性能比拼: Redis vs Dragonfly
本内容是对知名性能评测博主 Anton Putra Redis vs Dragonfly Performance (Latency - Throughput - Saturation) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准
在本视频中,我们将对比 Redis 和 Dragonfly。我们将观察 set 与 get 操作的延迟,重点关注 P99 百分位。这两个操作可能是你在使用任何缓存时最常用的操作。
我们还将查看吞吐量(THR 输出),了解每个数据库每秒能够处理多少请求,并验证 Dragonfly 声称其吞吐量是 Redis 的 25 倍的说法。
此外,我们还将测量两个数据库的 CPU 使用率、内存使用率和网络吞吐量。
第一次测试:基础测试

为了建立基准,我们将在每个缓存上使用 m7a.medium EC2 实例,它配备一个虚拟 CPU 和 4GB 内存。我们将使用 EKS 集群部署客户端来生成负载。
Dragonfly 最大的卖点是它能够使用多个 CPU 核心,使其更容易进行垂直扩展。因此在第二次测试中,我将为 Dragonfly 使用 m7a.xlarge 实例,它拥有 4 个虚拟 CPU 和 16GB 内存。
由于 Redis 大多是单线程的,因此我会采用水平扩展的方式来扩展 Redis。我将使用四个 m7a.medium 实例组成一个由四个 master 节点构成的集群,以匹配 Dragonfly 的 4 个 CPU 和 16GB 内存的容量。
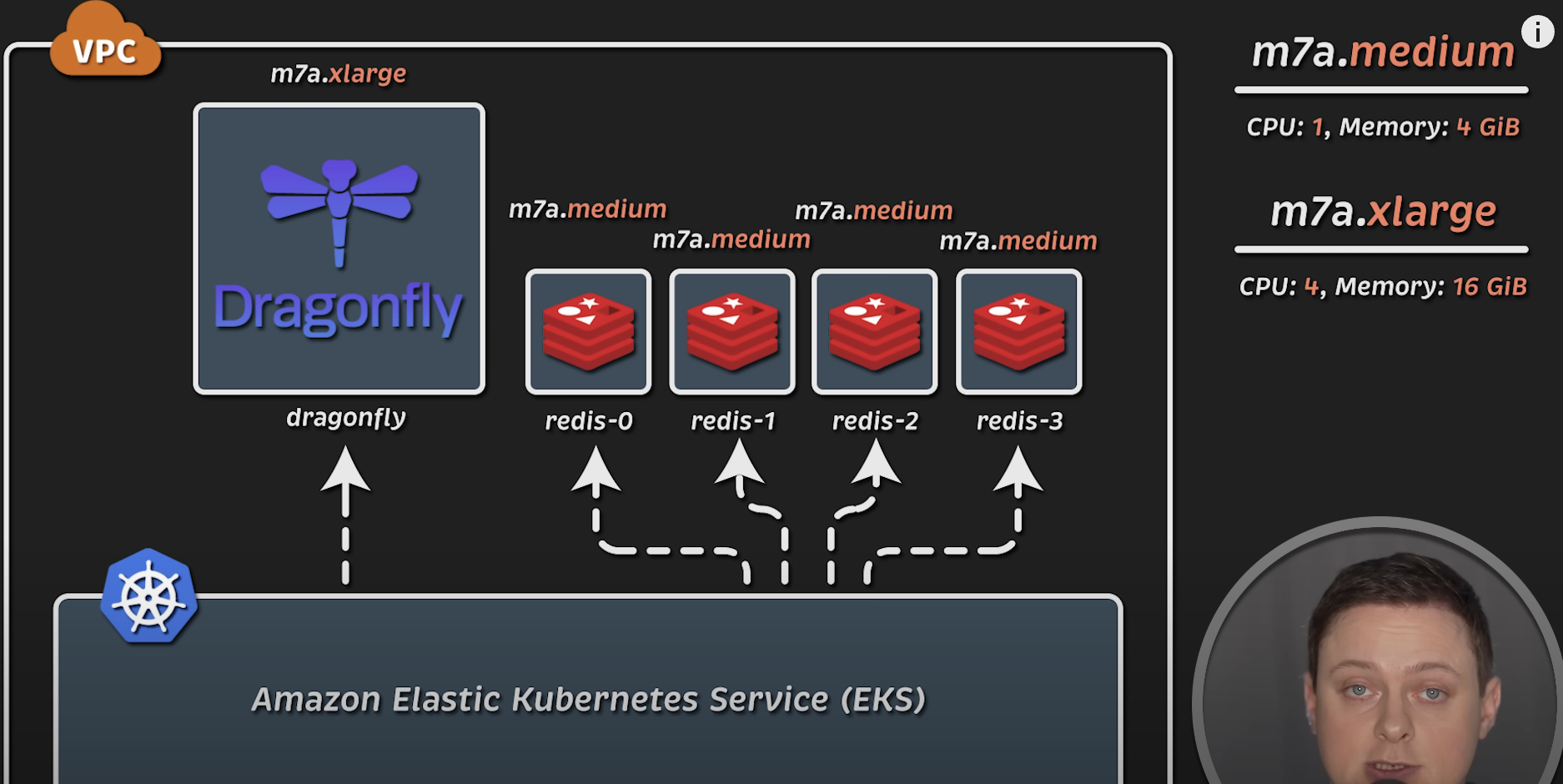
如你从 AWS 控制台看到的,第一次测试中我为两个数据库都使用了中型实例,并为 EKS 集群使用了三个 xlarge 实例,用于部署监控组件(如 Prometheus 和 Grafana),以及部署客户端以生成负载。而在第二次测试中,我将 EKS 扩展到四个节点,为 Dragonfly 使用 xlarge 实例,为 Redis 集群使用 medium 实例。
AWS 成本很高,因此我希望通过提供一对一的技术支持服务来支持我的频道并支付基础设施费用。详情请见视频描述。
Redis 集群设计
由于 Redis 多数情况下只使用单线程,因此扩展 Redis 需要使用集群。一个典型的生产集群由六个节点组成:三个 master 接受所有请求,并将数据复制到其后面的副本节点。客户端使用哈希函数(hash function)来决定将请求发送到哪一个节点。
如果一个 master 故障了,副本节点会被提升为 master,客户端不会察觉任何变化。这就是所谓的高可用(High Availability)。为了使集群正常工作,master 节点的数量应为奇数(例如 3、5、7 等),这样即便一个 master 故障,仍有多数可决定将副本提升为 master。
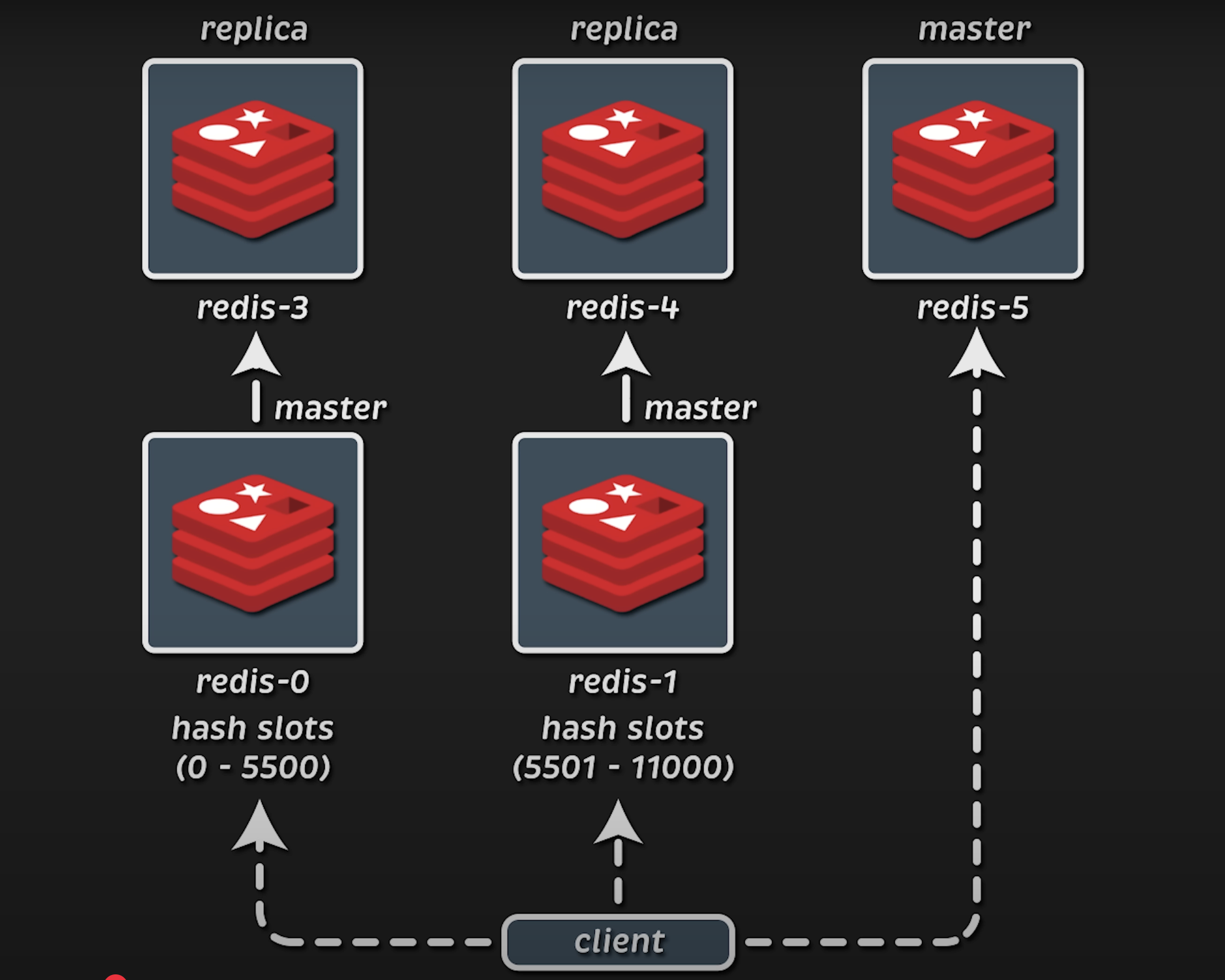
当然,如果你不需要高可用性(即只是把 Redis 当作缓存使用),一旦数据缺失,应用可以从别的地方(如数据库)重新获取数据,那么也可以不设置副本。此时你可以将 cluster-replicas 属性设置为 0,这样可以将基础设施成本减半。

所以在这次测试中,为了匹配 Dragonfly 的 4 个 CPU,我使用了一个由四个 master 组成、不含副本的 Redis 集群。
Dragonfly 的已知问题
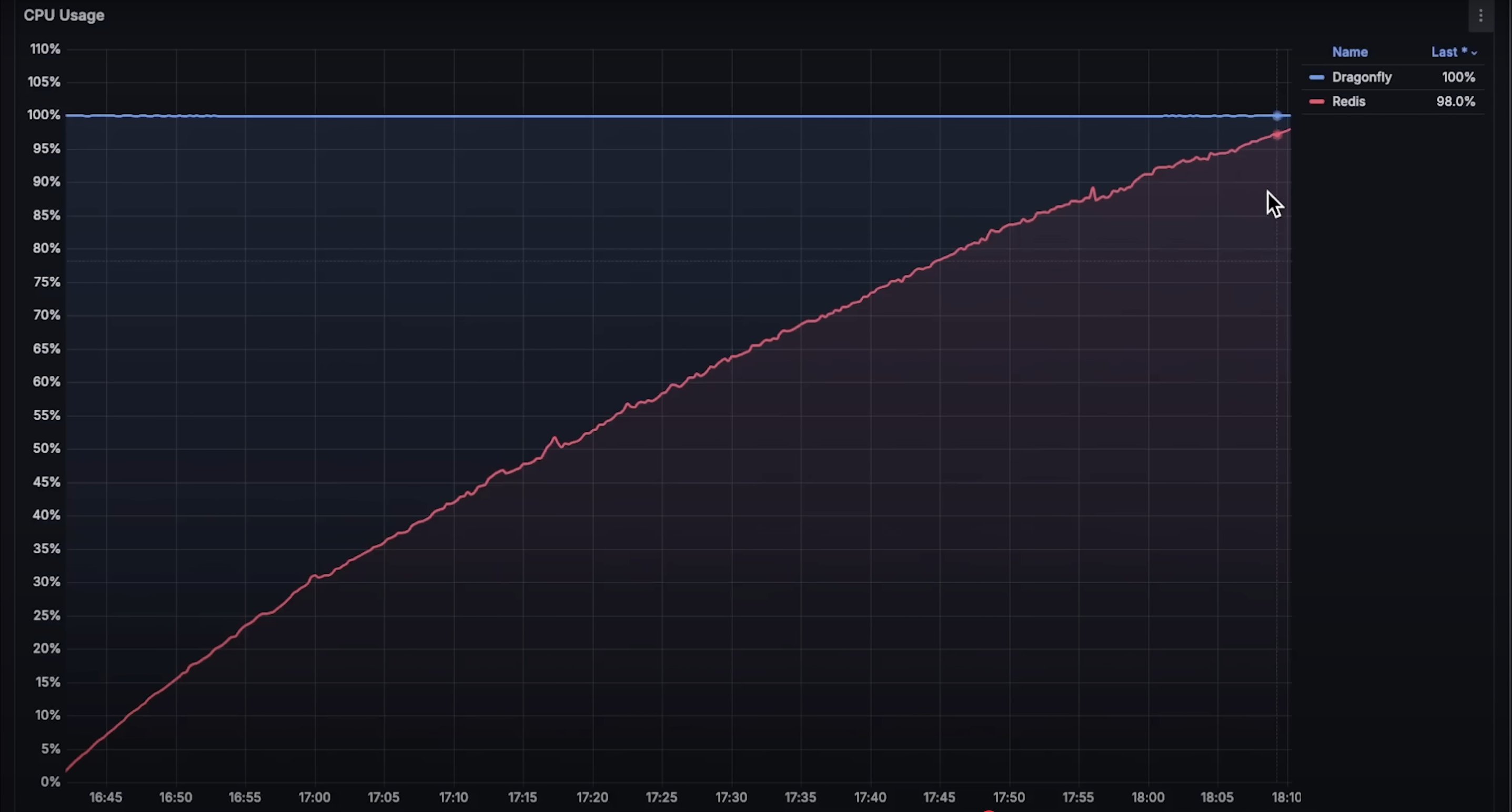
Dragonfly 存在一个已知问题:当使用某些监控系统(如 Prometheus)时,CPU 使用率会异常偏高。这个问题是由于 Dragonfly 使用了相对较新的 io_uring API,即使是网络操作也会被标记为 IO 等待(iowait),从而阻塞 CPU 使用率的准确显示。至少这是 Dragonfly 开发者的解释。
我在之前也对使用相同 API 的框架做过基准测试,但没有观察到这种行为。
虽然有一些解决方案,但从运维角度来看,你需要为这个数据库单独创建一套仪表盘和告警系统,这并不理想。这个问题似乎在新版内核中已被解决,但在此之前仍可以忽略,并不会影响 Dragonfly 的性能表现。
