ReAct Agent 实战:基于DeepSeek从0到1实现大模型Agent的探索模式
写在前面:动态思考,边想边做
大型语言模型(LLM)的崛起开启了通用人工智能(AGI)的无限遐想。但要让 LLM 从一个被动的“文本生成器”转变为能够主动解决问题、与环境交互的智能体(Agent),我们需要赋予它思考、行动和学习的能力。ReAct (Reason + Act) 框架正是实现这一目标的主流范式之一。
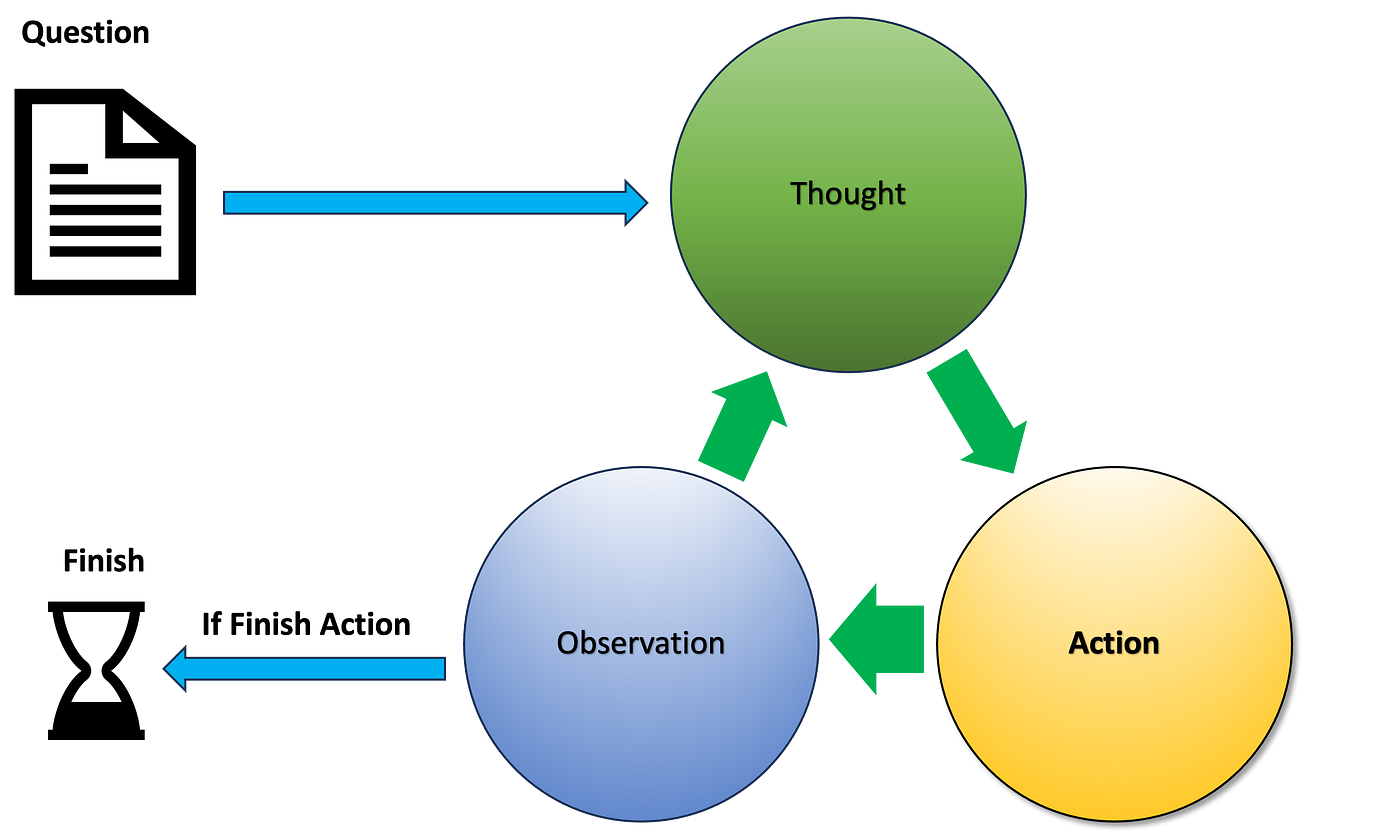
ReAct 的核心思想是模仿人类解决问题的方式:在观察环境后进行思考(Reasoning),基于思考决定下一步行动(Action),执行行动后观察结果(Observation),然后根据新的观察再次思考… 这个“思考-行动-观察”的循环使得 Agent 能够分解复杂任务、使用外部工具、处理异常情况,并逐步逼近最终目标。
与 Plan-and-Execute(先制定完整计划再执行)不同,ReAct 更强调每一步的即时思考和决策,使其对动态变化的环境具有更好的适应性。
本篇博客将深入探讨 ReAct 框架的原理,并使用 Python 从零开始(不依赖 LangChain 等高级框架,以便更好地理解底层逻辑)实现一个简单的、具备规划能力的 ReAct Agent。我们将涵盖其核心组件、Prompt 设计、代码实现以及运作流程。
1. ReAct 框架:“思考-行动”的循环
ReAct 框架由 Yao et al. (2022) 提出,其核心在于将 LLM 的推理能力 (Reasoning) 和行动能力 (Acting) 结合起来。Agent 的行为不再是一步到位的直接输出,而是通过一个迭代循环生成: