存储器综合:内存条
一、RW 1000题刷题
1、计算Cache缺失率

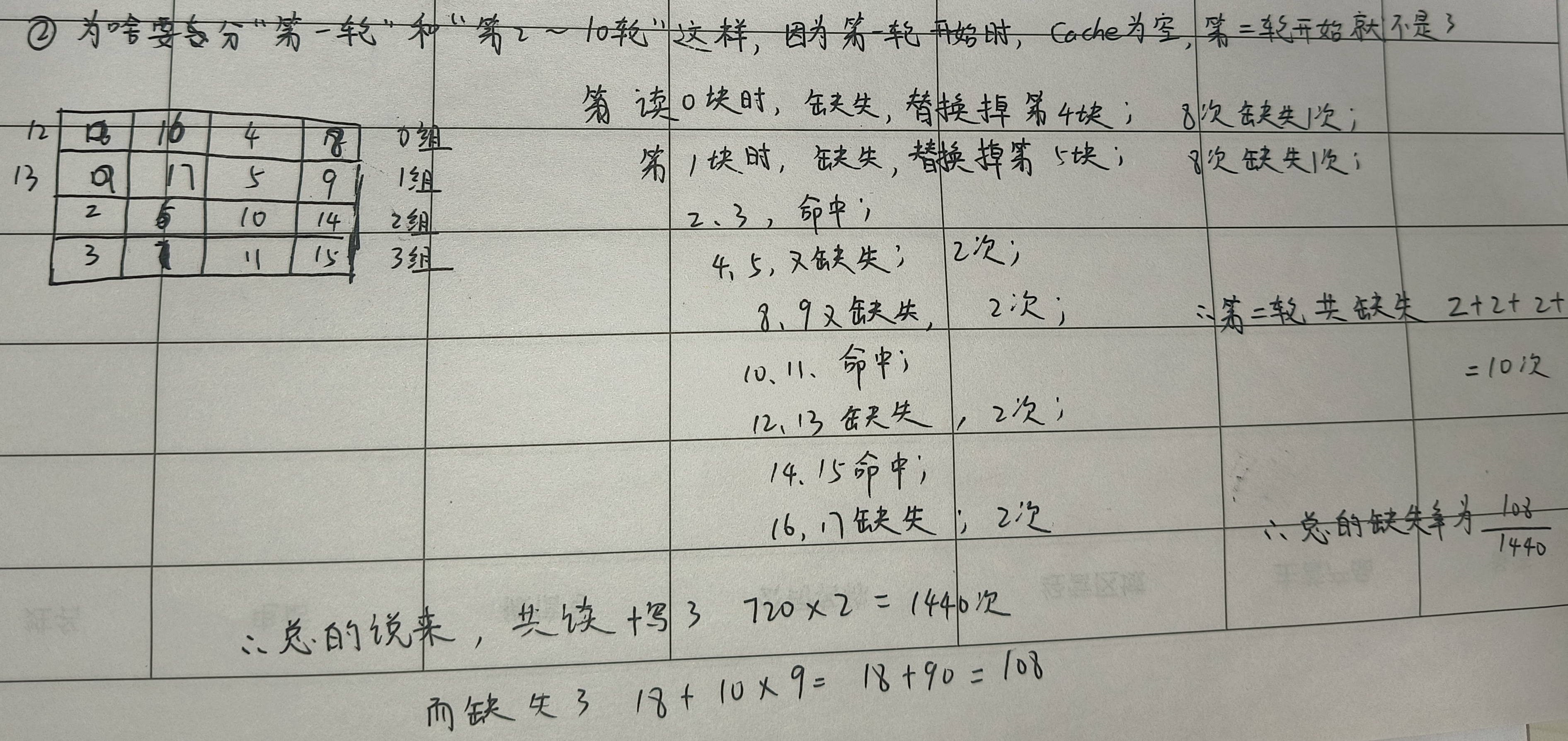
2、
二、前提回顾
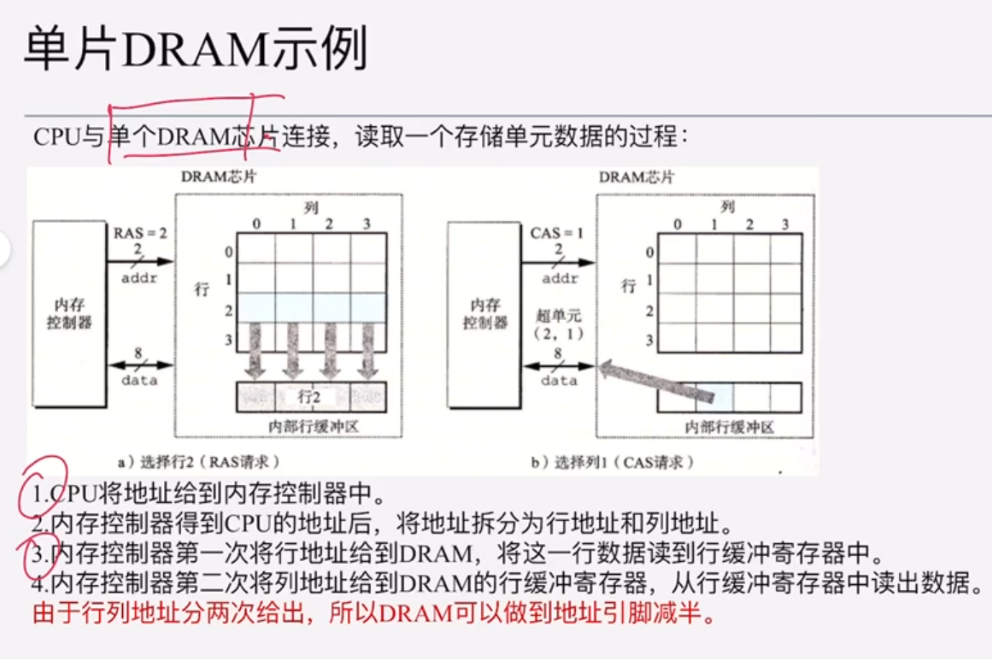
1、CPU从单个DRAM芯片中取地址
注意:Cache与主存的交互以“主存块”为单位,当出现Cache Miss时,主存以“主存块”为单位传输至Cache中。
2、内存条编址
多个DRAM芯片组成内存条,则地址=体号+芯片内内地址(行号+列号)
(1)存储周期=读出时间+电路恢复时间,但是一般都会把后者忽略;既:题目中的存储周期一般就是读出时间;
(2)顺序编址
体号是前几位,而剩余地址是芯片内的地址。
(3)交叉编址
地址=芯片内地址+体号
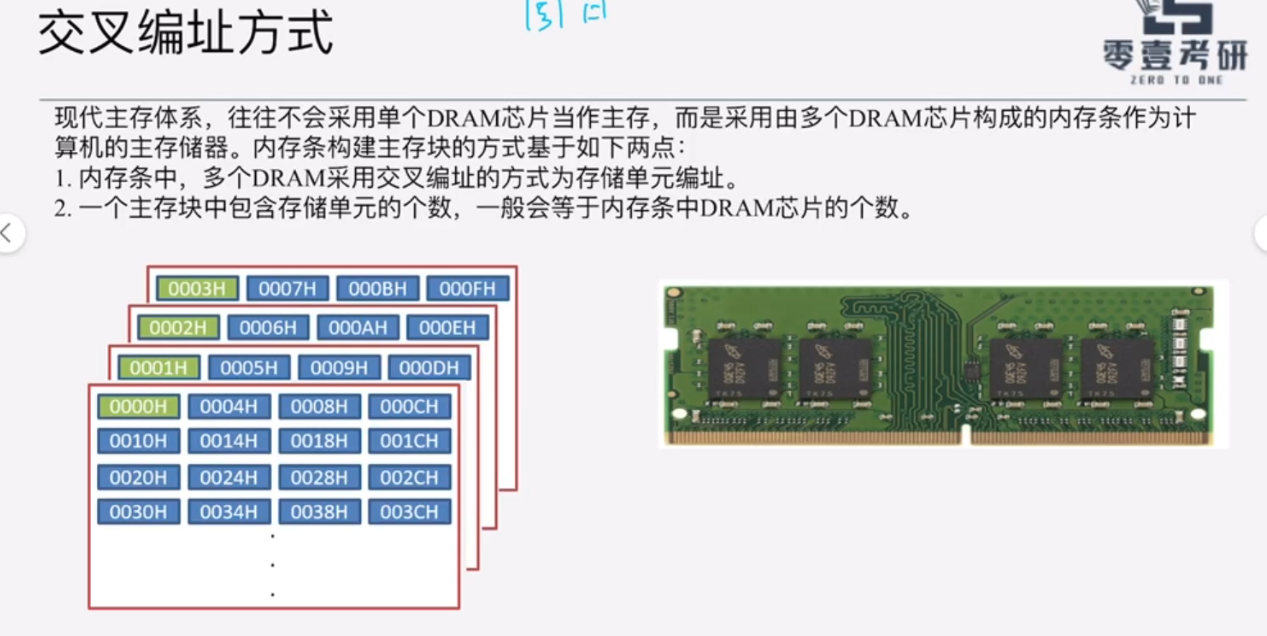
