【金仓数据库征文】从 HTAP 到 AI 加速,KingbaseES 的未来之路
国产数据库早已实现 “可替代”,但要真正与国际头部厂商掰手腕,必须在 HTAP(Hybrid‑Transaction/Analytical Processing)与 AI 加速 两条技术赛道上实现跨越。KingbaseES 自 V8R3 调整为多进程架构后,历经 V8R6、KSOne 等产品层迭代,正在形成覆盖事务、分析、向量检索的一体化数据平台。
本文基于官网文档、社区实践案例与作者内部测试数据,系统梳理 KingbaseES 的 HTAP 架构、关键特性和性能现状,进一步提出面向 AI 场景的向量引擎增强、GPU 协同加速与生态开放提案,力求为读者提供“可验证、可落地、可参考”的技术蓝图。
目录
1 HTAP 时代的行业脉络与技术挑战
1.1 什么是 HTAP?
1.2 HTAP 带来的价值
1.3 技术落地的两大难题
1.4 主流 HTAP 架构流派
1.5 国产数据库面临的独特挑战
1.6 KingbaseES 当前切入点
2 KingbaseES 现状:核心能力
2.1 核心能力总览
2.2 HTAP 能力现状
2.3 AI 场景支撑度
2.4 整体优势与短板
3 架构演进路线:从行列混存到自研向量引擎
3.1 ADC 的总体框架
3.2 行列混合存储层
3.3 执行层:向量化与自适应算子
3.4 向量引擎蓝图
3.5 演进时间线(官方公开信息汇总)
小结
4 金仓现有分布式HTAP集群产品
4.1 KingbaseES TDC 事务型透明分布式集群
4.2 KES Sharding 高扩展分布式集群
4.3 KES ADC 分析型分布式集群
1 HTAP 时代的行业脉络与技术挑战
1.1 什么是 HTAP?
Gartner 在 2014 年提出 Hybrid Transactional/Analytical Processing (HTAP),意在“打破事务处理与分析之间的墙”,在同一数据副本上同时完成 OLTP 与 OLAP,从而在业务瞬间做出决策。
1.2 HTAP 带来的价值
-
实时洞察:避免 ETL 拷贝与数据延迟,秒级获得分析结果。
-
