网络原理————HTTP
1,HTTP简介
我们上一期谈到了网络编程尤其是TCP和UDP,使用网络套接字来实现网络编程,上一期忘记说了,我们使用TCP的时候,我们用了线程池,这样就可以处理很多客户端而不会阻塞,那么如果客户端一直一直增加,那么线程不是就会一直增加吗,太多的线程不就反噬了吗,这是就会有IO多路复用,这个是啥意思呢,本质上就是让一个线程干多个活,比如当前线程正在服务一个客户端,但是这个客户端一直不请求,比如停在输入就不动了,那么线程就会先去别的客户端完成任务,等客户端发出请求了再回来;
好啦,现在正式来学习我们新的内容吧,HTTP:
HTTP是什么呢?
HTTP是超文本传输协议,是一种广泛的应用层协议,HTTP往往是基于TCP协议实现的,例如HTTP1.0,但是HTTP3是基于UDP实现的,但是我们还是广泛使用HTTP1.1, 应用层涉及的协议,其实有很多都是程序员自定的,那么如何自定协议呢?
第一步我们要明确传输的信息,第二步我们要约定组织信息的格式;
比如我们网购,就需要商家的id,商家的图片之类呀,而约定组织信息的格式就有很多了,比如:
1,行文本格式
可以直接写:1,商家241,商家点名....,商家商品.....可以直接这么写,这是很早之前的方案,在性能,安全性,和数据复杂性方面都是很弱的,我们直接淘汰它;
2,xml格式
还记得我们之前写JDBC的时候吗,我们在maven项目中导入过依赖,那个就是用的xml格式
这个就是xml格式,我们可以写
<Requset><UsedId>1000<UsedId>
<Request>响应的时候再把什么店名啥的放上去,但是这样的话我们会看到<UsedId> 这些玩意都重复的呀,我们服务器中最贵的就是带宽,我们用这个格式是很废带宽的,所以这个也不用;
3,json
这个是最常用的了,比如
{useid : 12,name : "zhangsan"
}这样也能表示我们要传递的信息,代码可读性更好了,并且比xml更节省带宽,但是还是存在冗余信息;
4,protobuf
基于二进制格式,对数据进行压缩,代码可读性很差,但是带宽消耗更小了;
我们当前所学的HTTP是javaWeb开发最核心的协议,一定要学好;
