Anomize: Better Open Vocabulary Video Anomaly Detection

标题:Anomize: 更优的开放词汇视频异常检测
原文链接:https://arxiv.org/pdf/2503.18094
发表:CVPR-2025
摘要
开放词汇视频异常检测(Open Vocabulary Video Anomaly Detection,OVVAD)旨在检测并分类基础和新颖的异常事件。然而,现有方法在应对新颖异常时面临两大挑战。其一是 检测歧义性(detection ambiguity):模型难以为不熟悉的异常赋予准确的异常分数;其二是 分类混淆(categorization confusion):新颖异常常被误分类为视觉上相似的基础实例。
为了解决这些挑战,我们探索多源补充信息,通过多层次视觉数据与匹配文本信息结合,缓解检测歧义性。同时,我们引入标签关系来指导新标签的编码过程,从而提升新颖视频与其标签之间的对齐效果,进而减少分类混淆。
我们提出的 Anomize 框架有效应对上述问题,在 UCF-CRIME 和 XD-VIOLENCE 数据集上实现了更优性能,验证了其在 OVVAD 任务中的有效性。
1. 引言
视频异常检测(Video Anomaly Detection, VAD)旨在识别视频中出现的异常事件,在现实世界中具有广泛的应用价值,例如公共安全监控系统。现有方法大致可以根据训练时使用的标签类型分为两类:
- 半监督 VAD(例如 [3, 22, 49])仅使用正常样本进行训练。模型通过学习正常模式,在测试时将偏离该模式的行为视为异常;
- 弱监督 VAD(例如 [13, 33, 50])在训练时使用带有视频级标签的正常和异常样本,但不依赖精确的时序标注。这类方法通常将检测任务视为视频级别的二分类问题。
尽管这些方法在封闭集设定下取得了不错的性能,但它们通常局限于识别训练中已出现过的异常类型,难以泛化到开放世界中多样且未见的异常事件。
近期研究开始关注更具挑战性的 开放集 VAD(open-set VAD)任务 [1, 9],该任务假设训练阶段接触到的异常为基础异常(base cases),而测试阶段可能出现的未见异常为新颖异常(novel cases)。该范式的目标是在训练时学习基础异常,并在推理时识别包括新颖异常在内的所有异常行为,从而打破封闭集检测的局限。然而,这种方式通常不关注异常的语义信息,因此模型的输出缺乏可解释性 [42]。
为克服这一问题,Wu 等人 [42] 提出了更具挑战性的任务:开放词汇视频异常检测(Open Vocabulary Video Anomaly Detection, OVVAD)。该任务在开放集的训练设定下,要求模型不仅能检测出异常,还需对其进行语义分类,输出异常事件的具体类别标签。
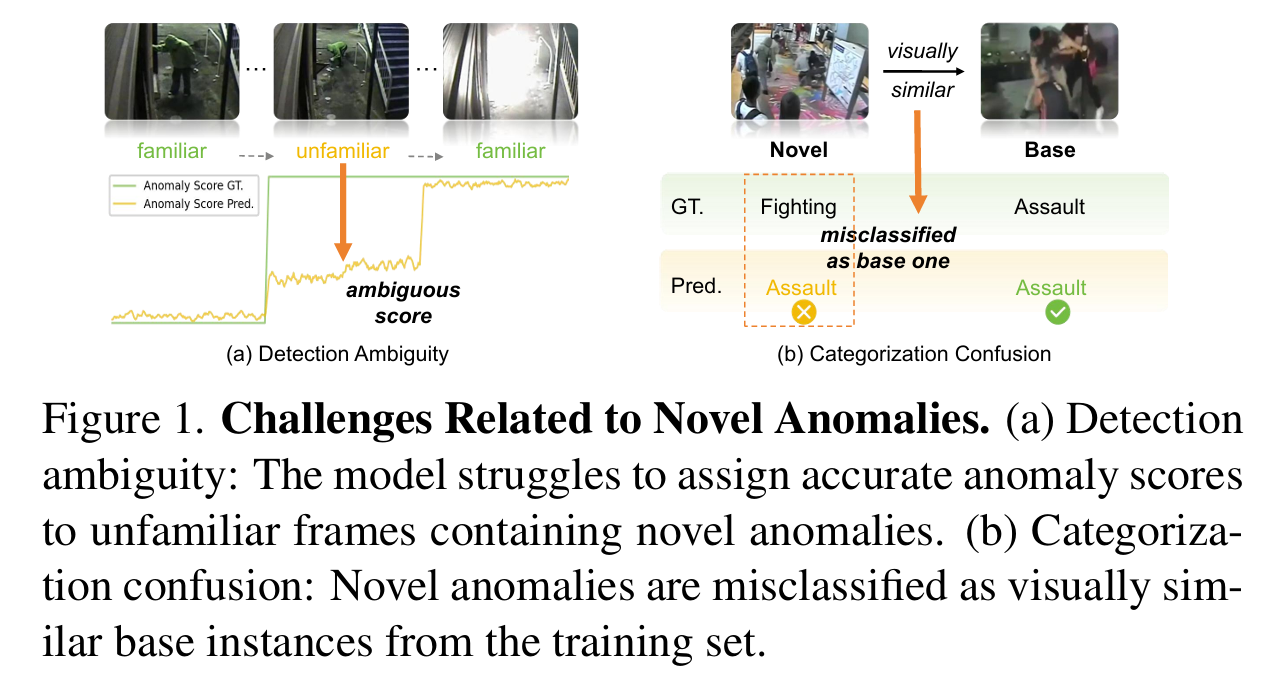
尽管开放词汇范式具备更强的实用性,但现有方法仍面临两个核心挑战:
- 检测歧义性(Detection Ambiguity):如图 1(a) 所示,面对从未见过的异常事件,模型常常无法获得足够的信息支持,因而难以给出准确的异常分数。这是因为当前方法通常依赖于训练集中的先验知识或特定的微调策略,缺乏对新颖异常的泛化能力;
- 分类混淆(Categorization Confusion):如图 1(b) 所示,模型倾向于将视觉上相似但语义不同的异常混淆。例如,模型可能将“打架”与“袭击”混为一类,因为它们在视觉层面上非常相似。由于开放词汇分类任务通常依赖于视觉-文本对齐(如使用 CLIP 进行多模态对比),如果新颖异常的视频编码在特征空间上更接近基础类别,就会出现严重的分类混淆。
目前的开放词汇方法大多借助预训练的视觉-语言模型(如 CLIP)来进行文本编码,其输入通常为模板化句子 [16, 29, 44, 45] 或标签词嵌入 [2, 4, 53]。这类方法通常仅依赖模型在预训练阶段获得的语义泛化能力,缺乏对文本表示的显式引导,限制了模型对新颖类别的多模态对齐能力。
为了解决上述问题,我们提出了一个全新的框架 —— Anomize,旨在有效缓解开放词汇异常检测中的检测歧义性与分类混淆问题。
首先,为了解决检测歧义性,我们设计了一个文本增强双流机制(text-augmented dual stream mechanism),由**静态流(static stream)和动态流(dynamic stream)**组成,分别关注不同维度的视觉特征,并通过匹配的文本信息进行增强:
- 动态流关注帧间的时序模式,引入行为描述类文本作为增强信息,提升对动作性异常(如跟踪)的检测;
- 静态流保留原始 CLIP 提取的图像特征,引入语义概念词库(ConceptLib)作为增强信息,以帮助检测依赖上下文环境的异常(如在高速公路上奔跑)。
这两个流之间具备天然的互补性,可以分别捕捉不同类型异常的关键特征(时序 vs. 上下文),并通过双分支融合,有效提高整体检测的泛化能力。
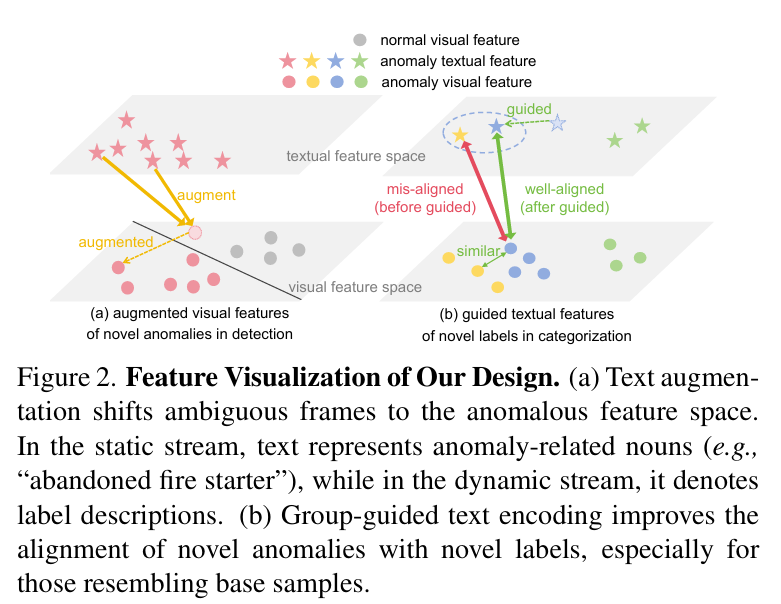
图 2. 我们设计的特征可视化。
(a) 文本增强机制将原本模糊的帧特征引导至异常特征空间。在静态流中,文本表示与异常相关的名词(如 “被遗弃的点火器”);而在动态流中,文本则表示标签描述。
(b) 分组引导的文本编码能够提升新颖异常与对应标签之间的对齐效果,尤其在新颖异常与基础样本在视觉上相似时尤为有效。
此外,该机制符合人类常识推理流程:即先理解异常的语义,再从图像中寻找相关迹象。在此基础上,图 2(a) 显示,我们的文本增强机制能够将原本模糊的视觉特征推向异常空间,使模型能够更准确地识别不熟悉的异常事件。