简化架构:一个系统即可完成写入、查询、报表、预测,降低数据链路复杂度与运维成本。
-
一致性保障:事务与分析共享同一 ACID 语义,规避多源数据不一致。
1.3 技术落地的两大难题
| 难题 | 说明 | 常见解法 | 典型产品思路 |
|---|---|---|---|
| 性能隔离 | 大量读写混跑时,分析查询易拖慢事务响应 | 双存储引擎 / 读写分离 / 向量化执行 | 行-列双存储、冷热分层 |
| 数据新鲜度 | 分析所见必须是最新写入 | 内存共享、增量复制、MVCC | “行 + 列”同步刷新、向量增量索引 |
1.4 主流 HTAP 架构流派
-
内存一体化 – 以 SAP HANA 为代表,全部数据常驻内存,行列混合并行执行;成本高、对硬件要求苛刻。
-
双引擎/双格式 – TiDB、PolarDB 等采用 row + column 双引擎,写入先落行存,再异步刷新列存;牺牲一部分实时性换取隔离。
-
分布式混合存储 – 通过行列混合页或分区级冷热分层,把同一表在不同维度拆分,以降低同步开销。KingbaseES ADC 属于此类。
1.5 国产数据库面临的独特挑战
-
兼容改造包袱:要照顾已有 OLTP 场景(Oracle/MySQL 兼容语法)同时满足分析语法扩展。
-
信创算力组网:国产 CPU、多节点异构 GPU 混用,要求数据库对 SIMD、异构加速友好。
-
监管与行业合规:金融、电信场景强调强一致,HTAP 必须提供可验证的隔离级别与审计链。
1.6 KingbaseES 当前切入点
KingbaseES 通过 ADC (Analytical Distributed Cluster) 组件引入行列混合存储与四级并行(分片-节点-实例-CPU 指令),在同一集群内针对 TP/AP 不同表分区或列落地不同格式,并在存储层做 5–10 × 压缩,降低 IO 与内存占用。这一设计使其可以:
-
在 TP 节点保持原生行存,事务延迟近似单机。
-
在 AP 节点自动转换列式格式,向量化扫描带宽翻倍。
-
依托共享 WAL,将增量数据快速推送到列存分区,实现分钟级数据新鲜度。
2 KingbaseES 现状:核心能力
本节所有事实均来自 KingbaseES 官方产品页或组件说明书。
