经典文献阅读之--SSR:(端到端的自动驾驶真的需要感知任务吗?)
0. 简介
端到端自动驾驶(E2EAD)方法通常依赖于监督感知任务来提取显式的场景信息(例如目标、地图)。这种依赖性需要代价高昂的标注,并且限制了实时应用中的部署和数据可扩展性。《DOES END-TO-END AUTONOMOUS DRIVING REALLY NEED PERCEPTION TASKS?》引入了SSR,这是一种仅使用16个导航引导的tokens作为稀疏场景表示的新框架,它为E2EAD高效地提取了关键场景信息。本文方法消除了对监督子任务的需求,允许计算资源集中在与导航意图直接相关的基本元素上。本文进一步引入了一种时间增强模块,它采用鸟瞰图(BEV)世界模型,通过自监督将预测的未来场景与实际的未来场景对齐。SSR在nuScenes数据集上实现了最先进的规划性能,相比于领先的E2EAD方法UniAD,L2误差相对减少了27.2%,碰撞率降低了51.6%。此外,SSR提供了10.9倍更快的推理速度和13倍更少的训练时间。该框架代表了实时自动驾驶系统的重大飞跃,并且为未来的可扩展部署铺平了道路。相关的代码将在Github上开源。有一说一这个工作还是挺有意思的,也许高纬度的信息对于轨迹判断更具有引导性。
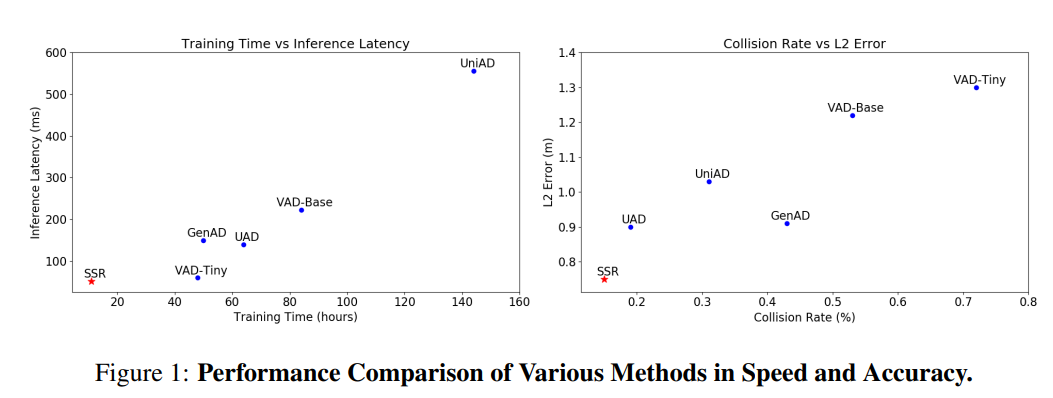
图1:各种方法在速度和准确性上的性能比较。
1. 主要贡献
如图2(a)所示,现有方法通常遵循之前的鸟瞰视图(BEV)感知范式,提取所有感知元素。这些方法依赖于Transformer(Vaswani et al., 2017)在额外的规划阶段识别相关元素。相比之下,如图2(b)所示,SSR直接在导航指令的指导下提取仅必要的感知元素,从而最小化冗余。我们的方法充分利用了端到端框架,以导航引导感知的方式打破了模块级级联架构。尽管之前的研究(Sun et al., 2024; Zhang et al., 2024)试图通过跳过BEV特征构建来减少计算,但它们仍然依赖于数百个特定任务的查询。然而,我们的方法通过仅使用16个由导航指令引导的标记,显著降低了计算开销。本文的贡献总结如下:
- 本文引入了一种受人类启发的E2EAD框架,它利用由导航指令引导的学习稀疏查询表示,通过自适应地聚焦于场景的基本部分来显著降低计算成本;
- 本文通过引入BEV世界模型对动态场景变化进行自监督来突出时间上下文在自动驾驶中的关键作用,消除了对代价高昂的感知任务监督的需求;
- 本文框架以最小的训练和推理成本在nuScenes数据集上实现了最先进的性能,为实时E2EAD建立了新的基准。
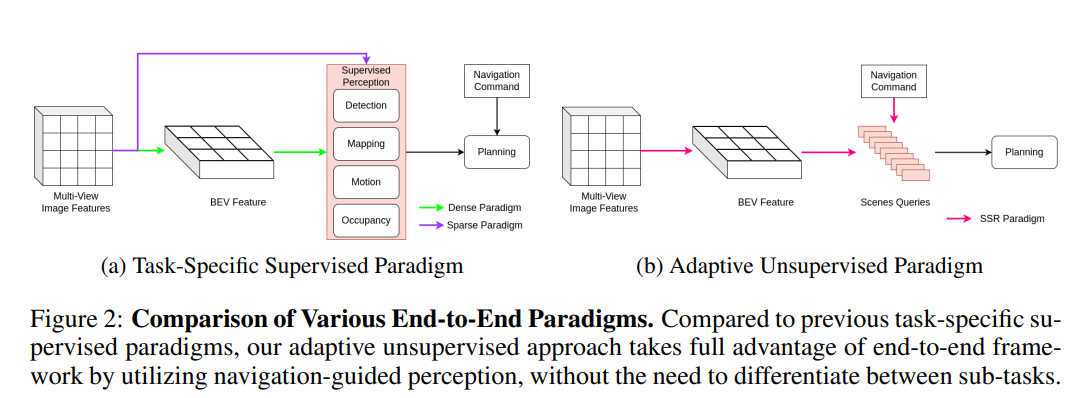
图2:各种端到端范式的比较。与之前的特定任务监督范式相比,我们的自适应无监督方法充分利用了端到端框架,通过利用导航引导的感知,无需区分子任务。
2. 概述
2.1 问题表述
在时间戳 t t t 时,给定周围的 N N N 视角相机图像 I t = [ I i t ] i = 1 N I_t = [I_i^t]_{i=1}^N It=[Iit]i=1N 和高层次导航指令 cmd,基于视觉的端到端自动驾驶(E2EAD)模型旨在预测规划轨迹 T T T,该轨迹由一组在鸟瞰视图(BEV)空间中的点组成。
2.2 BEV 特征构建
