【sylar-webserver】重构 增加内存池
文章目录
- 内存池
- 设定
- 结构
- ThreadCache
- CentralCache
- PageCache
- allocate
- deallocate
- 测试
参考 https://github.com/youngyangyang04/memory-pool
我的代码实现见 https://github.com/star-cs/webserver
内存池
-
ThreadCache(线程本地缓存)
- 每个线程独立的内存缓存
- 无锁操作,快速分配和释放
- 减少线程间竞争,提高并发性能
-
CentralCache (中心缓存)
- 管理多个线程共享的内存块
- 通过自旋锁保护
- 批量从 PageCache 获取内存,分配给 ThreadCache
-
PageCache (页缓存)
- 从操作系统获取大块内存
- 将大块内存切分成小块,供 CentralCache 使用
- 负责内存的回收和再分配
设定
constexpr size_t ALIGNMENT = 8;
constexpr size_t MAX_BYTES = 256 * 1024; // 256KB,为了提供 协程固定栈 128KB 的分配,这里设计为 256KB 上限
constexpr size_t FREE_LIST_SIZE = MAX_BYTES / ALIGNMENT; // ALIGNMENT等于指针void*的大小
8字节对齐
ThreadCache 会一次申请多批次的内存块,减少访问 CentralCache 次数。
ThreadCache 某一大小内存块链表 过多,返还给 CentralCache。
CentralCache 使用自旋锁
PageCache 每次至少分配 8 页
PageCache 回收页时,支持 合并 相连地址的下一页(实际上,没用到)
pageCache 和 centralCache 全局单例,threadCache 属于 线程单例
typedef sylar::ThreadLocalSingleton<ThreadCache> threadCache;
typedef sylar::Singleton<CentralCache> centralCache;
typedef sylar::Singleton<PageCache> pageCache;
结构
ThreadCache
管理 两个哈希数组,分别是 指向内存空间的地址 链表void*,每条链表的个数 size
哈希数组1~8B 9~16B 17~24B
index:0 -- index:1 -- index:2 -- ... -- index:FREE_LIST_SIZE | | | | 8B 16B 24B MAX_BYTES |8B
CentralCache
管理 两个哈希数组,分别是 指向内存空间的地址 链表void*,每条链表的自旋锁
PageCache
这里比较特殊
freeSpans_ 记录空闲 Span 信息看,方便分配
spanMap_ 记录所有的 Span信息,方便最后回收
struct Span{void* pageAddr; // 页起始地址size_t numPages; // 页数Span* next; // 链表指针};// 按页数管理空闲 Span ,不同页数对应不同 Span 链表std::map<size_t, Span*> freeSpans_;// 页首地址 到 span 的映射,用于回收// spanMap_不仅记录已分配的span,也记录空闲spanstd::map<void*, Span*> spanMap_;MutexType mutex_;
allocate
重点函数实现
ThreadCache::allocate
void* ThreadCache::allocate(size_t size){if(size == 0){size == ALIGNMENT;}if(size > MAX_BYTES){ // 超过 256KB 直接malloc分配 return malloc(size);}size_t index = SizeClass::getIndex(size); // 上转型得到哈希下标freeListSize_[index]--; // 提前减少if(void* ptr == freeListSize_[index]){// ptr void*类型强转为void**,再解引用即可得到 ptr->next 的值freeListSize_[index] = *reinterpret_cast<void**>(ptr);return ptr;}// 线程本地自由链表为空,则从中心缓存获取一批内存return fetchFromCentralCache(index);
}
malloc 小于 128k 内存,使用 brk 分配内存;malloc 大于 128k 内存,使用 mmap 分配内存,在堆和栈之间找一块空闲内存分配。brk 分配的内存需要等到高地址内存释放以后才能释放,而mmap分配的内存可以单独释放。
ThreadCache::fetchFromCentralCache
size_t ThreadCache::getBatchNum(size_t size){constexpr size_t MAX_BATCH_SIZE = 4 * 1024; // 4KBsize_t baseNum;if(size <= 32) baseNum = 64;else if(size <= 64) baseNum = 32;else if(size <= 128) baseNum = 16;else if(size <= 256) baseNum = 8;else if(size <= 512) baseNum = 4;else if(size <= 1024) baseNum = 2;else baseNum = 1; // 大于 1024 的对象每次只从中心缓存取1个size_t maxNum = std::max(size_t(1), MAX_BATCH_SIZE / size); // 确保不小于1return std::max(size_t(1), std::min(maxNum, baseNum));
}void* ThreadCache::fetchFromCentralCache(size_t index){// 从中心缓存批量获取内存size_t size = (index + 1) * ALIGNMENT;size_t batchNum = getBatchNum(size) // 即使当前只需要一个 size 大小的内存块,为了减少访问次数,多拿几个// 返回 batchNum 个 哈希序号为index 的块size_t realBatchNum; void* start = centralCache::GetInstance()->fetchRange(index, batchNum, realBatchNum);if(!start) return nullptr;// 调用 fetchFromCentralCache 之前已经减-1了freeListSize_[index] += realBatchNum;// 取一个返回,其余放入自由链表void* result = start;if(realBatchNum > 1){freeList_[index] = *reinterpret_cast<void**>(start);}*reinterpret_cast<void**>(result) = nullptr;return result;
}
CentralCache::fetchRange
分两种
| ------ 没 CentralCache::fetchFromPageCache
| ------ 有