软件版本和配置
我使用的 Redis 版本是 7.4.1,Dragonfly 版本是 1.125.4。
我从 GitHub 下载了 Dragonfly 的 Debian 安装包,该版本已开启所有必要的优化。我也从 GitHub 获取了 Redis 的发行版本。
我在 Redis 和 Dragonfly 上都禁用了持久化(persistence),其余配置保持一致。
我使用的客户端程序也在我的 GitHub 上可用,测试中使用的是相同的 Redis 客户端。Dragonfly 的一个优化亮点是:无需修改任何代码即可将 Redis 替换为 Dragonfly。
在第二次测试中,我使用了 Redis 的集群客户端,操作仍然是 set 和 get。
第一次测试结果
我们开始第一次测试。请注意,这次测试中 Dragonfly 和 Redis 都使用的是 m7a.medium 实例,每个实例只有一个虚拟 CPU 和 4GB 内存。
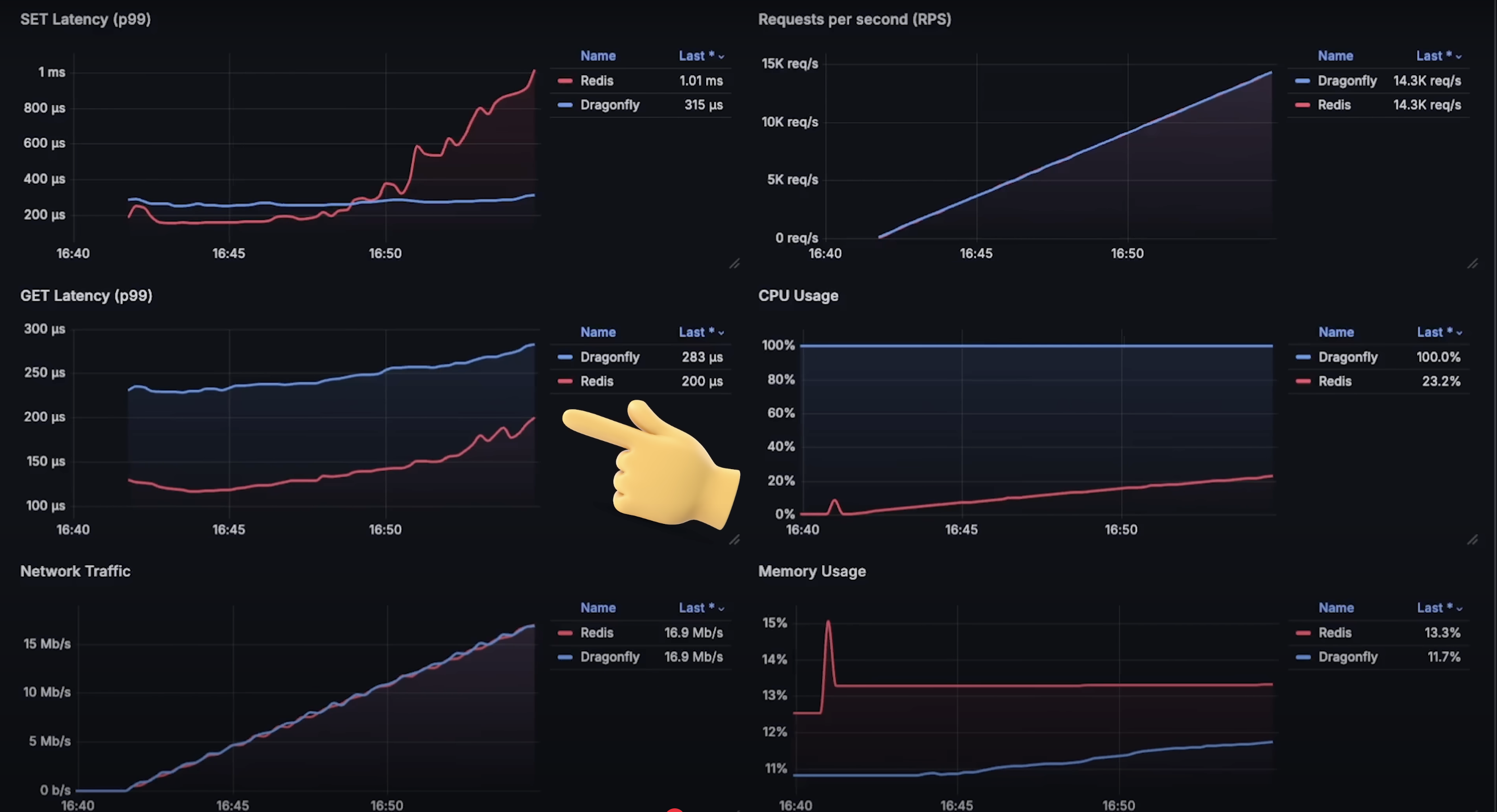
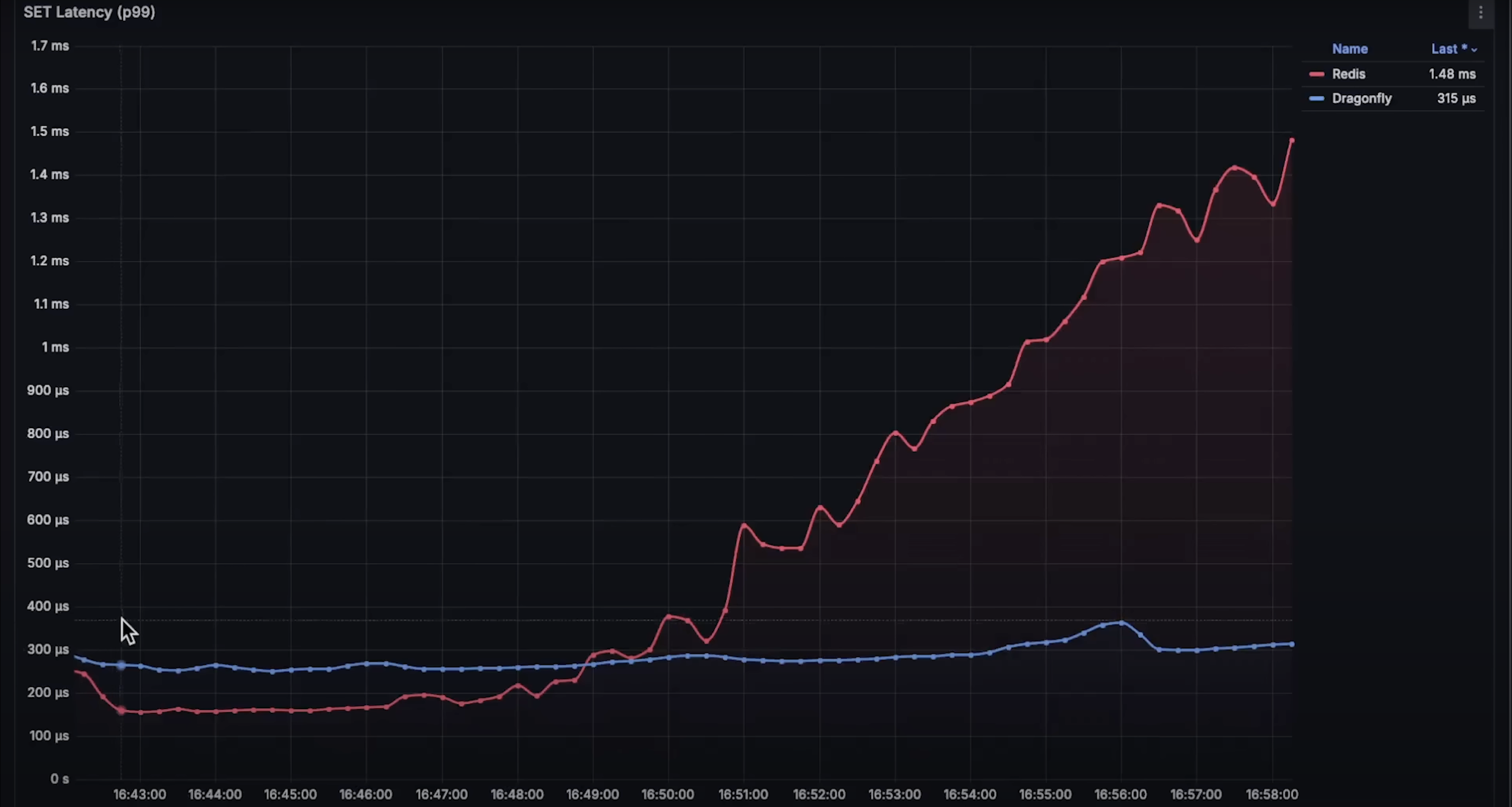
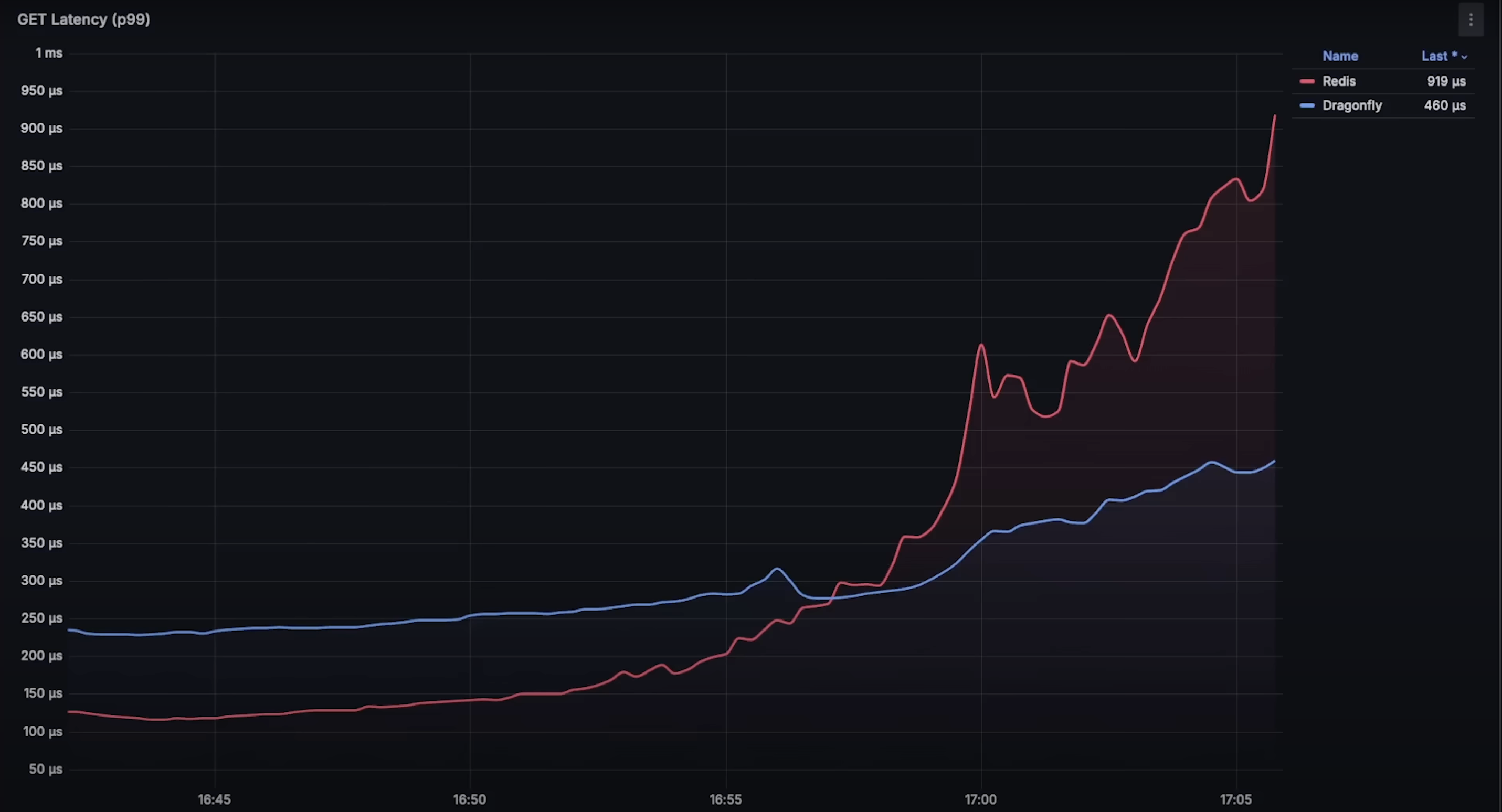
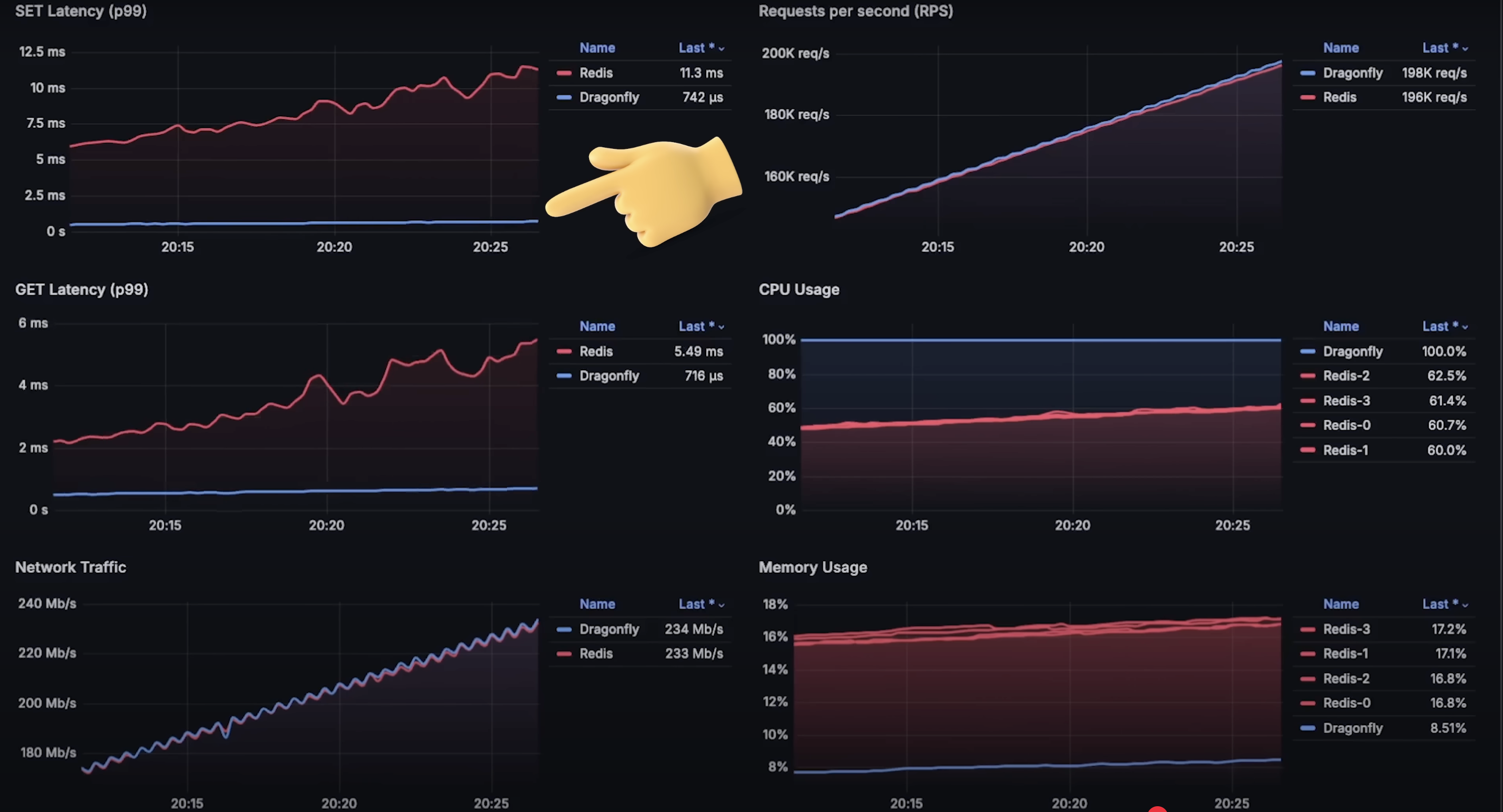