说这么多感觉在放屁嗷,你也没说HTTP到底是啥呀,我们在浏览器搜索网址时,我们输入一个URL,比如京东的网址,浏览器就把我们的HTTP请求发送给京东的服务器,服务器在接请求之后,返回一个HTTP响应,浏览器接收到HTTP请求之后就会解析,展示我们所看到的内容,HTTP呢就是应用层协议,TCP/IP是传输层协议,他们只在意传输的目标,而应用层协议在意的是我拿到这个请求,或者是响应之后我该怎么做........大家能懂不,简单来说,就是我们输入URL,就会有HTTP请求发送给服务器,服务器计算之后就会返回HTTP响应,浏览器就会解析HTTP响应;
另外HTTP是典型的一对一模式,请求就会有响应的响应,网络中还有其他模式,比如上传文件就是多问一答,下载文件就是一问多答;
2,HTTP协议格式
我们下面具体看看HTTP协议格式,我们要借助一个工具Fiddler,抓包工具,大家可以去官网下载, 这个小玩意;
这个小玩意;
下面来简单介绍一下这个小玩意的使用,我们下载好后打开Fiddler,
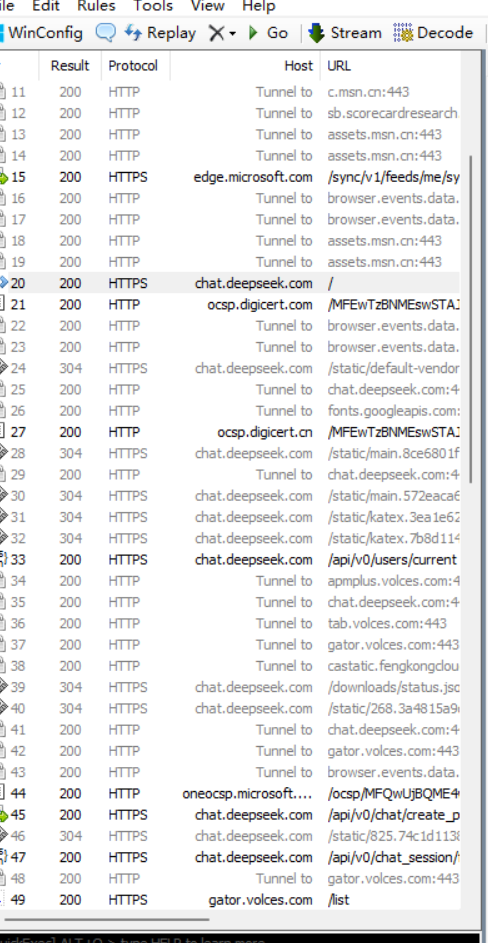
左侧是我们抓到的所有HTTP和HTTPS请求,我刚才打开了DeepSeek的网址,抓到了一个蓝色的HTTP请求,我们点击它,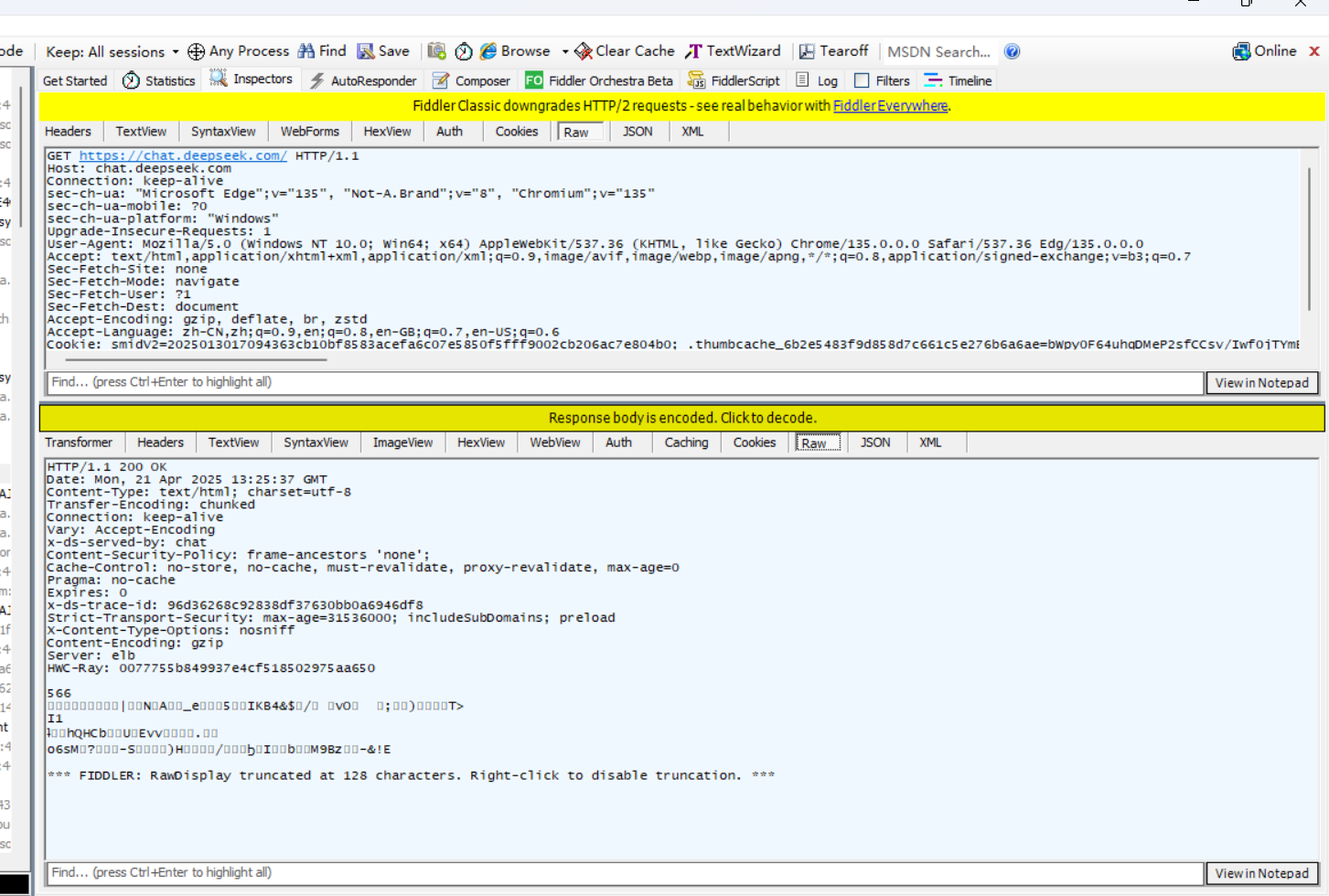
右上是请求报文,右下是响应报文,前提我们要点击那个Raw,这个就是我们的报文了,
我们可以点击这个就能在记事本中查看了,干嘛呢,太小了呀,所以在记事本中看,
左侧的报文可能有不同颜色的:
红色表示报错,
蓝色表示这个请求得到了个网页,
绿色表示是个js,
灰色表示这个响应的数据已经被缓存了;
Fiddler呢就是一个代理,它很清楚客户端和服务端的通信过程,就像点外卖,快递小哥很清楚用户买了什么和商家怎么做的,
下面我们来看请求和响应:
我们来抓一个搜狗的请求:
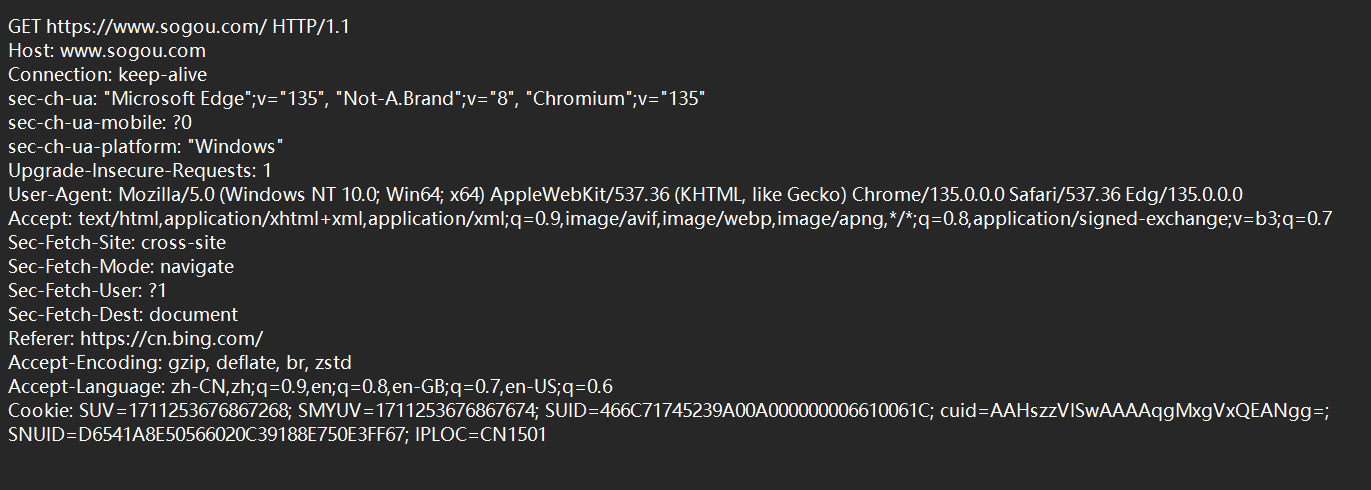
第一行我们叫首行,后面叫报头,之后是空行,可能有写请求会有正文,再来看响应
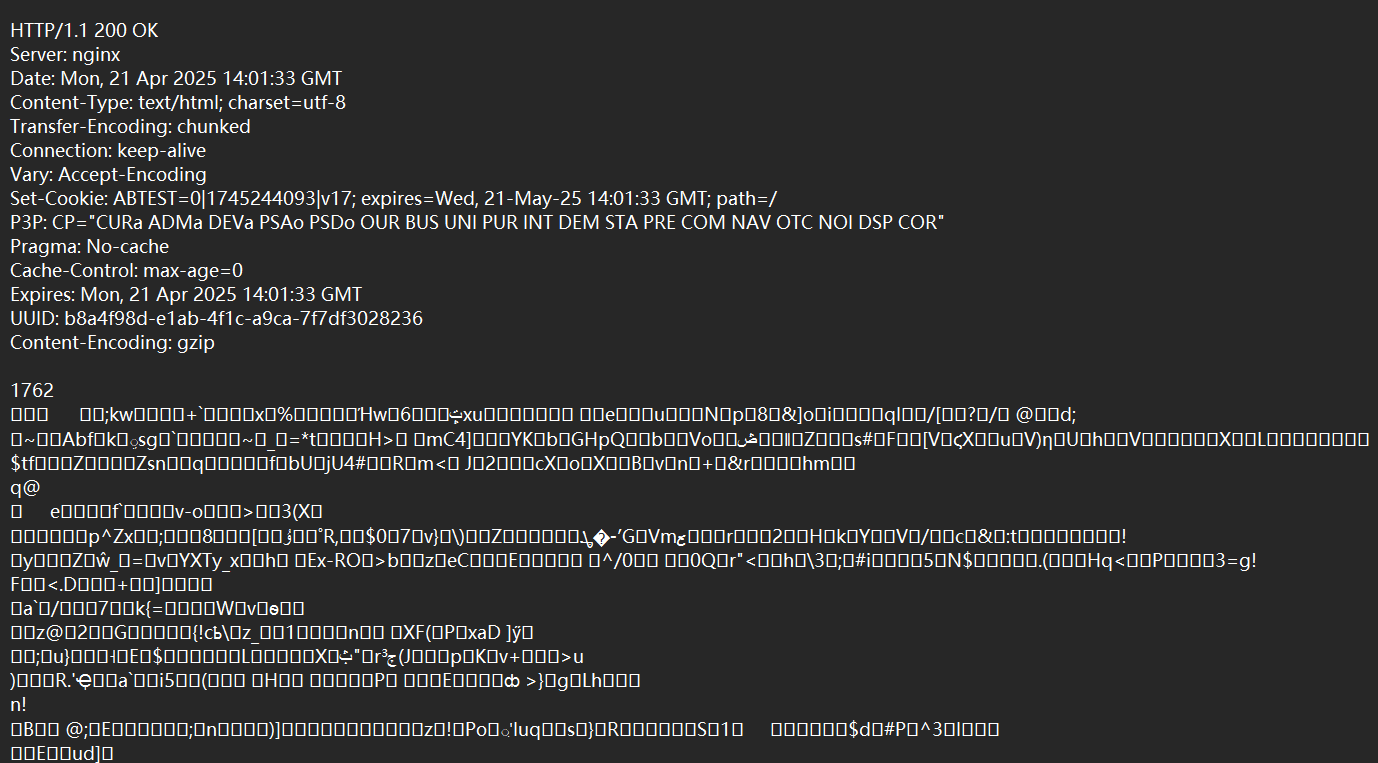
也是有首行,报头,空行,这会有正文了,不过看不懂嗷;
我们可以归纳一下请求和响应的协议格式:
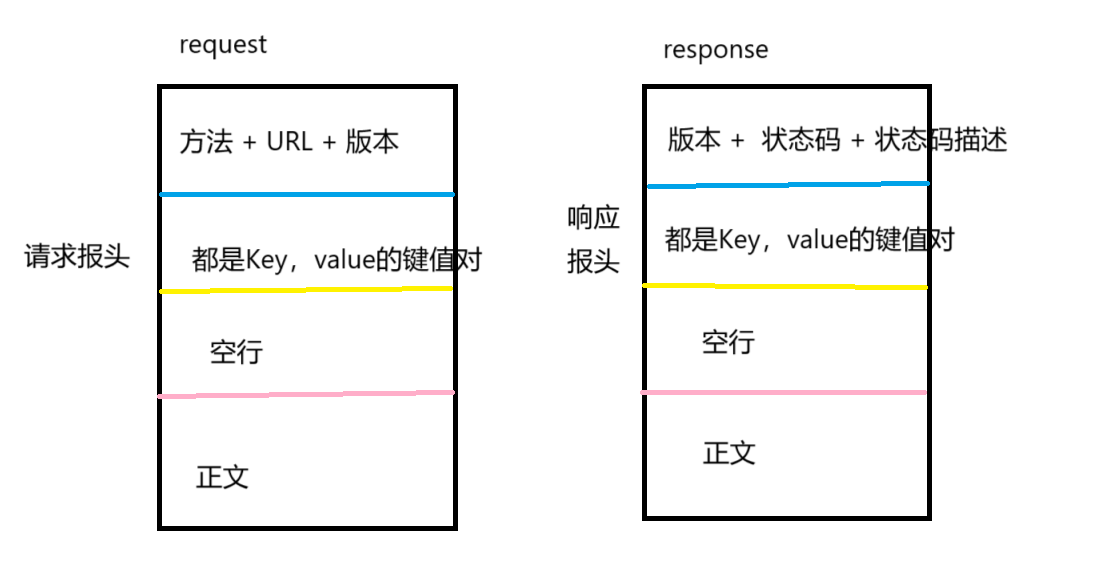
我们一会儿再详细讲这些方法啥的,