显然,代码里没有处理:
当有内存块时,但是已有的内存块数量 不满足 batchNum 个的情况。 后期可以修改代码逻辑 ⭐
void* CentralCache::fetchRange(size_t index, size_t batchNum, size_t& realBatchNum){if(index >= FREE_LIST_SIZE || batchNum == 0){return nullptr;}MutexType::Lock lock(locks_[index]);void* result = nullptr;try{result = centralFreeList_[index];if(!result){// 中心缓存为空,从页缓存获取新的内存块size_t size = (index + 1) * ALIGNMENT;size_t numPages;result = fetchFromPageCache(size, batchNum, numPages);if(!result){return nullptr;}// 将获取的内存块切分为小块// 分配到的 块数量 size_t totalBlocks = (numPages * PageCache::PAGE_SIZE) / size; size_t allocBlocks = std::min(batchNum, totalBlocks);realBatchNum = allocBlocks;// 转成char*进行 地址加减运算 ⭐⭐⭐char* start = static_cast<char*>(result);// result 返回的链表 allocBlocks块if(allocBlocks > 1){for(size_t i = 1; i < allocBlocks ; i++){void* current = start + (i-1) * size;void* next = start + i * size;*reinterpret_cast<void**>(current) = next;}*reinterpret_cast<void**>(start + (allocBlocks - 1) * size) = nullptr;}// 还剩下的 添加到 自由链表if(totalBlocks > allocBlocks){void* remainStart = start + allocBlocks * size;for(size_t i = allocBlocks + 1 ; i < totalBlocks ; ++i){void* current = start + (i-1) * size;void* next = start + i * size;*reinterpret_cast<void**>(current) = next;}*reinterpret_cast<void**>(start + (totalBlocks - 1) * size) = nullptr;centralFreeList_[index] = remainStart;}}else{// 中心缓存有index对应大小的内存块void* current = result;void* prev = nullptr;size_t count = 0;while(current && count < batchNum){prev = current;current = *reinterpret_cast<void**>(current);count++;}realBatchNum = count; // 这里同上,只会记录获得已有的。if(prev){*reinterpret_cast<void**>(prev) = nullptr; // 断开}centralFreeList_[index] = current;}}catch(...){throw;}return result;
}void* CentralCache::fetchFromPageCache(size_t size, size_t batchNum, size_t& outNumPages){size_t totalSize = batchNum * size;outNumPages = PageCache::getSpanPage(totalSize);return pageCache::GetInstance()->allocateSpan(outNumPages);
}// 当size <= 32KB,默认获取32KB,8页。如果size > 32KB,就按实际需求分配
size_t PageCache::getSpanPage(size_t size){if(size > PAGE_SIZE * SPAN_PAGES){return (size + PAGE_SIZE - 1) / PAGE_SIZE;}else{return SPAN_PAGES;}
}
PageCache::allocateSpan
void* PageCache::allocateSpan(size_t numPages){MutexType::Lock lock(mutex_);// 寻找合适的 空闲的span// lower_bound 函数返回第一个大于等于numPages的元素迭代器auto it = freeSpans_.lower_bound(numPages);if(it != freeSpans_.end()){Span* span = it->second; // 将取出的span从原来的空间链表freeSpans_[it->first]中移除if(span->next){freeSpans_[it->first] = span->next;}else{freeSpans_.erase(it);}// 如果 span 的 numPages 大于 需要的 numPages,拆分⭐if(span->numPages > numPages){Span* newSpan = new Span; newSpan->pageAddr = static_cast<char*>(span->pageAddr) + numPages * PAGE_SIZE;newSpan->numPages = span->numPages - numPages;newSpan->next = nullptr;// 记录新的spanspanMap_[newSpan->pageAddr] = newSpan;// 超出的部分 newSpan 放回 freeSpans_列表头部auto& list = freeSpans_[newSpan->numPages];newSpan->next = list;list = newSpan;// 修改之前的 span 页数// 这个span的信息在创建新span的时候,就记录到了spanMap_,修改指针内容即可⭐span->numPages = numPages; }// 记录分配span信息用于回收// 理论上这个 span->pageAddr在创建的时候已经记录了一遍// spanMap_[span->pageAddr] = span;return span->pageAddr;}// 没有合适的Span,向系统申请void* memory = systemAlloc(numPages);if(!memory) return nullptr;Span* span = new Span;span->pageAddr = memory;span->numPages = numPages;span->next = nullptr;spanMap_[span->pageAddr] = span;return memory;