在每秒 7500 个请求之前,Redis 实际上表现出更低的延迟。set 操作相对更消耗资源,因为它需要写入数据库,而 get 操作只需根据键读取值。
在达到每秒 177,000 个请求和 25% CPU 使用率之前,Redis 的 get 操作仍然具有较低延迟。
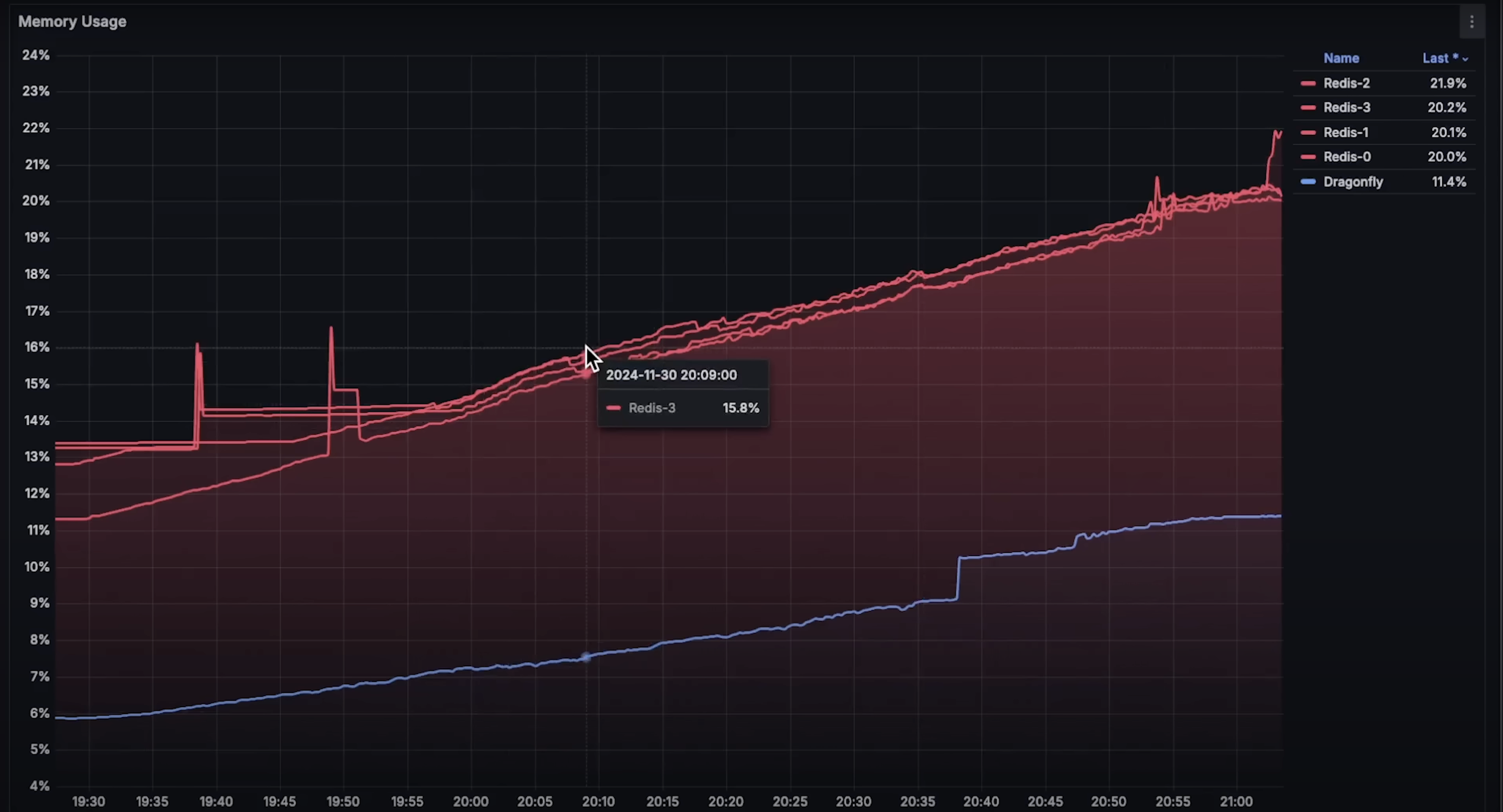
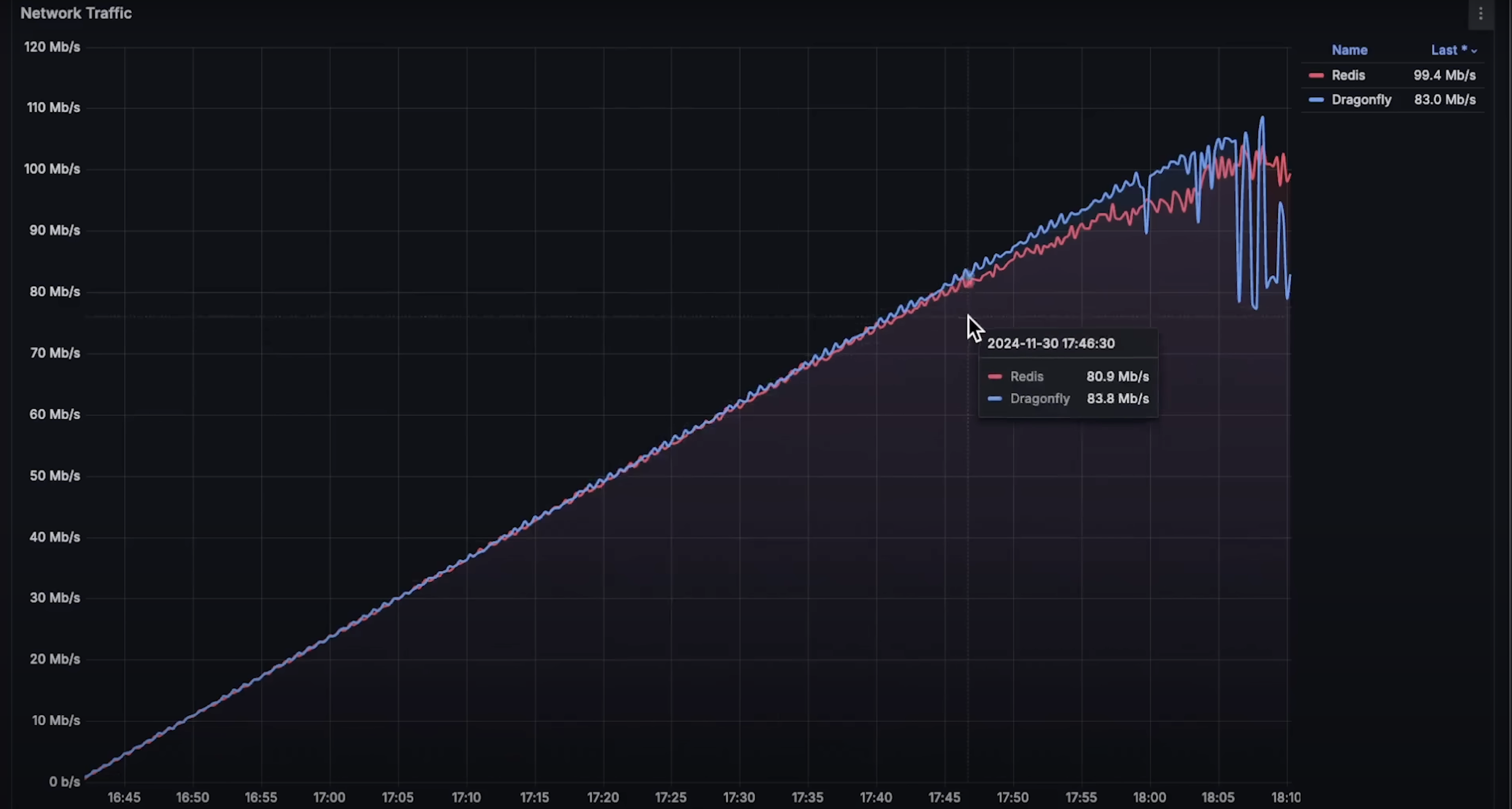
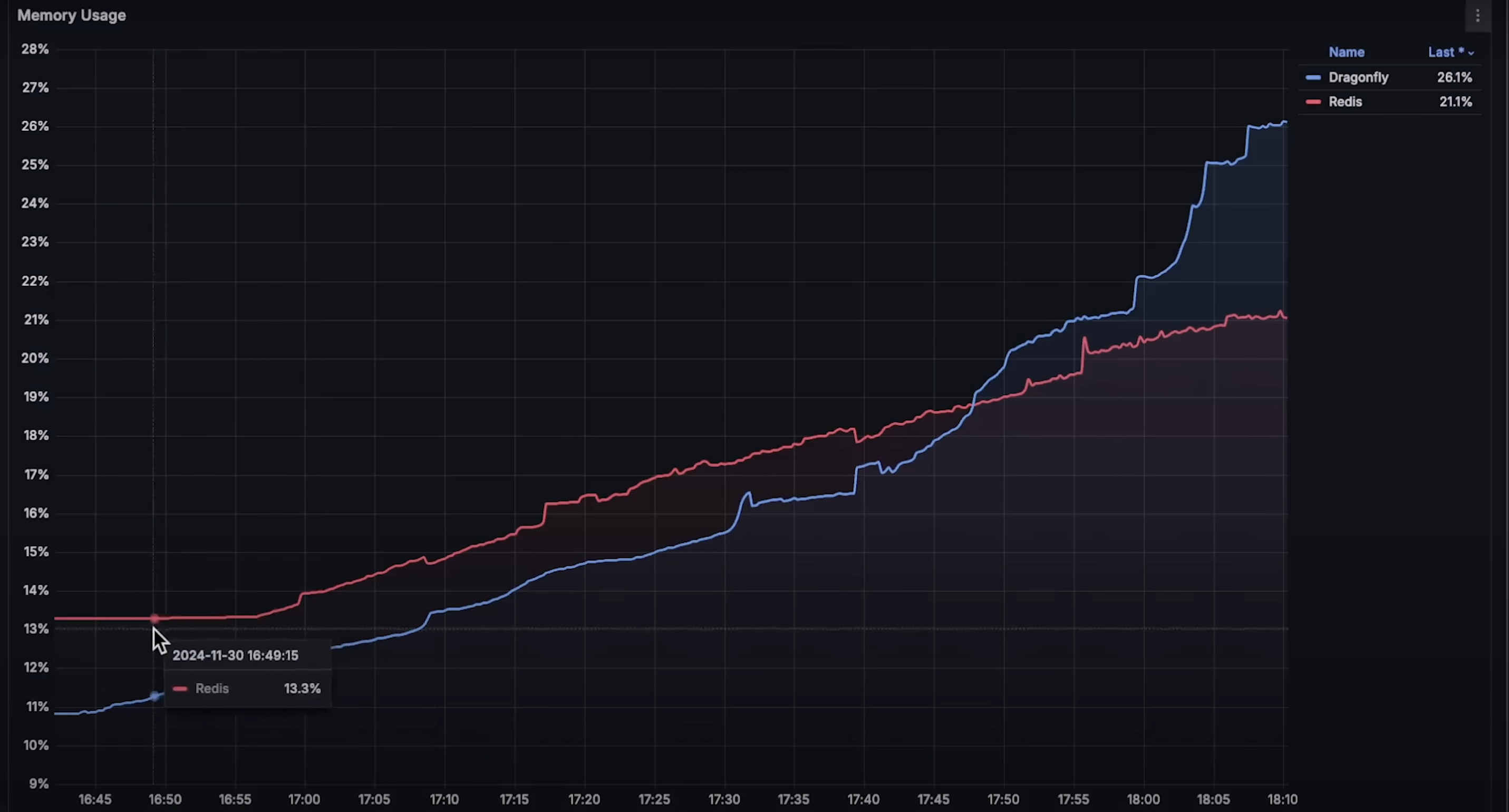
两个数据库都使用相同的 Redis 客户端,因此网络传输使用模式应该一致。但在内存使用方面,Dragonfly 的内存使用量略低。
我在两个数据库中都设置了相同的 20 秒过期时间。
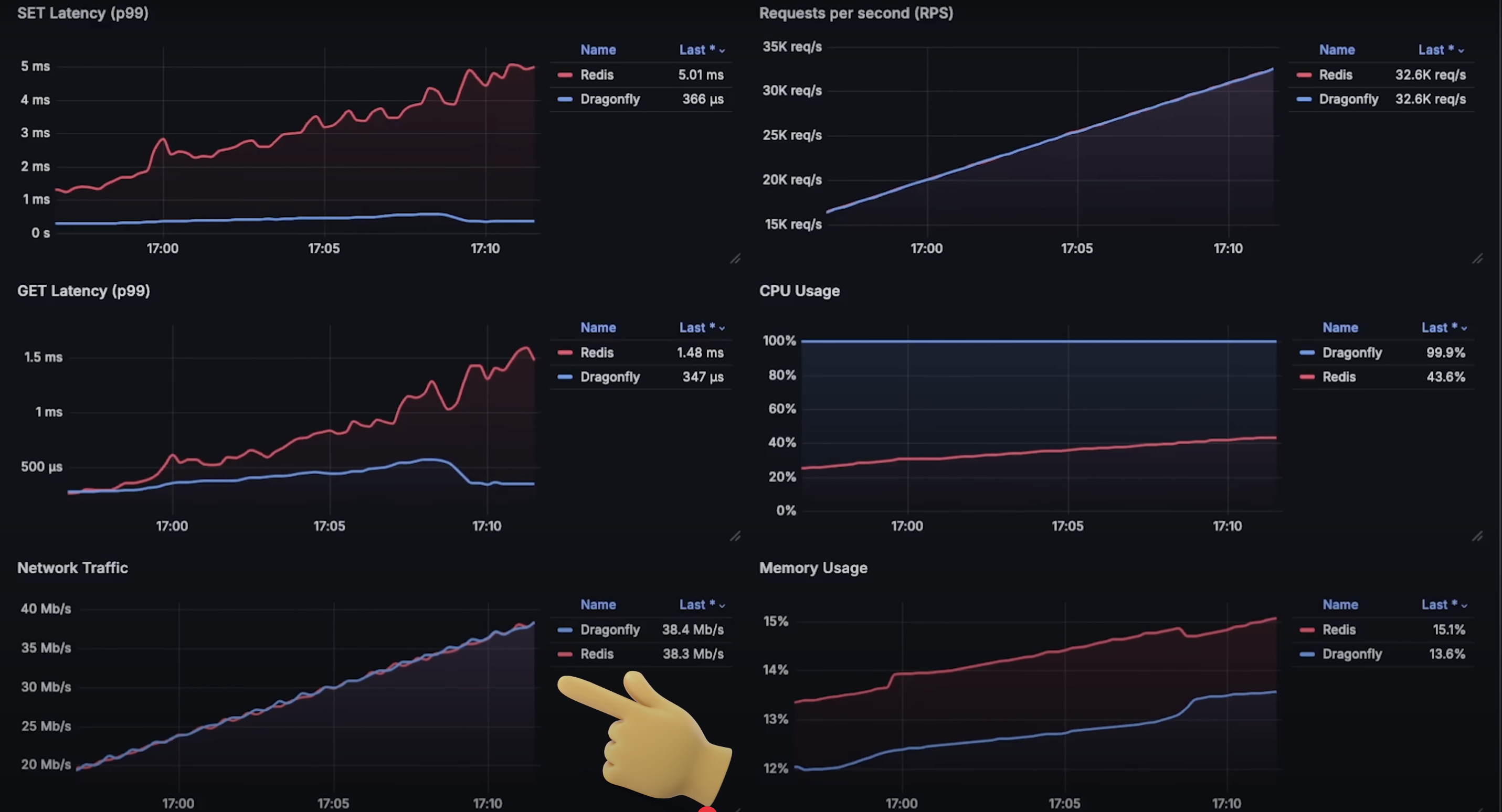
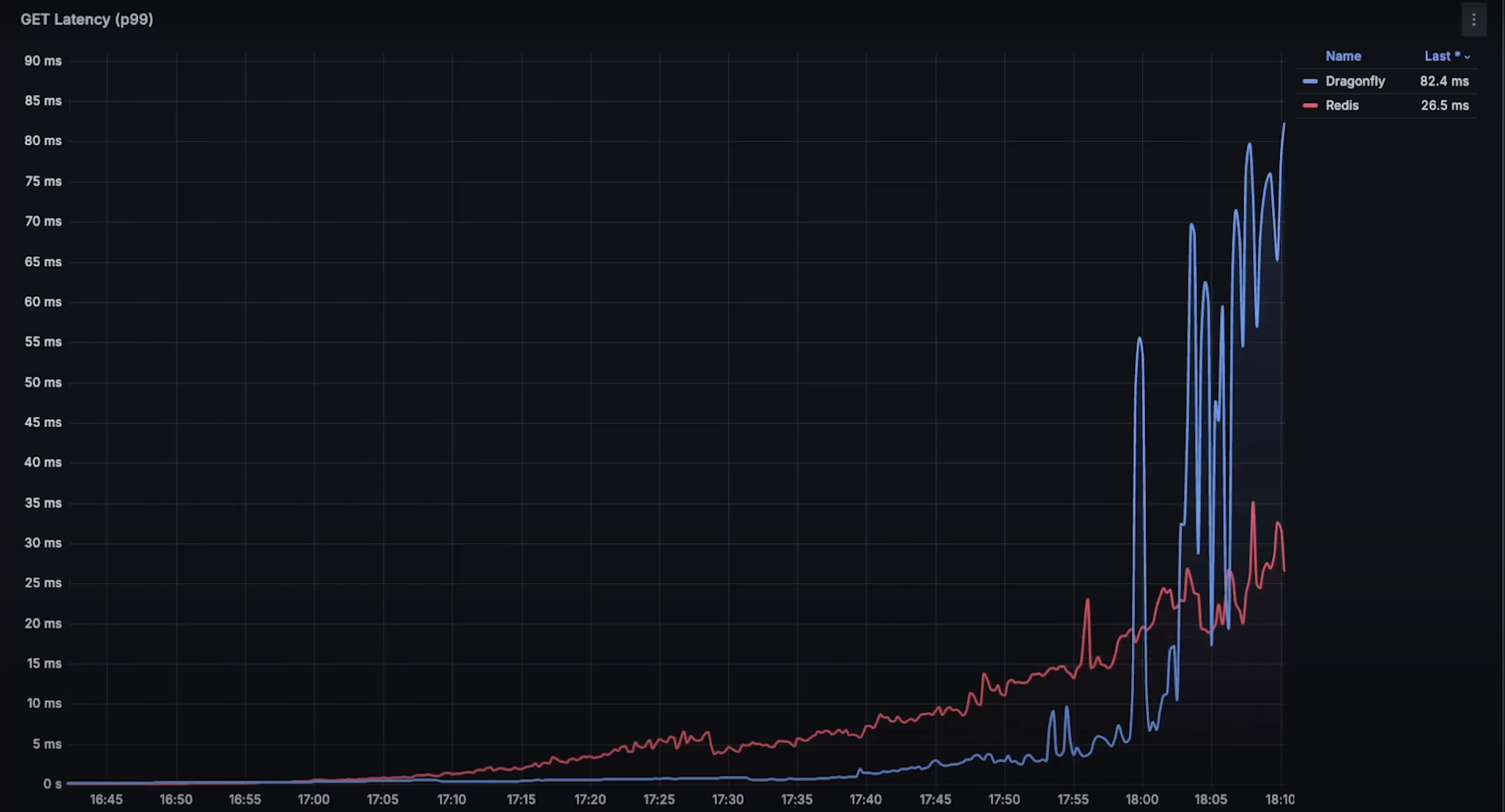
当请求达到每秒 60,000 时,你可以看到 Dragonfly 的延迟更低,因此能处理更多请求。这并不表示 Redis 已经失败。
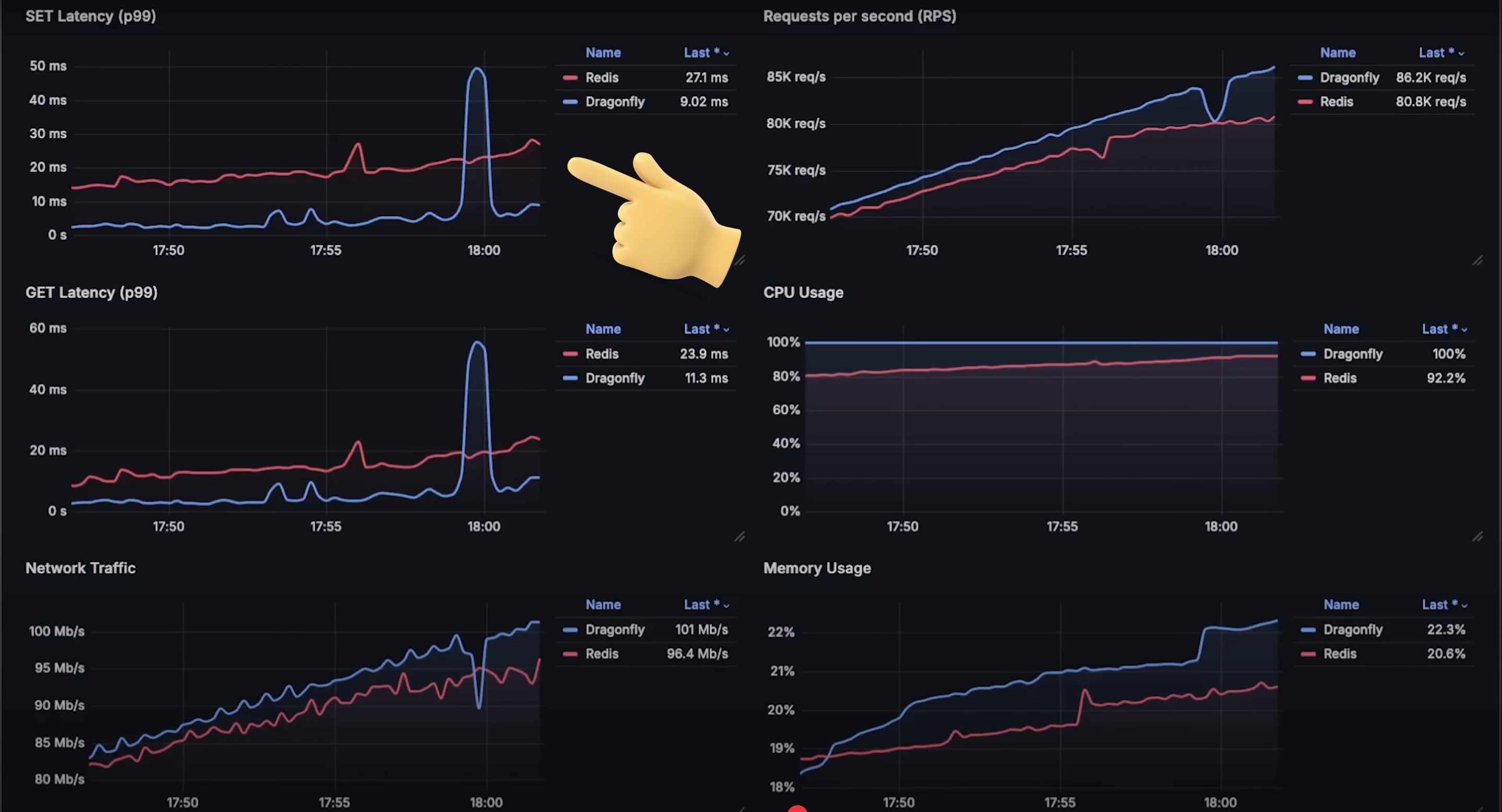
在达到每秒 880,000 请求时,两个数据库都开始难以处理更多请求,Dragonfly 的延迟和内存使用量也急剧上升。可以说这就是每个数据库处理能力的极限。