如图 3 所示, N N N 视角相机图像 I t I_t It 通过 BEV 编码器处理,以生成 BEV 特征。在 BEV 编码器(如 BEVFormer (Li et al., 2022b))中, I t I_t It 首先通过图像主干网络处理,以获得图像特征 F t = [ F i t ] i = 1 N F_t = [F_i^t]_{i=1}^N Ft=[Fit]i=1N。然后,使用一个 BEV 查询 Q ∈ R H × W × C Q \in \mathbb{R}^{H \times W \times C} Q∈RH×W×C 通过交叉注意力迭代地从前一帧的 BEV 特征 B t − 1 B_{t-1} Bt−1 中查询时间信息,并从 F t F_t Ft 中查询空间信息,从而得到当前的 BEV 特征 B t ∈ R H × W × C B_t \in \mathbb{R}^{H \times W \times C} Bt∈RH×W×C。这里, H × W H \times W H×W 表示 BEV 特征的空间维度, C C C 表示特征的通道维度。
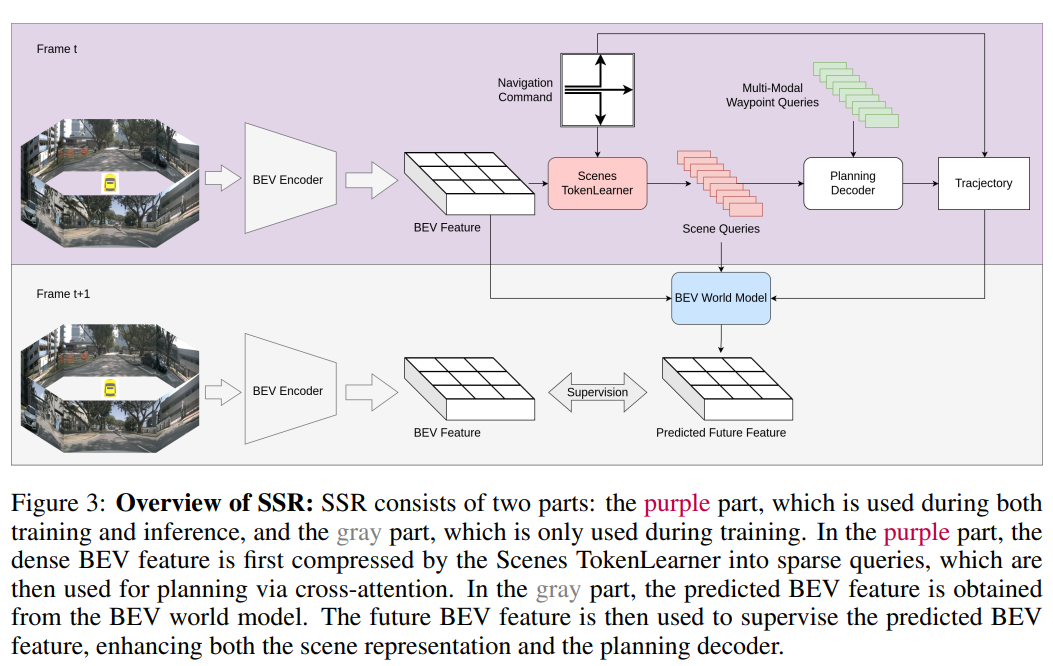
图 3:SSR 概述:SSR 由两个部分组成:紫色部分在训练和推理过程中均使用,而灰色部分仅在训练过程中使用。在紫色部分,密集的 BEV 特征首先通过场景令牌学习器(Scenes TokenLearner)压缩为稀疏查询,然后通过交叉注意力用于规划。在灰色部分,预测的 BEV 特征是从 BEV 世界模型中获得的。随后,未来的 BEV 特征被用来监督预测的 BEV 特征,从而增强场景表示和规划解码器的性能。
Q = CrossAttention ( Q , B t − 1 , B t − 1 ) , (1) Q = \text{CrossAttention}(Q, B_{t-1}, B_{t-1}), \tag{1} Q=CrossAttention(Q,Bt−1,Bt−1),(1)
B t = CrossAttention ( Q , F t , F t ) . (2) B_t = \text{CrossAttention}(Q, F_t, F_t). \tag{2} Bt=CrossAttention(Q,Ft,Ft).(2)
我们框架的关键组件是新颖的场景令牌学习模块(Scenes TokenLearner),用于提取重要的场景信息,详见第 3节。与依赖于密集 BEV 特征或数百个查询的传统方法不同,我们的方法使用一小组令牌有效地表示场景。利用这些稀疏场景令牌,我们生成规划轨迹,具体过程详见第4节。此外,在第5节中,我们介绍了一种增强的 BEV 世界模型,旨在通过自监督学习 BEV 特征进一步增强场景表示。
3. 导航引导场景令牌学习器(生成当前时刻结果)
BEV 特征是一种流行的场景表示方式,因为它们包含丰富的感知信息。然而,这种密集表示在搜索相关感知元素时会增加推理时间。为了解决这个问题,我们引入了一种使用自适应空间注意力的稀疏场景表示,显著降低了计算负担,同时保持高保真的场景理解。具体而言,我们提出了场景令牌学习器(Scenes TokenLearner, STL)模块,从 BEV 特征中提取场景查询 S t = [ s i ] i = 1 N s ∈ R N s × C S_t = [s_i]_{i=1}^{N_s} \in \mathbb{R}^{N_s \times C} St=[si]i=1Ns∈RNs×C,其中 N s N_s Ns 是场景查询的数量,以有效表示场景。