个人mysql学习笔记
1.概念
1-1. sql语言
数据定义语言(DDL): DROP, CREATE, ALERT语句
数据操作语言(DML): INSERT, UPDATE, DELETE语句
数据查询语言(DQL): SELECT语句
数据控制语言(DCL): GRANT, REVOKE, COMMIT, ROLLBACK语句
1-2. mysql
mysql是小型关系数据库管理系统。开源免费,学习成本低。
2.安装
2-1. 地址
mysql官网: https://www.mysql.com/downloads/
国内快速下载点: https://www.filehorse.com/download-mysql/download/

这个是windows系统的方案,ios和linux的这里我就不不写了,因为我没有苹果本!!!
这里直接用快速下载地址了,两个东西是一样的,效果如下:
2-2 安装配置
打开安装包
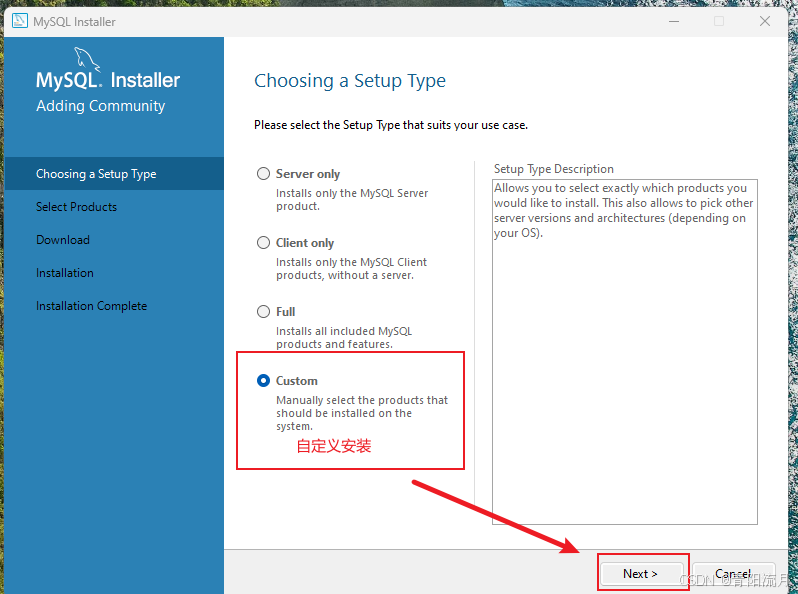
选择自定义安装
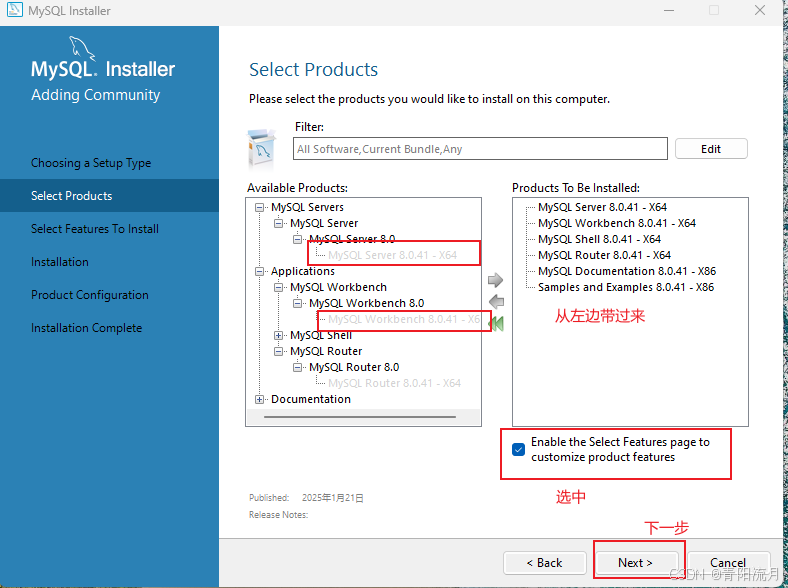
选择安装项,勾选中Enable the Select … 就会检查环境
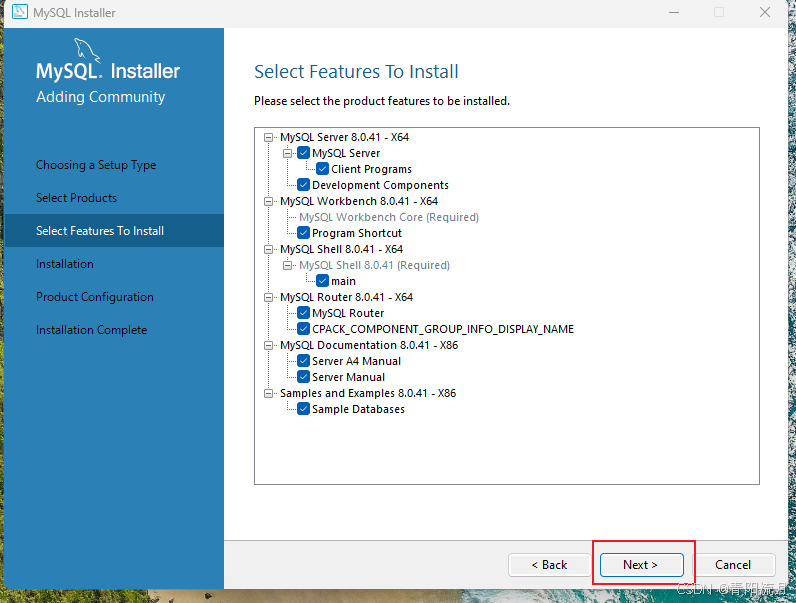
待安装项预览
开始下载
下载中
下载完毕
下一步
端口等配置,一般不用修改,直接下一步
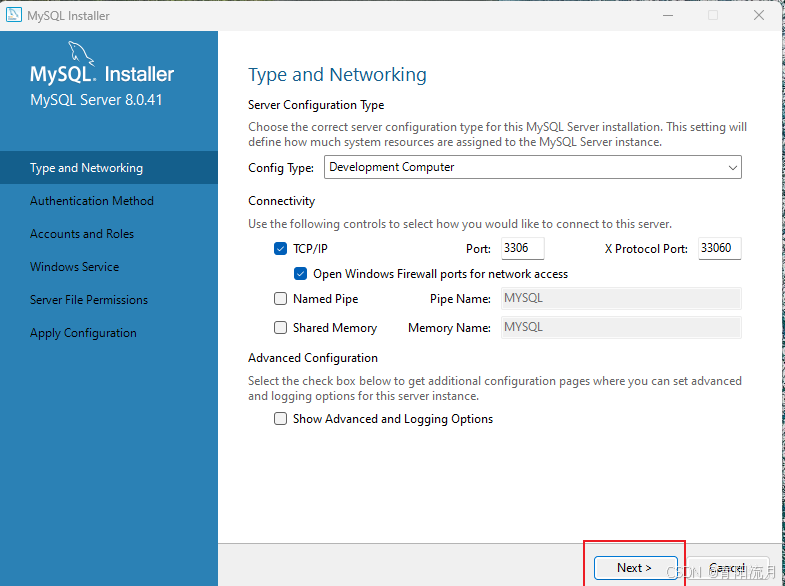
账户设置,记得选下面那个,安全系数高
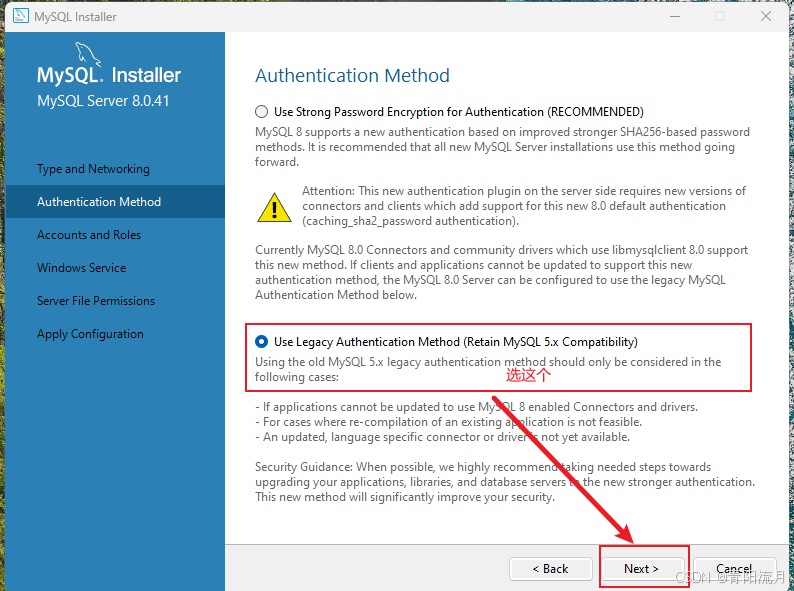
设置密码
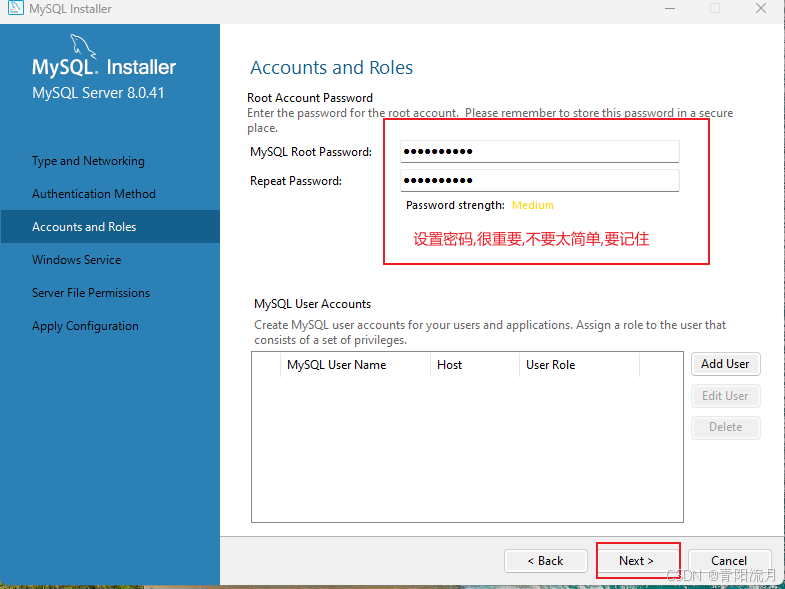
继续下一步
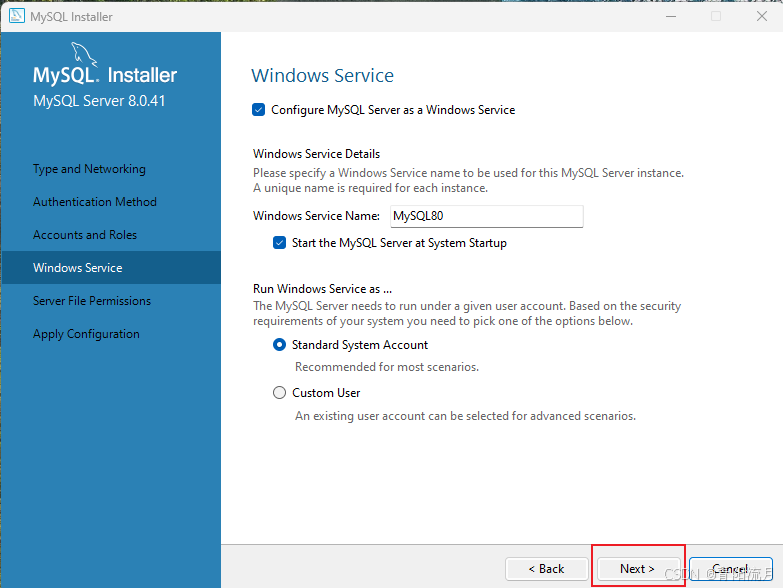
下一步
确认各项
确认完毕
下一步
下一步
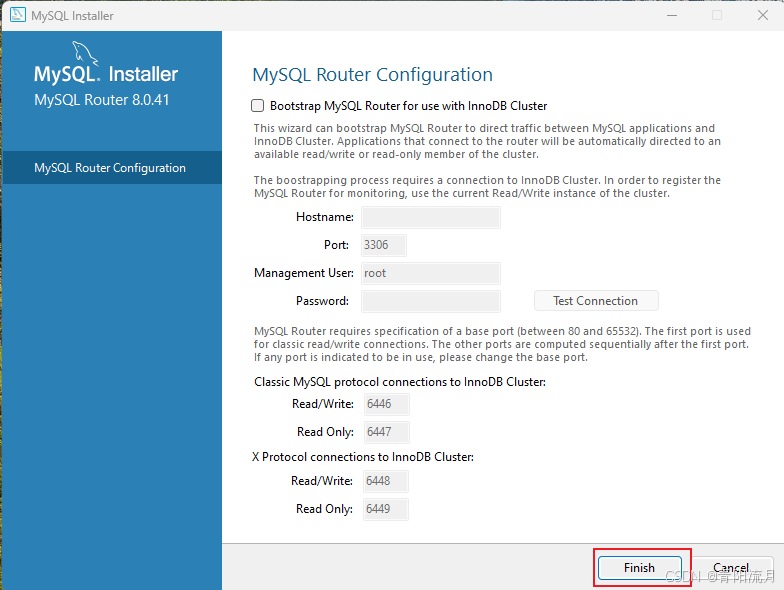
下一步
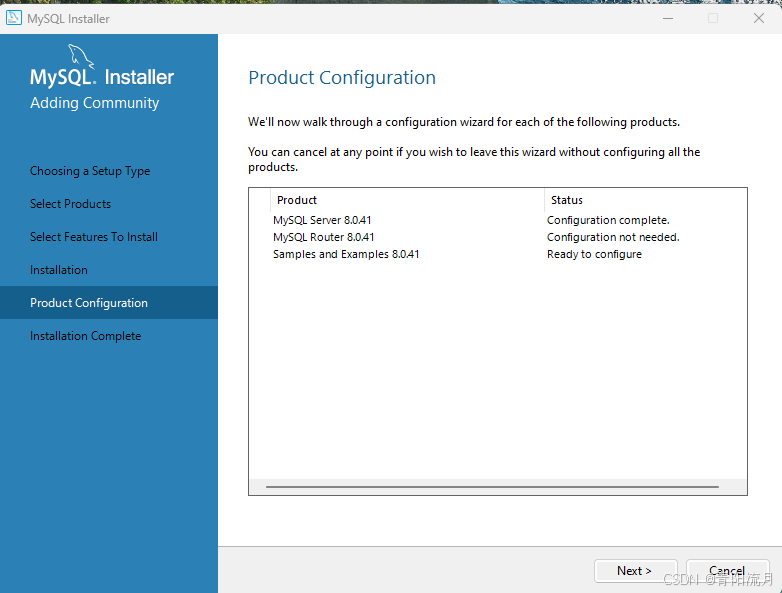
校验密码
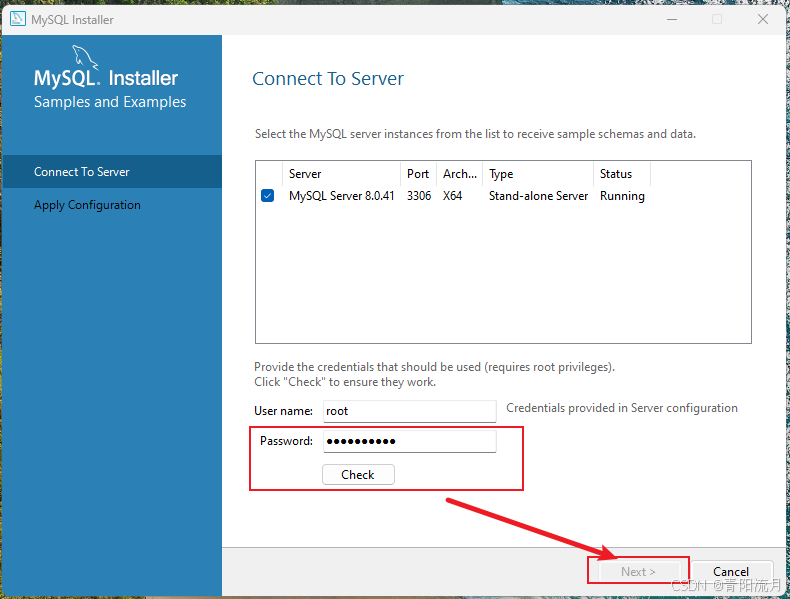
下一步
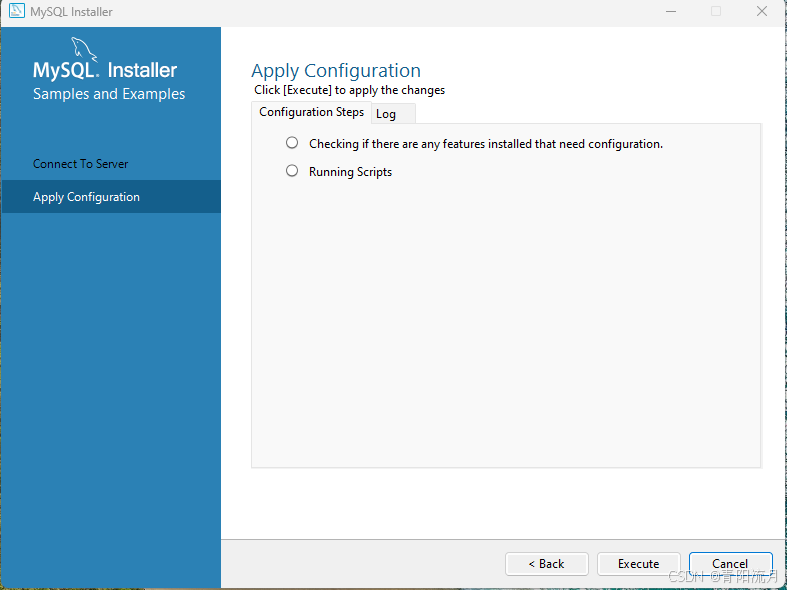
下一步
下一步
下一步
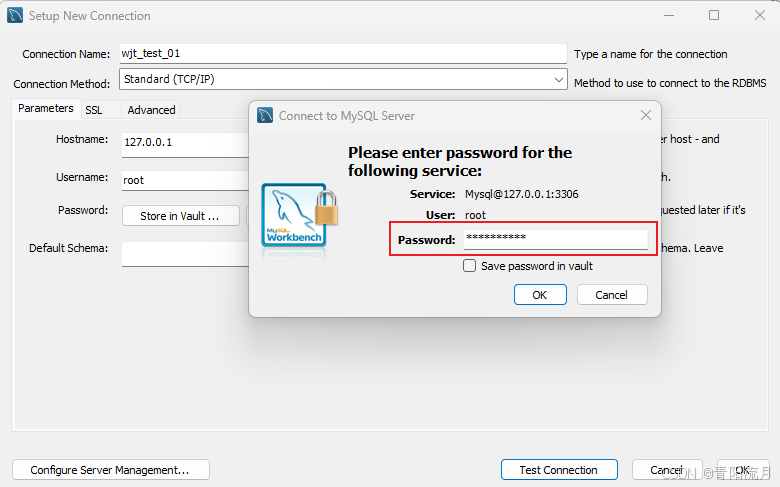
创建一个连接
输入密码
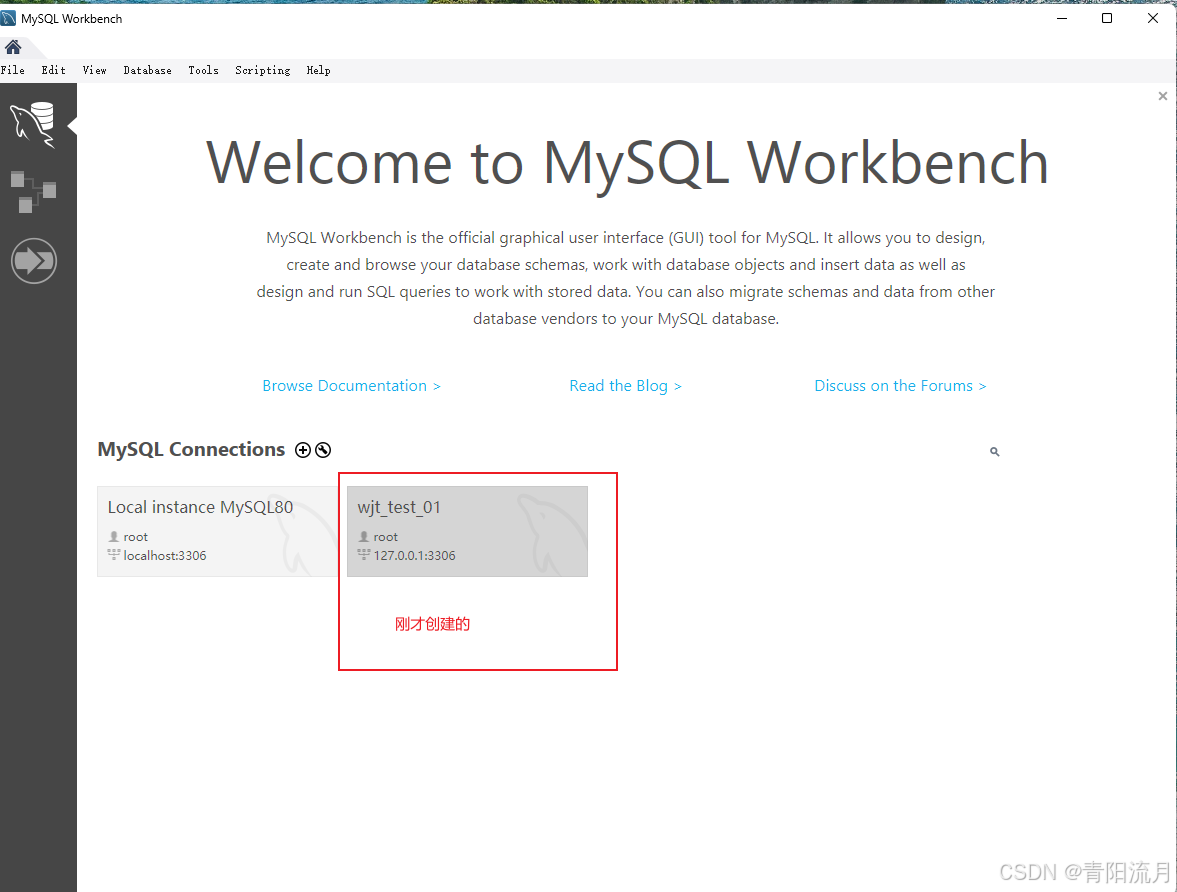
测试
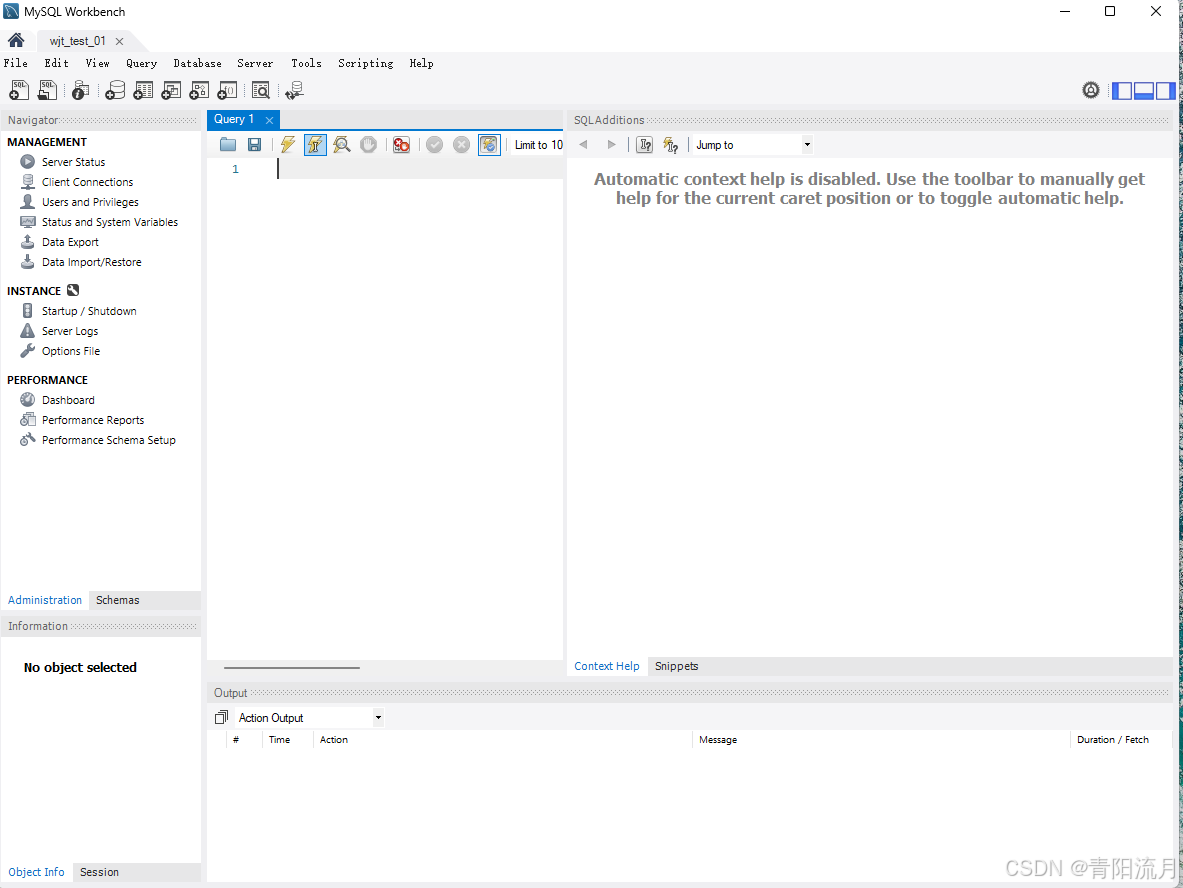
可视化界面
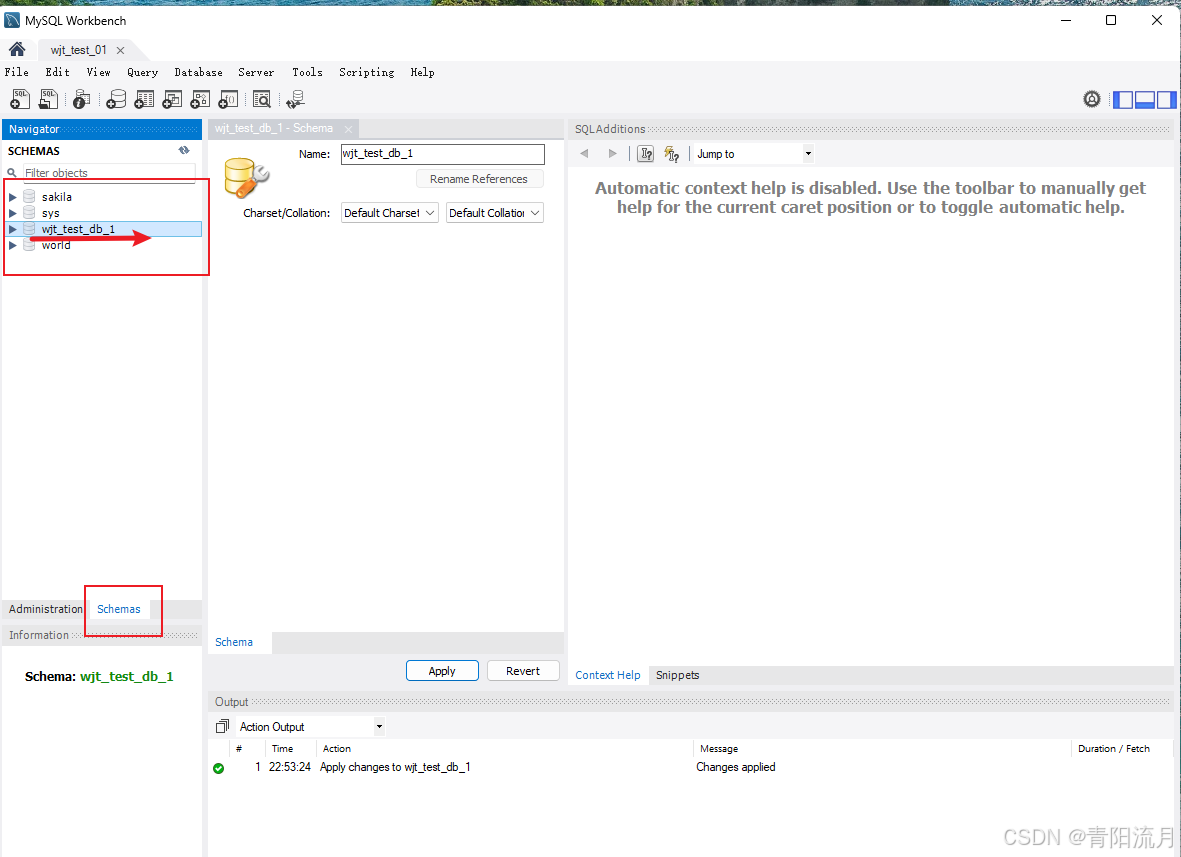
创建一个库

效果
这样就成功了
2-3 可视化工具