Redis 的表现非常一致,你可以将其与我之前使用相同实例测试 Memcached 的结果进行比较。
图表分析(第一次测试)
- 每秒请求数:如果你想知道 Dragonfly 和 Memcached 的对比结果,请观看相关视频
---结果显示 Memcached 更胜一筹。
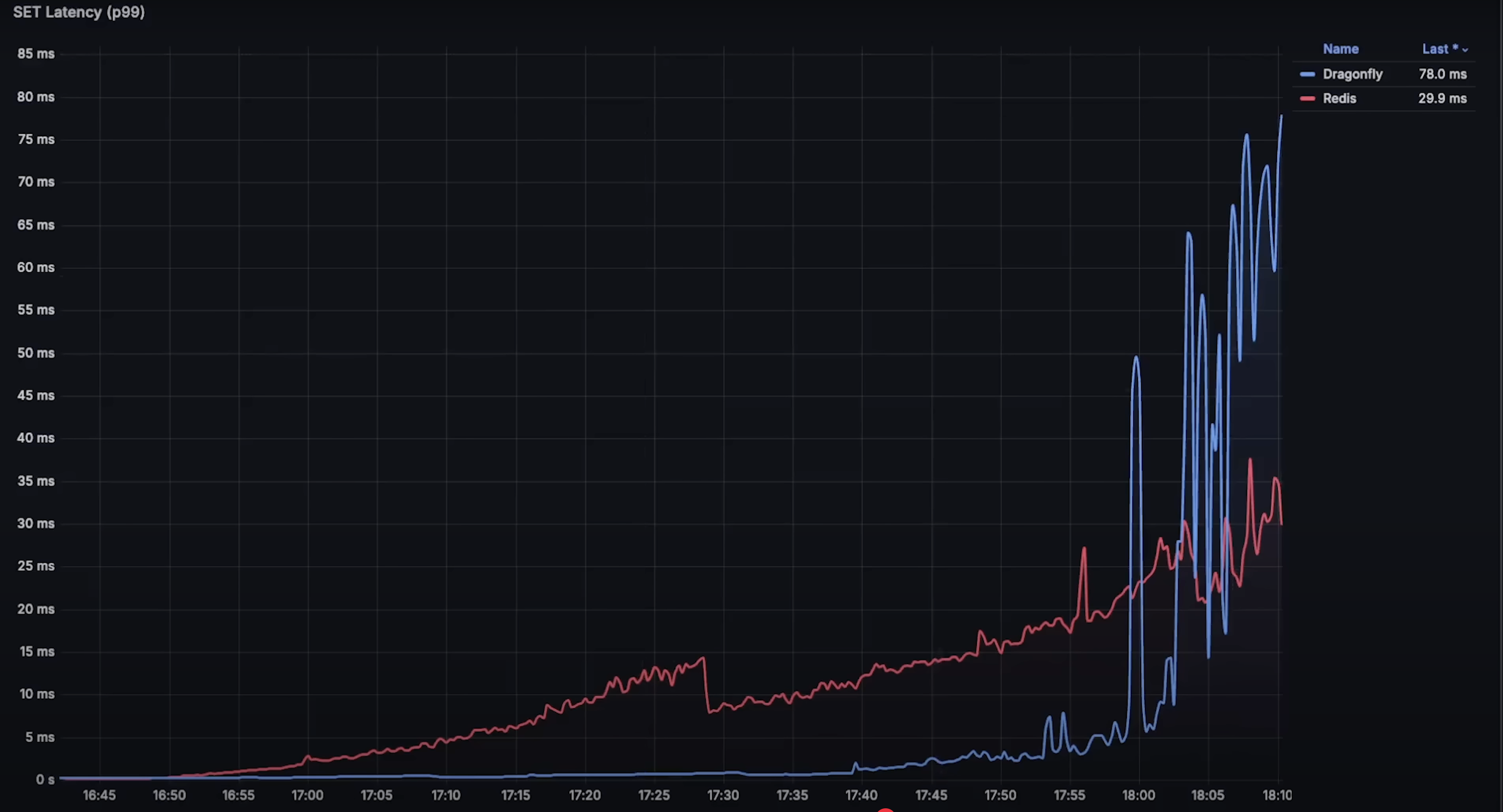
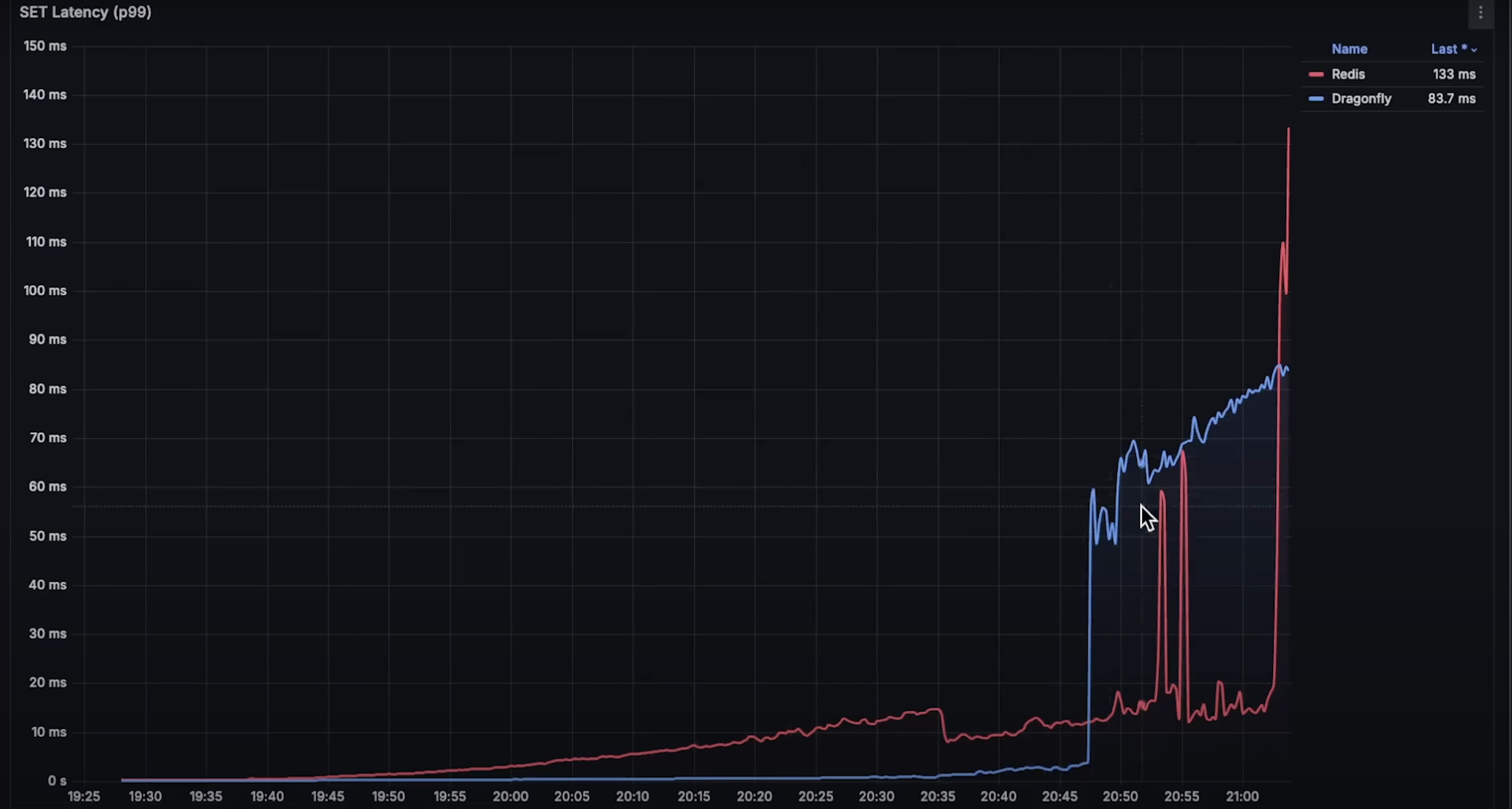
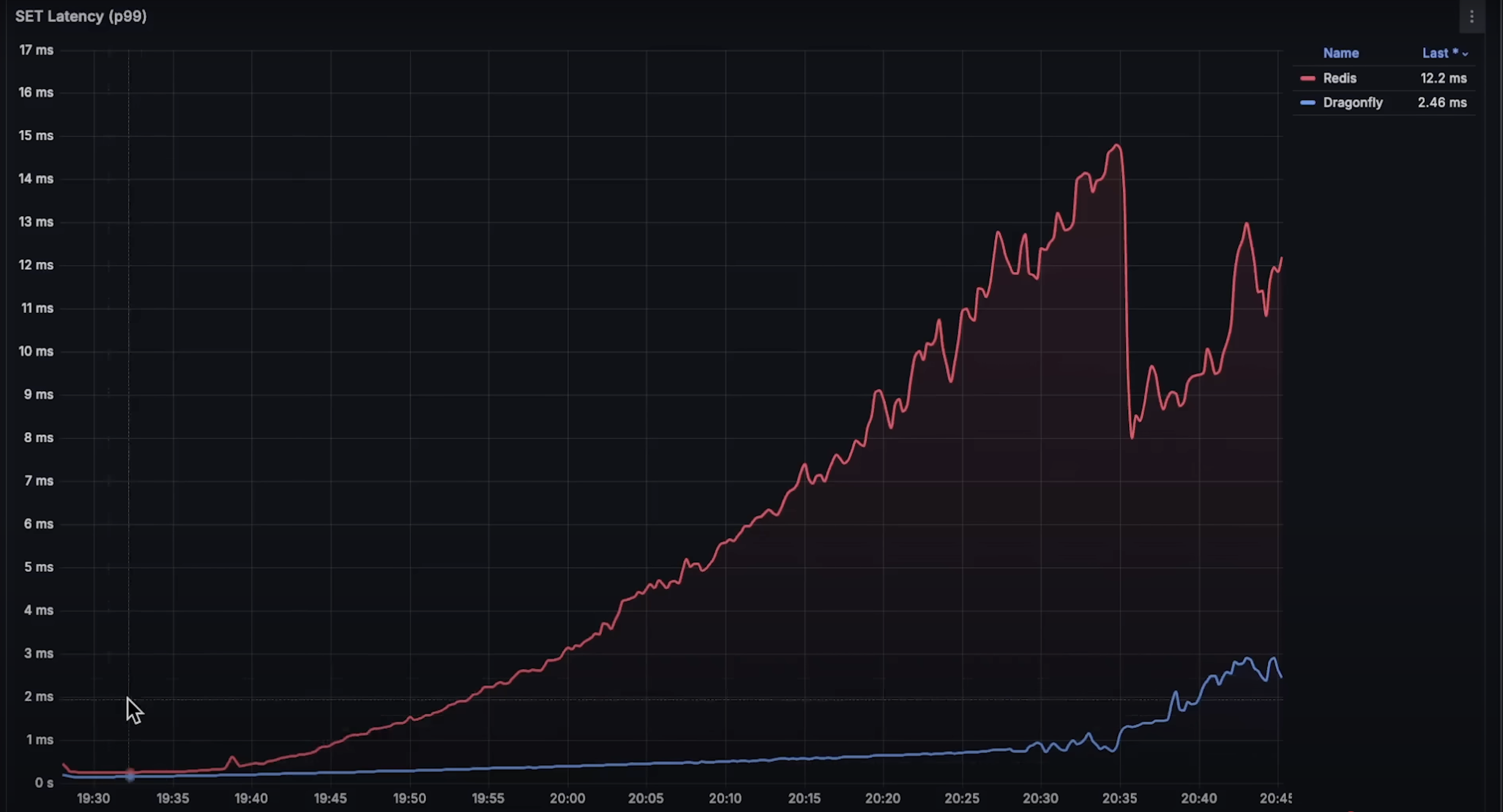
set操作延迟:Dragonfly 明显优于 Redis,整体延迟更低。在缓存系统中,延迟是关键因素。虽然开始几分钟 Redis 延迟更低,但在 CPU 使用率达到 10% 后就失去优势。
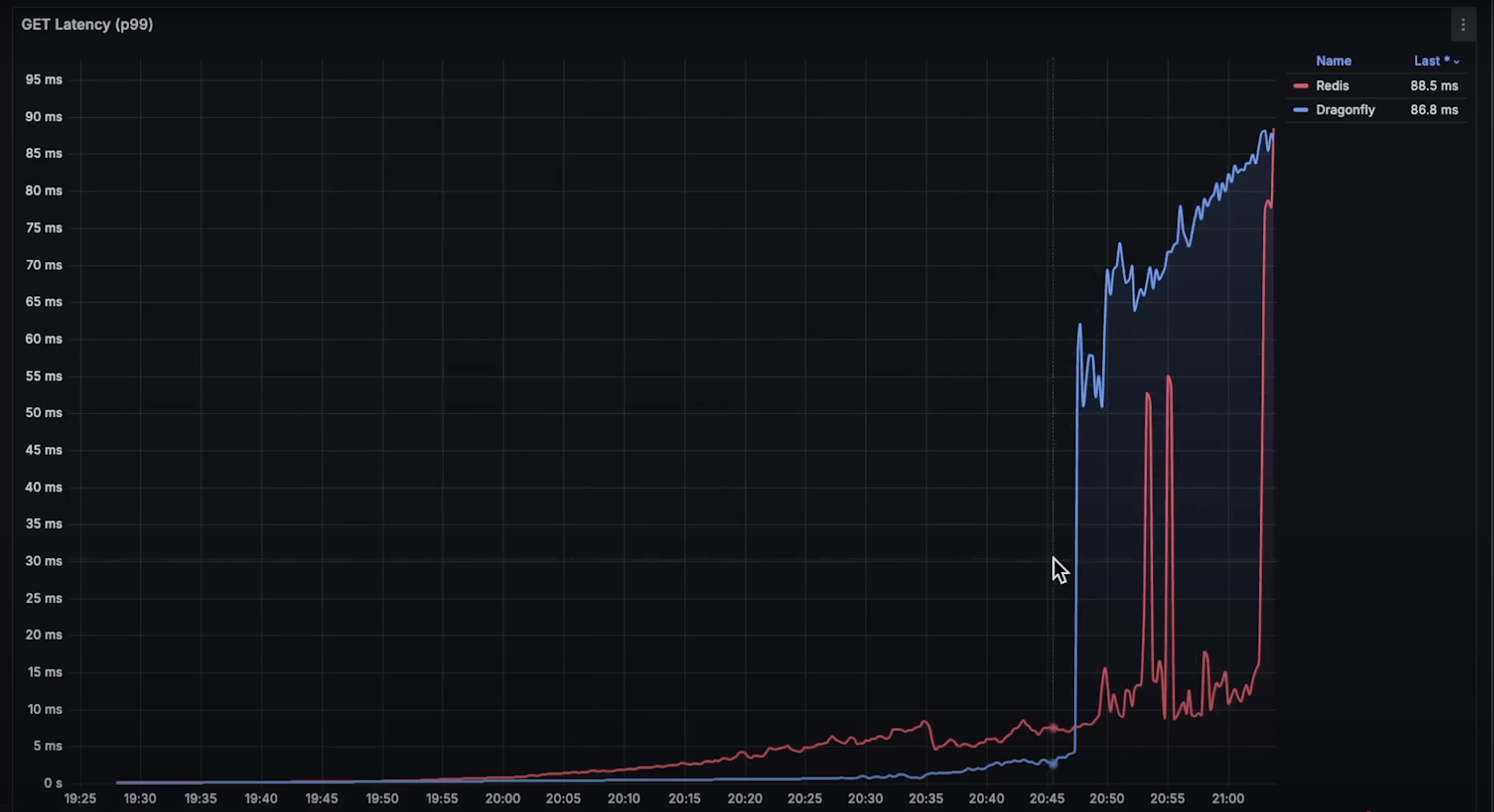
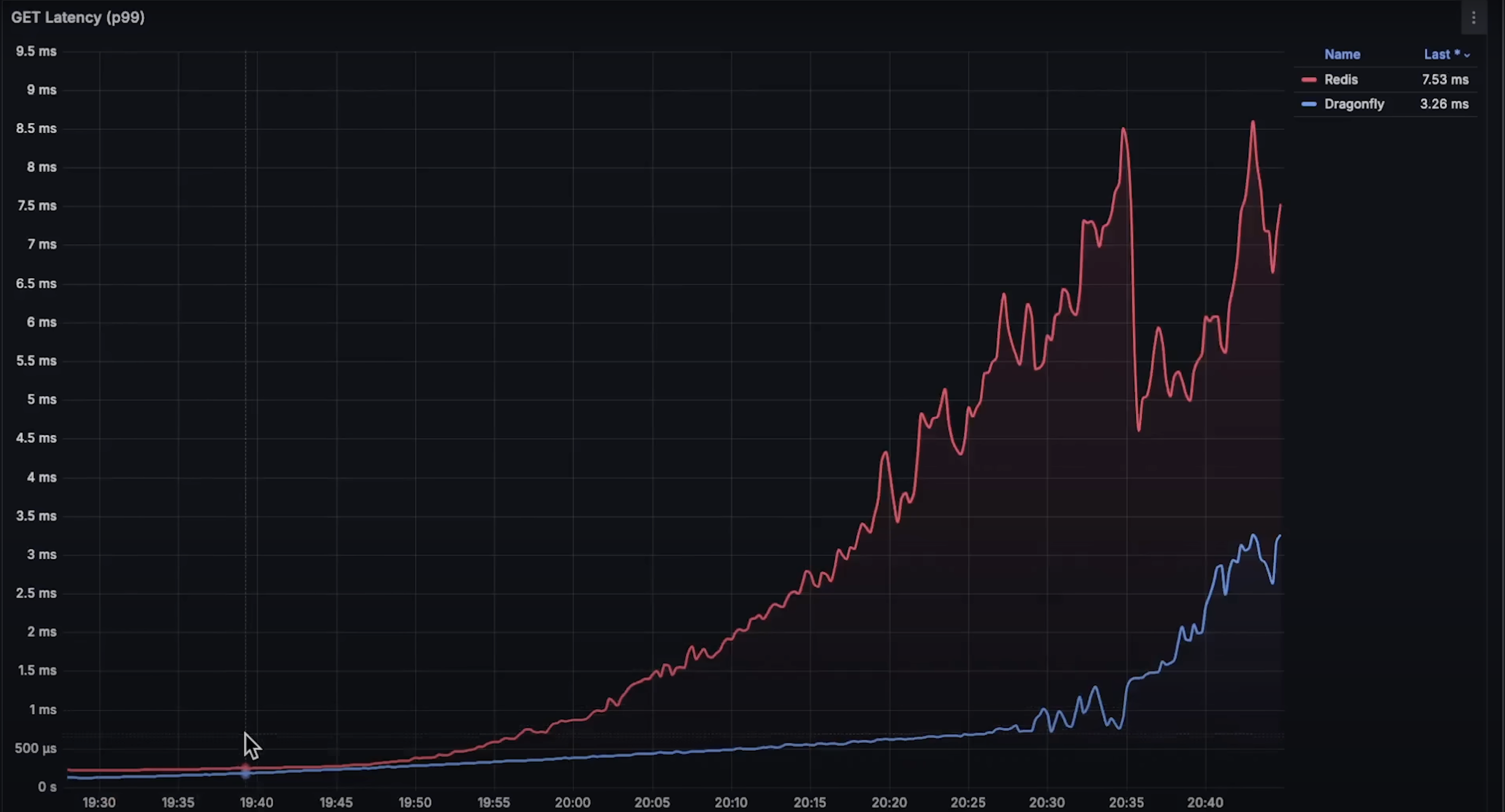
get操作延迟:情况类似,Dragonfly 明显更快。Redis 的优势维持稍久,但在达到 25% CPU 使用率后也消失。
- 网络使用:由于使用的是相同客户端,网络流量基本一致。
- CPU 使用率:标准仪表盘无法准确测量 Dragonfly 的 CPU 使用率,你需要做一些调整。
- 内存使用:测试结束时 Dragonfly 的内存使用高于 Redis,可能是因为其开始失败并尝试缓存请求。