其次,为了解决分类混淆问题,我们提出分组引导文本编码机制(group-guided text encoding mechanism)。该机制通过引入标签间的结构性关系,引导文本表示在特征空间中产生更合理的分布:
- 我们将视觉上相似的标签分为同一组,并使用 GPT 等大型语言模型生成每个标签的结构化描述;
- 组内标签的描述具有共同部分以保证其接近性,同时加入差异化细节以维持区分性。
如图 2(b) 所示,在分组引导机制的帮助下,即使新颖类别在训练阶段未出现,它们的文本表示也能有效映射至靠近的基础类别,从而提升多模态对齐能力,显著减少分类混淆。
我们的方法基于预训练的 CLIP 模型,在其视觉和文本编码器的基础上进行轻量化设计,具备良好的零样本能力。在两个真实世界开放视频异常检测基准(UCF-Crime 和 XD-Violence)上的实验验证了方法的有效性。
本文的贡献总结如下:
- 我们提出了一个文本增强双流机制,通过引入与异常标签语义相关的文本信息,有效缓解检测歧义性问题;
- 我们设计了分组引导文本编码机制,引导文本特征在多模态空间中更好对齐,显著缓解新颖异常的分类混淆问题;
- 在两个主流数据集上进行的大量实验证明,我们的方法在异常检测与分类两方面均优于现有方法,尤其在新颖类别上表现突出。
2. 相关工作
2.1 视频异常检测
半监督 VAD. 现有的半监督视频异常检测(VAD)方法通常可分为三类:一类分类模型(One-Class Classification, OCC)、重建模型 和 预测模型,这三类方法均仅使用正常数据进行训练。OCC 模型 [31, 32, 35, 40, 49] 通过识别落在正常数据所学习的超球体之外的数据点以实现异常检测。然而,正常性的定义可能具有歧义性,降低了检测效果 [23, 46]。重建方法 [3, 25, 30, 48, 52] 通常使用深度自动编码器(DAE)学习正常模式,通过较高的重建误差检测异常。但 DAE 仍可能以低误差重建异常帧,削弱检测性能。预测模型 [5, 8, 18, 22, 24, 26] 常使用生成对抗网络(GAN)预测未来帧,再与实际帧进行比较判断是否为异常。
弱监督 VAD. 弱监督视频异常检测(WSVAD)仅使用视频级标签进行训练,缺乏精确的时间或空间注释。WSVAD 通常将任务表述为多实例学习(MIL)问题 [19, 33, 34, 39, 50],将视频划分为片段并将片段预测聚合为视频级异常分数。Sultani 等人 [33] 首次提出使用深度多实例排序框架定义 WSVAD 范式。近期方法专注于优化模型结构,例如 Tian 等人 [34] 提出 RTFM,结合空洞卷积和自注意力机制检测细微异常,Zaheer 等人 [50] 则引入聚类驱动的正常性抑制机制。其他方法 [13, 27] 则使用预训练模型以获取任务无关知识,Wu 等人 [43] 提出 VadCLIP,使用 CLIP [29] 实现异常分数和标签的双分支输出。
开放集 VAD. 开放集 VAD 模型在正常行为和基础异常上训练,以检测所有异常,适用于开放世界场景。Acsintoae 等人 [1] 首次提出开放集 VAD,构建了基准数据集与评估框架。Zhu 等人 [54] 在多实例学习框架中结合了证据深度学习和正规化流,Hirschorn 等人 [9] 提出轻量级的正规化流框架,利用人体姿态图结构。
我们的方法在开放场景下同时提供检测和分类结果,聚焦于解决新颖异常相关的挑战。
2.2 开放词汇学习
近年来,预训练视觉语言模型 [11, 29] 的进展极大地推动了开放词汇任务的发展,包括开放词汇目标检测 [6, 15, 51]、语义分割 [7, 20, 47] 和动作识别 [12, 14, 21, 36] 等。这些研究广泛利用多模态模型的预训练知识,展现出强大的泛化能力。Wu 等人 [42] 首次提出使用预训练模型 CLIP 进行开放词汇视频异常检测(OVVAD)。然而,大多数方法偏重于视觉编码器,忽视了文本编码器,从而限制了零样本能力。
我们的方法进一步探索文本编码器的潜力,并引入引导式编码机制以提升 OVVAD 中的多模态对齐能力。
3. 提出的 Anomize 方法
3.1 总览
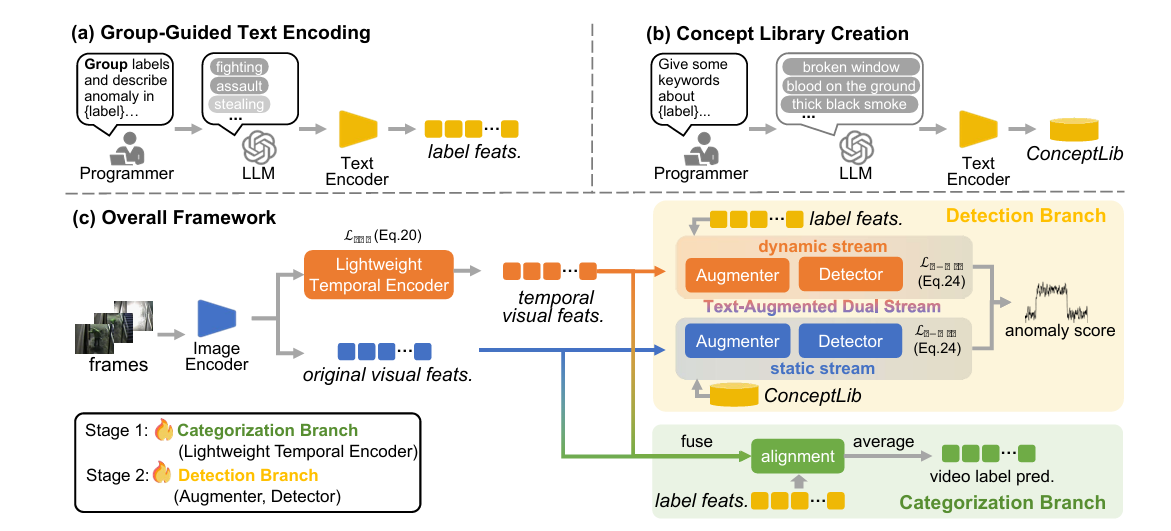
图 3. 我们提出的 Anomize 框架概览。
(a) 通过分组引导文本编码机制(Group-Guided Text Encoding)提取标签特征的流程;
(b) 构建用于异常检测的概念库 ConceptLib;
© 框架将异常标签与视频帧输入模型,输出帧级异常分数与预测标签。异常打分通过文本增强双流机制(Text-Augmented Dual Stream)完成,其中每个流分别接收对应的文本和视觉特征,最终融合两路结果作为输出。
在分类过程中,模型将由分组引导文本编码生成的标签特征与融合后的原始视觉特征与时间特征进行对齐。文本编码器与图像编码器均基于 CLIP 预训练模型,在训练过程中保持冻结,不进行梯度更新。
遵循 Wu 等人 [42] 的设置,我们将训练样本集定义为:
D = { ( v i , y i ) } i = 1 N + A \mathcal{D} = \{(v_i, y_i)\}_{i=1}^{N+A} D={(vi,yi)}i=1N+A
