仅追加KV数据库
仅追加KV数据库
6.1 我们将要做什么
在本章中,我们将创建一个基于文件的键值存储(KV Store),其核心是一个写时复制(Copy-on-Write, CoW)B+ 树。这种设计的目标是实现数据的持久性和原子性。
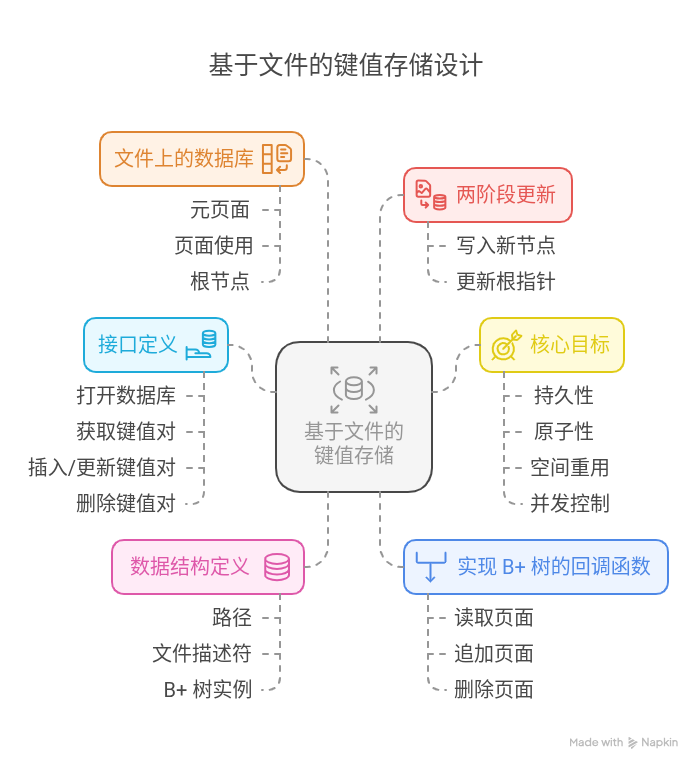
1. 设计概述
1.1 数据结构定义
type KV struct {Path string // 文件名// 内部字段fd int // 文件描述符tree BTree // B+ 树实例// 更多字段 ...
}
Path:存储文件的路径。fd:文件描述符,用于操作底层文件。tree:B+ 树实例,提供键值存储的核心功能。
1.2 接口定义
以下是 KV 提供的主要接口:
- 打开数据库:
func (db *KV) Open() error
- 打开或创建指定路径的文件,并初始化 B+ 树。
- 获取键值对:
func (db *KV) Get(key []byte) ([]byte, bool) {return db.tree.Get(key)
}
- 从 B+ 树中查找指定键,并返回对应的值和是否存在标志。
- 插入/更新键值对:
func (db *KV) Set(key []byte, val []byte) error {db.tree.Insert(key, val)return updateFile(db)
}
- 插入或更新键值对,并将更改写入文件。
- 删除键值对:
func (db *KV) Del(key []byte) (bool, error) {deleted := db.tree.Delete(key)return deleted, updateFile(db)
}
- 删除指定键值对,并将更改写入文件。
2. 核心目标
2.1 持久性
- 使用 追加写入(Append-Only) 的方式将数据写入文件。
- 每次修改都会生成新的页面,旧页面保持不变,确保数据不会因崩溃而丢失。
2.2 原子性
- 每次修改后,更新文件元信息以反映最新的树状态。
- 如果写入过程中发生崩溃,可以恢复到上次一致的状态。
2.3 空间重用
- 在本章中,我们忽略空间重用问题,所有数据都通过追加写入文件。
- 空间回收将在下一章中讨论。
2.4 并发控制
- 本章假设单进程顺序访问,忽略并发问题。
- 并发支持将在后续章节中实现。
3. 实现 B+ 树的回调函数
为了支持基于文件的 B+ 树,我们需要实现以下三个回调函数:
type BTree struct {root uint64get func(uint64) []byte // 读取页面new func([]byte) uint64 // 追加页面del func(uint64) // 删除页面(本章忽略)
}
6.2 两阶段更新
原子性 + 持久性
如第 3 章所述,对于写时复制树,根指针是被原子性更新的。然后使用 fsync 来请求并确认持久性。根指针本身的原子性是不够的;为了使整个树具有原子性,必须在根指针之前持久化新节点。由于缓存等因素,写入顺序并不是数据被持久化的顺序。因此,使用另一个 fsync 来确保顺序。
func updateFile(db *KV) error {// 1. 写入新节点。if err := writePages(db); err != nil {return err}// 2. 使用 `fsync` 强制执行步骤 1 和步骤 3 之间的顺序。if err := syscall.Fsync(db.fd); err != nil {return err}// 3. 原子性地更新根指针。if err := updateRoot(db); err != nil {return err}// 4. 使用 `fsync` 使所有内容持久化。return syscall.Fsync(db.fd)
}
替代方案:使用日志实现持久性
另一种双写方案也有两个包含 fsync 的阶段:
- 带校验和写入更新的页面。
- 使用
fsync使更新持久化(用于崩溃恢复)。 - 就地更新数据(应用双写)。
- 使用
fsync确保步骤 3 和步骤 1 的顺序(重用或删除双写)。
与写时复制的区别在于阶段的顺序:数据在第一次 fsync 后已持久化;数据库可以返回成功并将剩余操作放到后台完成。
双写类似于日志,日志每次更新也只需要一次 fsync。而且它可以是一个实际的日志,用来缓冲多个更新,从而提高性能。这是数据库中日志的另一个例子,除了 LSM 树之外。