第二次测试:扩展能力对比
这是我们可以用作基准的第一次测试。Dragonfly 最大优势是能利用多个核心进行垂直扩展,只需增加 CPU 和内存即可。但两个数据库也都可以水平扩展。
为了公平起见,我给 Redis 分配相同的资源(CPU 核心和内存),但方式是水平扩展。
所以这次,单个 Dragonfly 实例运行在 m7a.xlarge 实例上,有 4 个 CPU 核心。而 Redis 使用的是四个 m7a.medium 实例,每个一个 CPU。
从基础设施成本来看,两者基本相同。
从内存图来看,Dragonfly 起初内存使用更低,因为它拥有 16GB 内存,而 Redis 的每个节点只有 4GB,共四个。
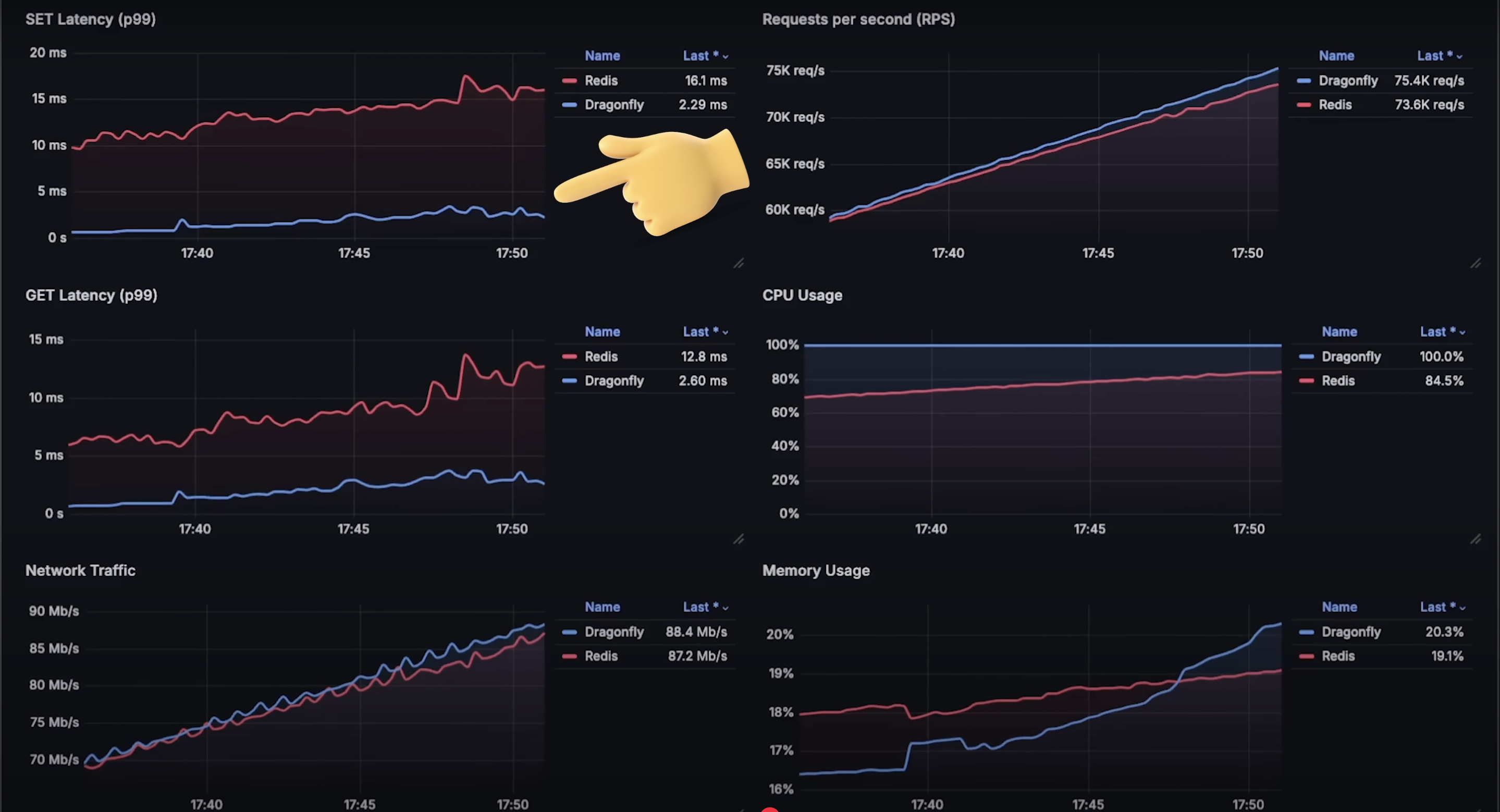
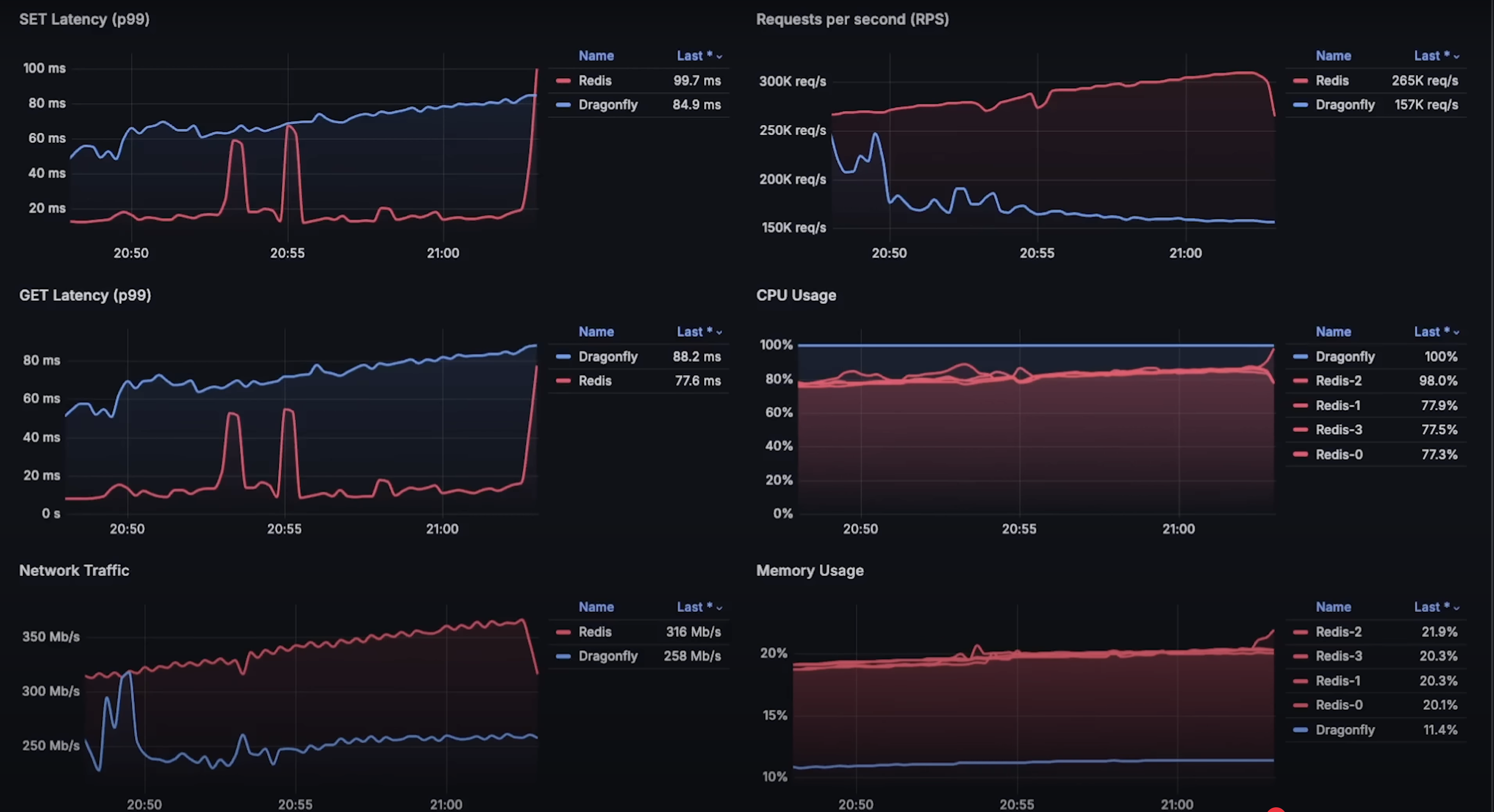
这次 Dragonfly 从一开始就能使用所有 CPU 核心,延迟更低。而 Redis 由于使用集群客户端,相比第一次测试(单节点)延迟增加。
get 操作也类似,Dragonfly 在延迟方面明显占优。
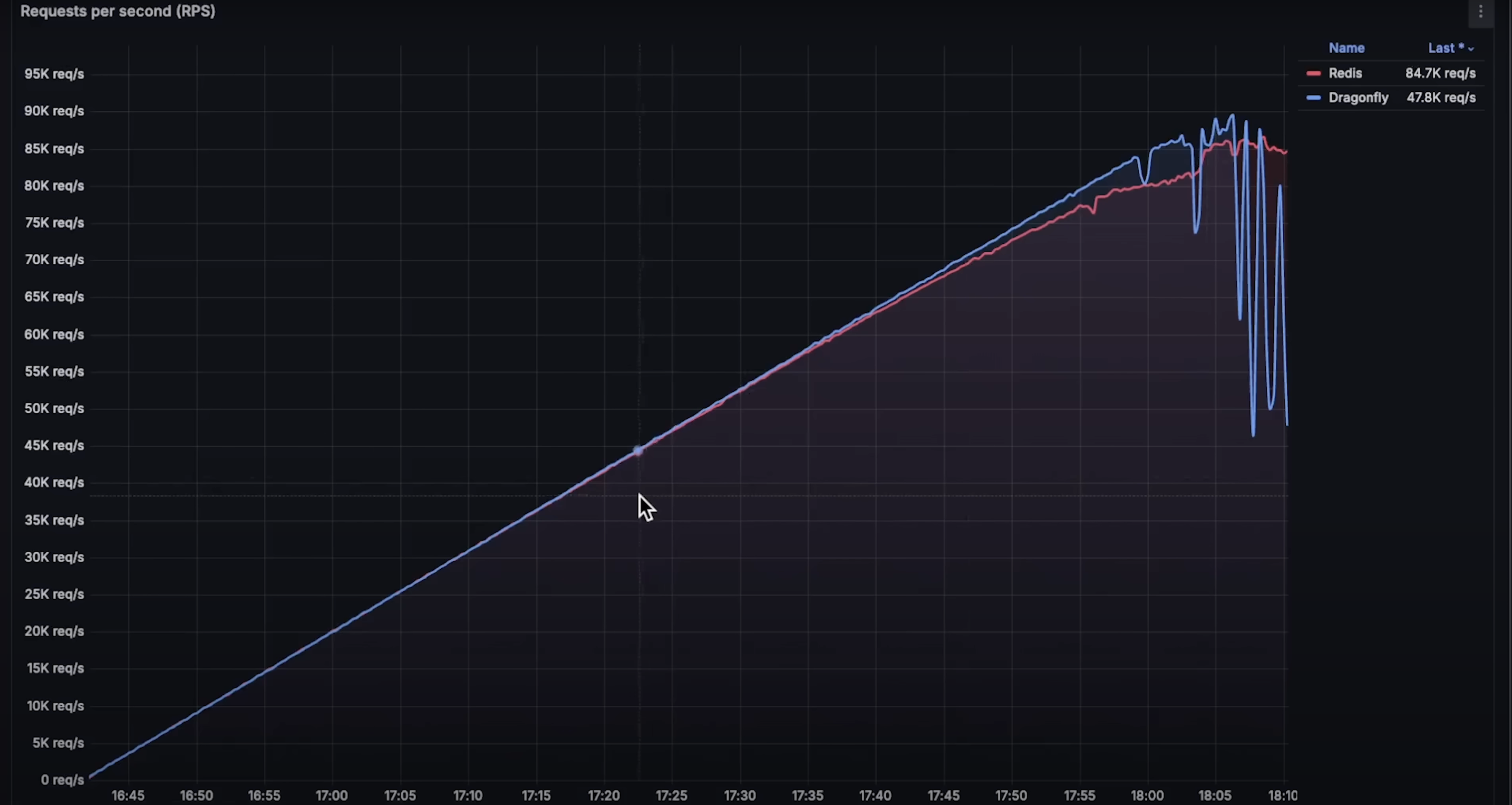
吞吐量对比
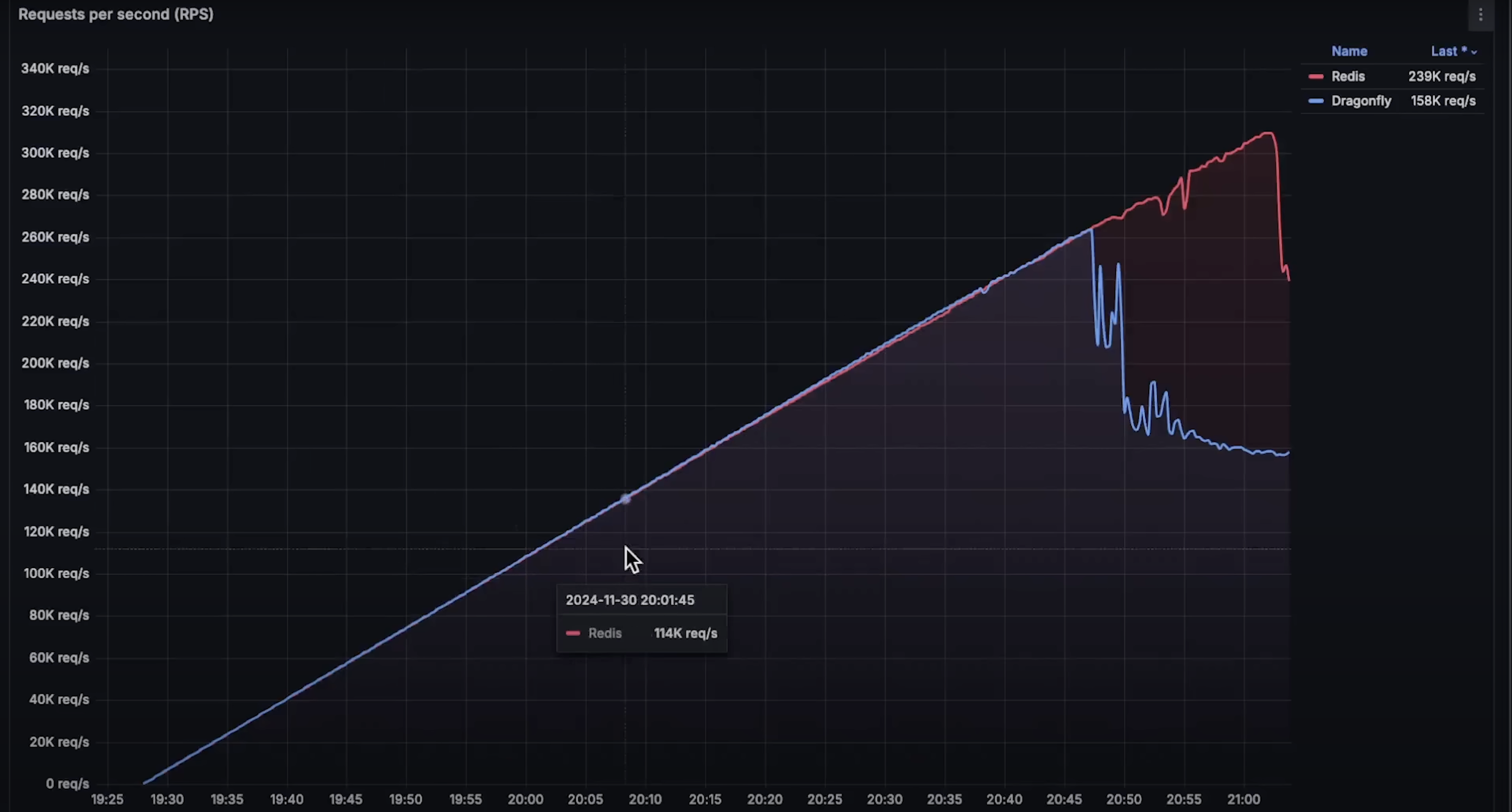