其中 N N N 为正常样本数, A A A 为异常样本数,即 D n \mathcal{D}_n Dn 表示正常样本集, D a \mathcal{D}_a Da 表示异常样本集。 v i v_i vi 表示视频样本, y i ∈ C base y_i \in \mathcal{C}_{\text{base}} yi∈Cbase 表示其对应的异常标签,其中每个 v i ∈ D a v_i \in \mathcal{D}_a vi∈Da 至少包含一个异常帧,而 v i ∈ D n v_i \in \mathcal{D}_n vi∈Dn 全部为正常帧。完整标签集合 C \mathcal{C} C 包含基础异常标签和新颖异常标签。
OVVAD 的目标是:在训练集 D \mathcal{D} D 上训练模型,预测帧级的异常分数和视频级的异常标签,标签来自 C \mathcal{C} C。
图 3 展示了 Anomize 框架的整体结构。我们利用预训练 CLIP 模型的编码器来提取视觉特征,借助其强大的泛化能力。视频帧由 CLIP 图像编码器 Φ visual \Phi_{\text{visual}} Φvisual 处理,提取出原始视觉特征:
x f ∈ R n × d x_f \in \mathbb{R}^{n \times d} xf∈Rn×d
其中 n n n 表示帧数, d d d 表示特征维度。原始特征通过轻量级时间编码器建模生成时间特征。原始视觉特征经过静态流(Static Stream),结合概念库(ConceptLib)中的概念词增强;时间特征通过动态流(Dynamic Stream),结合标签描述增强。
两个流各自预测异常分数,最终聚合为帧级异常分数 s ∈ R n × 1 s \in \mathbb{R}^{n \times 1} s∈Rn×1。对于分类任务,我们采用多模态对齐方法,首先融合视觉特征,然后使用 CLIP 文本编码器 Φ text \Phi_{\text{text}} Φtext 与分组引导的文本编码机制提取文本特征。帧级分类预测由特征对齐得到,进一步聚合为视频级分类结果 p video p_{\text{video}} pvideo。
3.2 轻量级时间编码器
我们使用冻结的 CLIP 图像编码器 Φ visual \Phi_{\text{visual}} Φvisual 提取视觉特征,以保留其零样本能力。然而,CLIP 是基于图文对的预训练模型,缺乏视频时间建模能力。近期方法 [14, 37, 38] 通常引入时间编码器,但这可能在新颖样本上导致性能下降,因为附加参数可能会对训练集过拟合。
因此,我们采用轻量级 LSTM [10] 进行时间建模,生成时间视觉特征 x tem ∈ R n × d x_{\text{tem}} \in \mathbb{R}^{n \times d} xtem∈Rn×d:
x tem = LSTM ( x f ) (1) x_{\text{tem}} = \text{LSTM}(x_f) \tag{1} xtem=LSTM(xf)(1)
补充材料中还讨论了其他参数高效模型的适用性。
3.3 分组引导的文本编码
以往方法主要依赖预训练模型的泛化能力,缺乏任务特定的指导,容易导致分类混淆。我们引入分组引导的文本编码机制(Group-Guided Text Encoding)来解决此问题。
我们借助大型语言模型(如 GPT-4 [28])生成标签描述。首先使用提示词 prompt group \text{prompt}_{\text{group}} promptgroup 对标签进行分组,使得同组内的视频具有较高的视觉相似度;接着使用 prompt desc \text{prompt}_{\text{desc}} promptdesc 为每个标签生成文本描述。这些描述捕捉组内的共有特征并强调各标签的独特性,确保其编码在特征空间中既相似又具可区分性。
result group = GPT ( prompt group , C ) (2) \text{result}_{\text{group}} = \text{GPT}(\text{prompt}_{\text{group}}, \mathcal{C}) \tag{2} resultgroup=GPT(promptgroup,C)(2)
result desc = GPT ( prompt desc , result group ) (3) \text{result}_{\text{desc}} = \text{GPT}(\text{prompt}_{\text{desc}}, \text{result}_{\text{group}}) \tag{3} resultdesc=GPT(promptdesc,resultgroup)(3)
将结果输入冻结的 CLIP 文本编码器 Φ text \Phi_{\text{text}} Φtext 得到标签描述编码:
t desc = Φ text ( result desc ) ∈ R c × d (4) t_{\text{desc}} = \Phi_{\text{text}}(\text{result}_{\text{desc}}) \in \mathbb{R}^{c \times d} \tag{4} tdesc=Φtext(resultdesc)∈Rc×d(4)
其中 c c c 表示异常类别数。
为了增强多模态对齐效果,我们将时间特征与原始视觉特征进行融合:
x fused = x tem + α x f (5) x_{\text{fused}} = x_{\text{tem}} + \alpha x_f \tag{5} xfused=xtem+αxf(5)
其中 α \alpha α 是标量权重。帧级预测概率为:
p frame = x fused t desc ⊤ ∥ x fused ∥ ∥ t desc ∥ (6) p_{\text{frame}} = \frac{x_{\text{fused}} t_{\text{desc}}^\top}{\|x_{\text{fused}}\| \, \|t_{\text{desc}}\|} \tag{6} pframe=∥xfused∥∥tdesc∥xfusedtdesc⊤(6)
其中 p frame ∈ R n × c p_{\text{frame}} \in \mathbb{R}^{n \times c} pframe∈Rn×c 表示每帧对 c c c 个异常标签的预测分布。视频级分类结果通过对每类标签的前 M M M 个帧预测取均值得到, M = n / 16 M = n / 16 M=n/16:
p avg = σ ( [ 1 M ∑ k = 1 M Top M ( p frame [ j ] ) ] j = 1 c ) (7) p_{\text{avg}} = \sigma \left( \left[ \frac{1}{M} \sum_{k=1}^{M} \text{Top}_M(p_{\text{frame}}[j]) \right]_{j=1}^{c} \right) \tag{7} pavg=σ [M1k=1∑MTopM(pframe[j])]j=1c (7)
最终的视频级预测标签为:
p video = arg max j p avg ( j ) (8) p_{\text{video}} = \arg\max_j p_{\text{avg}}(j) \tag{8} pvideo=argjmaxpavg(j)(8)
3.4 增强器(Augmenter)
在我们的方法中,两个流均使用统一的增强器将文本信息引入视觉编码。增强器接收视觉编码 e visual e_{\text{visual}} evisual 与文本编码 e text e_{\text{text}} etext 作为输入。
首先通过多头注意力机制 MHA ( ⋅ ) \text{MHA}(\cdot) MHA(⋅) 提取文本补充信息,其中 e visual e_{\text{visual}} evisual 为 Query, e text e_{\text{text}} etext 为 Key 和 Value,得到增强后的文本特征 e refine e_{\text{refine}} erefine:
e refine = MHA ( e visual , e text , e text ) (9) e_{\text{refine}} = \text{MHA}(e_{\text{visual}}, e_{\text{text}}, e_{\text{text}}) \tag{9} erefine=MHA(evisual,etext,etext)(9)
随后,视觉编码 e visual e_{\text{visual}} evisual 经过全连接层 FC ( ⋅ ) \text{FC}(\cdot) FC(⋅) 映射,与 e refine e_{\text{refine}} erefine 拼接后输入多层感知机(MLP)降维,得到最终增强特征:
e aug = MLP ( [ e refine ; FC ( e visual ) ] ) (10) e_{\text{aug}} = \text{MLP}([\;e_{\text{refine}};\; \text{FC}(e_{\text{visual}})\;]) \tag{10} eaug=MLP([erefine;FC(evisual)])(10)
3.5 文本增强双流(Text-Augmented Dual Stream)
在开放场景中,模型可能因信息不足而难以评估不熟悉的异常。为此,我们提出文本增强双流机制,通过互补的动态流(Dynamic Stream)与静态流(Static Stream)分别增强不同特征维度,为检测提供充分支持。
动态流. 鉴于视频异常检测(VAD)依赖时间信息,我们使用动态流基于增强的时间视觉特征 f aug ∈ R n × d f_{\text{aug}} \in \mathbb{R}^{n \times d} faug∈Rn×d 预测异常分数 s dyn ∈ R n × 1 s_{\text{dyn}} \in \mathbb{R}^{n \times 1} sdyn∈Rn×1:
f aug = Augmenter ( x tem , t desc ) (11) f_{\text{aug}} = \text{Augmenter}(x_{\text{tem}}, t_{\text{desc}}) \tag{11} faug=Augmenter(xtem,tdesc)(11)
s dyn = Sigmoid ( FC ( f aug + MLP ( f aug ) ) ) (12) s_{\text{dyn}} = \text{Sigmoid}(\text{FC}(f_{\text{aug}} + \text{MLP}(f_{\text{aug}}))) \tag{12} sdyn=Sigmoid(FC(faug+MLP(faug)))(12)
其中 Sigmoid ( ⋅ ) \text{Sigmoid}(\cdot) Sigmoid(⋅) 将结果映射至 [ 0 , 1 ] [0,1] [0,1] 区间。
静态流. 由于动态流在场景上下文方面存在局限,我们引入静态流对 CLIP 原始视觉特征进行增强。具体方法为:
我们构建概念库(ConceptLib),其中包含与异常相关的关键词,由 CLIP 文本编码器处理 GPT 生成的名词短语得到:
ConceptLib = Φ text ( GPT ( prompt conc , C ) ) (13) \text{ConceptLib} = \Phi_{\text{text}}(\text{GPT}(\text{prompt}_{\text{conc}}, \mathcal{C})) \tag{13} ConceptLib=Φtext(GPT(promptconc,C))(13)
然后,计算每一帧视觉特征 x f ( i ) x_f^{(i)} xf(i) 与概念词特征 h ∈ ConceptLib h \in \text{ConceptLib} h∈ConceptLib 的余弦相似度:
sim ( x f ( i ) , h ) = x f ( i ) h ⊤ ∥ x f ( i ) ∥ ⋅ ∥ h ∥ (14) \text{sim}(x_f^{(i)}, h) = \frac{x_f^{(i)} h^\top}{\|x_f^{(i)}\| \cdot \|h\|} \tag{14} sim(xf(i),h)=∥xf(i)∥⋅∥h∥xf(i)h⊤(14)
选择前 K K K 个相似度最大的概念特征 h f ( i ) ∈ R K × d h_f^{(i)} \in \mathbb{R}^{K \times d} hf(i)∈RK×d 及其得分 s f ( i ) ∈ R K s_f^{(i)} \in \mathbb{R}^{K} sf(i)∈RK:
h f ( i ) , s f ( i ) = TopK ( sim ( x f ( i ) , h ) ) (15) h_f^{(i)}, s_f^{(i)} = \text{TopK}(\text{sim}(x_f^{(i)}, h)) \tag{15} hf(i),sf(i)=TopK(sim(xf(i),h))(15)
将其得分归一化后加权,拼接成视频的增强文本特征:
h f new = [ σ ( s f ( i ) ) ⊙ h f ( i ) ] i = 1 n (16) h_f^{\text{new}} = \left[\; \sigma(s_f^{(i)}) \odot h_f^{(i)} \;\right]_{i=1}^{n} \tag{16} hfnew=[σ(sf(i))⊙hf(i)]i=1n(16)
接着, h f new h_f^{\text{new}} hfnew 与原始视觉特征 x f x_f xf 输入增强器,得到增强后的编码:
x aug = Augmenter ( x f , h f new ) (17) x_{\text{aug}} = \text{Augmenter}(x_f, h_f^{\text{new}}) \tag{17} xaug=Augmenter(xf,hfnew)(17)
最终,静态流的异常分数 s sta s_{\text{sta}} ssta 为:
s sta = Sigmoid ( FC ( x aug + MLP ( x aug ) ) ) (18) s_{\text{sta}} = \text{Sigmoid}(\text{FC}(x_{\text{aug}} + \text{MLP}(x_{\text{aug}}))) \tag{18} ssta=Sigmoid(FC(xaug+MLP(xaug)))(18)
融合预测. 两个流的异常分数融合得到最终预测:
s = β s dyn + ( 1 − β ) s sta (19) s = \beta s_{\text{dyn}} + (1 - \beta) s_{\text{sta}} \tag{19} s=βsdyn+(1−β)ssta(19)
其中 β \beta β 为控制两路权重的超参数。
3.6 损失函数(Objective Functions)
第一阶段训练. 本阶段聚焦于视频异常分类任务,仅训练 LSTM,其余模块保持冻结以避免冲突。分类损失为交叉熵损失 L ce \mathcal{L}_{\text{ce}} Lce,另加入分离损失 L sep \mathcal{L}_{\text{sep}} Lsep 以提升异常与正常的区分度:
L cat = L ce + L sep (20) \mathcal{L}_{\text{cat}} = \mathcal{L}_{\text{ce}} + \mathcal{L}_{\text{sep}} \tag{20} Lcat=Lce+Lsep(20)
L ce = − 1 N ∑ i = 1 N g i log ( p avg , i ) (21) \mathcal{L}_{\text{ce}} = -\frac{1}{N} \sum_{i=1}^{N} g_i \log(p_{\text{avg},i}) \tag{21} Lce=−N1i=1∑Ngilog(pavg,i)(21)
L sep = − 1 N ∑ i = 1 N [ max ( p avg , i [ 1 : ] ) − p avg , i [ 0 ] + 1 ] (22) \mathcal{L}_{\text{sep}} = -\frac{1}{N} \sum_{i=1}^{N} \left[ \max(p_{\text{avg},i}[1:]) - p_{\text{avg},i}[0] + 1 \right] \tag{22} Lsep=−N1i=1∑N[max(pavg,i[1:])−pavg,i[0]+1](22)
其中 p avg , i p_{\text{avg},i} pavg,i 为第 i i i 个样本的预测概率, g i g_i gi 为其标签的 one-hot 编码,正常类别置于索引 0 0 0, N N N 为批大小。
第二阶段训练. 本阶段聚焦于异常检测,训练动态和静态流,其他模块保持冻结。我们采用多实例学习(MIL)损失:
L det = L D-MIL + L S-MIL (23) \mathcal{L}_{\text{det}} = \mathcal{L}_{\text{D-MIL}} + \mathcal{L}_{\text{S-MIL}} \tag{23} Ldet=LD-MIL+LS-MIL(23)
具体为:对每个视频取其帧级分数中前 M M M 个平均,得到视频级预测 q ^ i \hat{q}_i q^i,再与视频标签 q i ∈ { 0 , 1 } q_i \in \{0,1\} qi∈{0,1} 计算二分类交叉熵损失,其中 X ∈ { D , S } X \in \{\text{D}, \text{S}\} X∈{D,S} 表示动态或静态流, w i w_i wi 为异常样本加权因子:
L X − MIL = − 1 N ∑ i = 1 N w i [ q i log ( q ^ i ) + ( 1 − q i ) log ( 1 − q ^ i ) ] (24) \mathcal{L}_{X-\text{MIL}} = -\frac{1}{N} \sum_{i=1}^{N} w_i \left[ q_i \log(\hat{q}_i) + (1 - q_i) \log(1 - \hat{q}_i) \right] \tag{24} LX−MIL=−N1i=1∑Nwi[qilog(q^i)+(1−qi)log(1−q^i)](24)
4. 实验结果
4.1 数据集与实现细节
数据集. 我们在两个广泛使用的基准数据集上验证了 Anomize 的性能:
- XD-Violence [41]:该数据集聚焦于暴力事件,是当前规模最大的相关数据集,包含 3954 个训练视频和 800 个测试视频,来自电影和 YouTube,涵盖 6 类异常事件,场景多样;
- UCF-Crime [33]:这是一个大规模监控视频数据集,包含 1610 个训练视频和 290 个测试视频,总长度约 128 小时,包含 13 类异常事件,涵盖室内外多种真实环境。
评估指标. 我们遵循以往工作 [33, 41] 的标准评估方法:
- 对于 UCF-Crime,使用 AUC(曲线下面积) 衡量模型在不同阈值下的整体检测能力;
- 对于 XD-Violence,使用 AP(平均精度) 衡量精确率和召回率的平衡;
- 在分类任务中,我们报告异常测试视频的 Top-1 分类准确率,分别统计 全部类别(总)、基础类别(subscript b b b) 和 新颖类别(subscript n n n)。
实现细节. 我们使用 PyTorch 在 RTX 4090 上训练模型,最大处理 256 帧。优化器为 AdamW [17],学习率为 2 × 1 0 − 5 2 \times 10^{-5} 2×10−5,批大小为 32。训练分为两个阶段,分别训练 16 和 64 轮。
我们采用预训练的 CLIP (ViT-B/16) 模型。MLP 模块包含两层全连接结构,激活函数为 GeLU。融合权重 α \alpha α 在训练时设为 1,测试时为 2。概念特征选择数 K K K:XD-Violence 为 25,UCF-Crime 为 5。融合异常分数的权重 β \beta β 在 XD-Violence 上为 1(基础类别为 0),在 UCF-Crime 上为 0.5(新颖类别为 0)。损失加权系数 w i w_i wi 根据每次迭代中正常与异常样本的比例动态调整。
4.2 与当前 SOTA 方法的对比
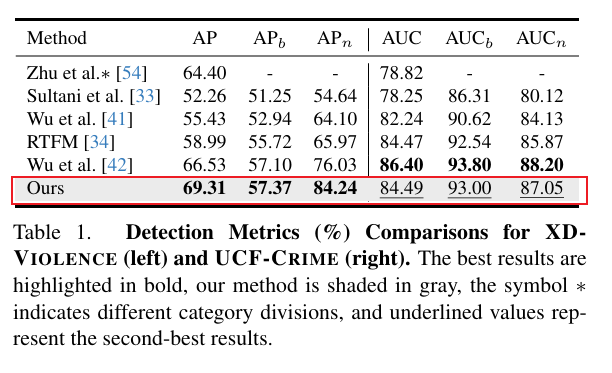
我们将方法与现有 VAD 方法进行对比,所有方法均使用 CLIP 提取的视觉特征,处于开放集设置下。
如表 1 所示,在 XD-Violence 上,我们在整体上提升了 2.78%,新颖类别上提升了 8.21%,表明 Anomize 有效缓解了检测歧义性问题。在 UCF-Crime 上,我们取得了与复杂 SOTA 模型相当的性能,得益于轻量级时间编码器和分阶段训练方式在检测分支上的适配。

由于多数方法仅关注检测任务,不含分类,我们将分类性能与 Wu 等人 [42] 的方法进行对比,结果见表 2。我们在 XD-Violence 上提升了 25.61%,UCF-Crime 上提升了 5.71%,新颖类别上分别提升了 56.53% 和 4.49%,证明方法显著减少了分类混淆。
4.3 消融实验(Ablation Studies)
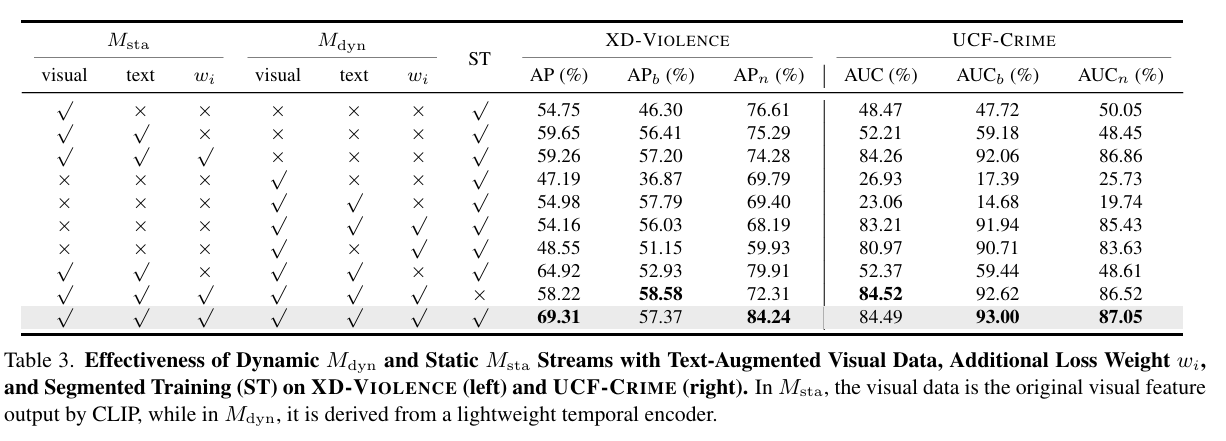
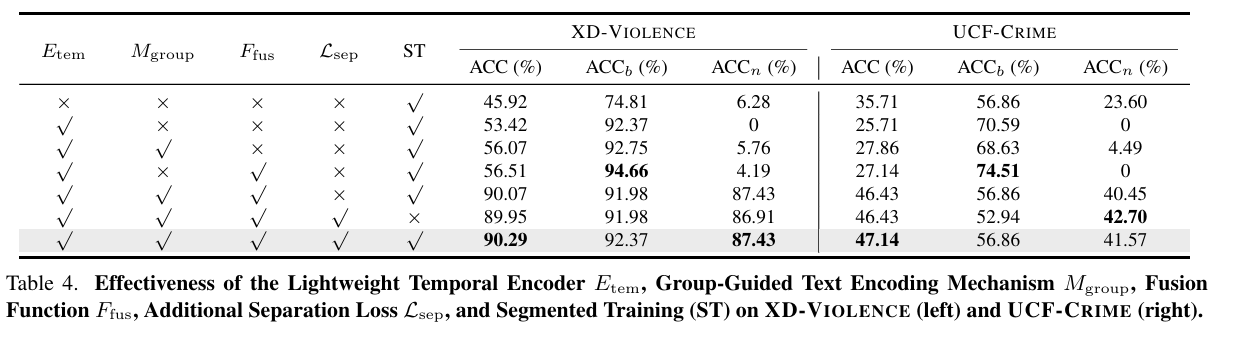
轻量级时间编码器的有效性. 如表 3 所示,动态流通过时间建模提供了关键的时序线索,有效补充静态流。虽然仅依赖时间信息会受噪声影响,但结合损失加权和文本增强后表现显著提升。表 4 也显示:添加时间编码器提升了基础类别的性能,但若无额外引导,对新颖样本仍存在混淆风险。
分组引导文本编码机制的有效性. 表 4 中第二行与第三行、第四行与第五行的对比显示,引入分组描述的文本编码优于基础方法,验证了我们所提出的文本编码机制的重要性。
文本增强的有效性. 表 3 显示,无论在动态流还是静态流中加入文本增强,均能减少检测歧义性。动态流中仅使用文本增强在 UCF-Crime 上略有下降,说明时间特征中存在一定噪声,但结合损失加权后显著恢复。
动态流与静态流整合的有效性. 表 3 第三、六和最后一行对比表明:两个流的整合优于单独使用,二者互为补充、相互约束。