我们不会使用日志,因为写时复制不需要它。但日志仍然提供了上述的好处;这也是日志在数据库中无处不在的原因之一。
内存数据的并发性
对于内存中的数据(关于并发性的原子性),可以通过互斥锁(mutex)或某些原子 CPU 指令来实现。存在一个类似的问题:由于乱序执行等因素,内存读/写可能不会按顺序出现。
对于内存中的写时复制树,在更新根指针之前,必须让新节点对并发读者可见。这称为内存屏障,类似于 fsync,尽管 fsync 不仅仅是强制顺序。
像互斥锁这样的同步原语,或者任何操作系统系统调用,将以一种可移植的方式强制内存顺序,因此你不必处理特定于 CPU 的原子操作或屏障(这些对于并发来说并不足够)。
6.3 文件上的数据库
文件布局
我们的数据库是一个单一文件,被划分为多个“页面”。每个页面都是一个 B+ 树节点,除了第一个页面;第一个页面包含指向最新根节点的指针和其他辅助数据,我们称这个页面为元页面(meta page)。
| 元页面 | 页面... | 根节点 | 页面... | (文件末尾)
| 根指针 | 页面使用 | | || | | |+----------|----------------+ || |+----------------------------+
新节点简单地像日志一样追加到文件中,但是我们不能使用文件大小来计算页面数量,因为在断电后,文件大小(元数据)可能与文件数据不一致。这取决于文件系统,我们可以通过在元页面中存储页面的数量来避免这个问题。
fsync 对目录的操作
正如第一章所述,在重命名之后必须对父目录使用 fsync。创建新文件时也是如此,因为有两件事情需要持久化:文件数据和引用该文件的目录。
我们将通过 O_CREATE 可能创建新文件后预执行 fsync。要同步一个目录,可以以只读模式 (O_RDONLY) 打开该目录。
func createFileSync(file string) (int, error) {// 获取目录文件描述符flags := os.O_RDONLY | syscall.O_DIRECTORYdirfd, err := syscall.Open(path.Dir(file), flags, 0o644)if err != nil {return -1, fmt.Errorf("open directory: %w", err)}defer syscall.Close(dirfd)// 打开或创建文件flags = os.O_RDWR | os.O_CREATEfd, err := syscall.Openat(dirfd, path.Base(file), flags, 0o644)if err != nil {return -1, fmt.Errorf("open file: %w", err)}// 同步目录if err = syscall.Fsync(dirfd); err != nil {_ = syscall.Close(fd) // 可能会留下空文件return -1, fmt.Errorf("fsync directory: %w", err)}return fd, nil
}
目录文件描述符可以由 openat 使用来打开目标文件,这保证了文件来自之前打开的同一个目录,以防目录路径在此期间被替换(竞态条件)。虽然这不是我们需要担心的问题,因为我们不期望有多进程操作。
mmap、页面缓存和 I/O
mmap 是一种将文件作为内存缓冲区进行读写的机制。使用 mmap 时,磁盘 I/O 是隐式的且自动完成的。
func Mmap(fd int, offset int64, length int, ...) (data []byte, err error)
为了理解 mmap,让我们回顾一些操作系统的基本概念。操作系统页面是虚拟地址和物理地址之间映射的最小单位。然而,进程的虚拟地址空间并不总是完全由物理内存支持;进程的一部分内存可以交换到磁盘上,当进程尝试访问它时:
- CPU 触发一个页面错误,将控制权交给操作系统。
- 操作系统然后:
- 将交换的数据读入物理内存。
- 重新映射虚拟地址到物理内存。
- 将控制权返回给进程。
- 进程继续运行,虚拟地址映射到实际的 RAM。
mmap 的工作原理与此类似,进程从 mmap 获得一个地址范围,当它访问其中的一个页面时,会发生页面错误,操作系统将数据读入缓存并重新映射页面到缓存。这就是只读场景下的自动 I/O。
当进程修改一个页面时,CPU 也会标记(称为脏位),以便操作系统稍后将页面写回磁盘。fsync 用于请求并等待 I/O 完成。这是通过 mmap 写入数据的方式,与 Linux 上的 write 并没有太大不同,因为 write 也进入相同的页面缓存。