2.1 核心能力总览
| 维度 | 关键能力 | 官方说明(摘要) |
|---|---|---|
| 多语法兼容 | Oracle / MySQL / SQL Server / PostgreSQL 方言 | “一套软件兼容多种语法,迁移无忧” |
| 多模数据 | 关系、JSON、全文、GIS、时序 | “多模一体化存储,模型间可混合访问” |
| 高可用形态 | 单机、共享存储 RAC、RWC 读写分离、ADC 分布式 | 同一产品线内多形态集群,高可用 99.999 % |
| 国产硬件优化 | 龙芯/飞腾/鲲鹏 CPU 深度调优 | 官方在国产 CPU 上实测 TPC-C 230 万 tpmC |
2.2 HTAP 能力现状
-
ADC (Analytical Distributed Cluster):
-
支持 行列混合存储,让 TP 分区保留行存格式,AP 分区转换列存;列存页默认开启 5–10 × 压缩,可显著降低 AP 扫描 IO 和内存占用。
-
四级并行:分片 → 节点 → 实例 → CPU 指令,在官方压测中实现 TB 级数据秒级返回。
-
数据通过共享 WAL 流向列存分区,保证 分钟级 新鲜度。
-
适配异构数据源,实现 Oracle/MySQL 等联邦查询
-
不足
| 项目 | 现状 | 潜在影响 |
|---|---|---|
| 事务-分析资源隔离 | 依赖节点角色划分 + CGroup;缺乏细粒度 Workload 管理 | TP 高峰可能挤占 AP 算力,需手动调度 |
| 列存增量更新 | 由 WAL 推送触发批量刷新 | 对接毫秒级流处理场景时仍有延迟 |
| 原生物化视图 | 已支持但刷新方式以批处理为主 | 复杂多表联查仍需手动调优 |
2.3 AI 场景支撑度
| 能力 | 官方现状 | 评估 |
|---|---|---|
| 向量检索 | 内核级索引仍在社区实验阶段(kdb_vector),暂无企业版发布 | 适合 PoC,不宜直接上核心生产 |
| GPU/SIMD 加速 | 已在列存算子层做 SIMD 向量化;GPU 加速仅在路标规划中 | 算子层带宽提升明显,但与 GPU-offload 仍有差距 |