}void* PageCache::systemAlloc(size_t numPages){size_t size = numPages * PAGE_SIZE;// 使用mmap分配内存void* ptr = mmap(nullptr, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);if(ptr == MAP_FAILED) return nullptr;// 清零内存memset(ptr, 0, size);return ptr;
}
deallocate
// 析构,把内存信息返还!!!⭐
ThreadCache::~ThreadCache(){for(size_t i = 0 ; i < FREE_LIST_SIZE ; ++i){if (freeList_[i]) {size_t blockSize = (i + 1) * ALIGNMENT;size_t blockNum = freeListSize_[i];// 全部返还centralCache::GetInstance()->returnRange(freeList_[i], blockNum * blockSize, i);freeList_[i] = nullptr;freeListSize_[i] = 0;}}
}void ThreadCache::deallocate(void* ptr, size_t size){if(size > MAX_BYTES){free(ptr);return;}size_t index = SizeClass::getIndex(size);// 插入到线程本地自由链表*reinterpret_cast<void**>(ptr) = freeList_[index];freeList_[index] = ptr;freeListSize_[index]++;// 判断是否需要将部分内存回收到中心缓存?if(shouldReturnToCentralCache(index)){returnToCentralCache(freeList_[index], size);}
}bool ThreadCache::shouldReturnToCentralCache(size_t index){// 设定阈值,当自由列表的大小超过一定数量时,返回到中心缓存size_t threshold = 64;return (freeListSize_[index] > threshold);
}void ThreadCache::returnToCentralCache(void* start, size_t size){size_t index = SizeClass::getIndex(size);// 补全size_t alignedSize = SizeClass::roundUp(size);size_t batchNum = freeListSize_[index];if(batchNum <= 1) return; // 如果只有一个块,则不归还size_t keepNum = std::max(batchNum / 4, size_t(1));size_t returnNum = batchNum - keepNum;/// 字节偏移,以 1 字节为单位。char* current = static_cast<char*>(start);char* splitNode = current;for(size_t i = 0; i < keepNum - 1; ++i){splitNode = reinterpret_cast<char*>(*reinterpret_cast<void**>(splitNode));if(splitNode == nullptr){// 如果链表提前结束,更新实际的返回数量returnNum = batchNum - (i+1);break;}}if(splitNode != nullptr){void* nextNode = *reinterpret_cast<void**>(splitNode);*reinterpret_cast<void**>(splitNode) = nullptr;freeList_[index] = start;freeListSize_[index] = keepNum;if(returnNum > 0 && nextNode != nullptr){centralCache::GetInstance()->returnRange(nextNode, returnNum * alignedSize, index);}}
}
// ⭐
CentralCache::~CentralCache(){// 仅需清理状态,内存由 PageCache 释放for (size_t i = 0; i < FREE_LIST_SIZE; ++i) {centralFreeList_[i] = nullptr;}printf("~CentralCache()");
}void CentralCache::returnRange(void* start, size_t size, size_t index){if(!start || size > FREE_LIST_SIZE)return;MutexType::Lock lock(locks_[index]);try{size_t blockSize = (index + 1) * ALIGNMENT;size_t blockNum = size / blockSize;// 找到要归还的链表的最后一个节点void* end = start;size_t count = 1;while(*reinterpret_cast<void**>(end) != nullptr && count < blockNum){end = *reinterpret_cast<void**>(end);count ++;}void* current = centralFreeList_[index];*reinterpret_cast<void**>(end) = current;centralFreeList_[index] = start;}catch(...){throw;}
}
PageCache::~PageCache(){// 释放所有 Span 占用的系统内存for (auto& entry : spanMap_) {Span* span = entry.second;if (span->pageAddr) {munmap(span->pageAddr, span->numPages * PAGE_SIZE);span->pageAddr = nullptr;}delete span; // 释放 Span 对象本身}spanMap_.clear();freeSpans_.clear();printf("~PageCache()");
}
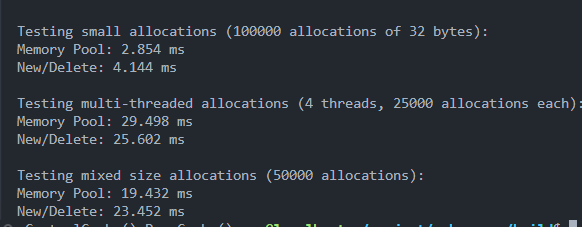
测试
详见 test/test_managerpool.cc
... int main()
{std::cout << "Starting performance tests..." << std::endl;// 控制 静态变量的初始化 顺序 ⭐⭐⭐⭐⭐sylar::pageCache::GetInstance();sylar::centralCache::GetInstance();// 预热系统PerformanceTest::warmup();// 运行测试PerformanceTest::testSmallAllocation();PerformanceTest::testMultiThreaded();PerformanceTest::testMixedSizes();return 0;
}
编译时,使用 -O3 优化。