你不必使用 mmap,但理解这些基础知识是很重要的。
6.4 管理磁盘页面
我们将使用 mmap 来实现这些页面管理回调,因为它非常方便。
func (db *KV) Open() error {db.tree.get = db.pageRead // 读取页面db.tree.new = db.pageAppend // 追加页面db.tree.del = func(uint64) {}// ...
}
调用 mmap
文件支持的 mmap 可以是只读(read-only)、读写(read-write)或写时复制(copy-on-write)。要创建一个只读的 mmap,可以使用 PROT_READ 和 MAP_SHARED 标志。
syscall.Mmap(fd, offset, size, syscall.PROT_READ, syscall.MAP_SHARED)
映射的范围可以大于当前文件大小,这是一个我们可以利用的事实,因为文件会增长。
mmap 处理增长的文件
mremap 重新映射到更大的范围,类似于 realloc。这是处理增长文件的一种方法。然而,地址可能会改变,这可能会影响后续章节中的并发读者。我们的解决方案是添加新的映射来覆盖扩展的文件。
type KV struct {// ...mmap struct {total int // mmap 大小,可以大于文件大小chunks [][]byte // 多个 mmap,可能是非连续的}
}
BTree.get:读取页面
func (db *KV) pageRead(ptr uint64) []byte {start := uint64(0)for _, chunk := range db.mmap.chunks {end := start + uint64(len(chunk))/BTREE_PAGE_SIZEif ptr < end {offset := BTREE_PAGE_SIZE * (ptr - start)return chunk[offset : offset+BTREE_PAGE_SIZE]}start = end}panic("bad ptr")
}
每次扩展文件时添加一个新的映射会导致大量映射,这对性能不利,因为操作系统需要跟踪它们。通过指数增长避免了这个问题,因为 mmap 可以超出文件大小。
func extendMmap(db *KV, size int) error {if size <= db.mmap.total {return nil // 足够的范围}alloc := max(db.mmap.total, 64<<20) // 将当前地址空间加倍for db.mmap.total + alloc < size {alloc *= 2 // 仍然不够?}chunk, err := syscall.Mmap(db.fd, int64(db.mmap.total), alloc,syscall.PROT_READ, syscall.MAP_SHARED, // 只读)if err != nil {return fmt.Errorf("mmap: %w", err)}db.mmap.total += allocdb.mmap.chunks = append(db.mmap.chunks, chunk)return nil
}
你可能会问,为什么不直接创建一个非常大的映射(比如 1TB),然后忘记文件的增长呢?毕竟未实现的虚拟地址不会产生任何成本。对于 64 位系统上的玩具数据库来说,这是可以接受的。
捕获页面更新
BTree.new 回调从 B+ 树更新中收集新页面,并从数据库末尾分配页面编号。
type KV struct {// ...page struct {flushed uint64 // 数据库大小(以页面数计)temp [][]byte // 新分配的页面}
}
pageAppend:追加页面
func (db *KV) pageAppend(node []byte) uint64 {ptr := db.page.flushed + uint64(len(db.page.temp)) // 直接追加db.page.temp = append(db.page.temp, node)return ptr
}
这些页面在 B+ 树更新后被写入(追加)到文件中。
写入页面
