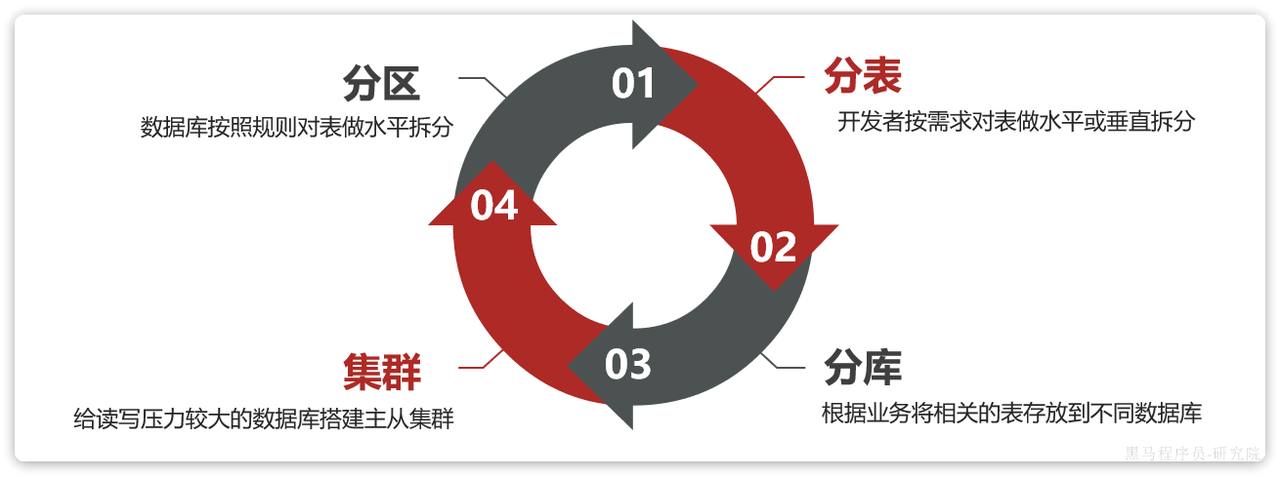
海量数据存储策略
对于数据库的海量数据存储,方案有很多,常见的有:
2.1.1.分区
表分区(Partition)是一种数据存储方案,可以解决单表数据较多的问题。MySQL5.1开始支持表分区功能。
数据库的表最终肯定是保存在磁盘中,对于InoDB引擎,一张表的数据在磁盘上对应一个ibd文件。如图,我们的积分榜单表对应的文件: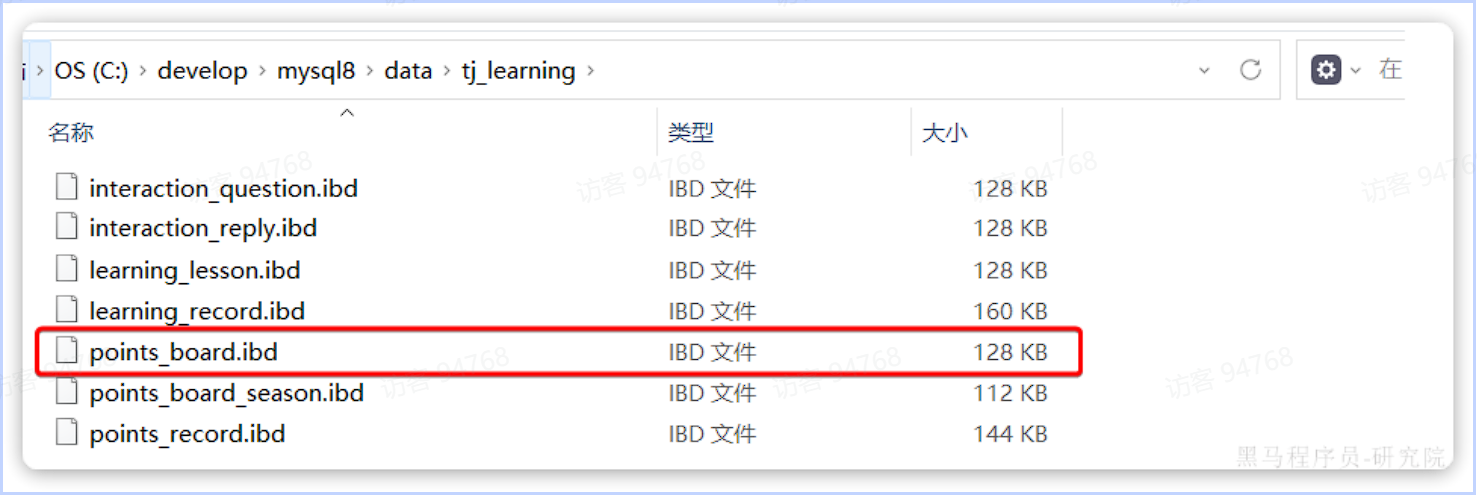
如果表数据过多,就会导致文件体积非常大。文件就会跨越多个磁盘分区,数据检索时的速度就会非常慢。
为了解决这个问题,MySQL在5.1版本引入表分区功能。简单来说,就是按照某种规则,把表数据对应的ibd文件拆分成多个文件来存储。从物理上来看,一张表的数据被拆到多个表文件存储了;从逻辑上来看,他们对外表现是一张表。
例如,我们的历史榜单数据,可以按照赛季切分:
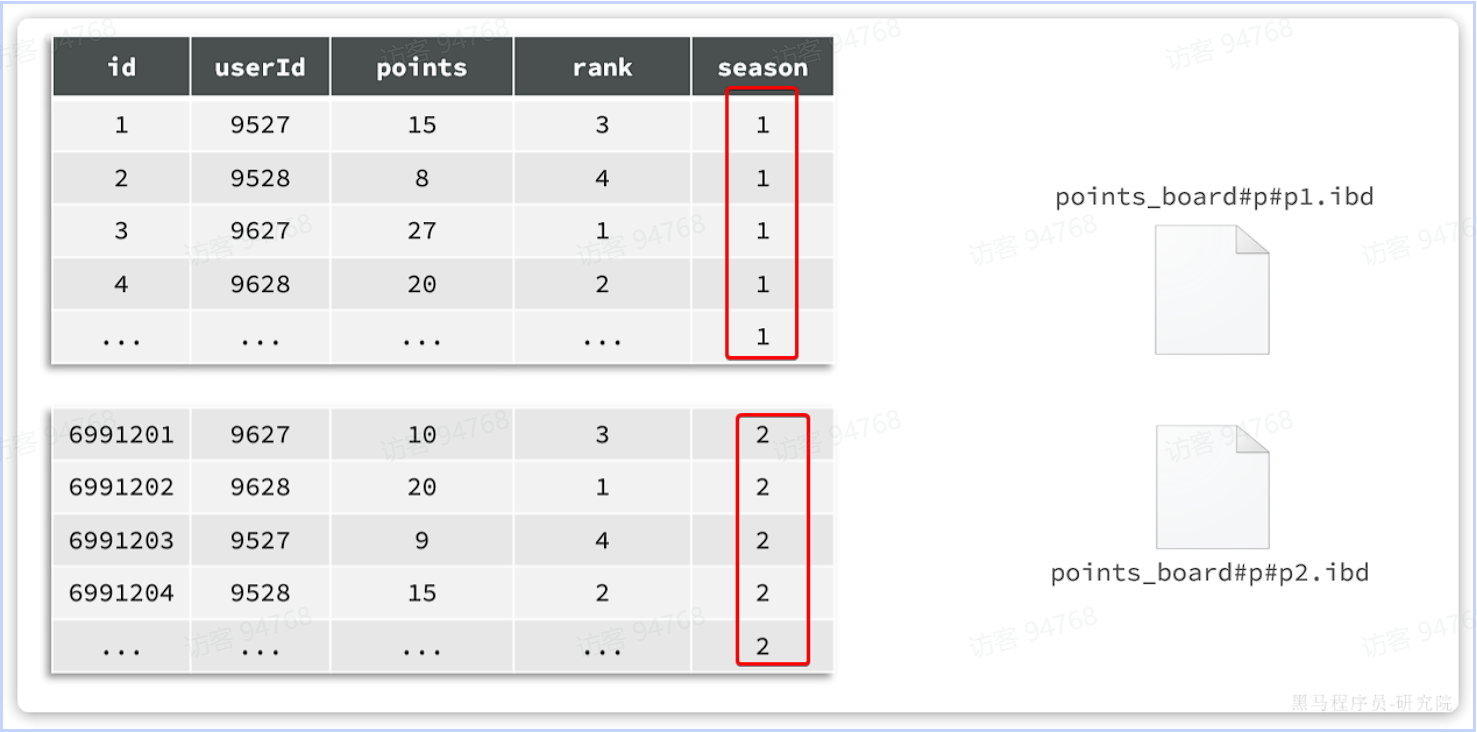
