Spark-Streaming简介 核心编程
1. Spark-Streaming概述
定义:用于处理流式数据,支持多种数据输入源,可运用Spark原语运算,结果能保存于多处。它以离散化流(DStream)为抽象表示,是RDD在实时数据处理场景的封装。
特点:易用,支持多语言编写实时计算程序;容错,可恢复丢失数据;易整合,能在Spark上运行,结合离线处理实现交互式查询。
2. Spark-Streaming架构:包含背压机制,1.5版本前靠设置静态参数限制Receiver数据接收速率,易导致资源利用率低。1.5版本起可动态调整,通过“spark.streaming.backpressure.enabled”控制,默认不启用。
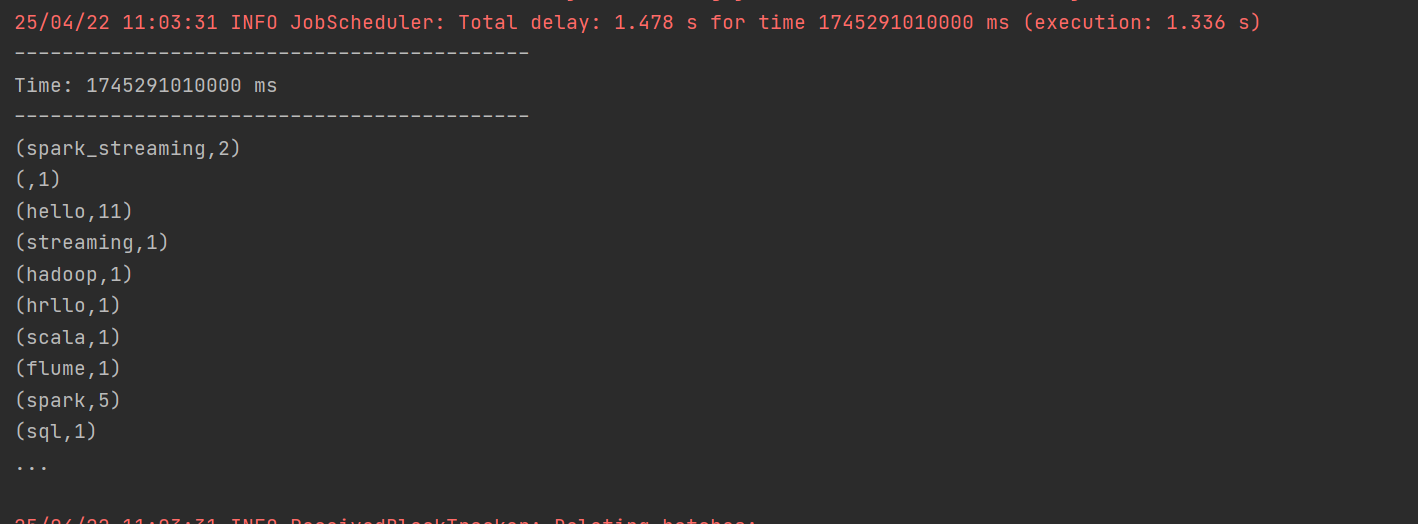
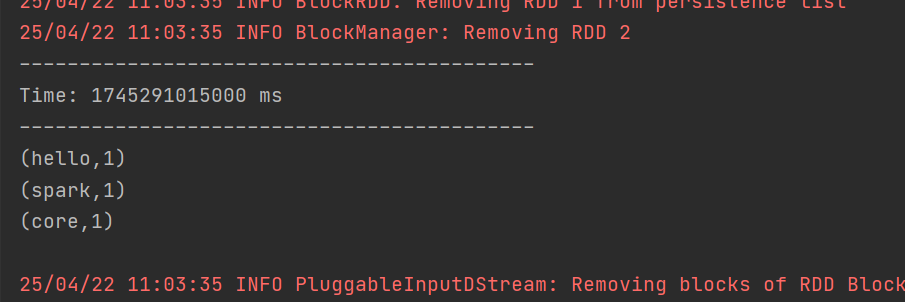
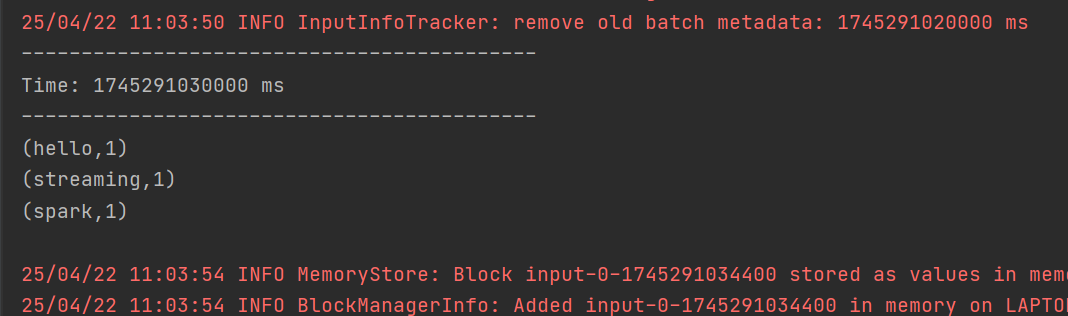
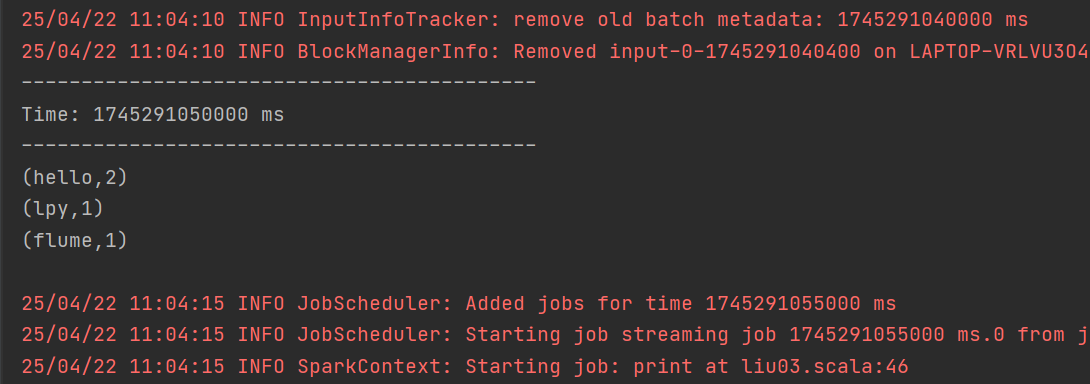