应用于"突发传送总线事务"
注意:主存块也需要对齐,(每个主存块的地址x)%(主存块大小)=0
eg:2017年真题
(4)
三、DRAM芯片扩展
位扩展扩展的是存储字长的位数,字扩展扩展的是存储单元的数目。
1、位扩展

将存储字长进行扩展。
2、字扩展
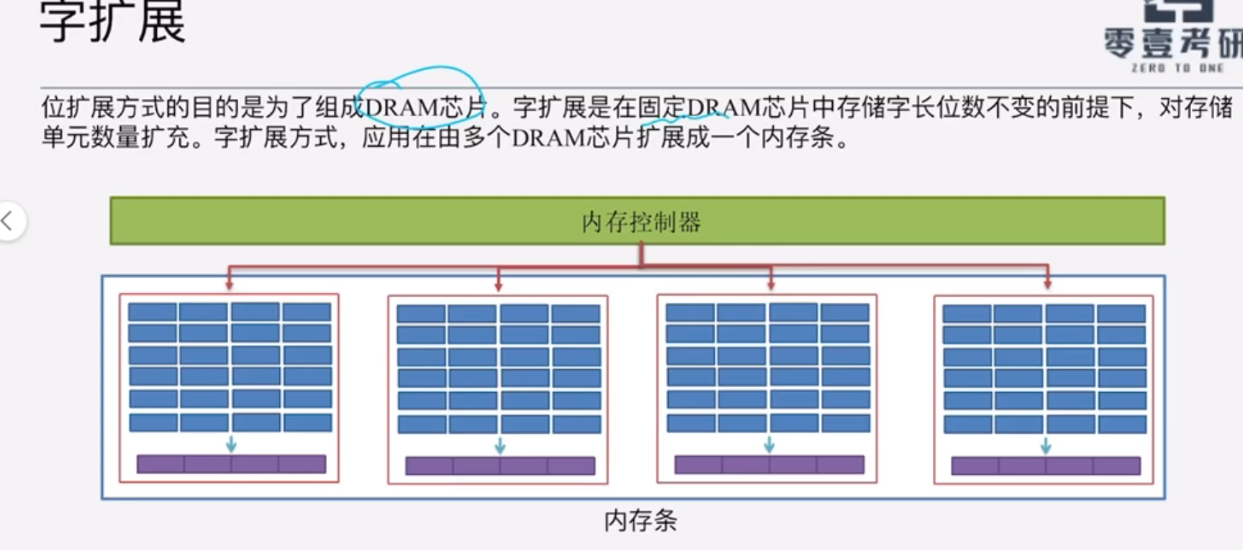
在固定DRAM芯片的存储字长不变的情况下,对存储单元数量进行扩充;
例如:由多个DRAM芯片扩展一个内存条。
3、字位同时扩展
既扩展存储单元的长度,又扩展存储单元的个数。
4、双口存储器(冷门考点)
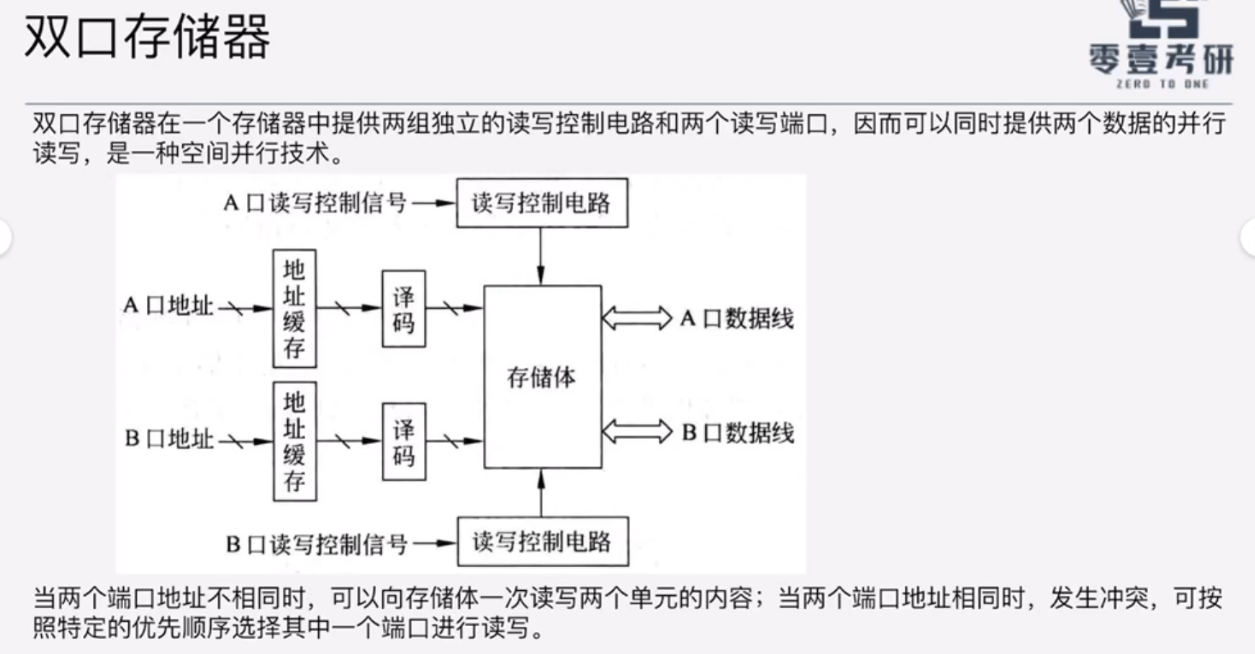
端口地址不相同时,可以并行读两个存储单元;当端口地址相同时,串行读出。