Header,报头,请求的属性,用冒号分割的键值对,用\n分割,直到遇到空行Header部分结束;
Body,正文,空行后面都是正文,body允许为空字符串,如果body存在那么在Header中就会有Content_Length存在来标识body的长度,如果响应中服务器返回了html,那么html就会在body中;那么为啥要有空行呢,这有啥用呀,HTTP中没有规定报头的长度,我们为了区分报头跟正文,我们就使用空行当分隔符了,因为TCP是面向字节流的,如果没这个空行就发生黏包问题了。
3,HTTP请求(Request)
下面我们来具体了解下请求;
1,认识URL
URL呢是文件在互联网上的唯一标识符;

看这个京东的URL,我们来一步步解析,第一个Https:是协议名,后面的www,jd.com是域名,DNS协议会把它解析成对应的IP地址和端口号,这里没有,在问号前面可能还会有层次路径,问号后面是查询字符串,是以键值对的形式写入的,中间使用&分阁;
我们来举一个例子,我们想吃麻辣烫,我们去呼和浩特新城区的4号路的好吃麻辣烫买麻辣烫,有微辣,菌汤,和番茄味的,我们现在以URL的方式完成我们的请求:
http://呼和浩特新城区:4号路好吃麻辣烫/菌汤/香菇的?葱=多放&香菜=少放&辣椒=不要
这就是URL了,我们使用它表示网络上的各种资源,就像居民的身份证一样;
下面来介绍另一个东西URL encode,这个是啥呢,//和?还有&我们已经使用了,那么我们就想要传输这个//和?呢,我们需要转义它,我们就会把这个字符的二级制格式拿出来,把它转换成16进制前面在加上百分号,不仅仅是特殊符号,有些字符和汉字也是需要转义的;
2,认识“方法”
我们用FIddler抓包的时候,首行通常会写一个get或者post之类的,这个就是方法,方法意思就是这次请求要干什么;
我们需要了解的有4个方法,get,post,put,delete;
1,get
get方法是最常用的http请求,我们获取Http,css,js,输入URL等都是都会发送一个get请求,get请求,我们直接来抓一个get请求看看,
GET https://www.sogou.com/ HTTP/1.1
Host: www.sogou.com
Connection: keep-alive