1.workbench: 官方提供,下载自带的
2.navicat免费版地址: https://www.navicat.com.cn/download/navicat-premium-lite
3.vscode集成: Database
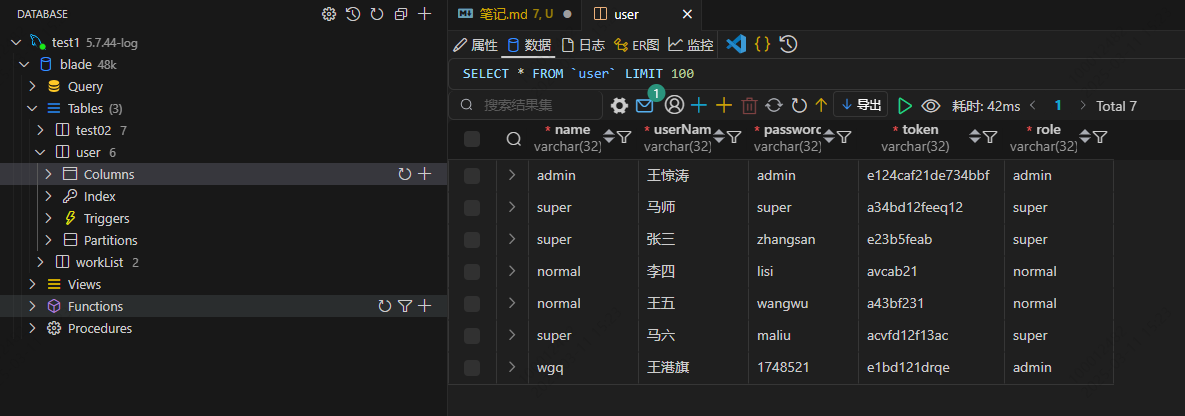
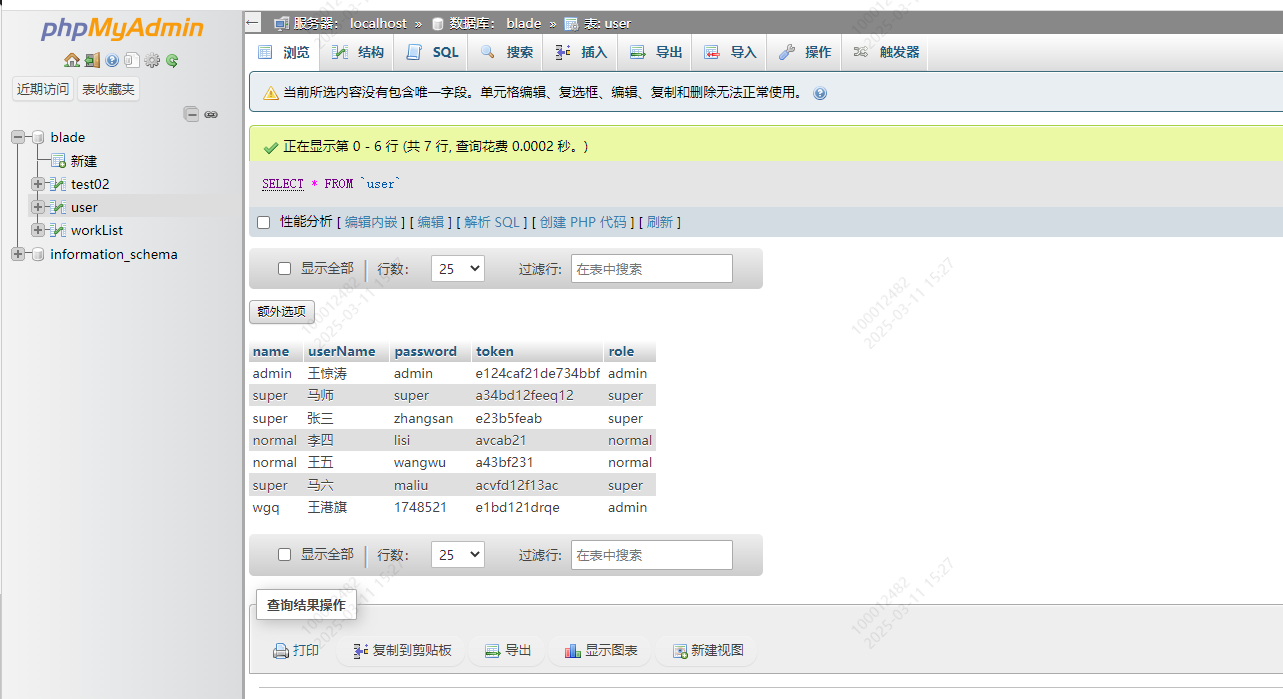
4.腾讯云服务器中的mysql,我就用这个可视化面板进行操作了
3.数据库的操作
3-1. 创建一个数据库地址
在mysql中,创建一个专门用来学习的数据库链接, 这个数据库的名是: wjt_test_db 密码设定为: 0123456
下面是我用腾讯云服务器的mysql,不是本地的。本地的创建就是安装教程中最后测试的那种方式。
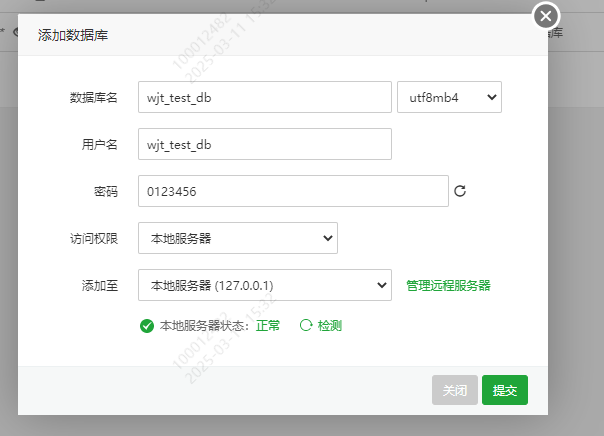
如果希望其他人能连接到,需要在访问权限那里进行操作,指定所有人,或者指定ip
这个数据库就是用来学习和熟练操作mysql的
3-2 .连接数据库
每个可视化工具都差不多,这里我使用vscode进行链接
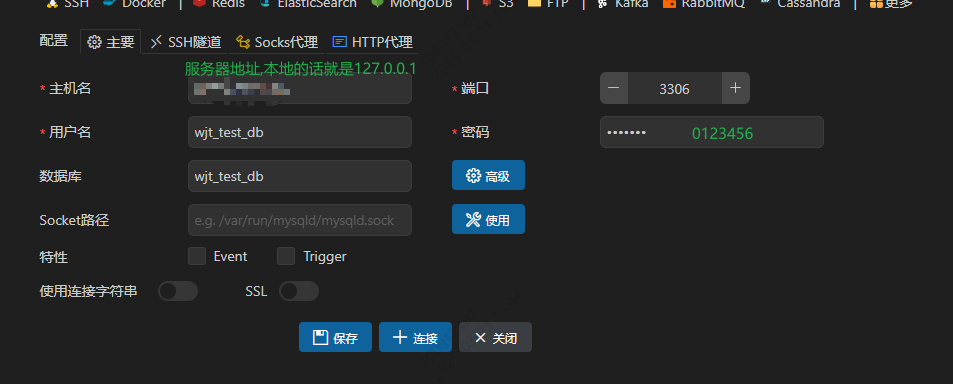
连接成功,效果如下:
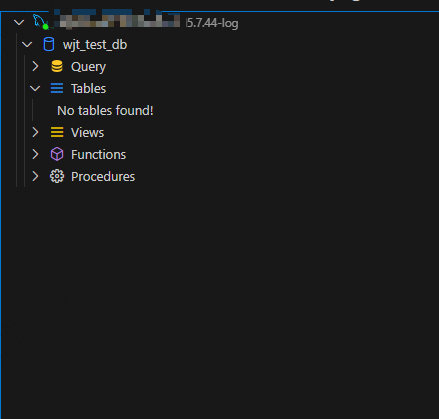
3-3. 数据库操作语句
添加数据库
CREATE DATABASE db_name
查看数据库情况
show db_name
删除数据库
DROP DATABASE db_name
4. 数据类型
类型有很多,因为我是js开发出身的,数据库的类型和js的类型还是有不少区别的。这里我也不说那些特殊的,只说常规常用的。
如果数字特别大,文本特别大,文件特别大,数据库里有提供其他类型的,下面的一般情况够用了
| 类型 | 字节数 | 描述和使用场景 | 举例 |
|---|---|---|---|
| INT | 4 | 整数数字类型,一般的数字类型,就用INT | 100 |
| FLOAT | 4 | 浮点数字类型,一般的小数类型,就用FLOAT | 10.11 |
| VARCHAR | 3 | 字符串类型,一般的字符串类型,就用VARCHAR | 你好,我叫王惊涛 |
| TEXT | 0~65535 | 文本类型,一般较大的文本用这个存,比如文章,详情描述等 | xxx…很多字 |
| YEAR | 1 | 时间里面的年, 格式是YYYY | 2024 |
| DATE | 4 | 年月日格式,格式是 YYYY-MM-DD | 2024-02-13 |
| TIME | 3 | 时分秒格式, 格式是 HH:MM:SS | 10:01:11 |
| DATETIME | 8 | 完整时间,格式是YYY-MM-DD HH:MM:SS | 2050-10-1 10:30:05 |