当发生“读冲突”时,可以通过改变存储体内部电路,从而以"广播"形式同时读出。
但是写冲突,一定是冲突无法解决的。
5、重要例题

MAR的位数表示:CPU能够访问的最大存储地址。
题干分析:主存地址空间 > 主存储器的内存,说明采用了虚拟内存的方式。而MAR的位数确实是反映了CPU能够访问的,而非真实物理地址。
地址空间是虚拟概念,内存空间是物理概念;MAR在CPU里。
为什么“物理内存的大小”不能大于“虚拟内存的大小”?
假设物理内存大小为64B,虚拟内存的大小为32B,此时操作系统将一个页放在了物理内存中的高32B内,但是CPU只能访问物理内存的低32B,那么这个页将永远不会被访问。
四、主存块传输过程,又称为“地址连续存储单元传输”

既:当想要猝发传送时,一定是采用多模块的交叉编址方式。
1、窄形结构传输

注意:DRAM芯片"准备数据的时间"=存储周期,一般被近似于"读某一存储单元的时间"
2、突发(猝发)传送总线事务
既:构建了快速传送通道的模式

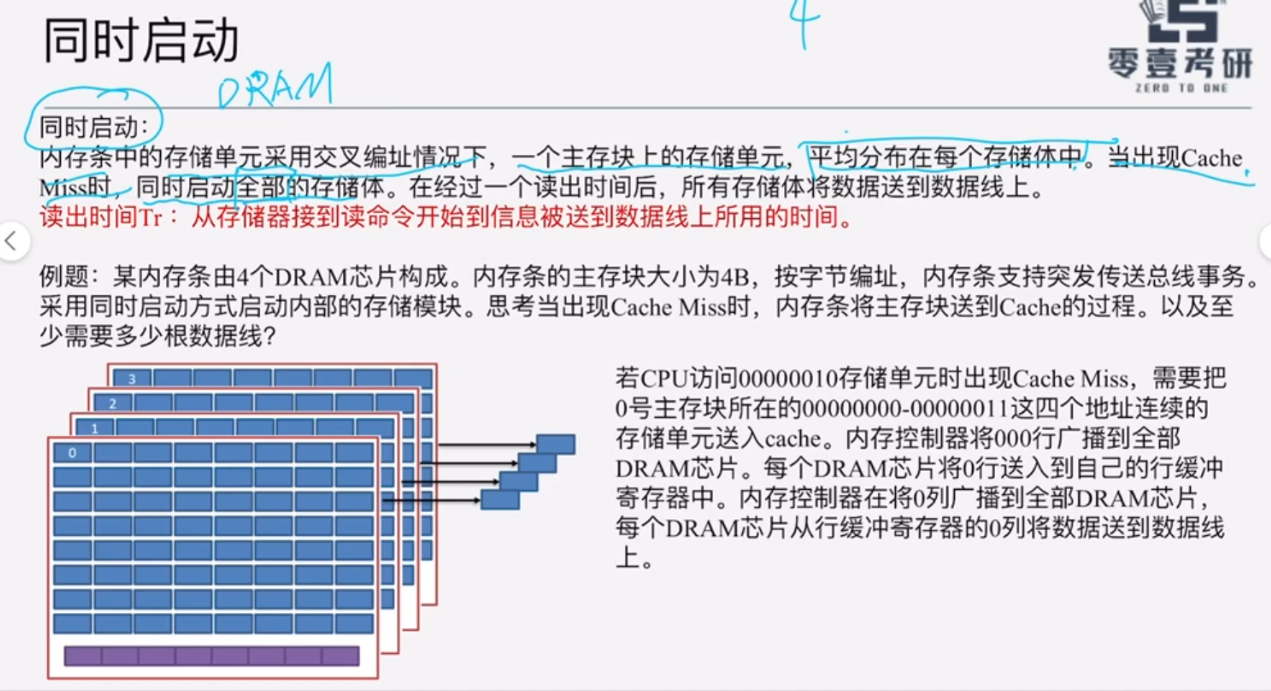
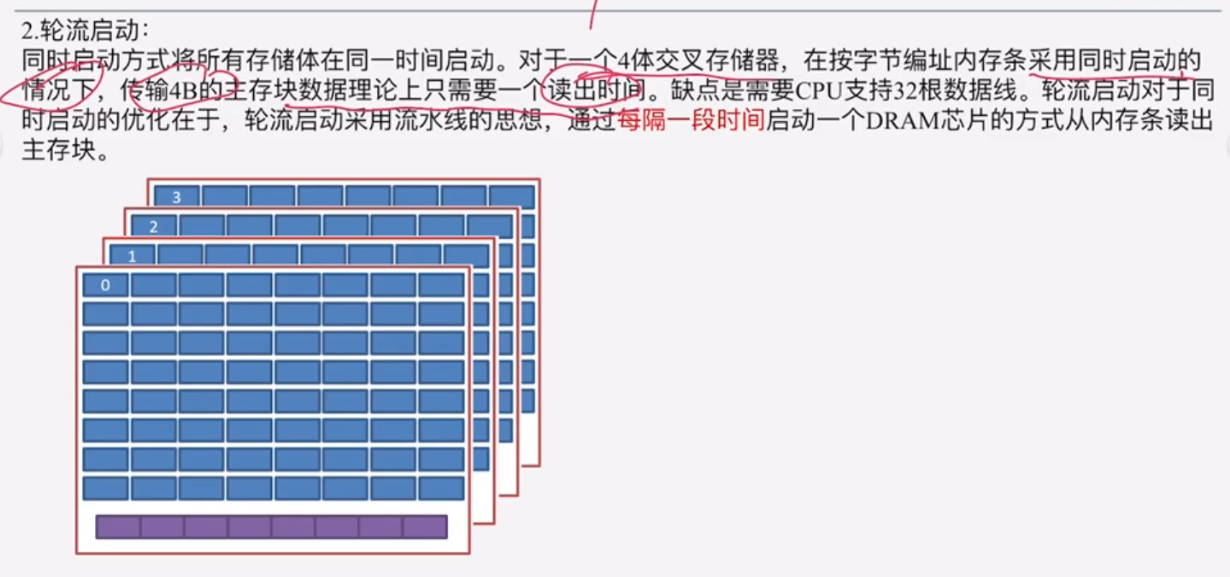
在"存储器准备数据"这一步骤中,有两种启动存储器的方式:轮流启动+同时启动。
而判断究竟是哪种启动方式:数据线的宽度。
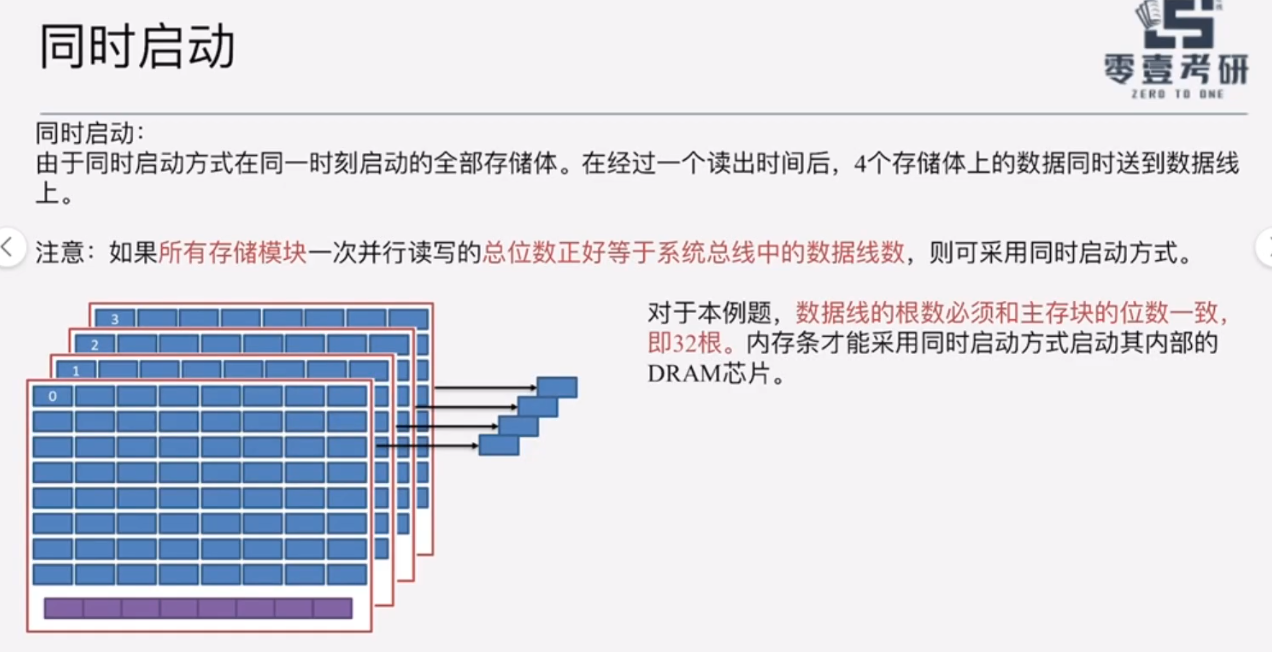
A、数据线宽度=存储单元长度,则是轮流启动;
B、数据线宽度=主存块长度,则是同时启动。
(1)同时启动
采用交叉编址时,一个主存块的四个存储单元会均匀地分布在4个DRAM芯片上;
经过一个读出时间(即存储周期)后,所有存储体将数据送到数据线上。