此时,赛季榜单表的磁盘文件就被分成了两个文件。但逻辑上还是一张表。增删改查的方式不会有什么变化,只不过底层MySQL底层的处理上会有变更。例如检索时可以只检索某个文件,而不是全部。
这样做有几个好处:
-
可以存储更多的数据,突破单表上限。甚至可以存储到不同磁盘,突破磁盘上限
-
查询时可以根据规则只检索某一个文件,提高查询效率
-
数据统计时,可以多文件并行统计,最后汇总结果,提高统计效率
-
对于一些历史数据,如果不需要时,可以直接删除分区文件,提高删除效率
表分区的本质是对数据的水平拆分,而拆分的方式也有多种,常见的有:
-
Range分区:按照指定字段的取值范围分区
-
List分区:按照指定字段的枚举值分区,必须提前指定好所有的分区值,如果数据找不到分区会报错
-
Hash分区:基于字段做hash运算后分区,一般做hash运算的字段都是数值类型
-
Key分区:根据指定字段的值做运算的结果分区,与hash分区类似,但不限定字段类型
对于赛季榜单来说,最合适的分区方式是基于赛季值分区,我们希望同一个赛季放到一个分区。这就只能使用List分区,而List分区却需要枚举出所有可能的分区值。但是赛季分区id是无限的,无法全部枚举,所以就非常尴尬。