额外损失设计的有效性. 表 3 强调了加权损失 w i w_i wi 在训练整合双流时的重要性。表 4 显示分离损失 L sep \mathcal{L}_{\text{sep}} Lsep 能缓解类别不平衡,提升性能。
分阶段训练的有效性. 表 3 和表 4 显示分阶段训练整体表现优于单阶段,尤其是在新颖类别上,说明单阶段训练可能引发优化冲突与过拟合风险。UCF-Crime 中,单阶段在新颖类别上略优但基础类别下降,说明存在随机性。
4.4 定性结果(Qualitative Results)
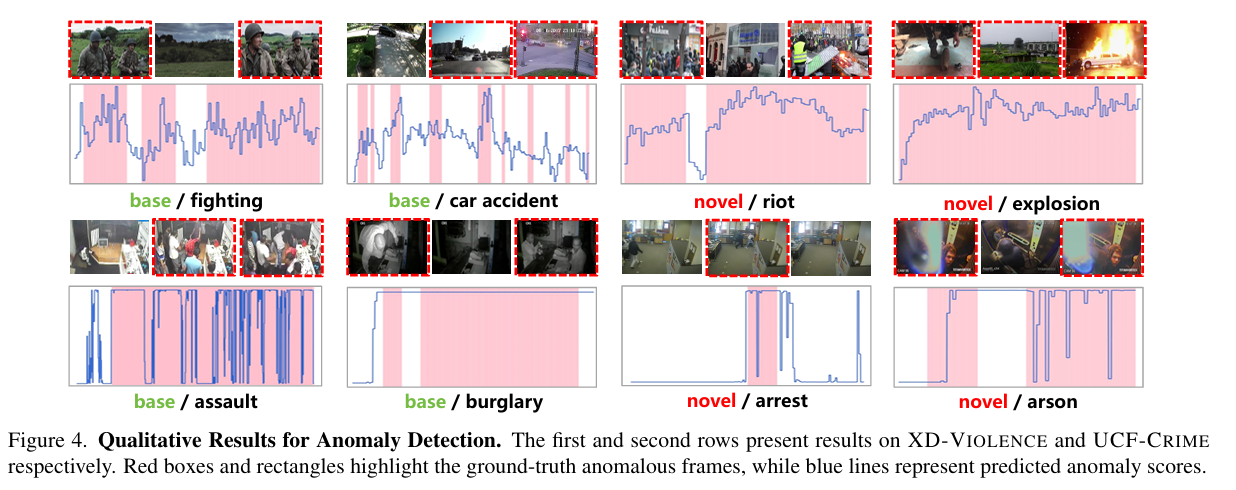
图 4 展示了模型在异常检测任务中的定性结果,分别从每个数据集中选取两个基础类别和两个新颖类别以覆盖所有标签分组。蓝色曲线表示模型预测的异常分数,粉色矩形表示真实异常时间段。可以观察到,模型能够准确定位异常片段,尤其在新颖类别上表现稳定,说明我们提出的文本增强双流机制为检测不熟悉异常提供了强有力的支持。
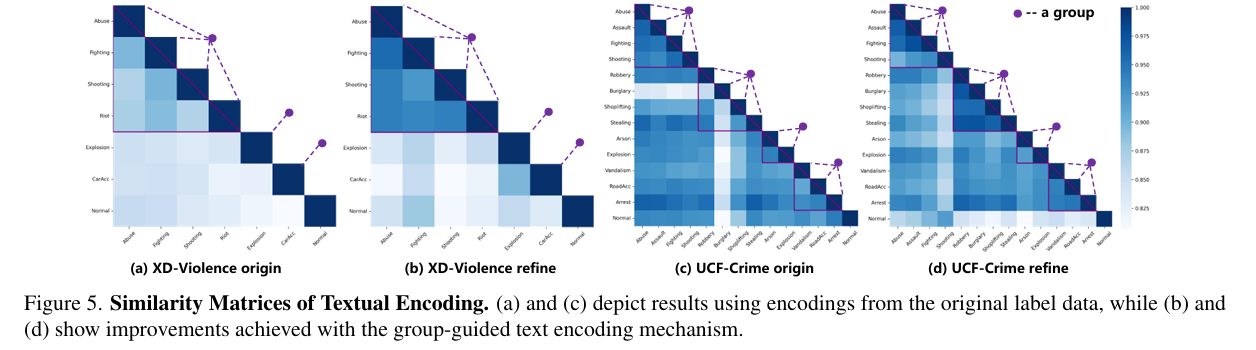
图 5 展示了标签文本编码的相似度矩阵:
- 图 5(a) 和 © 使用原始标签文本编码,可见即使标签在视觉上相似,其文本编码却分布分散,揭示了仅依赖预训练模型存在的对齐缺陷;
- 图 5(b) 和 (d) 则是经过分组引导文本编码机制后的结果,相似标签间的文本距离显著拉近,更好地与视觉特征对齐,验证了引导机制在多模态对齐中的有效性。
4.5 适应性与泛化能力(Adaptability and Generalization)
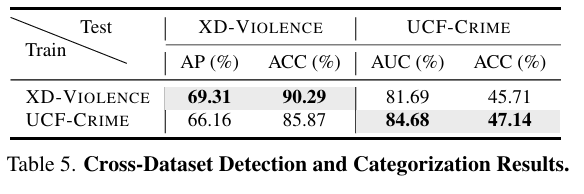
跨数据集能力分析. 表 5 展示了在一个数据集上进行开放集训练,然后在另一个数据集上直接测试的结果。例如,使用 XD-Violence 训练后在 UCF-Crime 上测试,依然取得了与目标数据集直接训练相当的性能。说明我们的方法具有良好的泛化能力。
开放词汇能力分析. 我们通过添加新标签数据的实验验证了 Anomize 在扩展类别空间时的稳定性,结果见表 6。添加数据来源于另一个数据集。
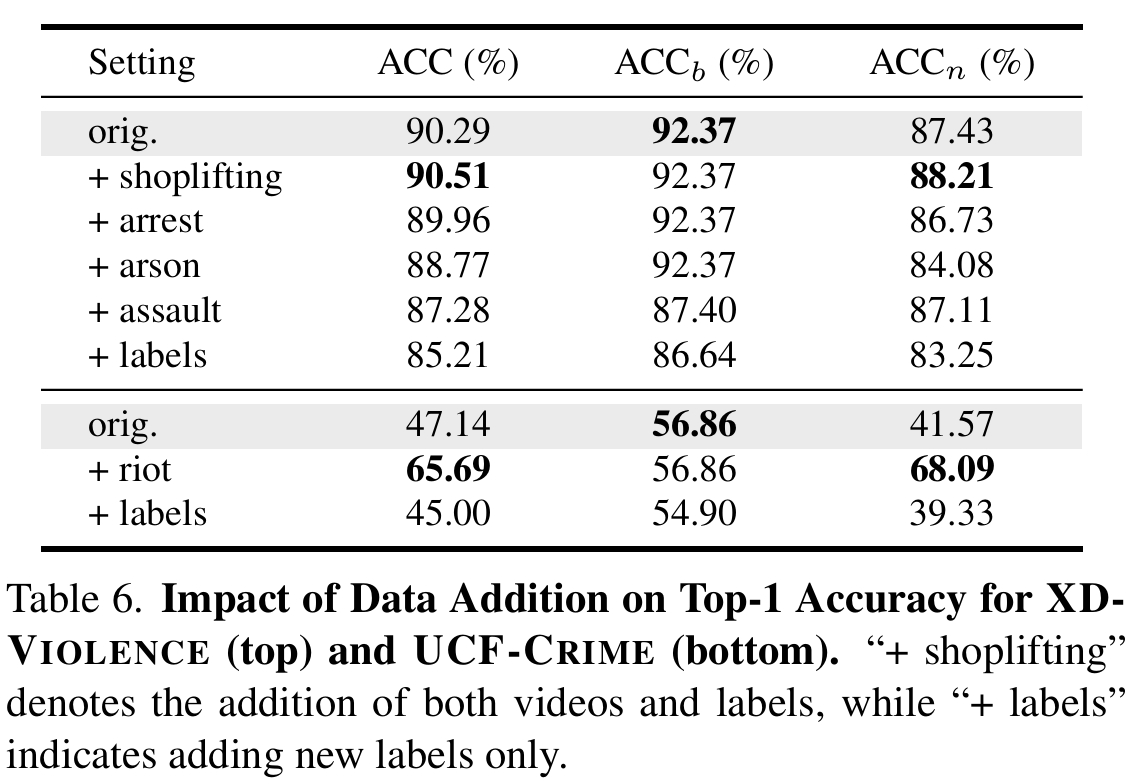
在 XD-Violence 上:
- 添加与原有标签属于同一组的标签(如 arson)以及不属于同组的标签(如 shoplifting)后,整体分类准确率变化不大;
- 唯一较明显的下降来自 assault 类,可能是由于其与 fighting 的视觉相似性导致混淆;
- 具体表现上,模型成功识别了 shoplifting(21/21)、arrest(3/5)、arson(7/10)、assault(3/3)等新标签。
在 UCF-Crime 上:
- 添加 riot 类显著提升了分类准确率,模型正确分类了其中 91/99 个样本;
- 虽然加入新标签会引入一些混淆,但整体性能保持稳健。
这说明:Anomize 能够在不重新训练的前提下,较好地适应新的开放词汇类别,具有良好的开放性和可扩展性。
5. 结论(Conclusion)
我们提出了 Anomize 框架,用于应对开放词汇视频异常检测(Open Vocabulary Video Anomaly Detection,OVVAD)中的两个关键挑战:检测歧义性(Detection Ambiguity)与分类混淆(Categorization Confusion)。
具体而言:
- 通过引入文本增强双流机制(Text-Augmented Dual Stream Mechanism),我们使用与异常相关的文本对视觉编码进行补充,增强了模型对不熟悉样本的检测能力,有效缓解了歧义性;
- 我们设计了分组引导文本编码机制(Group-Guided Text Encoding Mechanism),通过建立标签间的联系来优化文本编码,从而提升多模态对齐性能,缓解了新颖异常的分类混淆问题。
我们在两个主流开放场景数据集(XD-VIOLENCE 和 UCF-CRIME)上进行了实验,结果充分验证了 Anomize 在检测和分类两个任务上的有效性,尤其在处理新颖类别方面表现出显著优势。
附录:补充材料(Supplementary Material)
1. 概览(Overview)
本补充材料包括以下几个部分:
- 数据划分(Data Division)
- 添加数据的影响(Impact of Data Addition)
- 替换轻量级时间编码器的影响(Impact of Using Other Lightweight Temporal Encoder)
- 视频特征的 t-SNE 可视化(t-SNE Visualization of Video Features)
- 各类别结果可视化(Visualization of Per-Class Results)
- 提示词设计(Prompt Design)
- 局限性分析(Limitation)
2. 数据划分(Data Division)
在开放词汇视频异常检测(OVVAD)任务中,我们将异常标签划分为基础类别(base categories)与新颖类别(novel categories)。训练过程中仅使用基础类别的样本。
按照开放词汇学习的标准实践,出现频率较高的标签被指定为基础类别,稀有标签被定义为新颖类别:
- 对于 UCF-CRIME 数据集,基础类别为:Abuse、Assault、Burglary、Road Accident、Robbery 和 Stealing;
- 对于 XD-VIOLENCE 数据集,基础类别为:Fighting、Shooting 和 Car Accident。