注意下面对于读出时间的定义:从存储器接到读命令开始到信息被送到数据线上所用的时间。
主存块的读取原则:每次读取不同体号芯片上的同一行同一列,因为内存控制器将"广播"行号与列号到每个DRAM芯片中。
相当于:内存块的读取也有边界对齐原则,内存块的初始地址%大小=0。
超级重要的例题:
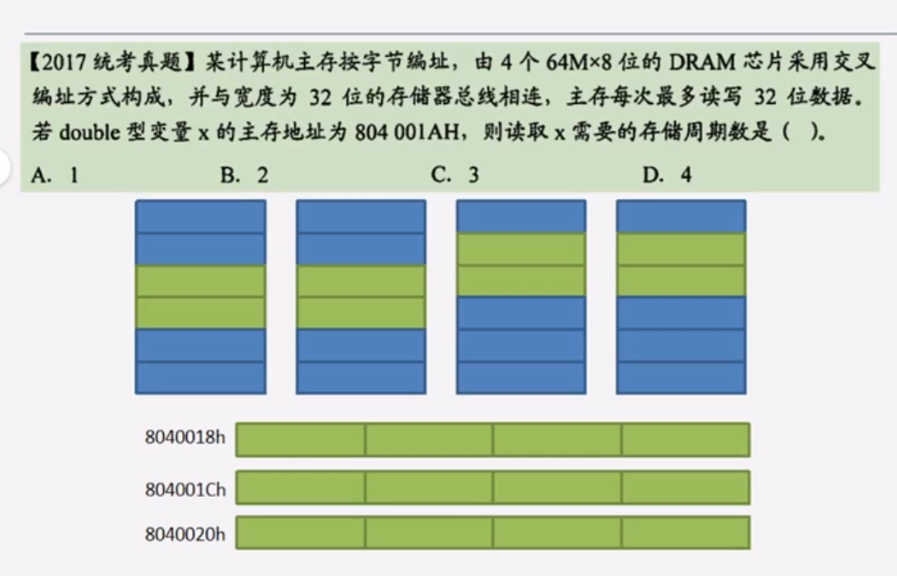
4个DRAM芯片的体号应该是2bit,由题意得:最后两位就是体号。
x的主存地址%4 ≠ 0,所以不可能是从x开始作为一个主存块。
所以:是3个存储周期。
扩展:SDRAM芯片
目前的内存条就是诸如SDRAM芯片,一个SDRAM芯片构成一个内存条,一个Cache块分布在一个芯片上。
SDRAM的每一步操作都在系统时钟的控制下进行,支持突发传送方式;第一次存取时给出首地址,同一行的所有数据被送到行缓冲器中,以后每个时钟可以连续地从行缓冲寄存器中输出一个数据。