MySQL的表分区详细信息可参考下面的文档:
https://www.cnblogs.com/wenxuehai/p/15901779.html
2.1.2.分表
分表是一种表设计方案,由开发者在创建表时按照自己的业务需求拆分表。也就是说这是开发者自己对表的处理,与数据库无关。
而且,一旦做了分表,无论是逻辑上,还是物理上,就从一张表变成了多张表!增删改查的方式就发生了变化,必须自己考虑要去哪张表做数据处理。
分区则在逻辑上是同一张表,增删改查与以前没有区别。这就是分区和分表最大的一种区别。
2.1.2.1.水平分表
例如,对于赛季榜单,我们可以按照赛季拆分为多张表,每一个赛季一张新的表。如图:
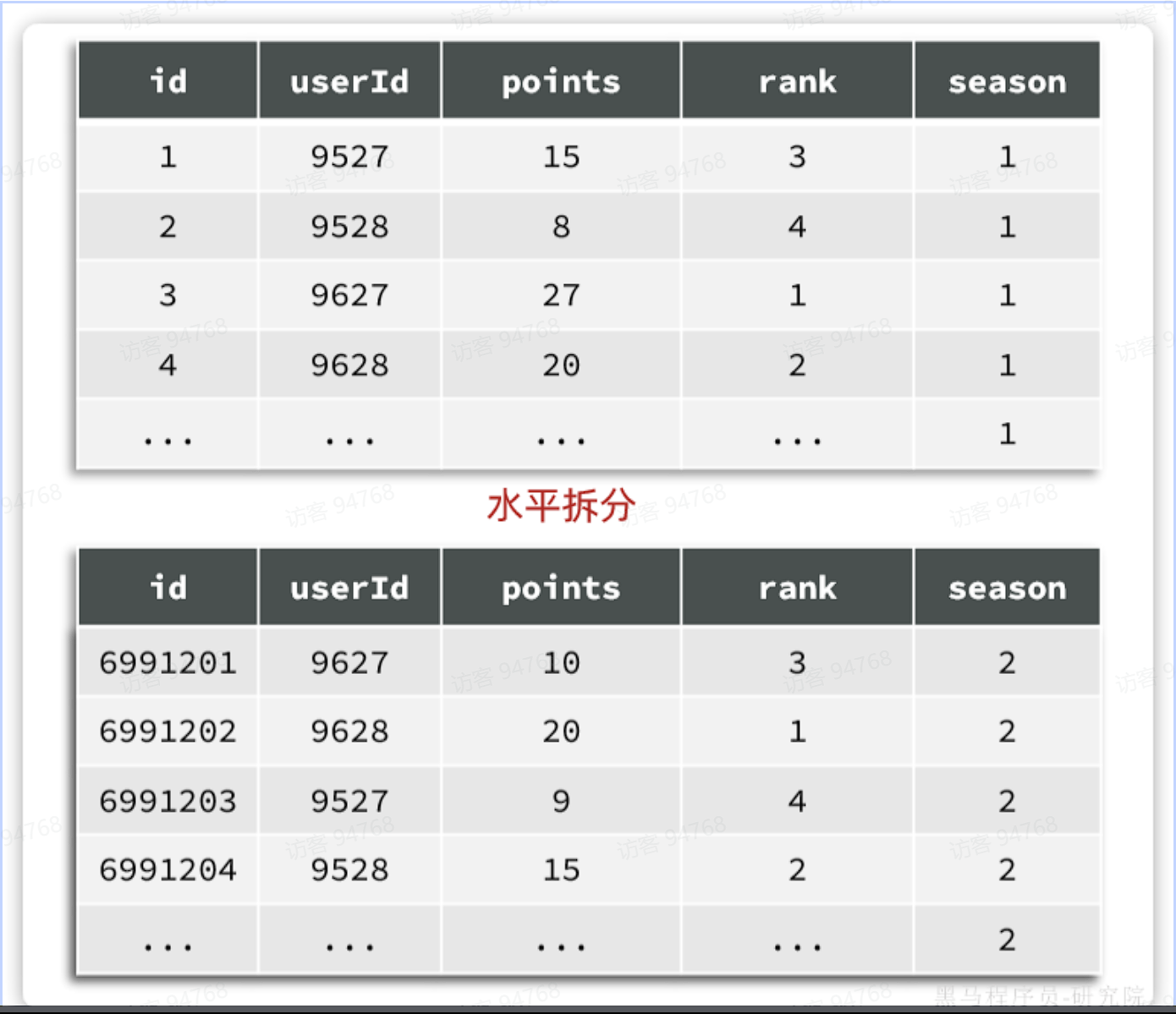
这种方式就是水平分表,表结构不变,仅仅是每张表数据不同。查询赛季1,就找第一张表。查询赛季2,就找第二张表。
由于分表是开发者的行为,因此拆分方式更加灵活。除了水平分表,也可以做垂直分表。