sec-ch-ua: "Microsoft Edge";v="135", "Not-A.Brand";v="8", "Chromium";v="135"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: cross-site
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://cn.bing.com/
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: SUV=1711253676867268; SMYUV=1711253676867674; SUID=466C71745239A00A000000006610061C; cuid=AAHszzVlSwAAAAqgMxgVxQEANgg=; SNUID=D6541A8E50566020C39188E750E3FF67; IPLOC=CN1501; ABTEST=0|1745244093|v17看下嗷,刚开始的方法名get,后面跟了URL和版本号, 我们看最下面,没有正文,get请求通常是没正文的,我们会通过查询字符串传参;
并且get请求的URL长度是没有限制的取决于浏览器和HTTP服务端的实现;
2,post
post一般会适用于登录界面,或者是上传文件,post的body一般不为空,并且存在content_type和content_length来指定Header,
另外两个方法其实用的很少,我们大可以用get和post实现很多很多的功能,put和delete的存在感很低,我们可能会根据语义来规范使用,比如put是上传,delete是删除,
我们现在来谈谈post和get的区别吧:
其实是没有本质上的区别的,可以混着使用;
1,语义上不同,get用于获取数据,post用来提交数据
2,携带数据的方式不同,get通常是在查询字符串上,也可以在body中,但是少见;post的数据通常是在body中,也有很少的在查询字符串上
3,get请求是幂等的,但是post请求不是幂等的,幂等性是啥意思呢,如果多次请求得到的结果是一样的,我们就视为幂等的,但是现在get也会被设计成不幂等的,比如猜你喜欢
4,get可以被缓存,而post不能被缓存
