spark和Hadoop之间的对比和联系
一、核心定位与架构差异
-
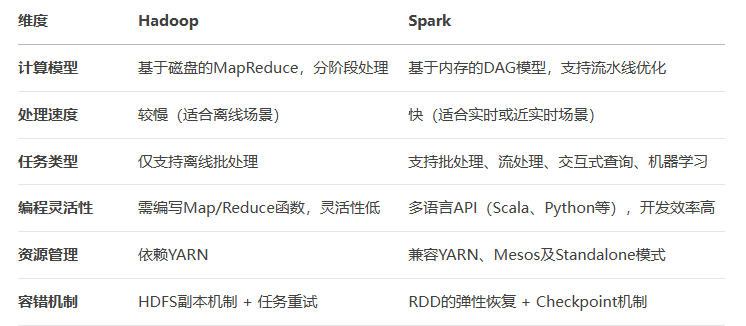
Hadoop
-
定位:分布式存储与离线批处理的基础框架,核心组件包括HDFS(存储)和MapReduce(计算),适合海量数据的低成本存储及离线处理(如日志分析、ETL)。
-
架构特点:依赖磁盘存储,任务分Map和Reduce两阶段,中间结果需写入HDFS,导致I/O开销大、速度较慢。
-
-
Spark
-
定位:专注于高效计算的分布式引擎,支持批处理、实时流处理、机器学习等多场景,核心基于内存计算和弹性分布式数据集(RDD)。
-
架构特点:通过DAG(有向无环图)优化任务调度,减少磁盘I/O,速度通常比Hadoop快10-100倍,适合实时或迭代计算(如机器学习、图计算)。
-
二、联系与互补性
-
技术栈互补
-
存储层依赖:Spark可直接读取HDFS数据,无需独立存储系统,降低架构复杂度。
-
资源管理整合:Spark可运行在YARN上,复用Hadoop的集群资源调度能力。
-
-
生态协同
-
Hadoop生态扩展:Hive、HBase等工具可与Spark集成,例如Hive on Spark提升查询性能。
-
实时+离线混合架构:如Kafka接入实时数据,Spark Streaming处理后将结果写入HDFS或HBase,形成全链路分析。
-
-
典型场景分工
-
Hadoop主导:长期数据存储、高容错性离线批处理(如历史日志归档)。
-
Spark主导:实时监控、交互式分析(如电商推荐系统)、复杂迭代计算(如PageRank算法)。
-
三、总结与选择建议
-
选择Hadoop:若需求为低成本存储或简单离线批处理,且对实时性要求低。
-
选择Spark:若涉及实时计算、机器学习等复杂场景,需高性能和灵活性。
-
组合使用:实际架构中常采用“HDFS存储 + Spark计算”模式,例如HDFS存储原始数据,Spark进行实时分析和模型训练。