行缓冲寄存器:用来缓存指定行中整行的数据,通常用SRAM实现。
(2)SDRAM详解(同步的DRAM,名称中的S来自同步)
袁书原话:支持突发传送方式,能够连续、快速地从行缓冲区中输出一连串数据。
01讲解:一个SDRAM芯片构成了内存,实现连续传送过程如下:
(因为只有一个,所以就不涉及究竟是交叉编址还是顺序编址)
SDRAM芯片会借助"行缓冲寄存器"进行连续传送,假设主存块大小为4B,那么SDRAM芯片会给出4个列信号,第一列传输完后会再传输第二列,以此类推。
相关真题:

选B
(3)轮流启动(超级重点)
注意间隔时间的计算:其实是靠总线周期确定的。
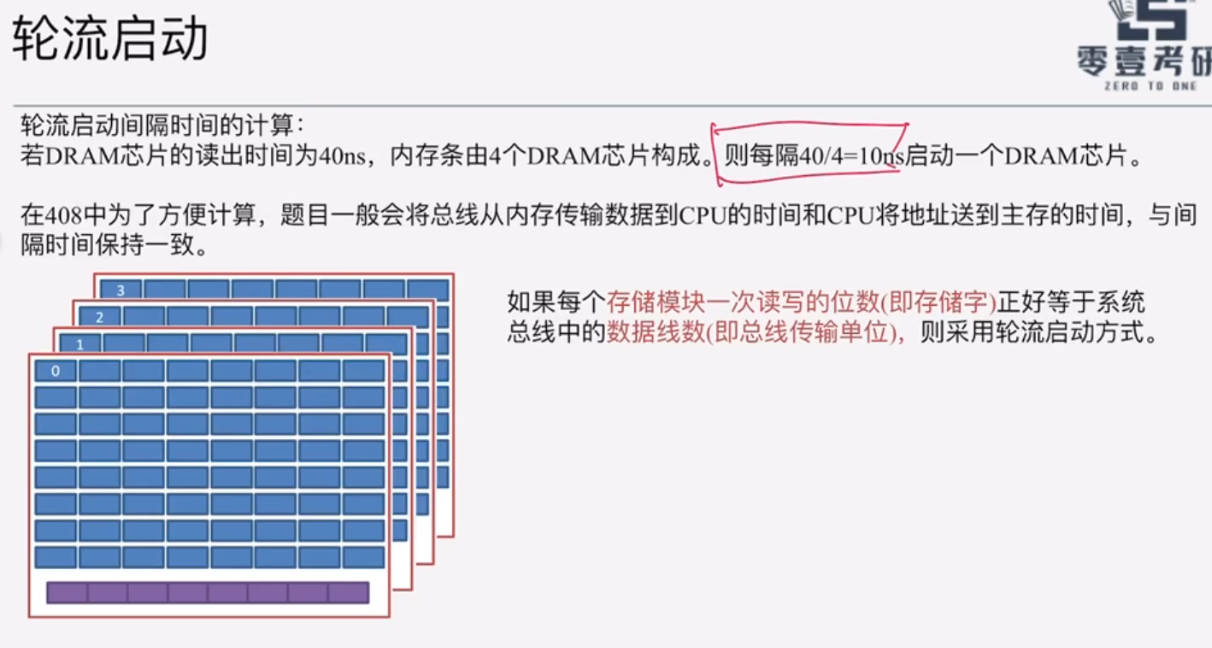
为了保持计算,以下三个时间均相等:
A. 总线周期:数据从数据线传输到CPU