关于安全性呢,有人可能会说get的查询字符串不就放上面了吗,我都能看到,post一般没有,那么post就比get安全,这种说法是错误的,因为post一抓个包,也是能看到的,安不安全取决于对它的加密程度;
还有说post的传输量大于get的,这个也是不准确的,因为没有明确规定post中body的长度和get的URL长度,取决于浏览器和服务器的实现;
还有一种错误的说法是get只能传输文本数据,post可以传输二进制数据,这种的说法也是错误的,虽然get的查询字符串确实只能传输文本数据,但是可以把二进制数据转化为16进制数据放到上面;
3,认识请求“报头”
下面我们正式来学习报头部分,刚才说这部分是键值对结构,我们来具体讲下都有什么需要关注的:
1)Host
表示服务器的地址和端口,
GET https://www.sogou.com/ HTTP/1.1
Host: www.sogou.com
Connection: keep-alive
sec-ch-ua: "Microsoft Edge";v="135", "Not-A.Brand";v="8", "Chromium";v="135"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: cross-site
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://cn.bing.com/
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: SUV=1711253676867268; SMYUV=1711253676867674; SUID=466C71745239A00A000000006610061C; cuid=AAHszzVlSwAAAAqgMxgVxQEANgg=; SNUID=D6541A8E50566020C39188E750E3FF67; IPLOC=CN1501; ABTEST=0|1745244093|v17还是看这个,那个Host后面跟的就是服务器的地址和端口,有同学可能要问了,这个跟首行的URL不是一样吗,是一样的,但是如果我们使用代理的话就不一样了,使用代理,URL可能就会发生变化,但是Host里面的是不会变的,存储的是最原始的路径,我们后面使用HTTPS加密的时候也不会去处理URL,而是针对Header和正文部分加密;