| BLOB | 0~65535 | 二进制类型,如文件,图片等 | 一张图片 |
5. 数据表的基本操作
5-1. 创建数据表
给数据库中新建一张表,每一条数据都有三个属性: id(整数类型), name(字符串类型), age (整数类型)
CREATE TABLE user_list( id INT, name VARCHAR(20), age INT );
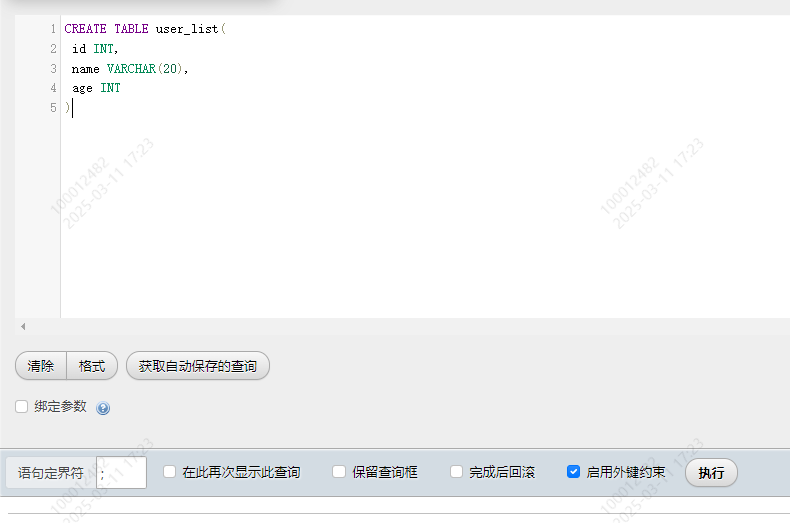
执行结果
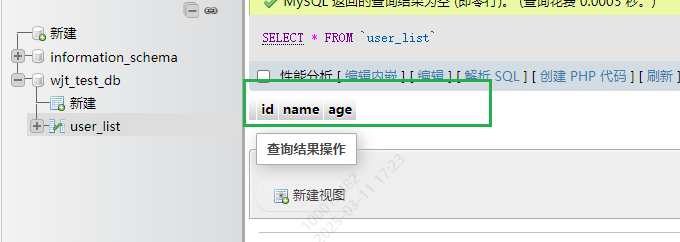
5-2. 查看数据表
1.查看当前数据库中所有的表
SHOW TABLES
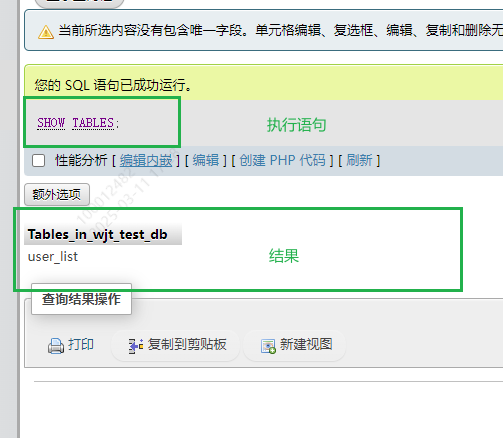
2.查看表的基本信息
SHOW CREATE TABLE tablename
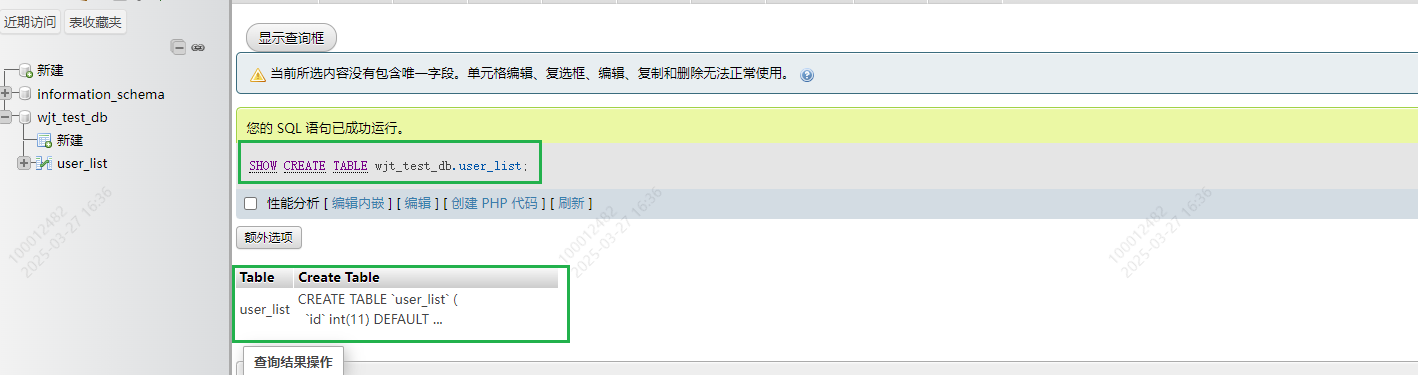
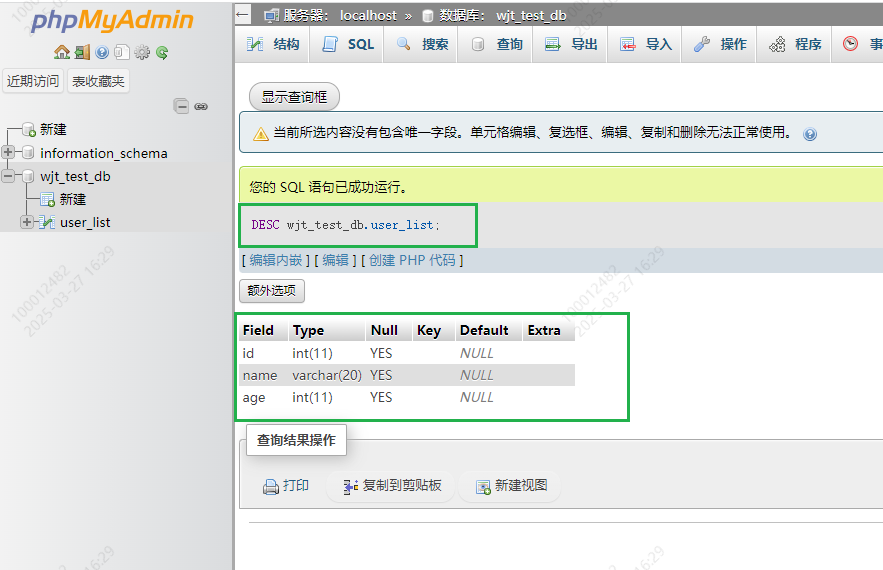
3.查看表的字段信息
desc 库名.表名 , 可以查找到这个表的字段信息
DESC DB.TABLE
5-3. 修改数据表
1.修改表名
ALTER TABLE oldname RENAME TO newname
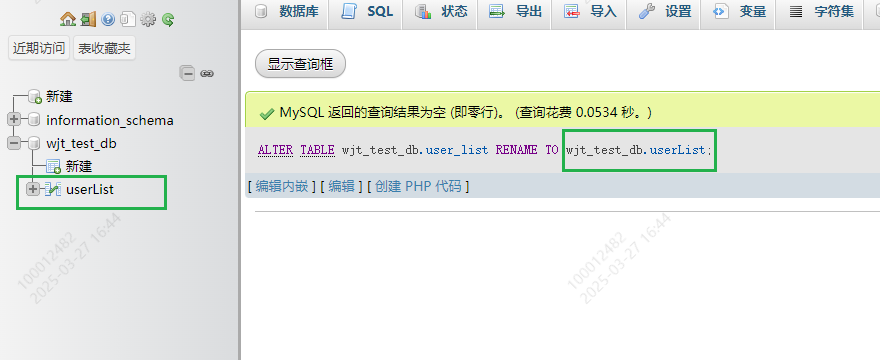
2.修改字段名
ALTER TABLE tablename CHANGE oldname newname varchar(10);
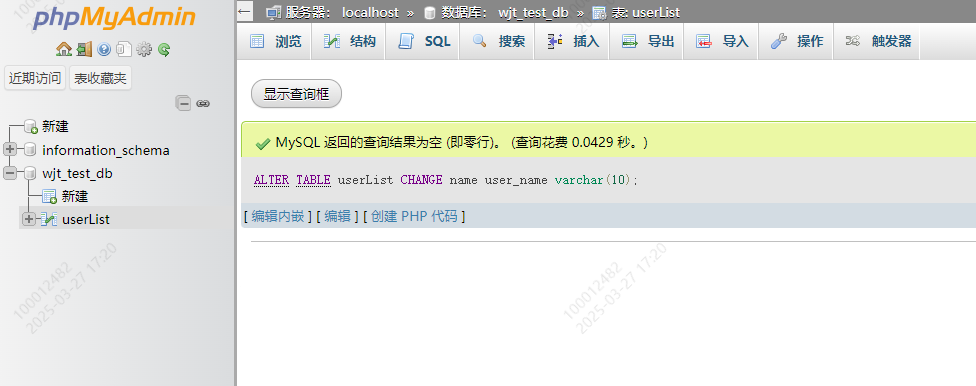
表的变化
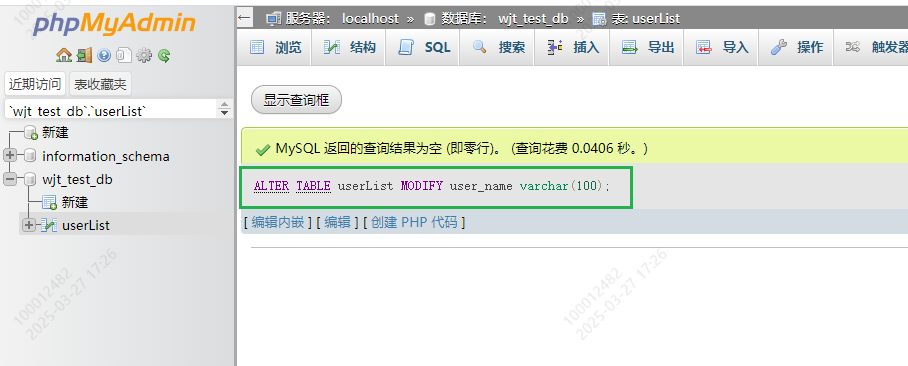
3.修改字段类型
ALTER TABLE tablename MODIFY user_name varchar(100);
4.新增字段
ALTER TABLE tablename ADD keyname varchar(30);
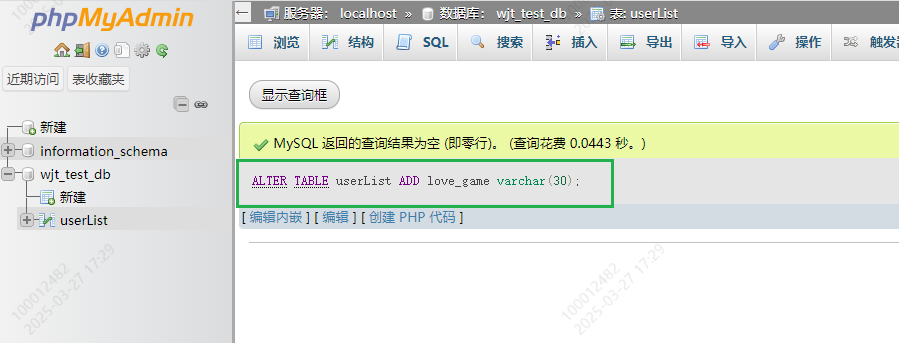
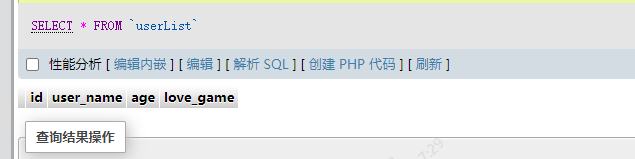
表格中多了一个love_name的字段
5.删除字段
ALTER TABLE tablename DROP keyname;
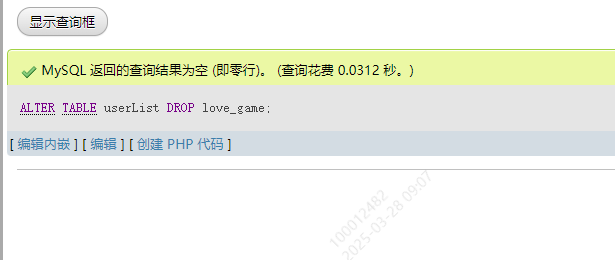
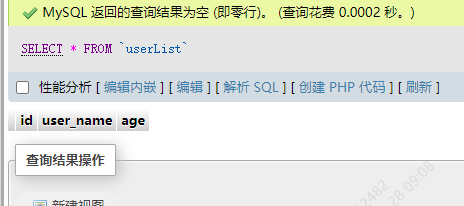
表格中的love_game字段就没了
5-4. 删除数据表
DROP TABLE tablename;
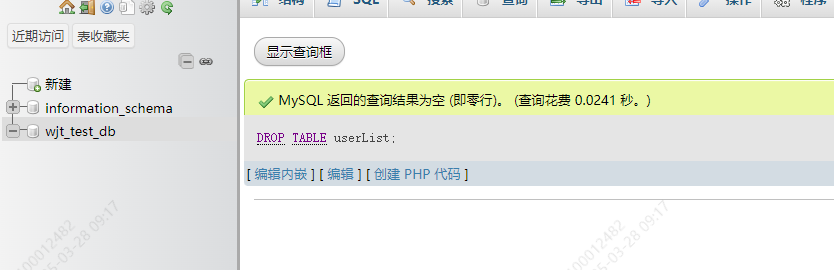
表格被删除了,这个操作还是慎用的,毕竟删表是一个有风险的行为。数据永远是最重要的!
