatabase(); // 最小化临界区} finally {lock.unlock();} }
(2) 无锁化改造
- CAS操作:利用原子类(如Redis的
INCR、数据库乐观锁)避免锁竞争。-- 数据库乐观锁示例 UPDATE inventory SET stock = stock - 1 WHERE product_id = 100 AND stock > 0;
6. 监控与应急处理
(1) 实时监控指标
- 核心指标:
- 锁等待时间(P50/P95/P99)
- 锁竞争失败率
- 锁持有时间分布
- 工具:Prometheus + Grafana 监控看板。
(2) 应急命令通道
- 强制释放锁:提供紧急API或脚本手动释放异常锁。
# Redis手动释放锁(需谨慎) redis-cli -h 127.0.0.1 -p 6379 EVAL "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end" 1 resource_lock lock_uuid
总结
通过 锁粒度优化 → 超时/重试策略 → 异步降级 → 公平性设计 → 业务改造 → 监控应急 的完整链路,可显著减少锁竞争导致的阻塞时间。关键在于:让锁的持有时间尽可能短,让竞争失败的处理尽可能轻量,让系统在锁不可用时仍能提供有限服务。
如何监控接口响应时间并优化服务的可用性?
监控接口响应时间并优化服务可用性是保障系统稳定性和用户体验的关键。以下是一套系统化的方法和实践:
一、监控体系搭建
-
指标采集层
- 核心指标:P99/P95响应时间、错误率、吞吐量(QPS/TPS)
- 网络指标:DNS时间、TCP连接时间、SSL握手时间
- 系统指标:CPU/Memory/IO使用率、线程池状态、GC频率
- 工具选择:
- APM:SkyWalking/Pinpoint/New Relic
- 时序数据库:Prometheus + Grafana
- 日志分析:ELK Stack(ES+Logstash+Kibana)
-
智能告警机制
- 动态基线告警:基于历史数据自动计算正常范围
- 多级触发:Warning(P90>300ms)→ Critical(P99>1s)
- 告警聚合:相似告警自动合并,避免告警风暴
二、深度根因分析
-
全链路追踪
- 示例TraceID分析:
API-Gateway(120ms) → UserService(80ms) → MySQL(50ms) → Redis(5ms) - 重点关注跨服务调用的网络延迟
- 示例TraceID分析:
-
热点分析矩阵
问题类型 特征 工具 CPU瓶颈 高Load/Long GC Arthas/async-profiler IO阻塞 线程BLOCKED状态 jstack + 火焰图 慢查询 数据库响应时间突增 Explain分析
三、优化实施策略
-
架构层优化
- 缓存策略:多级缓存(本地缓存 → Redis → DB)
- 异步化改造:非核心链路MQ解耦(如Kafka)
- 服务网格:Istio实现动态熔断/降级
-
代码级优化
// 反例:N+1查询 List<Order> orders = orderDao.listAll(); orders.forEach(order -> {order.setUser(userDao.get(order.getUserId())); // 循环查询 });// 正例:批量查询 List<Long> userIds = orders.stream().map(Order::getUserId).distinct().toList(); Map<Long, User> userMap = userDao.batchGet(userIds).stream().collect(Collectors.toMap(User::getId, Function.identity())); -
基础设施优化
- 网络:同AZ部署 → 多AZ容灾 → 全球加速(如AWS Global Accelerator)
- 容器化:K8s HPA自动扩缩容 + VPA资源调整
四、验证与迭代
-
压测标准流程
-
混沌工程实践
- 网络延迟注入:
tc qdisc add dev eth0 root netem delay 200ms - 服务故障演练:随机终止Pod模拟节点故障
- 网络延迟注入:
五、持续改进机制
-
SLO管理看板
Service Level Objectives: - 可用性: 99.95% (每月最多22分钟不可用) - 延迟: P99 < 500ms - 流量: 支持1000 QPS常态流量 -
优化案例库
问题现象 根因 解决方案 效果提升 每晚20:00响应时间飙升 定时任务抢占CPU 错峰调度 40%↓ 偶发5秒超时 TCP连接泄漏 连接池参数调优 99.9%↑
通过以上方法体系化实施,可将典型API的响应时间优化30%-70%,同时将系统可用性提升到99.9%以上。建议每季度进行全链路性能审计,持续发现优化点。
如果你需要将代码部署到阿里云的Linux服务器上,你会如何做?