2)Content-Length
X-Ceto-ref: 6808e87e5e0746e2ad939775c5bb5a92|AFD:6808e87e5e0746e2ad939775c5bb5a92|2025-04-23T13:17:50.871Z
Content-Encoding: gzip
Expires: Wed, 23 Apr 2025 13:17:50 GMT
Cache-Control: max-age=0, no-cache, no-store
Pragma: no-cache
Date: Wed, 23 Apr 2025 13:17:50 GMT
Content-Length: 18962
Connection: keep-alive
Set-Cookie: _C_ETH=1; domain=.msn.cn; path=/; secure; httponly
Set-Cookie: _C_Auth=
Set-Cookie: USRLOC=; expires=Fri, 23 Apr 2027 13:17:50 GMT; domain=.msn.cn; path=/; secure; samesite=none; httponly
Alt-Svc: h3=":443"; ma=93600
Akamai-Request-BC: [a=60.221.202.1这个是我随便截取的一个响应,我们可以看到有个content-Length :18962,这个表示呢body中的数据长度,单位是字节,有这一行键值对前提是要有body嗷,这玩意有啥用呢,我们开篇说过,我们现在常用的HTTP,版本小于2.0的,在传输层那是基于TCP实现的,HTTP协议呢,就是规定了TCP传输字符串的格式,比如首行之后是body呀,我们如果没有body的话读到空行就结束了,但是如果有body呢,那么长一坨坨,TCP是面向字节流的,TCP自己分不清哪到哪是一个有效的数据,所以就需要先读取Header中的content-Length,来明确自己在body中一次需要读取多少长度的字节;但是2.0版本之后HTTP使用UDP是不需要的,因为我们知道UDP是面向数据报;
3)Content-Type