2.1.2.2.垂直分表
什么是垂直分表呢?
如果一张表的字段非常多,比如达到30个以上,这样的表我们称为宽表。宽表由于字段太多,单行数据体积就会非常大,虽然数据不多,但可能表体积也会非常大!从而影响查询效率。
例如一个用户信息表,除了用户基本信息,还包含很多其它功能信息:

这个时候,我们就可以把其中的一些不常用字段拆分出去。一张表中包含登录常用字段,另一张表包含其它字段:

这个时候一张表就变成了两张表。而且两张表的结构不同,数据也不同。这种按照字段拆分表的方式,称为垂直拆分。
2.1.2.3.优缺点
分表方案与分区方案相比有一些优点:
-
拆分方式更加灵活
-
而且可以解决单表字段过多的问题
但是也有一些确定:
-
增删改查时,需要自己判断访问哪张表
-
垂直拆分还会导致事务问题及数据关联问题:原本一张表的操作,变为多张表操作。
不过,在开发中我们很多情况下业务需求复杂,更看重分表的灵活性。因此,我们大多数情况下都会选择分表方案。
2.1.3.分库和集群
无论是分区,还是分表,我们刚才的分析都是建立在单个数据库的基础上。但是单个数据库也存在一些问题:
-
单点故障问题:数据库发生故障,整个系统就会瘫痪
-
单库的性能瓶颈问题:单库受服务器限制,其网络带宽、CPU、连接数都有瓶颈
-
单库的存储瓶颈问题:单库的磁盘空间有上限,如果磁盘过大,数据检索的速度又会变慢
综上,在大型系统中,我们除了要做分表、还需要对数据做分库,建立综合集群。
首先,在微服务项目中,我们会按照项目模块,每个微服务使用独立的数据库,因此每个库的表是不同的,这种分库模式成为垂直分库。
而为了保证单节点的高可用性,我们会给数据库建立主从集群,主节点向从节点同步数据。两者结构一样,可以看做是水平扩展。
这个时候就会出现垂直分库、水平扩展的综合集群,如图:
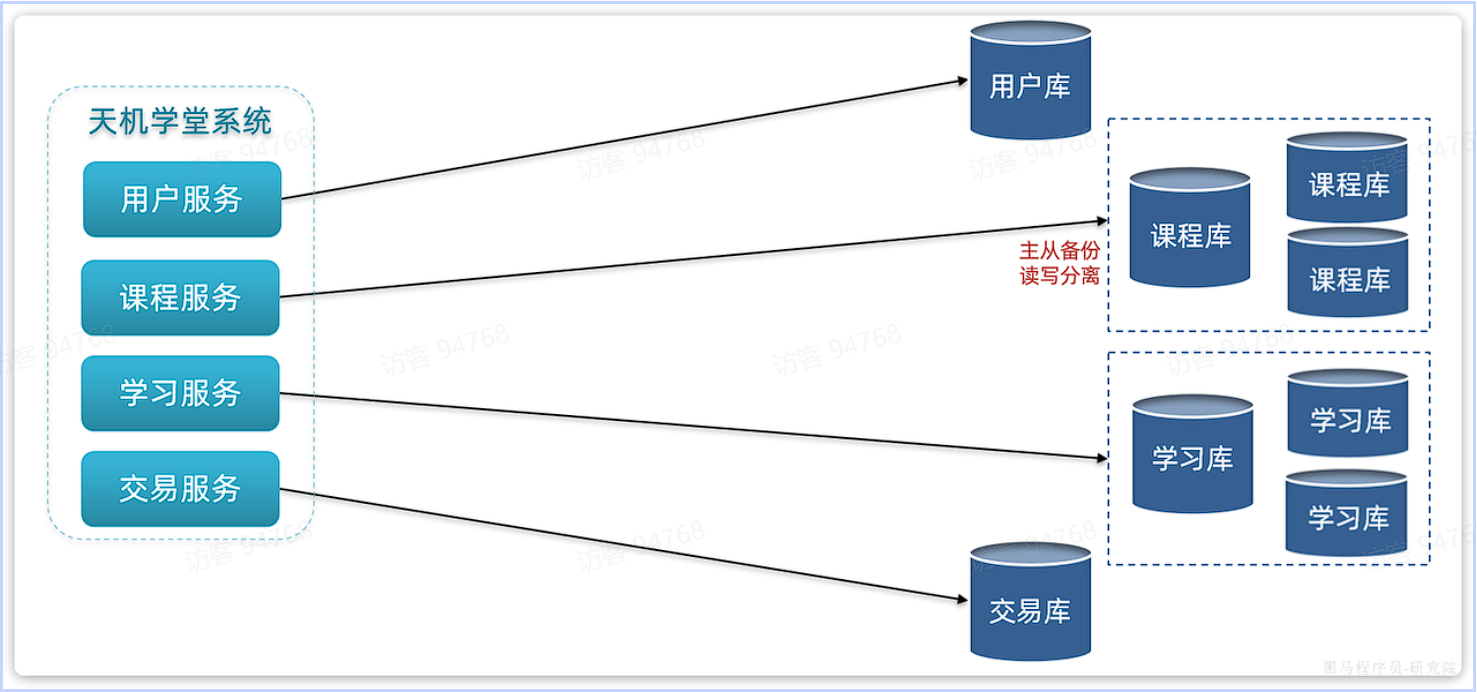
这种模式的优缺点:
优点:
-
解决了海量数据存储问题,突破了单机存储瓶颈
-
提高了并发能力,突破了单机性能瓶颈
-
避免了单点故障
缺点:
-
成本非常高
-
数据聚合统计比较麻烦
-
主从同步的一致性问题
-
分布式事务问题