func writePages(db *KV) error {// 如果需要,扩展 mmapsize := (int(db.page.flushed) + len(db.page.temp)) * BTREE_PAGE_SIZEif err := extendMmap(db, size); err != nil {return err}// 将数据页面写入文件offset := int64(db.page.flushed * BTREE_PAGE_SIZE)if _, err := unix.Pwritev(db.fd, db.page.temp, offset); err != nil {return err}// 丢弃内存中的数据db.page.flushed += uint64(len(db.page.temp))db.page.temp = db.page.temp[:0]return nil
}
pwritev 是带偏移量和多个输入缓冲区的 write 的变体。
我们需要控制偏移量,因为我们稍后还需要写入元页面。多个输入缓冲区由内核合并。
6.5 元页面
读取元页面
我们将向元页面添加一些魔数(magic bytes)以识别文件类型。
const DB_SIG = "BuildYourOwnDB06" // 各章节之间不兼容// | sig | root_ptr | page_used |
// | 16B | 8B | 8B |func saveMeta(db *KV) []byte {var data [32]bytecopy(data[:16], []byte(DB_SIG))binary.LittleEndian.PutUint64(data[16:], db.tree.root)binary.LittleEndian.PutUint64(data[24:], db.page.flushed)return data[:]
}func loadMeta(db *KV, data []byte) {if string(data[:16]) != DB_SIG {panic("invalid database signature")}db.tree.root = binary.LittleEndian.Uint64(data[16:24])db.page.flushed = binary.LittleEndian.Uint64(data[24:32])
}
当文件为空时,会预留元页面。
func readRoot(db *KV, fileSize int64) error {if fileSize == 0 { // 空文件db.page.flushed = 1 // 在首次写入时初始化元页面return nil}// 读取页面data := db.mmap.chunks[0]loadMeta(db, data)// 验证页面// ...return nil
}
更新元页面
写少量页对齐的数据到实际磁盘上,只修改单个扇区,在硬件级别可能是掉电原子性的。一些真正的数据库依赖于此特性。这也是我们更新元页面的方式。
// 3. 更新元页面。它必须是原子的。
func updateRoot(db *KV) error {if _, err := syscall.Pwrite(db.fd, saveMeta(db), 0); err != nil {return fmt.Errorf("write meta page: %w", err)}return nil
}
然而,原子性在不同的层级意味着不同的事情,正如你所见,重命名也是如此。对于系统调用级别的并发读者而言,write 并不是原子性的。这可能是因为页面缓存的工作原理。
当我们添加并发事务时,将考虑读写的原子性,但我们已经看到了一种解决方案:在 LSM 树中,只有第一级会被更新,并且它作为 MemTable 被复制,从而将并发问题移到了内存中。我们可以保持元页面的内存副本,并使用互斥锁进行同步,从而避免并发的磁盘读/写。
即使硬件在掉电情况下不是原子性的,通过日志加校验和也可以实现原子性。我们可以在每次更新时切换两个带校验和的元页面,以确保掉电后至少有一个元页面是完好的。这被称为双缓冲(double buffering),是一个有两个条目的循环日志。
这种机制不仅提高了系统的可靠性,还确保了即使发生意外断电,数据库也能恢复到一个一致的状态。通过这种方式,可以有效地管理元数据的更新,并保证其一致性与持久性。
6.6 错误处理
IO 错误后的场景
错误处理的最低要求是通过 if err != nil 传播错误。接下来,考虑在发生 IO 错误(如 fsync 或 write)后继续使用数据库的可能性:
-
在更新失败后读取数据?