表示请求数据的格式,显示了接收方需要如何解析body中的数据;
我们来看看都能解析什么数据:
1> HTML text/html 浏览器会解析标签,把标签转换成页面
2> CSS text/css 浏览器会解析选择器啥的,之后那这些样式应用到页面
3> JS application/javascript
4> JSON application/json
5> 图片 image/png ; image/jpg
博主知识有限..............反正呢,HTTP请求能包含很多格式,body可以传很多东西。
请求和响应呢,只要有body的话就一定有这两个属性,Content-Length和Content-Type,没有的话这个报文绝对是错误的;
4)User-Agent
User-Agent里面表示了了用户使用的设备,浏览器,还有操作系统的情况;
这个有啥用呢,以前呢,大家的浏览器版本是不一样的,存储空间都是很宝贵的,可能浏览器可以升级了,并且支持更多的功能了,一个网站就想升级下它的功能,但是呢,有很多用户是不喜欢升级的,我相信很多人都这样,不想踩坑嘛,那么怎么办,我们难道要放弃旧的用户吗,那肯定是不可能的,我们有了User-Agent就能知道当前用户的浏览器版,返回对应版本的网站响应,这也意味着程序员要更累了,维护两个版本的代码;还有一个用途是知道用户使用的设备,如果是手机返回手机的对应界面,如果是电脑端就返回电脑端的界面,虽然前端里好像有响应式什么什么来应对这个情况,但我们返回不同的版本也是个解决办法;
5) Referer
这个描述了当前页面是从哪个页面跳转过来的,我们来点个广告抓一下包,
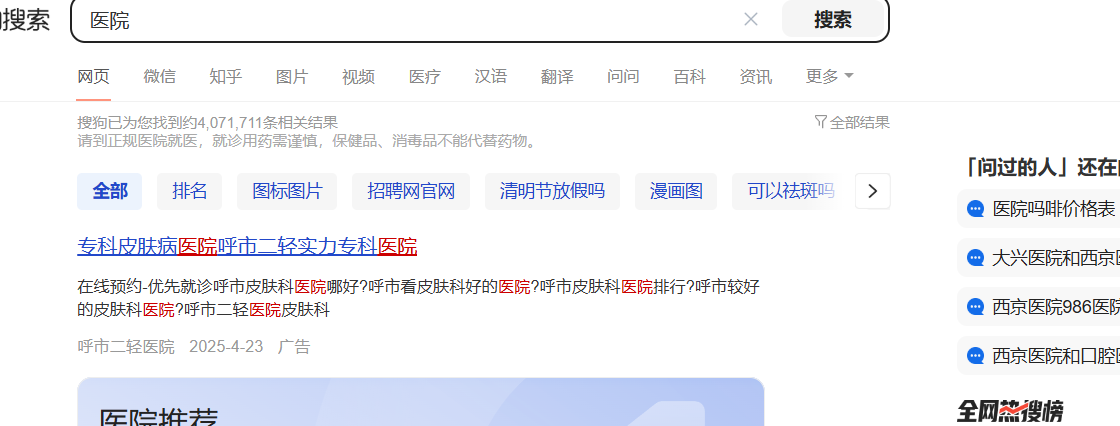
 抓包,可以看到嗷,这Referer是从搜狗来的,这里跟大家讲一个事,早期呢,大家都是使用HTTP的,各大广告平台会有一个按跳转次数计费,广告主和广告平台会去对跳转次数,但是广告主呢,总是少,最后有大佬发现了一个问题,就是运营商可以改他们的Referer,把Rerfer改成自己,那么这个广告钱不就归我了吗,这就是臭名昭著的运营商劫持,明晃晃的抢你的钱,后来大家使用了HTTPS才从技术上抵制了这样的影响;