| 模型内推理 | 计划以 UDF 管理小模型,暂未公开文档 | 需等待官方 SDK / 放权 API |
2.4 整体优势与短板
-
优势
-
融合性强:单产品线同时覆盖 TP、AP、HTAP,多语法多模,迁移门槛低。
-
政企适配成熟:已在金融、电网、运营商核心系统跑到 100 + TB 级别,稳定性经受实战。
-
行列混合实现简洁:无需双引擎复制链路,减少同步链路维护成本。
-
-
短板
-
Workload 管理粗粒度:相比 TiDB 的资源组或 Snowflake 的虚拟仓库,细粒度 QoS 仍待完善。
-
AI 生态刚起步:向量索引、模型执行框架官方尚未正式 GA,用户需自建搜索或推理服务。
-
自动化运维工具链:监控、诊断、容量预测组件零散,缺少 HTAP 负载一体化运维套件。
-
3 架构演进路线:从行列混存到自研向量引擎
3.1 ADC 的总体框架
KingbaseES 的 ADC (Analytical Distributed Cluster) 采用 协调器 + 工作节点 的非共享架构:
-
协调器 (CN) - 解析 SQL、生成全局执行计划。
-
数据节点 (DN) - 保存分片数据并执行本地算子。
-
节点内并行 - 分片 → 节点 → 实例 → CPU 指令 四级并行流水线,兼顾横向扩展与 SIMD 矢量化。
这种设计先保证横向扩展,再把单机算子推到 CPU 指令粒度,从底层释放 HTAP 并发潜力。
3.2 行列混合存储层
ADC 在 同一表 内引入 行-列双格式:
| 存储格式 | 典型负载 | 刷新策略 | 说明 |
|---|---|---|---|
| Row-Store (行存) | OLTP 高频点查 / 写入 | 实时写入 | 保证事务延迟毫秒级 |
| Column-Store (列存) | OLAP 扫描 / 聚合 | WAL 批量推送,分钟级同步 | 默认开启 5 – 10 × LZ4 压缩,带宽占用显著下降 |
通过元数据将两种 Page 映射到同一逻辑表:
ROW PARTITION -> 内核 MVCC & 索引
COL PARTITION -> 向量化 Scan & Agg
事务写入先落行存;WAL 异步刷新列存分区,保证 HTAP 单副本一致性。