3. 添加数据的影响(Impact of Data Addition)
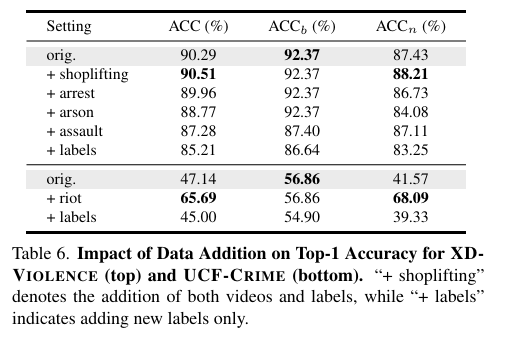
表 6 显示,添加新标签后整体性能下降可接受。新添加标签包括同组和跨组类别:
- 同组标签 与原训练标签相似,其编码距离较近,可能干扰原有预测,略微影响性能;
- 在两个数据集中,我们添加了如 drug trafficking、harassment、stalking、loitering、public intoxication;
- 另外 XD-VIOLENCE 中加入 shoplifting、arson、robbery 和 arrest;
- UCF-CRIME 中加入 riot。
详细分析如下:
- 添加 shoplifting 后,21 个样本中有 20 个被正确分类;
- arrest:5 个样本中正确分类 3 个;
- arson:10 个样本中正确分类 7 个;
- assault:3 个样本全部分类正确;
- riot:99 个样本中正确分类 91 个。
其中,shoplifting 是唯一未与基础标签同组的类别。这表明组内标签之间视觉编码相似性较高,更容易发生误判,但我们的方法依然取得了良好表现,说明引导文本编码机制能有效缓解分类混淆。
4. 替换时间编码器的影响(Impact of Using Other Lightweight Temporal Encoder)
我们在主文中采用了 LSTM 作为轻量级时间编码器,以降低对基础类别的过拟合,并减少新颖类别的混淆。该设计基于以下观察:
-
复杂度较高的时间编码器更容易过拟合训练数据;
-
这导致其对新颖数据提取的视觉特征容易与基础标签对齐,从而误分类。
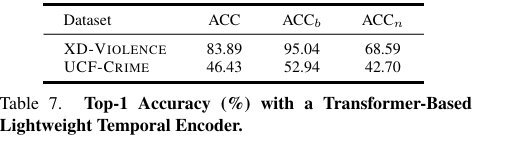
我们在补充实验中评估了基于 Transformer 的轻量级编码器,其结果如表 7 所示: -
Transformer 模型参数较多,导致整体性能不如 LSTM;
-
在 UCF-CRIME 上,Transformer 需使用更低的学习率( 5 × 1 0 − 8 5 \times 10^{-8} 5×10−8)避免过拟合;
-
虽然在新颖类别上有所提升,但对基础类别表现下降,最终整体性能更差。
无论使用哪种编码器,我们方法始终优于现有 SOTA,间接证明分组引导文本编码机制的有效性。
5. 视频特征的 t-SNE 可视化(t-SNE Visualization of Video Features)
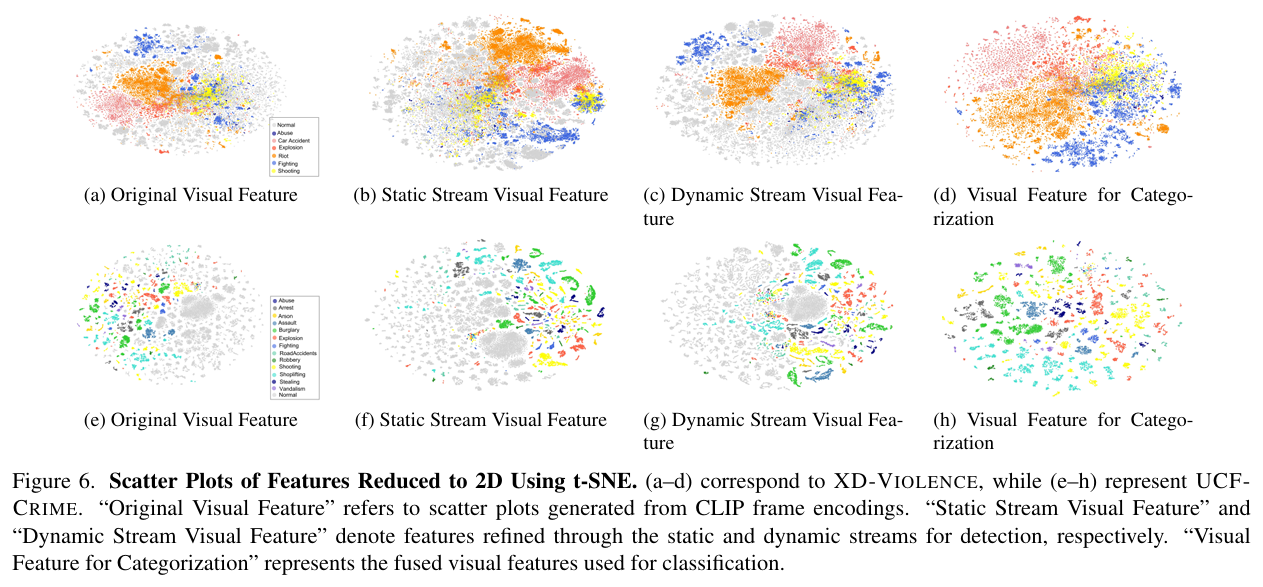
如图 6 所示:
- 原始 CLIP 编码(图 6a 和 6e)分布较为杂乱,不利于异常检测与分类;
- 静态流(图 6b、6f)与动态流(图 6c、6g)增强特征明显区分正常与异常,形成更清晰边界;
- **融合后的分类特征(图 6d、6h)**聚类更紧密,同一标签的样本靠近,提升分类性能。
注意:这些 t-SNE 图反映的是帧级特征。由于异常视频中也包含正常帧,因此部分样本点会有轻微重叠。
6. 每类别结果可视化(Visualization of Per-Class Results)
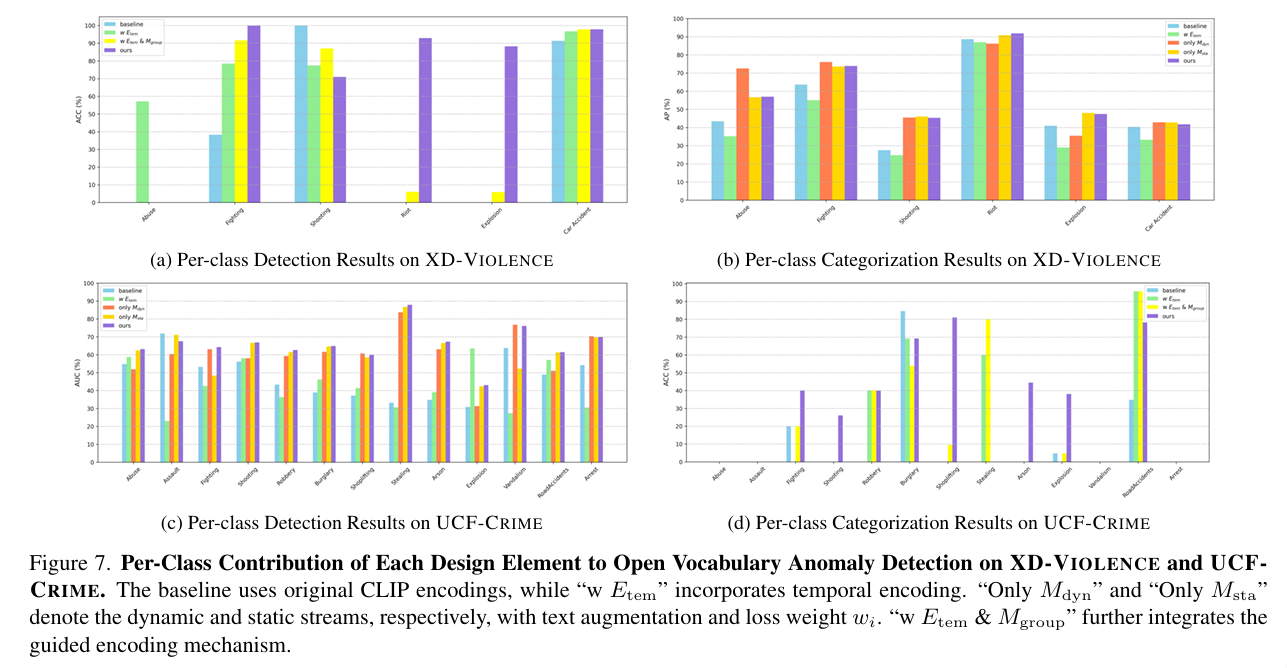
图 7 展示了我们各个设计组件在不同类别上的贡献,包括:
- 基线模型(使用原始 CLIP 编码);
- 加入时间编码器( w w w + E tem E_{\text{tem}} Etem);
- 分别使用动态流(Only M dyn M_{\text{dyn}} Mdyn)或静态流(Only M sta M_{\text{sta}} Msta)+ 文本增强 + 损失加权;
- 整合引导文本编码机制后的完整模型( w w w + E tem E_{\text{tem}} Etem + M group M_{\text{group}} Mgroup)。
在大多数基础和新颖类别上,我们的方法都实现了最佳或次优结果,证明其在检测和分类上的全面能力。
7. 提示词设计(Prompt Design)
为了更好地解释我们文本编码机制与 ConceptLib 概念库的设计优势,这里提供具体的提示词(prompt)示例。
我们使用 promptgroup 生成标签分组,人工修正噪声;再使用 promptdesc 为每组标签生成简洁的描述;promptconc 用于为 ConceptLib 生成名词短语。长度 L L L 与标签数成比例:
- XD-VIOLENCE(6 个标签): L = 200 L = 200 L=200
- UCF-CRIME(13 个标签): L = 500 L = 500 L=500
promptgroup.
将以下异常标签进行分组:{labels}。请根据视觉特征的相似性组织这些标签。具有相似行为、动作或场景背景的标签应归为同组。
promptdesc.
请描述以下异常类别:{labels}。每个描述开头一到两句话总结该组行为的共性,随后一到两句突出各类别的特征。请使用 50–70 个词描述每类异常的显著动作、行为及场景特征,保持一致的句式结构。
promptconc.
给定异常标签 {labels},请为每个标签生成 L L L 个名词短语,准确刻画与该标签相关的场景元素。这些短语应适用于 CLIP 模型文本编码,并能补充视觉特征,提升异常检测性能。
8. 局限性(Limitation)
本文在语义层面将动态元素(如行为描述句子)与静态元素(如名词词组)区分开。虽然两者之间可能存在轻微冗余,但并不会影响最终性能。
我们认为,若未来进一步在特征级别对这两类信息进行解耦建模,可能会带来额外性能提升。