抓包,可以看到嗷,这Referer是从搜狗来的,这里跟大家讲一个事,早期呢,大家都是使用HTTP的,各大广告平台会有一个按跳转次数计费,广告主和广告平台会去对跳转次数,但是广告主呢,总是少,最后有大佬发现了一个问题,就是运营商可以改他们的Referer,把Rerfer改成自己,那么这个广告钱不就归我了吗,这就是臭名昭著的运营商劫持,明晃晃的抢你的钱,后来大家使用了HTTPS才从技术上抵制了这样的影响;
6)cookie
这个是重点,大家好好理解一下:
我们这里讲一下cookie和session:
cookie是存储在客户端中,
session是存储在服务端的,
我们现在是客户端,我们要访问服务器,我们首先要登录,我们输入密码,如果密码正确了呢,就会生成一个sessionId,通过set-cookie把sessionId给客户端,同时服务端会生成一个session对象,把用户的关键信息都会保存到session对象中,服务端构建sessionId和Session对象作为键值对保存在服务端,而客户端被setCookie后内存中就有了sessionId,我们就可以拿着这个sessionId在服务器进行操作,并返回你需要的信息,但是一般setCookie是包含过期时间的,这就是为啥我们登录之后会有一段时间是不用登录的,但是时间太久了还是需要登录;
我们可以来举一个例子,我们去医院看病,医生会给我们发一个诊疗卡,因为医生很忙,是不会一个一个去记病人的,医生让你去抽血,做心电,都会让你刷诊疗卡并且更新你的信息,你做完一系列流程之后回到医生那,它又会去拿诊疗卡来看病,诊疗卡就相当于一个sessionId,我们去看病医生就会生成一个就诊卡,并且在电脑上有我们对应的信息,医生setCookie发给我们就诊卡,我们拿着就诊卡去看病;懂了没~
4,认识请求“正文”
接下来就是正文部分的内容了
这个是跟Header部分的Content-Type强相关的:
1)application/x-www-form-urlencoded
表单数据编码格式,数据编码为键值对,适用于简单文本数据的提交,不支持二级制数据,并且要符合URL编码;
2)multipart/form-data
混合数据类型(文本+二进制),支持文件上传,适用于登录场景,每个部分以 --boundary 开头,以 --boundary-- 结尾
3)application/json
以json形式传输结构化数据,支持复杂数据类型,