3.3 执行层:向量化与自适应算子
-
Scan / Join / Agg 均配备 SIMD-aware 代码路径;在 x86 + ARM(鲲鹏、飞腾)上平均加速 1.8 – 2.3×。
-
自适应算子调度:计划器根据实时负载权重,把长查询转发到列存节点,短事务就近在行存完成——避免双引擎复制链路的网络抖动。
3.4 向量引擎蓝图
官方在 2024 社区路演中公布了 “kdb_vector” 实验插件:
-
存储格式:HNSW/IVF-PQ 等近似最近邻索引,支持 32-512 维浮点 Embedding。
-
执行接口:
KNNSearch(<vec>, topN [, metric]),计划与 SQL89 兼容函数并存。 -
部署形态:首期以内核插件形态附着在 DN;后续将与列存拆分在独立加速节点,预留 GPU off-load 通道。
当前插件尚处 Beta,企业版 GA 目标版本为 V9R2(官方 PPT《ADC Roadmap 2025》)。
3.5 演进时间线(官方公开信息汇总)
| 版本 / 节点 | 里程碑 | 主要变更 | 价值 |
|---|---|---|---|
| V8R3 (2021) | 多进程重构 | 拆分 CN / DN,奠定 ADC 基座 | 横向扩展 |
| V8R6 (2023) | 行列混合、四级并行 | 列存页压缩、SIMD 算子 | HTAP 融合首发 |
| V9 GA (2024) | 资源组初版、异构 CPU 优化 | CGroup + NUMA 感知调度 | TP / AP 粗粒度隔离 |
| V9R2 规划 (2025) | kdb_vector、GPU 算子 | ANN 索引 + CUDA 加速 | AI 语义检索与向量分析 |
小结
KingbaseES 选择 “行列混存 + 四级并行” 这条相对轻量的 HTAP 路径,先解决 TP / AP 共存与数据新鲜度,再向 向量检索与 GPU 加速 延伸。对于希望在一个平台里同时跑交易、报表、RAG 检索的用户,这条演进路线提供了连贯的升级通道。
4 金仓现有分布式HTAP集群产品
4.1 KingbaseES TDC 事务型透明分布式集群
