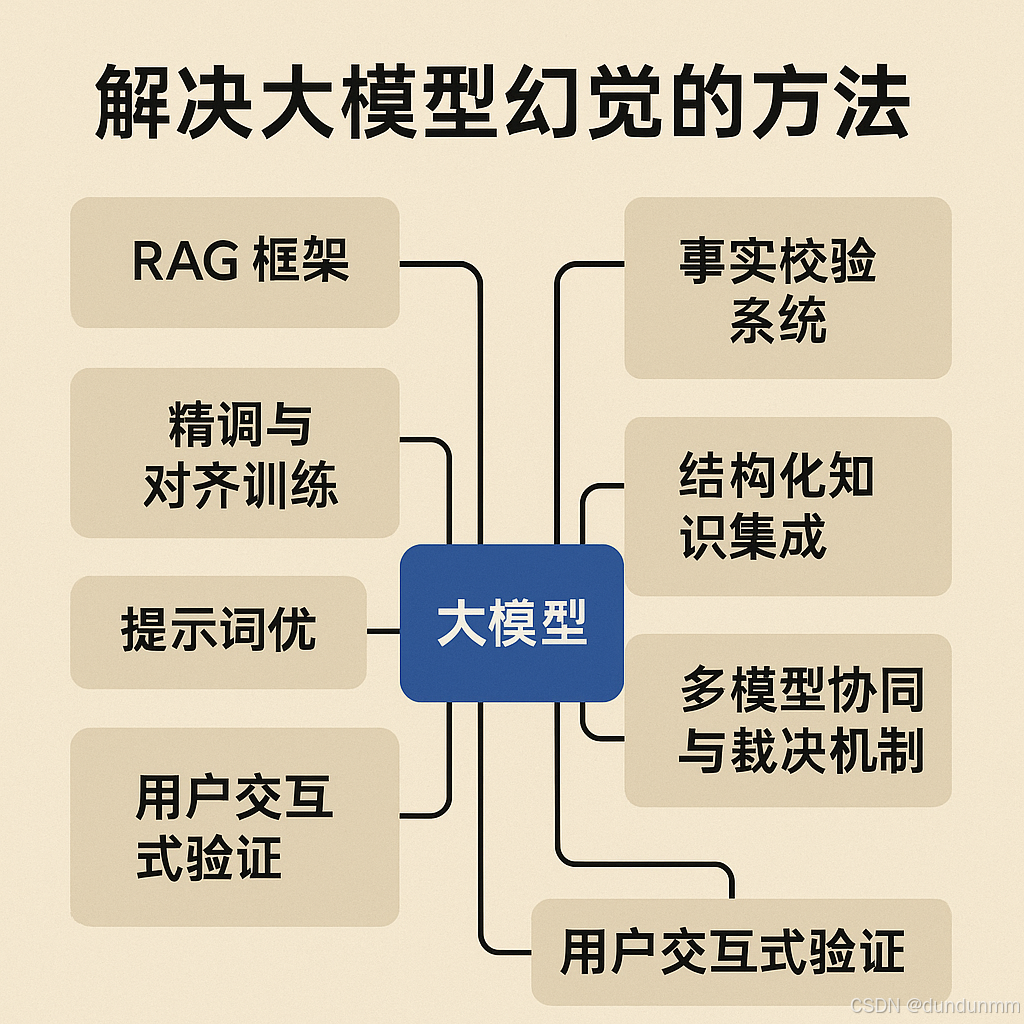
【每天一个知识点】如何解决大模型幻觉(hallucination)问题?
解决大模型幻觉(hallucination)问题,需要从模型架构、训练方式、推理机制和后处理策略多方面协同优化。
🧠 1. 引入 RAG 框架(Retrieval-Augmented Generation)
思路: 模型生成前先检索知识库中的真实信息作为上下文输入,让生成“有据可依”。
-
✅ 结合外部数据库、文档系统或向量知识库
-
✅ 常用于问答、总结、金融分析等领域
-
🔧 示例工具:FAISS、Elasticsearch、Milvus
🎯 2. 精调与对齐训练(Alignment Fine-tuning)
用高质量的真实数据或人工标注数据对模型再训练。
-
✅ 训练时加入“拒绝回答不确定内容”的偏好
-
✅ 使用RLHF(人类反馈强化学习)提升真实性与安全性
-
✅ 结合指令微调(Instruction Tuning)防止过度自由发挥
🛠️ 3. 提示词优化(Prompt Engineering)
精细设计prompt,引导模型关注事实和来源。
-
✅ 加入如“请基于以下文档回答”、“请注明出处”
-
✅ 提出明确限制:“如不知道请说明不知道”
-
✅ 通过 few-shot 提示加入“回答示例”来约束行为
🧾 4. 事实校验系统(Fact-checking Module)
在生成后,使用另一个模块来自动检验真假或一致性。
-
✅ 提取生成内容中的主张,去知识源中比对
-
✅ 使用NLI(自然语言推理)判断事实一致性
-
✅ 构建“可信度评分”系统筛选或标记高风险回答
🧩 5. 结构化知识集成(Knowledge Injection)
将知识图谱、结构化数据库中的内容融入上下文。
-
✅ 在生成任务中插入规则知识或约束
-
✅ 使用Schema/Slot填空方式确保字段准确
-
✅ 常用于金融、法律、医疗等要求高度准确的场景
📶 6. 多模型协同与裁决机制
多个模型生成多个版本,通过比对、投票或裁判选择最可信答案。
-
✅ 可显著提升准确性
-
✅ 增加稳定性和鲁棒性(尤其适用于自动报告生成)
-
⚠️ 成本较高,适合关键任务使用
✅ 7. 用户交互式验证(Human-in-the-loop)
在关键任务场景中,设计交互机制让用户校对或确认模型输出。
-
例如生成报告草稿→用户确认→模型修订
-
可视化高风险片段,提供编辑建议
📌 总结一句话:
“让模型懂得‘不知道’比假装知道更重要。”
——要想降低幻觉,不仅要提升知识准确度,还要让模型“知道它不知道”的边界。