【知识】性能优化和内存优化的主要方向
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
前言
现在有很多论文,乍一看很高级,实际上一搜全是现有技术的堆砌,但是这种裁缝式的论文依然能发表在很好的会议和期刊上,一部分原因是运气好遇到了懂得不全的审稿人。所以,你知道的优化方向越多,那你发顶会顶刊的机会也就更高(手动狗头)。
以下内容直接来自:Graphcore Documents — Graphcore Documents
性能优化
内存Memory
通常,更高效的内存使用将转化为训练和推理期间的性能改进。更好的优化内存意味着可以使用更大的批处理大小,从而提高推理和训练的吞吐量。当有更多临时内存可用时,需要在多个步骤中序列化的大型作(例如 matmul 和卷积)可以在更少的周期内执行。当有更多的处理器内存可用时,这减少了访问较慢流内存的需要。
流水线Pipeline
通过运行数据流水线来最大化GPU/CPU的利用率、重叠计算和通信阶段。一旦建立了流水线,总是有不止一个微批次“在运行”。
在训练期间,流水线为前向和后向的通道提供了两种选择:
- 分组
- 交错
分组调度通常更快,但比交错调度需要更多的内存来存储激活:
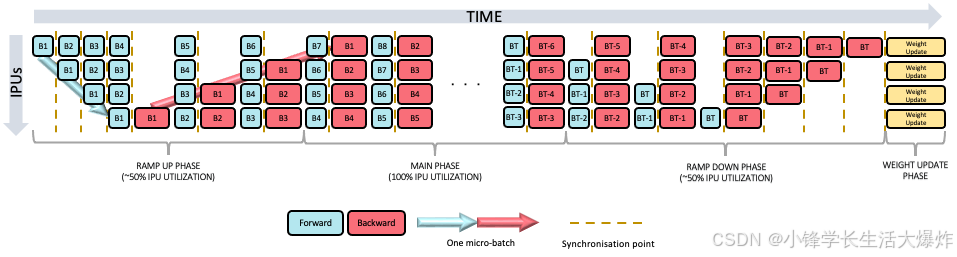
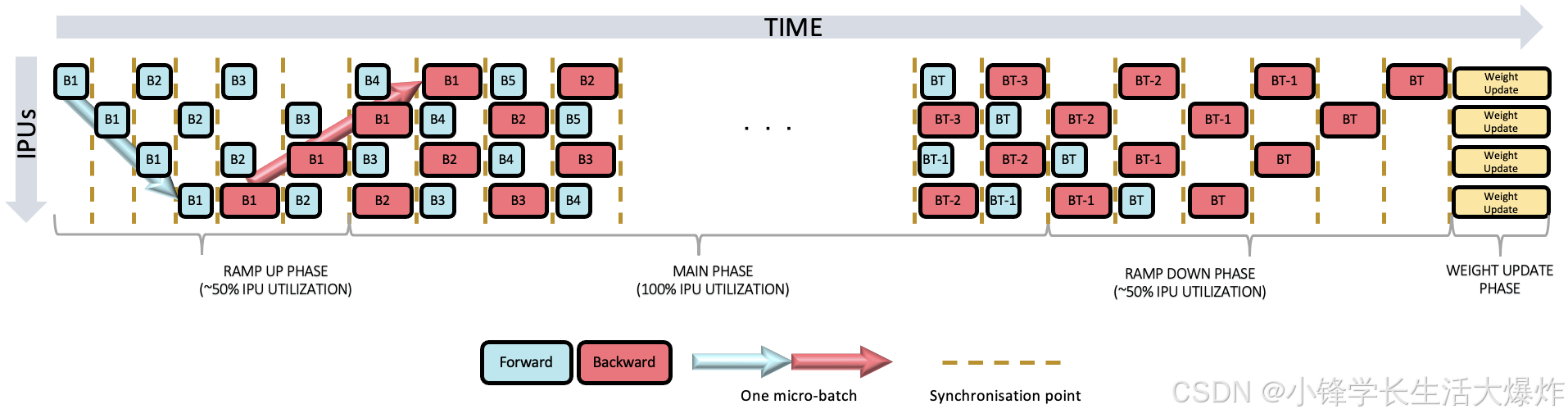