6.数据表的约束
6-1. 主键约束
PRIMARY KEY
特点: 值必须是唯一的,不能为空,不能重复。一张表只能设置一个主键
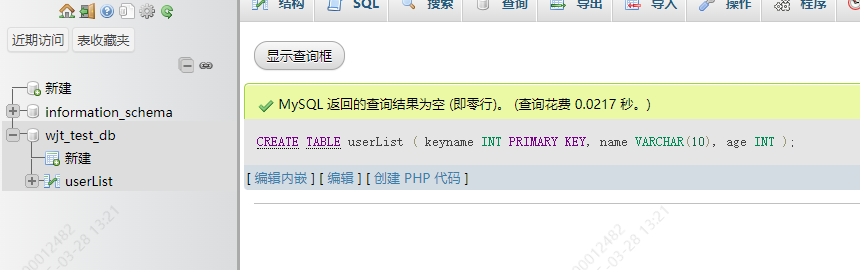
创建表的时候就设置约束:
CREATE TABLE tablename (keyname INT PRIMARY KEY,name VARCHAR(10),age INT)
如果已经存在一张表了,想对其中某个字段进行约束:
ALTER TABLE userList
ADD PRIMARY KEY (id);
设置联合主键:虽然一张表只能有一个主键,但是可以设置联合主键,也就是多个字段共同组合成一个主键
CREATE TABLE userList (first_name VARCHAR(20),last_name VARCHAR(20),age INT,PRIMARY KEY (first_name, last_name)
);
6-2. 非空约束
特点:值不能为空的约束
新建表时候设置
CREATE TABLE userList(
name VARCHAR(20) NOT NULL
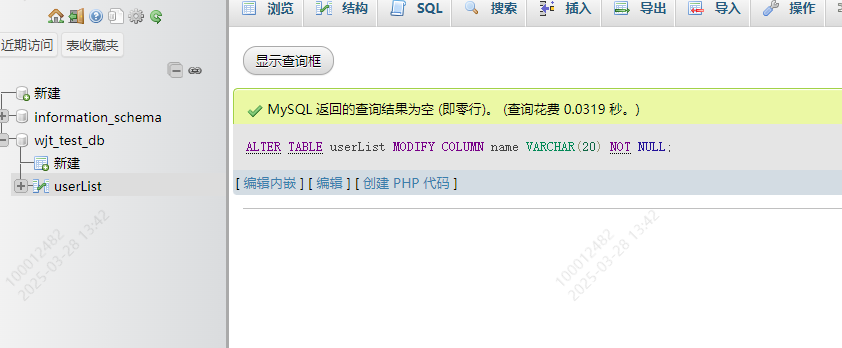
);已有的字段值
ALTER TABLE userList MODIFY COLUMN name VARCHAR(20) NOT NULL
6-3. 默认值约束
特点:给这个字段设置一个默认的值
*nationality : 国籍
创建表时就设置
CREATE TABLE userList (nationality VARCHAR(30) DEFAULT 'CHINA'
)
修改已有的值
ALTER TABLE userList ALTER COLUMN nationality SET DEFAULT 'CHINA';
当本身不存在该值,需要添加并且设置默认值
ALTER TABLE userList ADD COLUMN nationality VARCHAR(30) DEFAULT 'CHINA';


6-4. 唯一性约束
**特点:**该字段的值是唯一的,不能重复
创建表时:
CREATE TABLE userList (name VARCHAR(30) UNIQUE
)
修改已有的值:
ALTER TABLE userList ADD COLUMN name VARCHAR(30) UNIQUE
6-5. 外键约束
特点: 比如有两张表之间维护的数据具有关联性。设置一个外键代表两者之间的关联,外键是一个字段,这个字段不是所在表的主键,但是和另一张表的主键所对应,外键可以是一列或者多列。主表是主键所在的表,从表是外键所在的表。
假如现在有两个表:
表1userList是主表,表二homeList是从表
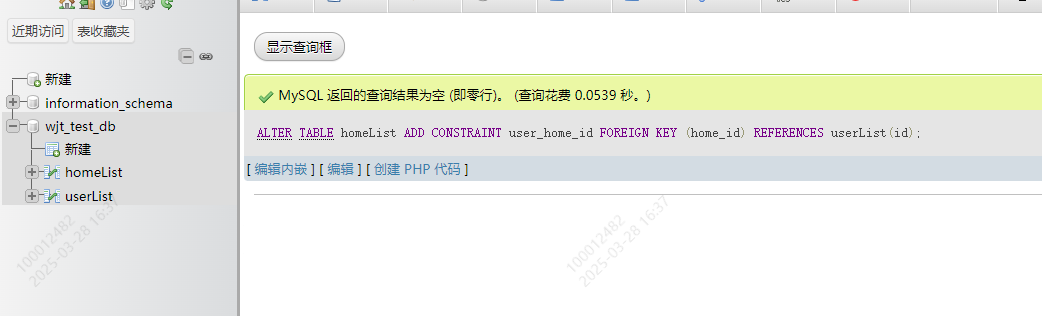
模板
ALTER TABLE 从表名 ADD CONSTRAINT 外键名 FOREIGN KEY (从表外键) REFERENCES userList(主表主键)ALTER TABLE homeList ADD CONSTRAINT user_home_id FOREIGN KEY (home_id) REFERENCES userList(id)
当主表中的数据被删除或者修改从表中的那条数据时,从表中所对应的数据也应该被删除。
删除外键
ALTER TABLE homeList DROP FOREIGN KEY user_home_id
外键约束规则:
- 从表中的外键一般都是主表的主键
- 从表里外键的数据类型必须与主表中主键的数据类型一致
- 主表发生变化时应注意主表与从表的数据一致性问题
7.数据表插入数据
7.1插入一条比较完整的信息
INSERT INTO userList(字段名x,字段名y) VALUES(字段值x,字段值y)
userList列表结构如下
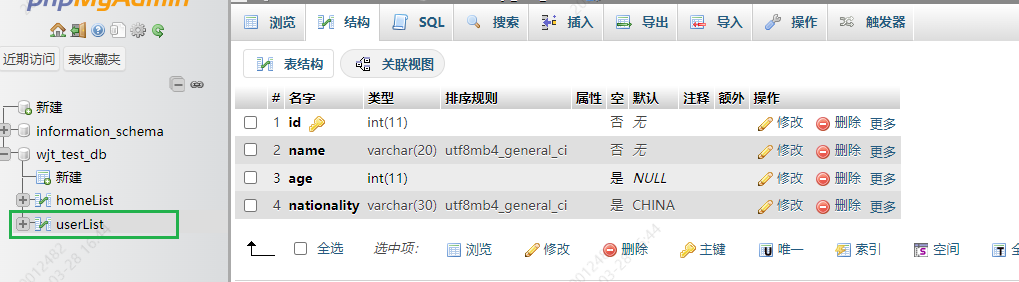
7.2 添加一条数据
INSERT INTO userList(id,name,age) VALUES(1,'王惊涛',29)

结果如下
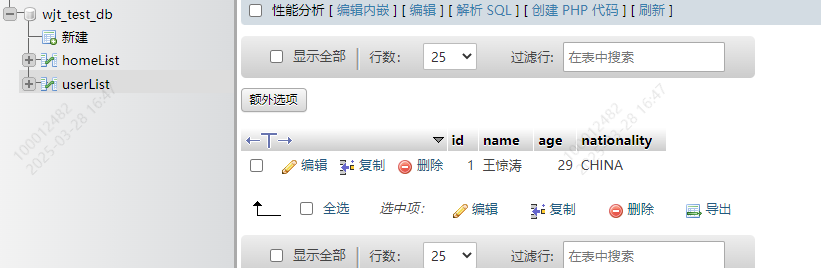
7.3 添加多条数据
只需要在后面继续加 ,(xxx)
INSERT INTO userList(id,name,age) VALUES(2,'王港奇',27),(3,'李景林',29)
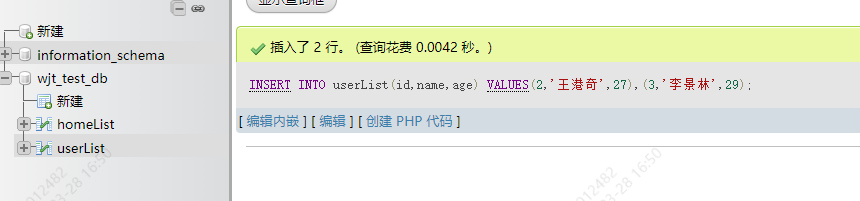
8.更新数据
8.1 更新某条数据
格式
UPDATE 表名 SET 字段x=值,字段y=值 WHERE 字段z=字段z
UPDATE userList SET age=30 WHERE id = 1
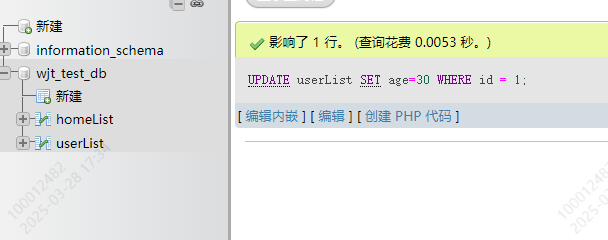
效果
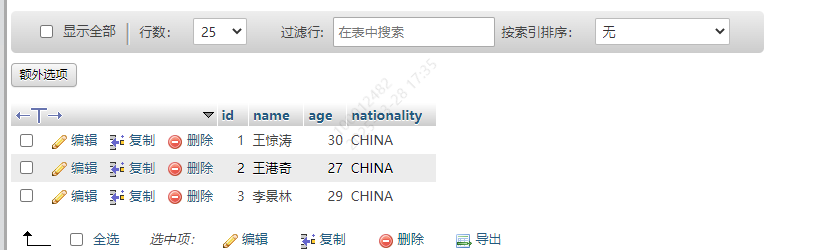
8.2 更新所有数据
UPDATE userList SET age=30
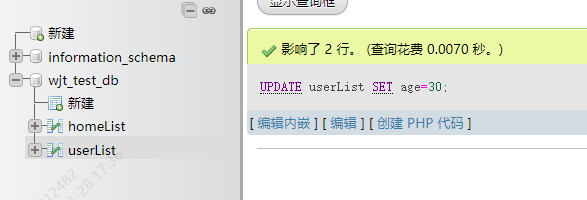
效果
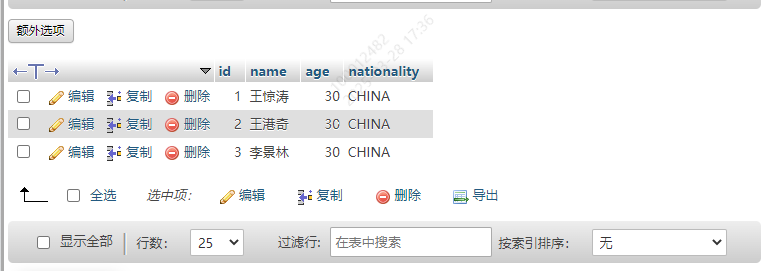
9.删除数据
9.1 根据指定条件删除
DELETE FROM 表名 WHERE 属性=值
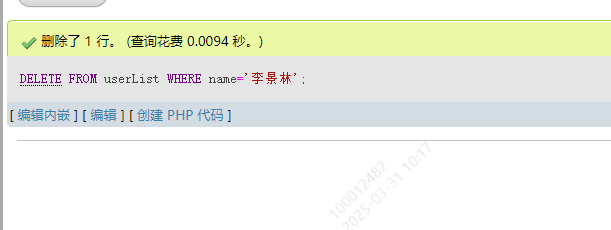
结果

9.2 删除全部数据
DELETE FROM 表名
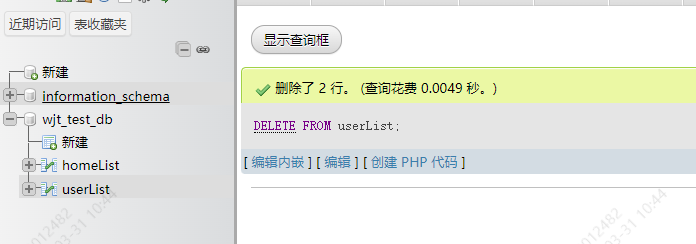
结果
10.简单查询
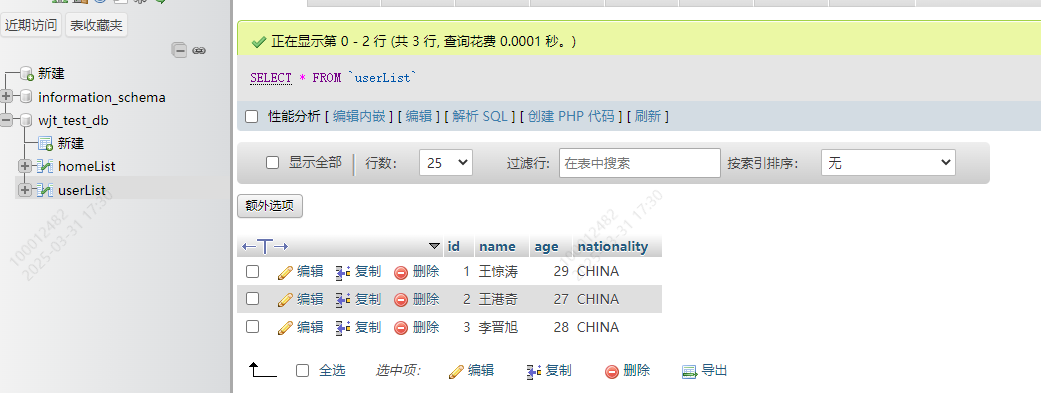
10.1 查询一张表的全部内容
SELECT * FROM tablename
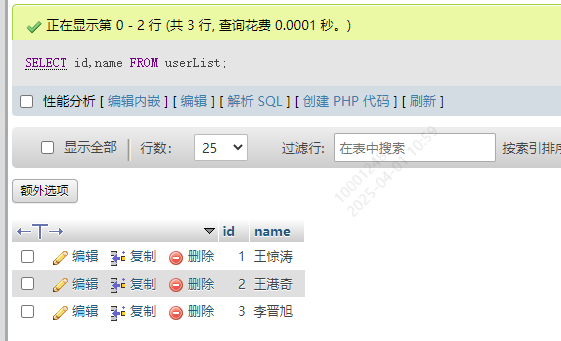
10.2 查询具体字段
SELECT 字段1,字段2 FROM tablename
10.3 固定值和运算符
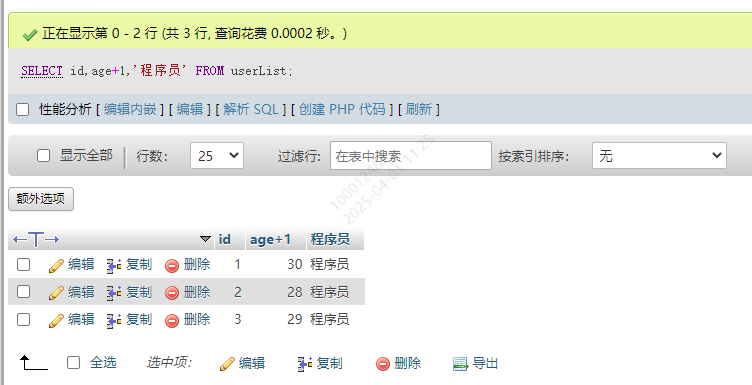
SELECT id,age+1,'程序员' FROM tablename
可以写一些常数值,和一些做了运算的属性值
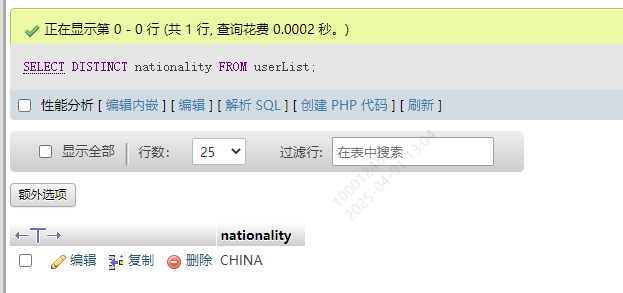
10.4 筛除重复数据
只要字段的值重复了.只返回一次
SELECT DISTINCT 字段1 FROM userList
11.创建几张用于测试的表
因为需要正常业务中,数据肯定是比较复杂的,各种业务数据之间也会有关联关系,每次查询的sql肯定不是一个简单的selet * 表名就能解决的。
这里我创建三张表有关关系并且比较通俗易懂的表
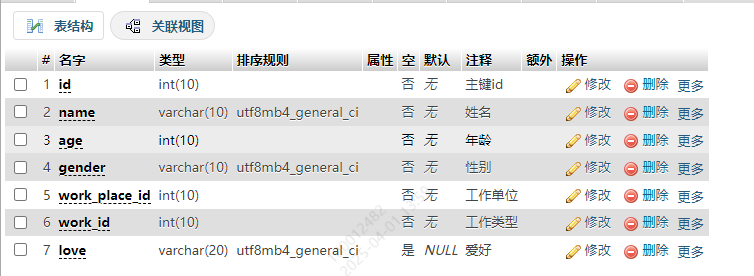
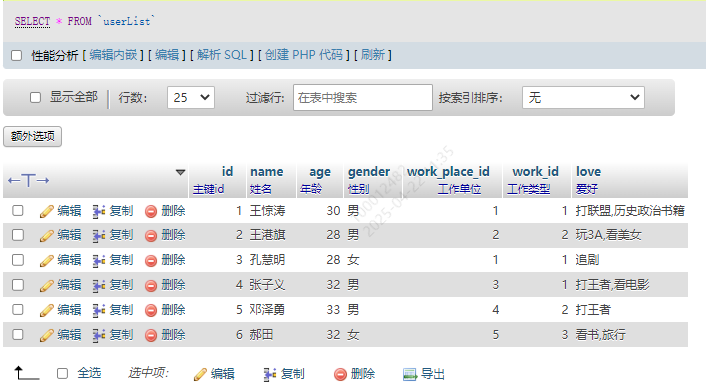
表1. userList
创建语句
CREATE TABLE `userList` (`id` int(10) NOT NULL COMMENT '主键id',`name` varchar(10) NOT NULL COMMENT '姓名',`age` int(10) NOT NULL COMMENT '年龄',`gender` varchar(10) NOT NULL COMMENT '性别',`work_place_id` int(10) NOT NULL COMMENT '工作单位',`work_id` int(10) NOT NULL COMMENT '工作类型',`love` varchar(20) COMMENT '爱好'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='人员信息表';
结构预览
插入数据
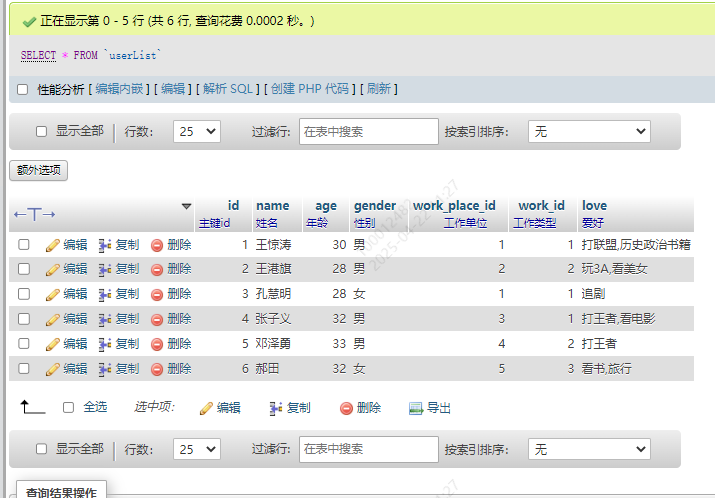
INSERT INTO `userList` (`id`, `name`, `age`, `gender`, `work_place_id`, `work_id`, `love`) VALUES ('1', '王惊涛', '29', '男', '1', '1', '打联盟,历史政治书籍'), ('2', '王港旗', '27', '男', '2', '2', '玩3A,看美女'), ('3', '孔慧明', '27', '女', '1', '1', '追剧'), ('4', '张子义', '31', '男', '3', '1', '打王者,看电影'), ('5', '邓泽勇', '32', '男', '4', '2', '打王者'), ('6', '郝田', '31', '女', '5', '3', '看书,旅行');