B. 传送首地址和命令:CPU将首地址和读命令传送到内存控制器
C. 芯片启动的间隔时间
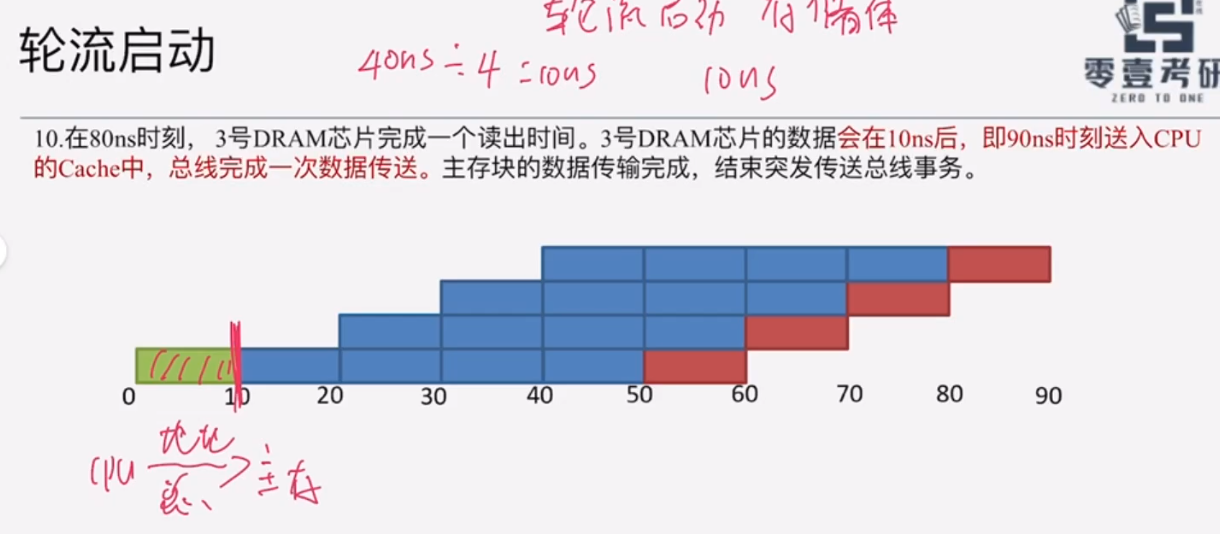
不算"传送地址到主存的时间",既:绿色的那一块。
后面的时间计算为:T+(n-1)*t,这里的T要加上总线周期
50ns+(4-1)*10ns=80ns
80ns+10ns=90ns
相关真题(都很重要)
1、2022年选择题

采用“同时启动”方式
B.支持突发传送,所以一定是:采用了多模块交叉编址
D.是列数*存储字长,不是行数
2、2013年43题

自己的答案:


第(4)题错了,纠正:
“Cache命中时的CPI是5ns” ≠ “Cache命中的时间为5ns”
而是:访问Cache的时间+指令执行完的时间,所以并不知道具体访问Cache的时间,而是将“访问Cache的指令的时间”平均到了每一条指令上,所以:相当于每一条指令都访问了Cache。
CPI定义:执行一条指令所需的时钟周期数。
自己的误区:我总是认为指令访问内存时才会访问Cache,但其实每条指令的执行都是默认优先访问Cache,所以:基本上每条指令都会访问Cache,题目中的访存次数就是Cache不命中时才访问的内存。
如果默认每条指令都要访问一次Cache(因为平均)的话,那么Cache命中的时间可以认为是每一条指令执行的时间。
整个题的时间=100条指令执行的时间+额外Cache不命中时带来的访存时间
100*5ns+100*0.05*85ns*1.2=1010ns
对比其他题目中的平均访问时间,因为并没有与指令向关联。
注意中的注意:Cache访问未命中时,也是要访问Cache的,所以未命中还得加上Cache命中的时间。