3. DStream实操 - WordCount案例
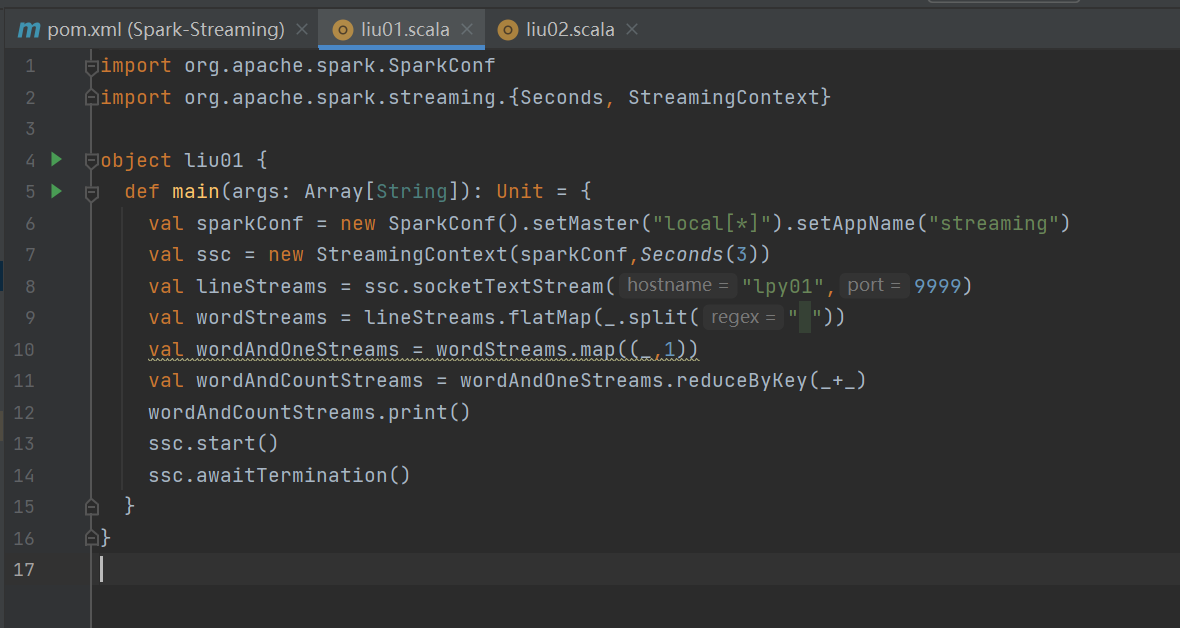
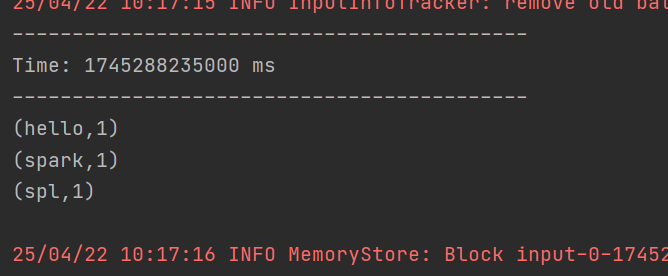
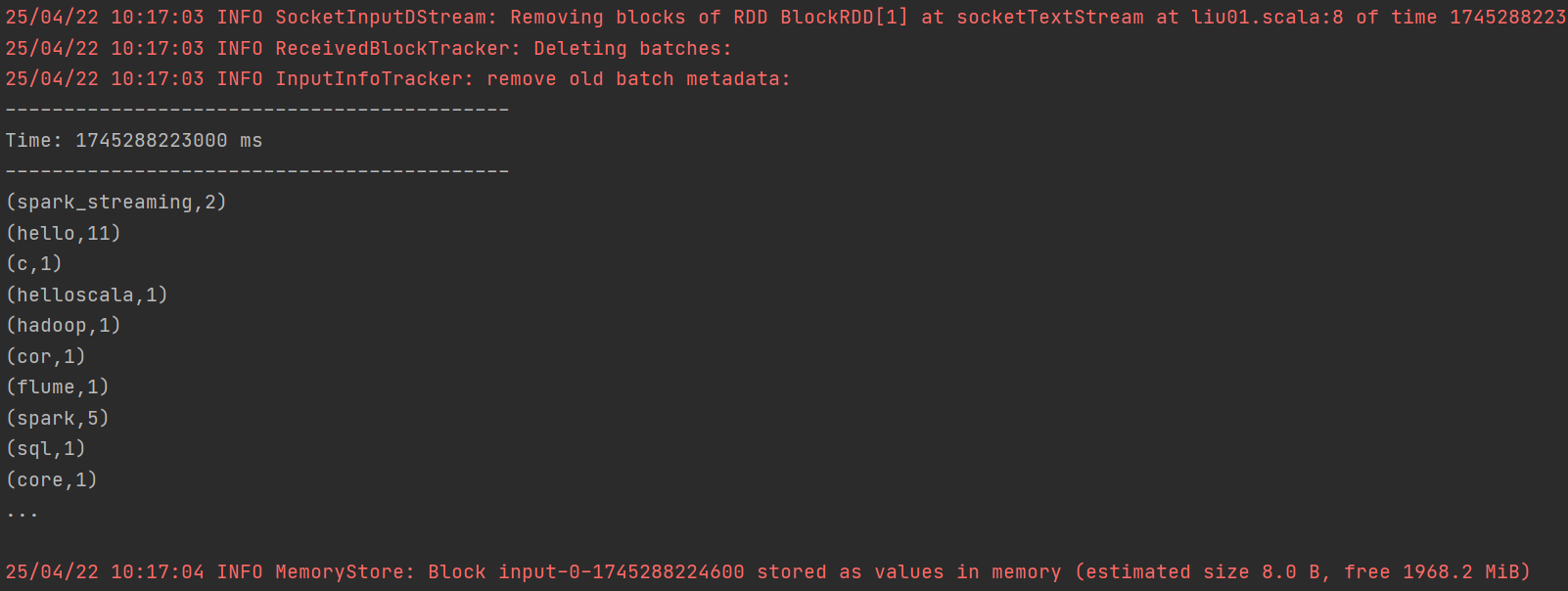