效果
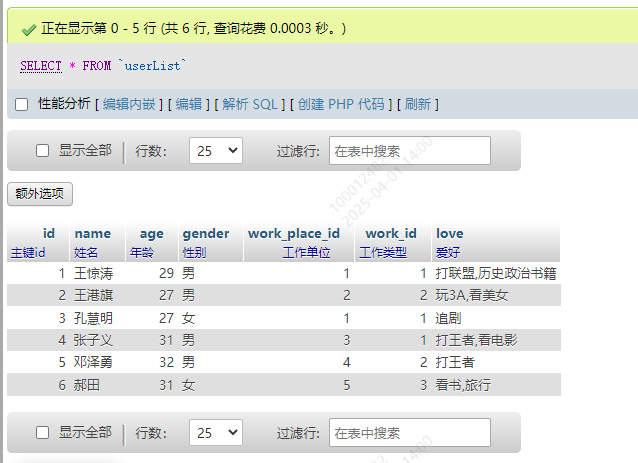
表2. workplaceList
创建语句
CREATE TABLE `workplaceList` (`id` int(10) NOT NULL COMMENT '主键id',`name` varchar(30) NOT NULL COMMENT '公司名称',`desc_text` varchar(30) NOT NULL COMMENT '公司描述',`job_num` int(10) NOT NULL COMMENT '员工数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='公司信息表';
结构预览
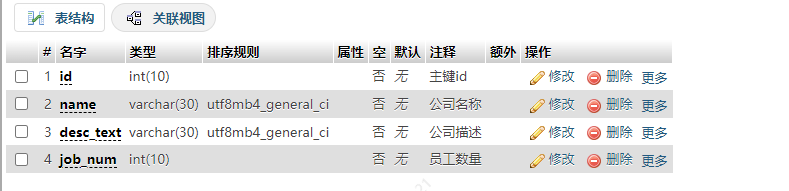
插入数据
INSERT INTO `workplaceList` (`id`, `name`, `desc_text`, `job_num`) VALUES ('1', '长城汽车', '一家汽车制造商,制度传统严格', '30000'), ('2', '小明公司', '一家小型互联网单位,爱加班', '50'), ('3', '京东', '以物流和电商成名的公司,不放弃兄弟', '50000'), ('4', '工银科技', '银行业务,擅长帽子戏法', '60000');
效果
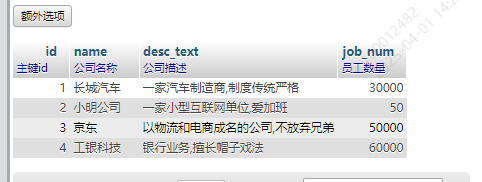
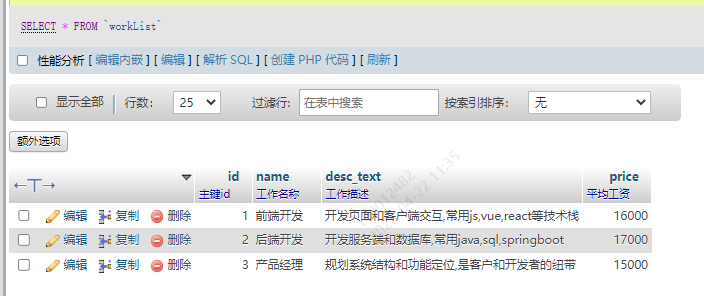
表3. workList
创建语句
CREATE TABLE `workList` (`id` int(10) NOT NULL COMMENT '主键id',`name` varchar(20) NOT NULL COMMENT '工作名称',`desc_text` varchar(50) NOT NULL COMMENT '工作描述',`price` int(10) NOT NULL COMMENT '平均工资'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='工作岗位信息表';
结构
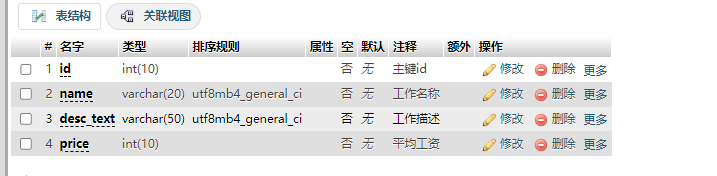
插入数据
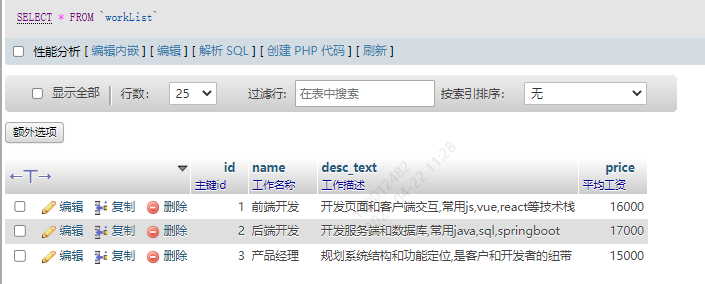
INSERT INTO `workList` (`id`, `name`, `desc_text`, `price`) VALUES ('1', '前端开发', '开发页面和客户端交互,常用js,vue,react等技术栈', '15000'), ('2', '后端开发', '开发服务端和数据库,常用java,sql,springboot', '16000'), ('3', '产品经理', '规划系统结构和功能定位,是客户和开发者的纽带', '14000');
效果
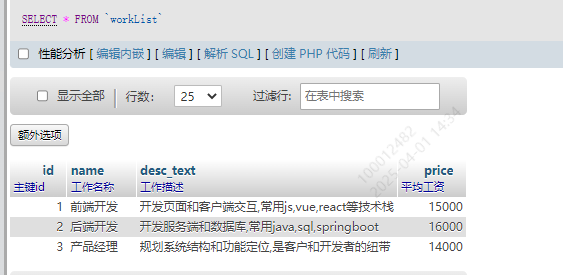
上面忘记设置主键id了,需要将各个表的id设置成主键,这里就不演示怎么弄了,前面有方法
12.函数功能
12-1 数学函数
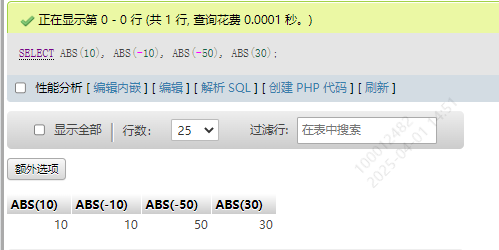
1.绝对值 ABS()
SELECT ABS(10), ABS(-10), ABS(-50), ABS(30)
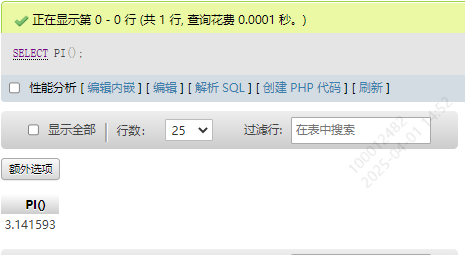
2.圆周率 PI()
SELECT PI()
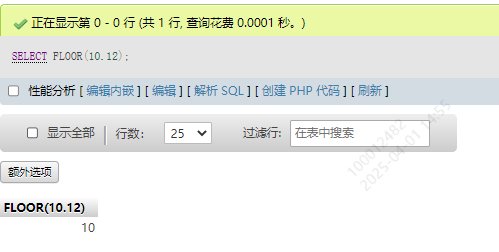
3.向下取整函数 FLOOR()
SELECT FLOOR(10.12)
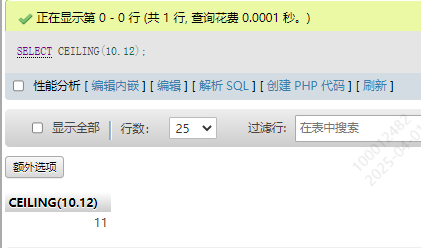
4.向上取整函数 CEILING()
SELECT CEILING(10.12)
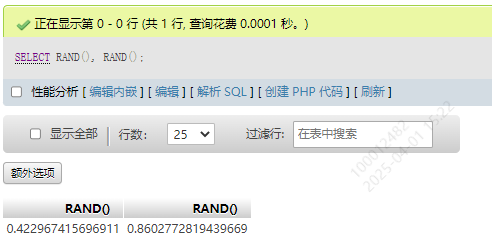
5.获取随机数 RAND()
会得到一个0到1之间的随机数
SELECT RAND(), RAND()
12-2 聚合函数
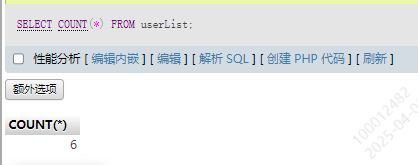
1.有效值总数COUNT()
函数的值是代表字段名,如果不指定具体字段,就用*表示全部
SELECT COUNT(*) FROM userList;
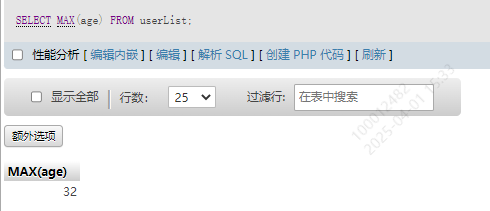
2.最大值MAX()
SELECT MAX(age) FROM userList;
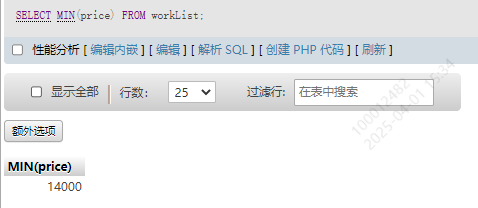
3.最小值MIN()
SELECT MIN(price) FROM workList;
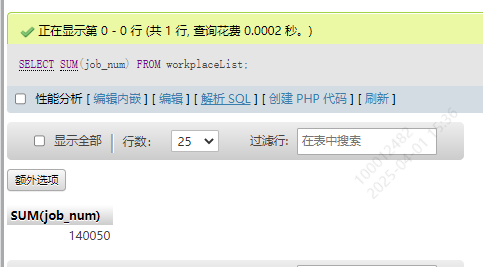
4.指定列之和SUM()
SELECT SUM(job_num) FROM workplaceList;
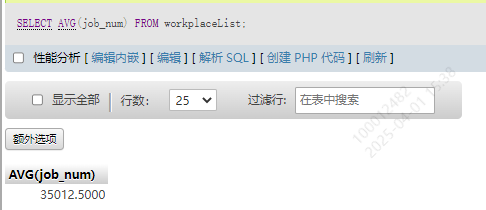
5.平均值AVG()
SELECT AVG(job_num) FROM workplaceList;
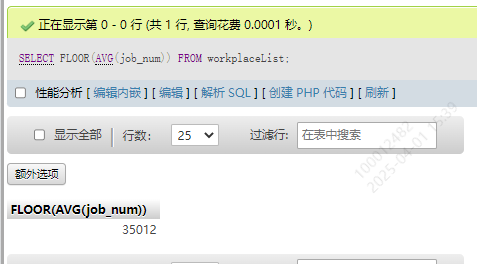
6.复合使用
SELECT FLOOR(AVG(job_num)) FROM workplaceList;
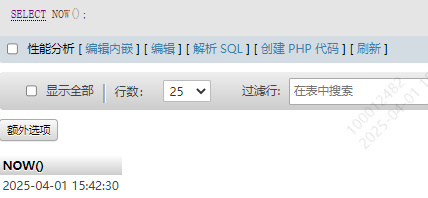
12-3 时间函数
SELECT NOW()
还有很多获取时间的函数,比如年月日
## 年
SELECT YEAR(NOW())
## 月
SELECT MONTH(NOW())
## 日
SELECT DAY(NOW())
## 时分秒
SELECT TIME(NOW());
12-4 字符串相关的函数
1.字符串拼接CONCAT
SELECT CONCAT ('a','b');

SELECT CONCAT(name,'-',age) FROM userList
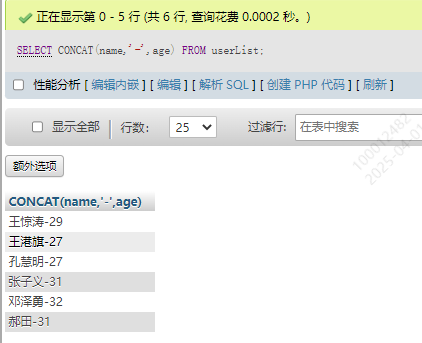
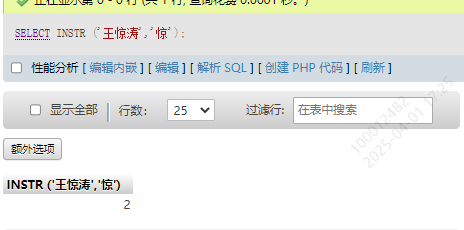
2.获取某个字符第一次出现的索引INSTR
SELECT INSTR ('王惊涛','惊')
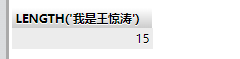
3.获取字符串字节长度LENGTH
这里是字节长度,不是常规的长度。一个中文占三个字节
SELECT LENGTH('我是王惊涛')
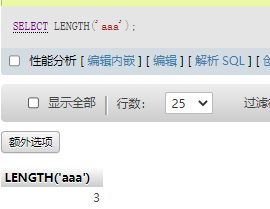
SELECT LENGTH('aaa')
13.按条件查询
13.1 关系运算符
1.等于 =
SELECT * FROM userList WHERE gender='男'
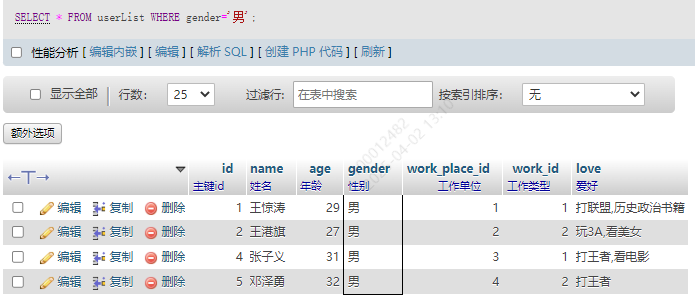
2.不等于 !=
SELECT * FROM userList WHERE gender != '男';
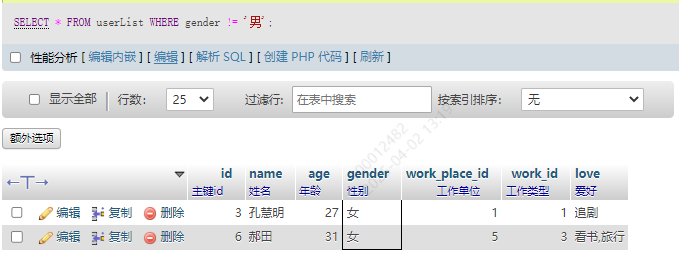
3.小于 <
SELECT * FROM userList WHERE age<30;
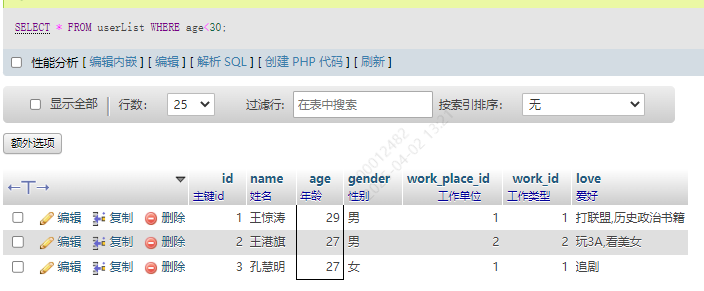
4.小于等于 <=
SELECT * FROM userList WHERE age<=31;
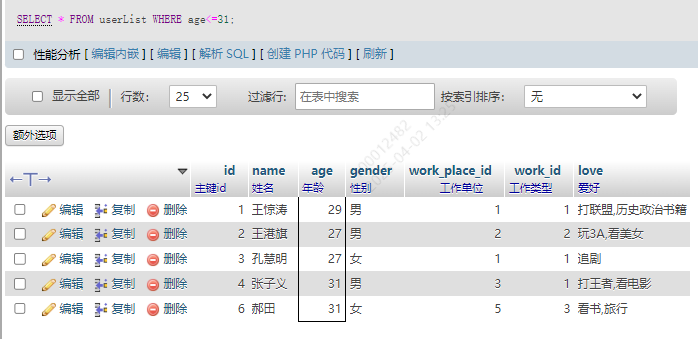
5.大于和大于等于 > >=
SELECT * FROM userList WHERE age>30;
SELECT * FROM userList WHERE age>=31;
再次不展示结果了
13.2 IN关键字查询
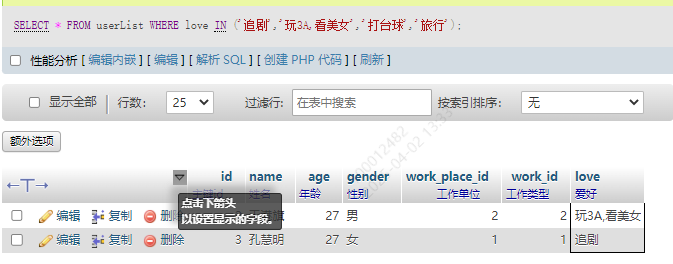
1.精准匹配
in关键字之前是字段值,in之后是一个集合,只要表中某一行的该字段值在这个集合中可以精准匹配,那就可以查询到
SELECT * FROM userList WHERE love IN ('追剧','玩3A,看美女','打台球','旅行')