交错调度使用更少的内存来存储激活,但可能会更慢,因为向后传递通常比向前传递长,总是在管道的每个阶段执行:
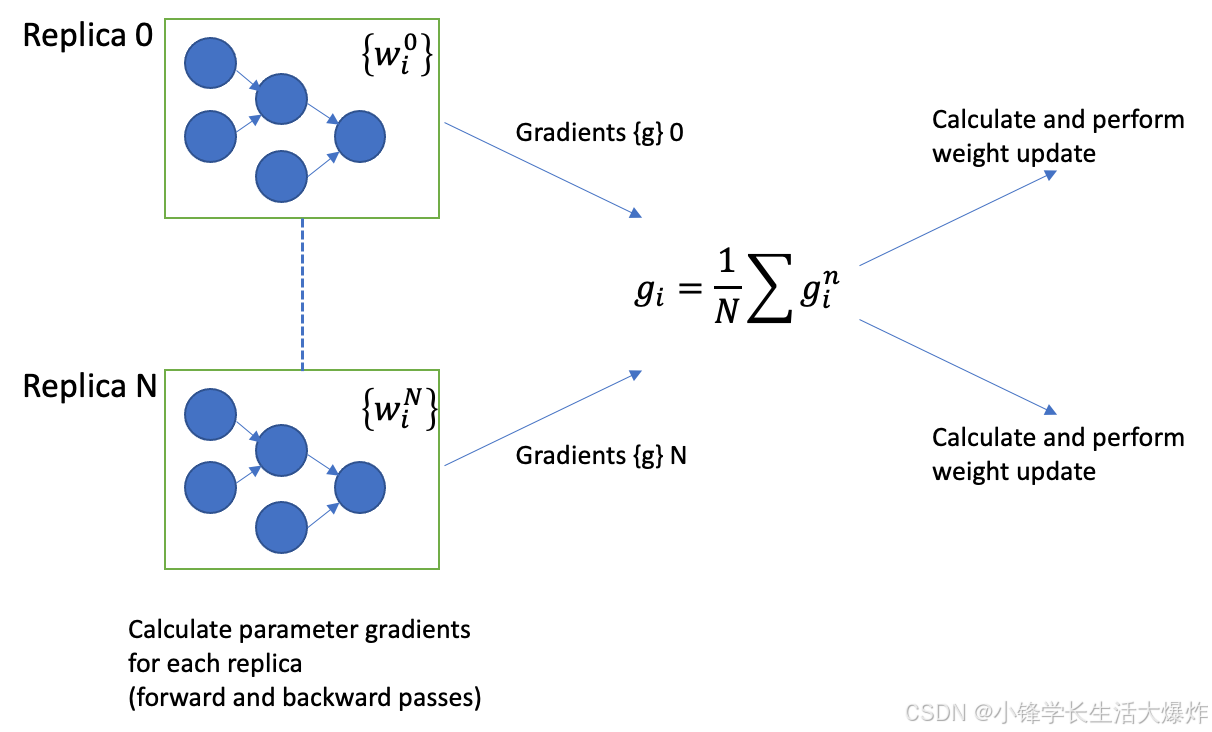
数据并行性
在模型足够小,但数据集很大的情况下,可以应用数据并行的概念。这意味着相同的模型被加载到每个GPU上,但数据在GPU之间被拆分。数据并行是执行分布式训练的最常见方法。副本通常跨越多个GPU,甚至系统。跨副本引入了更多通信,并引入了性能开销。通信开销的相对影响可以通过使用更大的副本批量来减少,通常是通过增加梯度积累。
I/O优化
GPU-CPU内存的访问方式会影响性能。
-
预取和预取深度
-
I/O与计算重叠
-
缩小数据精度
-
禁用变量卸载
内存优化
激活的重新计算
在使用反向传播训练的神经网络中,需要存储前向传递期间计算的激活,以便在后向传递中重复使用。这是计算相对于激活值的梯度所必需的。这是有问题的,因为在 forward pass 期间存储这些激活会使用始终有效的内存,并且内存量会随着微批处理大小而线性增长。

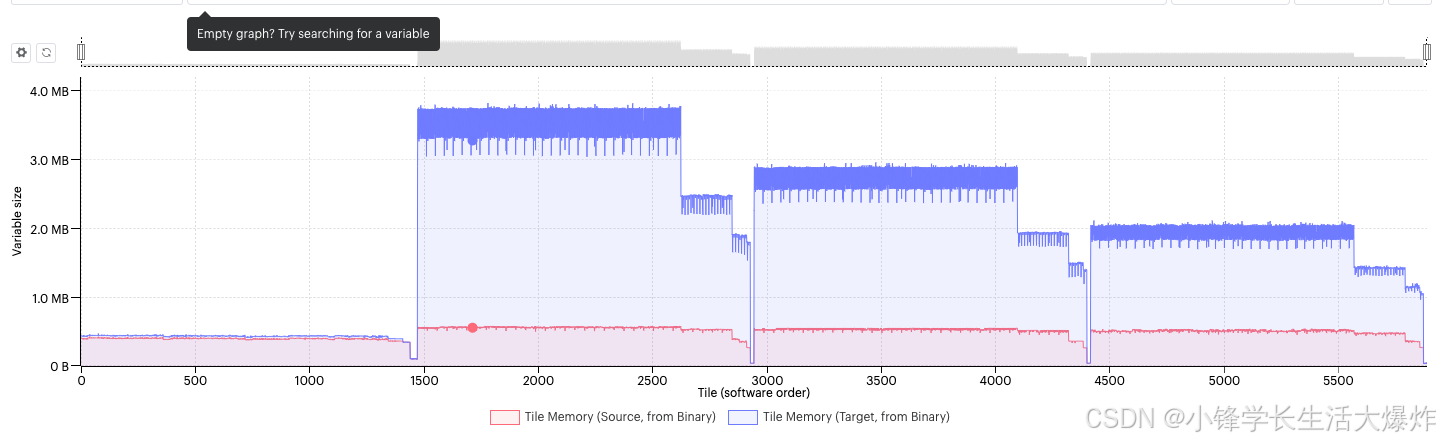
重新计算检查点
Recomputation checkpoints 是计算图中存储所有激活的点。从该点开始,图形中的任何激活都将从之前的检查点值重新计算,并存储在非始终有效的内存中,直到下一个检查点。图形中的检查点位置可以由框架自动设置,也可以手动插入。