场景令牌学习器的结构如图 4 所示。为了更好地关注与我们的导航意图相关的场景信息,我们采用了 Squeeze-and-Excitation (SE) 层(Hu et al., 2018)将导航命令 c m d cmd cmd 编码到密集的 BEV 特征中,生成导航感知的 BEV 特征 B t n a v i B^{navi}_t Btnavi:
B t n a v i = S E ( B t , c m d ) . ( 3 ) B^{navi}_t = SE(B_t, cmd). \quad (3) Btnavi=SE(Bt,cmd).(3)
然后,导航感知的 BEV 特征被传递到 BEV 令牌学习器(Ryoo et al., 2021)模块 T L B E V TL_{BEV} TLBEV,以自适应地关注最重要的信息。与之前在图像或视频领域应用 TokenLearner 的方式不同,我们在 BEV 空间中利用它,通过空间注意力推导出稀疏场景表示:
S t = T L B E V ( B t n a v i ) . ( 4 ) S_t = TL_{BEV}(B^{navi}_t). \quad (4) St=TLBEV(Btnavi).(4)
对于每个场景查询 s i s_i si,我们采用一个令牌化函数 M i M_i Mi,将 B t n a v i B^{navi}_t Btnavi 映射为一个令牌向量 R H × W × C → R C . \mathbb{R}^{H \times W \times C} \rightarrow \mathbb{R}^C. RH×W×C→RC.该令牌化器预测形状为 H × W × 1 H \times W \times 1 H×W×1 的空间注意力图,并通过全局平均池化获得学习到的场景令牌:
s i = M i ( B t n a v i ) = ρ ( B t n a v i ⊙ ω i ( B t n a v i ) ) , ( 5 ) s_i = M_i(B^{navi}_t) = \rho(B^{navi}_t \odot \omega_i(B^{navi}_t)), \quad (5) si=Mi(Btnavi)=ρ(Btnavi⊙ωi(Btnavi)),(5)
其中 ω ( ⋅ ) \omega(\cdot) ω(⋅) 是空间注意力函数, ρ ( ⋅ ) \rho(\cdot) ρ(⋅) 是全局平均池化函数。多层自注意力(Vaswani et al., 2017)被应用于进一步增强场景查询:
S t = S e l f A t t e n t i o n ( S t ) . ( 6 ) S_t = SelfAttention(S_t). \quad (6) St=SelfAttention(St).(6)
4. 基于稀疏场景表示的规划(监督当前时刻的结果差)
由于 S t S_t St 包含所有相关的感知信息,我们使用一组路径点查询 W t ∈ R N m × N t × C W_t \in \mathbb{R}^{N_m \times N_t \times C} Wt∈RNm×Nt×C 来提取多模态规划轨迹,其中 N t N_t Nt 是未来时间戳的数量, N m N_m Nm 表示驾驶命令的数量。