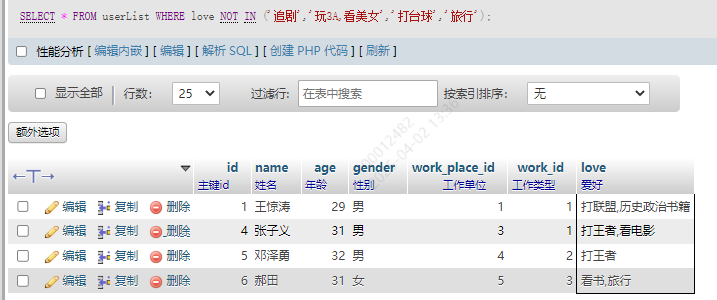
2.排除匹配
not in 就是不在这之内的都可以匹配到
SELECT * FROM userList WHERE love NOT IN ('追剧','玩3A,看美女','打台球','旅行')
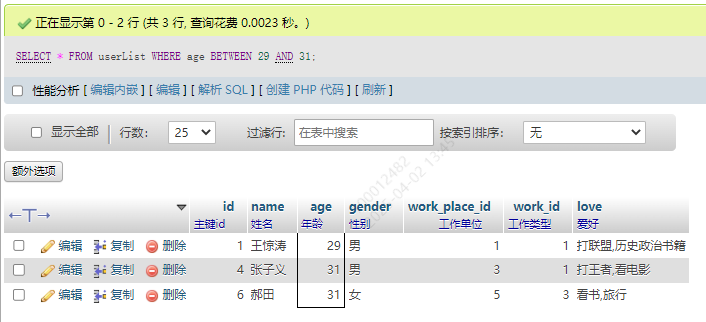
13.3 BETWEEN AND关键字查询
1.匹配区间
年龄在29到31这个区间的
SELECT * FROM userList WHERE age BETWEEN 29 AND 31
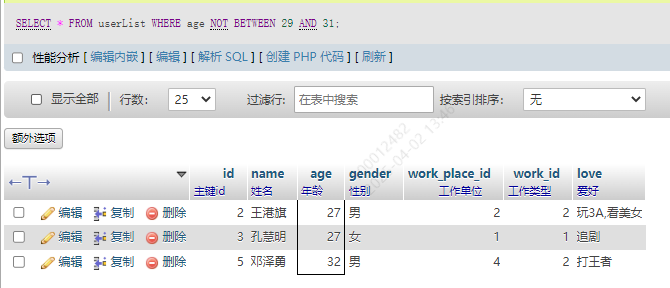
2.排除区间
年龄不在29到31这个区间的其他人
SELECT * FROM userList WHERE age NOT BETWEEN 29 AND 31
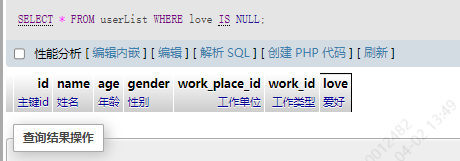
13.4 空值匹配 IS NULL
1.匹配空值
SELECT * FROM userList WHERE love IS NULL
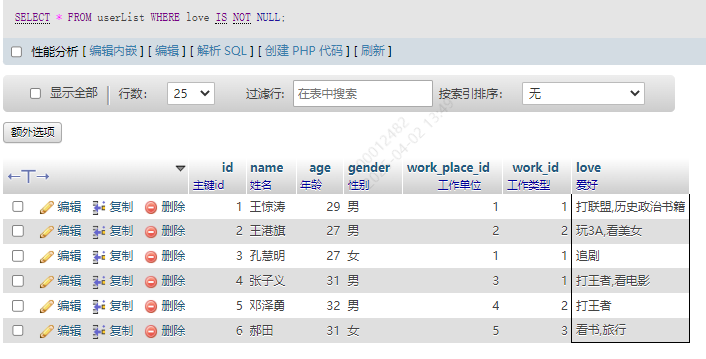
2.排除空值
SELECT * FROM userList WHERE love IS NOT NULL
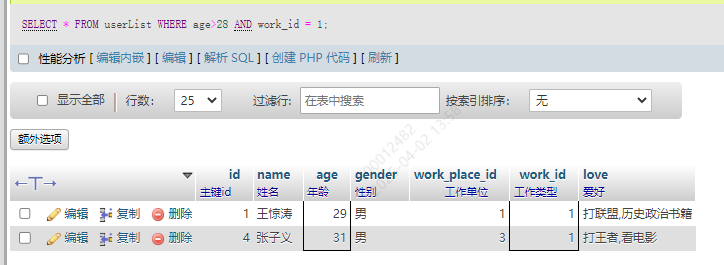
13.5 AND关键字
年龄大于28并且work_id必须是1,这两个条件都得满足
SELECT * FROM userList WHERE age>28 AND work_id = 1;
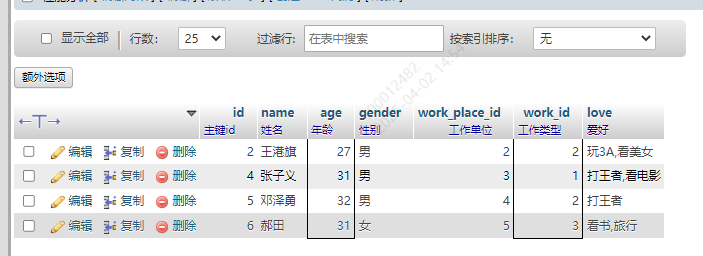
13.6 OR关键字
年龄大于29的,work_id是2的。只要这两个条件符合任何一个,都可以
SELECT * FROM userList WHERE age>29 OR work_id = 2;
13.7 LIKE关键字
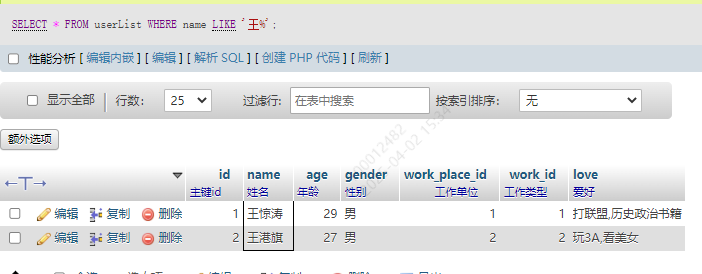
1.以某字符开头
某字段的值以某字符开头,使用 字段名 LIKE '字符%'去匹配
SELECT * FROM userList WHERE name LIKE '王%';
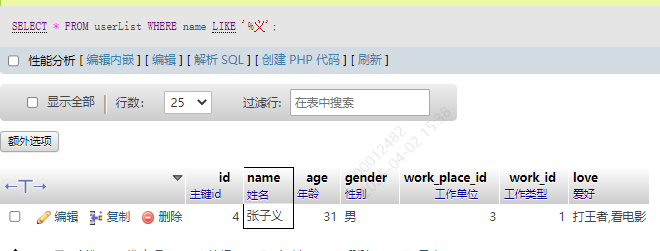
2.以某字符结尾
某字段的值以某字符结尾,使用 字段名 LIKE '%字符’去匹配
SELECT * FROM userList WHERE name LIKE '%义';
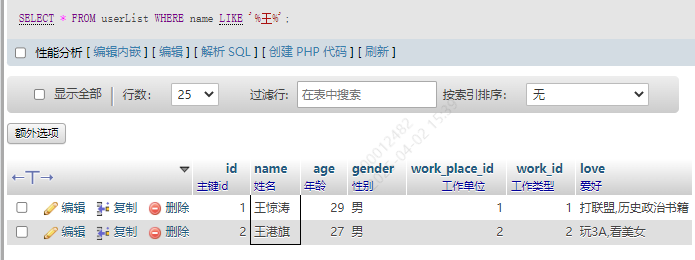
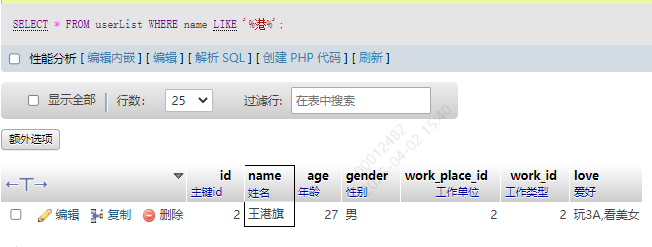
3.包含某字符的
不论这个字符在什么位置,只要存在,就能匹配到
SELECT * FROM userList WHERE name LIKE '%王%';
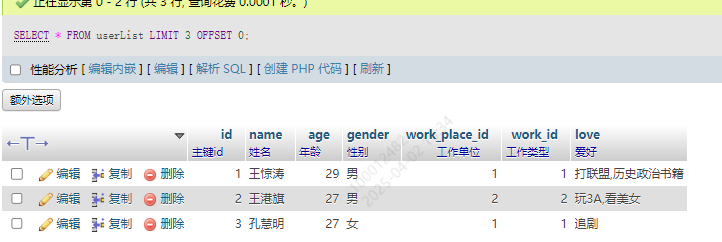
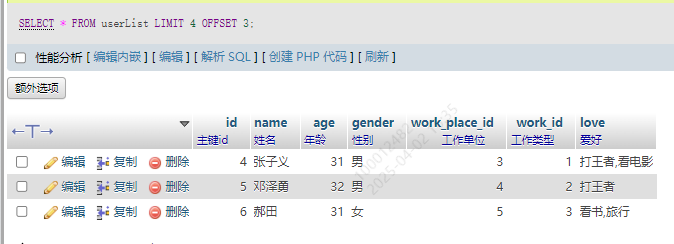
13.8 限制查询数据量 LIMIT OFFSET
分页查询基本上都用这个,LIMIT是查询的个数,OFFSET是从哪个开始,如果是3,就从表的第四个开始
SELECT * FROM userList LIMIT 3 OFFSET 0
13.9 排序 ORDER BY
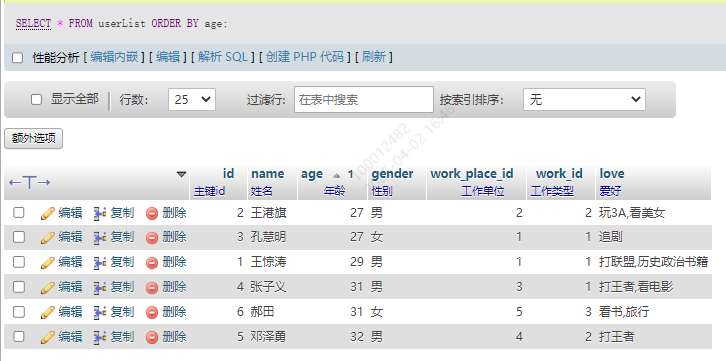
1.升序 ASC(默认)
如果什么都不写,或者是ASC,就是升序。下面两行sql的结果是一样的
SELECT * FROM userList ORDER BY age;
SELECT * FROM userList ORDER BY age ASC;
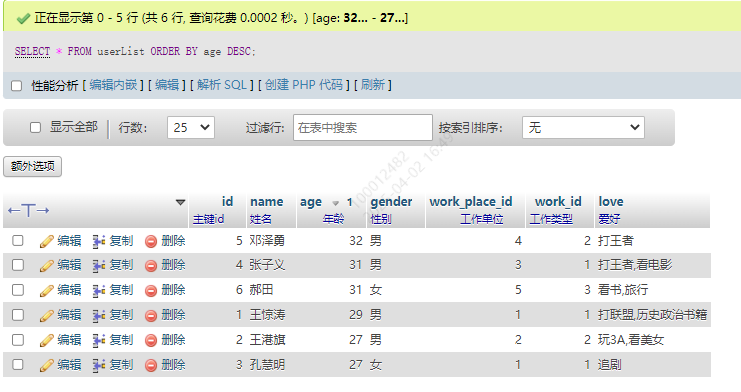
2.降序 DESC
SELECT * FROM userList ORDER BY age DESC;
3.多字段联合使用
字段 排序方式 , 字段 排序方式 用逗号隔开,可以使用多个字段进行排序
SELECT * FROM userList ORDER BY age DESC, work_id ASC;
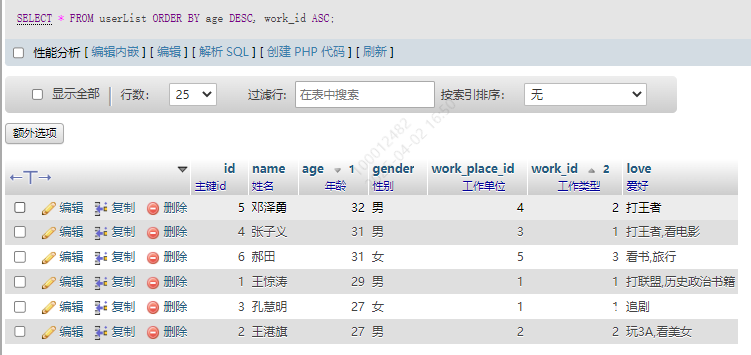
13.10分组 GROUP BY
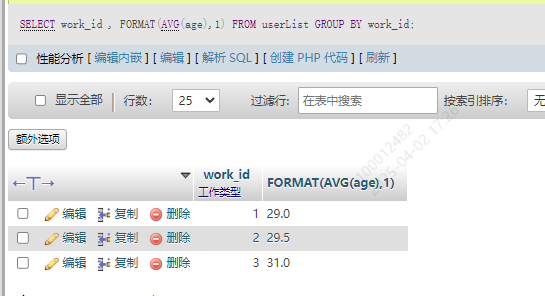
1.分组查询数据
和聚合函数一起使用: 以work_id为标志分组,比如1是前端组,2是后端组,3是产品组,求出这个三个组的平均年龄保留一位小数
SELECT work_id , FORMAT(AVG(age),1) FROM userList GROUP BY work_id;
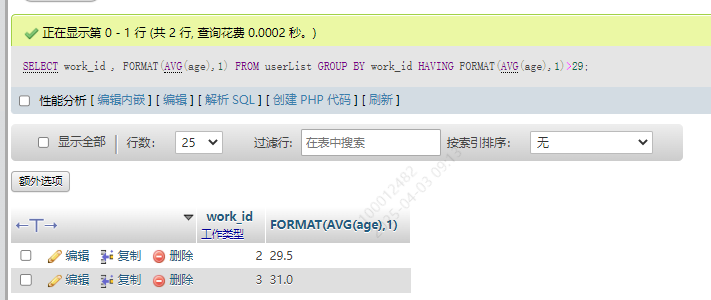
2.和HAVING搭配使用
HAVING也相当于一个判断条件,和WHERE有类似之处,不过他是从前面执行完毕后的结果中再去筛选。WHERE是直接从表中筛选
从上述结果中筛选出平均工资大于29的
SELECT work_id , FORMAT(AVG(age),1) FROM userList GROUP BY work_id HAVING FORMAT(AVG(age),1)>29
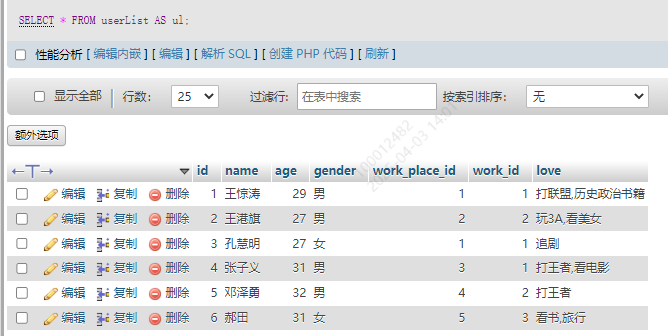
14.设置别名
14.1 给表设置别名
SELECT * FROM 表名 AS 别名
SELECT * FROM userList AS ul
14.2 字段设置别名
SELECT 字段名1 AS 别名1 , 字段名2 AS 别名2 FROM 表名
SELECT name AS 姓名 , age AS 年龄, gender AS 性别 FROM userList as ul
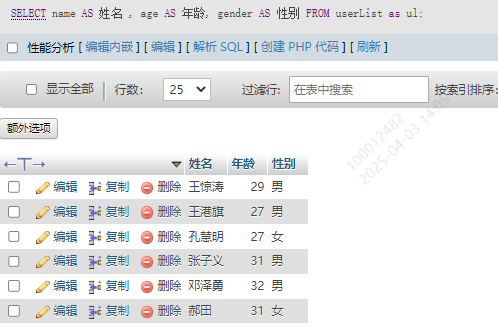
15.关联查询
15.1 查询单条数据的关联查询
数据之间和表之间很多时候,都是有关联性的。比如我现在想获取王惊涛的姓名,年龄,工作岗位名称,岗位平均薪资,公司名称和公司简介。这几条信息并不是存在于同一张表中,而是分散存在三张表中,那就需要用userList这张表为基础,去查询出其余关联的信息
SELECT
ul.name AS 姓名,
ul.age AS 年龄,
ul.id , wl.name AS 岗位名称, wl.price AS 岗位均薪, pl.name AS 公司名称, pl.desc_text AS 公司描述
FROM
userList AS ul, workList AS wl, workplaceList AS pl
WHERE
ul.name = '王惊涛'&& (ul.id = wl.id = pl.id)
;
15.2.交叉连接查询
SELECT * FROM userList CROSS JOIN workList
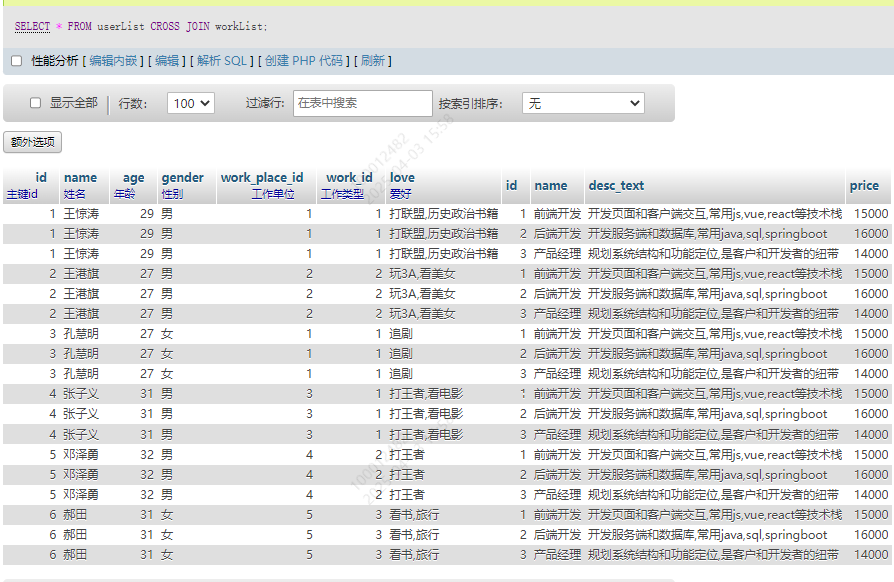
可以看到userList中的每一项都和workList中每一项进行了匹配,这肯定不是业务中需要的。形成这种情况的结果,称之为笛卡尔积。
15.3.内连接查询
也称简单连接,把两张表中相匹配的数据组织成一张表数据。
SELECT 查询字段1,查询字段2 FROM 表1 INNER JOIN 表2 ON 表1字段=表二字段
SELECT
ul.name AS userName, ul.id AS userId , wl.name AS workName , wl.desc_text AS workDesc
FROM
userList AS ul
INNER JOIN
workList AS wl
ON ul.work_id = wl.id;
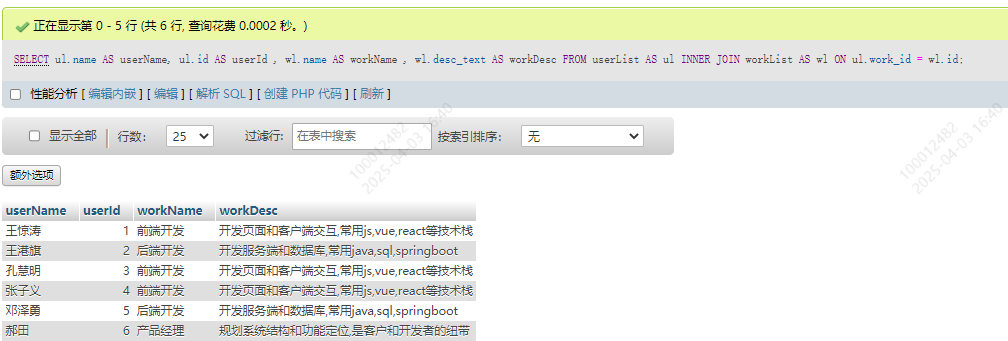
如果条件又不符合的,数据中就不会有这一条
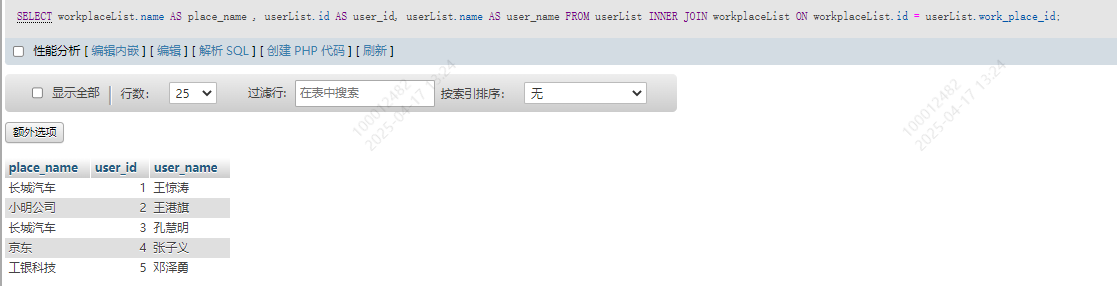
SELECT workplaceList.name AS place_name , userList.id AS user_id, userList.name AS user_name
FROM userList INNER JOIN workplaceList
ON workplaceList.id = userList.work_place_id
15.4左外连接查询
将两张表的数据进行匹配组合