仔细引入 recomputation checkpoints,无论模型是否是流水线的,都大大节省了 always-live 内存,因为节省的内存量对应于两个 checkpoint 之间的所有激活 FIFOs。权衡是计算周期的增加。实际上,在两个重新计算检查点之间,向后传递被向前和向后传递替换。根据经验,向后传递需要的周期数是向前传递的 2 到 2.2 倍。
在推理模式下,永远不会存储中间激活,因此不需要重新计算。
变量卸载
优化器状态参数(例如,ADAM 中的第一和第二矩)在训练期间始终存在于内存中。还可以将这些卸载到主机以节省 GPU 内存。优化器状态仅在权重更新步骤的开始(从主机到 GPU)和结束时(从 GPU 到主机)传输一次,因此通信损失比传输模型参数要小得多。将变量卸载到主机将创建一些 exchange 代码,其大小很难估计。它还将使用临时(并不总是实时的)数据存储器来存储来自主机和主机的输入和输出缓冲区。
减小批处理
在某些应用中,可以使用较小的批处理大小来减少内存需求。如果减少用于训练的全局批量大小(即权重更新之间处理的样本总数),则还应降低学习率。研究发现,按与批量大小相同的因子缩放学习率是有效的。有一些操作(例如批量规范化)是跨小批量计算的。减小批处理大小时,这些操作的性能可能会降低。如果这会导致问题,可以选择将批量标准化替换为组、层或实例标准化。
编写自定义操作
如果模型中有一个使用大量内存的特定作,可能会发现使用使用较少内存的较低级别库编写自定义作很有用。