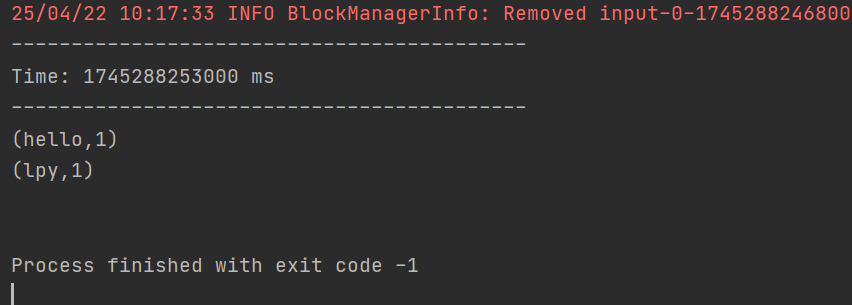
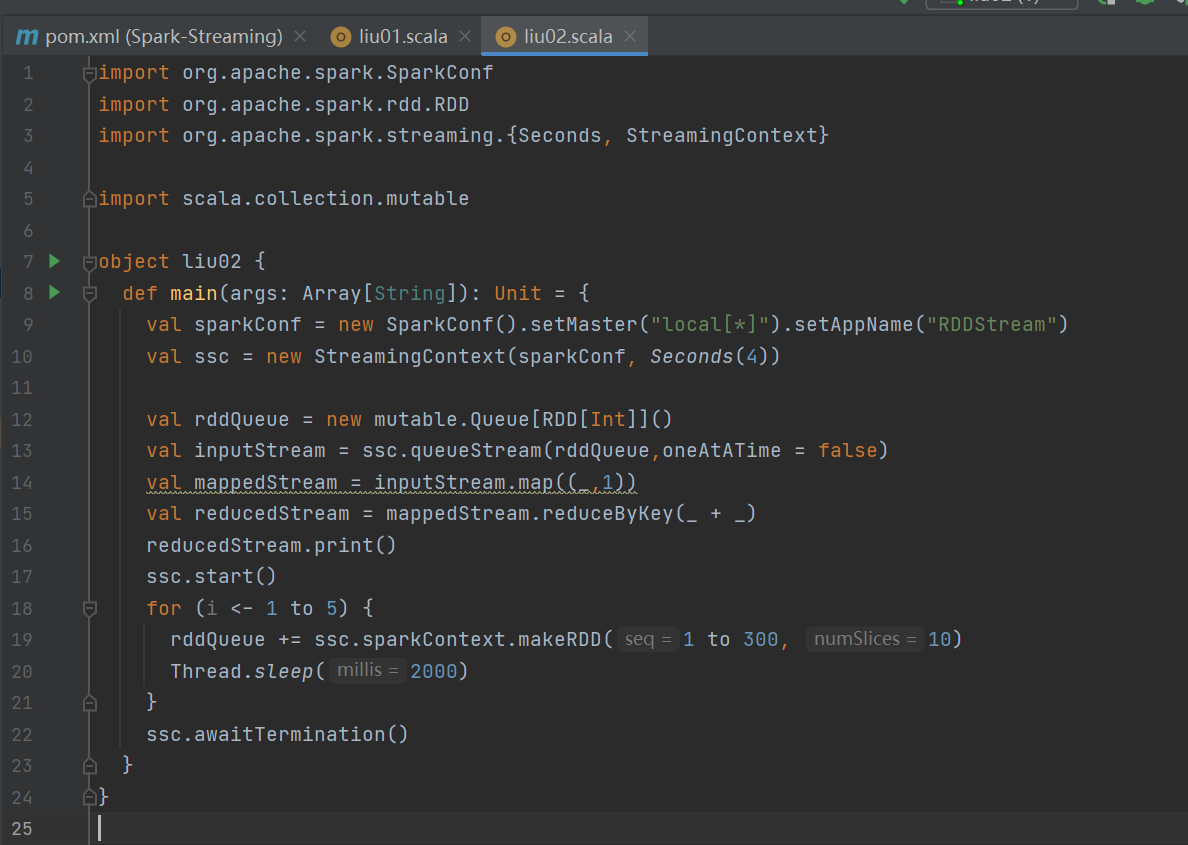
1. RDD队列创建DStream:可利用 ssc.queueStream(queueOfRDDs) 创建DStream,队列中的每个RDD都会被当作一个DStream处理。