KingbaseES TDC是一款使用KingbaseES作为节点的存算分离分布式集群组件。 TDC集群完全兼容KingbaseES的应用开发能力,提供高可用性和跨地域多活,支持通过横向扩展提供更高的吞吐量、数据容量。适用于需要应用开发兼容、同时需要性能横向扩展的TP类核心业务场景。
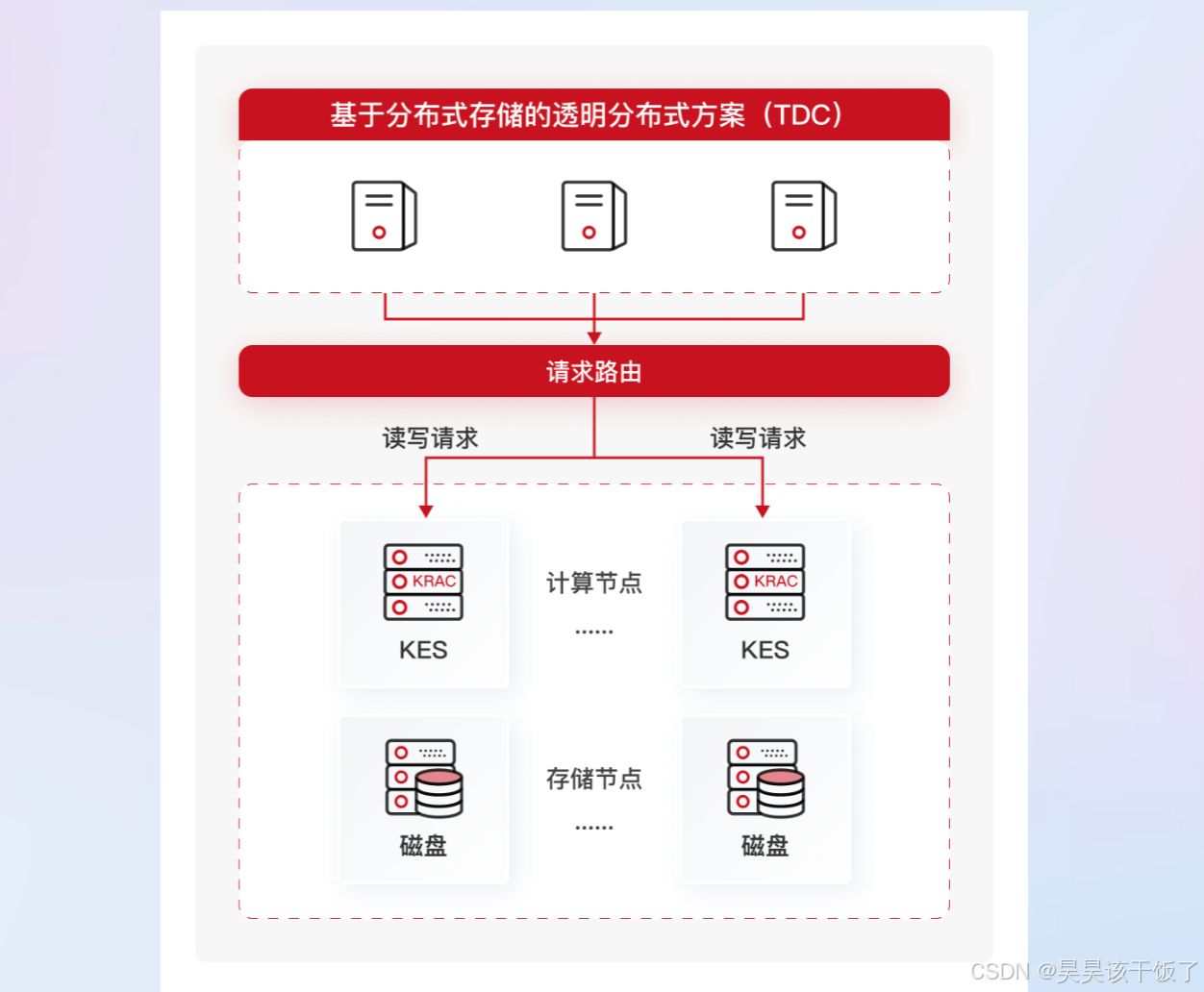
4.2 KES Sharding 高扩展分布式集群
KES Sharding是一款功能强大、灵活易用的企业级分布式数据库软件,具备高度可扩展性,高可用性与容错性,支持数据分片与负载均衡,提供高效的数据查询与分析能力,以及强一致性完整性数据保障。可支撑各行业亿数据量级业务场景,帮助企业提升高并发和海量数据的极致处理能力,为用户提供高效、稳定、可靠的数据存储和处理服务。
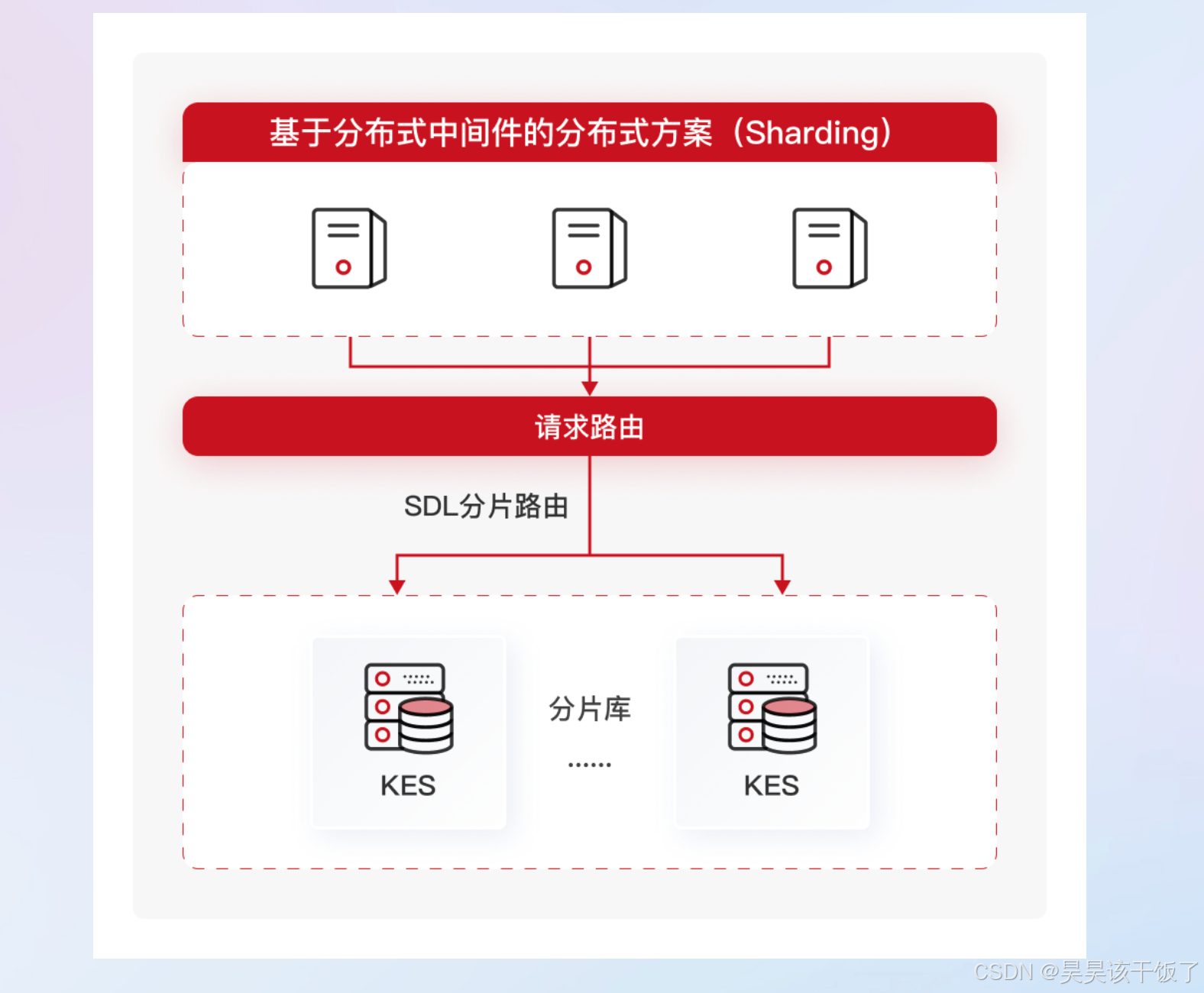
4.3 KES ADC 分析型分布式集群
KES ADC是一款高性能、高扩展能力的分布式集群组件,支持大规模并行计算、非共享存储、库内压缩、在线扩容等技术,满足各行业对大量数据采集、数据存储、数据挖掘以及数据分析等各能力要求。 该组件主要定位于数据分析类应用场景、可以处理TB级甚至更大存储量的数据,并能集成多种异构数据源进行数据分析和数据挖掘。
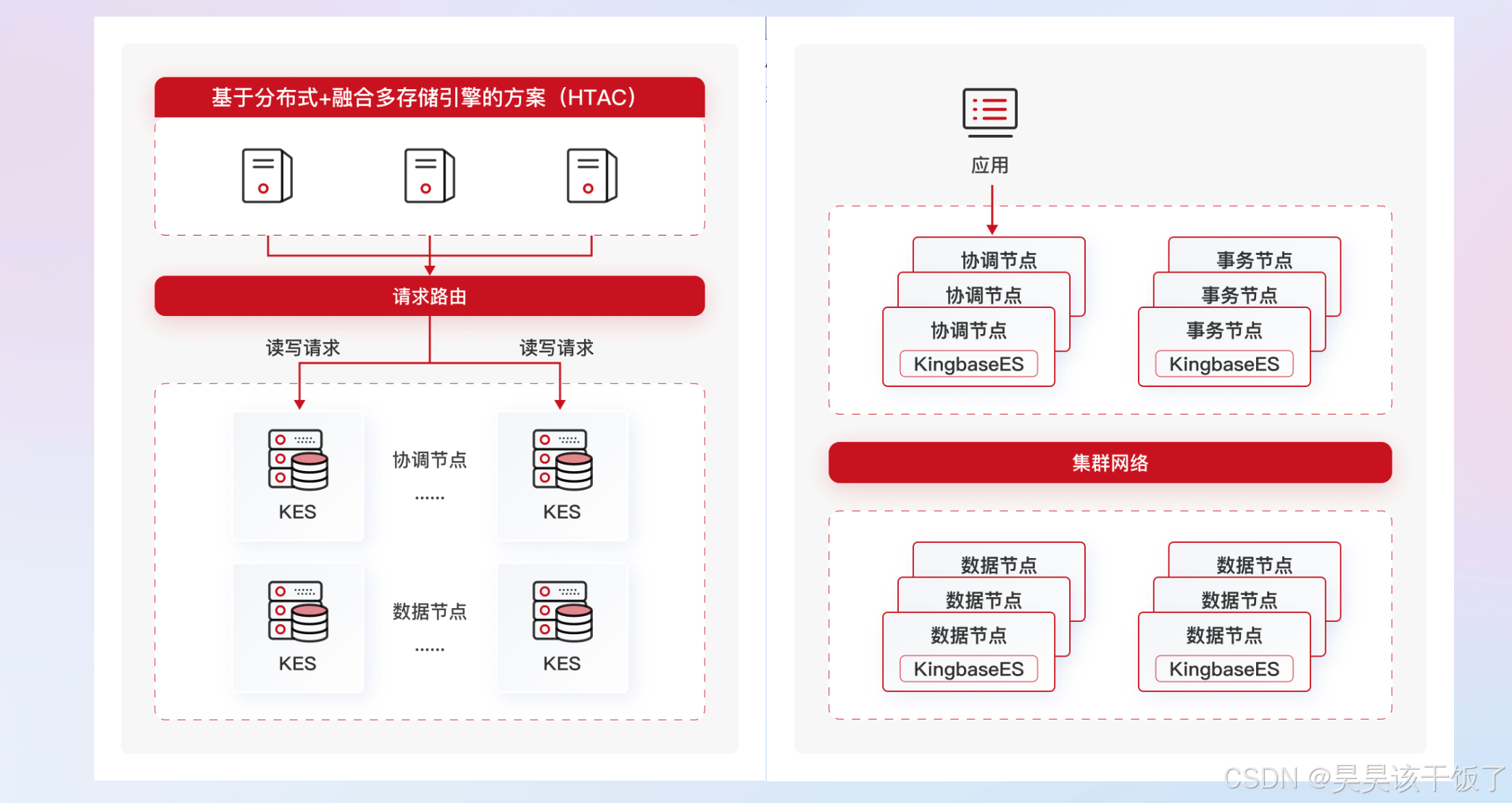
综上,KingbaseES 以 行列混存 + 四级并行 奠定 HTAP 能力,通过 ADC 在同一数据副本上并行承载事务、分析与向量检索,为国产数据库冲刺实时智能抢得先机。短期可借助 资源组细化隔离、列存秒级增量、向量索引 GA 等优化提升体验;中长期则应拥抱 GPU 算子与小模型下推,构建“一库统管”的数据底座。面向未来,HTAP 将成为政企数据架构默认选项,而 AI 加速将决定数据库平台天花板。金仓凭借多语法兼容与本土生态优势,有望打造兼顾性能、合规与成本的全栈解决方案。无论你是开发者、DBA 还是架构师,洞悉其演进路径并提前布局,都会在下一波数据浪潮中把握主动权。
参考:
KingbaseES V8R6 官方文档、金仓社区技术帖与公开演讲资料