将代码部署到阿里云的Linux服务器上,可以遵循以下步骤:
1. 准备工作
- 创建阿里云账号:如果还没有阿里云账号,首先创建一个。
- 购买ECS实例:在阿里云控制台购买一个适合的ECS实例,选择所需的操作系统(如Ubuntu或CentOS)。
2. 连接到ECS实例
- 获取连接信息:记录ECS实例的公网IP地址和SSH登录凭证(用户名和密码或SSH密钥)。
- 使用SSH连接:
ssh username@your-ecs-ip
3. 安装必要的软件
- 更新系统:
sudo apt update && sudo apt upgrade # Ubuntu sudo yum update # CentOS - 安装所需的依赖(如Git、编译工具、数据库等):
sudo apt install git build-essential # Ubuntu sudo yum install git gcc gcc-c++ # CentOS
4. 上传代码
-
使用SCP或SFTP上传代码:
- 使用SCP:
scp -r /path/to/your/code username@your-ecs-ip:/path/to/destination- 使用SFTP客户端(如FileZilla)进行上传。
-
使用Git克隆代码:
git clone https://github.com/your-repo.git
5. 配置环境
- 设置环境变量:根据需要配置环境变量,例如数据库连接信息。
- 安装依赖:根据项目的需求安装相关依赖(如使用
npm install、pip install等)。
6. 构建和运行应用
- 构建应用:如果是需要构建的项目(如Go、Node.js、Java等),执行相应的构建命令。
- 运行应用:
# 对于Go应用 go run main.go# 对于Node.js应用 node app.js
7. 设置服务管理
-
使用systemd管理应用(可选):
- 创建一个systemd服务文件
/etc/systemd/system/your-app.service,内容示例:
[Unit] Description=Your App[Service] ExecStart=/path/to/your/app Restart=always User=username[Install] WantedBy=multi-user.target - 创建一个systemd服务文件
-
启动服务:
sudo systemctl start your-app sudo systemctl enable your-app
8. 配置防火墙
- 开放必要的端口(如HTTP/HTTPS):
sudo ufw allow 80/tcp # Ubuntu sudo firewall-cmd --permanent --add-port=80/tcp # CentOS sudo firewall-cmd --reload
9. 域名和SSL配置
- 绑定域名:如果有域名,可以在阿里云控制台中绑定域名到ECS实例的IP。
- SSL配置(可选):使用Let’s Encrypt等工具为网站配置SSL。
10. 监控和维护
- 监控应用:使用监控工具(如Prometheus、Grafana)监控应用的性能和健康状态。
- 定期备份:设置定期备份,确保数据安全。
总结
以上步骤提供了在阿里云的Linux服务器上部署代码的基本流程。具体操作可能因项目需求和环境而有所不同,确保根据实际情况进行调整。
如何在Windows开发环境下打包Go语言代码,并使其在Linux环境中运行?
在Windows开发环境下打包Go语言代码并使其在Linux环境中运行,可以按照以下步骤进行:
1. 安装Go语言
确保在Windows上安装了Go语言开发环境。可以从Go官方网站下载并安装。
2. 设置Go环境变量
确保Go的环境变量已正确设置,特别是GOPATH和GOROOT。
3. 编写你的Go代码
编写你的Go代码并确保它能在Windows上正常运行。
4. 设置交叉编译环境
Go语言支持交叉编译,可以通过设置环境变量来编译为Linux可执行文件。
5. 编译代码
在命令行中使用以下命令编译你的Go应用:
set GOOS=linux
set GOARCH=amd64 # 或者386,取决于目标架构
go build -o yourapp
6. 确认编译成功
编译完成后,在当前目录下会生成一个名为yourapp的可执行文件。
7. 传输到Linux服务器
使用SCP、SFTP或者其他工具将可执行文件传输到Linux服务器:
scp yourapp username@your-linux-ip:/path/to/destination
8. 在Linux上运行
-
连接到Linux服务器:
ssh username@your-linux-ip -
给可执行文件添加执行权限:
chmod +x /path/to/destination/yourapp -
运行应用:
/path/to/destination/yourapp
9. 测试和验证
确保在Linux环境中测试应用程序,检查是否按预期工作。
10. 调试和优化
如有需要,返回Windows开发环境进行调试和优化,再次编译并部署。
总结
通过设置环境变量GOOS和GOARCH,可以在Windows环境中轻松地编译Go代码为Linux可执行文件。然后,将编译后的文件传输到Linux服务器上运行即可。这样可以高效地进行跨平台开发。