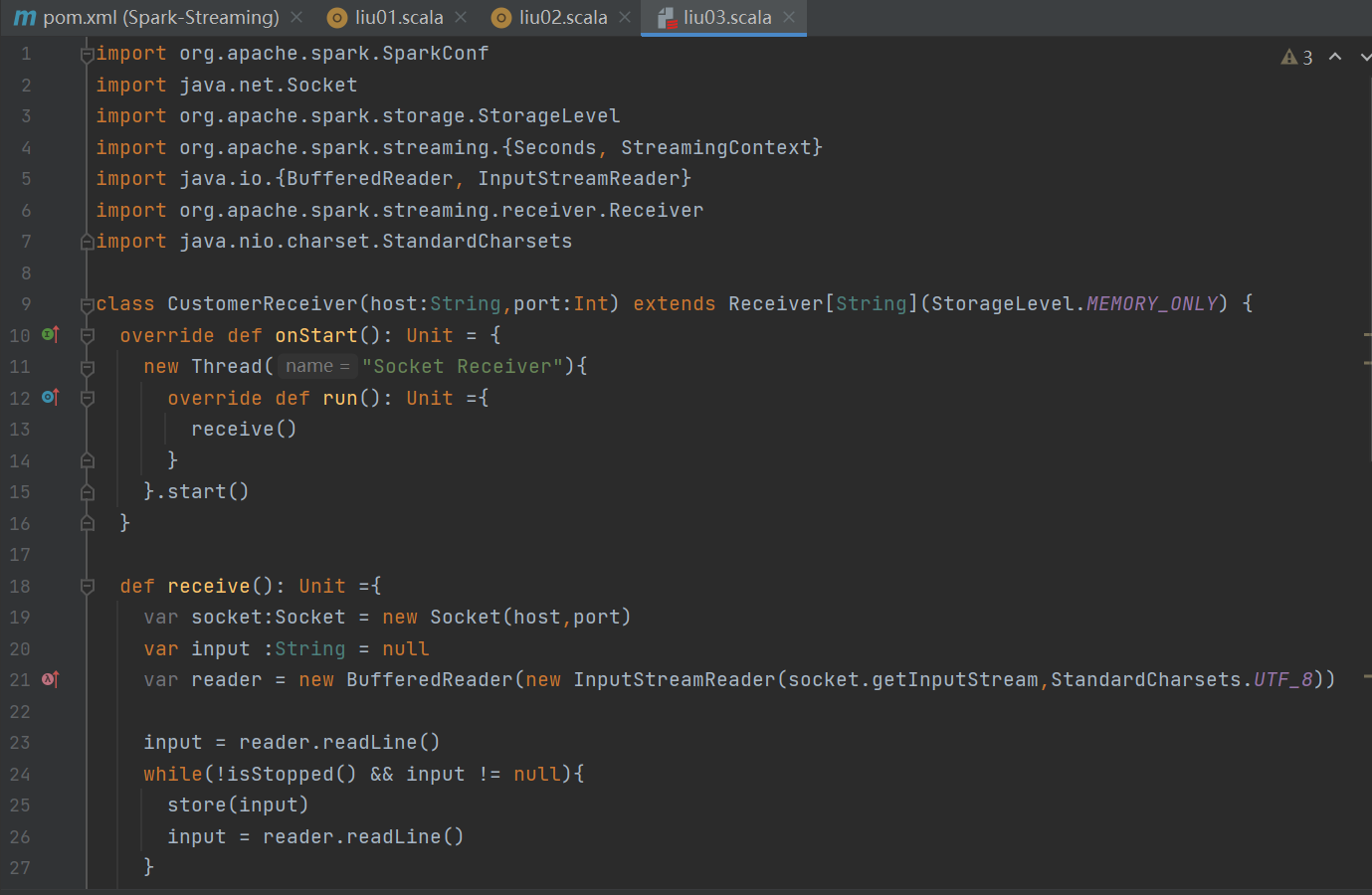
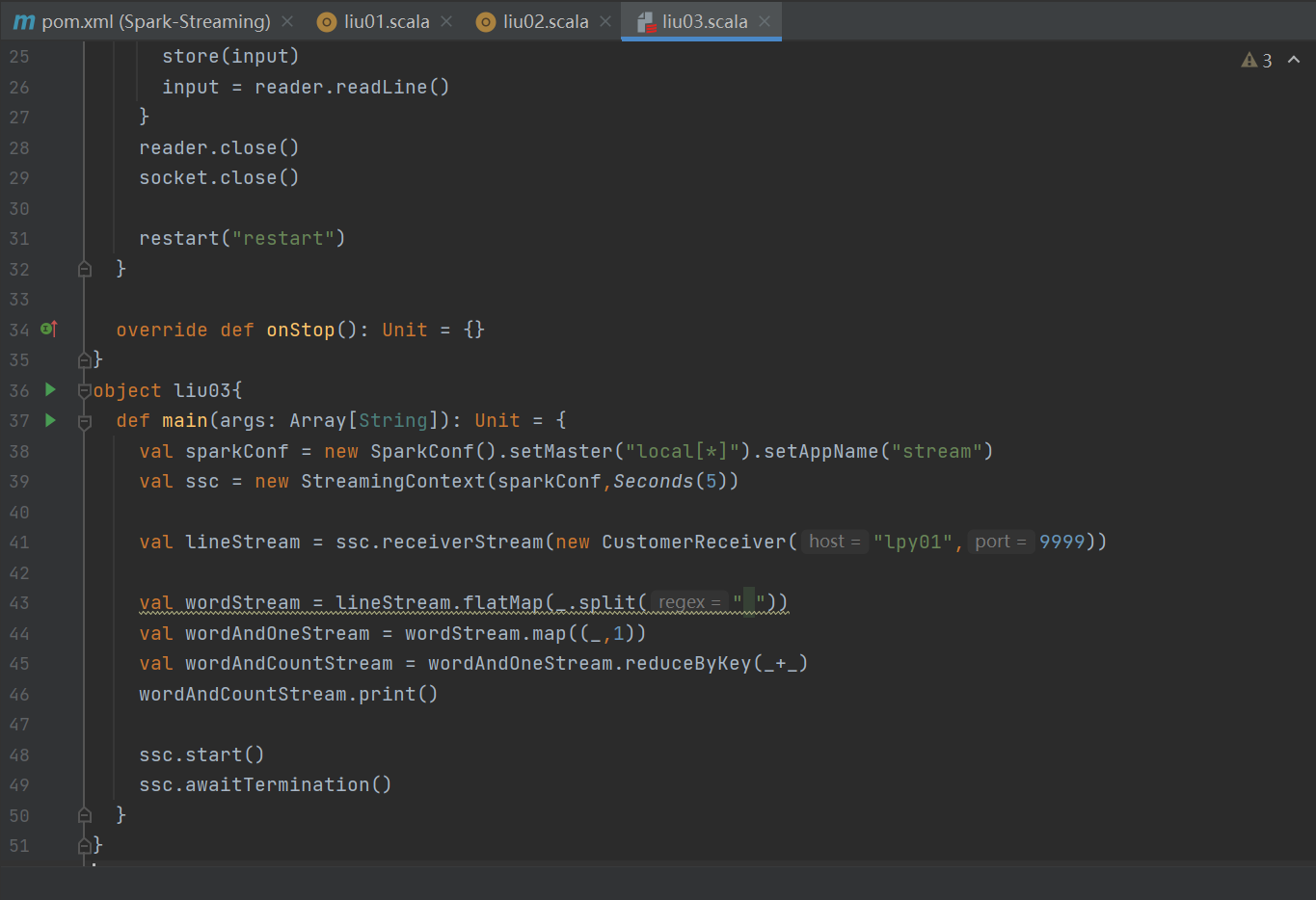
2. 自定义数据源创建DStream:自定义数据源需继承Receiver并实现 onStart 、 onStop 方法。