在每秒 260,000 请求时,Dragonfly 开始出现失败。考虑到一核时能处理 880,000 请求,理论上 4 核应处理 320,000。
而 Redis 实际达到了约 310,000 请求/秒,所以本次测试中,Redis 的吞吐量高于 Dragonfly。
这说明,即使你将 Dragonfly 限制为单核并进行水平扩展,它仍然表现更好。因此,Dragonfly 所宣传的“吞吐量是 Redis 的 25 倍”的说法具有一定误导性。这个结论是基于 Dragonfly 可以垂直扩展,而 Redis 是单线程且受单核限制的假设。
图表分析(第二次测试)
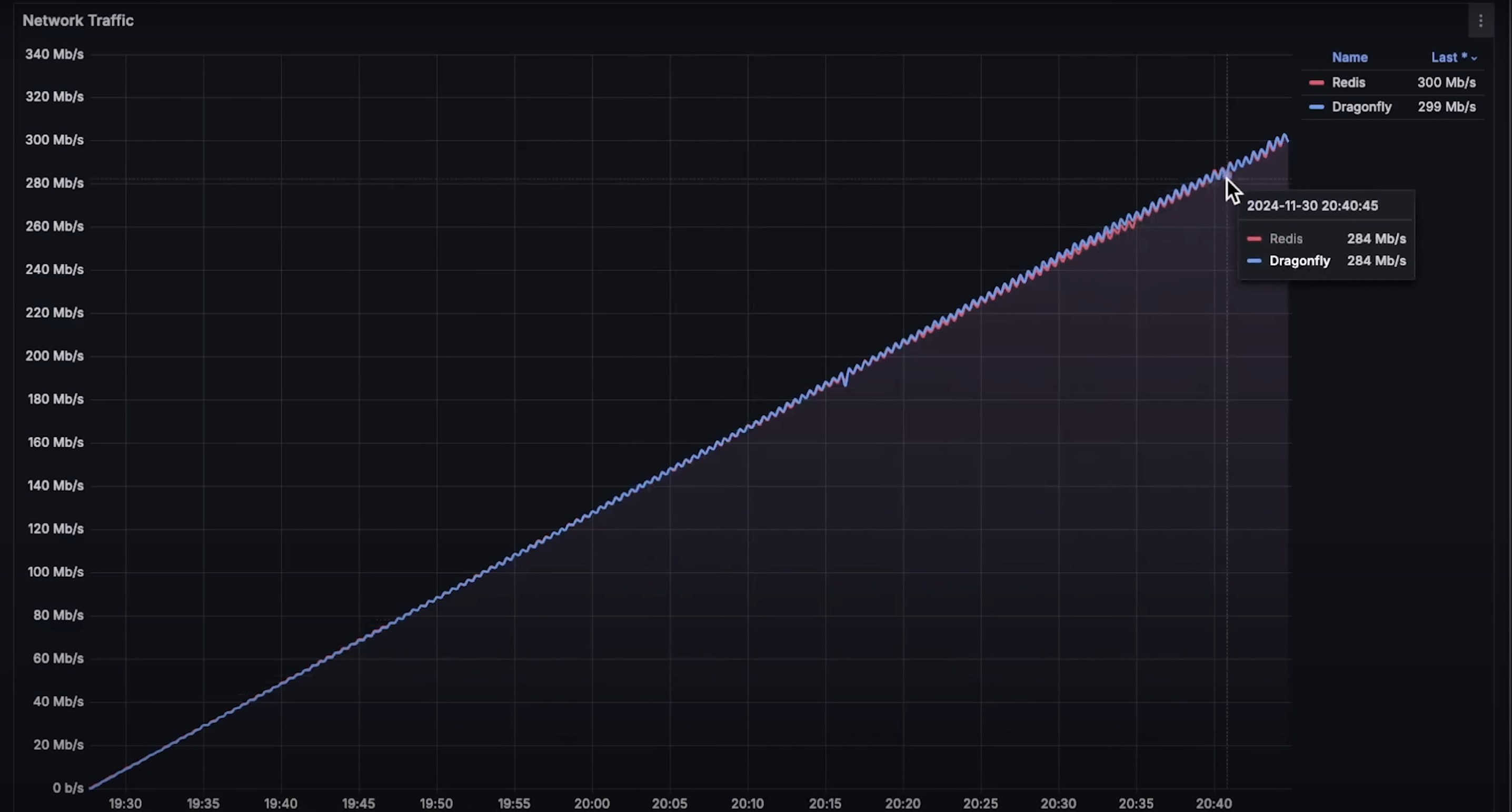
- 每秒请求数:Redis 达到 310,000,Dragonfly 达到 260,000。
- 延迟图表:Dragonfly 在
set和get操作的延迟上表现都远优于 Redis。
- 网络使用:完全一致。
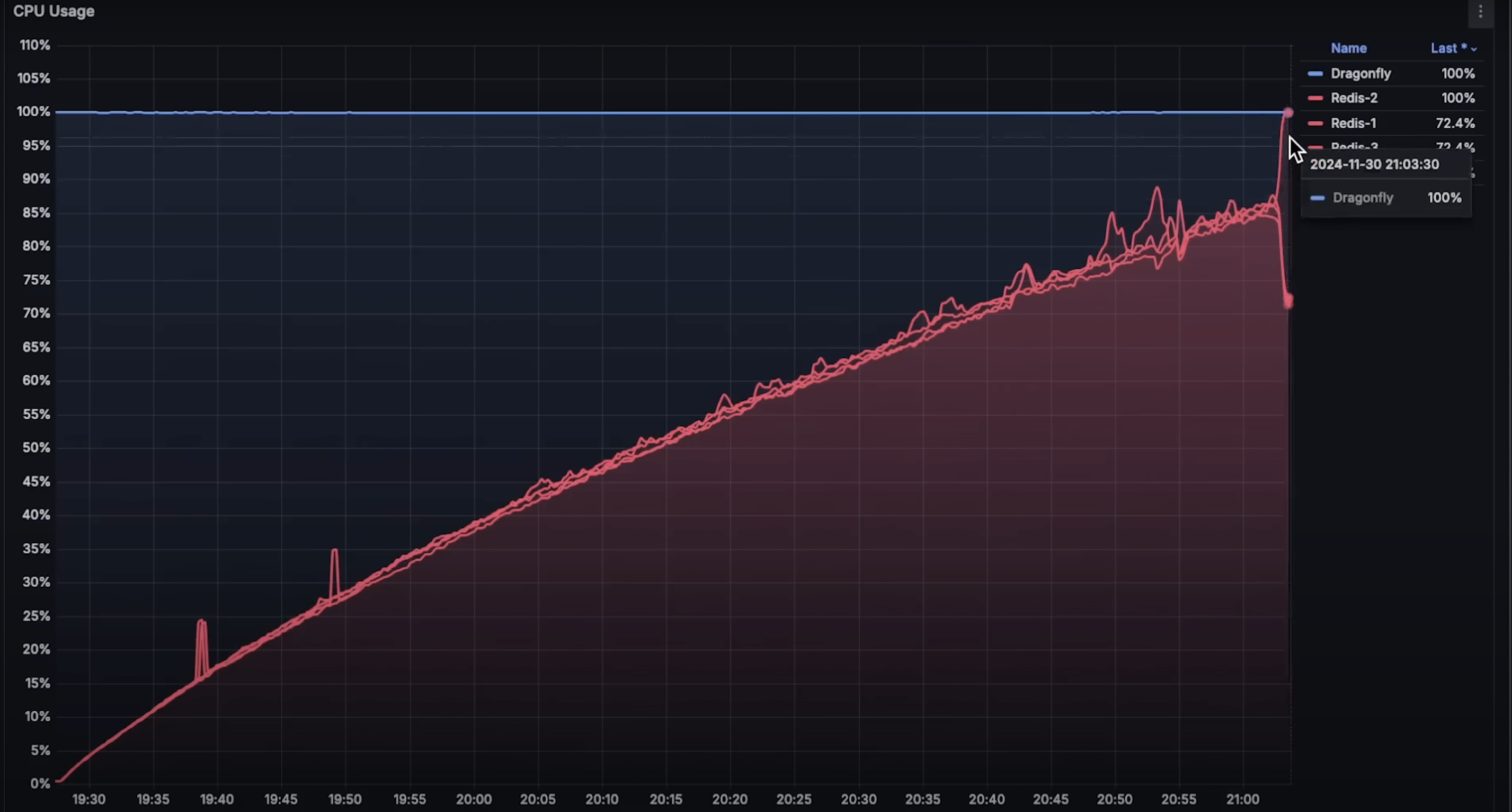
- CPU 使用:看起来当一个节点失败时,客户端触发超时,整个集群宕机。我在想,如果配置一个带副本的 Redis 高可用集群,也许能处理更多请求。
- 内存使用:Dragonfly 使用商业许可证。如果你考虑替代 Redis,这点也需要考虑。你可以看看其他完全开源的数据库,例如 WeeKey。