W t = C r o s s A t t e n t i o n ( W t , S t , S t ) . ( 7 ) W_t = CrossAttention(W_t, S_t, S_t). \quad (7) Wt=CrossAttention(Wt,St,St).(7)
然后,我们通过多层感知器(MLP)从 W t W_t Wt 中获得预测轨迹,并根据导航命令 c m d cmd cmd 选择输出轨迹 T ∈ R N t × 2 T \in \mathbb{R}^{N_t \times 2} T∈RNt×2:
T = S e l e c t ( M L P ( W t ) , c m d ) . ( 8 ) T = Select(MLP(W_t), cmd). \quad (8) T=Select(MLP(Wt),cmd).(8)
输出轨迹通过真实轨迹(GT)轨迹 T G T T_{GT} TGT 进行监督,使用 L1 损失进行定义,称为模仿损失 L i m i L_{imi} Limi:
L i m i = ∥ T G T − T ∥ 1 . ( 9 ) L_{imi} = \|T_{GT} - T\|_1. \quad (9) Limi=∥TGT−T∥1.(9)
5. 通过鸟瞰视角世界模型的时间增强(训练过程预测未来场景)
我们优先考虑时间上下文,通过世界模型增强场景表示,而非感知子任务。该模块的动机非常明确:如果我们预测的动作与实际动作相符,那么预测的未来场景应与实际未来场景密切相似。
如图4所示,我们引入鸟瞰视角世界模型(BWM)来预测未来的鸟瞰特征。首先,我们使用输出轨迹 T T T 将当前场景查询转换为未来帧,采用运动感知层归一化(MLN)(Wang et al., 2023a)。MLN模块帮助当前场景查询编码运动信息,生成梦境查询 D t D_t Dt:
D t = M L N ( S t , T ) . ( 10 ) D_t = MLN(S_t, T). \quad (10) Dt=MLN(St,T).(10)
对于梦境查询 D t D_t Dt,我们应用多层自注意力作为世界模型,以预测未来场景查询 S ^ t + 1 \hat{S}_{t+1} S^t+1:
S ^ t + 1 = S e l f A t t e n t i o n ( D t ) . ( 11 ) \hat{S}_{t+1} = SelfAttention(D_t). \quad (11) S^t+1=SelfAttention(Dt).(11)
然而,由于自动驾驶系统在连续帧中可能关注不同的区域,我们并不直接用未来场景查询 S t + 1 S_{t+1} St+1 来监督预测的场景查询 S ^ t + 1 \hat{S}_{t+1} S^t+1。相反,我们使用 TokenFuser(Ryoo et al., 2021)重建稠密的鸟瞰特征 B ^ t + 1 \hat{B}_{t+1} B^t+1:
B ^ t + 1 = T o k e n F u s e r ( S ^ t + 1 , B t ) = ψ ( B t ) ⊗ S ^ t + 1 , \begin{align}\hat{B}_{t+1} &= TokenFuser(\hat{S}_{t+1}, B_t) \tag{12} \\&= \psi(B_t) \otimes \hat{S}_{t+1}, \tag{13}\end{align} B^t+1=TokenFuser(S^t+1,Bt)=ψ(Bt)⊗S^t+1,(12)(13)