FROM 主 LEFT OUTER JOIN 从 ON 条件
以获取主表的数据为准,从表中有匹配的,那就插入数据中。如果从表中没有符合ON后面条件的,数值就是null。
左外连接:谁在左边谁就是主表(满的)
主说: 我满了,你随意
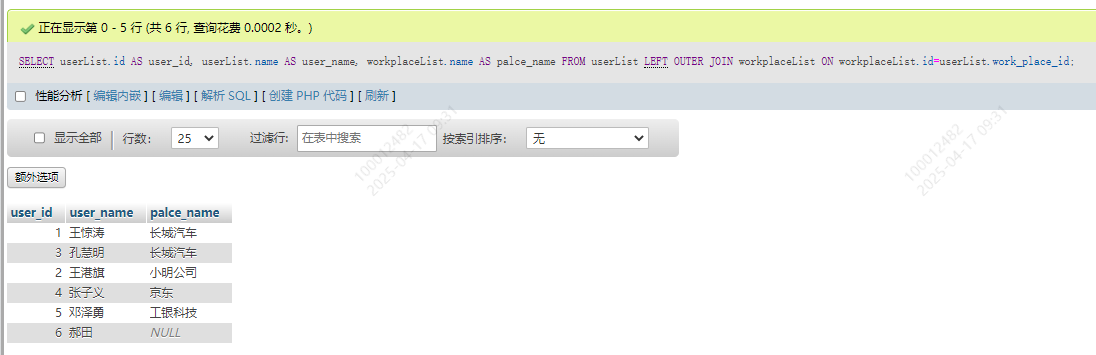
SELECT userList.id AS user_id, userList.name AS user_name, workplaceList.name AS palce_name
FROM userList LEFT OUTER JOIN workplaceList
ON workplaceList.id=userList.work_place_id;
15.5右外链查询
和左外连接正好想法,右外连接就是主在右边
FROM 从 RIGHT OUTER JOIN 主 ON 条件
SELECT workplaceList.name AS place_name , userList.id AS user_id, userList.name AS user_name
FROM workplaceList RIGHT OUTER JOIN userList
ON userList.work_place_id=workplaceList.id
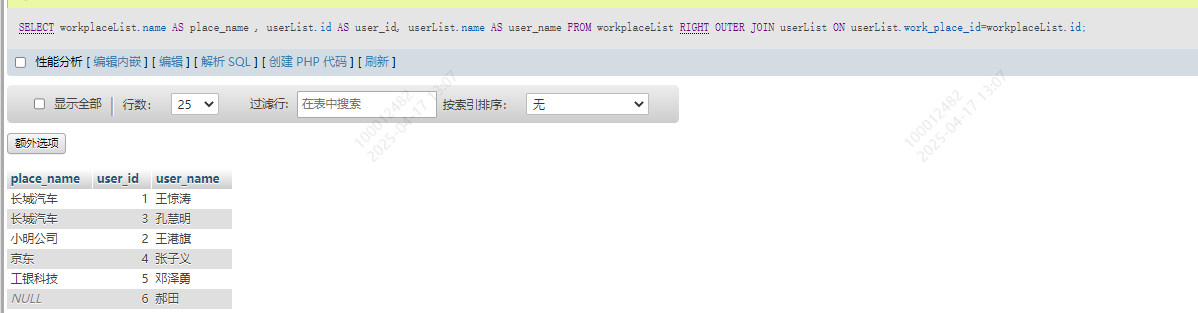
这个结果和之前的左外连接结果是一样的
调换位置之后
SELECT workplaceList.name AS place_name , userList.id AS user_id, userList.name AS user_name
FROM userList RIGHT OUTER JOIN workplaceList
ON userList.work_place_id=workplaceList.id;
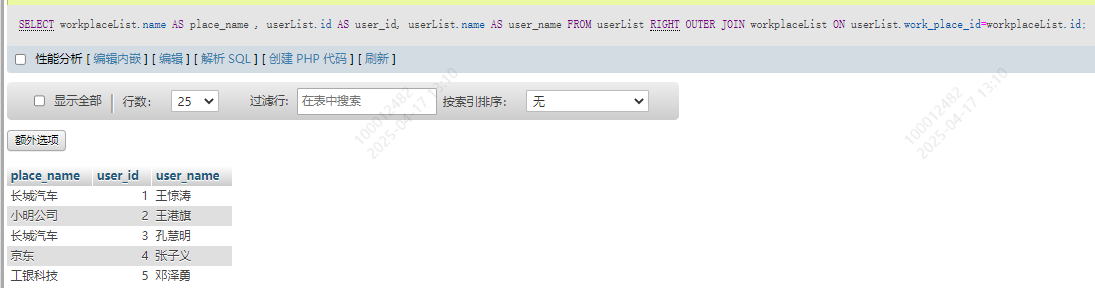
公司表的数据是全的,用户表作为外连的从表,即使有多出来的也就不会回显那条数据。
16.子查询
查询语句嵌套查询语句,将内部嵌套语句的查询结果作为外层嵌套查询的过滤条件。
16.1 条件运算符
SELECT * FROM 表1 WHERE xx属性=(SELECT yy属性 FROM 表2 WHERE 条件)
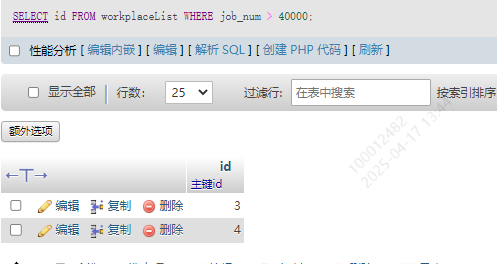
比如现在想查询userList表中有哪些人所在单位的员工数量大于40000人
首先,先去查询所有员工数量大于40000的单位id
SELECT id FROM workplaceList WHERE job_num > 40000;
查询结果如下
然后将这个结果作为一个过滤条件去查询对应的员工,也就是子查询
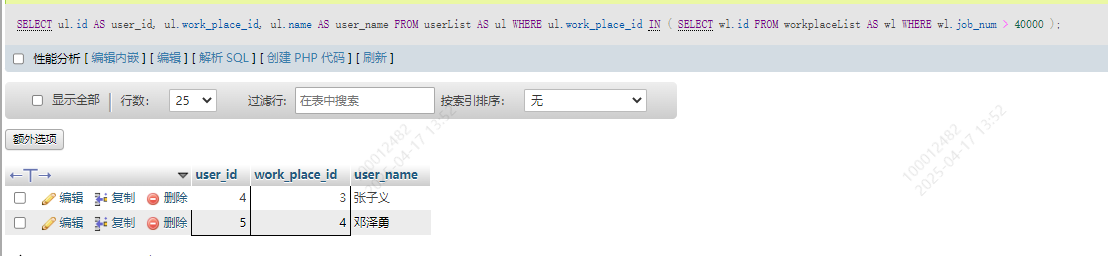
SELECT ul.id AS user_id, ul.work_place_id, ul.name AS user_name
FROM userList AS ul
WHERE ul.work_place_id IN (
SELECT wl.id FROM workplaceList AS wl WHERE wl.job_num > 40000
);
16.2 EXISTS关键字
SELECT XXX FROM 表1 WHERE EXISTS (子查询语句)
EXISTS后面的子查询语句只要有返回行,就会执行前面的查询语句。记住,这个子语句返回的内容是什么不重要,重要的是有没有返回行数。
SELECT * FROM userList WHERE EXISTS(SELECT * FROM userList WHERE id = 7);
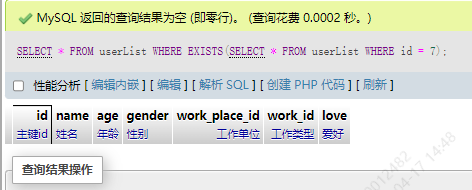
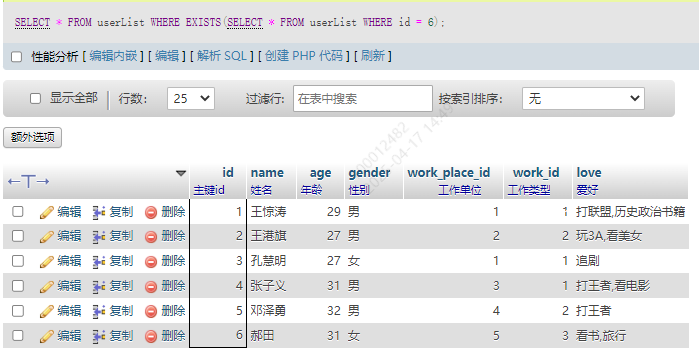
因为id最大的是6,没有7。所以不返回数据,子查询的结果判定为false。如果将id换成6,符合条件,就可以执行前面的查询
16.3 ANY关键字
表示满足其中任意一个条件就返回一个结果作为外层查询条件。(确实很绕,看示例)
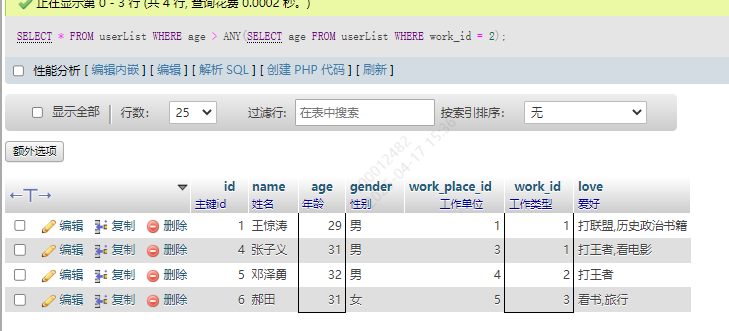
查询一下所有后端开发的年龄,只要大于其中的任何一个,就都符合条件。
SELECT * FROM userList WHERE age > ANY(SELECT age FROM userList WHERE work_id = 2);
16.4 ALL关键字
all是需要满足所有条件
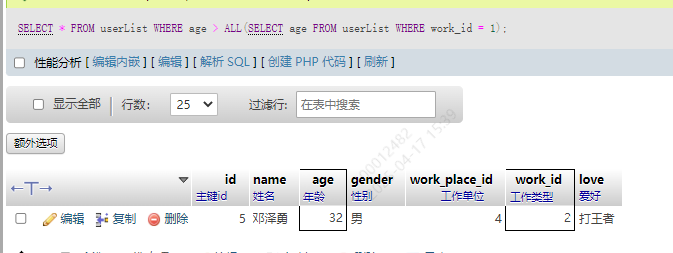
SELECT * FROM userList WHERE age > ALL(SELECT age FROM userList WHERE work_id = 2);
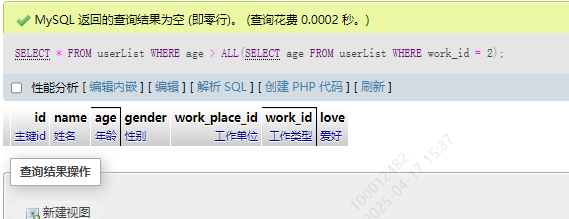
因为最大的后端开发年龄是32,没有人比他的年龄大,所以没有结果。
将子查询的条件换成前端开发。前端最大年龄是31,邓泽勇32,就符合条件了。
17.逻辑判断关键字
17.1 IF关键字
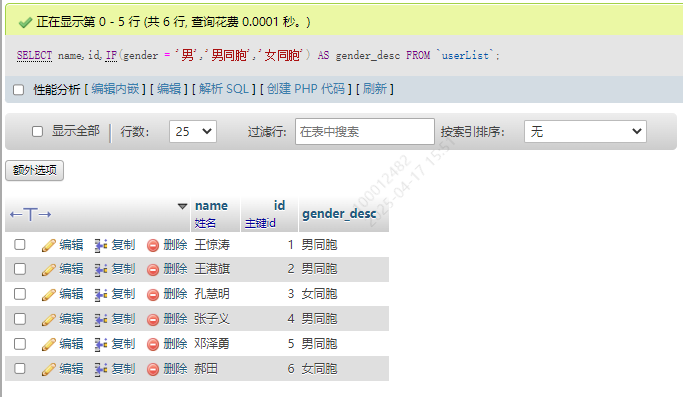
SELECT IF(判断条件,判断条件为true的值,判断条件为false的字段值) AS 别名 FROM 表
SELECT name,id,IF(gender = '男','男同胞','女同胞') AS gender_desc FROM `userList`;
17.2 CASE关键字
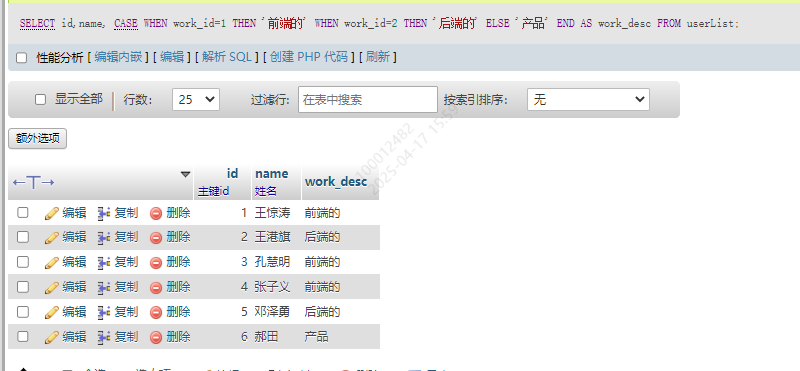
格式为
SELECT 属性1,属性2
CASEWHEN 条件1 THEN 'xxx'WHEN 条件2 THEN 'yyy'ELSE 'yyy'
END AS 属性别名
FROM 表;
获取人员的职务别称和个人信息
SELECT id,name,
CASEWHEN work_id=1 THEN '前端的'WHEN work_id=2 THEN '后端的'ELSE '产品'
END AS work_desc
FROM userList;
18. UNION关键字
比如我们将原来的userList列表复制了一份,并添加了一些数据
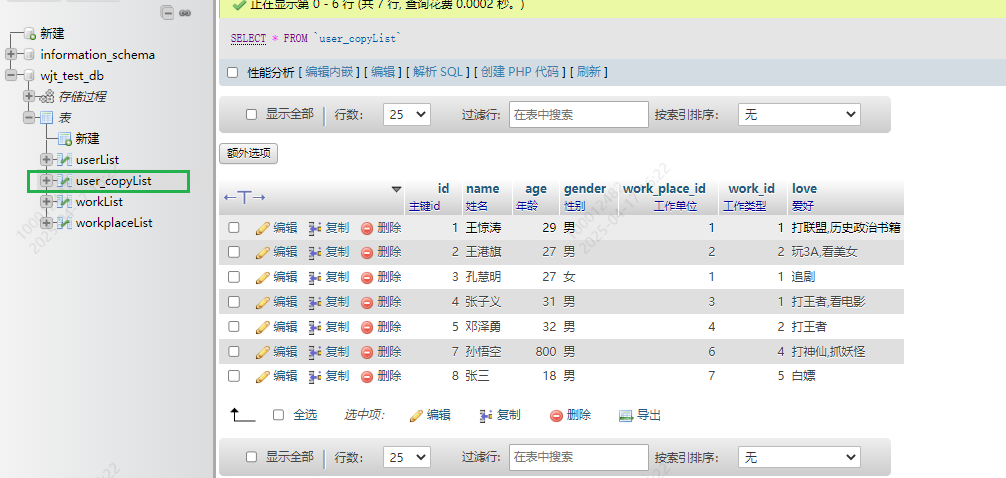
这张表和userList列表结构一样,不过数据有所区别,有重复的一些数据。我希望查询这两张表数据的结合,也就是所有人的数据,并且希望不要的重复获取,就可以用到UNION关键
SELECT 属性x,属性y FROM 表1
UNION
SELECT 属性x,属性y FROM 表2
SELECT id,name,age FROM userList
UNION
SELECT id,name,age FROM user_copyList;
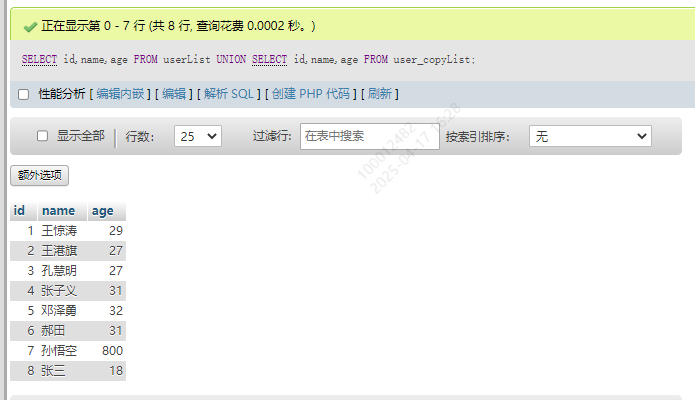
如果希望重复,可以使用UNION ALL关键字
SELECT id,name,age FROM userList
UNION ALL
SELECT id,name,age FROM user_copyList;
19.正则表达式
和其他语言差不多,正则匹配
SELECT 属性x,属性y FROM 表 WHERE 属性 REGEXP '正则表达式'
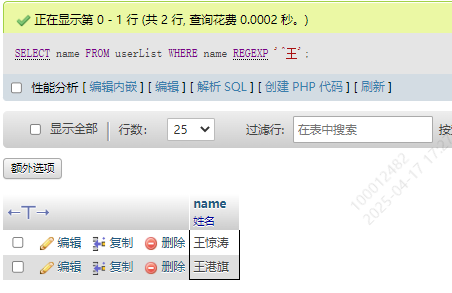
SELECT name FROM userList WHERE name REGEXP '^王'
获取name以王字开头的数据
20.mysql事务
20.1概念:
用于处理操作量大,复杂度高的数据。比如一个员工离职的时候,和他有关的东西都需要被清除。组织关系,职务岗位,权限范围,工时薪资等等。
事务的四个条件:
- 原子性: 一个事务的操作,要么全部完成,要么全部不完成,不会卡在终结某个环节。如果执行中有错误,就会被回滚到之前的状态。
- 一致性: 事务开始前和完成后,不会破坏数据库的结构,不会影响其他不相关的。
- 隔离性: 数据库允许多个并发事务同时操作,隔离性可以防止多个事务并发执行时由于交叉执行而导致不一致。
- 持久性: 事务处理结束后,对数据的修改就是永久的。
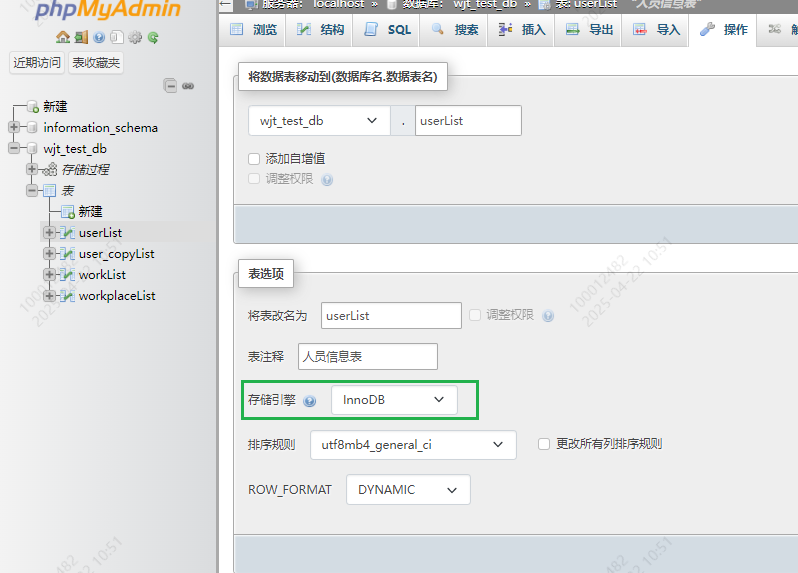
并且只有在mysql中使用了innodb数据库引擎的数据库或表才支持事务。
20.2命令
开始事务命令
BEGIN;
或者是
START TRANSACTION