- 合理的选择是表现得像什么都没发生一样。
-
在失败后再次更新?
- 如果错误仍然存在,则预计会再次失败。
- 如果错误是暂时的,能否从之前的错误中恢复?
-
在问题解决后重新启动数据库?
- 这只是崩溃恢复;已在第 3 章讨论过。
回滚到之前的版本
有一项调查研究了 fsync 失败的处理方法。从中我们可以了解到,这个主题与文件系统相关。如果我们在 fsync 失败后读取数据,某些文件系统会返回失败的数据,因为页面缓存与磁盘不匹配。因此,回读失败的写入是有问题的。
但因为我们使用的是写时复制(copy-on-write),这并不是问题;我们可以回滚到旧的树根以避免问题数据。树根存储在元页面中,但我们从未在打开数据库后从磁盘读取元页面,因此只需回滚内存中的根指针即可。
func (db *KV) Set(key []byte, val []byte) error {meta := saveMeta(db) // 保存内存状态(树根)db.tree.Insert(key, val)return updateOrRevert(db, meta)
}func updateOrRevert(db *KV, meta []byte) error {// 两阶段更新err := updateFile(db)// 在错误时回滚if err != nil {// 内存状态可以立即回滚以允许读取loadMeta(db, meta)// 丢弃临时数据db.page.temp = db.page.temp[:0]}return err
}
因此,在写入失败后,仍然可以以只读模式使用数据库。读取也可能失败,但由于我们使用的是 mmap,在读取错误时进程会被 SIGBUS 杀死。这是 mmap 的缺点之一。
从临时写入错误中恢复
一些写入错误是暂时的,例如“磁盘空间不足”。如果一次更新失败,而下一次成功,则最终状态仍然是好的。问题在于中间状态:在两次更新之间,磁盘上的元页面内容是未知的!
如果 fsync 在元页面上失败,磁盘上的元页面可能是新版本或旧版本,而内存中的树根是旧版本。因此,第二次成功的更新会覆盖较新版本的数据页面,如果此时发生崩溃,可能会导致损坏的中间状态。
解决方案是在恢复时重写最后已知的元页面。
type KV struct {// ...failed bool // 上次更新是否失败?
}func updateOrRevert(db *KV, meta []byte) error {// 确保在错误后磁盘上的元页面与内存中的一致if db.failed {// 写入并同步之前的元页面// ...db.failed = false}err := updateFile(db)if err != nil {// 磁盘上的元页面处于未知状态;// 标记它以便在后续恢复时重写。db.failed = true// ...}return err
}
对文件系统的依赖性
我们依赖文件系统正确报告错误,但有证据[4]表明它们并不总是能做到这一点。因此,整个系统是否能够正确处理错误仍然是值得怀疑的。
总结
-
错误传播:
- 使用
if err != nil检查和传播错误是最基本的方式。
- 使用
-
回滚机制:
- 写时复制允许我们回滚到旧的树根,避免损坏的数据。
- 回滚通过内存中的元页面实现,无需从磁盘重新加载。
-
临时错误恢复:
- 对于临时错误(如磁盘空间不足),可以通过重写最后已知的元页面来确保一致性。
-
文件系统的不确定性:
- 文件系统可能无法正确报告错误,因此需要额外的措施来应对潜在的不可靠性。
通过这些机制,数据库能够在发生 IO 错误时保持一定程度的可用性和一致性,同时为未来的恢复提供保障。