其中 ψ ( ⋅ ) \psi(\cdot) ψ(⋅) 是一个简单的多层感知器(MLP),使用 sigmoid 函数将鸟瞰特征 B t B_t Bt 重新映射为权重张量: R H × W × C → R H × W × N s \mathbb{R}^{H \times W \times C} \rightarrow \mathbb{R}^{H \times W \times N_s} RH×W×C→RH×W×Ns。在与 S ^ t + 1 ∈ R N s × C \hat{S}_{t+1} \in \mathbb{R}^{N_s \times C} S^t+1∈RNs×C 进行乘法运算 ⊗ \otimes ⊗ 后,我们获得预测的稠密鸟瞰特征 B ^ t + 1 ∈ R H × W × C \hat{B}_{t+1} \in \mathbb{R}^{H \times W \times C} B^t+1∈RH×W×C。该过程旨在从预测的场景查询中恢复鸟瞰特征,以便进行进一步的自我监督。
最后,我们使用 L2 损失对 B ^ t + 1 \hat{B}_{t+1} B^t+1 进行监督,该损失与由未来周围图像生成的真实未来鸟瞰特征 B t + 1 B_{t+1} Bt+1 进行比较。这被定义为鸟瞰重建损失 L b e v L_{bev} Lbev:
L b e v = ∥ B ^ t + 1 − B t + 1 ∥ 2 . ( 14 ) L_{bev} = \|\hat{B}_{t+1} - B_{t+1}\|_2. \quad (14) Lbev=∥B^t+1−Bt+1∥2.(14)
总之,我们对预测轨迹应用模仿损失 L i m i L_{imi} Limi,对预测的鸟瞰特征应用鸟瞰重建损失 L b e v L_{bev} Lbev。稀疏场景表示的总损失为:
L t o t a l = L i m i + L b e v . ( 15 ) L_{total} = L_{imi} + L_{bev}. \quad (15) Ltotal=Limi+Lbev.(15)

图5:场景查询的鸟瞰视角注意力图可视化。展示了16个学习到的标记中8个的注意力图。自我车辆位于中心位置,上方方向表示自我车辆的前方。较亮的区域代表更高的注意力权重。完整的图集见附录A.1。
图6:不同场景中的总注意力图。 FR:帧编号。
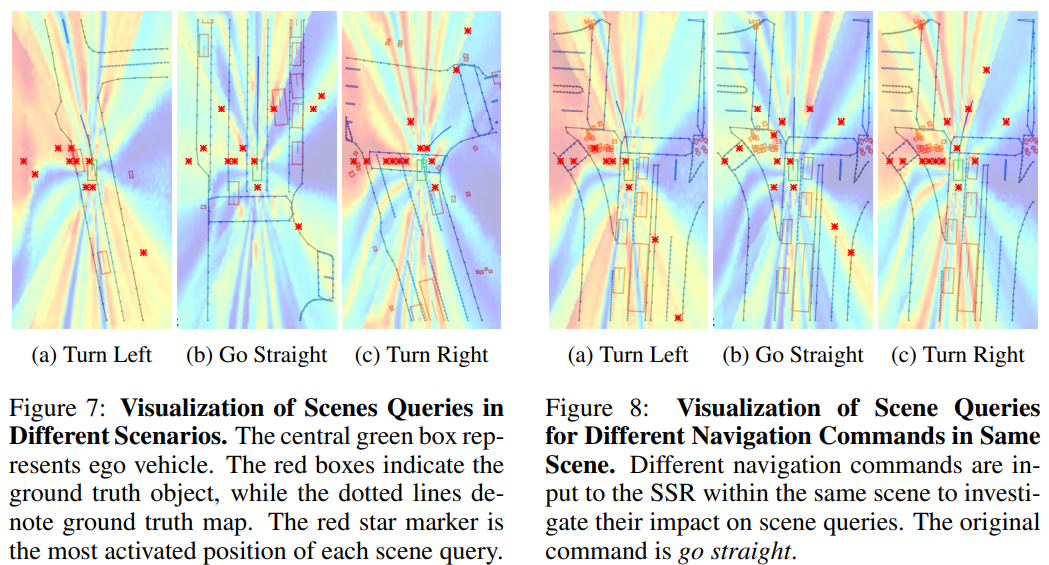
图7:不同场景中场景查询的可视化。中央的绿色框表示自我车辆。红色框表示真实物体,而虚线表示真实地图。红色星形标记是每个场景查询中激活程度最高的位置。
图8:同一场景中不同导航指令的场景查询可视化。将不同的导航指令输入到同一场景中的SSR,以研究它们对场景查询的影响。原始指令为“直行”。
6. 总结
SSR框架在端到端自动驾驶(E2EAD)领域中展现了显著的进步,挑战了传统对感知任务的依赖。通过利用导航引导的稀疏标记和时间自我监督,SSR克服了以感知为重的架构的局限性,以最小的成本实现了最先进的性能。此外,稀疏标记的可视化增强了SSR导航引导过程的可解释性和透明度。我们希望SSR能够为可扩展、可解释和高效的自动驾驶系统提供坚实的基础。