提交事务命令
COMMIT
回滚命令
ROLLBACK
设置保存点
可以在回滚的时候,回滚到该点
SAVEPOINT savepoint_name
用于回滚到之前设置的保存点
ROLLBACK TO SAVEPOINT savepoint_name
20.3使用示例
执行一个提交
--开始
START TRANSACTION--执行sql语句
UPDATE userList SET age = age + 1;
UPDATE workList SET price = price + 1000;COMMIT
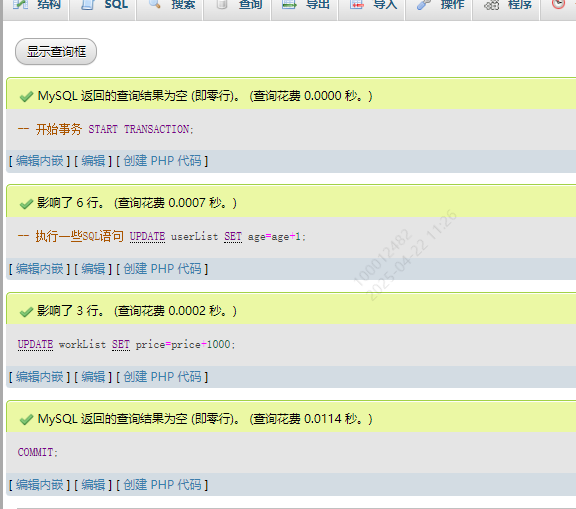
所有人年龄都加了1
所有岗位平均薪资加了1000
执行一个回滚
START TRANSACTIONUPDATE userList SET age = age + 1;
UPDATE workList SET price = price + 1000;ROLLBACK;
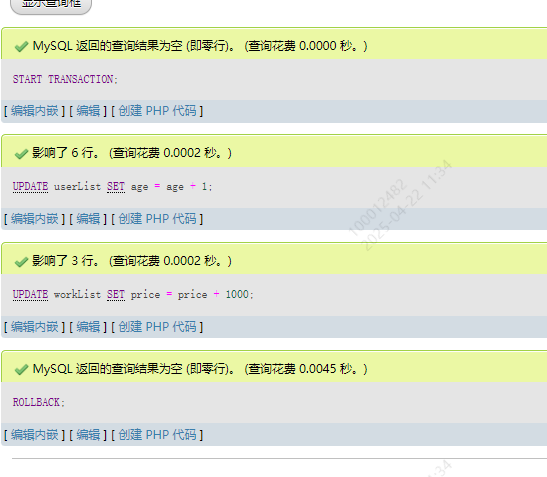
变化被重置了
21.mysql序列
创建表的时候,可以设置一个自增主键,以正整数的顺序递增。
CREATE TABLE new_table (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50)
);
22.mysql命令大全
22.1基础命令
| 操作 | 命令 |
|---|---|
| 连接到 MySQL 数据库 | mysql -u 用户名 -p |
| 查看所有数据库 | SHOW DATABASES; |
| 选择一个数据库 | USE 数据库名; |
| 查看所有表 | SHOW TABLES; |
| 查看表结构 | DESCRIBE 表名; 或 SHOW COLUMNS FROM 表名; |
| 创建一个新数据库 | CREATE DATABASE 数据库名; |
| 删除一个数据库 | DROP DATABASE 数据库名; |
| 创建一个新表 | CREATE TABLE 表名 (列名1 数据类型 [约束], 列名2 数据类型 [约束], …); |
| 删除一个表 | DROP TABLE 表名; |
| 插入数据 | INSERT INTO 表名 (列1, 列2, …) VALUES (值1, 值2, …); |
| 查询数据 | SELECT 列1, 列2, … FROM 表名 WHERE 条件; |
| 更新数据 | UPDATE 表名 SET 列1 = 值1, 列2 = 值2, … WHERE 条件; |
| 删除数据 | DELETE FROM 表名 WHERE 条件; |
| 创建用户 | CREATE USER ‘用户名’@‘主机’ IDENTIFIED BY ‘密码’; |
| 授权用户 | GRANT 权限 ON 数据库名.* TO ‘用户名’@‘主机’; |
| 刷新权限 | FLUSH PRIVILEGES; |
| 查看当前用户 | SELECT USER(); |
| 退出 MySQL | EXIT; |
22.2数据库相关命令
| 操作 | 命令 |
|---|---|
| 创建数据库 | CREATE DATABASE 数据库名; |
| 删除数据库 | DROP DATABASE 数据库名; |
| 修改数据库编码格式和排序规则 | ALTER DATABASE 数据库名 DEFAULT CHARACTER SET 编码格式 DEFAULT COLLATE 排序规则; |
| 查看所有数据库 | SHOW DATABASES; |
| 查看数据库详细信息 | USE 数据库名; |
| 查看数据库的状态信息 | SHOW STATUS; |
| 查看数据库的错误信息 | SHOW ERRORS; |
| 查看数据库的警告信息 | SHOW WARNINGS; |
| 查看数据库的表 | SHOW TABLES; |
| 查看表的结构 | DESC 表名; DESCRIBE 表名; SHOW COLUMNS FROM 表名; EXPLAIN 表名; |
| 创建表 | CREATE TABLE 表名 (列名1 数据类型 [约束], 列名2 数据类型 [约束], …); |
| 删除表 | DROP TABLE 表名; |
| 修改表结构 | ALTER TABLE 表名 ADD 列名 数据类型 [约束]; ALTER TABLE 表名 DROP 列名; ALTER TABLE 表名 MODIFY 列名 数据类型 [约束]; |
| 查看表的创建 SQL | SHOW CREATE TABLE 表名; |
22.3数据表相关命令
| 操作 | 命令 |
|---|---|
| 创建表 | CREATE TABLE 表名 (列名1 数据类型 [约束], 列名2 数据类型 [约束], …); |
| 删除表 | DROP TABLE 表名; |
| 修改表结构 | 添加列:ALTER TABLE 表名 ADD 列名 数据类型 [约束]; 删除列: ALTER TABLE 表名 DROP 列名;修改列: ALTER TABLE 表名 MODIFY 列名 数据类型 [约束];重命名列: ALTER TABLE 表名 CHANGE 旧列名 新列名 数据类型 [约束]; |
| 查看表结构 | DESC 表名; DESCRIBE 表名; SHOW COLUMNS FROM 表名; EXPLAIN 表名; |
| 查看表的创建 SQL | SHOW CREATE TABLE 表名; |
| 查看表中的所有数据 | SELECT * FROM 表名; |
| 插入数据 | INSERT INTO 表名 (列1, 列2, …) VALUES (值1, 值2, …); |
| 更新数据 | UPDATE 表名 SET 列1 = 值1, 列2 = 值2, … WHERE 条件; |
| 删除数据 | DELETE FROM 表名 WHERE 条件; |
| 查看表的索引 | SHOW INDEX FROM 表名; |
| 创建索引 | CREATE INDEX 索引名 ON 表名 (列名); |
| 删除索引 | DROP INDEX 索引名 ON 表名; |
| 查看表的约束 | SHOW CREATE TABLE 表名; (约束信息会包含在创建表的 SQL 中) |
| 查看表的统计信息 | SHOW TABLE STATUS LIKE ‘表名’; |
22.4事务相关命令
| 操作 | 命令 |
|---|---|
| 开始事务 | START TRANSACTION; 或 BEGIN; |
| 提交事务 | COMMIT; |
| 回滚事务 | ROLLBACK; |
| 查看当前事务的状态 | SHOW ENGINE INNODB STATUS; (可查看 InnoDB 存储引擎的事务状态) |
| 锁定表以进行事务操作 | LOCK TABLES 表名 WRITE; 或 LOCK TABLES 表名 READ; |
| 释放锁定的表 | UNLOCK TABLES; |
| 设置事务的隔离级别 | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; |
23.mysql8.0新增常用函数
| 函数 | 描述 | 实例 |
|---|---|---|
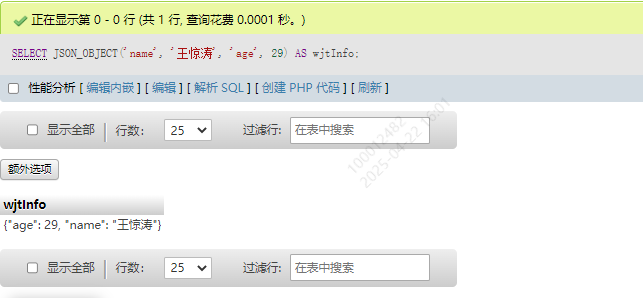
| JSON_OBJECT() | 将键值对转换为 JSON 对象 | SELECT JSON_OBJECT(‘name’, ‘王惊涛’, ‘age’, ‘29’) |
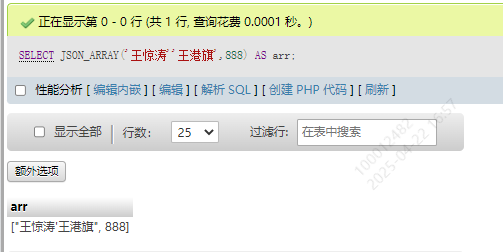
| JSON_ARRAY() | 将值转换为 JSON 数组 | SELECT JSON_ARRAY(‘王惊涛’,‘王港旗’,888) |
| JSON_EXTRACT() | 从 JSON 字符串中提取指定的值 | SELECT JSON_EXTRACT(‘{“name”: “王惊涛”, “age”: 29}’, ‘$.name’) |
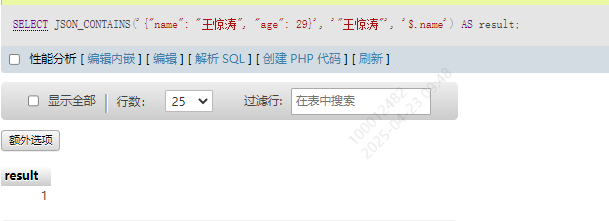
| JSON_CONTAINS() | 检查一个 JSON 字符串是否包含指定的值 | SELECT JSON_CONTAINS(‘{“name”: “王惊涛”, “age”: 29}’, ‘“王惊涛”’, ‘$.name’); |
键值转化为json
值转化为数组
从json字符串中提取指定的值
检查json字符串是否包含某个值